Машинное представление беззнаковых типов.
Машинное представление беззнаковых типов.
К беззнаковым типам в PASCAL относятся типы BYTE и WORD.
Формат машинного представления чисел типа BYTE приведен на рис 2.2. а).
Например: 1). Машинное представление числа 45: 45=2^5+2^3+2^2+2^0 = 00101101 2). Машинное представление границ диапазона допустимых значений чисел 0 и 255: 0: 00000000; 255: 11111111.
Машинное представление чисел со знаком.
Машинное представление чисел со знаком.
Для представления чисел со знаком определены следующие типы SHORTINT, INTEGER, LONGINT. В приведенных типах числа хранятся в дополнительном ко- де. Напомним, что дополнительный код положительных чисел совпадает с прямым кодом.
Формат машинного представления чисел типа SHORTINT приведен на рис 2.3. а) где s-знаковый разряд числа. Для положительных чисел s=0, для отрицательных s=1.
Например, машинное представление чисел в формате shortint: 1). 0: 00000000; 2). +127: 01111111; 3). -128: 10000000.
Формат машинного представления чисел типа INTEGER приведен на рис 2.3. б). Например:
1). +32765: 11111101 01111111; 2). -32765: 00000011 10000000; 3). -47: 11010001 11111111.
Машинное представление границ диапазона допустимых значений:
4). -32768: 00000000 10000000; 5). 32767: 11111111 01111111.
Формат машинного представления чисел типа LONGINT приведен на рис 2.3. в). Например, представление чисел в формате longint:
1). +89 01011001 00000000 00000000 00000000; 2). -89 10100111 11111111 11111111 11111111.
Машинное представление данных типа double
Машинное представление данных типа DOUBLE
Формат машинного представления данных типа DOUBLE следующий:
мл.байт ст.байт 7 0 15 8 23 16 31 24 39 32 47 40 55 52 51 48 63 56 м...м м...м м...м м...м м...м м...м х..х м...м s x..x -44 -50 -37 -43 -29 -36 -21 -28 -13 -20 -5 -12 3 0 -1 -4 10 4
где:
верхняя строка цифр от 0 до 63 - номера разрядов памяти; нижняя строка цифр от -50 до -1 - показатели степеней разрядов мантиссы; от 0 до 10 - разрядов характеристики; s - знаковый разряд числа; м - нормализованная мантисса; х - характеристика числа (x=2^10-1+p, где p - порядок нормализованного числа).
Например:
1). Число 15.375;
в двоичной системе счисления 1111.011; результат нормализации 1.111011*2^3; р=3.
Учитывая отбрасывание скрытой единицы и сдвиг порядка, получаем: s=0; x=2^10-1+3=2^10+2^1=1026;
в двоичной системе счисления х=10000000010; m=1110110...0;
машинное представление числа в формате DOUBLE:
0 00000000 00000000 00000000 00000000 31 32 00000000 11000000 00101110 01000000 63
2). Десятичное число 0.0375;
в двоичной системе счисления 0.011; результат нормализации 1.1*2^(-2); р=-2.
Учитывая отбрасывание скрытой единицы и сдвиг порядка, получаем: s=0; x=2^10-2^1-2^0=2^10-3;
в двоичной системе счисления х=01111111101; m=100...0;
машинное представление числа в формате DOUBLE:
0 00000000 00000000 00000000 00000000 31 32 00000000 00000000 11011000 00111111 63
3). Десятичное число 2.5;
аналогичные выкладки дают нормализованную мантиссу: 1.0100...0;
машинное представление числа 2.5: 00000000 00000000 00000000 00000000 00000000 00000000 00000100 01000000
4). Значения верхней и нижней границ диапазона положительных чисел:
~1.8*10^308 - 11111111 11111111 11111111 11111111 11111111 11111111 11101111 01111111 ~4.9*10^(-324) - 00000001 00000000 00000000 00000000 00000000 00000000 00000000 00000000
Символ ~ обозначает приближенное значение числа.
Машинное представление данных типа extended
Машинное представление данных типа EXTENDED
Формат машинного представления данных типа EXTENDED следующий:
мл.байт ст. байт 7 0 15 8 23 16 31 24 39 32 47 40 55 48 63 56 71 64 79 72 м..м м..м м..м м..м м..м м..м м..м м..м х..х sх..х -56-63-48-55-40-47-32-39-24-31-16-23-8 -15 0 -7 7 0 14 8
где:
верхняя строка цифр - номера разрядов памяти; нижняя строка цифр - показатели степеней разрядов мантиссы и характеристики; s - знаковый разряд числа; м - нормализованная мантисса; х - характеристика числа.
Например:
1). Число -15.375;
в двоичной системе счисления -1111.011; после нормализации -1.111011*2^3; р=3.
Учитывая присутствие скрытой единицы и сдвиг порядка, получаем: s=1; х=2^14-1+3=2^14+2^1=16386;
в двоичной системе счисления х=100000000000010; м=11110110...0
(в мантиссе единица стоящая слева от запятой не отбрасывается).
Машинное представление данного числа в формате EXTENDED:
0..0 0..0 0..0 0..0 0..0 0..0 0..0 11110110 00000010 11000000
2). Число 1.0;
аналогичные выкладки дают нормализованную мантиссу: 1.0...0; машинное представление числа 1.0: 0..0 0..0 0..0 0..0 0..0 0..0 0..0 10000000 11111111 00111111
3). Значения верхней и нижней границ диапазона положительных чисел
(символом * помечены разряды, значения которых при данной характеристике не идентифицируются т. е. их значения не влияют на значение мантиссы):
~1.2*10^4932 - ******** ******** 11111111 11111111 11111111 11111111 11111111 11111111 11111111 011111111 ~3.1*10^4944 - ******** ******** 00000001 00000000 000000000 00000000 00000000 00000000 00000001 000000000
где:
а - номера разрядов памяти, б - показатели степеней разрядов характеристики и мантиссы, s - знаковый разряд числа, м - нормализованная мантисса, х - характеристика числа.
1). Десятичное число 15.375;
в двоичной системе счисления 1111.011; результат нормализации 1.111011*2^3; р=3.
Учитывая отбрасывание неявной единицы и сдвиг порядка, получаем: s=0; х=2^7+1+3=2^7+2^2=132;
2). Десятичное число -0.5;
3). Десятичное число -25.75;
4). Число 0.0;
Машинное представление числа: 00000000 00000000 00000000 00000000 00000000 00000000
5). Числа верхней и нижней границ положительного диапазона
~1.7*10^38 - 11111111 11111111 11111111 11111111 11111111 01111111 ~2.9*10^(-35) - 00000001 00000000 00000000 00000000 00000000 00000000
где:
s - знаковый разряд, х - характеристика числа, м - нормализованная мантисса.
1). Число -15.375;
в двоичной системе счисления -1111.011; нормализованное двоичное число -1.111011*2^3; р=3.
Учитывая отбрасывание неявной единицы и сдвиг порядка, получаем: s=1; х=2^7-1+3=2^7+2^1=130;
2). Число -0.1875;
в двоичной системе счисления -0.0011; нормализованное двоичное число -1.1*2^(-3); р=-3.
Учитывая отбрасывание неявной единицы и сдвиг порядка, получаем: s=1; х=2^7-1-3=2^7-2^2;
3). Десятичное число 4.5;
4). Значения верхней и нижней границ чисел отрицательного диапазона
~-3.4*10^38 - 11111111 11111111 01111111 11111111 ~-.4*10^(-45) - 00000001 00000000 00000000 10000000
К данному типу массивов относятся массивы, у которых местоположения элементов со значениями отличными от фонового, могут быть математически описаны, т. е. в их расположении есть какая-либо закономерность.
Элементы, значения которых являются фоновыми, называют нулевыми; элементы, значения которых отличны от фонового, - ненулевыми. Но нужно помнить, что фоновое значение не всегда равно нулю.
Ненулевые значения хранятся, как правило, в одномерном массиве, а связь между местоположением в исходном, разреженном, массиве и в новом, одномерном, описывается математически с помощью формулы, преобразующей индексы массива в индексы вектора.
На практике для работы с разреженным массивом разрабатываются функции:
а) для преобразования индексов массива в индекс вектора; б) для получения значения элемента массива из ее упакованного представления по двум индексам (строка, столбец); в) для записи значения элемента массива в ее упакованное представление по двум индексам.
При таком подходе обращение к элементам исходного массива выполняется с помощью указанных функций. Например, пусть имеется двумерная разреженная матрица, в которой все ненулевые элементы расположены в шахматном порядке, начиная со второго элемента. Для такой матрицы формула вычисления индекса элемента в линейном представлении будет следующей : L=((y-1)*XM+x)/2), где L - индекс в линейном представлении; x, y - соответственно строка и столбец в двумерном представлении; XM - количество элементов в строке исходной матрицы.
В программном примере 3.1 приведен модуль, обеспечивающий работу с такой матрицей (предполагается, что размер матрицы XM заранее известен).
{===== Программный пример 3.1 =====} Unit ComprMatr; Interface Function PutTab(y,x,value : integer) : boolean; Function GetTab(x,y: integer) : integer; Implementation Const XM=...; Var arrp: array[1..XM*XM div 2] of integer; Function NewIndex(y, x : integer) : integer; var i: integer; begin NewIndex:=((y-1)*XM+x) div 2); end; Function PutTab(y,x,value : integer) : boolean; begin if NOT ((x mod 2<>0) and (y mod 2<>0)) or NOT ((x mod 2=0) and (y mod 2=0)) then begin arrp[NewIndex(y,x)]:=value; PutTab:=true; end else PutTab:=false; end; Function GetTab(x,y: integer) : integer; begin if ((x mod 2<>0) and (y mod 2<>0)) or ((x mod 2=0) and (y mod 2=0)) then GetTab:=0 else GetTab:=arrp[NewIndex(y,x)]; end; end.
Сжатое представление матрицы хранится в векторе arrp.
Функция NewIndex выполняет пересчет индексов по вышеприведенной формуле и возвращает индекс элемента в векторе arrp.
Функция PutTab выполняет сохранение в сжатом представлении одного элемента с индексами x, y и значением value. Сохранение выполняется только в том случае, если индексы x, y адресуют не заведомо нулевой элемент. Если сохранение выполнено, функция возвращает true, иначе - false.
Для доступа к элементу по индексам двумерной матрицы используется функция GetTab, которая по индексам x, y возвращает выбранное значение. Если индексы адресуют заведомо нулевой элемент матрицы, функция возвращает 0.
Обратите внимание на то, что массив arrp, а также функция NewIndex не описаны в секции IMPLEMENTATION модуля. Доступ к содержимому матрицы извне возможен только через входные точки PutTab, GetTab с заданием двух индексов.
В программном примере 3.2 та же задача решается несколько иным способом: для матрицы создается дескриптор - массив desc, который заполняется при инициализации матрицы таким образом, что i-ый элемент массива desc содержит индекс первого элемента i-ой строки матрицы в ее линейном представлении. Процедура инициализации InitTab включена в число входных точек модуля и должна вызываться перед началом работы с матрицей. Но доступ к каждому элементу матрицы (функция NewIndex) упрощается и выполняется быстрее: по номеру строки y из дескриптора сразу выбирается индекс начала строки и к нему прибавляется смещение элемента из столбца x. Процедуры PutTab и GetTab - такие же, как и в примере 3.1 поэтому здесь не приводятся.
{===== Программный пример 3.2 =====} Unit ComprMatr; Interface Function PutTab(y,x,value : integer) : boolean; Function GetTab(x,y: integer) : integer; Procedure InitTab; Implementation Const XM=...; Var arrp: array[1..XM*XM div 2] of integer; desc: array[1..XM] of integer; Procedure InitTab; var i : integer; begin desc[1]:=0; for i:=1 to XM do desc[i]:=desc[i-1]+XM; end; Function NewIndex(y, x : integer) : integer; var i: integer; begin NewIndex:=desc[y]+x div 2; end; end.
При использовании матриц смежности их элементы представляются в памяти ЭВМ элементами массива. При этом, для простого графа матрица состоит из нулей и единиц, для мультиграфа - из нулей и целых чисел, указывающих кратность соответствующих ребер, для взвешенного графа - из нулей и вещественных чисел, задающих вес каждого ребра.
Например, для простого ориентированного графа, изображенного на рис.6.2 массив определяется как:
mas:array[1..4,1..4]=((0,1,0,0),(0,0,1,1),(0,0,0,1),(1,0,1,0))
Матрицы смежности применяются, когда в графе много связей и матрица хорошо заполнена.
Многосимвольные группы (звенья) организуются в список, так что каждый элемент списка, кроме последнего, содержит группу элементов строки и указатель следующего элемента списка. Поле указателя последнего элемента списка хранит признак конца - пустой указатель. В процессе обработки строки из любой ее позиции могут быть исключены или в любом месте вставлены элементы, в результате чего звенья могут содержать меньшее число элементов, чем было первоначально. По этой причине необходим специальный символ, который означал бы отсутствие элемента в соответствующей позиции строки. Обозначим такой символ 'emp', он не должен входить в множество символов,из которых организуется строка. Пример многосимвольных звеньев фиксированной длинны по 4 символа в звене показан на рис.4.9.
Переменная длинна блока дает возможность избавиться от пустых символов и тем самым экономить память для строки. Однако появляется потребность в специальном символе - признаке указателя, на рис.4.10 он обозначен символом 'ptr'.
С увеличением длины групп символом, хранящихся в блоках, эффективность использования памяти повышается. Однако негативной характеристикой рассматриваемого метода является усложнение операций по резервированию памяти для элементов списка и возврату освободившихся элементов в общий список доступной памяти.
Память выделяется блоками фиксированной длины. В каждом блоке помимо символов строки и указателя на следующий блок содержится номера первого и последнего символов в блоке. При обработке строки в каждом блоке обрабатываются только символы, расположенные между этими номерами. Признак пустого символа не используется: при удалении символа из строки оставшиеся в блоке символы уплотняются и корректируются граничные номера. Вставка символа может быть выполнена за счет имеющегося в блоке свободного места, а при отсутствии такового - выделением нового блока. Хотя операции вставки/удаления требуют пересылки символов, диапазон пересылок ограничивается одним блоком. При каждой операции изменения может быть проанализирована заполненность соседних блоков и два полупустых соседних блока могут быть переформированы в один блок. Для определения конца строки может использоваться как пустой указатель в последнем блоке, так и указатель на последний блок в дескрипторе строки. Последнее может быть весьма полезным при выполнении некоторых операций, например, сцепления. В дескрипторе может храниться также и длина строки: считывать ее из дескриптора удобнее, чем подсчитывать ее перебором всех блоков строки.
Пример представления строки в виде звеньев с управляемой длиной 8 показан на рис.4.11.
Во многих задачах, связанных с деревьями, требуется осуществить систематический просмотр всех его узлов в определенном порядке. Такой просмотр называется прохождением или обходом дерева.
Бинарное дерево можно обходить тремя основными способами: нисходящим, смешанным и восходящим ( возможны также обратный нисходящий, обратный смешанный и обратный восходящий обходы). Принятые выше названия методов обхода связаны с временем обработки корневой вершины: До того как обработаны оба ее поддерева (Preorder), после того как обработано левое поддерево, но до того как обработано правое (Inorder), после того как обработаны оба поддерева (Postorder). Используемые в переводе названия методов отражают направление обхода в дереве: от корневой вершины вниз к листьям - нисходящий обход; от листьев вверх к корню - восходящий обход, и смешанный обход - от самого левого листа дерева через корень к самому правому листу.
Схематично алгоритм обхода двоичного дерева в соответствии с нисходящим способом может выглядеть следующим образом:
1. В качестве очередной вершины взять корень дерева. Перейти к пункту 2. 2. Произвести обработку очередной вершины в соответствии с требованиями задачи. Перейти к пункту 3. 3.а) Если очередная вершина имеет обе ветви, то в качестве новой вершины выбрать ту вершину, на которую ссылается левая ветвь, а вершину, на которую ссылается правая ветвь, занести в стек; перейти к пункту 2; 3.б) если очередная вершина является конечной, то выбрать в качестве новой очередной вершины вершину из стека, если он не пуст, и перейти к пункту 2; если же стек пуст, то это означает, что обход всего дерева окончен, перейти к пункту 4; 3.в) если очередная вершина имеет только одну ветвь, то в качестве очередной вершины выбрать ту вершину, на которую эта ветвь указывает, перейти к пункту 2. 4. Конец алгоритма.
Для примера рассмотрим возможные варианты обхода дерева (рис.6.26).
При обходе дерева представленного на рис.6.26 этими тремя методами мыполучим следующие последовательности: ABCDEFG ( нисходящий ); CBAFEDG ( смешанный ); CBFEGDA ( восходящий ).
Алгоритм сортировки простой выборкой, однако, редко применяется в том варианте, в каком он описан выше. Гораздо чаще применяется его, так называемый, обменный вариант. При обменной сортировке выборкой входное и выходное множество располагаются в одной и той же области памяти; выходное - в начале области, входное - в оставшейся ее части. В исходном состоянии входное множество занимает всю область, а выходное множество - пустое. По мере выполнения сортировки входное множество сужается, а выходное - расширяется.
Обменная сортировка простой выборкой показана в программном примере 3.8. Процедура имеет только один параметр - сортируемый массив.
{===== Программный пример 3.8 =====} Procedure Sort(var a : SEQ); Var x, i, j, m : integer; begin for i:=1 to N-1 do { перебор элементов выходного множества} { входное множество - [i:N]; выходное - [1:i-1] } begin m:=i; for j:=i+1 to N do { поиск минимума во входном множестве } if (a[j] < a[m]) then m:=j; { обмен 1-го элемента вх. множества с минимальным } if i<>m then begin x:=a[i]; a[i]:=a[m]; a[m]:=x; end;end; end;
Результаты трассировки программного примера 3.8 представлены в таблице 3.5. Двоеточием показана граница между входным и выходным множествами.
Каждый символ строки представляется в виде элемента связного списка; элемент содержит код символа и указатель на следующий элемент, как показано на рис.4.7. Одностороннее сцепление представляет доступ только в одном направлении вдоль строки. На каждый символ строки необходим один указатель, который обычно занимает 2-4 байта.
На физическом уровне над переменными перечислимого типа определены операции создания, уничтожения, выбора, обновления. При этом выполняется определение порядкового номера идентификатора по его значению и, наоборот, по номеру идентификатораего значение.
На логическом уровне переменные перечислимого типа могут быть использованы только в выражениях булевского типа и в операциях сравнения; при этом сравниваются порядковые номера значений.
Над битовыми типами возможны три группы специфических операций: операции булевой алгебры, операции сдвигов, операции сравнения.
Операции булевой алгебры - НЕ (not), ИЛИ (or), И (and), исключающее ИЛИ (xor). Эти операции и по названию, и по смыслу похожи на операции над логическими операндами, но отличие в их применении к битовым операндам состоит в том, что операции выполняются над отдельными разрядами операндов.
Так операция НЕ состоит в том, что каждый разряд операнда изменяет значение на противоположный. Выполнение операции, например, ИЛИ над двумя битовыми операндами состоит в том, что выполняется ИЛИ между первым разрядом первого операнда и первым разрядом второго операнда, это дает первый разряд результата; затем выполняется ИЛИ между вторым разрядом первого операнда и вторым разрядом второго, получается второй разряд результата и т.д.
Ниже даны примеры выполнения побитовых логических операций: а). x = 01101100 в). x = 01101100 not x = 10010011 y = 11001110 x and y = 01001100 б). x = 01101100 г). x = 01101100 y = 11001110 y = 11001110 x or y = 11101110 x xor y = 10100010
В некоторых языках (PASCAL) побитовые логические операции обозначаются так же, как и операции над логическими операндами и распознаются по типу операндов. В других языках (C) для побитовых и общих логических операций используются разные обозначения. В третьих (PL/1) - побитовые операции реализуются встроенными функциями языка.
Операции сдвигов выполняют смещение двоичного кода на заданное количество разрядов влево или вправо. Из трех возможных типов сдвига (арифметический, логический, циклический) в языках программирования обычно реализуется только логический (например, операциями shr, shl в PASCAL).
В операциях сравнения битовые данные интерпретируются как целые без знака, и сравнение выполняется как сравнение целых чисел. Битовые строки в языке PL/1 - более общий тип данных, к которому применимы также операции над строковыми данными, рассматриваемые в главе 4.
Операция удаления из сбалансированного дерева.
ОПЕРАЦИЯ УДАЛЕНИЯ ИЗ СБАЛАНСИРОВАННОГО ДЕРЕВА.
Удаление элемента из сбалансированного дерева является еще более сложной операцией чем включение, так как может удаляться не только какой-либо из листьев, но и любой узел (в том числе и корень). Поэтому при удалении необходимо правильно изменить структуру связей между элементами, а затем произвести балансировку полученного дерева.
В результате удаления какого-либо узла могут возникнуть ситуации аналогичные тем, что возникают при добавлении элемента:
1. Вершина была лево- или правоперевешивающей, а теперь стала сбалансированной. 2. Вершина была сбалансированной, а стала лево- или правоперевешивающей. 3. Вершина была перевешивающей, а вставка новой вершины в перевешивающее поддерево создала несбалансированное поддерево - привело к появлению критической вершины. Необходимо провести балансировку.
В общем процесс удаления элемента состоит из следующих этапов:
1. Следовать по дереву, пока не будет найден удаляемый элемент. 2. Удалить найденный элемент, не разрушив структуры связей между элементами. 3. Произвести балансировку полученного дерева и откорректировать показатели сбалансированности.
На каждом шаге должна передаваться информация о том, уменьшилась ли высота поддерева (из которого произведено удаление). Поэтому мы введем в список параметров переменную h, означающую "высота поддерева уменьшилась".
Простыми случаями являются удаление терминальных узлов и узлов с одним потомком. Если же узел, который надо удалить имеет два поддерева, мы будем заменять его самым правым узлом левого поддерева.
Для балансировки дерева после удаления используем две (симметричные) операции балансировки: Balance_R используется, когда уменьшается высота правого поддерева, а Balance_L - левого поддерева. Процедуры балансировки используют те же способы (LL- LR- RL- и RR-повороты), что и в процедуре вставки элемента.
Операция вставки вершины в сбалансированное дерево.
ОПЕРАЦИЯ ВСТАВКИ ВЕРШИНЫ В СБАЛАНСИРОВАННОЕ ДЕРЕВО.
Предполагается, что новая вершина вставляется на уровне листьев, или терминальных вершин (как левое или правое поддерево). При такой вставке показатели сбалансированности могут изменится только у тех вершин, которые лежат на пути между корнем дерева и вновь вставляемым листом.
Алгоритм включения и балансировки полностью определяется способом хранения информации о сбалансированности дерева. Определение типа узла имеет вид:
TYPE ref=^node; { указатель } node=record key:integer; { ключ узла } left,right:ref; { указатели на ветви } bal:-1..+1; { флаг сбалансированности } end;
Процесс включения узла состоит из последовательности таких трех этапов:
1. Следовать по пути поиска, (по ключу), пока не будет найден ключ или окажется,что ключа нет в дереве. 2. Включить новый узел и определить новый показатель сбалансированности. 3. Пройти обратно по пути поиска и проверить показатель сбалансированности у каждого узла.
На каждом шаге должна передаваться информация о том, увеличилась ли высота поддерева (в которое произведено включение). Поэтому можно ввести в список параметров переменную h, означающую "высота поддерева увеличилась".
Необходимые операции балансировки полностью заключаются в обмене значениями ссылок. Фактически ссылки обмениваются значениями по кругу, что приводит к однократному или двукратному "повороту" двух или трех узлов.
Описание программы:
ОПИСАНИЕ ПРОГРАММЫ:
Последовательность решения задачи:
1) Ввод выражения; 2) Построение бинарного дерева из данного выражения; 3) Вычисление математического выражения; 4) Вывод дерева на экран; 5) Вывод результата на экран.
Процедуры программы:
Процедура Tree - преобразует математическое выражение в бинарное дерево. Процедура работает с помощью рекурсивного нисходящего обхода. Имеет подпроцедуру UnderTree. Подпроцедура UnderTree - специальная процедура. Создает поддеревья исходя из приоритета математической операции. Имеет подпроцедуру Skob. Подпроцедура Skob - учитывает скобки в математическом выражении. Процедура Calc - вычисляет математическое выражение. Процедура использует рекурсивный нисходящий обход. Процедура Symb - определяет в дереве где переменная или константа, и где знак операции. Эта процедура нужна для вычисления математического выражения. Процедура использует рекурсивный нисходящий обход. Процедура OutTree - выводит дерево на экран. Процедура использует рекурсивный нисходящий обход.
{===== Программный пример 6.17 ====== } {$M 65500,0,100000} Program MathExpr; { Эта программа вычисляет } {математические выражения : *, /, +, -, ^. } Uses CRT; Type tr=^rec; {Тип дерево} rec=record pole:string; {Информационное поле } sym:boolean; {Флаг символа } zn:real; {Значение переменной } rend:boolean; {Вспомогательный флаг} l,r:tr; {Указатели на потомка} end; Var root,el : tr; {вершина и узлы дерева} st : string; {вспомогательная переменная} i,j : byte; { -------"-------} x,y : integer; { координаты для вывода дерева} g : byte; {вспомогательная переменная} yn : char; { -------"-------} code : integer; { для procedure VAL } {Процедура Tree } {Преобразование арифметического выражения в бинарное дерево } { Процедура использует рекурсивный нисходящий обход } Procedure Tree(p:tr); Procedure undertree(c:char); { создает поддеревья} Procedure Skob; {процедура для учитывания скобок} begin i:=i+1; repeat If p^.pole[i]='(' then Skob; i:=i+1; until p^.pole[i]=')'; end; {End of Skob} begin for i:=1 to Length(p^.pole) do begin if p^.pole[i]='(' then begin g:=i; Skob; if (p^.pole[i+1]<>'+') and (p^.pole[i+1]<>'-') and (p^.pole[i+1]<>'*') and (p^.pole[i+1]<>'/') and (p^.pole[g-1]<>'*') and (p^.pole[g-1]<>'/') and (p^.pole[g-1]<>'-') and (p^.pole[g-1]<>'+') and (p^.pole[i+1]<>'^') and (p^.pole[g-1]<>'^') then begin delete(p^.pole,i,1); delete(p^.pole,1,1); i:=0; end; end; if p^.pole[i]=c then begin New(p^.l); p^.l^.l:=nil; p^.l^.r:=nil; p^.l^.pole:=copy(p^.pole,1,i-1); p^.l^.zn:=0; p^.l^.sym:=false; New(p^.r); p^.r^.l:=nil; p^.r^.r:=nil; p^.r^.pole:=copy(p^.pole,i+1,ord(p^.pole[0])); p^.r^.zn:=0; p^.r^.sym:=false; i:=ord(p^.pole[0]); p^.pole:=c; end; end; end; {end of UnderTree} begin if p<>nil then {Строятся поддеревья в зависимости от приоритета} {арифметической операции } begin UnderTree('+'); UnderTree('-'); UnderTree('*'); Undertree('/'); Undertree('^'); Tree(p^.l); Tree(p^.r); end; end; {End of Tree} {Вычисление значения арифметического выражения} {Процедура использует рекурсивный нисходящий обход} Procedure Calc(p:tr); begin if p<> nil then begin if p^.l^.sym and p^.r^.sym then begin case p^.pole[1] of '+' : begin p^.zn:=p^.l^.zn+p^.r^.zn; p^.sym:=true; end; '-' : begin p^.zn:=p^.l^.zn-p^.r^.zn; p^.sym:=true; end; '*' : begin p^.zn:=p^.l^.zn*p^.r^.zn; p^.sym:=true; end; '/' : begin p^.zn:=p^.l^.zn/p^.r^.zn; p^.sym:=true; end; '^' : begin p^.zn:=EXP(p^.r^.zn*LN(p^.l^.zn)); p^.sym:=true; end; end; {end of case} end; Calc(p^.l); Calc(p^.r); end; end; {end of calc} {Процедура определяет где в дереве переменная или значение,} {и где знак операции. Использует рекурсивный нисходящий обход} Procedure Symb(p:tr); begin if p<> nil then begin if p^.pole[1] in ['a'..'z'] then begin p^.sym:=true; Write(p^.pole,'= '); Readln(p^.zn); end; if p^.pole[1] in ['0'..'9'] then begin p^.sym:=true; VAL(p^.pole,p^.zn,code); end; Symb(p^.l); Symb(p^.r); end; end; {End of Symb} { Процедура выводит на экран полученное дерево } { Процедура использует рекурсивный нисходящий обход} Procedure OutTree(pr:tr;f:byte); begin y:=y+2; if pr<>nil then begin If f=1 then begin x:=x-5; end; if f=2 then begin x:=x+9; end; GotoXY(X,Y); {Если f=0, то выводится корневая вершина} if f=0 then Writeln('[',pr^.pole,']'); {Если f=1, то - левое поддерево} if f=1 then Writeln('[',pr^.pole,']/'); {Если f=2, то - правое поддерево} if f=2 then Writeln('\[',pr^.pole,']'); OutTree(pr^.l,1); OutTree(pr^.r,2); end; y:=y-2; end; {End of OutTree} begin {Главная программа} repeat Window(1,1,80,25); x:=22; y:=0; TextBackGround(7); TextColor(Blue); ClrScr; {Ввод выражения, которое надо посчитать} Writeln('Введите ваше выражение:'); GotoXY(40,4); Write('Используйте следующие операции:'); GotoXY(50,5); Write(' + , - , * , / , ^ '); GotoXY(40,7); Write('Программа применяет деревья для'); GotoXY(40,8); Write('вычисления арифметического вы-'); GotoXY(40,9); Write('ражения.'); GotoXY(1,2); Readln(st); {root Создается корневая вершина} New(el); el^.l:=nil; el^.r:=nil; El^.pole:=st; el^.zn:=0; el^.sym:=false; el^.rend:=false; root:=el; {end of root} Tree(root); {Создается дерево} {Ввод значений переменных} Writeln('Введите значения:'); Symb(root); Window(30,1,80,25); TextBackGround(Blue); TextColor(White); ClrScr; WriteLn('Дерево выглядит так:'); {Вывод дерева на экран} OutTree(root,0); repeat if root^.l^.sym and root^.r^.sym then begin Calc(root); root^.rend:=true; end else calc(root); until root^.rend; Window(1,23,29,25); TextBackGround(Red); TextColor(Green); ClrScr; Writeln('Результат =',root^.zn:2:3); {Вывод результата } Write('Еще?(y/n)'); readln(yn); until yn='n'; end.
Результат работы программы представлен на рис 6.34.
Описание программы работы со сбалансированными деревьями.
ОПИСАНИЕ ПРОГРАММЫ РАБОТЫ СО СБАЛАНСИРОВАННЫМИ ДЕРЕВЬЯМИ.
1. Процедура NOTE.
В процессе работы пользователя с программой MAVERIC выводит подсказку в нижней части экрана. Подсказка содержит коды клавиш,определяющих режим работы программы.
2. Процедура CREATE.
Создает новый узел дерева,в том числе и корень; записывает ключ дерева и обнуляет указатели узла на его ветви. Включает счетчик узлов и определяет корень дерева,путем установки на него указателя ROOT. Указатель ROOT устанавливается только в случае,если счетчик узлов дерева равен 0.
3. Процедура SEARCH.
Входным элементом для процедуры SEARCH является определяемый пользователем ключ для поиска или создания нового узла. Новый ключ сравнивается с ключом предыдущего узла.Если узла с таким ключом нет в дереве,то вызывается процедура CREATE.
В зависимости от того, больше или меньше ключ нового узла ключа узла предыдущего выбирается вид включения нового узла в дерево - справа или слева. На каждом этапе работы процедуры проверяется флаг "h" определяющий,увеличилась ли высота поддерева; а также проверяется поле "p^.bal" определяющее способ балансировки.
Процедура SEARCH является рекурсивной процедурой,т.е. она вызывает сама себя.При первом проходе процедура SEARCH обращается к корню дерева,затем проходит по всему дереву,последовательно вызывая ветви корня,затем ветви ветвей и так далее.
В случае,если необходима балансировка,процедура SEARCH производит так называемые "повороты" ветвей дерева,путем переопределения указателей.Если балансировка затрагивает корень дерева, процедура переопределяет корень,меняя указатель ROOT,а затем производит балансировку.
4. Процедура DELETE.
Процедура DELETE удаляет ключ из дерева и,если необходимо,производит балансировку.Входным параметром является определяемый пользователем ключ. Процедура DELETE имеет три одпроцедуры: balance_R,balance_L и Del.Подпроцедуры balance_R и balance_L являются симметричными и выполняют балансировку при уменьшении высоты правого или левого поддеревьев соответственно.
Если узла с заданным пользователем ключом нет в дереве,то выводится соответствующее сообщение.Если данный ключ меньше ключа предыдущего узла,то происходит рекурсивный вызов процедуры Delete и обход дерева по левой ветви.Если возникает необходимость балансировки,то вызывается подпроцедура balance_L.Если заданный пользователем ключ больше ключа предыдущего узла,то производится обход дерева по правой ветви и в случае необходимости балансировки вызывается подпроцедура balance_R.
Если подпроцедуры балансировки затрагивают корень дерева,то меняется указатель на корень дерева - ROOT.Эта операция заложена в обоих подпроцедурах balance_R и balance_L.
При обнаружении узла с заданным пользователем ключом подпроцедура Del производит операцию удаления данного узла.
5. Процедура OUTTREE.
Рекурсивная процедура OutTree выводит изображение дерева на монитор. Входными параметрами является указатель на корень дерева ROOT и переменная F определяющая,является ли текущий узел корнем или правой или левой ветвью.
После каждой операции над деревом процедура OutTree выводит изображение дерева заново,предварительно очистив экран.
6. Основная программа.
Программа Maveric работает в текстовом режиме,для чего в начале инициализируется модуль CRT. Основная программа выводит заставку и ожидает нажатия одной из определенных в программе клавиш. При помощи процедуры Note внизу экрана выводится подсказка со списком определенных клавиш и соответствующих им операций.При нажатии клавиши B вызывается процедура Create,при нажатии клавиши S вызывается процедура Search,при нажатии D - процедура Delete.Программа работает в диалоговом режиме.
Режим работы с пользователем прекращается при нажатии клавиши ESC.
{======Программный пример 6.22 ====== } {$T-} Program Maveric; USES CRT; label L1,L2,L3,L4; TYPE ref=^node; { указатель на узел } node=record key:integer; { ключ узла } left,right:ref; { указатели на ветви } bal:-1..+1; { флаг сбалансированности } end; VAR root, { указатель на корень дерева } p:ref; { новое дерево } x:integer; { ключ узла } h:boolean; { true-высота поддерева увеличилась } n:char; { клавиша подсказки } Ta,Tb, { координаты начала вывода дерева } a,b:integer; { координаты вывода подсказки } count:byte; { счетчик узлов дерева } Procedure Note; { процедура вывода подсказки } Begin TextBackground (white); GotoXY(5,25); textcolor(black); write('B-новое дерево S-поиск по ключу '); write (' D-удаление по ключу Esc-выход'); End; Procedure Create (x:integer; var p:ref; var h:boolean); { создание нового дерева } Begin NEW(p); h:=true; with p^ do begin key:=x; left:=nil; right:=nil; bal:=0; end; if count=0 then root:=p; count:=count+1; End; Procedure Search(x:integer; var p,root:ref; var h:boolean); var p1,p2:ref; {h=false} Begin if p=nil then Create(x,p,h) {слова нет в дереве,включить его} else if x < p^.key then begin Search(x,p^.left,root,h); if h then {выросла левая ветвь} case p^.bal of 1: begin p^.bal:=0; h:=false; end; 0: p^.bal:=-1; -1: begin {балансировка} if p=root then root:=p^.left; {смена указателя на вершину} p1:=p^.left; if p1^.bal=-1 then begin {однократный LL-поворот} p^.left:=p1^.right; p1^.right:=p; p^.bal:=0; p:=p1; end else begin {2-х кратный LR-поворот} if p1=root then root:=p1^.right; p2:=p1^.right; p1^.right:=p2^.left; p2^.left:=p1; p^.left:=p2^.right; p2^.right:=p; if p2^.bal=-1 then p^.bal:=+1 else p^.bal:=0; if p2^.bal=+1 then p1^.bal:=-1 else p1^.bal:=0; p:=p2; end; p^.bal:=0; h:=false; end; end; end else if x > p^.key then begin Search(x,p^.right,root,h); if h then {выросла правая ветвь} case p^.bal of -1: begin p^.bal:=0; h:=false; end; 0: p^.bal:=+1; 1: begin {балансировка} if p=root then root:=p^.right; {смена указателя на вершину} p1:=p^.right; if p1^.bal=+1 then begin {однократный RR-поворот} p^.right:=p1^.left; p1^.left:=p; p^.bal:=0; p:=p1; end else begin {2-х кратный RL-поворот} if p1=root then root:=p1^.left; p2:=p1^.left; p1^.left:=p2^.right; p2^.right:=p1; p^.right:=p2^.left; p2^.left:=p; if p2^.bal=+1 then p^.bal:=-1 else p^.bal:=0; if p2^.bal=-1 then p1^.bal:=+1 else p1^.bal:=0; p:=p2; end; p^.bal:=0; h:=false; end; end; end; End {Search}; Procedure Delete (x:integer; var p,root:ref; var h:boolean); var q:ref; {h:false} procedure balance_L ( var p:ref; var h:boolean); {уменьшается высота левого поддерева} var p1,p2:ref; b1,b2:-1..+1; begin {h-true,левая ветвь стала короче} case p^.bal of -1: p^.bal:=0; 0: begin p^.bal:=+1; h:=false; end; 1: begin {балансировка} p1:=p^.right; b1:=p1^.bal; if b1 >= 0 then begin {однократный RR-поворот} if p=root then root:=p^.left; p^.right:=p1^.left; p1^.left:=p; if b1 = 0 then begin p^.bal:=+1; p1^.bal:=-1; h:=false; end else begin p^.bal:=0; p1^.bal:=0; end; p:=p1; end else begin {2-х кратный RL-поворот} if p1=root then root:=p1^.left; p2:=p1^.left; b2:=p2^.bal; p1^.left:=p2^.right; p2^.right:=p1; p^.right:=p2^.left; p2^.left:=p; if b2=+1 then p^.bal:=-1 else p^.bal:=0; if b2=-1 then p1^.bal:=+1 else p1^.bal:=0; p:=p2; p2^.bal:=0; end; end; end; end; {balance_L} procedure balance_R (var p:ref; var h:boolean); {уменьшается высота правого поддерева} var p1,p2:ref; b1,b2:-1..+1; begin {h-true,правая ветвь стала короче} case p^.bal of 1: p^.bal:=0; 0: begin p^.bal:=-1; h:=false; end; -1: begin {балансировка} p1:=p^.left; b1:=p1^.bal; if b1 nil then begin Del(r^.right,h); if h then balance_R(r,h); end else begin q^.key:=r^.key; r:=r^.left; h:=true; end; end;{Del} Begin {Delete} if p=nil then begin TextColor(white); GotoXY(a,b+2); write ('Ключа в дереве нет'); h:=false; end else if x < p^.key then begin Delete(x,p^.left,root,h); if h then balance_L(p,h); end else if x > p^.key then begin Delete(x,p^.right,root,h); if h then balance_R(p,h); end else begin {удаление p^} q:=p; if q^.right=nil then begin p:=q^.left; h:=true; end else if q^.left=nil then begin p:=q^.right; h:=true; end else begin Del(q^.left,h); if h then balance_L(p,h); end; {dispose(q);} GotoXY(a,b); writeln('Узел с ключом ',x,' удален из дерева.'); end; End{Delete}; Procedure OutTree(pr:ref;f:byte); Begin Tb:=Tb+2; If f=1 then Ta:=Ta-2; if f=2 then Ta:=Ta+8; if pr<>nil then begin GotoXY(TA,TB); case f of 0: Writeln('[',pr^.key,']'); 1: Writeln('[',pr^.key,']/'); 2: Writeln('\[',pr^.key,']'); end; OutTree(pr^.left,1); OutTree(pr^.right,2); end; Tb:=Tb-2; Ta:=Ta-2; End; {OutTree} BEGIN {main program} L4: count:=0; a:=25; b:=5; TextBackground(black); ClrScr; TextBackground (red); gotoxy(a,b); textcolor(white); writeln(' WELCOME TO THE LAND '); gotoxy(a,b+1); WRITE(' OF BALANCED TREES '); while n <> #27 do begin note; n:=readkey; case n of #66: goto L1; {'B'} #68: goto L3; {'D'} #83: goto L2; {'S'} #98: begin {'b'} L1: clrscr; TextBackground (green); gotoxy(a,b); writeln ('Введите ключ для нового дерева'); gotoxy(a+32,b); read(x); Create(x,p,h); end; #115: begin {'s'} L2: ClrScr; TextBackground (blue); gotoxy(a,b); TextColor(white); writeln('Введите ключ для поиска и включения'); gotoxy(a+40,b); read(x); Search(x,p,root,h); Ta:=26; Tb:=10; OutTree(root,0); end; #100: begin {'d'} L3: ClrScr; TextBackground (yellow); gotoxy(a,b); TextColor(black); writeln('Введите ключ для удаления узла'); gotoxy(a+32,b); read(x); Delete(x,p,root,h); Ta:=26; Tb:=10; OutTree(root,0); end; end; end; Dispose(p); ClrScr; TextBackground (red); GotoXY(a,b); TextColor(white); writeln('Are you sure? Yes/No'); GotoXY (a+23,b); n:=readkey; if (n=#78) or (n=#110) then goto L4; END. {main program}
Описание работы:
Описание работы:
П.1 - осуществляется поиск места для вставки элемента. Производится последовательный рекурсивный вызов процедурой самой себя. При нахождении места для вставки к дереву добавляется новый элемент с помощью процедуры ВСТАВИТЬ_ЭЛЕМЕНТ. П.2 - Если такой элемент уже существует в дереве, то выводится сообщение об этом и выполнение процедуры завершается. П.3 (П.5) - производит изменение показателей сбалансированности после включения нового элемента в левое (правое для П.5) поддерево. П.4 (П.6) - производит балансировку дерева путем перестановки указателей - т.е. LL- и LR-повороты (RR- и RL-повороты в П.6) П.7 - с помощью рекурсивных вызовов в стеке запоминается весь путь до места создания новой вершины. В П.7 производится обратный обход дерева, корректировка всех изменившихся показателей сбалансированности (в П. 3 и 5) и при необходимости балансировка. Это позволяет производить правильную балансировку, даже если критическая вершина находится далеко то места вставки.
ОПИСАНИЕ РАБОТЫ:
П.1 - производится рекурсивный поиск самого правого элемента в поддереве. Если элемент найден, то он ставится на место удаленного элемента, устанавливается флаг удаления, и осуществляется выход. Если установлен флаг удаления элемента, то вызывается процедура балансировки. П.5 - т.к. эта процедура рекурсивная, то производится возврат в место предыдущего вызова, либо в вызывающую процедуру (Delete).
Описание работы алгоритма:
ОПИСАНИЕ РАБОТЫ АЛГОРИТМА:
П.1 - осуществляет поиск удаляемого элемента с помощью рекурсивных вызовов процедуры Delete (т.е. - самой себя). При этом в стеке сохраняется весь путь поиска. Если было произведено удаление элемента, то производится вызов соответствующей процедуры балансировки. Если элемент с заданным ключом не найден, то выводится соответствующее сообщение. П.2 - производится удаление элемента с одной ветвью простым переносом указателя. Устанавливается флаг удаления элемента. П.3 - производится вызов процедуры Del, производящей удаление элемента с двумя поддеревьями. П.5 - т.к. эта процедура рекурсивная, то производится возврат в место предыдущего вызова, либо в главную программу.
ОПИСАНИЕ РАБОТЫ АЛГОРИТМА:
П.1 - если вершина не является критической, то производится изменение показателей сбалансированности. Если вершина критическая - создаются вспомогательные указатели. П.2 и 3 - производят балансировку дерева однократным RR(п.2) и двукратным RL- (п.3) поворотами и изменение показателей сбалансированности.
Определения.
ОПРЕДЕЛЕНИЯ.
Одной из наиболее часто встречающихся задач является поиск необходимых данных. Существуют различные методы, отличающиеся друг от друга временем поиска, сложностью алгоритмов, размерами требуемой памяти. Обычно стремятся всячески сократить время, затрачиваемое на поиск необходимого элемента. Одним из самых быстрых методов является поиск по упорядоченному бинарному дереву. При удачной структуре дерева время поиска элементов не превышает в среднем log N. Но при неудачной структуре время поиска может значительно возрасти, достигая N\2. ( N - число элементов дерева).
Одним из методов, улучшающих время поиска в бинарном дереве является создание сбалансированных деревьев обладающих минимальным временем поиска.
Одно из определений сбалансированности было дано Адельсоном-Вельским и Ландисом:
Дерево является СБАЛАНСИРОВАННЫМ тогда и только тогда, когда для каждого узла высота его двух поддеревьев различается не более чем на 1.
Поэтому деревья, удовлетворяющие этому условию, часто называют "АВЛ-деревьями" (по фамилиям их изобретателей).
Операции выполняемые над сбалансированным деревом: поиск, вставка, удаление элемента.
Обратимся к задаче поддержания структуры дерева таким образом, чтобы за время, не превышающее (log N), могла быть выполнена каждая из следующих операций:
1) вставить новый элемент; 2) удалить заданный элемент; 3) поиск заданного элемента.
С тем чтобы предупредить появление несбалансированного дерева, вводится для каждого узла (вершины) дерева показатель сбалансированности, который не может принимать одно из трех значений, левое - (L), правое - (R), сбалансированное - (B), в соответствии со следующими определениями:
левое - узел левоперевешивающий, если самый длинный путь по ее левому поддереву на единицу больше самого длинного пути по ее правому поддереву;
сбалансированное - узел называется сбалансированный, если равны наиболее длинные пути по обеим ее поддеревьям;
правое - узел правоперевешивающий, если самый длинный путь по ее правому поддереву на единицу больше самого длинного пути по ее левому поддереву;
В сбалансированном дереве каждый узел должен находится в одном из этих трех состояний. Если в дереве существует узел, для которого это условие несправедливо, такое дерево называется несбалансированным.
Перебор элементов списка.
Перебор элементов списка.
Эта операция, возможно, чаще других выполняется над линейными списками. При ее выполнении осуществляется последовательный доступ к элементам списка - ко всем до конца списка или до нахождения искомого элемента.
Алгоритм перебора для односвязного списка представляется программным примером 5.1.
{==== Программный пример 5.1 ====} { Перебор 1-связного списка } Procedure LookSll(head : sllptr); { head - указатель на начало списка } var cur : sllptr; { адрес текущего элемента } begin cur:=head; { 1-й элемент списка назначается текущим } while cur <> nil do begin < обработка c^.inf >
{обрабатывается информационная часть того эл-та, на который указывает cur. Обработка может состоять в:
печати содержимого инф.части; модификации полей инф.части; сравнения полей инф.части с образцом при поиске по ключу; подсчете итераций цикла при поиске по номеру; и т.д., и т.п. }
cur:=cur^.next;
{ из текущего эл-та выбирается указатель на следующий эл-т и для следующей итерации следующий эл-т становится текущим; если текущий эл-т был последний, то его поле next содержит пустой указатель и, т.обр. в cur запишется nil, что приведет к выходу из цикла при проверке условия while }
end; end;
В двухсвязном списке возможен перебор как в прямом направлении (он выглядит точно так же, как и перебор в односвязном списке), так и в обратном. В последнем случае параметром процедуры должен быть tail - указатель на конец списка, и переход к следующему элементу должен осуществляться по указателю назад:
cur:=cur^.prev;
В кольцевом списке окончание перебора должно происходить не по признаку последнего элемента - такой признак отсутствует, а по достижению элемента, с которого начался перебор. Алгоритмы перебора для двусвязного и кольцевого списка мы оставляем читателю на самостоятельную разработку.
Перестановка элементов списка.
Перестановка элементов списка.
Изменчивость динамических структур данных предполагает не только изменения размера структуры, но и изменения связей между элементами. Для связных структур изменение связей не требует пересылки данных в памяти, а только изменения указателей в элементах связной структуры. В качестве примера приведена перестановка двух соседних элементов списка. В алгоритме перестановки в односвязном списке (рис.5.9, пример 5.5) исходили из того, что известен адрес элемента, предшествующего паре, в которой производится перестановка. В приведенном алгоритме также не учитывается случай перестановки первого и второго элементов.
Поиск элемента.
ПОИСК ЭЛЕМЕНТА.
Поиск элемента в сбалансированном дереве уже применялся в операциях вставки и удаления элементов. Поэтому необходимо отдельно рассмотреть эту операцию.
Пусть дано некоторое бинарное дерево, в котором каждый левый элемент меньше вышележащего, а правый - больше.
Для нахождения элемента с заданным ключом начинаем поиск с корневого элемента, сравнивая его ключ с искомым. Если искомый ключ меньше, то продолжаем поиск по левому поддереву (так как его элемент меньше текущего), а если ключ больше - то по правому (его элемент больше). Сравнивая аналогичным образом искомый ключ с ключом текущего элемента мы будем последовательно спускаться по дереву до тех пор, пока ключи искомого и текущего элемента не совпадут - элемент найден. Если мы дошли до уровня листьев (ниже элементов уже нет), а элемент не найден, значит он отсутствует в дереве.
Этот алгоритм пригоден для поиска в любых бинарных деревьях, но при работе со сбалансированными деревьями время поиска элемента минимально.
Поиск записи в дереве( find ).
ПОИСК ЗАПИСИ В ДЕРЕВЕ( Find ).
Нужная вершина в дереве ищется по ключу. Поиск в бинарном дереве осуществляется следующим образом.
Пусть построено некоторое дерево и требуется найти звено с ключом X. Сначала сравниваем с X ключ, находящийся в корне дерева. В случае равенства поиск закончен и нужно возвратить указатель на корень в качестве результата поиска. В противном случае переходим к рассмотрению вершины, которая находится слева внизу, если ключ X меньше только что рассмотренного, или справа внизу, если ключ X больше только что рассмотренного. Сравниваем ключ X с ключом, содержащимся в этой вершине, и т.д. Процесс завершается в одном из двух случаев:
1) найдена вершина, содержащая ключ, равный ключу X; 2) в дереве отсутствует вершина, к которой нужно перейти для выполнения очередного шага поиска.
В первом случае возвращается указатель на найденную вершину. Во втором - указатель на звено, где остановился поиск, (что удобно для построения дерева ). Реализация функции Find приведена в программном примере 6.2.
{=== Программный пример 6.2. Поиск звена по ключу === } Function Find(k:KeyType;d:TreePtr;var rez:TreePtr):bollean; { где k - ключ, d - корень дерева, rez - результат } Var p,g: TreePtr; b: boolean; Begin b:=false; p:=d; { ключ не найден } if d <> NIL then repeat q: =p; if p^.key = k then b:=true { ключ найден } else begin q:=p; { указатель на отца } if k < p^.key then p:=p^.left { поиск влево } else p:=p^.right { поиск вправо} end; until b or (p=NIL); Find:=b; rez:=q; End; { Find }
Поразрядная цифровая сортировка.
Поразрядная цифровая сортировка.
Алгоритм требует представления ключей сортируемой последовательности в виде чисел в некоторой системе счисления P. Число проходов сортировка равно максимальному числу значащих цифр в числе - D. В каждом проходе анализируется значащая цифра в очередном разряде ключа, начиная с младшего разряда. Все ключи с одинаковым значением этой цифры объединяются в одну группу. Ключи в группе располагаются в порядке их поступления. После того, как вся исходная последовательность распределена по группам, группы располагаются в порядке возрастания связанных с группами цифр. Процесс повторяется для второй цифры и т.д., пока не будут исчерпаны значащие цифры в ключе. Основание системы счисления P может быть любым, в частном случае 2 или 10. Для системы счисления с основанием P требуется P групп.
Порядок алгоритма качественно линейный - O(N), для сортировки требуется D*N операций анализа цифры. Однако, в такой оценке порядка не учитывается ряд обстоятельств.
Во-первых, операция выделения значащей цифры будет простой и быстрой только при P=2, для других систем счисления эта операция может оказаться значительно более времяемкой, чем операция сравнения.
Во-вторых, в оценке алгоритма не учитываются расходы времени и памяти на создание и ведение групп. Размещение групп в статической рабочей памяти потребует памяти для P*N элементов, так как в предельном случае все элементы могут попасть в какую-то одну группу. Если же формировать группы внутри той же последовательности по принципу обменных алгоритмов, то возникает необходимость перераспределения последовательности между группами и все проблемы и недостатки, присущие алгоритмам включения. Наиболее рациональным является формирование групп в виде связных списков с динамическим выделением памяти.
В программном примере 3.15 мы, однако, применяем поразрядную сортировку к статической структуре данных и формируем группы на том же месте, где расположена исходная последовательность. Пример требует некоторых пояснений.
Область памяти, занимаемая массивом перераспределяется между входным и выходным множествами, как это делалось и в ряде предыдущих примеров. Выходное множество (оно размещается в начале массива) разбивается на группы. Разбиение отслеживается в массиве b. Элемент массива b[i] содержит индекс в массиве a,с которого начинается i+1-ая группа. Номер группы определяется значением анали- зируемой цифры числа, поэтому индексация в массиве b начинается с 0. Когда очередное число выбирается из входного множества и должно быть занесено в i-ую группу выходного множества, оно будет записано в позицию, определяемую значением b[i]. Но предварительно эта позиция должна быть освобождена: участок массива от b[i] до конца выходного множества включительно сдвигается вправо. После записи числа в i-ую группу i-ое и все последующие значения в массиве b корректируются - увеличиваются на 1.
{===== Программный пример 3.15 =====} { Цифровая сортировка (распределение) } const D=...; { максимальное количество цифр в числе } P=...; { основание системы счисления } Function Digit(v, n : integer) : integer; { возвращает значение n-ой цифры в числе v } begin for n:=n downto 2 do v:=v div P; Digit:=v mod P; end; Procedure Sort(var a : Seq); Var b : array[0..P-2] of integer; { индекс элемента, следующего за последним в i-ой группе } i, j, k, m, x : integer; begin for m:=1 to D do begin { перебор цифр, начиная с младшей } for i:=0 to P-2 do b[i]:=1; { нач. значения индексов } for i:=1 to N do begin { перебор массива } k:=Digit(a[i],m); { определение m-ой цифры } x:=a[i]; { сдвиг - освобождение места в конце k-ой группы } for j:=i downto b[k]+1 do a[j]:=a[j-1]; { запись в конец k-ой группы } a[b[k]]:=x; { модификация k-го индекса и всех больших } for j:=k to P-2 do b[j]:=b[j]+1; end; end;
Результаты трассировки программного примера 3.15 при P=10 и D=4 представлены в таблице 3.9.
Порядок.
Порядок.
Над элементами списка задано транзитивное отношение, определяемое последовательностью, в которой элементы появляются внутри списка. В списке (x,y,z) атом x предшествует y, а y предшествует z. При этом подразумевается, что x предшествует z. Данный список не эквивалентен списку (y,z,x). При представлении списков графическими схемами порядок определяется горизонтальными стрелками. Горизонтальные стрелки истолковываются следующим образом: элемент из которого исходит стрелка,предшествует элементу, на который она указывает.
Представление битовых типов.
Представление битовых типов.
В ряде задач может потребоваться работа с отдельными двоичными разрядами данных. Чаще всего такие задачи возникают в системном программировании, когда, например, отдельный разряд связан с состоянием отдельного аппаратного переключателя или отдельной шины передачи данных и т.п. Данные такого типа представляются в виде набора битов, упакованных в байты или слова, и не связанных друг с другом. Операции над такими данными обеспечивают доступ к выбранному биту данного. В языке PASCAL роль битовых типов выполняют беззнаковые целые типы byte и word. Над этими типами помимо операций, характерных для числовых типов, допускаются и побитовые операции. Аналогичным образом роль битовых типов играют беззнаковые целые и в языке C.
В языке PL/1 существует специальный тип данных - строка битов, объявляемый в программе, как: BIT(n).
Данные этого типа представляют собой последовательность бит длиною n. Строка битов занимает целое число байт в памяти и при необходимости дополняется справа нулями.
Представление разреженных матриц методом связанных структур.
Представление разреженных матриц методом связанных структур.
Методы последовательного размещения для представления разреженных матриц обычно позволяют быстрее выполнять операции над матрицами и более эффективно использовать память, чем методы со связанными структурами. Однако последовательное представление матриц имеет определенные недостатки. Так включение и исключение новых элементов матрицы вызывает необходимость перемещения большого числа других элементов. Если включение новых элементов и их исключение осуществляется часто, то должен быть выбран описываемый ниже ме- тод связанных структур.
Метод связанных структур, однако, переводит представляемую структуру данных в другой раздел классификации. При том, что логическая структура данных остается статической, физическая структура становится динамической.
Для представления разреженных матриц требуется базовая структура вершины (рис.3.6), называемая MATRIX_ELEMENT ("элемент матрицы"). Поля V, R и С каждой из этих вершин содержат соответственно значение, индексы строки и столбца элемента матрицы. Поля LEFT и UP являются указателями на следующий элемент для строки и столбца в циклическом списке, содержащем элементы матрицы. Поле LEFT указывает на вершину со следующим наименьшим номером строки.
Представление разреженным матриц методом последовательного размещения.
Представление разреженным матриц методом последовательного размещения.
Один из основных способов хранения подобных разреженных матриц заключается в запоминании ненулевых элементов в одномерном массиве и идентификации каждого элемента массива индексами строки и столбца, как это показано на рис. 3.5 а).
Доступ к элементу массива A с индексами i и j выполняется выборкой индекса i из вектора ROW, индекса j из вектора COLUM и значения элемента из вектора A. Слева указан индекс k векторов наибольшеее значение, которого определяется количеством нефоновых элементов. Отметим, что элементы массива обязательно запоминаются в порядке возрастания номеров строк.
Более эффективное представление, с точки зрения требований к памяти и времени доступа к строкам матрицы, показано на рис.3.5.б). Вектор ROW уменьшнен, количество его элементов соответствует числу строк исходного массива A, содержащих нефоновые элементы. Этот вектор получен из вектора ROW рис. 3.5.а) так, что его i-й элемент является индексом k для первого нефонового элемента i-ой строки.
Представление матрицы А, данное на рис. 3.5 сокращает требования к объему памяти более чем в 2 раза. Для больших матриц экономия памяти очень важна. Способ последовательного распределения имеет также то преимущество, что операции над матрицами могут быть выполнены быстрее, чем это возможно при представлении в виде последовательного двумерного массива, особенно если размер матрицы велик.
Представление строк вектором переменной длины с признаком конца.
ПРЕДСТАВЛЕНИЕ СТРОК ВЕКТОРОМ ПЕРЕМЕННОЙ ДЛИНЫ С ПРИЗНАКОМ КОНЦА.
Этот и все последующие за ним методы учитывают переменную длину строк. Признак конца - это особый символ, принадлежащий алфавиту (таким образом, полезный алфавит оказывается меньше на один символ), и занимает то же количество разрядов, что и все остальные символы. Издержки памяти при этом способе составляют 1 символ на строку. Такое представление строки показано на рис.4.4. Специальный символ-маркер конца строки обозначен здесь 'eos'. В языке C, например, в качестве маркера конца строки используется символ с кодом 0.
Представление строк вектором переменной длины со счетчиком.
ПРЕДСТАВЛЕНИЕ СТРОК ВЕКТОРОМ ПЕРЕМЕННОЙ ДЛИНЫ СО СЧЕТЧИКОМ.
Счетчик символов - это целое число, и для него отводится достаточное количество битов, чтобы их с избытком хватало для представления длины самой длинной строки,какую только можно представить в данной машине. Обычно для счетчика отводят от 8 до 16 битов. Тогда при таком представлении издержки памяти в расчете на одну строку составляют 1-2 символа. При использовании счетчика символов возможен произвольный доступ к символам в пределах строки, поскольку можно легко проверить, что обращение не выходит за пределы строки. Счетчик размещается в таком месте, где он может быть легко доступен - начале строки или в дескрипторе строки. Максимально возможная длина строки, таким образом, ограничена разрядностью счетчика. В PASCAL, например, строка представляется в виде массива символов, индексация в котором начинается с 0; однобайтный счетчик числа символов в строке является нулевым элементом этого массива. Такое представление строк показано на рис.4.5. И счетчик символов, и признак конца в предыдущем случае могут быть доступны для программиста как элементы вектора.
Представление в памяти.
Представление в памяти.
Для представления чисел со знаком в ряде компьютеров был использован метод, называемый методом знака и значения. Обычно для знака отводится первый (или самый левый) бит двоичного числа затем следует запись самого числа.
Например, +10 и -15 в двоичном виде можно представить так:
Отметим, что по соглашению 0 используется для представления знака плюс и 1 - для минуса. Такое представление удобно для программистов т.к. легко воспринимается, но не является экономичным.
Если требуется сложить или вычесть два числа, то для решения вопроса о том, какие действия следует при этом предпринять, надо сначала определить знак каждого числа. Например, сложение чисел +6 и -7 на самом деле подразумевает операцию вычитания, а вычитание -6 из +7 операцию сложения. Для анализа знакового бита требуется особая схема и, кроме того, при представлении числа в виде знака и величины необходимы отдельные устройства для сложения и вычитания, т.е., если положительное и отрицательные числа представлены в прямом коде, операции над кодами знаков выполняются раздельно. Поэтому представление чисел в виде знака и значения не нашло широкого применения.
В то же время, при помощи обратного и дополнительного кодов, используемых для представления отрицательных чисел, операция вычитания (алгебраического сложения) сводится к операции простого арифметического сложения. При этом операция сложения распространяется и на разряды знаков, рассматриваемых как разряды целой части числа. Именно поэтому для представления целых чисел со знаком применяется дополнительный код.
Дополнительный код отрицательного числа формируется по следующим правилам:
модуль отрицательного числа записать в прямом коде, в неиспользуемые старшие биты записать нули; сформировать обратный код числа, для этого нуль заменить единицей, а единицу заменить нулем; к обратному коду числа прибавить единицу.
Например, для числа -33 в формате integer: 1000000000100001 прямой код 0111111111011110 обратный код +_______________1 1111111111011111 дополнительный кодДля положительных чисел прямой, обратный и дополнительный коды одинаковы. Аналогично представляются целые числа в формате shortint, longint, comp.
При разработке программ на этапе выбора типа данных важно знать диапазон целых величин, которые могут храниться в n разрядах памяти. В соответствии с алгоритмом преобразования двоичных чисел в десятичные, формула суммирования для n разрядов имеет вид:
n-1 2^0 + 2^1 + 2^3 + ... + 2^(n-1), или СУММА (2^i) = 2^n - 1. i=0При n-битовом хранении числа в дополнительном коде первый бит выражает знак целого числа. Поэтому положительные числа представляются в диапазоне от 0 до 1*2^0 + 1*2^1 +...+ 1*2^(n-2) или от 0 до 2^(n-1) - 1. Все другие конфигурации битов выражают отрицательные числа в диапазоне от -2^(n-1) до -1. Таким образом, можно сказать, что число N может храниться в n разрядах памяти, если его значение находится в диапазоне:
-2^(n-1) В некоторых областях вычислений требуются очень большие или весьма малые действительные числа. Для получения большей точности применяют запись чисел с плавающей точкой. Запись числа в формате с плавающей точкой является весьма эффективным средством представления очень больших и весьма малых вещественных чисел при условии, что они содержат ограниченное число значащих цифр, и, следовательно, не все вещественные числа могут быть представлены в памяти. Обычно число используемых при вычислениях значащих цифр таково, что для большинства задач ошибки округления пренебрежимо малы.
Формат для представления чисел с плавающей точкой содержит одно или два поля фиксированной длины для знаков. Количество позиций для значащих цифр различно в разных ЭВМ, но существует, тем не менее, общий формат, приведенный на рисунке 2.5 а). В соответствии с этой записью формат вещественного числа содержит в общем случае поля мантиссы, порядка и знаков мантиссы и порядка.
Узел, который необходимо удалить, обозначен двойной рамкой. Если задано сбалансированное дерево (рис.6.35. a), то последовательное удаление узлов с ключами 4,8,6,5,2,1 и 7 дает деревья (рис.6.35 b...h).
Удаление ключа 4 само по себе просто, т.к. он представляет собой терминальный узел. Однако при этом появляется несбалансированность в узле 3. Его балансировка требует однократного левого поворота налево. Балансировка вновь становится необходимой после удаления узла 6. На этот раз правое поддерево корня балансируется однократным поворотом направо.
Удаление узла 2, хотя само по себе просто, так как он имеет только одного потомка, вызывает сложный двукратный поворот направо и налево.
И четвертый случай: двукратный поворот налево и направо вызывается удалением узла 7, который прежде заменяется самым правым элементом левого поддерева, т.е. узлом с ключом 3.
Рассмотрим бинарное дерево представленное на рис. 6.28 (а), которое состоит только из двух узлов. Включение ключа 7 дает вначале несбалансированное дерево (т.е. линейный список). Его балансировка требует однократного правого (RR) поворота, давая в результате идеально сбалансированное дерево (b). Последующее включение узлов 2 и 1 дает несбалансированное поддерево с корнем 4. Это поддерево балансируется однократным левым (LL) поворотом (d). Далее включение ключа 3 сразу нарушает критерий сбалансированности в корневом узле 5.
Сбалансированность теперь восстанавливается с помощью более сложного двукратного поворота налево и направо (LR); результатом является дерево (e). Теперь при следующем включении потерять сбалансированность может лишь узел 5. Действительно, включение узла 6 должно привести к четвертому виду балансировки: двукратному повороту направо и налево (RL). Окончательное дерево показано на рис.6.35 (а-f).
Создается семимерный массив меток и его элементам задаются требуемые значения.Оператор генерирует метку исходя из значения поля корневой вершины. И передается управление управление оператору, помеченного меткой. Если данная вершина концевая, то в качестве значения выдается значение переменной или константы, обозначенной этой вершиной. Эта операция выполняется путем использования правого указателя данной вершины для ссылки на нужную запись в таблице символов. Для неконцевой вершины инициализируются рекурсивные вычисления ее поддеревьев, характеризующих операнды текущего оператора. Этот процесс продолжается до тех пор, пока не будут достигнуты листья дерева. Для полученных листьев значения выбираются из соответствующих записей таблицы символов.
Ниже приводится программа, вычисляющая арифметическое выражение.
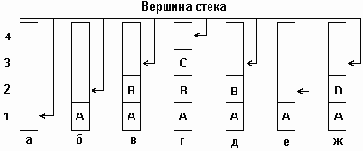
Процедуры обхода дерева, использующие стек.
ПРОЦЕДУРЫ ОБХОДА ДЕРЕВА, ИСПОЛЬЗУЮЩИЕ СТЕК.
Тип стека при нисходящем обходе.
Stack=^Zveno; Zveno = record next: Stack; El: pointer; end;
Процедура включения элемента в стек при нисходящем и смешанном обходе ( Push_st ) приведена в программном примере 6.10.
{ === Програмнный пример 6.10 ====} Procedure Push_st (var st: stack; p: pointer); Var q: stack; begin new(q); q^.el:=p; q^.next:=st; st:=q; end;
Функция извлечения элемента из стека при нисходящем и смешанном обходе ( Pop_st ) приведена в программном примере 6.11.
{ === Програмнный пример 6.11 ====} Function Pop_st (var st: stack):pointer; Var e,p: stack begin Pop_st:=st^.el; e:=st; { запоминаем указатель на текущую вершину } st:=st^.next;{сдвигаем указатель стека на следующий элемент} dispose(e); { возврат памяти в кучу } end;
При восходящем обходе может быть предложен следующий тип стека:
point=^st; st = record next: point; l: integer; add: pointer; end;
Процедура включения элемента в стек при восходящем обходе ( S_Push ) приведена в программном примере 6.12.
{ === Програмнный пример 6.12 ====} Procedure S_Push (var st: point; Har: integer; add: pointer); Var q: point; begin new(q); { выделяем место для элемента } q^.l:=Har; { заносим характеристику } q^.add:=add; { заносим указатель } q^.next:=st; { модифицируем стек } st:=q; end;
Функция извлечения элемента из стека при восходящем обходе (S_Pop) демонстрируется в программном примере 6.13.
{ === Програмнный пример 6.13 ====} Function S_Pop (var st: point; var l: integer):pointer; Var e,p: point; begin l:=st^.l; S_Pop:=st^.add; e:=st; { запоминаем указатель на текущую вершину} st:=st^.next; {сдвигаем указатель стека на след. элемент } dispose(e); { уничтожаем выбранный элемент } end;
Прошивка бинарных деревьев.
ПРОШИВКА БИНАРНЫХ ДЕРЕВЬЕВ.
Под прошивкой дерева понимается замена по определенному правилу пустых указателей на сыновей указателями на последующие узлы, соответствующие обходу.
Рассматривая бинарное дерево, легко обнаружить, что в нем имеются много указателей типа NIL. Действительно в дереве с N вершинами имеется ( N+1 ) указателей типа NIL. Это незанятое пространство можно использовать для изменения представления деревьев. Пустые указатели заменяются указателями - "нитями", которые адресуют вершины дерева, и расположенные выше. При этом дерево прошивается с учетом определенного способа обхода. Например, если в поле left некоторой вершины P стоит NIL, то его можно заменить на адрес, указывающий на предшественника P, в соответствии с тем порядком обхода, для которого прошивается дерево. Аналогично, если поле right пусто, то указывается преемник P в соответствии с порядком обхода.
Поскольку после прошивания дерева поля left и right могут характеризовать либо структурные связи, либо "нити", возникает необходимость различать их, для этого вводятся в описание структуры дерева характеристики левого и правого указателей (FALSE и TRUE).
Таким образом, прошитые деревья быстрее обходятся и не требуют для этого дополнительной памяти (стек), однако требуют дополнительной памяти для хранения флагов нитей, а также усложнены операции включения и удаления элементов дерева.
Прошитое бинарное дерево на Паскале можно описать следующим образом:
type TreePtr:=^S_Tree; S_Tree = record key: KeyType; { ключ } left,right: TreePtr; { левый и правый сыновья } lf,rf: boolean; { характеристики связей } end;
где lf и rf - указывают, является ли связь указателем на элемент или нитью. Если lf или rf равно FALSE, то связка является нитью.
До создания дерева головная вершина имеет следующий вид: Здесь пунктирная стрелка определяет связь по нити. Дерево подшивается к левой ветви.
Пузырьковая сортировка.
Пузырьковая сортировка.
Входное множество просматривается, при этом попарно сравниваются соседние элементы множества. Если порядок их следования не соответствует заданному критерию упорядоченности, то элементы меняются местами. В результате одного та- кого просмотра при сортировке по возрастанию элемент с самым большим значением ключа переместится ("всплывет") на последнее место в множестве. При следующем проходе на свое место "всплывет" второй по величине ключа элемент и т.д. Для постановки на свои места N элементов следует сделать N-1 проходов. Выходное множество, таким образом, формируется в конце сортируемой последовательности, при каждом следующем проходе его объем увеличивается на 1, а объем входного множества уменьшается на 1.
Порядок пузырьковой сортировки - O(N^2). Среднее число сравнений - N*(N-1)/2 и таково же среднее число перестановок, что значительно хуже, чем для обменной сортировки простым выбором. Однако, то обстоятельство, что здесь всегда сравниваются и перемещаются только соседние элементы, делает пузырьковую сортировку удобной для обработки связных списков. Перестановка в связных списках также получается более экономной.
Еще одно достоинство пузырьковой сортировки заключается в том, что при незначительных модификациях ее можно сделать чувствительной к исходной упорядоченности входного множества. Рассмотрим некоторые их таких модификаций.
Во-первых, можно ввести некоторую логическую переменную, которая будет сбрасываться в false перед началом каждого прохода и устанавливаться в true при любой перестановке. Если по окончании прохода значение этой переменной останется false, это означает, что менять местами больше нечего, сортировка закончена. При такой модификации поступление на вход алгоритма уже упорядоченного множества потребует только одного просмотра.
Во-вторых, может быть учтено то обстоятельство, что за один просмотр входного множества на свое место могут "всплыть" не один, а два и более элементов. Это легко учесть, запоминая в каждом просмотре позицию последней перестановки и установки этой позиции в качестве границы между множествами для следующего просмотра. Именно эта модификация реализована в программной иллюстрации пузырьковой сортировке в примере 3.9. Переменная nn в каждом проходе устанавливает верхнюю границу входного множества. В переменной x запоминается позиция перестановок и в конце просмотра последнее запомненное значение вносится в nn. Сортировка будет закончена, когда верхняя граница входного множества станет равной 1.
{===== Программный пример 3.9 =====} Procedure Sort( var a : seq); Var nn, i, x : integer; begin nn:=N; { граница входного множества } repeat x:=1; { признак перестановок } for i:=2 to nn do { перебор входного множества } if a[i-1] > a[i] then begin { сравнение соседних эл-в } x:=a[i-1]; a[i-1]:=a[i]; a[i]:=x; { перестановка } x:=i-1; { запоминание позиции } end; nn:=x; { сдвиг границы } until (nn=1); {цикл пока вых. множество не захватит весь мас.} end;
Результаты трассировки программного примера 3.9 представлены в таблице 3.6.
Это модификация обменного варианта сортировки. В этом методе входное и выходное множества находятся в одной последовательности, причем выходное - в начальной ее части. В исходном состоянии можно считать, что первый элемент последовательности уже принадлежит упорядоченному выходному множеству, остальная часть последовательности - неупорядоченное входное. Первый элемент входного множества примыкает к концу выходного множества. На каждом шаге сортировки происходит перераспределение последовательности: выходное множество увеличивается на один элемент, а входное - уменьшается. Это происходит за счет того, что первый элемент входного множества теперь считается последним элементом выходного. Затем выполняется просмотр выходного множества от конца к началу с перестановкой соседних элементов, которые не соответствуют критерию упорядоченности. Просмотр прекращается, когда прекращаются перестановки. Это приводит к тому, что последний элемент выходного множества "выплывает" на свое место в множестве. Поскольку при этом перестановка приводит к сдвигу нового в выходном множестве элемента на одну позицию влево, нет смысла всякий раз производить полный обмен между соседними элементами - достаточно сдвигать старый элемент вправо, а новый элемент записать в выходное множество, когда его место будет установлено. Именно так и построен программный пример пузырьковой сортировки вставками - 3.12.
{===== Программный пример 3.12 =====} Procedure Sort (var a : Seq); Var i, j, k, t : integer; begin for i:=2 to N do begin { перебор входного массива } {*** вх.множество - [i..N], вых.множество - [1..i] } t:=a[i]; { запоминается значение нового эл-та } j:=i-1; {поиск места для эл-та в вых. множестве со сдвигом} { цикл закончится при достижении начала или, когда будет встречен эл-т, меньший нового } while (j >= 1) and (a[j] > t) do begin a[j+1]:=a[j]; { все эл-ты, большие нового сдвигаются } j:=j-1; { цикл от конца к началу выходного множества } end; a[j+1]:=t; { новый эл-т ставится на свое место } end; end;
Результаты трассировки программного примера 3.11 представлены в таблице 3.8.
Разреженный массив - массив, большинство элементов которого равны между собой, так что хранить в памяти достаточно лишь небольшое число значений отличных от основного (фонового) значения остальных элементов.
Различают два типа разреженных массивов:
1) массивы, в которых местоположения элементов со значениями отличными от фонового, могут быть математически описаны; 2) массивы со случайным расположением элементов.
В случае работы с разреженными массивами вопросы размещения их в памяти реализуются на логическом уровне с учетом их типа.
К данному типу массивов относятся массивы, у которых местоположения элементов со значениями отличными от фонового, не могут быть математически описаны, т. е. в их расположении нет какой-либо закономерности.
Ё 0 0 6 0 9 0 0 Ё Ё 2 0 0 7 8 0 4 Ё Ё10 0 0 0 0 0 0 Ё Ё 0 0 12 0 0 0 0 Ё Ё 0 0 0 3 0 0 5 Ё
Пусть есть матрица А размерности 5*7, в которой из 35 элементов только 10 отличны от нуля.
Алгоритм существенно упрощается при использовании рекурсии. Так, нисходящий обход можно описать следующим образом:
1). Обработка корневой вершины; 2). Нисходящий обход левого поддерева; 3). Нисходящий обход правого поддерева.
Алгоритм рекурсивного нисходящего обхода реализован в программном примере 6.5.
{=== Программный пример 6.5. Рекурсивное выполнение нисходящего обхода ===} Procedure r_Preorder (t: TreePtr); begin if t = nil then begin writeln('Дерево пусто'); exit; end; (*------------------- Обработка данных звена --------------*) ................................ if t^.left <> nil then r_Preorder(t^.left); if t^.right <> nil then r_Preorder(t^.right); End; { r_Preorder }
Текст программы процедуры рекурсивного обхода (r_Postorder) демонстрируется в програмном примере 6.9.
{ ==== Программный пример 6.9. ===== } (*--------- Рекурсивное выполнение нисходящего обхода -----*) Procedure r_Postorder (t: TreePtr); Begin if t = nil then begin writeln('Дерево пусто'); exit; end; if t^.left <> nil then r_Postorder (t^.left); if t^.right <> nil then r_Postorder (t^.right); (*-------------- Обработка данных звена --------------*) ................................ End; { r_Postorder }
Если в рассмотренных выше процедурах поменять местами поля left и right, то получим процедуры обратного нисходящего, обратного смешанного и обратного восходящего обходов.
Еще раз повторим, что физическая структура адреса принципиально различна для разных аппаратных архитектур. Так, например, в микропроцессоре i386 обе компоненты адреса 32-разрядные; в процессорах семейства S/390 адрес представляется в виде 31-разрядного смещения в одном из 19 адресных пространств, в процессоре Power PC 620 одним 64-разрядным словом может адресоваться вся как оперативная, так и внешняя память.
Операционная система MS DOS была разработана именно для процессора i8086 и использует описанную структуру адреса даже, когда выполняется на более совершенных процессорах. Однако, это сегодня единственная операционная система, в среде которой программист может работать с адресами в реальной памяти и с физической структурой адреса. Все без исключения современные модели процессоров аппаратно выполняют так называемую динамическую трансляцию адресов и совместно с современными операционными системами обеспечивают работу программ в виртуальной (кажущейся) памяти. Программа разрабатывается и выполняется в некоторой виртуальной памяти, адреса в которой линейно изменяются от 0 до некоторого максимального значения. Виртуальный адрес представляет собой число - номер ячейки в виртуальном адресном пространстве. Преобразование виртуального адреса в реальный производится аппаратно при каждом обращении по виртуальному адресу. Это преобразование выполняется совершенно незаметно (прозрачно) для программиста, поэтому в современных системах программист может считать физической структурой адреса структуру виртуального адреса. Виртуальный же адрес представляет собой целое число без знака. В разных вычислительных системах может различаться разрядность этого числа. Большинство современных систем обеспечивают 32-разрядный адрес, позволяющий адресовать до 4 Гбайт памяти, но уже существуют системы с 48 и даже 64-разрядными адресами.