Файлы с точки зрения пользователя
Прежде, чем рассматривать структуры файловых систем, давайте сначал выясним, какие же операции над файлами и их именами обычно предоставляются. По аналогии с адресным пространством, иногда употребляют термин пространство имен, характеризующее совокупность всех допустимых имен файлов. Структура пространства имен зависит как от операционной так и от файловой системы. Структура каталогов ФС накладывает ограничения на длину имен файлов и символы, которые могут употребляться в именах. ОС может устанавливать собственное ограничение на длину имени файла.Как правило, ограничения на длину имени на уровне ОС обусловлены требованием совместимости со старым программным обеспечением: если в спецификациях системных вызовов сказано, что имя файла не может содержать более 12 символов, разработчики программного обеспечения будут выделять под буфер для хранения имени файла именно столько места. Такая программа без перекомпиляции не сможет работать с именами файлов большей длины и с каталогами, содержащими такие имена.
Монтирование файловых систем
Прежде чем ОС сможет использовать файловую систему, она должна выполнить над этой системой операцию, называемую монтированием (mount). В общем случае операция монтирования включает следующие шаги. Проверку типа монтируемой ФС. Проверку целостности ФС. Считывание системных структур данных и инициализацию соответствующего модуля файлового менеджера (драйвера файловой системы). В некоторых случаях — модификацию ФС с тем, чтобы указать, что она уже смонтирована. При этом устанавливается так называемый флаг загрязнения (dirty flag). Смысл этой операции будет объяснен и разд.Формат имен файлов
В различных ФС допустимое имя файла может иметь различную
длину ц нем могут использоваться различные наборы символов. Так, в RT-H
и RSX-Ц имена файлов состоят из символов кодировки RADIX-50 и имеют длину
9 символов: 6 символов — собственно имя, а 3 — расширение. При этом имя
имеет вид "ХХХХХХ.ХХХ", но символ '.' не является частью имени
— это просто знак препинания. Предполагается, что расширение должно соответствовать
типу данных, хранящихся в файле: SAV будет именем абсолютного загружаемого
модуля, FOR — программы на Фортране, CRH - "файлом информации о системном
крахе", как было написано в одном переволе руководства (попросту
говоря, это посмертная выдача ОС, по которой можно попытаться понять причину
аварии).
В СР/М и ее потомках MS DOS-DR DOS, а также в VMS имена файлов хранятся
в 8-битной ASCII-кодировке, но почему-то разрешено использование только
букв верхнего регистра, цифр и некоторых печатаемых символов. При этом
в системах линии СР/М имя файла имеет 8 символов плюс 3 символа расширения,
а в VMS как имя, так и расширение могут содержать более 32 символов. Все
перечисленные системы используют нечувствительный к регистру букв поиск
в каталогах: имена file.с, File.С и FILE.С считаются одним и тем же именем.
Ограничения на формат имени в MS DOS
Любопытно, что MS/DR DOS при поиске в каталоге переводят в верхний регистр
имя, заданное пользователем, но оставляют без изменений имя, считанное
из каталога. Строго говоря, это ошибка: если мы создадим имя файла, содержащее
буквы нижнего регистра, то ни одна программа не сможет открыть или переименовать
такой файл.
Автору довелось столкнуться с такой проблемой при попытке прочитать дискету,
записанную ОС ТС (Экспериментальная UNIX-подобная ОС для Паскаль-машины
N9000). Проблему удалось решить только при помощи шестнадца-теричного
дискового редактора прямым редактированием имен в каталогах. Возможно,
существует и более элегантное решение, но автору не удалось его найти.
Использовать конструкцию *.* бесполезно, потому что, в действительности,
операции над файлами, заданными таким образом, состоят из двух операций:
FindFirst/FindNext, которая возвращает [следующее] имя файла, соответствующее
шаблону, и Open. FindFirst/FindNext возвращает недопустимое имя файла
и Open не может использовать его. Программа CHKDSK не возражает против
имен файлов в нижнем регистре. Строго говоря, это тоже ошибка. Все остальные
способы, так или иначе, сводятся к прямой (в обход ДОС) модификации ФС.
Кроме того, любопытных эффектов можно достичь, попытавшись создать файл
с именем, содержащим русские буквы.
Наибольшим либерализмом в смысле имен отличаются ОС семейства Unix, в
которых имя файла может состоять из любых символов кодировки ASCII, кроме
символов '\000' и V, например, из восьми символов перевода каретки. При
этом '\000' является ограничителем имени, а V — разделителем между именем
каталога и именем файла. Никакого разделения на имя и расширение нет,
и хотя имена файлов с программой на языке С заканчиваются ".с",
а объектных модулей — ".о", точка здесь является частью имени.
Вы можете создать файл с именем "gcc-2.5.8.tar.gz". В UNIX SVR3
длина имени файла ограничена 14 символами, а в BSD UNIX, Linux и SVR4—
только длиной блока на диске, т. е. 512 байтами или более. При этом нулевой
символ считается концом имени в каталоге.
Возможность использовать в именах неалфавитные символы типа перевода каретки или ASCII EOT (End Of Transmission) кажется опасным излишеством. На самом деле:
это не излишество а, скорее, упрощение — из процедур, работающих с именами, удалена проверка символа на "допустимость"; оно не столь уж опасно: такой файл всегда можно переименовать.В некоторых случаях процесс набора имени файла в командной строке превращается в нетривиальное упражнение, потому что shell (командный процессор) рассматривает многие неалфавитные символы как команды. Но надо отметить, что, правильно используя кавычки и символ '\', пользователь может передать команде аргумент, содержащий любые символы ASCII, кроме \000".
Длинные имена файлов в ОС семейства
СР/М
В последнее время в ОС стало модным поддерживать длинные имена файлов.
Отчасти это, возможно, связано с тем, что производители ПО для персональных
компьютеров осознали, что системы семейства Unix являются потенциально
опасными конкурентами, а длинные имена файлов традиционно считаются одним
из преимуществ этого семейства.
Например, OS/2, использующая файловую систему HPFS (High Performance File
System — высокопроизводительная файловая система), поддерживает имена
файлов длиной до 256 символов, содержащие печатаемые символы и пробелы.
Точка считается частью имени, как и в UNIX, и можно создавать имена, содержащие
несколько точек. Аналогичную структуру имеют имена в NTFS, используемой
в Windows NT/2000/XP, VFAT (реализация файловой системы FAT16, используемая
в Windows 95/98/ME) и FAT32.
Описанные ОС при поиске файла приводят к одному регистру
все алфавитные символы в имени. С одной стороны, это означает дополнительное
Удобство для пользователя — при наборе имени не нужно заботиться о регистре
букв, с другой — пользователь не может создать в одном каталоге файлы
"text.txt" и "Text.txt". Из-за этого, например, нельзя
использовать принятое в UNIX соглашение о том, что файл на языке С имеет
расширение "с", а на языке C++ — "С".
Главная же проблема, возникающая при работе с нечувствительными « п гистру
именами, — это преобразование регистра в именах, использующи национальные
алфавиты: русский, греческий, японскую слоговую азбуку т. д. Файловая
система, поддерживающая такие имена, должна учитыват языковые настройки
ОС, что создает много сложностей, в том числе и при считывании удаляемых
носителей, записанных в одной стране, где-нибудь за границей. В системах
семейства Win32 эта проблема решена за счет хранения имен в формате Unicode.
Некоторые ОС, например, RSX-11 и VMS, поддерживают также номер версии
файла. В каталоге может существовать несколько версий файла с одним именем;
если номер версии при открытии файла не задается, то открывается последняя
версия.
Версии файла очень удобны при разработке любых объектов, от программ или
печатных плат до книг: если вам не понравились изменения, внесенные вами
в последнюю версию, вы всегда можете откатиться назад. Ныне функцию хранения
предыдущих версий изменяемых файлов и управляемого отката к ним реализуют
специальные приложения, системы управления версиями
(version control system) (RCS, CVS и др.).
Операции над файлами
Большинство современных ОС рассматривают файл как неструктурированную последовательность байтов переменной длины. В стандарте POSIX над файлом определены следующие операции.
int open(char * fname, int flags, mode_t mode)Эта операция "открывает" файл, устанавливая соединение между программой и файлом. При этом программа получает "ручку" или дескриптор файла — целое число, идентифицирующее данное соединение. Фактически это индекс в системной таблице открытых файлов для данной задачи. Все остальные операции используют этот индекс для ссылки на файл. Параметр char * fname задает имя файла, int flags — это битовая маска, определяющая режим открытия файла. Файл может быть открыт только для чтения, только для записи и для чтения и записи; кроме того, можно открывать существующий файл, а можно пытаться создать новым файл нулевой длины. Необязательный третий параметр mode используется только при создании файла и задает атрибуты этого файла. off_t lseek(int handle, off_t offset., int whence)
Эта операция перемещает указатель чтения/записи в файле. Параметр offset задает количество байтов, на которое нужно сместить указатель, а параметр whence — начало отсчета смещения. Предполагается, что смещение можно отсчитывать от начала файла (SEEK_SET), от его кониа (SEEK_END) и от текущего положения указателя (SEEK_CUR). Операция возвращает положение указателя, отсчитываемое от начала файла. Таким образом, вызов iseek (handle, о, SEEK_cuR) возвратит текущее положение указателя, не передвигая его. int read(int handle, char * where, size__t howjnuch)
Операция чтения из файла. Указатель where задает буфер, куда нужно поместить прочитанные данные; третий параметр указывает, сколько данных надо считать. Система считывает требуемое число байтов из файла, начиная с указателя чтения/записи в этом файле, и перемещает указатель к концу считанной последовательности. Если файл кончился раньше, считывается столько данных, сколько оставалось до его конца. Операция возвращает количество считанных байтов. Если файл открывался только для записи, вызов read возвратит ошибку. int write(int handle, char * what, size__t how_much)
Операция записи в файл. Указатель what задает начало буфера данных; третий параметр указывает, сколько данных надо записать. Система записывает требуемое число байтов в файл, начиная с указателя чтения/записи в этом файле, заменяя хранившиеся в этом месте данные, и перемещает указатель к концу записанного блока. Если файл кончился раньше, его длина увеличивается. Операция возвращает количество записанных байтов. Если файл открывался только для чтения, вызов write возвратит ошибку. int ioctl ( int handle, int cmd, .. . .)
int fcntl(int handle, int cmd, . . . )
Дополнительные операции над файлом. Первоначально, по-видимому, предполагалось, что ioctl — это операции над самим файлом, a fcntl — это операции над дескриптором открытого файла, но потом историческое развитие несколько перемешало функции этих системных вызовов. Стандарт POS1X определяет некоторые операции как над дескриптором, например дублирование (в результате этой операции мы получаем два дескриптора, связанных с одним и тем же файлом), так и над самим файлом, например, операцию truncate — обрезать файл до заданной длины. В большинстве версий Unix операцию truncate можно использовать и для вырезания данных из середины файла. При считывании данных из такой вырезанной области считываются нули, а сама эта область не занимает физического места на диске.
Важной операцией является блокировка участков файла. Стандарт POSIX
предлагает для этой цели библиотечную функцию, но в системах семейства
Unix эта функция реализована через вызов fcntl.
Большинство реализаций стандарта POSIX предлагает и свои дополнительные
операции. Так, в Unix SVR4 этими операциями можно устанавливать
синхронную или отложенную запись (Подробнее понятие отложены записи обсуждается
в разд. Асинхронная модель ввода-вывода
с точки зрения приложений) и т. д.
Отображение участка файла в виртуальное адресное пространство процесса. Параметр prot задает права доступа к отображенному участку: на чтение, запись и исполнение. Отображение может происходить на заданный виртуальный адрес, или же система может выбирать адрес для отображения сама.
Еще две операции выполняются уже не над файлом, а над его именем: это операции переименования и удаления файла. В некоторых системах, например в системах семейства Unix, файл может иметь несколько имен, и существует только системный вызов для удаления имени. Файл удаляется при удалении последнего имени.
Видно, что набор операций над файлом в этом стандарте очень похож на
набор операций над внешним устройством. И то, и другое рассматривается
как неструктурированный поток байтов. Для полноты картины следует сказать,
что основное средство межпроцессной коммуникации в системах семейства
Unix (труба) также представляет собой неструктурированный поток данных.
Идея о том, что большинство актов передачи данных может быть сведено к
байтовому потоку, довольно стара, но Unix была одной из первых систем,
где эта идея была приближена к логическому завершению.
Примерно та же модель работы с файлами принята в СР/М, а набор файловых
системных' вызовов MS DOS фактически скопирован с вызовов Unix v7. В свою
очередь, OS/2 и Windows NT/2000/XP унаследовали принципы работы с файлами
непосредственно от MS DOS.
В системах, не имеющих Unix в родословной, может использоваться несколько
иная трактовка понятия файла. Чаще всего файл трактуется как набор записей
(рис. 11.4). Обычно система поддерживает записи как постоянной длины,
так и переменной. Например, текстовый файл интерпретируется
как файл с записями переменной длины, а каждой строке текста соответствует
одна запись. Такова модель работы с файлами в VMS и в ОС линии OS/360-MVS-z/OS
фирмы IBM.
Практика систем с неструктурированными файлами показала, что, хотя структурированные
файлы часто бывают удобны для программиста, необязательно встраивать поддержку
записей в ядро системы. Это вполне можно сделать и на уровне библиотек.
К тому же структурированные файлы сами по себе не решают серьезной проблемы,
полностью осознанной лишь в 80-е годы при разработке новых моделей взаимодействия
человека с компьютером.

Рис. 11.4. Неструктурированный файл и файлы как наборы
записей
Простые файловые системы
Наиболее простой файловой системой можно считать структуру, создаваемую архиватором системы UNIX — программой tar (Tape ARchive — архив на [магнитной] ленте). Этот архиватор просто пишет файлы один за другим помещая в начале каждого файла заголовок с его именем и длиной (рис. 11.5). Аналогичную структуру имеют файлы, создаваемые архиваторами типа arj; в отличие от них, tar не упаковывает файлы.
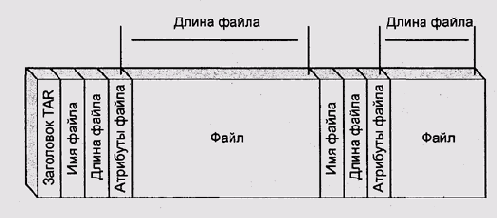
Рис. 11.5. Структура архива tar
Для поиска какого-то определенного файла вы должны прочитать первый
заголовок; если это не тот файл, то отмотать ленту до его конца, прочитать
новый заголовок и т. д. Это не очень удобно, если мы часто обращаемся
к отдельным файлам, особенно учитывая то, что цикл перемотка — считывание
— перемотка у большинства лентопротяжных устройств происходит намного
медленнее, чем простая перемотка. Изменение же длины файла в середине
архива или его стирание вообще превращается в целую эпопею. Поэтому tar
используется для того чтобы собрать файлы с диска в некую единую сущность,
например, для передачи по сети или для резервного копирования, а для работы
файлы обычно распаковываются на диск или другое устройство с произвольным
доступом.
Для того чтобы не заниматься при каждом новом поиске просмотром всего
устройства, удобнее всего разместить каталог в определенном месте, например
в начале ленты. Наиболее простую, из знакомых автору, файловую систему
такого типа имеет ОС RT-11. Это единственная известная автору файловая
система, которая с одинаковым успехом применялась как на лентах, так и
на устройствах с произвольным доступом. Все более сложные ФС, обсуждаемые
далее, используются только на устройствах произвольного доступа. В наше
время наиболее распространенный тип запоминающего устройства произвольного
доступа — это магнитный или оптический диск, поэтому далее в тексте мы
будем называть такие устройства просто дисками — для краткости, хотя такое
сокращение и не вполне корректно.
В этой ФС, как и во всех обсуждаемых далее, место на диске или ленте выделяется
блоками. Размер блока, как правило, совпадает с аппаратным размером сектора
(512 байт у большинства дисковых устройств), однако многие фС могут использовать
логические блоки, состоящие из нескольких секторов (так называемые кластеры).
Использование блоков и кластеров вместо адресации с точностью до байта
обусловлено двумя причинами. Во-первых, у большинства устройств произвольного
доступа доступ произволен лишь с точностью до сектора, т. е. нельзя произвольно
считать или записать любой байт — нужно считывать или записывать весь
сектор целиком. Именно поэтому в системах семейства Unix такие устройства
называются блочными (block-oriented).
Во-вторых, использование крупных адресуемых единиц позволяет резко увеличить
адресуемое пространство. Так, используя 16-битный указатель, с точностью
до байта можно адресовать всего 64 Кбайт, но если в качестве единицы адресации
взять 512-байтовый блок, то объем адресуемых данных сможет достичь 32
Мбайт; если же использовать кластер размером 32 Кбайт, то можно работать
с данными объемом до 2 Гбайт. Аналогично, 32-битовый указатель позволяет
адресовать с точностью до байта 4 Гбайт данных, т. е. меньше, чем типичный
современный жесткий диск; но если перейти к адресации по блокам, то адресное
пространство вырастет до 2 Тбайт, что уже вполне приемлемо для большинства
современных запоминающих устройств.
Таким образом, адресация блоками и кластерами позволяет использовать в
системных структурах данных короткие указатели, что приводит к уменьшению
объема этих структур и к снижению накладных расходов. Под накладными расходами
в данном случае подразумевается не только освобождение дискового пространства,
но и ускорение доступа: структуры меньшего размера быстрее считываются,
в них быстрее производится поиск и т. д. Однако увеличение объема кластера
имеет оборотную сторону — оно приводит к внутренней фрагментации (см.
разд. Алгоритмы динамического управления
памятью).
Ряд современных файловых систем использует механизм, по-английски называемый
block siiballocation, т. е. размещение частей
блоков. В этих ФС кластеры имеют большой размер, но есть возможность разделить
кластер на несколько блоков меньшего размера и записать в эти блоки "хвосты"
от нескольких разных файлов (рис. 11.6). Это, безусловно, усложняет ФС,
но позволяет одновременно использовать преимущества, свойственные и большим,
и маленьким блокам. Поэтому ряд распространенных ФС, например файловая
система Novell Netware 4.1 и FFS (известная также как UFS и Berkley FS),
используемая во многих системах семейства Unix, применяе этот механизм.

Рис. 11.6. Субаллокация блоков
Субаллокация требует от файловой системы
поддержания запаса свободных блоков на случай, если пользователю потребуется
увеличить длину одного из файлов, "хвост" которого был упакован
во фрагментированный блок. Учебные пособия по Netware рекомендуют поддерживать
на томах с субаллокацией не менее тысячи свободных кластеров, но не предоставляют
штатных методов обеспечения этого требования. Напротив, UFS показывает
свободное место на диске с учетом "неприкосновенного" резерва
свободного пространства, так что нулевое показываемое свободное пространство
соответствует 5% или 10% физического свободного места. Объем этого резерва
настраивается утилитами конфигурации ФС.
Но вернемся к простым файловым системам. В RT-11 каждому файлу выделяется
непрерывная область на диске. Благодаря этому в каталоге достаточно хранить
адрес первого блока файла и его длину, также измеренную в блоках. В RT-11
поступили еще проще: порядок записей в каталоге совпадает с порядком файлов
на диске, и началом файла считается окончание предыдущего файла. Свободным
участкам диска тоже соответствует запись в каталоге (рис. 11.7). При создании
файла система ищет первый свободный участок подходящего размера.
Фактически эта структура отличается от формата tar только тем, что каталог
вынесен в начало диска, и существует понятие свободного участка внутри
области данных. Эта простая организация имеет очень серьезные недостатки.

Рис. 11.7. Структура файловой системы RT-11

Рис. 11.8. Дефрагментация диска в RT-11
Для того чтобы решить обе эти проблемы, необходимо позволить файлам занимать
несмежные области диска. Наиболее простым решением было бь хранить в конце
каждого блока файла указатель на следующий, т. е. превра тить файл в связанный
список блоков (рис. 11.9). При этом, естественно в каждом блоке хранить
не 512 байт данных, а на 2 — 4 байта меньше. При строго последовательном
доступе к файлу такое решение было бы впотне приемлемым, но при попытках
реализовать произвольный доступ возникнут неудобства. Возможно, поэтому,
а может и по каким-то исторически сложившимся причинам такое решение не
используется ни в одной из известных автору ОС.

Рис. 11.9. Файл в виде односвязного списка блоков
Отчасти похожее решение было реализовано в MS DOS и DR DOS. Эти системы
создают на диске таблицу, называемую FAT (File
Allocation Table, таблица размещения файлов). В этой таблице каждому блоку,
предназначенному для хранения данных, соответствует 12-битовое значение.
Если блок свободен, то значение будет нулевым. Если же блок принадлежит
файлу, то значение равно адресу следующего блока этого файла. Если это
последний блок в файле, то значение — OxFFF (рис. 11.10). Существует также
специальный код для обозначения плохого (bad) блока, не читаемого из-за
дефекта физического носителя. В каталоге хранится номер первого блока
и длина файла, измеряемая в байтах.
Емкость диска при использовании 12-битовой FAT оказывается ограничена
4096 блоками (2 Мбайт), что приемлемо для дискет, но совершенно не годится
для жестких дисков и других устройств большой емкости. На таких устройствах
DOS использует FAT с 16-битовыми элементами. На еще больших (более 32
Мбайт) дисках DOS выделяет пространство не блоками. а кластерами из нескольких
блоков. Эта файловая система так и называется - FAT.
Она очень проста и имеет одно серьезное достоинство: врожденную устойчивость
к сбоям (fault tolerance), но об этом далее. В то же время у нее
есть и ряд серьезных недостатков.

Рис. 11.10. Структура файловой системы FAT
Первый недостаток состоит в том, что при каждой операции над файлами
система должна обращаться к FAT. Это приводит к частым перемещениям головок
дисковода и в результате к резкому снижению производительности. Действительно,
исполнение программы arj на одной и той же машине под MS DOS и под DOS-эмулятором
систем Unix или OS/2 различается по скорости почти в 1,5 раза. Особенно
это заметно при архивировании больших каталогов.
Использование дисковых кэшей, а особенно помещение FAT в оперативную память,
существенно ускоряет работу, хотя обычно FAT кэшируется только для чтения
ради устойчивости к сбоям. При этом мы сталкиваемся со специфической проблемой:
чем больше диск, тем больше у него FAT, соответственно, тем больше нужно
памяти. У тома Novell Netware 3.12 размером 1,115 Гбайт с размером кластера
4 Кбайт размер FAT достигает мегабайта (легко понять, что Netware использует
FAT с 32-разрядными элементами. При 16-разрядном элементе FAT дисковый
том такого объема с таким размером кластера просто невозможен). При монтировании
такого тома Netware занимает под FAT и кэш каталогов около 6 Мбайт памяти.
Для сравнения, Netware 4 использует субаллокацию, поэтому можно относительно
безнаказанно увеличивать объем кластера и нет необходимости делать кластер
таким маленьким. Для дисков такого объема Netware 4 устанавливает размер
кластера 16 Кбайт, что приводит к уменьшению всех структур данных в 4
раза. Понятно, что для MS DOS, которая умеет адресовать всего 1 Мбайт
(1088 Кбайт, если разрешен НМА), хранить такой FAT в памяти целиком просто
невозможно.
Разработчики фирмы MicroSoft пошли другим путем: они ограничили разрядность
элемента FAT 16 битами. При этом размер таблицы не может превышать 128
Кбайт, что вполне терпимо. Зато вся файловая система может быть разбита
только на 64 Кбайт блоков. В старых версиях MS DOS это приводило к невозможности
создавать файловые системы размером 32 Мбайт.
В версиях старше 3.11 появилась возможность объединять блоки в кластеры
Например, на дисках размером от 32 до 64 Мбайт кластер будет состоять
из 2 блоков и иметь размер 1 Кбайт. На дисках размером 128—265 Мбайт кластер
будет уже размером 4 Кбайта и т. д.
Windows 95 использует защищенный режим процессора х86, поэтому адресное
пространство там гораздо больше одного мегабайта. Разработчики фирмы Microsoft
решили воспользоваться этим и реализовали версию FAT с 32-битовым элементом
таблицы — так называемый FAT32. Однако дисковый кэш Windows 95 не стремится
удержать весь FAT в памяти; вместо этого FAT кэшируется на общих основаниях,
наравне с пользовательскими данными. Поскольку работа с файлами большого
(больше одного кластера) объема требует прослеживания цепочки элементов
FAT, а соответствующие блоки таблицы могут не попадать в кэш, то производительность
резко падает. В сопроводительном файле Microsoft признает, что производительность
FAT32 на операциях последовательного чтения и записи может быть в полтора
раза ниже, чем у кэшированного FAT 16.
В заключение можно сказать, что при использовании FAT на больших дисках
мы вынуждены делать выбор между низкой производительностью, потребностями
в значительном объеме оперативной памяти или большим размером кластера,
который приводит к существенным потерям из-за внутренней фрагментации.
Для эффективного управления большими объемами данных необходимо что-то
более сложное, чем FAT.
"Сложные" файловые системы
Структуры "сложных" файловых систем отличаются большим разнообразием, однако можно выделить несколько общих принципов.Обычно файловая система начинается с заголовка, или, как это называется в системах семейства Unix, суперблока (superblock). Суперблок хранит информацию о размерах дискового тома, отведенного под ФС, указатели на начало системных структур данных и другую информацию, зависящую от типа ФС. Например, для статических структур может храниться их размер. Часто суперблок содержит также магическое число — идентификатор типа файловой системы. Аналог суперблока существует даже в FAT — это так называемая загрузочная запись (boot record).
Практически все современные ФС разделяют список свободных блоков и структуры, отслеживающие размещение файлов. Чаще всего вместо списка свободных блоков используется битовая карта, в которой каждому блоку соответствует один бит: занят/свободен. В свою очередь, список блоков для каждого файла обычно связан с описателем файла. На первый взгляд, эти описатели кажется естественным хранить в каталоге, но их, как правило, выносят в отдельные области, часто собранные в специальные области диска — таблицу инодов, метафайл и т. д. Такое решение уменьшает объем каталога и, соответственно, ускоряет поиск файла по имени. К тому же многие ФС сортируют записи в каталоге по имени файла, также с целью ускорения поиска. Понятно, что сортировка записей меньшего размера происходит быстрее.
В файловой системе HPFS, используемой в OS/2 и Windows NT, каждая запись в каталоге содержит имя файла и указатель vtajhode (файловую запись). Каталоги в этой ФС организованы в виде В-деревьев и отсортированы по именам файлов.
Файловая запись занимает один блок на диске и содержит список так называемых extent ("расширений") — (у этого термина нет приемлемого русского аналога. В переводах документации по OS/360 (ОС ЕС) так и писали: экстент.). Каждый экстент описывает непрерывную последовательность дисковых блоков, выделенных файлу. Он задает начальный блок такой последовательности и ее длину. Вместо списка свободных блоков используется битовая карта диска, в которой каждому блоку соответствует один бит: занят/свободен.
Нужно отметить, что идея экстентов далеко не нова: аншюгичная структура используется в некоторых версиях Unix с начала 80-х годов, а истоки этой идеи теряются в глубине 60-х.
Файловая запись обычно размещается перед началом первого экстента файла, хотя это и не обязательно. Она занимает один блок (512 байт) и может содержать до десяти описателей экстентов (рис. 11.11). Кроме того, она содержит информацию о времени создания файла, его имени и расширенных атрибутах (см. разд.
Устойчивость ФС к сбоям
Свойство устойчивости к сбоям питания (power-fault tolerance) является одной из важных характеристик файловой системы. Строго говоря, имеется в виду устойчивость не только к сбоям питания, но и к любой ситуации, при которой работа с ФС прекращается без выполнения операции размонтирования. Поэтому правильнее было бы говорить об устойчивости к любым сбоям системы, а не только питания.С другой стороны, если говорить просто об "устойчивости к сбоям", возникает неприятная двусмысленность. Под устойчивостью к сбоям можно понимать устойчивость к сбоям всей системы, например, к тем же сбоям питания, а можно понимать устойчивость к дефектам физического носителя, которые могут привести к потере части данных на диске. Вторая проблема обычно решается с помощью механизма горячей замены (логической переадресации) сбойных блоков, который обсуждается к разд.
Устойчивость к сбоям питания
На самом деле, неожиданное прекращение работы с ФС может произойти не только при сбое питания, но и в следующих ситуациях:
извлечении носителя из дисковода (подробнее об этом см. далее); нажатии кнопки RESET нетерпеливым пользователем; фатальном аппаратном сбое; аппаратном сбое, который сам по себе не был фатальным, но система не смогла правильно восстановиться, что привело к ее разрушению; разрушении системы из-за чисто программных проблем. На практике часто сложно провести границы между тремя последними типами
сбоев. В качестве примера можно привести проблему, описанную в разд. Обмен
данными с пользовательским процессом. В системах класса ДОС последняя
причина возникает очень часто, поэтому в таких системах можно использовать
только устойчивые сбоям ФС.
В системах класса ОС "спонтанные" зависания происходят намного
реже Система, зависающая по непонятным или неустранимым причинам раз в
несколько дней, считается малопригодной для серьезного использования а
делающая это раз в месяц — подозрительно ненадежной. Поэтому в таких системах
можно позволить себе роскошь использовать неустойчивые к сбоям ФС. Тем
более что такие системы, как правило, обладают более высокой производительностью,
чем устойчивые ФС.
К тому же перед выключением системы, интегрированной в сеть, необходимо
уведомить всех клиентов и все серверы о разъединении. Только чисто клиентская
машина может быть выключена из сети без проблем. Поэтому на сетевых серверах
в любом случае необходима процедура закрытия системы
(shutdown). Так почему бы не возложить на эту процедуру еще и функцию
размонтирования ФС?
В системах же реального времени, которые по роду работы могут часто и
неожиданно перезапускаться, например, при отладке драйверов или программ,
осуществляющих доступ к аппаратуре, стараются использовать устойчивые
к сбоям ФС.
Хотя первая из перечисленных выше причин — извлечение носителя из дисковода
— не является "сбоем" даже в самом широком смысле этого слова,
с точки зрения ФС она мало чем отличается от сбоя. Поэтому на удаляемых
носителях, таких, как дискеты, можно использовать только устойчивые ФС.
Интересный альтернативный подход используется в компьютерах Macintosh
и некоторых рабочих станциях. У этих машин дисковод не имеет кнопки для
извлечения дискеты. Выталкивание дискеты осуществляется программно, подачей
соответствующей команды дисководу. Перед подачей такой команды ОС может
выполнить нормальное размонтирование ФС на удаляемом диске.
В узком смысле слова "устойчивость" означает лишь то, что ФС
после аварийной перезагрузки не обязательно нуждается в восстановлении.
Такие ФС обеспечивают целостность собственных структур данных в случае
сбоя, но, вообще говоря, не гарантируют целостности пользовательских данных
в файлах.
Нужно отметить, что даже если ФС считается в этом смысле устойчивой, некоторые
сбои для нее могут быть опасны. Например, если запустить команду DISKOPT
на "устойчивой" файловой системе FAT и в подходящий момент нажать
кнопку RESET, то значительная часть данных
на диске может быть навсегда потеряна.
С другой стороны, можно говорить об устойчивости в том смысле, что в ФС
после сбоя гарантирована целостность пользовательских данных. Достаточно
простого анализа для того чтобы убедиться, что такую гарантию нельзя обеспечить
на уровне ФС; обеспечение подобной целостности накладывает серьезные ограничения
и на программы, работающие с данными, а иногда оказывается просто невозможным.
Характерный и очень простой пример: архиватор InfoZip работает над созданием
архива. Программа сформировала заголовок файла, упаковала и записала на
диск около 50% данных, и в этот момент произошел сбой. В zip-архивах каталог
находится в конце архивного файла и записывается туда после завершения
упаковки всех данных. Обрезанный в случайном месте zip-файл не содержит
каталога и поэтому, безусловно, является безнадежно испорченным. Поэтому
при серьезном обсуждении проблемы устойчивости к сбоям говорят не о гарантии
целостности пользовательских данных, а об уменьшении вероятности их порчи.
Поддержание целостности структур ФС обычно гораздо важнее, чем целостность
недописанных в момент сбоя пользовательских данных. Дело в том, что если
при сбое оказывается испорчен создававшийся файл, это достаточно неприятно;
если же окажется испорчена файловая система, в худшем случае это может
привести к потере всех данных на диске, т. е. к катастрофе. Поэтому обычно
обеспечению целостности ФС при сбоях уделяется гораздо больше внимания.
Упоминавшаяся выше "врожденная" устойчивость к сбоям файловой
системы FAT объясняется тем, что в этой ФС удаление блока из списка свободных
и выделение его файлу производится одним действием — модификацией элемента
FAT (рис. 11.16). Поэтому если во время этой процедуры произойдет сбой
или дискета будет вынута из дисковода, то ничего страшного не случится:
просто получится файл, которому выделено на один блок больше, чем его
длина, записанная в каталоге. При стирании этого файла все его блоки будут
помечены как свободные, поэтому вреда практически нет.
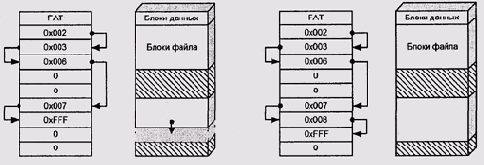
Рис. 11.16. Модификация FAT
Нужно отметить, что при активном использовании отложенной записи FAT
и родственные ФС теряют это преимущество. Отложенная запись FAT является
единственным способом добиться хоть сколько-нибудь приемлемой производительности
от ФС с 32-битовым FAT. Поэтому, хотя Novell NetWare и использует ФС,
основанную на 32-битной FAT, после аварийной перезагрузки эта система
вынуждена запускать программу аварийною становления дисковых томов. Аналогичным
образом ведет себя и FAT3? Если же система хранит в одном месте список
или карту свободных блоков, а в другом месте списки блоков, выделенных
каждому файлу (рис. 11.17) как это делают HPFS или ФС систем семейства
Unix, то при прерывании операции выделения места в неподходящий момент
могут либо теряться блоки (если мы сначала удаляем блок из списка свободных—
рис. 11.18) либо получаться блоки, которые одновременно считаются и свободными,
и занятыми (если мы сначала выделяем блок файлу).
Первая ситуация достаточно неприятна, вторая же просто недопустима: первый
же файл, созданный после перевызова системы, будет "перекрещиваться"
с испорченным (рис. 11.19). Поэтому все ОС, использующие файловые системы
такого типа (системы семейства Unix, OS/2, Windows NT и т. д.), после
аварийной перезагрузки первым делом проверяют своп ФС соответствующей
программой восстановления.

Рис. 11.17. Модификация структур данных сложной ФС

Рис. 11.18. Потерянный блок

Рис. 11.19. Пересекающиеся файлы
Задача обеспечения целостности файловых систем при сбоях усложняется
тем, что дисковые подсистемы практически всех современных ОС активно используют
отложенную запись, в том числе и при работе с системными структурами данных.
Отложенная запись, особенно в сочетании с сортировкой запросов по номеру
блока на диске, может приводить к тому, что изменения инода пли файловой
записи все-таки запишутся на диск раньше, чем изменения списка свободных
блоков, что может приводить к возникновению "скрещенных" файлов.
Для того чтобы этого не происходило, сортировке, как правило, подвергают
только запросы чтения, но не записи.
Восстановление ФС после сбоя
Чаще всего суперблок неустойчивых ФС содержит флаг
flirty ("грязный"), сигнализирующий о том, что ФС, возможно,
нуждается в восстановлении. Этот флаг сбрасывается при нормальном размонтировании
ФС и устанавливается при ее монтировании или при первой модификации после
монтирования. Таким образом, если ОС погибла, не успев размонтировать
свои дисковые тома, после перезагрузки на этих томах dirty-флаг будет
установлен, что и станет сигналом необходимости починки.
Восстановление состоит в том, что система проверяет пространство, выделенное
всем файлам. При этом должны выполняться следующие требования.
Практически все ФС при выделении блока сначала удаляют его из списка свободных и лишь потом отдают файлу, поэтому при "обычных" сбоях перекрещивание файлов возникнуть может только как следствие отложенной записи в сочетании с сортировкой запросов. Возникновение таких ошибок обычно сигнализирует либо об ошибке в самом файловом менеджере, либо об аппаратных сбоях на диске, либо о том, что структуры ФС были модифицированы в обход файлового менеджера. Например, в ДОС это может быть признаком вирусной активности.
3. Каждому файлу должно быть выделено пространство, соответствующее его длине. Если файлу выделено больше блоков, чем требуется, лишние блоки помечаются как свободные. Если меньше, файл укорачивается. Возможно, в укороченных файлах часть данных оказывается потеряна. 4. Все блоки, не принадлежащие файлам, должны быть помечены, как свободные. Соответствующий тип ошибок — потерянные блоки — наиболее частый результат системных сбоев как в файловой системе FAT, так и в более сложных файловых системах. Сами по себе ошибки этого типа относительно безобидны. Обычно программа восстановления не помечает потерянные блоки как свободные,
а выделяет из них непрерывные цепочки и создает из этих цепочек файлы.
Например, в OS/2 программа восстановления пытается найти в потерянных
блоках файловые записи, а потом создает ссылки на найденные таким образом
файлы в каталоге \FOUND.XXX. В DOS эти файлы помещаются в корневой каталог
ФС под именами FILEXXXX.CHK (вместо ХХХХ подставляется номер). Предполагается,
что пользователь просматривает все такие файлы и определяет, не содержит
ли какой-то из них ценной информации, например, конца насильственно укороченного
файла.
В системах семейства Unix существует несколько специфических ошибок, связанных
с инодами.

Рис. 11.20. Инод-сирота
Ручное восстановление файловой системы
В некоторых особенно тяжелых случаях программа восстановления оказывается
не в состоянии справиться с происшедшей аварией и администратору системы
приходится браться за дисковый редактор.
В процессе эксплуатации системы SCO Open Desktop 4.0 у автора неоднократно
возникала необходимость выполнять холодную перезагрузку без нормального
размонтирования файловых систем. Одна из таких перезагрузок привела к
катастрофе.
Дисковая подсистема машины состояла из кэширующего контроллера дискового
массива. Контроллер активно использовал отложенную запись, что, по-видимому,
и послужило причиной катастрофы. Во время планового резервного копирования
драйвер лентопротяжки "впал в ступор" и заблокировал процесс
копирования (механизм возникновения этой аварии подробнее обсуждался в
разд. Обмен данными с пользовательским
процессом). Из-за наличия зависшего процесса оказалось невозможно
размонтировать файловую систему, и машина была перезагружена нажатием
кнопки RESET без выполнения нормального закрытия, в том числе и без выполнения
операции закрытия драйвера дискового массива, которая должна была сбросить
на диски содержимое буферов контроллера.
После перезагрузки система автоматически запустила программу восстановления
файловой системы fsck (File System ChecK), которая выдала радостное сообщение:
DUP in inode 2. Для незнакомых с системными утилитами Unix н обходимо
сказать, что DUP означает ошибку перекрещивания файлов, а инп~ 2— это
инод корневого каталога ФС. Таким образом, корневая директория дискового
тома объемом около 2 Гбайт оказалась испорчена. При этом пода ляющее большинство
каталогов и файлов были не затронуты катаклизмом оказались недоступны.
Программа восстановления не могла перенести ссылк на соответствующие иноды
в каталог lost+found, так как ссылка на него такж идет из корневого каталога.
Ситуация представлялась безвыходной. Катастрофа усугублялась тем, что
произошла она во время резервного копирования, а последняя "хорошая"
копия была сделана неделю назад. Большую часть пользовательских данных
можно было бы восстановить, но среди потерянных файлов оказался журнальный
файл сервера СУБД ORACLE (сама база данных находилась в другом разделе
диска). Пришлось заняться восстановлением ФС с использованием дискового
редактора, мотивируя это тем, что "терять все равно уже нечего"
Собственно, в восстановлении ФС участвовало два человека — автор и штатный
администратор системы. Автор ни в коем случае не хочет создать у читателя
впечатление, что план восстановления был разработан лично им — это был
плод совместных усилий, проб и ошибок.
Редактирование системных данных "сложных" ФС с использованием
простого шестнадцатеричного дискового редактора является крайне неблагодарным
занятием. Есть основания утверждать, что это вообще невозможно. Во всяком
случае, автору не доводилось слышать об успехе такого предприятия. К счастью,
системы семейства Unix предоставляют для редактирования ФС специальную
программу fsdb (File System DeBugger— отладчик файловой системы). Пользовательским
интерфейсом эта программа напоминает программу DEBUG.COM, поставляемую
с MS DOS; главным ее преимуществом является то, что она "знакома"
с основными понятиями файловой системы. Так, например, fsdb позволяет
просмотреть содержимое 10-го логического блока файла с инодом 23 456,
выделить физический блок 567 345 файлу с инодом 2 или пометить инод 1245
как свободный.
Первая попытка восстановления состояла в том, что мы удалили тот инод,
с которым перекрещивался корневой каталог, смонтировали том командой "безусловного"
монтирования (которая позволяла монтировать поврежденные тома), создали
командой mkdir каталог lost+found и вновь запустили fsck. Попытка завершилась
крахом. Беда была в том, что, как оказалось, корневой каталог пересекался
также и со списком свободных блоков, т. е. создание каталога, а потом
его расширение командой f sck снова приводило к порче корневого каталога
и задача сводилась к предыдущей.
Таким образом, нам необходимо было либо исправить вручную список свободных
блоков, либо найти способ создать директорию lost+found без обращений
к этому списку. Дополнительная сложность состояла в том, что с каталогом
lost+found не связано фиксированного инода, а определить инод старого
lost+found не представлялось возможным.
Мы решили не связываться с восстановлением списка свободных блоков. Вместо
этого мы просмотрели листинг последней "правильной" резервной
копии, нашли там ненужный пустой каталог и присоединили его к корневому
под названием lost+found. После этого нам оставалось лишь уповать на то,
что вновь создаваемые f sck-ссылки на файлы не приведут к необходимости
удлинить наш lost+found. К счастью, этого не произошло: все потомки корневого
каталога благополучно получили имена в lost+found. По существу, ФС пришла
в пригодное для чтения состояние, оставалось лишь правильно определить
имена найденных каталогов. Это также оказалось относительно несложной
задачей: большая часть каталогов на томе состояла из домашних каталогов
пользователей и их имена можно было восстановить на основании того, кому
эти каталоги принадлежали. Для остальных каталогов имя достаточно легко
определялось после сопоставления их содержимого с листингом резервной
копии.
Во многих современных ОС реализованы устойчивые к сбоям файловые системы:
jfs в AIX и OS/2 v4.5, Veritas в UnixWare, NTFS в Windows NT/2000/XP.
Практически все такие ФС основаны на механизме, который по-английски называется
intention logging (регистрация намерений).
Файловые системы с регистрацией намерений
Термин, вынесенный в заголовок этого подраздела, является дословной калькой
(возможно, не очень удачной) англоязычного термина intention logging.
В русском языке, к сожалению, еще нет общепринятого термина для этого
понятия.
Идея журналов регистрации намерений пришла из систем управления базами
данных. В СУБД часто возникает задача внесения согласованных изменений
в несколько разных структур данных. Например, банковская система переводит
миллион долларов с одного счета на другой. СУБД вычитает 1 000 000 из
суммы на первом счету, затем пытается добавить ту же величину ко второму
счету и в этот момент происходит сбой.
Для СУБД этот пример выглядит очень тривиально, но мы выбрали его потому,
что он похож на ситуацию в файловой системе: в каком бы порядке Ни производились
действия по переносу объекта из одной структуры в другую, сбой в неудачный
момент приводит к крайне неприятной ситуации. В СУБД эта проблема была
осознана как острая очень давно — ведь миллион долларов всегда был намного
дороже одного сектора на диске.
Удовлетворительное решение проблемы заключается в следующем.

Рис. 11.21. Выполнение транзакции с регистрацией намерений
Журнал часто называют журналом регистрации намерений
(intention log), что очень хорошо отражает суть дела, потому что
в этот журнал записываются именно намерения (intentions).
При использовании отложенной записи транзакция считается полностью завершенной,
только когда последний блок измененных данных будет физически записан
на диск. При этом в системе обычно будет одновременно существовать несколько
незавершенных транзакций (рис. II.22). Легко понять, что при операциях
с самим журналом отложенную запись вообше нельзя использовать.

Рис. 11.22. Очередь исполняющихся транзакций
Если произошел сбой системы, после перезагрузки запускается программа восстановления базы данных (рис. 11.23). Эта программа просматривает конец журнала.
Если она видит там испорченную запись, то игнорирует ее: сбой произошел во время записи в журнал. Если все записи помечены как успешно выполненные транзакции, то сбой произошел между транзакциями: ничего особенно страшного не случилось; во всяком случае, ничего исправлять не надо. Если найдена запись, которая отмечает начатую, но невыполненную транзакцию, то сбой произошел во время этой транзакции. Это наиболее неприятная ситуация, но журнал содержит достаточно информации для того чтобы или восстановить состояние базы данных до начала транзакции (выполнить откат назад (rollback)), или же доделать предполагавшиеся изменения.Нужно отметить, что данные, необходимые для выполнения отката, могут иметь большой объем. Фактически это копия всех данных, подвергающихся Изменению в ходе транзакции. Многие СУБД, такие как ORACLE, хранят эти данные не в самом журнале, а в специальной области данных, называемой сегмент отката (rollback segment).

Рис. 11.23. Журнал транзакций после сбоя
Более подробная информация о работе журналов намерений в базах данных
может быть найдена в соответствующей литературе [Дейт 1999, Дейт 1988).
Необходимо только отметить, что книги и даже фирменная документация по
простым СУБД типа dBase или FoxPro здесь не помогут, поскольку эти пакеты
не содержат средств регистрации в журнале.
Идея журнала намерений достаточно естественно переносится в программу
управления файловой системой. Но здесь возникает интересный вопрос -что
же считать транзакцией: только операции по распределению пространства
на диске или также все операции по изменению данных?
Первый вариант проще в реализации и оказывает меньшее влияние на производительность;
зато он гарантирует только целостность самой ФС, но не может гарантировать
целостности пользовательских данных, если сбой произойдет в момент записи
в файл.
Второй вариант требует выделения сегмента отката и сильно замедляет работу.
Действительно, ведь теперь данные пишутся на диск два раза: сначала в
сегмент отката, а потом в сам файл. Зато он существенно снижает вероятность
порчи пользовательских данных.
ряд современных ФС с регистрацией намерений поддерживают оба режима работы
и предоставляют выбор между этими вариантами администратору системы. Например,
у файловой системы vxfs пли Veritas, входящей в пакет UnixWare (версия
Unix SVR4, поставляемая фирмой Novell), существует две версии. Одна версия,
поставляемая вместе с системой по умолчанию, включает в транзакцию только
системные данные. Другая, "advanced", версия, которая поставляется
за отдельные деньги, осуществляет регистрацию намерений как для системных,
так и для пользовательских данных.
Журналы намерений в Veritas
В Veritas 2 дисковый том разбит на области, называемые группами цилиндров
(термин, унаследованный из FFS— файловой системы BSD Unix). Каждая группа
цилиндров имеет свою карту свободных блоков, участок динамической таблицы
инодов и журнал намерений (рис. 11.24). Журнал намерений организован в
виде кольцевого буфера записей о транзакциях. В журнал пишутся данные
только о транзакциях над инодами, принадлежащими к этой группе цилиндров.
При этом в каждой группе может исполняться одновременно несколько транзакций
и окончанием транзакции считается физическое завершение записи модифицированных
данных. Количество одновременно исполняющихся транзакций ограничено объемом
журнала, но поскольку каждая группа цилиндров имеет свой журнал, это ограничение
не играет большой роли.
Рис. 11.24. Группы цилиндров и журналы транзакций Veritas
Устойчивость ФС к сбоям диска
Кроме общесистемных сбоев, ФС должна обеспечивать средства восстановления при физических сбоях диска. Наиболее распространенным видом таких сбоев являются нечитаемые — "плохие" (bad) — блоки, появление которых обычно связано с физическими дефектами магнитного носителя.Быстрее всего плохие блоки возникают на гибких магнитных дисках, которые соприкасаются с головкой чтения/записи и из-за этого подвержены физическому износу и повреждениям. Кроме того, гибкие диски подвергаются опасным воздействиям и вне дисковода. Например, при вносе дискеты с улицы в теплое помещение на поверхности диска будет конденсировать влага, а соприкосновение головки дисковода с влажным диском практич ски наверняка повредит магнитный слой.
Жесткие магнитные диски помещены в герметичный корпус и — в норме не соприкасаются с головками дисковода, поэтому срок службы таких дис ков намного больше. Появление одиночных плохих блоков на жестком диске скорее всего свидетельствует о заводском дефекте поверхности или же о том, что магнитный слой от старости начал деградировать.
Весьма опасной причиной порчи жестких дисков является соприкосновение головок чтения/записи с поверхностью вращающегося диска (head crash) например, из-за чрезмерно сильных сотрясений диска во время работы В частности, из-за этого не следует переставлять работающие компьютеры особенно во время активных операций с диском. Обычно такое соприкосновение приводит к повреждению целой дорожки или нескольких дорожек диска, а зачастую и самой головки. Для несъемных жестких дисков это нередко означает потерю целой рабочей поверхности: считывание данных с нее требует замены блока головок, что весьма дорого.
Обычно ошибки данных обнаруживаются при чтении. Дисковые контроллеры используют при записи кодировку с исправлением ошибок, чаще всего коды Хэмминга (см. разд. Контрольные суммы), которые позволяют обнаруживать и исправлять ошибки. Тем не менее, если при чтении была выявлена ошибка, большинство ОС отмечают такой блок как плохой, даже если данные удалось восстановить на основании избыточного кода.
В файловой системе FAT плохой блок или кластер, содержащий такой блок, отмечается кодом OxFFB или OxFFFB для дисков с 16-разрядной FAT. Эта файловая система не способна компенсировать плохие блоки в самой FAT или в корневом каталоге диска. Такие диски просто считаются непригодными для использования.
В "сложных" файловых системах обычно используется более сложный, но зато и более удобный способ обхода плохих блоков, называемый горячей заменой (hotfixing). При создании файловой системы отводится небольшой пул блоков, предназначенных для горячей замены. В файловой системе хранится список всех обнаруженных плохих блоков, и каждому такому блоку поставлен в соответствие блок из пула горячей замены (рис. 11.25). При этом плохие блоки, на которые оказались отображены системные структуры данных, например участок таблицы инодов, также подвергаются горячей замене. Таблица горячей замены может быть как статической, так и динамической.
Современные контроллеры жестких дисков часто предоставляют свои средства горячей замены блоков, происходящие незаметно для центрального процессора.

Рис. 11.25. Горячая замена (динамическое переназначение) блоков диска
На первый взгляд, динамическая таблица горячей замены предпочтительна, однако не нужно забывать о двух немаловажных факторах. Файловая система вынуждена использовать для справки таблицу горячей замены при всех обращениях к диску, поэтому увеличение таблицы приводит к замедлению работы. Множественные плохие блоки на жестком диске свидетельствуют либо о том, что диск дефектный, либо о том, что магнитный слой начал разрушаться от старости (иными словами, что этот диск пора выбрасывать), либо о каких-то других не менее серьезных проблемах, вроде разгерметизации корпуса и проникновения в него пыли. С учетом обоих факторов кажется целесообразным установить предел количества плохих блоков, после достижения которого диск нуждается в замене. Следует отметить также, что этот предел не может превышать нескольких процентов общей емкости диска. В свете этого небольшая статическая таблица блоков горячей замены представляется вовсе не такой уж плохой идеей.Драйверы файловых систем
При эксплуатации ОС может возникнуть необходимость монтировать файловые системы, отличающиеся от "родной" ФС. Особенно часто она возникает в организациях, где используются ОС нескольких разных типов. Да и в организациях, работающих с монокультурой MS DOS/MS Windows, такая потребность возникает все чаще. Во-первых, доступ к файлам на файловом сервере осуществляется существенно иными способами, чем к файлам локальном диске, даже если на сервере стоит та же ДОС с той же Фс тип FAT. Во-вторых, дисководы для CD-ROM становятся все дешевле и расгт страняются все шире. При этом стандартная ФС на CD-ROM — вовсе FAT.Решение этой проблемы приходит в голову сразу — необходим драйвеп файловой системы со стандартным интерфейсом, подобный драйверу ннеш него устройства. Естественно, набор функций такого драйвера должен быть существенно иным. mount — монтирование ФС. В зависимости от типа ФС параметры тгой функции должны различаться. Для ФС на локальных дисках достаточно передать системный идентификатор монтируемого диска. Для ФС на удаленной машине мы должны передать сетевой адрес этой машины и имя требуемой файловой системы. Во многих случаях проводится различие между монтированием ФС для чтения/модификации или только для чтения: при монтировании с модификацией устанавливается флаг загрязнения (dirty flag) ФС. umount — размонтирование ФС. GetFreeSpace или df — получение информации о ФС: общее пространство, свободное пространство, количество файлов и т. д. FindFirst/FindNext ИЛИ opendir/readdir — функции длячтения из каталога. Считанную информацию необходимо привести к формату, принятому в данной ОС. В частности, может оказаться необходимым сократить и/или преобразовать считанные имена файлов. Например, драйвер HPFS, используемый в-эмуляторе MS DOS, в системе OS/2 не выполняет такого преобразования. В результате — программы DOS не видят файлов и каталогов с длинными именами. access — проверить существование файла и возможность доступа к нему в заданном режиме, например, для чтения или для записи. stat — функция для получения информации о файле с заданным именем. Драйвер ФС должен считать доступную информацию о файле и привести ее к принятому в ОС формату. При этом возможно придется проигнорировать часть считанной информации, а другую часть, напро-- тив, драйвер вынужден сочинять сам. Так, драйвер файловой системы FAT в ОС семейства Unix вынужден сочинять идентификатор хозяина файла, права доступа и т. д. open - открыть существующий или создать новый файл с заданным именем. read и write — функции считывания данных из файла ц записи в него. lseek — позиционирование в файле. lock — функция (в действительности, набор функций) блокировки для
синхронизации доступа к файлу или его участкам. (Подробнее о них см. в
разд. Захват участков файлов). При работе с локальными ФС операции блокировки могут прослеживаться ядром системы и не доходить до драйвера ФС, но при
работе с разделяемыми по сети ФС блокировки необходимо отслеживать
на уровне протокола разделения файлов, поэтому драйвер сетевой ФС
обязан знать о блокировках. close — закрыть файл. delete или unlink — удалить файл или его имя. link — создать связь с файлом (новое имя). Далеко не все ОС и ФС поддерживают эту операцию. mkdir — создать каталог. rmdir — удалить каталог. Обычно разрешено удаление только пустых каталогов. Кроме собственно драйвера ФС, для ее полноценной поддержки нужны следующие программы: программа создания ФС — mkfs или FORMAT; программа контроля и починки ФС — fsck или CHKDSK; программа fstyp, которая смотрит на содержимое устройства и пытается определить, "ее" это ФС или не ее. Она полезна при монтировании ФС с автоматическим определением ее типа; программа mount, которая принимает из командной строки зависящие от типа ФС параметры, проверяет их допустимость и инициализирует драйвер ФС.
Драйверы файловых систем в SCO UnixWare
Например, дистрибутив ОС UnxiWare 2.0 фирмы SCO, основанной на ядре UNIX
System V R4.2, содержит драйверы следующих файловых систем.
memfs — файловая система, размещающая файлы в оперативной памяти. Может
рассматриваться как эквивалент виртуального диска в MS DOS.
dosfs — файловая система FAT.
s5 — "классическая" ФС, сохранившаяся
почти без изменений с самых ранних версий системы— s5, по-видимому, означает
Unix System 5. Ограничивает имя файла 14 символами. Неустойчива к сбоям.
ufs — файловая система, разработанная в университете
Беркли, известная также как FFS (Fast File System) и Berkley FS. Является
основной ФС в большинстве версий BSD UNIX и поддерживается многими другими
ОС семейства Unix. Имеет более высокую производительность, чем s5, в первую
очередь за счет разбиения таблицы инодов и списка свободных блоков на
участки (группы цилиндров). Поддерживает дисковые квоты ограничения на
объем дискового пространства, занятого файлами того и~~ иного пользователя.
Ограничивает имя файла размером блока (обычно 512 символов). Неустойчива
к сбоям.
bfs — Boot File System — загрузочная файловая
система. Эта ФС очень простую структуру, отчасти похожую на файловую систему
все файлы в ней обязаны занимать непрерывное пространство. "Гака
структура упрощает первичный загрузчик системы, которому теперь не нужно
разбираться в каталогах и инодах. bfs имеет довольно низкую про-изводительность
и требует длительной процедуры размонтирования. если в нее были записаны
новые данные. Фактически, при таком размонтирова-нии происходит операция
сжатия ФС, эквивалентная команде SQEESE в RT-11. Используется для хранения
ядра системы и нескольких конфигурационных файлов, применяемых при загрузке.
Все эти данные считываются лишь при загрузке системы и перезаписываются
только при изменениях конфигурации ядра, поэтому высокая производительность
от этой ФС не требуется.
vxfs — устойчивая к сбоям ФС Veritas с регистрацией
намерений. Версия, входящая в стандартную поставку системы, включает в
регистрируемые транзакции только системные структуры данных. За отдельную
плату можно приобрести "продвинутую" версию Veritas, которая
обеспечивает транзакции и для записи пользовательских данных.
cdfs — файловая система ISO, используемая
на CD-ROM.
nfs — Network File System — драйвер файловой
системы, обеспечивающий разделение файлов с использованием сетевого протокола
TCP/IP. Протокол NFS был предложен фирмой Sun Microsystems в середине
80-х годов и в настоящее время поддерживается практически всеми членами
семейства Unix. NFS-клиенты и NFS-серверы реализованы практически для
всех современных ОС.
rfs — Remote File Sharing — использование
удаленной UNIX-системы в качестве файлового сервера. Этот протокол был
разработан фирмой AT&T в 80-е годы и пригоден только для соединения
систем UNIX System V.
nucfs — NetWare Unix Client File System. Этот
драйвер предназначен для присоединения к файловым серверам Novell Netware.
Он входит в состав системы UnixWare, поставляемой фирмой SCO, но не в
остальные версии UNIX SVR4.
