Amazon (AWS)
Amazon является поставщиком инфраструктуры как сервиса (infrastructure as a service, IaaS). Другими словами, Amazon обеспечивает набор базовых служб для использования компьютерной инфраструктуры (ресурсов процессоров, хранения данных и сети), установки некоторой платформы (например, сервер Web и приложений Tomcat и сервер баз данных MySQL) и запуска приложения на этой платформе. Тем самым, Amazon обеспечивает отличную основу для реализации различных архитектурных вариантов. Основными службами Amazon, которые использовались в экспериментах, описываемых в этой статье, являются EC2 (для получения ресурсов процессоров), EBS (для получения сервиса хранения, который можно монтировать подобно диску) и S3 (для получения области хранения, которую можно использовать для хранения данных "ключ-значение"). Поскольку эти службы могли бы запросто обеспечиваться другими поставщиками "облачных" служб, все архитектурные варианты, реализуемые поверх инфраструктуры Amazon, объявляются в табл. 1 гибкими (flexible). В последние два года компания Amazon стала обеспечивать более развитые службы, такие как RDS и SimpleDB. Эти службы доступны только в "облачной" среде Amazon. Все службы Amazon подробно описаны в [1], включая цены на использование каждого сервиса. В следующих пунктах этого подраздела описывается, как мы реализовали пять разных архитектурных вариантов с использованием служб Amazon (AWS).
Анализ альтернативных архитектур управления транзакциями в "облачной" среде
Дональд Коссман, Тим Краска и Саймон Лоузинг
Перевод: Сергей Кузнецов
Оригинал: Donald Kossmann, Tim Kraska, Simon Loesing. An evaluation of alternative architectures for transaction processing in the cloud. Proceedings of the 2010 International Conference on Management of Data (SIGMOD 2010), June 6-11, 2010, Indianapolis, Indiana, USA, pp. 579-590
This translation is a derivative of ACM-copyrighted material. ACM did not prepare this translation and does not guarantee that it is an accurate copy of the originally published work. The original intellectual property contained in this work remains the property of ACM.
Дональд Коссман, Тим Краска и Саймон Лоузинг
Перевод: Сергей Кузнецов
Дональд Коссман, Тим Краска и Саймон Лоузинг
Перевод: Сергей Кузнецов
Дональд Коссман, Тим Краска и Саймон Лоузинг
Перевод: Сергей Кузнецов
Дональд Коссман, Тим Краска и Саймон Лоузинг
Перевод: Сергей Кузнецов
Дональд Коссман, Тим Краска и Саймон Лоузинг
Перевод: Сергей Кузнецов
Анализ стоимости
На рис. 11 показаны дневная стоимость сетевого трафика, ресурсов процессоров и хранения данных. Стоимость сетевого трафика показана красным цветом. Стоимость сетевого трафика является полностью изменичивой, зависящей от рабочей нагрузки. На рис. 11 фиксированная часть стоимости ресурсов процессоров показана оранжевым цветом, а переменная часть – желтым цветом. Фиксированная часть стоимости ресурсов процессоров – это стоимость резервирования машин. Переменная часть этой стоимости определяется дополнительными расходами при реальном использовании ресурсов процессоров. Например, стоимость виртуальных машин EC2 зависит от интенсивности их использования. У стоимости хранения данных также имеются фиксированный и переменный компоненты. Фиксированной частью стоимости хранения данных является месячная стоимость хранения базы данных. Переменная часть этой стоимости определяется затратами на выполнение каждого запроса чтения данных из базы данных и записи данных. Как будет показано в подразделе 6.5, фиксированная часть стоимости хранения данных для наших экспериментов не существенна, и поэтому на рис. 11 синим цветом показано одно значение показателя стоимости хранения данных как суммы фиксированной и переменных частей. На рис. 11 для каждого варианта при EB=250 показано разбиение общей стоимости по видам ресурсов (сеть, процессоры, хранение данных). Как и ранее, для краткости опущены результаты для MySQL/R и Google AE без кэширования (они аналогичны результатам для MySQL и Google AE с кэшированием соответственно).
Как видно на рис. 11, в общей стоимости для варианта MySQL при EB=250 доминирует стоимость сетевого трафика. Еще одним существенным фактором является стоимость резервирования виртуальных машин EC2 для серверов Web и приложений, а также серверов баз данных. Все остальные факторы стоимости являются незначительными. Для SimpleDB в общей стоимости доминирует (переменная) стоимость процессорных ресурсов, требуемых для выполнения запросов на чтение и запись данных.
Как отмечалось в предыдущем пункте, SimpleDB является дорогостоящей службой. Все остальные факторы стоимости для SimpleDB не сильно отличаются от факторов стоимости других вариантов. У варианта S3 значительную часть общей стоимости составляет стоимость хранения данных, поскольку (как отмечалось в предыдущем пункте) стоимость чтения и записи данных в S3 значительно больше соответствующей стоимости EBC. Все остальные факторы стоимости S3 сопоставимы с соответствующими факторами стоимости других вариантов, реализованных в "облачной" среде Amazon.
Легко видеть, что Google AE является единственным вариантом без фиксированных затрат на резервирование процессорных ресурсов. Стоимость этих ресурсов является полностью переменной, но даже при наличии средней рабочей нагрузки в 250 EB, она значительна. Тем не менее, отсутствие какой-либо фиксированной стоимости (имеется только несущественная фиксированная часть стоимости хранения базы данных в облачной среде Google) делает службы Google привлекательными для небольших приложений.
Еще раз заметим, что, по-видимому, Azure ориентируется на сектор рынка, в котором Microsoft не будет конкурировать с Google. Microsoft назначает фиксированную цену на резервирование машин для серверов приложений и баз данных. Однако после соответствующей оплаты при реальном использовании этих машин никакие дополнительные переменные расходы не возникают.

Рис. 12. MySQL: факторы стоимости при изменении числа EB

Рис. 13. RDS: факторы стоимости при изменении числа EB

Рис. 14. SimpleDB: факторы стоимости при изменении числа EB

Рис. 15. S3: факторы стоимости при изменении числа EB

Рис. 16. AE/C: факторы стоимости при изменении числа EB

Рис. 17. Azure: факторы стоимости при изменении числа EB
Рис. 12-17 подтверждают эти результаты. На этих рисунках визуализируется процентное соотношение факторов стоимости для каждого варианта в зависимости от рабочей нагрузки. Рис. 12 и 13 для MySQL в RDS закрашены, в основном, красным цветом, поскольку в общей стоимости этих вариантов доминирует стоимость сетевого трафика, почти независимо от рабочей нагрузки.
Только при небольших рабочих нагрузках (EB<100) существенной становится стоимость резервирования машин (оранжевая часть рисунков). На обоих рисунках интересный эффект представляют зигзаги. Каждый такой шаг (при EB>1500) показывает, что на уровне серверов Web и приложений добавилась еще одна виртуальная машина EC2, чтобы система могла справиться с возросшей рабочей нагрузкой.
Рис. 14 подверждает, что в общей стоимости варианта SimpleDB доминирует стоимость выполнения запросов и операций обновления данных службой SimpleDB. Соответственно, рис. 15 показывает, что при наличии высоких рабочих нагрузок (EB>1000) в стоимости архитектуры распределенного управления, реализованной поверх S3, доминирует стоимость использования службы AWS S3. При наличии небольших рабочих нагрузок доминируют фиксированная стоимость резервирования машин EC2 и стоимость сетевого трафика.
Рис. 16 подтверждает, что в общей стоимости варианта Google AE доминирует (переменная) стоимость процессорных ресурсов. Только при наличии очень низких рабочих нагрузок (EB<10) в стоимости этого варианта доминирует стоимость хранения данных (синяя часть рисунка), но при таких рабочих нагрузках общая стоимость является пренебрежимо малой (несколько центов). В отличие от этого, рис. 17 в основном закрашен красным, что подтвреждает доминирование в общей стоимости варианта Azure стоимости сетевого трафика – как и для вариантов MySQL. На рис. 17 имеются такие же зигзаги, как и на рис. 12 и 13, возникающие при добавлении нового сервера приложений при очередном возрастании рабочей нагрузки на 1500 EB.
Как и раньше, эти результаты являются артефактами моделей ценообразования поставщиков "облачных" служб. Вероятно, представленные результаты скоро изменятся, как только возрастет уровень конкуренции между компаниями. Тем не менее, важно понимать факторы стоимости системы. Например, в прошлом, (переменная) стоимость процессорного времени уменьшалась быстрее стоимости сетевого трафика.
Табл. 5.Вертикальное масштабирование RDS: пропускная способность, Cost/WIPS, предсказуемость стоимости

Аннотация
"Облачные" вычисления (cloud computing) сулят ряд преимуществ для развертывания приложений, насыщенных данными (data-intensive application). Одна из важных перспектив состоит в снижении расходов на основе использования бизнес-модели "платы по мере использования" (pay-as-you-go). Еще одной перспективой является (практически) неограниченная производительность, достигаемая путем увеличения числа серверов при возрастании рабочей нагрузки. В этой статье рассматриваются альтернативные архитектуры, поддерживающие "облачное" выполнение приложений баз данных, и приводятся результаты тщательного анализа существующих коммерческих "облачных" служб, которые основаны на этих архитектурах. В центре внимания этой работы находится обработка транзакций (т.е. рабочие нагрузки с чтением и обновлением данных), а не аналитические рабочие нагрузки, привлекающие в последнее время большое внимание исследователей. Полученные результаты неожиданны в нескольких отношениях. Наиболее важно то, что, как нам представляется, в "облачных" службах всех основных поставщиков применяются разные архитектуры. В результате стоимость и производительность этих служб существенно изменяются в зависимости от особенностей рабочей нагрузки.
Архитектуры распределенных систем баз данных
В этом разделе заново пересматриваются архитектуры распределенных систем баз данных, используемые в сегодняшних "облачных" вычислениях. В качестве отправной точки описывается классическая многозвенная архитектура приложений баз данных. Затем обсуждаются четыре разновидности этой арихитектуры. Эти разновидности основаны на простых принципах распределенных баз данных – приниципах репликации, разделения и кэширования. Интересным аспектом является то, как эти понятия оформляются и применяются в коммерческих "облачных" службах (разд. 4).

Рис. 1. Классическая архитектура системы баз данных
AWS MySQL
Первый вариант изучался в соответствии с классической архитектурой рис. 1. Этот вариант можно считать базовым для всех экспериментов, потому что он следует классической (не допускающей использование "облачной" среды) модели развертывания корпоративного Web-приложения. В своей реализации мы использовали переменное число машин EC2 для запуска серверов Web и приложений и выполнения логики приложения (тестового набора TPC-W). Мы изменяли число машин EC2 в зависимости от рабочей нагрузки. В качестве комбинированного сервера Web и приложений использовался Tomcat версии 6.0.18. На уровне сервера баз данных мы использовали MySQL версии 5.0.51 с InnoDB, работающий в среде Ubuntu 8.04. Сервер MySQL работал на отдельной машине EC2. В качестве системы хранения мы использовали EBS для хранения и базы данных, и журналов. EBS гарантирует персистентность (данные EBS реплицируются). Теоретически, базу данных можно было бы сохранять и на локальных дисках машин EC2, на которых работает сервер MySQL. Однако этот подход привел бы к утрате всех данных в случае отказа машины EC2. Поэтому возможность такого варианта в экспериментах не предусматривалась. Что же касается производительности, то на рис. 6 приводятся результаты сравнения производительности EBS при выполнении операций чтения и записи с соответствующими показателями локально подключенного диска. Как можно видеть, пропускная способность обоих вариантов примерно одна и та же.

Рис. 6. Производительность EBS при выполнении операций чтения/записи
AWS MySQL/R
Для исследования архитектуры с репликацией (рис. 3) мы использовали MySQL Replication версии 5.0.51 на некотором наборе машин EC2. В этом варианте мы использовали для хранения базы данных (более дешевые) локальные диски машин EC2, поскольку долговечность данных обеспечивалась архитектурой репликации. EBS использовалось только для журналов эталонной копии. Эти журналы требовались для перехода к использованию резервного оборудования после отказа мастер-сервера.
В MySQL Replication используется протокол ROWA/эталонная копия, описанный в подразделе 3.3, для синхронизации всех запросов на обновление, а запросы от приложений на чтение могут обрабатываться любым сервером-сателлитом. Репликация не является прозрачной. Поэтому в каждом сервере приложений поддерживаются подключения к мастер-серверу и к одному серверу-сателлиту. Запросы обновляющих транзакций обрабатываются мастер-сервером, в то время как запросы только читающих транзакций направляются серверам-сателлитам, ассоциированным с сервером приложений. Как и при использовании AWS MySQL Tomcat использовался как интегрированный сервер Web и приложений, и число машин для этого уровня изменялось в зависимости от рабочей нагрузки.
Мы также экспериментировали с MySQL Cluster версий 5.0.51 и 7.0.8a. Использование MySQL Cluster сулило горизонтальное масштабирование при наращивании числа серверов [17]. К сожалению, обе эти версии MySQL Cluster показали в наших экспериментах производительность, худшую, чем у одиночной системы MySQL (AWS MySQL), и поэтому мы не представляем полученные результаты в этой статье. Мы не можем объяснить, почему нам не удалось воспроизвести результаты [17] в "облачной" среде Amazon.
AWS RDS
В конце 2009 г. компания Amazon выпустила RDS – службу реляционных баз данных (relational database service). По существу, RDS реализует такую же платформу, что и описанный выше подход AWS MySQL. Поэтому мы полагаем, что эти подходы обеспечивают примерно одинаковую производительность с близкими затратами. Различием является то, что RDS заранее комплектуется таким образом, что пользователям не приходится беспокоиться о развертывании, внесении исправлений и обновлений в программное обеспечение, а также о резервном копировании данных. RDS доступна в пяти разных "размерах", начиная от небольших серверов и заканчивая учетверенными сверхбольшими серверами баз данных. Очевидно, что для поддержки слабых рабочих нагрузок достаточно небольшого сервера, а крупные серверы нужны при наличии тяжелых рабочих нагрузок, содержащих много запросов на чтение и обновление. Соответственно, цены использования RDS меняются от $0,11 в час для небольшого сервера до $3,11 в час для учетверенного сверхбольшого сервера. За счет этого RDS поддерживает вертикальное масштабирование (scale-up) на уровне баз данных. Однако, поскольку RDS основывается на классической архитектуре, она не может обеспечить горизонтальное масштабирование (scale-out) за счет увеличения числа серверов баз данных.
В качестве четвертого архитектурного варианта мы реализовали средства выполнения тестового набора прямо поверх S3. Этот вариант соответствует архитектуре распределенного управления, представленной на рис. 4. В S3 обеспечивается только низкоуровневый интерфейс put/get, так что все высокоуровневые службы типа обработки SQL-запросов и индексации на основе B-деревьев было необходимо реализовать как часть приложения. Мы включили эти средства в состав библиотеки, поддерживающей основные средства управления базами данных для поддержки выполнения тестового набора TPC-W. Для повышения производительности эта библиотека сохраняла несколько кортежей в одном объекте S3. Кроме того, в этой библиотеке был реализован протокол, синхронизующий паралельный доступ к одним и тем же объектам S3 от нескольких серверов приложений. Для этой цели мы использовали базовый протокол, предложенный в [3]. Этот протокол простым образом реализуется поверх S3. Как и в варианте AWS SimpleDB, протокол поддерживает только согласованность в конечном счете. Более высокие уровни согласованности можно реализовать с использованием других протоколов из [3], но в своем исследовании мы этим не занимались, чтобы не отклоняться от основной цели работы. Для улучшения производительности в серверах приложений выполнялось кэширование объектов S3. В частности, объекты S3, представляющие страницы индекса в виде B-дерева, сохранялись в кэше серверов приложений даже за пределами границ транзакций. Базовый протокол, описанный в [3], применим и для обеспечения корректности при кэшировании страниц данных и индексов.
В [3] для реализации основного протокола поддержки долговечности транзакций и согласованности данных в конечном счете использовалась служба поддержки персистентных очередей Amazon SQS (Simple Queue Service). В описываемом исследовании мы использовали этот подход и реализовали базовый протокол на основе собственной реализации очередей. Наши очереди поддерживались на переменном числе машин EC2 и EBS, чтобы обеспечить сохранность журналов очередей в случае отказов машин. В зависимости от рабочей нагрузки число машин EC2 изменялось от одной до пяти. Период TTL (time to live – время жизни) для кэширования устанавливался в 120 секунд, а интервал установки контрольных точек (определенный в [3]) – в 10 секунд. Установка контрольных точек производилась под воздействием сторожевого таймера (watchdog) [3].
В качестве интегрированного сервера Web, приложений и баз данных использовался сервер Tomcat и библиотека, в которой реализовывались основные контрукции SQL и поддержка согласованности. В заисимости от рабочей нагрузки изменялось число используемых машин EC2.
AWS SimpleDB
Как упоминалось в начале этого подраздела, у Amazon также имеется собственная служба баз данных – SimpleDB. SimpleDB поддерживает простой интерфейс, позволяющий пользователям вставлять, модифицировать и удалять записи. Кроме того, эта служба позволяет выбирать записи на основе значений их ключей или диапазонов значений первичных и вторичных ключей. Подробности реализации SimpleDB не опубликованы. Из личных бесед с техническими специалистами Amazon нам удалось узнать, что архитектура SimpleDB лучше всего характеризуется как комбинация разделения (рис. 2) и репликации (рис. 3). Однако, в отличие от MySQL Replication, SimpleDB не синхронизует обращения по чтению и записи к разным копиям одних и тех же данных, так что эта служба поддерживает только низкий уровень согласованности, называемый согласованностью в конечном счете (eventual consistency) [29]. К марту 2010 г. в SimpleDB в качестве наивысшего уровня согласованности также поддерживалось "согласованное чтение". К сожалению, мы не могли учесть наличие этого релиза в своих эккспериментах, потому что он появился слишком поздно.
На уровне приложения вариант AWS SimpleDB реализуется с использованием той же конфигурации, что и другие варианты AWS, т.е. Tomcat с переменным числом машин EC2. Поскольку в SimpleDB не поддерживается SQL, операции SQL, подобные соединению и агрегации, необходимо реализовывать на уровне приложения. Для этого мы реализовали (Java-) библиотеку с этими операциями SQL и вручную оптимизированными SQL-запросами (т.е. с выбранными порядками и методами выполнения соединений). Очевидно, что для применения этого подхода потребовалась пересылка всех требуемых данных из SimpleDB в серверы приложений, что привело к ухудшению производительности по сравнению с подходом пересылки запросов, выполняемых полнофункциональными SQL-ориентированными системами баз данных.
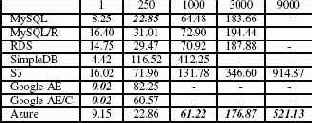
Cost/WIPS
В табл. 3 приводятся значения показателя Cost/WIPS для альтернативных вариантов при изменении числа EB. Как обсуждалось в подразделе 6.1, при низких рабочих нагрузках (менее 100 EB) самым дешевым является Google AE, а при средних и высоких рабочих нагрузках – Azure. Стоимость трех вариантов MySQL (MySQL, MySQL/R и RDS) при средних рабочих нагрузках (EB=100 и EB=3000) (почти) такая же, как у Azure, но они не справляются c высокими рабочими нагрузками (подраздел 6.2).
Табл. 6. Время и стоимость массовой загрузки; размер базы данных и стоимость хранения
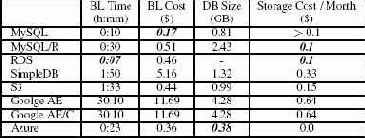
Выдающиеся стоимостные показатели Google AE при низких рабочих нагрузках объясняются двумя причинами. Во-первых, Google AE является единственным вариантом без фиксированных расходов. Требуется только незначительный помесячный платеж за хранение базы данных (см. табл. 6). Во-вторых, во время выполнения этих экспериментов компания Google позволила бесплатно использовать шесть часов процессорного времени в день. Поэтому приложения, укладывающиеся в эту квоту или требующие лишь ненамного больших процессорных ресурсов, оказывались особенно дешевыми.
Azure и варианты MySQL побеждают при средних и высоких рабочих нагрузках, поскольку при таких рабочих нагрузках фиксированные расходы амортизируются. Для SQL-сервера Azure помесячная плата составляет $100, если размер базы данных не превышает 100 гигабайт, независимо от числа запросов, которые придется обработать серверу. При использовании MySQL и MySQL/R необходимо арендовать виртуальные машины EC2, чтобы поддерживать базы данных в режиме онлайн. Аналогично, при использовании RDS требуется вносить фиксированную почасовую плату, так что стоимость в расчете на WIPS уменьшается при возрастании рабочей нагрузки. Следует заметить, что при использовании "облачных" служб Google сетевой трафик обходится дешевле, чем при использовании служб Amazon и Microsoft.
Этот анализ стоимости в значительной мере является артефактом бизнес-моделей, используемых компаниями Amazon, Google и Microsoft. Очевидно, что все поставщики в любой момент времени могут изменить свою политику ценообразования, и Amazon в прошлом часто уже это делала. Однако анализ стоимости показывает, в расчете на какой вид рабочей нагрузки оптимизируется та или иная служба. Google, очевидным образом, нацелена на бюджетный рынок, а Microsoft, похоже, ориентируется на корпоративных заказчиков. Кроме того, мы полагаем, что стоимость в действительности является хорошим показателем эффективности приложений.
Табл. 4. Общая стоимость за день (в долларах), изменяется число EB
Cтоимость за день
В табл. 4 показана общая стоимость за день использования альтернативных подходов при изменяющейся нагрузке (числе EB). (Знак "-" показывает, что данный вариант не смог справиться с данной нагрузкой.) Эти результаты согласуются с наблюдениями предыдущего пункта: Google выигрывает при наличии низких рабочих нагрузок; Azure выигрывает при наличии средних или высоких рабочих нагрузок. Все остальные варианты занимают промежуточные позиции. Три варианта MySQL близки по стоимости к Azure в дипазоне рабочих нагрузок, с которыми они справляются. Еще раз заметим, что в Azure и трех вариантах MySQL применяются примерно одни и те же архитектурные принципы (классическая архитектура плюс репликация с использованием эталонной копии). В этом эксперименте особняком стоит SimpleDB. При используемой в настоящее время схеме ценообразования SimpleDB является исключительно дорогостоящей службой. Высокая стоимость SimpleDB особенно досадна при большом числе EB, поскольку пользователям приходится платить даже в той ситуации, когда SimpleDB не обрабатывает много запросов и не справляется с рабочей нагрузкой.
Как показывает табл. 4, общая стоимость использования S3 линейно возрастает при росте рабочей нагрузки. Это именно то поведение, которого следовало бы ожидать от модели "платы по мере использования". Для S3 высокая стоимость соответствует высокой пропускной способности, так что высокая стоимость S3 при наличии высоких рабочих нагрузок является допустимой. Это наблюдение подтвержается хорошими значениями показателя Cost/WIPS для S3 при наличии высоких рабочих нагрузок (табл. 3). Тем не менее, для большинства рабочих нагрузок S3 является более дорогостоящей, чем другие варианты (за исключением SimpleDB). Это явление можно объяснить моделями ценообразования Amazon для EBS и S3. Например, операция записи в S3 обходится в сотни раз дороже, чем операция записи в EBS (а эта служба используется в вариантах MySQL). Amazon может оправдать эти различия тем, что S3 поддерживает параллельное выполнение операций обновления с обеспечением соласованности в конечном счете, а EBS поддерживает только последовательное выполнение операций записи (и чтения).

Рис. 11. Факторы стоимости при 250 EB (в долларах)
Анализ альтернативных архитектур управления транзакциями в облачной среде
В отличие от Amazon, компания Google следует только стратегии платформа как сервис (platform as a service, PaaS). Google AppEngine – это служба, позволяющая развертывать приложения целиком, не обеспечивая при этом контроля над компьютерными ресурсами. Google AppEngine автоматически увеличивает и уменьшает объем ресурсов, потребляемых приложением, в зависимости от рабочей нагрузки. В качестве языков программирования поддерживаются Python и Java со встраиваемым SQL для обеспечения доступа к базам данных. Мы использовали Java-версию Google AppEngine с Google SDK 1.2.4 и отображение данных на основе JPA (Java Persistence API). К сожалению, в Google поддерживается только упрощенный диалект SQL, называемый GQL. Поскольку возможностей GQL нам не хватало, мы реализовали отсутствующие функциональные возможности на языке Java в составе библиотеки (точно так же, как для вариантов с AWS S3 и AWS SimpleDB). Например, в GQL не поддерживаются группировки, агрегатные функции, соединения и предикаты LIKE. Как и Amazon в случае SimpleDB, Google не публикует какие-либо подробности о своей реализации GQL и распределенной системы баз данных. Согласно [13], в Google AppEngine применяется комбинированная архитектура с разделением и репликацией (рис. 2 и 3).
Одной из приятных особенностей Google AppEngine является то, что в этой службе поддерживается MemCache. Поэтому в Google AppEngine обеспечивается удобный интерфейс, позволяющий программистам приложений помещать объекты в MemCache и выбирать их оттуда. При использовании MemCache Google AppEngine полностью следует архитектуре, изображенной на рис. 5. Мы экспериментировали с обоими вариантами (кэширующим и некэширующим).
Горизонтальное масштабирование (scale-out)
На рис. 7 показана производительность в WIPS, достигнутая каждым из вариантов, как функция от числа EB. Для упрощения понимания на рис. 7 не показаны результаты для Google AppEngine без кэширования и для MySQL/R. Служба Google AppEngine без кэширования продемонстрировала почти такую же производительность, что и Google AppEngine с кэшированием, во всех случаях немного худшую, но различия были незначительными, и кривая на графике получилась почти такой же. Служба MySQL/R показала почти такую же производительность, что и MySQL; снова во всех случаях производительность MySQL/R была немного хуже, чем MySQL/R, но кривые на графике почти не отличаются. При наличии рабочих нагрузок с большим числом запросов на обновление данных (таких как рабочая нагрузка "оформления заказов" в TPC-W) мастер-сервер становится узким местом, и горизонтальное масштабирование только читающих транзакций за счет увеличения числа серверов-сателлитов не приводит к какому-либо выигрышу в производительности.
Рис. 7 показывает, что единственными масштабируемыми вариантами являются S3 и Azure. Как отмечалось в предыдущем подразделе, S3 – это единственный вариант, основанный на архитектуре без узких мест. Azure хорошо масштабируется за счет использования мощных машин для поддержки серверов баз данных. Оба эти варианта идеально масштабируются вплоть до 9000 EB и достигают максимальной пропускной способности при наличии 9000 EB. Для сравнения, идеальная пропускная способность некоторой абсолютно совершенной системы показана на рис. 7 точечной линией. У всех других вариантов имеется предел масштабируемости, и они не справляются с нагрузкой при возрастании числа EB выше этого предела. Базовые варианты, основанные на MySQL и RDS, достигают своего предела при числе EB около 3500; для SimpleDB предел наступает при примерно 3000 EB; для Google AE с кэшированием пределом является несколько сотен EB.

Рис. 8. RDS: WIPS(EB)

Рис. 9. SimpleDB: WIPS(EB)
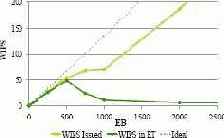
Рис. 10. AE/C: WIPS(EB)
Поведение архитектурных вариантов в ситуациях перегрузки поразительным образом различается.
На рис. 8- 10 более детально показано поведение AWS RDS, SimpleDB и Google AppEngine по отношению к производительности. Как и на рис. 7, на этих рисунках показаны идеальное поведение (точечная линия) и наблюдаемое (WIPS) поведение (зеленая линия). Кроме того, желтая линия показывает число поступающих запросов. Напомним (см. разд. 5), что в тестовом наборе TPC-W специфицируется, что клиент (т.е. эмулируемый браузер) ожидает ответа до направления своего следующего запроса. Поэтому, если система не справляется с нагрузкой и больше не производит ответов, то число поступающих запросов становится меньше, чем в идеальной системе. Очевидно, что линия WIPS должна находится ниже линии поступающих запросов. На рис. 8-10 демонстрируются следующие эффекты, возникающие в ситуациях перегрузки разных вариантов:
RDS (рис. 8): Пропускная способность RDS прекращает расти после возрастания числа EB до 3500 и остается после этого неизменной. Другими словами, обеспечиваются ответы на все запросы, но на все большее число запросов ответы не поступают за время, специфицированное в тестовом наборе TPC-W. Напомним, что вариант MySQL с технической точки зрения является тем же, что и RDS, и поэтому обладает таким же поведением (для краткости не показанным на рисунках).
SimpleDB (рис. 9): Рис. 7 показывает, что максимальная пропускная способность достигается при наличии 3000 EB и составляет более 200 WIPS. В действительности, служба SimpleDB в наших экспериментах стала перегруженной уже при 1000 EB и пропускной способности в 128 WIPS. В этом состоянии SimpleDB перестала справляться с запросами записи в горячие точки (hot spot). В тестовом наборе TPC-W часто обновляются объекты позиция заказа (item), и соответствующие запросы на обновление перестали обрабатываться. В соответствии с правилами тестового набора TPC-W недопустимой является ситуация, в которой система не может обработать более 10% запросов любой категории (разд. 5). В результате в табл. 2 в качестве показателя пиковой производительности зафиксировано 128 WIPS.
В ситуации перегрузки SimpleDB просто отказывается обрабатывать запросы и возвращает код ошибки. Поскольку это происходит без какой-либо задержки, число поступающих запросов возрастает линейно при росте числа EB.
Google AE/C (рис. 10): Подобно SimpleDB, Google AE (с кэшированием и без кэширования) в ситуации перегрузки прекращает обрабатывать запросы. На рис. 10 этому эффекту сответствует линейный рост числа поступающих запросов. В отличие от SimpleDB, Google AE поступает "по справедливости" и отказывается обрабатывать запросы всех категорий. Другими словами, в ситуации перегрузки система перестает обрабатывать и запросы на чтение, и запросы на запись. В экспериментах с горизонтальным масштабированием служба Google AppEngine показала наихудшую производительность по сравнению со всеми другими вариантами. Это явление можно объяснить тем, что Google фокусируется на поддержке минимальных рабочих нагрузок за минимально возможную цену (см. следующий подраздел).
Табл. 3. Cost/WIPS (в долларах), изменяется число EB

Экспериментальная среда
В этом разделе описываются тестовый набор и экспериментальная среда, которая использовалась для выполнения экспериментов. Результаты экспериментов представлены в следующем разделе.
Эксперименты и результаты
В этом разделе представлены результаты производительности (WIPS) и стоимости ($) прогона тестового набора TPC-W с использованием восьми вариантов "облачных" служб, описанных в разд. 4. Кроме того, в этом разделе показаны время и стоимость массовой загрузки тестовой базы данных для каждого варианта.
Табл. 2. Пропускная способность, Cost/WIPS, предсказуемость стоимости

Кэширование
На рис. 5 показано, как можно интегрировать кэширование на уровне сервера баз данных. Кэширование может объединяться с другими архитектурами (разделением, репликацией и распределенным управлением). И снова принцип прост: результаты запросов к базе данных сохраняются специальными серверами кэширования. Обычно эти серверы сохраняют результаты запросов в своей основной памяти (main memory), так что доступ к кэшу оказывается настолько быстрым, насколько это возможно. Соответственно, набор кэширующих серверов обычно называется MemCache. Наиболее широко используемым программным обеспечением (с открытыми исходными текстами), поддерживающим такие распределенные кэши в основной памяти, является Memcached [9].
Как и в случае с репликацией, имеется много разных схем поддержки согласованности кэша при изменениях базы данных. На рис. 5 представлен подход, в котором согласованность кэша контролируется приложением. Этот подход используется в AppEngine компании Google, которая является единственным известным нам поставщиком "облачных" услуг, использующим "ферму" выделенных MemCache-серверов. К сожалению, Google не публикует какие-либо подробности о реализации MemCache.
Кэширование также может помочь в реализации потенциала cloud computing в отношении стоимости и масштабируемости. Для кэширования можно использовать дешевые машины. Кроме того, число кэширующих машин может тривиальным образом увеличиваться и уменьшаться в любой момент времени.
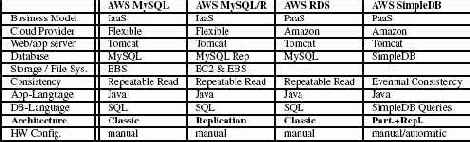
Табл. 1. Общие сведения об "облачных" службах


Классика
На рис. 1 показана классическая архитектура, используемая в большинстве сегодняшних приложений баз данных (например, в SAP R/3 [5]). Запросы от клиентов направляются балансировщиком нагрузки (изображенным на рис. 1 в виде карусели) в одну из доступных машин, на которой выполняются Web-сервер и сервер приложений. Web-сервер обрабатывает (HTTP-) запросы, поступающие от клиентов, а сервер приложений выполняет указанную логику приложения с использованием, например, языков Java или C# со встроенным SQL (или LINQ, или какого-либо другого языка программирования баз данных). Операторы встроенного SQL доставляются на сервер баз данных, который интерпретирует запрос, возвращает результат и, возможно, изменяет базу данных. Для обеспечения персистентности сервер баз данных сохраняет все данные и журналы на устройствах хранения данных. Интерфейс между сервером баз данных и системой хранения данных предполагает пересылку физических блоков данных (например, блоков размером в 64 килобайта) с использованием запросов get и put. В традиционных системах хранения данных используются диски, подключаемые локально к машине, на которой работает сервер баз данных, или объединяемые в сеть устройства хранения данных (storage area network, SAN). На рис. 1 демонстрируется вариант архитектуры, в котором система хранения данных отделена от сервера баз данных (т.е. SAN). Вместо традиционных вращающихся дисков в системах хранения данных следующего поколения, возможно, будут использоваться твердотельные диски (solid-state disk), основная память или комбинация разных носителей.
Классическая архитектура обеспечивает ряд важных преимуществ. Во-первых, она позволяет использовать на всех уровнях компоненты, являющиеся "лучшими в своем классе" "best-of-breed"). В результате в расчете на каждый из этих уровней образовался жизнеспособный рынок конкурирующих продуктов. Во-вторых, классическая архитектура позволяет добиться масштабируемости и эластичности на уровнях хранения данных и серверов Web и приложений.
Например, если требуется скорректировать пропускную способность приложения в соответствии с увеличившейся активностью пользователей, то можно легко увеличить число машин на уровне серверов Web и приложений, чтобы справиться с повысившейся рабочей нагрузкой. Аналогичным образом, при снижении рабочей нагрузки некоторые машины на этом уровне можно отключить или использовать для других целей. На уровне хранения данных можно увеличивать или уменьшать число машин (или дисков) для повышения пропускной способности системы хранения при возрастании рабочей нагрузки и/или для решения проблем, связанных с изменением размеров базы данных.
Потенциальным узким местом классической архитектуры является сервер баз данных. Если сервер баз данных становится перегруженным, единственным выходом из положения является покупка более мощной машины. Машины, используемые для поддержки серверов баз данных, обычно стоят недешево, поскольку они должны уметь справляться с пиковой рабочей нагрузкой. Поэтому классической архитектуре с рис. 1 свойственны ограничения по отношению и к масштабируемости, и к стоимости – двум важным целям "облачных" вычислений. В следующих подразделах этого раздела рассматриваются архитектуры, выбираемыми разработчиками "облачных" служб для преодоления этих ограничений на уровне сервера баз данных.

Рис. 2. Разделение
Литература
[1] Amazon. Amazon WebServices, October 2009.
[2] C. Binnig, D. Kossmann, T. Kraska, and S. Loesing. How is the Weather Tomorrow? Towards a Benchmark for the Cloud. In Proc. of DBTest, pages 1–6, 2009.
[3] M. Brantner, D. Florescu, D. A. Graf, D. Kossmann, and T. Kraska. Building a Database on S3. In Proc. of SIGMOD, pages 251–264, 2008.
[4] E. A. Brewer. (Invited Talk) Towards Robust Distributed Systems. In Proc. of PODC, page 7, 2000.
[5] R. Buck-Emden. The SAP R/3 System. Addison-Wesley, 2nd edition, 1999.
[6] M. J. Carey, D. J. DeWitt, and J. F. Naughton. The 007 Benchmark. In Proc. of SIGMOD, pages 12–21, 1993.
[7] M. J. Carey, D. J. DeWitt, J. F. Naughton, M. Asgarian, P. Brown, J. Gehrke, and D. Shah. The BUCKY Object-Relational Benchmark (Experience Paper). In Proc. of SIGMOD, pages 135–146, 1997.
[8] S. Ceri and G. Pelagatti. Distributed databases principles and systems. McGraw-Hill, Inc., 1984.
[9] Danga. MemCached, October 2009.
[10] D. J. DeWitt. The Wisconsin Benchmark: Past, Present, and Future. In J. Gray, editor, The Benchmark Handbook for Database and Transaction Systems , 2nd edition. Morgan Kaufmann, 1993.
[11] D. J. DeWitt, P. Futtersack, D. Maier, and F. Velez. A Study of Three Alternative Workstation-Server Architectures for Object Oriented Database Systems. In Proc. of VLDB, pages 107–121, 1990.
[12] D. Florescu and D. Kossmann. . SIGMOD Rec., 38(1):43–48, 2009. Rethinking Cost and Performance of Database Systems
Имеется перевод на русский язык: Даниела Флореску, Дональд Коссман. Переосмысление стоимости и производительности систем баз данных, 2009.
[13] J. Furman, J. Karlsson, J. Leon, A. Lloyd, S. Newman, and P. Zeyliger. Megastore: A Scalable Data System for User Facing Applications. In Proc. of SIGMOD, 2008.
[14] Gartner. Gartner Top Ten Disruptive Technologies for 2008 to 2012. Emerging Trends and Technologies Roadshow, 2008.
[15] T. Kraska, M. Hentschel, G. Alonso, and D. Kossmann. Consistency Rationing in the Cloud: Pay Only when it Matters.
In Proc. of VLDB, volume 2, pages 253–264, 2009.
Имеется перевод на русский язык: Тим Краска, Мартин Хеншель, Густаво Алонсо, Дональд Коссман . Рационализация согласованности в "облаках": не платите за то, что вам не требуется, 2010.
[16] U. F. Minhas, J. Yadav, A. Aboulnaga, and K. Salem. Database Systems on Virtual Machines: How Much Do You Lose? In ICDE Workshops, pages 35–41, 2008.
[17] MySQL-AB. Benchmarking Highly Scalable MySQL Clusters, October 2009.
[18] Oracle. Oracle Real Application Clusters, October 2009.
[19] A. Pavlo, E. Paulson, A. Rasin, D. J. Abadi, D. J. DeWitt, S. Madden, and M. Stonebraker. A Comparison of Approaches to Large-Scale Data Analysis. In Proc. of SIGMOD, pages 165–178, 2009.
Имеется перевод на русский язык: Эндрю Павло, Эрик Паулсон, Александр Разин, Дэниэль Абади, Дэвид Девитт, Сэмюэль Мэдден, Майкл Стоунбрейкер. Сравнение подходов к крупномасштабному анализу данных, 2009.
[20] C. Plattner and G. Alonso. Ganymed: Scalable Replication for Transactional Web Applications. In Proc. of Middleware, pages 155–174, 2004.
[21] A. Schmidt, F. Waas, M. L. Kersten, M. J. Carey, I. Manolescu, and R. Busse. XMark: A Benchmark for XML Data Management. In Proc. of VLDB, pages 974–985, 2002.
[22] S. Sengupta. SQL Data Services: A Lap Around. In Microsoft Professional Developers Conference (PDC), 2008.
[23] W. Sobel, S. Subramanyam, A. Sucharitakul, J. Nguyen, H. Wong, A. Klepchukov, S. Patil, A. Fox, and D. Patterson. Cloudstone: Multi-Platform, Multi-Language Benchmark and Measurement Tools for Web 2.0. In Proc. of CAA, 2008.
[24] M. Stonebraker. The Case for Shared Nothing. IEEE Database Eng. Bull., 9(1):4–9, 1986.
[25] M. Stonebraker, J. Frew, K. Gardels, and J. Meredith. The Sequoia 2000 Benchmark. In Proc. of SIGMOD, pages 2–11, 1993.
[26] M. Stonebraker and J. M. Hellerstein, editors. Readings in Database Systems. Morgan Kaufmann, 4th edition, 2005.
[27] A. Tanenbaum and M. van Steen. Distributed Systems: Principles and Paradigms.Prentice Hall, 2002.
[28] TPC. TPC-W 1.8. TPC Council, 2002.
[29] W. Vogels. Eventually Consistent. Commun. ACM, 52(1):40–44, 2009.
Массовая загрузка
Для полноты в табл. 6 для всех альтернативных вариантов показано время и стоимость массовой загрузки, а также размер базы данных и месячная стоимость ее хранения. Как и раньше, выигрышные результаты выделены полужирным шрифтом и курсивом. Во всех случаях для массовой загрузки базы данных использовались наилучшие доступные средства. В случае MySQL данные заносились через JDBC-подключение. В случае SimpleDB мы использовали операцию пакетной вставки (batch-put), которая сохраняет сразу 25 записей. Для S3 отсутствует какая-либо особая поддержка массовой загрузки, так что данные загружались с использованием стандартного протокола, описанного в [3]. В случае Google AE для применения средства Google для пакетного импорта данных мы использовали скрипт на языке Python. В случае Azure использовался SQL Azure Migration Wizard. В целом, в этой категории явным образом победила система MySQL. Для MySQL/R стоимость и время загрузки в точности в три раза превышали эти показатели для MySQL, поскольку для MySQL/R мы использовали коэффициент репликации, равный трем.
Если говорить о размере базы данных и стоимости месячного хранения (два последних столбца табл. 6), то, как видно, победила служба Azure. Однако в целом стоимость хранения данных является незначительной и не является важным фактором общей стоимости (подраздел 6.3). Следует заметить, что для всех вариантов, кроме MySQL, стоимость месячного хранения возрастает линейно при росте размера базы данных. В варианте MySQL для хранения баз данных используется EBS (п. 4.1.1), а функция стоимости EBS является более сложной. Для EBS разумно обеспечивать избыточные ресурсы, поскольку если устройство ESB становится полностью заполненным, то необходимо обеспечить новое устройство ESB большей емкости, и данные должны копироваться со старого устройства ESB на новое устройство. Очевидно, что копирование данных – это очень дорогостоящая процедура, так что во избежание подобных случаев лучше сразу позаботиться о резерве внешней памяти.
Методология, показатели и реализация
Целью этой оценки производительности являлось изучение масштабируемости (с учетом пропускной способности) и стоимости альтернативных "облачных" служб при наличии различных рабочих нагрузок. Для этого мы реализовали и пропустили тестовый набор TPC-W с использованием этих альтернативных служб (описанных в разд. 4), а также измерили WIPS и стоимость при изменении числа EB (числа имитируемых параллельно работающих пользователей). Как отмечалось в предыдущем подразделе, мы изменяли нагрузку от одного EB (слабая рабочая нагрузка) до 9000 EB (тяжелая рабочая нагрузка). Мы не оценивали другие обещанные возможности "облачных" вычислений, такие как доступность, время выхода на рынок и гибкость, потому что эти показатели трудно измерить. Таким образом, измерялись следующие показатели:
WIPS(EB): Пропускная способность допустимых запросов в одну секунду в зависимости от числа эмулируемых браузеров (EB). Чем выше, тем лучше. (Как объяснялось в предыдущем подразделе, "допустимым запросом" считается запрос, время выполнения которого соответствует установленным требованиям.)
Cost/WIPS(EB): Стоимость в соответствии с пропускной способность снова в зависимости от числа EB. Чем меньше, тем лучше.
CostPerDay/WIPS(EB): (Прогнозируемая) общая стоимость выполнения тестового набора с некоторым числом EB в течение 24 часов. Чем меньше, тем лучше.
s(Cost/WIPS): Среднеквадратичное отклонение Cost/WIPS для разных значений числа EB (от EB=1 до EB=max, где max – это число EB, при котором была бы достигнута наивысшая пропускная способность). Этот показатель является мерой предсказуемости стоимости службы. В идеале показатель Cost/WIPS не должен зависеть от нагрузки и потому должен являться предсказуемым. Так что, чем меньше значение s, тем лучше.
Кроме этих показателей, мы измеряли время и стоимость массовой загрузки тестовой базы данных, а также ее размер и стоимость месячного хранения.
В зависимости от используемого варианта службы мы применяли одну из двух экспериментальных установок для определения стоимости и WIPS при заданном числе EB.
Для вариантов SimpleDB, S3 и Google AppEngine (с кэшированием и без кэширования) мы измеряли WIPS для ряда значений числа EB (EB=1, 250, 500, 1000, 2000, 3000, 4000 и 9000, если это оказывалось возможным) в течение 10 минут. Для этих вариантов мы не могли выполнить измерения для всего спектра значений числа EB из-за ограниченного бюджета. Для трех вариантов, основанных на MySQL (MySQL, MySQL/R и RDS), и варианта Azure мы проводили измерения для всех значений числа EB в диапазоне от EB=1 до EB=9000. Для этого мы начинали работу при EB=1 и затем увеличивали рабочую нагрузку, добавляя по одному EB через каждые 0,4 секунды. Во всех случаях перед каждым экспериментальным прогоном тестового набора мы выполняли "разогревающий" (warm-up) двухминутный прогон; стоимость и пропускная способность этой двухминутной разогревающей фазы не учитываются в результатах, представленных в этой статье.
Для обеспечения стабильности результатов мы выполняли ряд дополнительных экспериментов и измерений. Для MySQL,MySQL/R, RDS и Azure все эксперименты повторялись по семь раз, и в результаты включались средние значения WIPS и стоимости, полученные при каждых семи прогонах. Из-за бюджетных ограничений для вариантов SimpleDB, S3, Google AE (с кэшированием и без кэшироввания) все эксперименты повторялись только по три раза. Кроме того, мы прогоняли несколько частных вариантов тестового набора (при фиксированном числе EB) в течение более долгого времени (до тридцати минут), чтобы оценить, смогут ли службы настроить свою конфигурацию к имеющейся рабочей нагрузке. Однако нам не удалось выявить таких эффектов. Только при использовании Microsoft Azure мы наблюдали небольшую разрывность. В наших первых экспериментах служба Azure быстро становилась недоступной при EB=2000 и EB=5500. Мы полагаем, что в эти моменты времени службы Azure перемещали базу данных TPC-W на более крупные машины, чтобы можно было справиться с возрастающей рабочей нагрузкой. Этот эффект наблюдался только при выполнении самого первого эксперимента с использованием Azure.
Как кажется, Azure при уменьшении рабочей нагрузки не возвращает базу данных на менее мощные машины, так что все последующие эксперименты с использованием Azure (предположительно) выполнялись на крупной машине баз данных. Однако в целом все результаты были на удивление стабильными, и мы получили только один резко выделяющийся частный результат в одном из экспериментов с MySQL. Хорошо известно, что качество услуг, обеспечиваемое поставщиками "облачных" служб, является изменчивым, но долговременное детальное изучение этих отклонений не являлось целью описываемой работы.
Эксперименты с использованием AWS RDS и Microsoft Azure выполнялись в феврале 2010 г. Эксперименты с использованием других вариантов "облачных" служб выполнялись в октябре 2009 г. (В октябре 2009 г. Azure и RDS еще не были широко доступны.) Очевидно, что все поставщики "облачных" служб внесут в них изменения, которые повлияют на полученные нами результаты, точно так же, как развитие аппаратуры и технологии влияет на результаты любых исследований производительности. Тем не менее, мы полагаем, что результаты этого исследования позволяют лучше понять основные свойства альтернативных архитектур платформ "облачных" вычислений (разд. 3).
Во всех экспериментах эмулируемые браузеры тестового набора TPC-W выполнялись на машинах EC2 в облачной среде Amazon. Поэтому в экспериментах с использованием Google AppEngine и Azure клиентские машины находились не в тех центрах данных, в которых располагались серверные машины, обрабатывающие запросы. Чтобы не допустить несправедливости мы обеспечили, чтобы для всех вариантов с использованием служб Amazon клиентские машины EC2 и серверные машины EC2 тоже располагались в разных центрах данных. Это делалось путем явного выбора центра данных при запуске виртуальных машин (instance) EC2 для клиентов и серверов.
Для выполнения серверов Web и приложений в "облачной" среде Amazon мы использовали средние (medium) машины EC2 HIGH-CPU.
Соответственно, мы использовали для тех же целей средние машины и в "облачной" среде Azure. Средние машины EC2 и Azure обладают примерно одинаковой производительностью и стоимостью, так что результаты являются прямо сопоставимыми. Кроме того, в "облачных" средах Amazon и Azure мы вручную подбирали число машин для выполнения серверов Web и приложений. С помощью отдельных экспериментов (не описываемых в данной статье) мы обнаружили, что один средний сервер может справиться с нагрузкой 1500 EB. Соответственно, мы обеспечивали один сервер Web и приложений на каждые 1500 EB, увеличивая число машин до шести для поддержки максимальной рабочей нагрузки 9000 EB. В варианте S3 интегрированный сервер Web, приложений и баз данных справлялся только с 900 EB, так что для поддержки этого варианта использовалось до десяти машин EC2. Мы заранее выделяли машины EC2 и Azure, чтобы обеспечить их доступность в случае потребности (при возрастании нагрузки). В экспериментах с использованием Google AppEngine у нас отсутствовала возможность влияния на выбор вида и числа машин, использовавшихся на уровне серверов Web и приложений, поскольку серверы автоматически обеспечивались Google AppEngine (табл. 1).
Для выполнения серверов баз данных в вариантах AWS MySQL и AWS MySQL/R мы также использовали средние машины EC2. В случаях, когда не оговаривается противное, в варианте AWS RDS мы использовали крупную (large) машину, поскольку характеристики производительности крупной машины RDS схожи с характеристиками средней машины EC2. Во всех вариантах машины баз данных было невозможно конфигурировать.
Как отмечалось в разд. 2, мы не выполняли какие-либо "пиковые" эксперименты, предлагавшиеся в [2]. Целью "пиковых" экспериментов является оценка того, насколько быстро поставщик служб адаптируется к быстрым изменениям в рабочей нагрузке. Как отмечалось выше, мы не смогли заметить каких-либо существенных настроек, выполняемых службами самостоятельно (с примечательным исключением при первом экспериментальном прогоне тестового набора в среде Azure), и поэтому мы полагаем, что наши результаты представляют стационарное поведение систем.Однако более детальный анализ "пиковой" производительности и адаптируемости является важной темой будущих исследований.
Во всех экспериментах изображения, используемые в составе тестового набора TPC-W (например, фотографии продуктов) хранились вне базы данных в отдельной файловой системе. В "облачной" среде Amazon для экономии все изображения сохранялись в локальной файловой системе EC2. В среде Azure изображения сохранялись в составе Web-проекта.
Microsoft
Компания Microsoft недавно выпустила Azure – набор "облачных" служб, основанных на Windows, SQL Server и .Net. Для выполнения экспериентов с Azure мы реализовали тестовый набор TPC-W на языке C# со встраиваемым SQL. Теоретически в "облачной" среде Azure можно было бы использовать и другие технологии, например, Java, но ко времени выполнения наших экспериментов были недоступны требуемые для этого библиотеки доступа к службам баз данных и другим службам Azure. Подобно Amazon и Google, Microsoft пока еще не опубликовала все подробности реализации Azure. Как утверждается в [22], в Azure используется архитектура репликации (с использованием мастер-сервера и серверов-сателлитов), показанная на рис. 3. Поэтому Azure следует напрямую сравнивать с вариантом AWS MySQL/R.
Все три поставщика "облачных" служб берут плату за хранение данных, сетевой трафик и ресурсы процессоров. Для некоторых категорий ресурсов они устанавливают близкие расценки (например, для ресурсов процессоров). Однако имеются и трудно уловимые различия. Например, Azure отличается от Amazon и Google принципом оплаты использования службы баз данных SQL Azure. Вместо того, чтобы брать плату по мере использования этой службы, с пользователей взимается помесячная абонетская плата, размер которой зависит от объема базы данных при отсутствии ограничений на число подключений.
Облачные службы
В этом разделе описываются альтернативные службы, предлагаемые тремя крупными игроками в области "облачных" вычислений – компаниями Amazon (AWS, Amazon Web Services), Google и Microsoft. Поскольку какие-либо стандарты пока еще отсутствуют, эти службы различаются во многих аспектах: бизнес-моделями, программными компонентами, используемыми на всех уровнях, и моделями программирования. Сводка различий и ключевых характеристик приведена в табл. 1. Для экспериментов, описываемых в разд. 6, наиболее уместна строка Архитектура (Architecture), и поэтому эта строка в табл. 1 выделена. Другой важной категорией является Конфигурация аппаратных средств (HW configuration). Для использования нескольких служб требуется указание нужного числа виртуальных машин, а также того, какие виды серверов должны быть установлены на этих машинах. Только в Google AppEngine аппаратные ресурсы на всех уровнях выделяются автоматически в зависимости от рабочей нагрузки. В SimpleDB и Azure ресурсы автоматически предоставляются и настраиваются на уровнях "сервера баз данных" и "системы хранения", но на уровне серверов Web и приложений требуется ручное конфигурирование аппаратных ресурсов. Компания Amazon обеспечивает службу AutoScaling, которую можно использовать для автоматического увеличения и уменьшения числа машин EC2 на уровне серверов Web и приложений. Однако мы не использовали эту службу при проведении экспериментов, чтобы иметь возможность управлять ими и сосредоточиться на масштабируемости на уровне баз данных.
Общая картина
В табл. 2 кратко излагаются общие результаты этого исследования. Более развернутый анализ приводится в последующих подразделах. В первом столбце приводятся данные о наивысшей пропускной способности (WIPS), которой удалось достичь в каждом варианте. Во втором и третьем столбцах перечисляются значения показателя Cost/WIPS для слабых рабочих нагрузок (EB=1, второй столбец) и для высоких рабочих нагрузок (EB=max, третий столбец). В четвертом столбце приводится среднее значение и отклонение стоимости для всего диапазона рабочих нагрузок, от EB=1 до EB=max. Здесь под EB=max понимается максимальное число EB, с которым сумел справиться данный вариант "облачной" службы, т.е. число EB, при котором была достигнута максимальная пропускная способность. Во всех столбцах наивысшие значения показателей выделены полужирным шрифтом и курсивом.
Если взглянуть на первый столбец (пропускная способность), то становится ясно, что только S3 и Azure смогли справиться с высокой рабочей нагрузкой в 9000 EB. Для всех других вариантов при росте числа EB узким местом становится сервер баз данных. Мы полагаем, что вариант S3 с архитектурой распределенного управления способен масштабироваться за пределами 9000 EB. Это единственная архитектура без потенциальных узких мест. Поскольку служба Azure основана на архитектуре репликации (подраздел 3.3), она исчерпывает свои возможности масштабирования, когда мастер-сервер баз данных становится перегруженным. Однако, как кажется, Microsoft использует для поддержки уровня баз данных SQL Azure высокопроизводительные машины, так что при наличии 9000 EB предел возможностей этой службы достигнут не был.
Если обратиться к результатам "Cost/WIPS", то можно заметить, что для всех служб, кроме Google AE, меньшее значение этого показателя достигается при высоких рабочих нагрузках. В идеале "Cost/WIPS" должно было бы быть константой, не зависящей от рабочей нагрузки. Если для некоторой службы значение "Cost/WIPS" оказывается более высоким при низкой рабочей нагрузке, чем при высокой рабочей нагрузке, то это означает, что с этой службой связаны фиксированные расходы, которые требуется оплачивать независимо от уровня использования службы.
Например, во всех вариантах Amazon требуется платить хотя бы за одну виртуальную машину EC2, чтобы иметь возможность отвечать на запросы клиентов, даже если нет вообще никакой нагрузки. Кроме того, в некоторых вариантах Amazon приходится платить за машины на уровне базы данных. Подобно этому, чтобы поддерживать Web-приложение в режиме онлайн, в варианте Azure приходится помесячно платить за SQL Azure и, по крайней мере, за одну машину с сервером Web и приложений. Единственный вариант, в котором отсутствуют какие-либо фиксированные расходы и не приходится ничего платить в отсутствие какой-либо нагрузки, обеспечивает Google AppEngine. Очевидно, что такие фиксированные расходы не вяжутся с парадигмой платы по мере использования, приверженность которой обещалась в области cloud computing.
Четвертый столбец табл. 2 показывает среднее значение и среднее квадратичное отклонение показателя Cost/WIPS на всем диапазоне значений числа EB, с которым смогла справиться соответствующая служба. У всех служб, кроме Google, имеется высокое отклонение, означающее, что стоимость службы сильно зависит от нагрузки и потому становится непредсказуемой (если только нагрузка системы не является постоянной).

Рис. 7. Сравнение архитектур
От переводчика
Меня продолжают интересовать различные аспекты управления данными в новых условиях неограниченного горизонтального масштабирования аппаратных средств. В настоящее время эта область достаточно строго распадается на два направления: управление аналитическими данными и управление транзакционными данными. Наиболее интересным работам первого направления посвящены следующие статьи:
Эндрю Павло, Эрик Паулсон, Александр Разин, Дэниэль Абади, Дэвид Девитт, Сэмюэль Мэдден, Майкл Стоунбрейкер.
Майкл Стоунбрейкер, Дэниэль Абади, Дэвит Девитт, Сэм Мэдден, Эрик Паулсон, Эндрю Павло и Александр Разин.
Джеффри Коэн, Брайен Долэн, Марк Данлэп, Джозеф Хеллерстейн, Кейлэб Велтон.
Эрик Фридман, Питер Павловски и Джон Кислевич.
Азза Абузейд, Камил Байда-Павликовски, Дэниэль Абади, Ави Зильбершац, Александр Разин. .
Ю Ксу, Пекка Костамаа, Лайк Гао. .
Возможно, заслуживает внимания и моя обзорная статья
Не менее интересно, хотя и совсем по-другому, развивается и второе направление. Здесь имеется некоторое противостояние между лагерем, опирающимся на теорему CAP (по этому поводу очень советую почитать замечательную заметку Стоунбрейкера Ошибки в системах баз данных, согласованность "в конечном счете" и теорема CAP) и, следуя этой теореме, отказывающихся от обеспечение свойств ACID в своих транзакциях, и группой, возлавляемой тем же Стоунбрейкером, которые стремятся к новому поколению транзакционных средств управления данными, в которых свойства ACID продолжают поддерживаться. Этой тематике тоже посвящен ряд интересных статей:
Даниела Флореску, Дональд Коссман. ;
Тим Краска, Мартин Хеншель, Густаво Алонсо, Дональд Коссман. ;
Пэт Хелланд, Дейв Кэмпбел. .
Майкл Стоунбрейкер, Сэмюэль Мэдден, Дэниэль Абади, Ставрос Харизопулос, Набил Хачем, Пат Хеллэнд. .
Ставрос Харизопулос, Дэниэль Абади, Сэмюэль Мэдден, Майкл Стоунбрейкер. .
Эван Джонс, Дэниэль Абади и Сэмуэль Мэдден. .
Сравнению этих подходов следовало бы посвятить отдельную статью, но пока ее нет, а в вводной заметке к переводу такое сравнение выполнить невозможно. Поэтому пока я просто продолжаю собирать интересные статьи про новые транзакционные системы управления данными и предлагаю вашему вниманию статью Дональда Коссмана и его коллег, в которой на основе тестового набора TPC-W сравниваются характеристики производительности и стоимости "облачных" систем управления данными от разных компаний и с разной архитекурой. Я считаю эту статью полезной и познавательной.
Сергей Кузнецов
Распределенное управление
На рис. 4 изображена архитектура, моделирующая систему баз данных как распределенную систему. На первый взгляд, эта архитектура кажется похожей на архитектуры с разделением и репликацией, показанные на рис. 2 и 3. Отличия едва уловимы, но они оказывают колоссальное влияние на реализацию, производительность и стоимость системы. Архитектуру с распределенным управлением можно также охарактеризовать, как архитектуру с общими дисками (shared-disk architecture) [24] с поддержкой слабых связей между узлами для достижения масштабируемости.
В этой архитектуре система хранения данных отделяется от серверов баз данных, и серверы баз данных параллельно и автономно обращаются к совместно используемым данным, содержащимся в системе хранения. Чтобы синхронизовать доступ по чтению и записи к общим данным, могут применяться распределенные протоколы, обеспечивающие разные уровни согласованности. Как и случаях, рассмотренных в предыдущих подразделах, здесь потенциально применимы самые разнообразные протоколы. Обзор таких протоколов и уровней согласованности приведен в классическом учебнике [27]. Для сокращения накладных расходов уровень управления базами данных сливается с уровнем серверов Web и приложений; другими словами, доступ к базе данных обеспечивается некоторой библиотекой в составе сервера приложений, а не отдельными процессами сервера баз данных.
Потенциально эта архитектура лучше всего подходит для cloud computing. Она обеспечивает полную масштабируемость и эластичность на всех уровнях. Каждый HTTP-запрос может направляться любому серверу (связке "Web-сервер/сервер приложений/сервер баз данных"), так что на этом уровне можно достичь полной масштабируемости. Кроме того, на уровне хранения данные могут любым образом реплицироваться и разделяться, так что масштабируемости можно достичь и на этом уровне. Еще одной особенностью этой архитектуры является то, что на всех уровнях можно использовать дешевую аппаратуру. Однако за эту масштабируемость приходится платить. В соответствии с теоремой CAP [4], невозможно одновременно обеспечить согласованность, доступность и устойчивость к разделению сети. В исследованном нами варианте этой архитектуры (Amazon S3, разд. 4) согласованность принесена в жертву, и обеспечивается только уровень согласованности, называемый согласованностью в конечном счете (eventual consistency) [29]. В терминах баз данных поддержка согласованности в конечном счете обеспечивает долговечность (durability) и, при небольших изменениях, атомарность (atomicy) распределенных транзакций баз данных, но не согласуется с требованием их изоляции (isolation) (т.е. требованием сериализуемости).

Рис. 5. Кэширование
Разделение
На рис. 2 показано, как можно приспособить классическую архитектуру систем баз данных к использованию разделения данных. Идея проста: вместо того чтобы нагрузить один сервер баз данных управлением всей базой данных целиком, мы логически разделяем эту базу данных и обязываем управлять каждым разделом отдельный сервер баз данных. В литературе баз данных исследовалось много схем разделения; например, вертикальное и горизонтальное разделение, циклическое разделение (round-robin partitioning), разделение с хэшированием (hashing partitioning), разделение по диапазону значений (range partitioning) [8]. Все эти подходы работоспособны и могут быть применены к управлению данными "в облаках".
Варианты архитектуры, представленной на рис. 2, могут различаться не только схемами разделения. Во-первых, разделение может быть прозрачным или видимым для программиста приложений (очевидно, что предпочтительным является прозрачное разделение). Во-вторых, устройства хранения данных могут подключаться к машине, на которой работает сервер баз данных, или быть от нее отделены, например, в сеть устройств хранения данных (как показано на рис. 1). На рис. 2 представлен вариант, в котором доступ к распределенной базе данных является прозрачным, и устройства хранения данных подключаются к каждому серверу баз данных. На практике можно обнаружить использование и других вариантов (разд. 4).
По отношению к cloud computing архитектура с рис. 2 была впервые применена в Force.com – платформе, на которой выполнялось приложение Salesforce, и которая была открыта для выполнения заказных приложений. В Force.com ключом разделения является арендатор (tenant). Другими словами, данные распределяются в зависимости от приложения, которое генерирует эти данные и владеет ими. Разделение охватывает весь серверный стек приложений, включая Web-сервер и сервер приложений. Все запросы, направляемые к одному арендатору, обрабатываются одними и теми же Web-сервером, сервером приложений и сервером баз данных.
В результате Force. com настраивается при увеличении числа приложений. Однако архитектура Force.com не поддерживает масштабируемость одного приложения сверх возможностей одного сервера баз данных. Поэтому мы не включили в свое исследование эксперименты с этой платформой. Мы полагаем, что Force.com продемонстрировала бы в наших экспериментах поведение, схожее с поведением вариантов, основанных на классической архитектуре.
Разделение данных и архитектура, представленная на рис. 2, обеспечивают эффективный путь к раскрытию потенциала cloud computing. Серверы баз данных могут функционировать на дешевых машинах, что приводит к использованию большого числа машин, каждая из которых работает с данными довольно небольшого объема, чтобы иметь возможность выдержать нагрузку. Однако у разделения имеются ограничения масштабируемости при наличии колеблющейся рабочей нагрузки: при увеличении или уменьшении числа машин в качестве реакции на возрастание (или снижение) интенсивности рабочей нагрузки запросов/операций обновления требуется перераспределение данных, т.е. пересылка данных между машинами. Чтобы добиться улучшенной масштабируемости и отказоустойчивости, требуется объеденить разделение с репликацией.
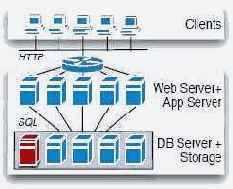
Рис. 3. Репликация
Репликация
На рис. 3 показано, каким образом в архитектуре систем баз данных может быть использована репликация. Опять же, эта идея проста и активно изучалась в прошлом. Как и в случае разделения, имеется несколько серверов баз данных. Каждый сервер баз данных управляет некоторой копией всей базы данных (или раздела базы данных, если репликация объединяется с разделением). При этом допустимо множество вариантов. На рис. 3 демонстрируется вариант, в котором репликация является прозрачной, и устройства хранения данных присоединены к серверам баз данных. Наиболее важным аспектом схемы репликации является механизм поддержания реплик в согласованном состоянии. Наиболее известен протокол ROWA (read-once, write all – чтение из любой реплики, запись во все реплики), основанный на поддержке эталонной копии (Master copy) [20]. Если репликация не является прозрачной, приложения направляют все запросы на обновление данных серверу баз данных, который управляет эталонной копией, а этот сервер (мастер-сервер, Master server) передает все обновления серверам-сателлитам после того, как эти обновления удается успешно зафиксировать. Приложения могут направлять запросы на чтение данных любому серверу баз данных (мастеру или сателлиту). Если репликация является прозрачной, то запросы автоматически направляются мастеру или сателлиту. На рис. 3 показана прозрачная репликация. Мастер сервер окрашен красным цветом (в левом нижнем углу рисунка).
Серверы баз данных могут работать на дешевом компьютерном оборудовании. В частности, серверы-сателлиты могут работать на дешевых стандартных машинах. Кроме того, архитектура с рис. 3 может хорошо масштабироваться при возрастании и сокращении рабочей нагрузки, если рабочая нагрузка в основном состоит из запросов на чтение данных. При сокращении рабочей нагрузки в любой момент времени любой сервер-сателлит может быть выведен из конфигурации системы. Если рабочая нагрузка возрастает, то при добавлении сервера-сателлита требуется скопировать в него базу данных с мастер-сервера (или какого-либо сервера-сателлита). Как показано в разд. 6, при наличии рабочих нагрузок с большим числом операций обновления мастер-сервер может стать узким местом системы.
Репликацию можно использовать для повышения уровня масштабируемости и надежности системы. Один из протоколов обеспечения надежности на основе репликации был разработан Oracle в составе продукта Oracle RAC [18].

Рис. 4. Распределенное управление
Родственные работы
В описываемом исследовании мы следуем многолетней традиции сообщества баз данных подвергать тестовым испытаниям новые виды систем управления базами данных по мере появления на рынке новых продуктов. Первой работой в этом направлении был знаменитый Висконскинский эталонный тестовый набор (Wisconsin benchmark [10]), который с течением времени привел к появлению серии тестовых наборов TPC, предназначенных для оценки производительности и стоимости систем баз данных для различных рабочих нагрузок; например, TPC-C и TPC-E для рабочих нагрузок OLTP, TPC-H для рабочих нагрузок OLAP, TPC-W и TPC-App – для всего стека Web-приложений. Кроме того, разработан ряд тестовых наборов для специализированных систем баз данных; например, OO7 для объектно-ориентированных систем баз данных [6], Bucky для объектно-реляционных систем баз данных [7], XMark XML-ориентированных систем баз данных [21] и Sequoia для научных систем баз данных [25]. Конечно, также проводились многочисленные исследования производственных показателей различных аспектов серверов приложений, систем баз данных, распределенных систем баз данных и отдельных компонентов инфраструктуры cloud computing (например, DHT – Distributed Hash Table). В одной из недавних статей [16] исследуется производительность реляционных систем баз данных, выполняемых на некоторой виртуальной машине. Безусловно, все эти результаты являются существенными. Однако целью нашего проекта была не оценка отдельных компонентов, а измерение сквозной (end-to-end) производительности альтернативных архитектур на всем стеке Web-приложений.
Несколько исследований посвящалось оценке производительности и масштабируемости инфраструктур "облачных" вычислений. В недавнем исследовании, выполнявшемся в сообществе баз данных, производительность Hadoop сравнивалась с производительностью более традиционных (основанных на SQL) систем баз данных [19]. Это исследование фокусировалось на крупномасштабных аналитических рабочих нагрузках с доступом к данным только по чтению, в то время как наше исследование концентрируется на рабочих нагрузках OLTP.
В [15] приводятся результаты родственного исследования соотношений "стоимость-согласованность" при выполнении рабочих нагрузок OLTP в "облачной" среде. Наиболее близкой нашему исследованию работой является проект Cloudstone из университета Беркли. В Cloudstone специфицируются база данных и рабочая нагрузка для изучения "облачных" инфраструктур [23], и определяются показатели производительности и стоимости, на основе которых сравниваются альтернативные системы. В своих экспериментах мы могли бы использовать рабочую нагрузку Cloudstone, но мы предпочли выбрать тестовый набор TPC-W по причине его популярности и широкого признания в сообществе баз данных. Описываемое исследование основывается на двух предыдущих статьях, в которых излагалась наша позиция. В [12] предлагалось в ходе экспериментов по изучению производительности обращать внимание не только на величины задержки и пропускной способности, но и на стоимость. В [2] описывалась серия экспериментов, направленных на оценку "облачных" инфраструктур. Данное исследование можно считать первым шагом к реализации программы, намеченной в [2]: мы выполнили эксперименты, предложенные в [2] для оценки "масштабируемости" и "стоимости". Эксперименты из [2] с "пиковой" рабочей нагрузкой и отказоустойчивостью остались на будущее. На нашу работу особенно повлияла классическая статья, посвященная клиент-серверным архитектурам баз данных [11].
Тестовый набор TPC-W
Поскольку нас интересовала сквозная производительность корпоративных Web-приложений, включающих обработку транзакций, мы использовали тестовый набор TPC-W [28]. В других тестовых наборах для OLTP (таких как TPC-C и TPC-E) упор делается на влиянии на общую производительности системы баз данных, и не имитируется какая-либо сложная логика приложения. Хотя организация TPC не рекомендует использовать TPC-W, этот тестовый набор остается популярым и в индустрии, и в академических организациях.
Тестовый набор TPC-W моделирует онлайновый книжный магазин с использованием смеси из пятнадцати видов запросов: поиск продуктов, выдача информации о продуктах, оформление заказа на покупку и т.д. Кроме того, в TPC-W специфицируются три вида рабочих нагрузок: (a) просмотр товаров (browsing), (b) подбор товаров (shopping), (c) оформление заказов (ordering). Для каждого вида рабочей нагрузки устанавливается вероятность появления в ней каждого вида запроса. Во всех экспериментах, описываемых в этой статье использовалась смесь "оформление заказов", поскольку в ней содержится больше всего запросов на обновление данных (примерно треть от общего числа запросов). Наконец, рабочий набор TPC-W позволяет изучать различные рабочие нагрузки с учетом темпа поступления запросов. Для этой цели в рабочем наборе TPC-W используются эмулируемые пользовательские браузеры (emulated browser, EB). Каждый EB имтирует действия одного пользователя, который выдает запрос (в соответствии с вероятностями, установленными для используемой смеси), ожидает ответа и по истечении специфицированного времени выдает следующий запрос. Мы изменяли параметр EB от 1 (≈ 500 запросов в час) до 9000 (≈ 1250 запросов в секунду). В смеси "оформление заказов" запросу уровня TPC-W соответствовало в среднем 6,6 HTTP-запросов, поскольку Web-страницы TPC-W содержат несколько встроенных компонентов (например, изображений).
В тестовом наборе TPC-W имеются два показателя. Первый показатель – это показатель пропускной способности, т.е.
число допустимых запросов TPC-W, поступающих за одну секунду. Для этого показателя обычно (и в данной статье) используется аббревиатура WIPS (от Web Interactions Per Second). Важно, что учитываются только допустимые запросы, время обработки которых соответствует установленным требованиям. В зависимости от вида запроса допустимое время ответа изменяется от 3 до 20 секунд. Результаты выполнения тестового набора принимаются во внимание, если 90% всех запросов каждой категории являются допустимыми, и система обеспечивает полный ответ на каждый из этих запросов в пределах допустимого времени. Нельзя, например, игнорировать все запросы на обновление данных и добиваться высокого значения WIPS за счет выполнения только запросов на чтение.
Вторым показателем, определяемым в TPC-W, является Cost/WIPS. Этот показатель связывает производительность (т.е. WIPS) с совокупной стоимостью владения (total cost of ownership) компьютерной системы. Чтобы обеспечить возможность измерения этого показателя, в тестовом наборе TPC-W приводятся точные правила вычисления стоимости системы. Для данного исследования эти правила пришлось ослабить, потому что они не применимы ни к каким исследуемым "облачным" службам. Во всех наших экспериментах стоимость определялась размером счета, который мы должны были оплатить.
Кроме упрощения правил вычисления показателя Cost/WIPS, мы ввели в тестовый набор TPC-W следующие изменения:
База данных тестового набора: В тестовом наборе TPC-W указывается, что размер тестовой базы данных возрастает линейно в зависимости от числа EB. Поскольку нас особо интересовали масштабируемость служб по отношению к транзакционной рабочей нагрузки и эластичность этих служб при изменении рабочей нагрузки, мы выполняли все свои эксперименты с использованием фиксированной тестовой базы данных, соответствующей стандартной базе данных TPC-W для 100 EB. Эта база данных содержала информацию о 10000 единицах товаров, и ее исходные данные составляли 315 мегабайт, что обычно приводило к размерам баз данных около 1 гигабайта при добавлении индексов (подраздел 6.5).
Вертикальное масштабирование (scale-up)
Одной из целей cloud computing является горизонтальное масштабирование (scale-out), т.е. обеспечение повышения пропускной способности за счет увеличения числа машин. Тем не менее, некоторые поставщики "облачных" служб поддерживают и возможности вертикального масштабирования (scale-up). Для классической архитектуры и архитектур с разделением и репликацией данных, описанных в разд. 3, такие возможности вертикального масштабирования являются важными, поскольку сервер баз данных может стать узким местом, и его вертикальное масштабирование является единственным путем к достижению высокой пропускной способности. Опция вертикального масштабирования обеспечивается в Amazon RDS. В табл. 5 показаны общие результаты в отношении пропускной способности, Cost/WIPS и предсказуемости стоимости. Можно видеть, что (как и следовало ожидать) более крупная машина способна выдержать более высокую рабочую нагрузку. Однако даже самая крупная машина RDS не способна справиться с рабочей нагрузкой в 9000 EB и обеспечить пропускную способность выше 1000 WIPS. Очевидно, что при вертикальном масштабировании повышается фиксированная часть стоимости системы (наблюдается высокое значение показателя Cost/WIPS при низких рабочих нагрузках) и, соответственно, снижается уровень предсказуемости стоимости (т.е. возрастает отклонение).
Табл. 6. Время и стоимость массовой загрузки; размер базы данных и стоимость хранения
вычислений пользуется чрезвычайно большой популярностью.
В последнее время понятие "облачных" вычислений пользуется чрезвычайно большой популярностью. Компания Gartner ставит cloud computing в верхние строчки списка наиболее прорывных технологий ближайших лет [14]. Все основные поставщики программного обеспечения и многие начинающие компании примкнули к движению "в облака" и утверждают, что их продукты уже готовы или готовятся к использованию в "облачной" инфраструктуре.
"Облачные" вычисления сулят обеспечить несколько новых возможностей. Они сулят сократить время выхода на рынок за счет устранения или упрощения процессов планирования, приобретения и подготовки к использованию аппаратных средств. Они сулят обеспечить разные способы сокращения расходов. Во-первых, за счет перехода к использованию бизнес-модели "платы по мере использования" можно превратить капитальные вложения в текущие расходы. Во-вторых, "облачная" инфраструктура может обеспечить более высокий (близкий к 100%) коэффициент загруженности аппаратных ресурсов. Поэтому cloud computing часто считают важной технологией для обеспечения экологически безопасного использования вычислительных средств (green computing). Кроме того, при использовании "облачных" вычислений сокращаются эксплуатационные расходы и трудозатраты за счет автоматизации таких IT-задач, как обновление системы безопасности (security patch) и переключение на резервные мощности при отказе оборудования (fail-over). Что касается производительности, то cloud computing обещает (практически) неограниченную масштабируемость, так что IT-администраторам не требуется беспокоиться о поддержке пиковой рабочей нагрузки. Наконец, "облачные" вычисления сулят гибкость при использовании программных и аппаратных средств и при управлении ими, что позволяет сократить время выхода на рынок и уменьшить расходы.
К настоящему времени выпущен ряд продуктов. В частности, свои продукты предлагают три крупнейших участника IT-индустрии – Amazon, Google и Microsoft.
Все эти продукты объединяет то, что они доступны широкой аудитории пользователей за счет оформления технологии cloud computing в виде сервисов, которые можно вызывать с любого персонального компьютера на основе интерфейса REST. Кроме того, все текущие предложения направлены на обеспечение всех основных преимуществ "облачных" вычислений, и они завоевывают все большее признание на IT-рынке.
Цель этой статьи состоит в том, чтобы заложить первую небольшую веху на пути к анализу упомянутых продуктов. С использованием базы данных и рабочей нагрузки тестового набора TPC-W мы произвели оценку предложений Amazon, Google и Microsoft и сравнили результаты этих экспериментов с результатами, полученными при прогоне тестового набора TPC-W на Java-сервере приложений с применением обычной системы реляционных баз данных. В частности, мы старались найти ответы на следующие вопросы:
Насколько хорошо оцениваемые продукты масштабируются при возрастании рабочей нагрузки? Действительно ли можно достичь (практически) неограниченной производительности?
Насколько дорогостоящими являются эти продукты, и как соотносятся коэффициенты их экономической эффективности (cost/performance ratio)?
Насколько предсказуемы расходы с учетом возможных изменений рабочей нагрузки?
Очевидно, что результаты, описываемые в этой статье, являются всего лишь мгновенным снимком текущего состояния дел. Основной вклад статьи состоит в формировании некоторого каркаса, который может позволить поставщикам улучшать свои службы, а пользователям – сравнивать продукты.
Как будет показано, наши эксперименты привели к ряду неожиданных результатов. Хотя многие службы со стороны выглядят очень похожими (например, матрицы цен Microsoft Azure и Amazon Web Services почти идентичны относительно пропускной способности сети, стоимости хранения данных и ресурса процессора), они очень различаются, когда речь идет о сквозной производительности (end-to-end performance), масштабируемости и стоимости использования. Может быть, еще более неожиданными оказались различия в архитектурах, поддерживающих управление крупномасштабными данными и транзакционные рабочие нагрузки в "облачной" инфраструктуре.
В то время как большинство (традиционных) систем баз данных общего назначения (например, DB2, MySQL, Oracle 11, Postgres, Microsoft SQL Server) основывается практически на одних и тех же "хрестоматийных" архитектуре и структурах данных (например, во всех них используются динамическое программирование, индексы на основе B-деревьев, упреждающая запись в журнал (write-ahead logging)) [26], различия в реализации "облачных" служб колоссальны. Хотя время хрестоматийной архитектуры "облачных" служб еще далеко не пришло, в этой статье мы пытаемся "заглянуть за кулисы", классифицировать варианты архитектуры и подготовить почву для сравнения различных вариантов архитектуры по отношению к производительности и стоимости.
Оставшаяся часть статьи структурирована следующим образом. В разд. 2 приводится обзор родственных работ. В разд. 3 описываются альтернативные архитектуры баз данных, предназначенные для обработки транзакций "в облаках". В разд. 4 кратко обсуждаются службы, используемые нами для экспериментов и представляющие различные архитектуры, которые описываются в разд. 3. В разд. 5 приводятся детальные данные о тестовом наборе и экспериментальной среде. В разд. 6 представлены результаты экспериментов. В разд. 7 содержатся заключительные замечания и планы будущих исследований.
В этой статье представлены результаты
В этой статье представлены результаты первого исследования сквозной производительности и стоимости выполнения транзакционных корпоративных Web-приложений с применением альтертнативных "облачных" служб. Поскольку этот рынок еще не является зрелым, показатели стоимости и производительности альтернативных служб значительно различаются. Большинству служб свойственны проблемы масштабируемости. В этой связи интересны наблюдения за поведением разных служб в ситуациях перегрузки. Что касается стоимости, стало ясно, что у разных поставщиков "облачных" служб имеются разные бизнес-модели, и что они ориентируются на разные виды приложений. Похоже, что компания Google в большей степени заинтересована в поддержке небольших приложений с низкими рабочими нагрузками, а Azure в настоящее время является наиболее подходящей службой для поддержки средних и крупных приложений. Публичные "облачные" среды часто критикуют за отсутствие поддержки загрузки данных крупного объема. Эта критика подтверждается нашими экспериментами. По-прежнему трудно загрузить терабайт или больший объем исходных данных на основе API, обеспечиваемых поставщиками служб.
Нам не удалось ответить на более фундаментальный вопрос о том, в чем состоит правильная архитектура управления данными в "облачной" среде. Неясно, являются ли полученные нами результаты проявлением текущего уровня зрелости исследованных служб, или же в них отражаются фундаментальные особенности использованных архитектур. Мы надеямся, что наше исследование приведет к постоянному отслеживанию развития альтернативных подходов и продуктов управлению данными в "облаках".
