Аналитические методы на основе матриц
В нашем случае основной интерес представляют крупные, плотно заполненные матрицы. Обычно мы имеем дело с матрицей расстояний D, где D(i,j) > 0 почти для всех (i,j). Также нас интересуют ковариационные матрицы Σ для сильно коррелирующих наборов данных.
Аннотация
Поскольку все проще и дешевле накапливать и сохранять огромные объемы данных, самые разнообразные предприятия нанимают статистиков для выполнения сложного анализа данных. В этой статье основное внимание уделяется новым приемам магнетичного, основательного, гибкого анализа данных ("МОГучего" анализа данных – Magnetic, Agile, Deep (MAD) data analysis) как радикального отхода от корпоративных хранилищ данных (Enterprise Data Warehouses) и бизнес-аналитики (Business Intelligence). Мы представляем свою философию разработки, методы и опыт, обеспечивающие MAD-аналитику в компании Fox Audience Network на основе использования параллельной системы баз данных Greenplum. Мы описываем методологию проектирования баз данных, поддерживающую гибкий стиль анализа данных в этой среде. Мы также представляем параллельные по данным алгоритмы, используемые в сложных статистических методах, причем фокусируемся на плотностных методах (density method). Наконец, мы размышляем о средствах систем баз данных, допускающих гибкие проектирование и разработку алгоритмов с совместным использованием интерфейсов SQL и MapReduce поверх различных механизмов хранения данных.
Базы данных и статистические пакеты
Средства BI обладают довольно ограниченными статистическими функциональными возможностями. Поэтому во многих организациях стандартным приемом является извлечение частей базы данных в настольные программные пакеты: статистические пакеты типа SAS, Matlab или R, электронные таблицы наподобие Excel или собственный код пользователей, написанный на языках типа Java.
Этот подход чреват различными проблемами. Во-первых, копирование выборки из большой базы данных часто бывает гораздо менее эффективным, чем проталкивание вычислений ближе к данным; легко получить выигрыш в производительности на порядок величин, если выполнять код в базе данных. Во-вторых, для большинства статистических пакетов требуется, чтобы их данные умещались в основной памяти. При работе с большими наборами данных это означает, что для формирования выборки нужно отбирать образцы, что приводит к утрате детализации. В современных приложениях, таких как размещение рекламы, для микротаргетинга (microtargeting) требуется понимание даже небольших групп населения. При взятии образцов и сводок в наборе данных могут потеряться успешные бизнес-модели (long tail), а именно они все чаще требуются в борьбе за эффективность бизнеса.
Лучший подход состоит в тесной интеграции статистических пакетов с массивно параллельной базой данных. К сожалению, для многих имеющихся в настоящее время статистических пакетов отсутствуют параллельные реализации какого-либо вида. Параллелизованные статистические библиотеки, (например, посредством ScaLAPACK ) основываются на использовании протоколов обмена сообщениями между процессорами (на базе MPI) и не интегрируются естественным образом с параллелизмом по данным популярных решений для обработки больших объемов данных.
Благодарности
Благодарим Ноэля Сио (Noelle Sio) и Дэвида Хаббарда (David Hubbard) из FAN за их вклад в эту работу и Джеймса Марка (James Marca) из университета Южной Калифорнии в Ирвине за помощь в организации наших обсуждений.
ETL и ELT
Для поддержки традиционных хранилищ данных используются специальные инструментальные средства, выполняющие задачу извлечения-преобразования-загрузки (Extract-Transform-Load, ETL) данных. В последние годы наблюдается расширяющаяся тенденция к переносу работы по преобразованию данных в СУБД, чтобы обеспечить возможность ее параллельного выполнения на основе использования трансформационных SQL-скриптов. Этот подход получил название ELT, поскольку преобразование данных производится после их загрузки. Подход ELT становится еще более естественным при использовании внешних таблиц. Трансформационные запросы можно написать по отношению к внешним таблицам, что устраняет потребность в загрузке непреобразованных данных. Это может существенно ускорить цикл разработки преобразований – в особенности, в сочетании с использованием при отладке преобразований раздела SQL LIMIT как "средства онлайновой агрегации для бедных" .
В дополнение к преобразованиям, представляемым на SQL, в Greenplum поддерживаются скрипты MapReduce внутри СУБД; они могут запускаться над внешними данными на основе Scatter/Gather или же над таблицами базы данных (подраздел 6.3). Это позволяет программистам писать трансформационные скрипты в стиле программирования потоков данных, используемом во многих средствах ETL, и выполнять их в требуемом масштабе на основе средств распараллеливания, которые поддерживаются в СУБД.
FOX Audience Network
FOX Audience Network (FAN) является рекламной сетью, обсуживающей несколько Internet-издательств, включая MySpace.com, IGN.com и Scout.com. При наличии более 150 миллионов пользователей она является одной из крупнейших в мире рекламной сетью.
Хранилище данных FAN сегодня реализуется на основе системы Greenplum Database, работающей на сорока двух узлах: из которых сорок узлов используется для обработки запросов, а два являются управляющими узлами (один для восстановления после отказов). В узлах обработки запросов используются машины Sun X4500 ("Thumper") с двумя двухъядерными процессорами Opteron, 48 500-гигабайтными дисковыми устройствами и 16 гагабайтами основной памяти. В EDW компании в настоящее время сохраняется 200 терабайт индивидуальных производственных данных, которые зеркалируются для обеспечения возможности восстановления после сбоев. EDW быстро растет: каждый день в хранилище данных FAN поступает от четырех до семи миллиардов строк из журналов сервера управления рекламой, что составляет примерно пять терабайт. Основная таблица фактов о восприятии рекламы наращивается с октября 2007 г. и представляет собой сейчас единую таблицу с более чем полутора триллионами строк. Миллионы строк данных измерений о рекламодателях и рекламных компаний ежедневно поступают от системы управления связями с заказчиками (Customer Relationship Management, CRM) FAN. Кроме того, имеются подробные данные о каждом из более чем 150 миллионов пользователей. EDW компании FAN является единственным репозиторием, в котором все три источника данных интегрируются для использования в исследовательских целях или для производства отчетов.
EDW рассчитано на поддержку самых разных пользователей от менеджеров по учету продаж до ученых-исследователей. Потребности этих пользователей очень различаются, и к хранилищу данных каждый день применяются различные программные средства построения отчетов и обработки статистики. Непосредственно для этого хранилища данных компания MicroStrategy реализовала средство BI, поддерживающее генерацию отчетов по продажам, макетингу и большинству других направлений бизнеса компании.
У исследователей также имеется доступ к тому же хранилищу данных в режиме командной строки. Так что экосистема запросов является очень динамичной.
По-видимому, никакой набор предопределенных агрегатов не смог бы обеспечить ответ на любой вопрос. Например, легко представить себе вопросы, в которых комбинируются переменные рекламодателей и пользователей. В FAN это обычно означает непосредственное обращение к таблице фактов. Например, торговый агент мог бы легко задать следующий вопрос: Сколько энтузиасток Всемирного фонда природы в возрасте более 30 лет повторно посетило страницу сообщества Toyota в течение последних четырех дней и обратило внимание на средний прямоугольник? ("Средний прямоугольник" ("medium rectangle") – это стандартный формат рекламного баннера в Web.) Цель состоит в том, чтобы обеспечить ответы на такие непредвиденные вопросы в течение минут, и не допускается отвергать запросы, ответы на которые заранее не вычислены.
В этом примере можно обойтись простым SQL-запросом, но в подобных сценариях всегда далее задается сравнительный вопрос: Насколько эти дамы похожи на тех, которые повторно посетили страницу Nissan? На этой стадии мы начинаем заниматься многомерным статистическим анализом, для которого требуются более сложные методы. В FAN исследователи предпочитают использовать R, а пакет RODBC часто применяется для организации непосредственного интерфейса с хранилищем данных. Если для формирования ответов на такие вопросы оказывается достаточно данных объемом не более пяти миллионов строк, подобные данные часто экспортируются и анализируются в R. Случаи, в которых это невозможно, являются основным побудительным мотивом данной статьи.
В дополнение к хранилищу данных, группа машинного обучения FAN использует несколько крупных кластеров Hadoop. Эта группа применяет десятки алгоритмов классификации, управляемого и неуправляемого обучения, нейронных сетей и обработки текстов на естественном языке. Такие методы не относятся к тем, которые традиционно поддерживаются в РСУБД, и их реализация в среде Hadoop приводит к потребности в миграции крупных объемов данных для выполнения любого одноцелевого исследования.Доступность методов машинного обучения прямо в хранилище данных позволила бы существенно сократить расходы по времени, обучению и управлению системой, и обеспечение этой доступности является одной из целей работы, описываемой в данной статье.
Функционалы
Базовая статистика не нова для реляционных баз данных – в большинстве систем поддерживаются средние значения, дисперсии и некоторые виды квантилей. Но моделирующие и сравнительные статистические средства в системы обычно не встраиваются. В этом подразделе мы представляем параллельные по данным реализации ряда методов сравнительной статистики, выраженные на SQL.
В предыдущем подразделе скаляры и векторы являлись атомарными единицами. Здесь основным объектом является функция плотности распределения вероятностей. Например, плотность нормального (Гауссова) распределения


SELECT x.value, (x.value - d.mu) * d.n / d.sigma AS z_score FROM x, design d
Интеллектуальный анализ данных и аналитика в базе данных
У параллельных алгоритмов интеллектуального анализа данных (data mining) имеется серьезная библиография; см., например, подборку Заки (Zaki) и Хо (Ho) . Наиболее распространенные методы data mining (кластеризация, классификация, поиск ассоциативных правил) имеют дело с тем, что можно было бы назвать поточечным принятием решений (pointwise decisions). При кластеризации и классификации ставится соответствие между индивидуальными точками и когортами (cohort) (метками классов или идентификаторами кластеров); результатом действия ассоциативных правил являются комбинаторные коллекции индивидуальных точек. Хотя эти проблемы нетривиальны, в области статистического моделирования имеются и некоторые другие методы. Например, распространенным методом анализа рекламы является A/B-тестирование (A/B testing), в котором берутся показатели отклика (response rates) некоторой подгруппы населения и некоторой контрольной группы, и с использованием различных метрик сравниваются их статистические плотности.
Стандартные методы data mining в коммерческих базах данных полезны, но очень прицельны: они соответствуют лишь малому числу из сотен статистических библиотек, поставляемых в составе статистических пакетов, таких как R, SAS или Matlab. Кроме того, они обычно реализуются в виде "черного ящика" – код компилируется в плагин сервера баз данных. В отличие от этого, статистические пакета типа R или Matlab являются гибкими средами программирования, в которых библиотечные подпрограммы могут расширяться и модифицироваться аналитиками. В MAD-анализе требуется, чтобы аналогичные возможности программирования на основе расширяемых средств SQL и/или MapReduce были привнесены в сценарии использования крупных данных. В этом контексте иногда могут быть полезны и процедуры data mining в виде черных ящиков, но только в небольшом числе случаев.
Кроме нашей работы, в литературе описаны и другие интересные попытки выполнения значительных научных вычислений на языке SQL; наиболее значительная работа выполнена в связи с Sloan Digital Sky Survey . Уместно также упомянуть управление экспериментами и сложным SQL-кодом . Кроме того, интересующимся читателям стоит познакомиться с работами, посвященными новым исследовательским системам управления научными данными и масштабируемости R . Что касается интеграции данных, то нашей МОГучей философии близка и идея "пространств данных" .
История вопроса: если вы не МОГучи
Аналитическая обработка данных – это не новая область. В этом разделе мы описываем стандартные приемы и родственные работы в направлениях BI и крупномасштабного анализа данных, чтобы образовать контекст для представления своего МОГучего подхода.
Эволюция данных: хранение и разделение
В жизненном цикле данных в МОГучем хранилище данных участвуют данные в разных состояниях. Когда некоторый источник данных в первый раз загружается в систему, аналитики обычно часто обращаются к нему, выполняя существенные аналитические и трасформационные операции. Когда для некоторого источника данных преобразования и определения таблиц начинают стабилизироваться, рабочая нагрузка больше напоминает ту, которая свойственна традиционным EDW: частые добавления к большой таблицы "фактов" и редкие обновления таблиц "детальных данных". Эти зрелые данные, наиболее вероятно, используются для эпизодического анализа и решения стандартных задач отчетности. Поскольку данные в таблицах "фактов" со временем стареют, обращения к ним могут происходить менее часто, и они даже могут перемещаться во внешний архив. Заметим, что в одном хранилище данных в любой момент времени могут сосуществовать данные во всех состояниях.
Поэтому в СУБД, хорошо подходящей для MAD-аналитики, требуется поддерживать несколько механизмов хранения данных, ориентированных на различные стадии жизненного цикла данных. На ранней стадии внешние таблицы обеспечивают легковесный подход к экспериментированию с преобразованиями данных. Таблицы детальных данных обычно обладают умеренными размерами и подвергаются периодическим обновлениям; для них хорошо подходят традиционные методы хранения транзакционных данных. В основном только пополняемые таблицы файлов лучше хранить в сжатой форме, позволяющей эффективно выполнять операции вставки и чтения данных за счет замедления операций обновления существующих строк. Должна поддерживаться возможность выгружать эти данные из хранилища данных по мере их старения без прерывания выполняемой обработки.
В Greenplum обеспечивается несколько механизмов хранения данных. Развитые средства спецификации разделения данных языка SQL позволяют применять эти механизмы к таблицам целиком или их частям. Как отмечалось ранее, в Greenplum поддерживаются внешние таблицы.
Также обеспечивается формат хранения вида "кучи" для часто обновляемых данных и возможность хранения таблиц в сильно сжатой форме, оптимизированной для выполнения операций добавления данных ("append-only", AO), для которых не предполагаются операции обновления. Оба эти механизма хранения данных интегрированы в транзакционную инфраструктуру. Для единиц хранения типа AO допускаются различные режимы сжатия. В одном крайнем случае, когда сжатие отключается, очень быстро выполняется загрузка массивных данных. При другой крайности используются наиболее действенные режимы сжатия, позволяющие расходовать как можно меньше пространства области хранения. Имеются и компромиссные режимы "среднего" сжатия, обеспечивающие эффективный просмотр таблиц для счет небольшого замедления загрузки. В последней версии Greenplum также появилось идейно близкое "поколоночное" разделение таблиц, ориентированных на добавление данных. Это способствует повышению уровня сжатия и гарантирует, что при выполнении запросов над крупными архивными таблицами из внешней памяти будут считываться только требуемые столбцы.
Администратор базы данных может гибким образом специфицировать требуемый механизм хранения. В Greenplum поддерживается много способов разделения таблиц с целью повышения производительности выполнения запросов и загрузки данных, а также содействия управлению крупными наборами данных. Самым верхним уровнем разделения является политика распределения (distribution policy), специфицируемая в разделе DISTRIBUTED BY оператора CREATE TABLE и определяющая, каким образом строки таблицы распределяются по отдельным узлам кластера Greenplum. В то время, как у всех таблиц имеется политика распределения, пользователь опционально может специфицировать для таблицы политику разделения (partitioning policy), которая разъединяет данные таблицы в разделы по диапазону или по списку. Политика разделения по диапазону позволяет пользователю специфицировать упорядоченный набор неперекрывающихся разделов для столбца разделения.
У каждого раздела имеются начальное (START) и конечное (END) значения. Политика разделения по списку позволяет пользователю специфицировать набор разделов для некоторой совокупности столбцов, причем каждый раздел соответствует некоторому конкретному значению. Например, таблица sales может быть хэш-распределена по узлам по sales_id. Кроме того, в каждом узле строки могут быть разъединены по диапазону в разделы по месяцам, а строки в каждом из этих разделов могут быть дополнительно разъединены по трем регионам продаж. Заметим, что структура разделения полностью поддается изменениям: в любой момент времени пользователь может добавлять новые разделы или удалять существующие разделы или подразделы.
Разделение таблиц важно по ряду причин. Во-первых, оптимизатор запросов осведомлен о структуре разделения и может анализировать предикаты с целью исключения разделов (partition exclusion): сканировать только некоторый поднабор разделов, а не таблицу целиком. Во-вторых, у каждого раздела таблицы может иметься свой формат хранения в соответствии с ожидаемой рабочей нагрузкой. Типичная схема состоит в разделении таблицы по полю временной метки и хранении старых разделов в сильно сжатом формате, ориентированном только на добавление данных, а более новых ("более горячих") разделов – в формате, в большей степени допускающем обновления данных. В-третьих, становится возможным атомарный обмен разделами (atomic partition exchange). Вместо того, чтобы вставлять в таблицу по одной строке за раз, пользователь может воспользоваться ETL или ELT для размещения своих данных в некоторой временной таблице. После того, как данные очищены и преобразованы, можно воспользоваться командой ALTER TABLE ... EXCHANGE PARTITION для привязки этой временной таблицы в качестве раздела существующей таблицы путем выполнения быстрой атомарной операции. Эта возможность делает разделение особенно полезным для организаций, которые выполняют ежедневные, еженедельные или ежемесячные массивные загрузки данных, и в особенности в тех случаях, когда они удаляют или архивируют старые данные для поддержки в хранилище данных в оперативном режиме некоторого окна данных фиксированного размера.Та же идея позволяет пользователям осуществлять физическую миграцию таблиц и модифицировать форматы хранения, ограждая производственные таблицы от накладных расходов загрузки и преобразования данных.
Когда наступит будущее?
Когда мы говорим, что подход MAD является будущим аналитики, это не только наши мечты. Для ряда ведущих организаций это будущее уже наступило и приносит явную и возрастающую пользу. Но у более консервативных организаций может отсутствовать даже путеводная нить к обретению аналитического МОГущества, и в них может царить разочарование из-за отсутствия в прошлом успехов у штатных аналитиков или от инициатив по интеллектуальному анализу данных. Однако эти уроки следует воспринимать в контексте их времени. По мнению Вариана, цитата из интервью которого взята в качестве эпиграфа к этой статье, экономика данных изменяется с экспоненциальной скоростью. Вопрос стоит не в том, следует ли обрести МОГущество, а лишь в том, как и когда. Почти во всех средах имеет смысл некоторый эволюционный процесс: даже когда новые навыки, приемы и люди объединяются для разработки подходов MAD, стоит продолжать поддерживать функционирование традиционных, консервативных хранилищ данных. Это сосуществование нескольких стилей аналитики само по себе представляет пример МОГучего подхода.
Литература
T. Barclay et al. Loading databases using dataflow. SIGMOD Record, 23(4), 1994. J. Choi et al. ScaLAPACK: a portable linear algebra library for distributed memory computers – design issues and performance. Computer Physics Communications, 97(1-2), 1996. High-Performance Computing in Science. C.-T. Chu et al. Map-Reduce for machine learning on multicore. In NIPS, pages 281-288, 2006. J. Dean and S. Ghemawat. MapReduce: Simplified data processing on large clusters. In OSDI, pages 137-150, 2004. S. Dubner. Hal Varian answers your questions, February 2008. M. Franklin, A. Halevy, and D. Maier. From databases to dataspaces: a new abstraction for information management. SIGMOD Rec., 34(4), 2005. G. Graefe. Encapsulation of parallelism in the volcano query processing system. SIGMOD Rec., 19(2), 1990. J Gray et al. Data cube: A relational aggregation operator generalizing group-by, cross-tab, and sub-totals. Data Min. Knowl. Discov., 1(1), 1997. Greenplum. A unified engine for RDBMS and MapReduce, 2009. F. R. Hampel et al. Robust Statistics - The Approach Based on Influence Functions. Wiley, 1986. J. M. Hellerstein, P. J. Haas, and H. J. Wang. Online aggregation. In ACM SIGMOD, 1997. W. Holland, February 2009. Downloaded from
http://www.urbandictionary.com/define.php?term=mad. W. H. Inmon. Building the Data Warehouse. Wiley, 2005. Y. E. Ioannidis et al. Zoo: A desktop experiment management environment. In VLDB, 1996. A. Kaushik. Web Analytics: An Hour a Day. Sybex, 2007. N. Khoussainova et al. A case for a collaborative query management system. In CIDR, 2009. K. Lange. Optimization. Springer, 2004. M. T. Roth and P. M. Schwarz. Don't scrap it, wrap it! A wrapper architecture for legacy data sources. In VLDB, 1997. M. Stonebraker. Inclusion of new types in relational data base systems. In ICDE, 1986. M. Stonebraker et al. C-store: a column-oriented dbms. In VLDB, 2005. M. Stonebraker et al. Requirements for science data bases and SciDB. In CIDR, 2009. A. S. Szalay et al. Designing and mining multi-terabyte astronomy archives: the sloan digital sky survey. SIGMOD Rec., 29(2), 2000. R. Vuduc, J. Demmel, and K. Yelick. Oski: A library of automatically tuned sparse matrix kernels. In SciDAC, 2005. M.J. Zaki and C.-T. Ho. Large-Scale Parallel Data Mining. Springer, 2000. Y. Zhang, H. Herodotou, and J. Yang. Riot: I/O-efficient numerical computing without SQL. In CIDR, 2009.
Логарифмические отношения правдоподобия
Отношения правдоподобия полезны для сравнения некоторой подсовокупности с совокупностью в целом по некоторым конкретным характеристикам. Например, в области рекламы могут учитываться такие характеристики пользователей, как любимый напиток и семейное положение. Могло бы потребоваться узнать, привлекает ли кофе молодых родителей в большей степени, чем популяцию в целом.
Здесь мы имеем две функции плотности (или распределения масс) для одного и того же набора данных X. Назовем одно распределение основной гипотезой f0, а другое – альтернативной гипотезой f1. Обычно f0 и f1 являются разными параметризациями одной и той же плотности. Например, N(μ0, σ0) и N(μA, σA). Сходство L относительно fi задается следующим соотношением:

Логарифмическое отношение подобия (log-likelihood ratio, LLR) определяется как
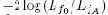

Эти вычисления хорошо распределяются, если

SELECT 2 * sum(log(f_llk(T.value, d.alt_param))) - 2 * sum(log(f_llk(T.value, d.null_param))) AS llr FROM T, design AS d
Для вычисления такого запроса от РСУБД требуется значительная гибкость и изощренность.
Пример: полиномиальное распределение
Полиномиальное (multinomial) распределение является расширением биномиального распределения. Рассмотрим случайную переменную X с k дискретными исходами. Для них имеются вероятности p = (p1, ...,pk1). При n попытках суммарное распределение вероятности выражается следующим образом:

Чтобы получить pi, предположим, что базисная совокупность представлена в таблице outcome со столбцом outcome.
CREATE VIEW B AS SELECT outcome, outcome_count / sum(outcome_count) over () AS p FROM (SELECT outcome, count(*)::numeric AS outcome_count FROM input GROUP BY outcome) AS a
В контексте выбора модели часто бывает удобно сравнить один и тот же набор данных при наличии двух разных полиномиальных распределений.

Или на SQL:
SELECT 2 * sum(T.outcome_count * log B.p) - 2 * sum(T.outcome_count * log T.p) FROM B, test_population AS T WHERE B.outcome = T.outcome
MapReduce и параллельное программирование
В то время как для корпоративного использования предлагались методологии BI и EDW, внимание многих разработчиков привлекла модель программирования MapReduce, введенная компанией Google. Очень заметные успехи Google в областях размещения рекламы и обработки текстов (и их публичное принятие методов статистического машинного обучения) способствовали быстрому росту популярности этого подхода. В недавней статье о реализации алгоритмов машинного обучения в среде MapReduce был выделен ряд стандартных методов, которые могут быть применены в параллельном по данным стиле посредством обобщения. Проект Apache Mahout является попыткой реализовать эти методы в открытой реализации MapReduce Hadoop. Результаты, описанные в этой статье, равно применимы и к SQL, но важно технико-социальное явление, сопутствующее MapReduce: появление этой модели привело к тому, что ряд расположенных к статистике исследователей и разработчиков сфокусировался на крупных данных и параллельном по данным программировании, а не на программировании для мультипроцессоров на основе MPI. Этот дух параллельного по данным программирования способствовал разработке и наших алгоритмов, описываемых в разд. 5. Но, как отмечается в разд. 4, стиль программирования – это лишь один аспект подхода MAD к управлению процессом аналитики.
Мера tf-idf и косинусная мера сходства
Введение векторных операций позволяет нам говорить о методах гораздо более компактно. Здесь мы рассматриваем конкретный пример: установление сходства документов – инструмент, общеупотребительный в Web-рекламе. Одна из областей использования – выявление подделок. Когда у многих разных рекламодателей имеются ссылки на очень похожие страницы, обычно, на самом деле, все они являются одной группой злоумышленников, и очень вероятно использование для оплаты украденых кредитных карт. Поэтому разумным подходом является обследование исходящих ссылок рекламодателей и поиск похожих документов.
Распространенная метрика сходства документов tf-idf включает три или четыре шага, которые все легко распределяются и хорошо сводятся к методам SQL. Во-первых, необходимо создать триплеты (document, term, count). Затем с использованием простых SQL-запросов с GROUP BY вычисляются маргиналы по document и term. После этого исходные триплеты можно расширить оценкой tf-idf по каждому измерению (т.е. для каждого слова результирующего словаря) путем соединения триплетов с маргиналами данного документа и отделения счетчика числа документов от счетчика числа терминов. На основе этого для каждых двух документов вычисляется косинусная мера сходства, и получается стандартная метрика "расстояния".
Более точно, хорошо известно, что для двух векторов весов терминов x и y косинусное сходство θ задается соотношением θ =
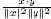
SELECT a1.row_id AS document_i, a2.row_id AS document_j, (a1.row_v * a2.row_v) / ((a1.row_v * a1.row_v) * (a2.row_v * a2.row_v)) AS theta FROM A AS a1, A AS a2 WHERE a1.row_id > a2.row_id
Для любого аналитика, привыкшего к скриптовой среде SAS или R, эта формулировка совершенно приемлема. Кроме того, работа по распределению объектов и определению операций выполняется DBA. Если объекты и операции становятся более сложными, возрастают преимушества наличия предопределенных операций. С практической точки зрения мы превращаем систему баз данных из простой системы выборки данных в интерактивную среду аналитического программирования.
Методы повторного взятия образцов
Параметрическое моделирование предполагает, что данные поступают от некоторого процесса, который полностью представляется математическими моделями с рядом параметров – например, средним значением и дисперсией нормального распределения. Параметры реального процесса требуется оценивать на основе существующих данных служащих "образцом" этого процесса. При получении таких параметров для крупных данных можно было бы склониться к простому использованию агрегатов SQL AVERAGE и STDDEV, но обычно этого бывает недостаточно. В реальных наборах данных, подобных тем, которые существуют в FAN, неизменно содержатся аномальные значения и другие артефакты. Наивная "простая статистика" над такими данными (т.е. использование агрегатов SQL) не является устойчивой (robust) и приводит к "сверхподгонке" ("overfitting") модели по отношению к этим артефактам. Это может препятствовать тому, чтобы в модели должным образом отражались свойства реальных процессов.
Основная идея повторного взятия образцов состоит в том, что из некоторого набора данных управляемым образом постоянно берутся образцы, над каждым образцом вычисляется сводная статистика, и образцы тщательно комбинируются, чтобы получить более устойчивые оценки свойств всего набора данных. Интуитивно понятно, что редкие аномальные данных будут появляться лишь не в многих образцах (или вообще не будут появляться) и не будут приводить к искажению оценок.
В литературе по статистике описываются два стандартных метода повторного взятия образцов. Метод раскрутки очень прост: из совокупности размера N выбираются k элементов (подобразец размера k) и над ними вычисляется требуемая статистика Θ0. Теперь сменим подобразец и выберем другие случайные k элементов. Новая статистика Θ1 будет отличаться от предыдущей. Повторим это "взятие образцов" десятки или сотни раз. Распределение результирующих Θi называется выборочным распределением (sampling distribution). В соответствии с центральной предельной теоремой (Central Limit Theorem) выборочное распределение является нормальным, и поэтому среднее значение крупного выборочного распределения является точной оценкой Θ*.
Альтернативой раскрутки является метод расщепления выборки (jackknife), который постоянно перевычисляет сводную статистику Θi путем исключения одного или нескольких элементов данных из общего набора данных для определения влияния некоторых подсовокупностей. Результирующий набор наблюдений используется как выборочное распределение таким же образом, как и в методе раскрутки, для получения хорошей оценки интересующей статистики.
Важно то, что не требуется, чтобы все подобразцы были в точности одного и того же размера, хотя использование образцов сильно различающегося размера может привести к некорректным пределам погрешности.
В предположении, что интересующую статистику Θ легко получить посредством применения SQL, например, путем вычисления среднего значения набора значений, единственное, что требуется, – это организация повторного взятия образцов на основе генератора достаточно случайных чисел. Проиллюстрируем это на примере метода раскрутки. Рассмотрим таблицу T с двумя столбцами (row_id, value) и N строками. Предположим, что столбец row_id содержит значения 1, ..., N. Поскольку взятие каждого следующего образца производится с полной заменой предыдущего образца, мы можем заранее определить повторное взятие образцов. Это означает, что если мы производим M взятий образцов, что мы можем заранее решить, что запись i будет присутствовать в подобразцах 1, 2, 25, ... и т.д.
Функция random() генерирует равномерно распределенные случайные элементы из (0,1), а функция floor(x) выдает целую часть x. Мы используем эти функции при разработке эксперимента с повторным взятием образцом. Предположим, что у нас имеется N = 100 объектов изучения, и мы хотим произвести 10000 попыток взятия образцов размером 3.
CREATE VIEW design AS SELECT a.trial_id, floor (100 * random()) AS row_id FROM generate_series(1,10000) AS a (trial_id), generate_series(1,3) AS b (subsample_id)
Уровень доверия к генератору случайных чисел здесь зависит от системы и исследователю нужно проверить, что при масштабировании функции random() она по-прежнему возвращает равномерно распределенные случайные значения нужного масштаба.
Для выполнения эксперимента на этим представлением достаточного одного запроса:
CREATE VIEW trials AS SELECT d.trial_id, AVG(a.values) AS avg_value FROM design d, T WHERE d.row_id = T.row_id GROUP BY d.trial_id
Это представление формирует выборочное распределение: средние значения каждого подобразца. Окончательные результат процесса раскрутки выдается простым запросом над этим представлением:
SELECT AVG(avg_value), STDDEV(avg_value) FROM trials;
Этот запрос возвращает представляющую интерес статистику на заданным числом подобразцов. Для функций AVG() и STDDEV() уже имеется параллельная реализация, так что и весь метод работает параллельно. Заметим, что представление design имеет относительно небольшой размер (примерно 30000 строк), и поэтому может размещаться в основной памяти; следовательно, все 10000 "экспериментов" выполняются за один параллельный проход по таблице T, т.е. с теми же расходами, которые требуются для вычисления одного наивного SQL-агрегата.
При реализации метода расщепления выборки используется аналогичный прием для выполнения нескольких экспериментов за один проход по таблице, не считая взятия случайной подсовокупности на каждом проходе.
МОГучая СУБД
Для реализации подхода MAD, описанного в общих чертах в разд. 4, требуется поддержка СУБД. Во-первых, загрузка данных в "магнетичную" базу данных должна быть безболезненной и эффективной, чтобы аналитики могли использовать новые источники данных внутри хранилища данных. Во-вторых, для поддержки "гибкости" системы требуется обеспечить простую эволюцию хранения данных на физическом уровне. Наконец, для поддержки "основательности" анализа – и, в действительности, всех аспектов MAD-аналитики – требуется, чтобы база данных была мощной и гибкой средой программирования, привлекательной для разработчиков с разными предпочтениями.
МОГучее программирование
Хотя в подходе MAD предпочтение отдается быстрому импорту и частому использованию данных, а не их тщательному моделированию, это не означает отказа от структурированных баз данных как таковых. Как отмечалось в разд. 4, средства СУБД управления структурированными данными могут быть очень полезны для организации экспериментальных данных, пробных наборов данных и экспериментальных потоков работ. На самом деле, на предприятиях, в которых используются инструменты типа Hadoop, обычно имеются также СУБД, и/или развертываются легкие системы баз данных типа Hive. Но в том же разд. 4 отмечалась и полезность унификации структурированной среды и предпочитаемыми аналитиками средами программирования.
Аналитиками данных становятся люди разных профессий. Некоторые из них являются экспертами по SQL, но многие – нет. Аналитики с научной или математической подготовкой обычно хорошо знакомы со статистическими пакетами, такими как R, SAS или Matlab. Эти пакеты работают с данными в основной памяти на настольных компьютерах, но они поддерживают удобные абстракции математического программирования и обеспечивают доступ к библиотекам, содержащим сотни статистических процедур. Для других аналитиков привычны традиционные языки программирования типа Java, Perl и Python, но обычно им не по душе написание параллельного или ориентированного на оптимизацию ввода-вывода кода.
Способ расширения функциональных возможностей системы баз данных, впервые примененный в Postgres , теперь не является экзотикой в СУБД – это опора современной аналитики, позволяющая выполнять код поблизости от данных. Чтобы привлечь различных программистов, в интерфейсе правильно организованной расширяемой СУБД должно поддерживаться несколько языков. В этом отношении достаточно мощной стала PostgreSQL: в этой СУБД поддерживается множество языков программирования расширений, включая R, Python и Perl. В Greenplum перенимаются эти интерфейсы, и обеспечивается возможность выполнения получаемых программ на кластере параллельно по данным.
Конечно, автоматический параллелизм не обеспечивается: разработчикам приходится думать о том, как их код будет выполняться в папаллельной по данным среде (как мы поступали по отношению к примерам из разд. 5).
У разработчиков, в дополнение к работе по реализации статистических методов на расширяемом SQL (подобных тем, которые описывались в разд. 5), имеется энтузиазм к реализации методов с использованием парадигмы программирования MapReduce, популяризируемой Google и Hadoop. С точки зрения разработки языков программирования в MapReduce и современном SQL применяются очень похожие подходы к параллелизму: в обеих случаях используются модели программирования с распараллеиванием по данным для архитектур без совместно используемых ресурсов; обеспечивается возможность восходящих вызовов (upcall) расширений для обработки отдельных кортежей или наборов кортежей в потоке данных. Но, как явление культуры, MapReduce привлекает внимание многих разработчиков, заинтересованных в выполнении крупномасштабного анализа над большими данными, и широко распространено мнение, что эта среда программирования более привлекательна, чем SQL. МОГучее хранилище данных должно привлекать и этих программистов, позволяя им программировать в любимом ими стиле MapReduce в контексте, интегрирующем оба эти подхода с общими корпоративными данными, и обеспечивая более сложные средства управления продуктами данных.
В Greenplum эта проблема решается путем реализации интерфейса программирования MapReduce, механизмом поддержки времени выполнения которого является тот же самый исполнитель запросов, который используется для поддержки SQL . Пользователи пишут функции Map и Reduce на знакомых языках типа Python, Perl или R и связывают их со скриптами MapReduce посредством простого конфигурационного файла. Затем они могут выполнить эти скрипты через интерфейс командной строки, передающий конфигурацию и код MapReduce в СУБД, которая возвращает получаемые результаты в конфигурируемое место назначения: командную строку, файлы или таблицы СУБД.
Для взаимодействия с СУБД требуется указать только ее IP-адрес и свои аутентификационные данные (пользователь/пароль, ключи PGP и т.д.). Следовательно, разработчики, применяющие традиционные инструментальные средства с открытыми кодами, продолжают использовать свои любимые редакторы текстов, системы управления исходным кодом и интерфейсы shell; им ничего не нужно знать об утилитах базы данных, синтаксисе SQL, проектировании схемы и т.д.
Исполнитель Greenplum обеспечивает доступ к файлам для заданий MapReduce с использованием того же метода Scatter/Gather, который применяется для доступа к внешним таблицам в SQL. Кроме того, в Greenplum скрипты MapReduce могут взаимодействовать со всеми средствами базы данных и наоборот. В качестве входных данных скриптов MapReduce могут использоваться таблицы и представления, а результаты работы скриптов могут сохраняться в виде таблиц базы данных, к которым можно напрямую обращаться из среды SQL. Поэтому можно организовывать сложные конвейеры, некоторые фазы которых представлены на SQL, а некоторые – в синтаксисе MapReduce. Выполнение этих фаз может производиться полностью по требованию (при запуске фаз SQL и MapReduce в конвейере) или при материализации их результатов внутри или вне базы данных. Разные скрипты могут взаимодействовать на основе обычных интерфейсов: через таблицы и представления базы данных или входные потоки MapReduce. Для написания функций Map и Reduce, а также функций, расширяющих SQL, можно использовать разнообразные языки программирования.
Эта интероперабельность интерфейсов программирования очень важны для MAD-аналитиков. Она привлекает их (и, следовательно, данные) к хранилищу данных. Она обеспечивает разработчикам гибкость за счет возможности использования знакомых интерфейсов программирования и обеспечения взаимодействия между разными стилями программирования. Наконец, аналитики могут разрабатывать новые методы с использованием наилучших имеющихся средств, включая многие специализированные модули, написанные для используемых языков программирования.
При работе с разнообразными заказчиками Greenplum мы обнаружили, что разработчики, равно комфортно чувствующие себя при использовании и SQL, и MapReduce, гибко выбирают наилучший подход при решении разных задач. Например, подход MapReduce оказывается более удобным при написании ETL-скриптов для файлов, в которых известен порядок данных, и этот порядок может использоваться при преобразовании данных. MapReduce также облегчает спецификацию преобразований, в которых имеется одной входной поток данных и производится много выходных потоков, – это также распространено в средах ENL, в которых "измельчаются" входные записи, и производятся потоки результирующих таблиц со смешанными форматами. Как не странно, SQL оказывается более удобным, чем MapReduce, для задач, связанных с графовыми данными, такими как ссылки в Web или социальные сети, поскольку большую часть алгоритмов в этой сфере (PageRank, вычисление коэфициентов кластеризации и т.д.) можно компактно закодировать с исползованием "самосоединений" таблицы ссылок.
МОГучие способности: новые приемы анализа больших данных
Джеффри Коэн, Брайен Долэн, Марк Данлэп, Джозеф Хеллерстейн, Кейлэб Велтон.
Перевод: Сергей Кузнецов
Оригинал: Jeffrey Cohen, Brian Dolan, Mark Dunlap, Joseph M. Hellerstein, Caleb Welton. MAD Skills: New Analysis Practices for Big Data. Proceedings of the VLDB'09 Conference, Lyon, France, August 24-28, 2009,
Джеффри Коэн, Брайен Долэн, Марк Данлэп, Джозеф Хеллерстейн, Кейлэб Велтон.
Перевод: Сергей Кузнецов
Джеффри Коэн, Брайен Долэн, Марк Данлэп, Джозеф Хеллерстейн, Кейлэб Велтон.
Перевод: Сергей Кузнецов
Джеффри Коэн, Брайен Долэн, Марк Данлэп, Джозеф Хеллерстейн, Кейлэб Велтон.
Перевод: Сергей Кузнецов
Джеффри Коэн, Брайен Долэн, Марк Данлэп, Джозеф Хеллерстейн, Кейлэб Велтон.
Перевод: Сергей Кузнецов
Джеффри Коэн, Брайен Долэн, Марк Данлэп, Джозеф Хеллерстейн, Кейлэб Велтон.
Перевод: Сергей Кузнецов
Направления и размышления
Работа, описываемая в этой статье, является результатом довольно быстрых интерактивных обсуждений с людьми разных профессий и с разной подготовкой, основной интерес для которых представляют данные. Структура статьи заранее не планировалась; вместо этого мы применили МОГучий подход: собрали много данных, организовали быстрые обсуждения с несколькими заинтересованными сторонами и постарались поглубже вникнуть в детали.
Как и в MAD-анализе, мы ожидаем новых вопросов и новых выводов при поступлении большего числа данных. В число проблем, исследуемых в настоящее время, входит следующее:
Управление пакетами и повторное использование: Во многих случаях аналитику требуется всего лишь увязать и параметризовать готовые методы из учебников типа линейной регрессии повторного взятия образцов. Для поддержки этого имеется настоятельная потребность (в средах и SQL, и MapReduce) в некотором решении для управления пакетов и в репозитории наподобие репозитория CRAN для R, чтобы обеспечить очень простое повторное использование кода. Помимо прочего, для этого требуется стандартизовать словарь таких объектов, как векторы, матрицы, функции и функционалы.
Совместная оптимизация методов хранения и запросов для линейной алгебры: Имеется много вариантов размещения матриц в узлах кластера . Мы полагаем, что во всех случаях для хранения матрицы могут использоваться записи, к которым применяются методы, написанные в синтаксисе SQL или MapReduce. Следующим шагом является усложнение оптимизатора запросов, которое позволит ему (a) учитывать наличие нескольких одновременно используемых способов хранения матриц и (b) выбирать из числа эквивалентных библиотечных процедур линейной алгебры те процедуры, которые настраиваются к разным способам хранения.
Автоматизация физического проектирования для повторяющихся задач: Аналитики, занимающиеся ETL/ELT или базовой аналитикой, часто выполняют несколько разного рода проходов по массивным наборам данных. Обычно им приходится задумываться над тем, как следует хранить эти данные: оставить их вне базы данных, использовать один из многочисленных форматов хранения базы данных, материализовать повторяющиеся вычисления и т.д. Аналитикам эти вопросы не интересны, их интересуют данные. Было бы полезно, чтобы система принимала соответствующие решения автоматически (или, возможно, полуавтоматически).
Оперативная обработка запросов для MAD-аналитики: Быстрота аналитики зависит от того, насколько часто аналитик сможет выполнять свои задачи. Методы, подобные онлайновой агрегации (Online Aggregation ), могут радикально ускорить этот процесс, но для этого их нужно значительно расширить, чтобы обеспечить обсуждаемую здесь основательную аналитику. Требуются методы получения полезных скользящих оценок (running estimates) для более сложных вычислений, включая эпизодический код наподобие программ MapReduce. Нужны также методы приоритизации данных, позволяющие учитывать данные на "хвостах" распределений.
Новые требования
Как люди, искушенные в данных, аналитики предъявляют новый набор требований к среде базы данных. У них имеется глубокое понимание корпоративных данных, и они стремятся быть первопроходцами новых источников данных. Аналогично тому, как системные инженеры всегда склонны к работе с новейшей и мощнейшей аппаратурой, аналитики всегда жаждут новых источников данных. Когда появляются новые бизнес-процессы, производящие данные, аналитики немедленно требуют новых данных.
Эти требования к скорости поступления и широте охвата новых данных создают напряженность в отношениях с ортодоксами хранилищ данных. Инмон описывает традиционную точку зрения следующим образом:
Невозможно занести данные ... в среду хранилища данных без их предварительной интеграции. Если в хранилище данных поступают не интегрированные данные, их невозможно использовать для поддержки единого представления данных. А единое представление данных во многом является сутью планируемой среды.
К сожалению, проблема полной интеграции нового источника данных в "планируемое" хранилище данных часто является весьма существенной, и ее решение может задержать возможность доступа к данным на месяца, а во многих случаях и навсегда. Архитектурная точка зрения приводит к разногласиям в аналитике, отталкиванию источников данных от хранилища данных, и в результате получается поверхностное, неполное хранилище данных. Эта точка зрения противоречит идеалам MAD.
В условиях возрастающей сложности аналитических методов и увеличивающейся значимости аналитики мы принимаем ту точку зрения, что намного более важно обеспечить аналитикам гибкость, чем стремиться к иллюзорному идеалу полной интеграции. В действительности, в любой организации именно аналитики притягивают, отыскивают интересные данные, которые должны стать частью единой большой картины. Они могут также действовать как система раннего обнаружения касательно проблем качества данных. Ради возможности познакомиться с данными первыми они готовы смириться с наличием "грязных" данных, и они будут сами следить за тем, чтобы операционные данные выверялись до их поступления в хранилище данных.
У аналитиков обычно имеются более высокие стандарты качества данных, чем у типичного бизнес-подразделения, работающего с инструментами BI. Они не боятся больших плоских таблиц, хранящих полные наборы данных, пренебрегая образцами и агрегатами, которые могут маскировать ошибки и приводить к потере важных характеристик на хвостах распределений.
По нашему опыту, хорошие отношения с группой аналитики является отличной профилактической мерой для избежания будущих проблем с управлением данными. Удовлетворение их потребностей и отзывчивость к их заботам способствуют улучшению жизнеспособности всего хранилища данных.
В конечном счете, аналитика производит новые продукты данных, обладающие высокой значимостью для предприятия. Аналитики – это не только потребители, но и производители корпоративных данных. Для этого требуется подготовить хранилище данных к преобразованию данных, генерируемых аналитиками, в продукты данных, пригодные для использования в стандартных средствах бизнес-отчетности.
Полезно также при возможности использовать единую параллельную платформу и нагрузить ее как можно большей функциональностью. Это снижает стоимость операций и упрощает эволюцию программного обеспечения от экспериментальных программ аналитиков к производственному коду, влияющему на рабочие характеристики. Например, жизненный цикл некоторого алгоритма размещения рекламы мог бы начаться с отвлеченной аналитической задачи, а закончиться программным средством, обращенным к заказчикам. Если этот средство работает под управлением данными, лучше всего, чтобы весь его жизненный цикл происходил в единой среде разработки над полным набором данных предприятия. В этом отношении мы согласны с центральным догматом ортодоксов хранилищ данных: заметным преимуществом является размещение всех данных организации в одном репозитории. Мы расходится во мнениях по поводу того, как следует достигать этой цели.
Короче говоря, в разумном бизнесе следует использовать не планируемое хранилище данных, а, скорее, некоторую развивающуюся структуру, над которой повторяется непрерывный цикл изменений:
В данном бизнесе производится анализ для определения областей потенциального совершенствования.
Бизнес либо реагирует на результаты этого анализа, либо их игнорирует. Реагирование приводит к появлению новых или изменению существующих методов ведения бизнеса (возможно, новых процессов или систем взаимодействия подразделений), которые обычно генерируют новые наборы данных.
Аналитики включают новые наборы данных в свои модели.
Бизнес опять задается вопросом "Как можно еще усовершенствоваться?"
В разумном, конкурентноспособном бизнесе будут изыскиваться способы ускорить прохождение этого цикла. Описываемый далее подход MAD является конструктивным шаблоном, призванным поддерживать эту возрастающую скорость.
Обретение большего МОГущества
Центральная философия МОГучего моделирования данных состоит в том, чтобы поместить в хранилище данных данные организации как можно быстрее. Вторичные по отношению к этой цели очистка и интеграция данных должны осуществляться разумным образом.
Для практического воплощения этих идей мы предлагаем трехуровневый подход. При загрузке необработанных таблиц фактов или журналов следует использовать переходную (Staging) схему. Данными в этой схеме разрешается манипулировать только инженерам и некоторым аналитикам. В производственной схеме хранилища данных (Production Data Warehouse) сохраняются агрегаты, служащие большинству пользователей. К этой схеме предоставляется доступ подготовленным пользователям, комфортно чувствующим себя в крупномасштабной среде SQL. Поддерживается отдельная отчетная (Reporting) схема, содержащая специализированные статические агрегаты, используемые средствами генерации отчетов и случайными пользователями. Эта схема должна быть настроена таким образом, чтобы обеспечивать быстрый доступ к умеренным объемам данных.
Эти три уровня физически не разделяются. Пользователи с должными полномочиями могут соединять данные из разных уровней и схем. В модели FAN в переходной схеме сохраняются необработанные журналы рекламных акций. Аналитикам предоставляется доступ к этим журналам в исследовательских целях и для применения лабораторного подхода к анализу данных. Вопросы, начинающиеся на уровне журнала событий, часто становятся более масштабными, требующими специальной агрегации. При общении исследователей с администраторами базы данных выявляются распространенные вопросы, и это часто приводит к тому, что агрегаты, исходно предназначавшиеся для какого-то одного аналитика, переносятся в производственную схему.
Производственная схема обеспечивает быстрые ответы на распространенные вопросы, которые пока еще не настолько распространены, чтобы по ним требовались отчеты. Многие из этих вопросов предвосхищаются во время исталляции, а многие – нет. Долгое ожидание данных может привести к "маниакальному обжорству" ("feeding frenzies"), когда по отношению к этим данным начинает задаться один вопрос за другим.
На этой стадии, когда бизнес-аналитики начинают проникать в новую среду, очень важна гибкость. Им нужна ежедневная или ежемесячная информация. Вопросы относительно ежедневных характеристик превращаются в информационные панели (dashboard).
Аналитикам следует предоставить внутри хранилиза данных еще и четвертый класс схем, который мы называем "песочницей" ("sandbox"). Схема-песочница находится под полным контролем аналитиков и может использоваться для управления их экспериментальными процессами. Аналитики являются ухищренными в данных разработчиками, и им часто требуется отслеживать свою работу и ее результаты и сохранять соответствующие данные в базе данных. Например, как мы увидем в разд. 5, для структуризации задачи кодирования при разработке сложных конструкций на языке SQL принято использовать SQL-представления в качестве "подпрограмм". В течение разработки, вероятно, эти представления будут определяться и часто редактироваться. Аналогично, аналитикам может понадобиться материализовать результаты запросов, выполненных при выполнении их исследований, и позже повторно их использовать; эта материализация может также помочь процессу разработки программного обеспечения и повысить эффективность в условиях итеративной разработки аналитического потока работ. Кроме того, аналитикам для собственного удобства часто хочется отложить про запас свои любимые наборы данных, чтобы использовать их при разработке новых методов над известными данными.
Возможность перескакивать от очень специального к очень общему способствует иследованиям и творчеству. По мере использования, преобразования, обсуждения и усвоения данных организации обучаются и изменяют свою деятельность. Скорость прогресса зависит от скорости и глубины исследований. МОГучее проектирование направлено на увеличение этой скорости.
1Не следует это путать с созданием изолированной среды программных процессов (sandboxing) с целью обеспечения компьютерной безопасности. Здесь мы понимаем слово "песочница" как место для игр.
Обычный метод наименьших квадратов
Мы начнем с обычного метода наименьших квадратов (Ordinary Least Squares, OLS) – классического метода подбора кривой для данных, обычно с использованием полиномиальной функции. В Web-рекламе одним из стандартных приложений этого метода является моделирование сезонных тенденций. При наличии нескольких простых определенных пользователями функций над векторами аналитики могут естественным образом выражать OLS на SQL.
В нашем случае мы находим стастистическую оценку β*, наилучшем образом удовлетворяющую соотношение Y = Xβ. Здесь X = n × k – это набор фиксированных (независимых) переменных, и Y – набор из n наблюдений (зависимых переменных), которые мы хотим промоделировать посредством функции X с параметром β.
Как отмечается в ,

можно подсчитать путем вычисления A = X′X и b = X′y как суммирования. В параллельной базе данных это можно выполнить путем параллельного вычисления локальных A и b в каждом разделе базы данных с последующим слиянием промежуточных результатов в заключительном последовательном вычислении.
В результате будут получены квадратная матрица и вектор. Заключительное вычисление производится путем обращения небольшой матрицы A и ее умножения на вектор для получения коэффициентов β*.
Кроме того, попутно может быть произведено вычисление коэффициента смешанной корреляции R2:

В следующем SQL-запросе мы вычисляем коэффициенты β*, а также компоненты коэффициента смешанной корреляции:
CREATE VIEW ols AS SELECT pseudo_inverse(A) * b as beta_star, (transpose(b) * (pseudo_inverse(A) * b) - sum_y2/count) -- SSR / (sum_yy - sumy2/n) -- TSS as r_squared FROM ( SELECT sum(transpose(d.vector) * d.vector) as A, sum(d.vector * y) as b, sum(y)^2 as sum_y2, sum(y^2) as sum_yy, count(*) as n FROM design d ) ols_aggs;
Отметим использование определяемой пользователем функции для транспонирования вектора и определяемых пользователем агрегатов для суммирования объектов (многомерного) массива. Массив A – это небольшой массив, размещаемый в основной памяти, с которым мы обращаемся, как с одним объектом; функция pseudo-inverse реализует известное из учебников псевдообращение матрицы методом Мура-Пенроуза (Moore-Penrose).
Все указанные вычисления можно эффективно произвести за один проход по данным. Для удобства мы инкапсулировали это еще в двух определяемых пользователями функциях:
SELECT ols_coef(d.y, d.vector), ols_r2(d.y, d.vector) FROM design d;
До выполнения реализации этой функциональности внутри СУБД один из заказчиков Greenplum имел привычку вычислять OLS путем экспорта данных и их импорта в R, и этот процесс занимал несколько часов. Они сообщали о значительном повышении производительности после перехода к вычислению внутри СУБД. Основным преимуществом является параллельное выполнение анализа неподалеку от данных с их минимальным перемещением.
OLAP и кубы данных
В 1990-е гг. получили распространение кубы данных и оперативная аналитическая обработка данных (On-Line Analytic Processing, OLAP), что привело к интенсивным коммерческим разработкам и значительным академическим исследованиям. В реляционной среде основная идея OLAP преобразовалась в расширение SQL CUBE BY . Инструментальные средства BI оформляли эти сводные показатели в виде интуитивно понятных "межтабличных" визуализаций. При группировке по немногим измерениям аналитик видит грубую столбчатую диаграмму "обобщения" (roll-up); группировка по большему числу измерений позволяет перейти на более детальный уровень (drill down). Для этого вида анализа статистики используют термин дескриптивная (описательная) статистика. Такой подход традиционно применяется к результатам экспериментальных исследований. Эта функциональность полезна для получения интуитивного представления о процессе, определяющем данный эксперимент. Например, за счет описания потока данных о посещении некоторого Web-сайта можно получить лучшие интуитивные знания об основных свойствах состава пользователей.
В отличие от этого, статистика выводов (inferential statistics), или индуктивная статистика (inductive statistics) направлена на то, чтобы напрямую фиксировать основные свойства популяции. В число используемых приемов входят подбор моделей и параметров для данных и вычисление функций правдоподобия. Для применения статистики выводов требуется больше вычислений, чем для получения простых сводных данных, предоставляемых OLAP, но при этом обеспечивается большая вероятностная мощность, которую можно использовать для решения таких задач, как предсказание (например, "какие пользователи, вероятно, кликнули бы по этому новому рекламному банеру?"), анализ причинных связей (например, "какие свойства данной страницы приводят к ее повторному посещению пользователями?") и дистрибутивное сравнение (distributional comparison) (например, "чем модель покупательского поведения владельцев грузовиков отличается от аналогичной модели владельцев легковых автомобилей с кузовом "седан"?"). Индуктивный подход также является более устойчивым к наличию аномальных значений и других особенностей в заданном наборе данных. Хотя OLAP и кубы данных остаются полезными для получения инстуитивного понимания, использование статистики выводов становится необходимой во многих важных автоматических и полуавтоматических бизнес-процессах, включая размещение рекламы, оптимизацию Web-сайтов и управление связями с заказчиками.
Проектирование МОГучих баз данных
Традиционная философия хранилищ данных связана с дисциплинированным подходом к моделированию информации и процессов на предприятии. Словами сторонника хранилищ данных Билла Инмона (Bill Inmon), это "планируемая среда" . Как демонстрируется ниже, эта точка зрения по поводу хранилищ данных не согласуется с принципами магнетизма и гибкости, поддержка которых требуется во многих новых аналитических средах.
Сопряженные градиенты
Здесь мы обсуждаем параллельную по данным реализацию метода сопряженных градиентов (Conjugate Gradiant) для решения системы линейных уравнений. Мы можем использовать это для реализации машины опорных векторов (Support Vector Machines, SVM) – современного метода бинарной классификации. Бинарные классификаторы являются распространенным средством в области размещения рекламы, используемым для превращения мгогомерных характеристик пользователей в простые булевские метки типа "является любителем автомашин", которые можно объединять в диаграммы любителей (enthusiast chart). Кроме того, что метод сопряженных градиентов служит строительным блоком для SVM, он позволяет оптимизировать большой класс функций, которые можно аппроксимировать рядами Тейлора второго порядка.
Для математика решение матричного уравнения Ax = b не представляет труда, если оно существует: x = A-1b. Как отмечалось в подразделе 5.1, мы не можем считать, что в состоянии найти A-1. Если матрица A является (n × n)-симметричной и положительно определенной (symmetric and positive definite, SPD), то мы можем использовать метод сопряженных градиентов. Для применения этого метода не требуется ни df(y), ни A-1, и он сходится не более чем за n итераций. Общее описание метода проводится в . Здесь мы кратко описываем решение уравнения Ax = b как точки экстремума f(x) = ½x´Ax + b´x + c. Грубо говоря, у нас имеется некоторая оценка





Начнем итерацию по i.

При включении этого метода в базу данных мы сохраняли (vi, xi, ri, αi) как строку и вставляли на каждом проходе строку i+1.
Для этого потребовалось определить функции update_alpha(r_i, p_i, A), update_ x(x_i, alpha_i, v_i), update_r(x_i, alpha_i, v_i, A) и update_v(r_i, alpha_ i, v_i, A). Хотя вызовы функций были избыточными (например, update_v() также запускается для обновления ri+1), это позволяло нам вставлять на каждом шаге одну полную строку. Затем перед продолжением вычислений внешний управляющий процесс проверял значение ri. После достижения точки сходимости x* вычисляется элементарным образом.
Наличие метода сопряженных градиентов позволяет реализовать более сложные методы типа SVM. В своей основе метод SVM направлен на максимизацию расстояния между заданным множеством точек и подходящей гиперплоскостью. Это расстояние выражается длиной нормальных векторов


Этот метод применяется для решения более общей проблемы функций высокой размерности в приближении рядом Тейлора fx0(x) ≈ f(x0 + df(x)(x - x0) + ½(x - x0)´d2f(x)(x - x0). При хорошем начальном приближении для x* и распространенном предположении о непрерывности f(·) мы знаем, что матрица будет SPD поблизости от x*. Подробности см. в .
Статистика, параллельная по данным
Аналитики и статистики являются наиболее ухищренными в данных сотрудниками организации, и поэтому от них зависит МОГущество организации. В этом разделе мы сосредотачиваемся на мощных и общих статистических методах, которые делают хранилище данных более "магнетичным" и "гибким" для анализа, стимулируют аналитиков производить "основательные" исследования и значительно повышать уровень сложности и масштабности анализа данных.
Наш общий подход заключается в том, чтобы разработать иерархию математических понятий на SQL и инкапсулировать их таким образом, чтобы позволить аналитикам работать с использованием сравнительно знакомой статистической терминологии без потребности разработки статистических методов на SQL с самого начала при каждом вычислении. Аналогичную функциональность можно закодировать с использованием синтаксиса MapReduce.
В традиционных SQL-ориентированных базах данных обеспечиваются типы данных и функции для простой (скалярной) арифметики. Следующим уровнем абстракции является векторная арифметика со своим набором операций. Векторные объекты совместно с векторными операциями приводят нас к языку линейной алгебры. В подразделе 5.1 мы предлагаем методы для этих операций. На этом уровне мы можем говорит на языке машинного обучения, математического моделирования и статистики. Следующий уровень абстракции – это уровень функций; плотности вероятностей являются специализированными функциями. С интуитивных позиций, имеется и еще один уровень абстракции, на котором функции являются базовыми объектами, и алгебры создаются с использованием операций, называемых "функционалами", которые действуют над функциями. Это область функционального анализа. Методы типа t-тестов или отношений правдоподобия (likelihood ratio) являются функционалами. В A/B-тестировании функционалы обрабатывают одновременно два математических объекта: функции плотности распределений f1(·) и f2(·).
Тем самым, наша задача состоит в том, чтобы развить методы баз данных от скалярных до векторных, потом до методов над функциями, и потом до методов над функционалами. Кроме того, мы должны сделать это в массивно параллельной среде. Это не тривиально. Даже у "простой" на вид проблемы представления матриц нет одного оптимального решения. В нескольких следующих подразделах мы описываем методы, используемые нами для превращения параллельной базы данных в сильно масштабируемый статистический пакет. Мы начинаем с векторной арифметики и продвигаемся по направлению к функционалам, обсуждая попутно мощные статистические методы.
U-тест Манна-Уитни
Ранговая и порядковая статистика (rank and order statistics) вполне поддается реляционной обработке, поскольку основной целью здесь является единовременная обработка некоторого набора данных, а не какого-либо одного элемента данных. В следующем примере иллюстрируется сравнение двух полных наборов данных без накладных расходов на описание параметризуемой плотности.
U-тест Манна-Уитни (Mann-Whitney U Test, MWU) – это популярная замена t-теста Стьюдента (Student) в случае непараметрических данных. Основная идея состоит в том, чтобы взять две популяции A и B и решить, происходят ли они из одной и той же основной популяции, путем изучения рангового порядка, в котором элементы A и B обнаруживаются в общем порядке. Если элементы A находятся "впереди" этой последовательности, а элементы B – позади, то A и B являются разными популяциями. В рекламной среде отклики баннеров (click-through rate) в Web-рекламе склонны не подчиняться простым параметрическим моделям, таким как Гауссово или логарифмически-нормальным распределениям. Но часто оказывается полезно сравнивать распределения откликов баннеров разных рекламных компаний, чтобы, например, выбрать одну из них с лучшим средним откликом баннеров. MWU позволяет решить эту задачу.
При заданной таблице T со столбцами SAMPLE ID, VALUE получаются номера строк, и они суммируются посредством оконных функций SQL.
CREATE VIEW R AS SELECT sample_id, avg(value) AS sample_avg sum(rown) AS rank_sum, count(*) AS sample_n, sum(rown) - count(*) * (count(*) + 1) AS sample_us FROM (SELECT sample_id, row_number() OVER (ORDER BY value DESC) AS rown, value FROM T) AS ordered GROUP BY sample_id
Если размеры образцов достаточно велики, например, больше 5000, можно принять аппроксимацию нормальным распределением. Используя ранее определенное представление R, заключительный этап вычисления статистических данных можно выразить на SQL следующим образом:
SELECT r.sample_u, r.sample_avg, r.sample_n (r.sample_u - a.sum_u / 2) / sqrt(a.sum_u * (a.sum_n + 1) / 12) AS z_score FROM R as r, (SELECT sum(sample_u) AS sum_u, sum(sample_n) AS sum_n FROM R) AS a GROUP BY r.sample_u, r.sample_avg, r.sample_n, a.sum_n, a.sum_u
Окончательный результат представляет собой набор чисел, описывающих связи между функциями. Эту простую программу можно инкапсулировать хранимыми процедурами и сделать ее доступной аналитикам путем простого вызова SELECT mann whitney(value) FROM table, что чрезвычайно способствует развитию словаря базы данных.
Векторы и матрицы
Реляционные базы данных разрабатываются в расчете на масштабирование при росте объема данных. Здесь описывается, как мы представляем крупные "векторные" и "матричные" объекты в виде отношений и реализуем над ними логические операции. Это дает нам векторную арифметику.
До построение операций нам нужно определить, что означает "вектор" (часто в форме матрицы) в контексте базы данных. Имеется много способов разделения таких матриц ("блоками", "порциями" ("chunk")) по узлам параллельной системы (см., например, , гл. 4). Простой способ, хорошо подходящий для параллельных баз данных, состоит в представлении матрицы в виде отношения со схемой (row number integer, vector numeric[]) и разрешении СУБД разделять строки между процессорами произвольным образом – например, на основе хэширования или циклической схемы. На практике мы часто материализуем и A, и A´, чтобы этот метод построчного представления работал более эффективно.
Для матриц, представляемых подобным образом в виде горизонтально разделенных отношений, нам нужно реализовать базовую матричную арифметику в виде запросов над этими отношениями, чтобы эти запросы могли выполняться параллельно.
Рассмотрим две матрицы A и B одной и той же размерности. На SQL легко выражается сложение матриц:
SELECT A.row_number, A.vector + B.vector FROM A, B WHERE A.row_number = B.row_number;
Заметим, что здесь операция "+" выполняется над массивами числовых типов и возвращает массив той же размерности, так что на выходе получается матрица той же размерености, что и у матриц-операндов. Если в СУБД не поддерживается операция сложения векторов, ее легко реализовать с использованием объектно-реляционных расширений и зарегистрировать как инфиксную операцию . Для выполнения этого запроса оптимизатор запросов, вероятно, выберет метод соединения с хэшированием, который хорошо распараллеливается.
Умножение матрицы на вектор Av также выражается просто:
SELECT 1, array_accum(row_number, vector*v) FROM A;
Здесь снова операция "*" выполняется над массивами числовых значений, но в этом случае она возвращает одно числовое значение – скалярное произведение операндов:

В большинстве РСУБД имеются функции над последовательностями. В PostgreSQL и Greenplum команда generate series(1, 50) сгенерирует последовательность 1, 2, ..., 50. Один из способов вычисления транспонированной матрицы A´ для матрицы A размерности m×n можно выразить на SQL следующим образом (для n = 3):
SELECT S.col_number, array_accum(A.row_number, A.vector[S.col_number]) FROM A, generate_series(1,3) AS S(col_number) GROUP BY S.col_number;
К сожалению, если A хранит n-мерные вектора, то в операции группирования будут участвовать n копий таблицы A. Альтернативой является переход к другому представлению матриц, например, к разреженному представлеению вида (row number, column number, value). Преимущество такого подхода состоит в том, что в этом случае на SQL гораздо легче выразить операцию перемножения матриц AB:
SELECT A.row_number, B.column_number, SUM(A.value * B.value) FROM A, B WHERE A.column_number = B.row_number GROUP BY A.row_number, B.column_number
Этот запрос очень эффективно выполняется над разреженными матрицами, если в них не сохраняются нулевые значения. Вообще говоря, хорошо известно, что никакое одно представление не удовлетворяет все потребности, и на практике приходится использовать смеси. При отсутствии должной абстракции это может привести к путанице, посколько для каждого представления нужно определять специальные операции.
В SQL разные представления можно получить за счет соглашений об именовании (материализованных) производных таблиц, но выбор такой таблицы обычно производится аналитиком, поскольку традиционный оптимизатор запросов не знает об эквивалентности этих производных таблиц. Результаты исследования в этом направлении описаны в литературе по параллельным вычислениям , но их еще требуется интегрировать с механизмами оптимизации запросов и поддержки вычислений над данными большого объема.
Приведенные рассуждения применимы к операциям скалярного умножения, сложения векторов и умножения векторов/матриц, которые по своей сути являются однопроходными методами. Задача деления матриц в параллельно контексте не решена окончательным образом. Одно из неудобств SQL состоит в отсутствии удобного синтаксиса для организации итераций. Фундаментальные методы вычисления обратной матрицы предполагают два или большее число проходов по данным. Однако рекурсивные или итеративные процедуры могут выполняться во внешних процессах с минимальным объемом потока данных с основного узла. Например, в методе сопряженных градиентов, описываемом в п. 5.2.2, между итерациями запрашивается всего одно значение. Хотя деление матриц усложнено, мы можем разработать оставшуюся часть методов, описываемых в этой статье, на основе процедур псевдоинверсии (с учетом предупреждений, приводимых в учебниках по математики по поводу существования и сходимости).
Обширный набор (теперь распределенных) векторных объектов и операций над ними образует существительные и глаголы математических статистиков. В этом смысле функции действуют как высказывания. Мы продолжим рассмотрением знакомого примера, выраженного на этом языке.
Вклад авторов
В этой статье описываются методы и навыки, полученные при разработке средств МОГучей аналитики для компании Fox Audience Network с использованием крупной установки системы Greenplum Database. Мы обсуждаем свою методологию проектирования баз данных, которая ориентирована на обеспечение гибкого, но, вместе с тем, организованного подхода к анализу данных (разд. 4). Мы представляем ряд параллельных по данным статистических алгоритмов, разработанных для этой среды, которые фокусируются на моделировании и сравнении плотностей распределений. К их числу относятся специальные методы, такие как обычный метод наименьших квадратов (Ordinary Least Squares), метод слпряженных градиентов (Conjugate Gradiant) и метод, основанный на U-критерии Манна-Уитни (Mann-Whitney U Testing), а также методы общего назначения, такие как метод перемножения матриц (matrix multiplication) и метод раскрутки (Bootstrapping) (разд. 5). Наконец, мы размышляем о важных средствах систем баз данных, делающих возможными быструю и гибкую разработку алгоритмов, включая высокопроизводительное включение/извлечение данных (data ingress/egress), хранение неоднородных данных, а также гибкое программирование с использованием расширяемых интерфейсов SQL и MapReduce к единой системе (разд. 6).
Наше обсуждение бросает вызов многим общепринятым положениям. В области проектирования и анализа хранилищ данных мы отстаиваем тезис "Меньше моделируйте, больше итерируйте" (Model Less, Iterate More). Этот тезис противоречит позиции ортодоксов хранилищ данных, и его смысл означает передачу всей полноты власти от администраторов баз данных аналитикам. Мы говорим о потребности в однородных системах, поддерживающих и интегрирующих разнообразные стили программирования с большими объемами данных, поскольку аналитики происходят из многих разных профессиональных сообществ. Это означает отказ от религиозных дебатов относительно преимуществ SQL над MapReduce или R над Java с целью сосредоточиться на развитии единого параллельного механизма обработки потоков данных, который может поддерживать различные стили программирования средств нетривиальной аналитики. Наконец, мы утверждаем, что этот параллельный механизм обработки потоков данных может и должен объединять много источников данных и форматов хранения. Это направлено на более гладкую интеграцию или консолидацию традиционно разрозненных инструментальных средств, включая традиционные реляционные базы данных, поколоночные системы хранения, средства ETL и распределенные файловые системы.
Если вы подыскиваете род деятельности,
Если вы подыскиваете род деятельности, в котором ваши усилия будут высоко востребованы, вам следует найти область, в которой вы сможете обеспечить дефицитные дополнительные услуги по отношению к тому, что повсеместно распространено и дешево обходится. А что повсеместно распространо и дешево обходится? Данные. А что является дополнительной услугой по отношению к данным? Анализ.
– Профессор Хал Вариан, университет Беркли, главный экономист Google
mad (прил.): прилагательное, используемое для усиления смысла существительного.
1- dude, you got skills (чувак, ты кое-что можешь).
2- dude, you got mad skills (чувак, ты могуч).
– UrbanDictionary.com
Стандартная бизнес-практика крупномасштабного анализа данных опирается на понятие "корпоративного хранилища данных" (Enterprise DataWarehouse, EDW), запросы к которому поступают из программного обеспечения "бизнес-аналитики" (Business Intelligence, BI). Инструментальные средства BI позволяют создавать отчеты и интерактивные интерфейсы, обобщающие данные на основе применения агрегатных функций (вычисляющих, например, количество или среднее значение) к различным иерархическим разбиениям данных на группы. В 1990-е гг. это являлось темой значительных академических исследований и производственных разработок.
Традиционно считается, что тщательно спроектированное EDW играет центральную роль при правильном применении IT. Проектирование и эволюция детальной схемы EDW служит общим принципом дисциплинированной интеграции данных крупных предприятий, совершенствуя результаты и представления всех бизнес-процессов. Результирующая база данных играет роль репозитория характеристик критических бизнес-функций. Кроме того, сервер баз данных, сохраняющий EDW, традиционно является основным вычислительным средством, служащим центральным, масштабируемым механизмом ключевой корпоративной аналитики. Концептуальное и вычислительное центральное положение EDW делает его критически важным дорогостоящим ресурсом, используемым для производства отчетов над большим количеством данных, и эти отчеты ориентируются на руководящих лиц, принимающих решения.
EDW традиционно контролируется специально назначаемыми сотрудниками IT, которые не только сопровождают систему, но и тщательно контролируют доступ к ней, чтобы руководящие лица могли гарантированно расчитывать на высокий уровень обслуживания.
Хотя во многих ситуациях этот ортодоксальный подход EWD продолжает применяться, ряд факторов способствует продвижению совсем другой философии управления крупномасштабными данными на предприятиях. Во-первых, хранение данных теперь обходится настолько дешево, что небольшие подгруппы предприятия могут разработать изолированную базу данных астрономического масштаба в пределах своего собственного бюджета. Наиболее крупное хранилище данных всего лишь десятилетней давности можно было бы теперь сохранить на менее чем 20 дисках стоимостью менее 100 долларов. Отдельный департамент может сам заплатить за систему хранения данных объемнее на 1-2 порядка без согласования этого с руководством. Тем временем, число внутрикорпоративных крупномасштабных источников данных значительно возрастает: крупные базы данных сегодня возникают даже на основе единственного источника потоков данных о посещении Web-сайтов (click-stream), журналов программных систем, архивов электронной почты и дискуссионных форумов и т.д. Наконец, общепризнанной стала значимость анализа данных, и многочисленные компании демонстрируют, что сложный анализ данных способствует сокращению расходов и даже прямому росту доходов. Результатом этих возможностей является массовый переход к сбору и использованию данных в нескольких оранизационных единицах корпораций. Преимущество этого перехода состоит в том, что он содействует повышению эффективности и росту культуры использования данными, но он усиливает децентрализацию данных, с которой призвано бороться хранилище данных.
В этом изменяющемся климате сбора разрозненных крупномасштабных данных целесообразен подход, который мы называемым МОГучим анализом данных (MAD analisys). Акроним MAD происходит от трех аспектов этой среды, отличающих ее от ортодоксальных EDW:
Магнетичность (magnetic): Подходы к организации традиционных EDW предполагают "отталкивание" новых источников данных, т.е. данные из нового источника не включаются в EDW, пока они не будут очищены и интегрированы. С учетом повсеместности данных в современных организациях сегодняшнее хранилище данных может идти в ногу с аналитическими потребностями организации, только будучи "притягательным" ("магнетичным"), притягивая все источники данных, появляющиеся в организации, независимо от их качества.
Гибкость (agile): Традиционные хранилища данных основываются на долгосрочном тщательном проектировании и планировании. С учетом роста числа источников данных и потребности во все более сложном и критически важном анализе данных современное хранилище данных должно вместо этого позволять аналитикам простым образом воспринимать, классифицировать, производить и перерабатывать данные в быстром темпе. Для этого требуется база данных, логическое и физическое содержимое которой может постоянно и быстро изменяться.
Основательность (deep): В современном анализе данных используются все более сложные статистические методы, далеко выходящие за пределы обобщения (rollup) и детализации (drilldown) традиционных методов BI. Кроме того, при выполнении этих алгоритмов аналитикам часто требуется одновременно видеть и лес целиком, и отдельные деревья – им нужно исследовать огромные наборы данных, не прибегая к использованию образцов и выборок. Современное хранилище данных должно служить и основательным (глубоким) репозиторием данных, и механизмом поддержки выполнения сложных алгоритмов.
Как отмечал Вариан, имеется возрастающая потребность в МОГучих аналитиках данных. Часто они являются высоквалифицированными статистиками, обладающими хорошими знаниями в области программного обеспечения, но обычно фокусирующимися на основательном анализе данных, а не на управлении базами данных. Для поддержки их деятельности требуется применять подход MAD к проектированию хранилища данных и созданию инфраструктуры систем баз данных.При достижении этих целей возникают интересные проблемы, отличающиеся от тех, на решении которых традиционно сосредатачивается исследовательское сообщество и индустрия хранилищ данных.
Загрузка и выгрузка
Важность высокоскоростной загрузки и выгрузки данных для крупных параллельных СУБД подчеркивалась более десяти лет тому назад , и сегодня эти аспекты еще более важны. Аналитики часто загружают новые данные, и нередко им нравится "размазывать" наборы данных между системами (например, между СУБД и кластером Hadoop) для решения конкретных задач. Поскольку аналитики очищают данные и повышают их качество, а также используют их в процессах разработки аналитических методов, эти данные часто применяются при решении разных задач. Если время загрузки данных измеряется в днях, поток работ аналитиков качественно меняется. Задержки такого рода отталкивают данные от хранилища данных.
Кроме обеспечения быстрой загрузки данных в базу данных, СУБД, хорошо подходящая для MAD-аналитики, должна позволять пользователям базы данных выполнять запросы прямо над внешними таблицами: строки подаются из файлов или от сервисов, к которым происходит доступ по требованию во время обработки запросов. За счет непосредственного и параллельного доступа к внешним данным правильно организованная СУБД может устранить накладные расходы на загрузку данных и поддержку их актуального состояния. Внешние таблицы ("обертки", "wrapper") обычно обсуждаются в контексте интеграции данных . Но в контексте МОГучего хранилища данных главным является массивно-параллельный доступ к файловым данным, располагающимся в локальной высокоскоростной сети.
В Greenplum полностью параллельный доступ при загрузке данных и обработке запросов над внешними таблицами реализуется на основе метода потоковой передачи данных с их рассеиванием и сбором (Scatter/Gather Streaming). Эта идея напоминает идею внутренней организации традиционных баз данных без общих ресурсов (sharing-nothing) , но в данном случае требуется координация с внешними процессами, чтобы параллельно "подпитывать" данными все узлы СУБД. Когда в систему поступает поток данных, эти данные могут размещаться в таблицах базы данных для последующего доступа или использоваться непосредственно как данные внешней таблицы с параллельным вводом-выводом. При использовании этой технологии заказчики Greenplum достигают скорости загрузки полностью зеркалируемой производственной базы данных в четыре терабайта в час при незначительном влиянии на операции, одновременно выполняемые над той же базой данных.
