Простейший случай взаимодействия двух компьютеров
В самом простом случае взаимодействие компьютеров может быть реализовано с помощью тех же самых средств, которые используются для взаимодействия компьютера с периферией, например, через последовательный интерфейс RS-232C. В отличие от взаимодействия компьютера с периферийным устройством, когда программа работает, как правило, только с одной стороны - со стороны компьютера, в этом случае происходит взаимодействие двух программ, работающих на каждом из компьютеров.
Программа, работающая на одном компьютере, не может получить непосредственный доступ к ресурсам другого компьютера - его дискам, файлам, принтеру. Она может только «попросить» об этом программу, работающую на том компьютере, которому принадлежат эти ресурсы. Эти «просьбы» выражаются в виде сообщений, передаваемых по каналам связи между компьютерами. Сообщения могут содержать не только команды на выполнение некоторых действий, но и собственно информационные данные (например, содержимое некоторого файла).
Рассмотрим случай, когда пользователю, работающему с текстовым редактором на персональном компьютере А, нужно прочитать часть некоторого файла, расположенного на диске персонального компьютера В (рис. 1.7). Предположим, что мы связали эти компьютеры по кабелю связи через СОМ-порты, которые, как известно, реализуют интерфейс RS-232C (такое соединение часто называют нуль-модемным). Пусть для определенности компьютеры работают под управлением MS-DOS, хотя принципиального значения в данном случае это не имеет.

Рис. 1.7. Взаимодействие двух компьютеров
Драйвер СОМ-порта вместе с контроллером СОМ-порта работают примерно так же, как и в описанном выше случае взаимодействия ПУ с компьютером. Однако при этом роль устройства управления ПУ выполняет контроллер и драйвер СОМ-порта другого компьютера. Вместе они обеспечивают передачу по кабелю между компьютерами одного байта информации. (В «настоящих» локальных сетях подобные функции передачи данных в линию связи выполняются сетевыми адаптерами и их драйверами.)
Драйвер компьютера В периодически опрашивает признак завершения приема, устанавливаемый контроллером при правильно выполненной передаче данных, и при его появлении считывает принятый байт из буфера контроллера в оперативную память, делая его тем самым доступным для программ компьютера В.
В некоторых случаях драйвер вызывается асинхронно, по прерываниям от контроллера.
Таким образом, в распоряжении программ компьютеров А и В имеется средство для передачи одного байта информации. Но рассматриваемая в нашем примере задача значительно сложнее, так как нужно передать не один байт, а определенную часть заданного файла. Все связанные с этим дополнительные проблемы должны решить программы более высокого уровня, чем драйверы СОМ-портов. Для определенности назовем такие программы компьютеров А и В приложением А и приложением В соответственно. Итак, приложение А должно сформировать сообщение-запрос для приложения В. В запросе необходимо указать имя файла, тип операции (в данном случае - чтение), смещение и размер области файла, содержащей нужные данные.
Чтобы передать это сообщение компьютеру В, приложение А обращается к драйверу СОМ-порта, сообщая ему адрес в оперативной памяти, по которому драйвер находит сообщение и затем передает его байт за байтом приложению В. Приложение В, приняв запрос, выполняет его, то есть считывает требуемую область файла с диска с помощью средств локальной ОС в буферную область своей оперативной памяти, а далее с помощью драйвера СОМ-порта передает считанные данные по каналу связи в компьютер А, где они и попадают к приложению А.
Описанные функции приложения А могла бы выполнить сама программа текстового редактора, но включать эти функции в состав каждого приложения - текстовых редакторов, графических редакторов, систем управления базами данных и других приложений, которым нужен доступ к файлам, - не очень рационально (хотя существует большое количество программ, которые действительно самостоятельно решают все задачи по межмашинному обмену данными, например Kermit - программа обмена файлами через СОМ-порты, реализованная для различных ОС, Norton Commander 3.0 с его функцией Link). Гораздо выгоднее создать специальный программный модуль, который будет выполнять функции формирования сообщений-запросов и приема результатов для всех приложений компьютера.
Как уже было ранее сказано, такой служебный модуль называется клиентом. На стороне же компьютера В должен работать другой модуль - сервер, постоянно ожидающий прихода запросов на удаленный доступ к файлам, расположенным на диске этого компьютера. Сервер, приняв запрос из сети, обращается к локальному файлу и выполняет с ним заданные действия, возможно, с участием локальной ОС.
Программные клиент и сервер выполняют системные функции по обслуживанию запросов приложений компьютера А на удаленный доступ к файлам компьютера В. Чтобы приложения компьютера В могли пользоваться файлами компьютера А, описанную схему нужно симметрично дополнить клиентом для компьютера В и сервером для компьютера А.
Схема взаимодействия клиента и сервера с приложениями и операционной системой приведена на рис. 1.8. Несмотря на то что мы рассмотрели очень простую схему аппаратной связи компьютеров, функции программ, обеспечивающих доступ к удаленным файлам, очень похожи на функции модулей сетевой операционной системы, работающей в сети с более сложными аппаратными связями компьютеров.

Рис. 1.8. Взаимодействие программных компонентов при связи двух компьютеров
Очень удобной и полезной функцией клиентской программы является способность отличить запрос к удаленному файлу от запроса к локальному файлу. Если клиентская программа умеет это делать, то приложения не должны заботиться о том, с каким файлом они работают (локальным или удаленным), клиентская программа сама распознает и перенаправляет (redirect) запрос к удаленной машине. Отсюда и название, часто используемое для клиентской части сетевой ОС, - редиректор. Иногда функции распознавания выделяются в отдельный программный модуль, в этом случае редиректором называют не всю клиентскую часть, а только этот модуль.
Протокол АТМ
Протокол АТМ занимает в стеке протоколов АТМ примерно то же место, что протокол IP в стеке TCP/IP или протокол LAP-F в стеке протоколов технологии frame relay. Протокол АТМ занимается передачей ячеек через коммутаторы при установленном и настроенном виртуальном соединении, то есть на основании готовых таблиц коммутации портов. Протокол АТМ выполняет коммутацию по номеру виртуального соединения, который в технологии АТМ разбит на две части - идентификатор виртуального пути (Virtual Path Identifier, VPI) и идентификатор виртуального канала (Virtual Channel Identifier, VCI). Кроме этой основной задачи протокол АТМ выполняет ряд функций по контролю за соблюдением трафик - контракта со стороны пользователя сети, маркировке ячеек-нарушителей, отбрасыванию ячеек-нарушителей при перегрузке сети, а также управлению потоком ячеек для повышения производительности сети (естественно, при соблюдении условий трафик - контракта для всех виртуальных соединений).
Протокол АТМ работает с ячейками следующего формата, представленного на рис. 6.32.

Рис. 6.32.
Формат ячейки АТМ
Поле Управление потоком (Generic Flow Control) используется только при взаимодействии конечного узла и первого коммутатора сети. В настоящее время его точные функции не определены.
Поля Идентификатор виртуального пути (VitualPath Identifier, VPI) и Идентификатор виртуального канала (Vitual Channel Identifier, VCI) занимают соответственно 1 и 2 байта. Эти поля задают номер виртуального соединения, разделенный на старшую (VPI) и младшую (VCI) части.
Поле Идентификатор типа данных (Payload Type Identifier, PTI) состоит из 3-х бит и задает тип данных, переносимых ячейкой, - пользовательские или управляющие (например, управляющие установлением виртуального соединения). Кроме того, один бит этого поля используется для указания перегрузки в сети - он называется Explicit Congestion Forward Identifier, EFCI - и играет ту же роль, что бит FECN в технологии frame relay, то есть передает информацию о перегрузке по направлению потока данных.
Поле Приоритет потери кадра ( Cell Loss Priority, CLP) играет в данной технологии ту же роль, что и поле DE в технологии frame relay - в нем коммутаторы АТМ отмечают ячейки, которые нарушают соглашения о параметрах качества обслуживания, чтобы удалить их при перегрузках сети. Таким образом, ячейки с CLP=0 являются для сети высокоприоритетными, а ячейки с CLP=1 - низкоприоритетными.
Поле Управление ошибками в заголовке (Header Error Control, НЕС)
содержит контрольную сумму, вычисленную для заголовка ячейки. Контрольная сумма вычисляется с помощью техники корректирующих кодов Хэмминга, поэтому она позволяет не только обнаруживать ошибки, но и исправлять все одиночные ошибки, а также некоторые двойные. Поле НЕС обеспечивает не только обнаружение и исправление ошибок в заголовке, но и нахождение границы начала кадра в потоке байтов кадров SDH, которые являются предпочтительным физическим уровнем технологии АТМ, или же в потоке бит физического уровня, основанного на ячейках. Указателей, позволяющих в поле данных кадра STS-n (STM-n) технологии SONET/SDH обнаруживать границы ячеек АТМ (подобных тем указателям, которые используются для определения, например, границ виртуальных контейнеров подканалов Т1/Е1), не существует. Поэтому коммутатор АТМ вычисляет контрольную сумму для последовательности из 5 байт, находящихся в поле данных кадра STM-n, и, если вычисленная контрольная сумма говорит о корректности заголовка ячейки АТМ, первый байт становится границей ячейки. Если же это не так, то происходит сдвиг на один байт и операция продолжается. Таким образом, технология АТМ выделяет асинхронный поток ячеек АТМ в синхронных кадрах SDH или потоке бит физического уровня, основанного на ячейках.
Рассмотрим методы коммутации ячеек АТМ на основе пары чисел VPI/VCI. Коммутаторы АТМ могут работать в двух режимах - коммутации виртуального пути и коммутации виртуального канала. В первом режиме коммутатор выполняет продвижение ячейки только на основании значения поля VPI, а значение поля VCI он игнорирует.
Обычно так работают магистральные коммутаторы территориальных сетей. Они доставляют ячейки из одной сети пользователя в другую на основании только старшей части номера виртуального канала, что соответствует идее агрегирования адресов. В результате один виртуальный путь соответствует целому набору виртуальных каналов, коммутируемых как единое целое.
После доставки ячейки в локальную сеть АТМ ее коммутаторы начинают коммутировать ячейки с учетом как VPI, так и VCI, но при этом им хватает для коммутации только младшей части номера виртуального соединения, так что фактически они работают с VCI, оставляя VPI без изменения. Последний режим называется режимом коммутации виртуального канала.
Для создания коммутируемого виртуального канала в технологии АТМ используются протоколы, не показанные на рис. 6.30. Подход здесь аналогичен подходу в сети ISDN - для установления соединения разработан отдельный протокол Q.2931, который весьма условно можно отнести к сетевому уровню. Этот протокол во многом похож на протоколы Q.931 и Q.933 (даже номером), но в него внесены, естественно, изменения, связанные с наличием нескольких классов трафика и дополнительных параметров качества обслуживания. Протокол Q.2931 опирается на достаточно сложный протокол канального уровня SSCOP, который обеспечивает надежную передачу пакетов Q.2931 в своих кадрах. В свою очередь, протокол SSCOP работает поверх протокола AAL5, который необходим для разбиения кадров SSCOP на ячейки АТМ и сборки этих ячеек в кадры при доставке кадра SSCOP в коммутатор назначения.
ПРИМЕЧАНИЕ
Протокол Q.2931 появился в стеке протоколов технологии АТМ после принятия версии интерфейса UNI 3.1, а до этого в версии UNI 3.0 вместо него использовался протокол Q.93B. Из-за несовместимости протоколов Q.2931 и Q.93B версии пользовательского интерфейса UNI 3.0 и UNI 3.1 также несовместимы. Версия UNI 4.0 обратно совместима с UNI 3.1, так как основана на тех же служебных протоколах, что и версия UNI 3.1.
Виртуальные соединения, образованные с помощью протокола Q.2931, бывают симплексными (однонаправленными) и дуплексными.
Протокол Q. 2931 позволяет также устанавливать виртуальные соединения типа «один-к-одному» (point-to-point) и «один-ко-многим» (point-to-multipoint). Первый случай поддерживается во всех технологиях, основанных на виртуальных каналах, а второй характерен для технологии АТМ и является аналогом мультивещания, но с одним ведущим вещающим узлом. При установлении соединения «один-ко-многим» ведущим считается узел, который является инициатором этого соединения. Сначала этот узел устанавливает виртуальное соединение всего с одним узлом, а затем добавляет к соединению с помощью специального вызова по одному новому члену. Ведущий узел становится вершиной дерева соединения, а остальные узлы - листьями этого дерева. Сообщения, которые посылает ведущий узел, принимают все листья соединения, но сообщения, которые посылает какой-либо лист (если соединение дуплексное), принимает только ведущий узел.
Пакеты протокола Q.2931, предназначенные для установления коммутируемого виртуального канала, имеют те же названия и назначение, что и пакеты протокола Q.933, рассмотренные выше при изучении технологии frame relay, но структура их полей, естественно, другая.
Адресом конечного узла в коммутаторах АТМ является 20-байтный адрес. Этот адрес может иметь различный формат, описываемый стандартом ISO 7498. При работе в публичных сетях используется адрес стандарта Е.164, при этом 1 байт составляет AFI, 8 байт занимает IDI - основная часть адреса Е.164 (15 цифр телефонного номера), а остальные 11 байт части DSP (Domain Specific Part) распределяются следующим образом.
4 байта занимает поле старшей части DSP - High-Order Domain Spesific Part (HO-DSP), имеющее гибкий формат и, в сущности, представляющее собой номер сети АТМ, который может делиться на части для агрегированной маршрутизации по протоколу PNNI, подобной той, которая используется в технике CIDR для сетей IP.
6 байт занимает поле идентификатора конечной системы - End System Identifier (ESI), которое имеет смысл МАС - адреса узла АТМ, причем формат его также соответствует формату МАС - адресов IEEE.
1 байт составляет поле селектора, которое не используется при установлении виртуального канала, а имеет для узла локальное назначение.
При работе в частных сетях АТМ обычно применяется формат адреса, соответствующий домену международных организаций, причем в качестве международной организации выступает АТМ Forum. В этом случае поле IDI занимает 2 байта, которые содержат код АТМ Forum, данный ISO, а структура остальной части DSP соответствует описанной выше за исключением того, что поле HO-DSP занимает не 4, а 10 байт.
Адрес ESI присваивается конечному узлу на предприятии-изготовителе в соответствии с правилами IEEE, то есть 3 первых байта содержат код предприятия, а остальные три байта - порядковый номер, за уникальность которого отвечает данное предприятие.
Конечный узел при подключении к коммутатору АТМ выполняет так называемую процедуру регистрации. При этом конечный узел сообщает коммутатору свой ESI - адрес, а коммутатор сообщает конечному узлу старшую часть адреса, то есть номер сети, в которой работает узел.
Кроме адресной части пакет CALL SETUP протокола Q.2931, с помощью которого конечный узел запрашивает установление виртуального соединения, включает также части, описывающие параметры трафика и требования QoS. При поступлении такого пакета коммутатор должен проанализировать эти параметры и решить, достаточно ли у него свободных ресурсов производительности для обслуживания нового виртуального соединения. Если да, то новое виртуальное соединение принимается и коммутатор передает пакет CALL SETUP дальше в соответствии с адресом назначения и таблицей маршрутизации, а если нет, то запрос отвергается.
Протокол CMIP и услуги CMIS
Доступ к управляющей информации, хранящейся в управляемых объектах, обеспечивается с помощью элемента системы управления, называемого службой CMSIE (Common Management Information Service Element). Служба CMSIE построена в архитектуре распределенного приложения, где часть функций выполняет менеджер, а часть - агент. Взаимодействие между менеджером и агентом осуществляется по протоколу CMIP. Услуги, предоставляемые службой CMSIE, называются услугами CMIS (Common Management Information Services).
Протокол CMIP и услуги CMIS определены в стандартах Х.710 и Х.711 ITU-T.
Услуги CMIS разделяются на две группы - услуги, инициируемые менеджером (запросы), и услуги, инициируемые агентом (уведомления).
Услуги, инициируемые менеджером, включают следующие операции:
M-CREATE
инструктирует агента о необходимости создать новый экземпляр объекта определенного класса или новый атрибут внутри экземпляра объекта;
M-DELETE
инструктирует агента о необходимости удаления некоторого экземпляра объекта определенного класса или атрибута внутри экземпляра объекта;
M-GET
инструктирует агента о возвращении значения некоторого атрибута определенного экземпляра объекта;
M-SET
инструктирует агента об изменении значения некоторого атрибута определенного экземпляра объекта;
M-ACTION
инструктирует агента о необходимости выполнения определенного действия над одним или несколькими экземплярами объектов.
Агент инициирует только одну операцию:
M-EVENT_REPORT - отправка уведомления менеджеру.
Для реализации своих услуг служба CMISE должна использовать службы прикладного уровня стека OSI - ACSE, ROSE.
Отличие услуг CMIS от аналогичных услуг SNMP состоит в большей гибкости. Если запросы GET и SET протокола SNMP применимы только к одному атрибуту одного объекта, то запросы M-GET, M-SET, M-ACTION
и M-DELETE
могут применяться к более чем одному объекту. Для этого стандарты CMIP/CMIS вводят такие понятия, как обзор (scoping), фильтрация (filtering) и синхронизация (synchronization).
Протокол LLC уровня управления логическим каналом (
Протокол LLC обеспечивает для технологий локальных сетей нужное качество услуг транспортной службы, передавая свои кадры либо дейтаграммным способом, либо с помощью процедур с установлением соединения и восстановлением кадров. Протокол LLC занимает уровень между сетевыми протоколами и протоколами уровня MAC. Протоколы сетевого уровня передают через межуровневый интерфейс данные для протокола LLC - свой пакет (например, пакет IP, IPX или NetBEUI), адресную информацию об узле назначения, а также требования к качеству транспортных услуг, которое протокол LLC должен обеспечить. Протокол LLC помещает пакет протокола верхнего уровня в свой кадр, который дополняется необходимыми служебными полями. Далее через межуровневый интерфейс протокол. LLC передает свой кадр вместе с адресной информацией об узле назначения соответствующему протоколу уровня MAC, который упаковывает кадр LLC в свой кадр (например, кадр Ethernet).

В основу протокола LLC положен протокол HDLC (High-level Data Link Control Procedure), являющийся стандартом ISO. Собственно стандарт HDLC представляет собой обобщение нескольких близких стандартов, характерных для различных технологий: протокола LAP-B сетей Х.25 (стандарта, широко распространенного в территориальных сетях), LAP-D, используемого в сетях ISDN, LAP-M, работающего в современных модемах. В спецификации IEEE 802.2 также имеется несколько небольших отличий от стандарта HDLC.
Первоначально в фирменных технологиях подуровень LLC не выделялся в самостоятельный подуровень, да и его функции растворялись в общих функциях протокола канального уровня. Из-за больших различий в функциях протоколов фирменных технологий, которые можно отнести к уровню LLC, на уровне LLC пришлось ввести три типа процедур. Протокол сетевого уровня может обращаться к одной из этих процедур.
Протокол надежной доставки TCP-сообщений
Протокол IP является дейтаграммным протоколом и поэтому по своей природе не может гарантировать надежность передачи данных. Эту задачу - обеспечение надежного канала обмена данными между прикладными процессами в составной сети -решает протокол TCP (Transmission Control Protocol), относящийся к транспортному уровню.
Протокол TCP работает непосредственно над протоколом IP и использует для транспортировки своих блоков данных потенциально ненадежный протокол IP. Надежность передачи данных протоколом TCP достигается за счет того, что он основан на установлении логических соединений между взаимодействующими процессами. До тех пор пока программы протокола TCP продолжают функционировать корректно, а составная сеть не распалась на несвязные части, ошибки в передаче данных на уровне протокола IP не будут влиять на правильное получение данных.
Протокол IP используется протоколом TCP в качестве транспортного средства. Перед отправкой своих блоков данных протокол TCP помещает их в оболочку IP-пакета. При необходимости протокол IP осуществляет любую фрагментацию и сборку блоков данных TCP, требующуюся для осуществления передачи и доставки через множество сетей и промежуточных шлюзов.
На рис. 5.22 показано, как процессы, выполняющиеся на двух конечных узлах, устанавливают с помощью протокола TCP надежную связь через составную сеть, все узлы которой используют для передачи сообщений дейтаграммный протокол IP.
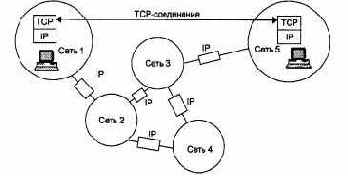
Рис. 5.22. TCP-соединение создает надежный канал связи между конечными узлами
Протокол PPP
Этот протокол разработан группой IETF (Internet Engineering Task Force) как часть стека TCP/IP для передачи кадров информации по последовательным глобальным каналам связи взамен устаревшего протокола SLIP (Serial Line IP). Протокол PPP стал фактическим стандартом для глобальных линий связи при соединении удаленных клиентов с серверами и для образования соединений между маршрутизаторами в корпоративной сети. При разработке протокола PPP за основу был взят формат кадров HDLC и дополнен собственными полями. Поля протокола PPP вложены в поле данных кадра HDLC. Позже были разработаны стандарты, использующие вложение кадра PPP в кадры frame relay и других протоколов глобальных сетей.
Основное отличие РРР от других протоколов канального уровня состоит в том, что он добивается согласованной работы различных устройств с помощью переговорной процедуры, во время которой передаются различные параметры, такие как качество линии, протокол аутентификации и инкапсулируемые протоколы сетевого уровня. Переговорная процедура происходит во время установления соединения.
Протокол РРР основан на четырех принципах: переговорное принятие параметров соединения, многопротокольная поддержка, расширяемость протокола, независимость от глобальных служб.
Переговорное принятие параметров соединения. В корпоративной сети конечные системы часто отличаются размерами буферов для временного хранения пакетов, ограничениями на размер пакета, списком поддерживаемых протоколов сетевого уровня. Физическая линия, связывающая конечные устройства, может варьироваться от низкоскоростной аналоговой линии до высокоскоростной цифровой линии с различными уровнями качества обслуживания.
Чтобы справиться со всеми возможными ситуациями, в протоколе РРР имеется набор стандартных установок, действующих по умолчанию и учитывающих все стандартные конфигурации. При установлении соединения два взаимодействующих устройства для нахождения взаимопонимания пытаются сначала использовать эти установки. Каждый конечный узел описывает свои возможности и требования.
Затем на основании этой информации принимаются параметры соединения, устраивающие обе стороны, в которые входят форматы инкапсуляции данных, размеры пакетов, качество линии и процедура аутентификации.
Протокол, в соответствии с которым принимаются параметры соединения, называется протоколом управления связью (Link Control Protocol, LCP). Протокол, который позволяет конечным узлам договориться о том, какие сетевые протоколы будут передаваться в установленном соединении, называется протоколом управления сетевым уровнем (Network Control Protocol, NCP). Внутри одного РРР - соединения могут передаваться потоки данных различных сетевых протоколов.
Одним из важных параметров РРР - соединения является режим аутентификации. Для целей аутентификации РРР предлагает по умолчанию протокол РАР (Password Authentication Protocol), передающий пароль по линии связи в открытом виде, или протокол CHAP (Challenge Handshake Authentication Protocol), не передающий пароль по линии связи и поэтому обеспечивающий большую безопасность сети. Пользователям также разрешается добавлять и новые алгоритмы аутентификации. Дисциплина выбора алгоритмов компрессии заголовка и данных аналогична.
Многопротокольная поддержка - способность протокола РРР поддерживать несколько протоколов сетевого уровня - обусловила распространение РРР как стандарта де-факто. В отличие от протокола SLIP, который может переносить только IP-пакеты, или LAP-B, который может переносить только пакеты Х.25, РРР работает со многими протоколами сетевого уровня, включая IP, Novell IPX, AppleTalk, DECnet, XNS, Banyan VINES и OSI, а также протоколами канального уровня локальной сети. Каждый протокол сетевого уровня конфигурируется отдельно с помощью соответствующего протокола NCP. Под конфигурированием понимается, во-первых, констатация того факта, что данный протокол будет использоваться в текущей сессии РРР, а во-вторых, переговорное утверждение некоторых параметров протокола. Больше всего параметров устанавливается для протокола IP - IP-адрес узла, IP-адрес серверов DNS, использование компрессии заголовка IP-пакета и т.
д. Протоколы конфигурирования параметров соответствующего протокола верхнего уровня называются по имени этого протокола с добавлением аббревиатуры СР (Control Protocol), например протокол IPCP, IPXCP и т. п.
Расширяемость протокола. Под расширяемостью понимается как возможность включения новых протоколов в стек РРР, так и возможность использования собственных протоколов пользователей вместо рекомендуемых в РРР по умолчанию. Это позволяет наилучшим образом настроить РРР для каждой конкретной ситуации.
Независимость от глобальных служб. Начальная версия РРР работала только с кадрами HDLC. Теперь в стек РРР добавлены спецификации, позволяющие использовать РРР в любой технологии глобальных сетей, например ISDN, frame relay, Х.25, Sonet и HDLC.
Переговорная процедура протоколов LCP и NCP может и не завершиться соглашением о каком-нибудь параметре. Если, например, один узел предлагает в качестве MTU значение 1000 байт, а другой отвергает это предложение и в свою очередь предлагает значение 1500 байт, которое отвергается первым узлом, то по истечении тайм-аута переговорная процедура может закончиться безрезультатно.
Возникает вопрос - каким образом два устройства, ведущих переговоры по протоколу РРР, узнают о тех параметрах, которые они предлагают своему партнеру? Обычно у реализации протокола РРР есть некоторый набор параметров по умолчанию, которые и используются в переговорах. Тем не менее каждое устройство (и программа, реализующая протокол РРР в операционной системе компьютера) позволяет администратору изменить параметры по умолчанию, а также задать параметры, которые не входят в стандартный набор. Например, IP-адрес для удаленного узла отсутствует в параметрах по умолчанию, но администратор может задать его для сервера удаленного доступа, после чего сервер будет предлагать его удаленному узлу.
Хотя протокол РРР и работает с кадром HDLC, но в нем отсутствуют процедуры контроля кадров и управления потоком протокола HDLC. Поэтому в РРР используется только один тип кадра HDLC - ненумерованный информационный.В поле управления такого кадра всегда содержится величина 03. Для исправления очень редких ошибок, возникающих в канале, необходимы протоколы верхних уровней - TCP, SPX, NetBUEl, NCP и т. п.
Одной из возможностей протокола РРР является использование нескольких физических линий для образования одного логического канала, так называемый транкинг каналов. Эту возможность реализует дополнительный протокол, который носит название MLPPP (Multi Link РРР). Многие производители поддерживают такое свойство в своих маршрутизаторах и серверах удаленного доступа фирменным способом. Использование стандартного способа всегда лучше, так как он гарантирует совместимость оборудования разных производителей.
Общий логический канал может состоять из каналов разной физической природы. Например, один канал может быть образован в телефонной сети, а другой может являться виртуальным коммутируемым каналов сети frame relay.
Протокол SLIP
Протокол SLIP (Serial Line IP) был первым стандартом де-факто, позволяющим устройствам, соединенным последовательной линией связи, работать по протоколам TCP/IP. Он был создан в начале 80-х годов и в 1984 году встроен Риком Адамсом (Rick Adams) в операционную систему 4.2 Berkley Unix. Позднее SLIP был поддержан в других версиях Unix и реализован в программном обеспечении для ПК.
Правда, ввиду его функциональной простоты, SLIP использовался и используется в основном на коммутируемых линиях связи, которые не характерны для ответственных и скоростных сетевых соединений. Тем не менее коммутируемый канал отличается от некоммутируемого только более низким качеством и необходимостью выполнять процедуру вызова абонента, поэтому SLIP вполне применим и на выделенных каналах.
Протокол SLIP выполняет единственную функцию - он позволяет в потоке бит, которые поступают по выделенному (или коммутируемому) каналу, распознать начало и конец IP-пакета. Помимо протокола IP, другие протоколы сетевого уровня SLIP не поддерживает.
Чтобы распознать границы IP-пакетов, протокол SLIP предусматривает использование специального символа END, значение которого в шестнадцатеричном представлении равно С0. Применение специального символа может породить конфликт: если байт пересылаемых данных тождественен символу END, то он будет ошибочно определен как признак конца пакета. Чтобы предотвратить такую ситуацию, байт данных со значением, равным значению символа END, заменяется составной двухбайтовой последовательностью, состоящей из специального символа ESC (DB) и кода DC. Если же байт данных имеет тот же код, что и символ SLIP ESC, то он заменяется двухбайтовой последовательностью, состоящей из собственно символа SLIP ESC и кода DD. После последнего байта пакета передается символ END.
Механизм формирования составных последовательностей показан на рис. 6.13. Здесь приведены стандартный IP-пакет (один байт которого тождественен символу END, а другой - символу SLIP ESC) и соответствующий ему SLIP-пакет, который больше на 4 байта.

Рис. 6.13.
Инкапсуляция IP-пакетов в SLIP-пакеты
Хотя в спецификации протокола SLIP не определена максимальная длина передаваемого пакета, реальный размер IP-пакета не должен превышать 1006 байт. Данное ограничение связано с первой реализацией протокола SLIP в соответствующем драйвере для Berkley Unix, и его соблюдение необходимо для поддержки совместимости разных реализации SLIP (большинство современных реализации позволяют администратору самому установить размер пакета, а по умолчанию используют размер 1500 байт).
Для установления связи по протоколу SLIP компьютеры должны иметь информацию об IP-адресах друг друга. Однако возможна ситуация, когда, скажем, при осуществлении соединения между хостом и маршрутизатором последнему понадобится передать хосту информацию о его IP-адресе. В протоколе SLIP нет механизмов, дающих возможность обмениваться адресной информацией. Это ограничение не позволяет использовать SLIP для некоторых видов сетевых служб.
Другой недостаток SLIP - отсутствие индикации типа протокола, пакет которого инкапсулируется в SLIP-пакет. Поэтому через последовательную линию по протоколу SLIP можно передавать трафик лишь одного сетевого протокола - IP.
При работе с реальными телефонными линиями, зашумленными и поэтому искажающими пакеты при пересылке, требуются процедуры обнаружения и коррекции ошибок. В протоколе SLIP такие процедуры не предусмотрены. Эти функции обеспечивают вышележащие протоколы: протокол IP проводит тестирование целостности пакета по заголовку IP, а один из двух транспортных протоколов (UDP или TCP) проверяет целостность всех данных по контрольным суммам.
Низкая пропускная способность последовательных линий связи вынуждает сокращать время передачи пакетов, уменьшая объем содержащейся в них служебной информации. Эта задача решается с помощью протокола Compressed SLIP (CSLIP), поддерживающего сжатие заголовков пакетов. Появление CSLIP объясняется тем фактом, что при использовании программ типа Telnet, Riogin и других для пересылки одного байта данных требуется переслать 20-байтовый заголовок IP-пакета и 20-байтовый заголовок TCP-пакета (итого 40 байт).Спецификация CSLIP обеспечивает сжатие 40-байтового заголовка до 3-5 байт. На сегодняшний момент большинство реализации протокола SLIP поддерживают спецификацию CSLIP.
Таким образом, протокол SLIP выполняет работу по выделению из последовательности передаваемых по последовательному каналу бит границ IP-пакета. Протокол не имеет механизмов передачи адресной информации, идентификации типа протокола сетевого уровня, определения и коррекции ошибок.
Протокол «состояния связей» OSPF
Протокол OSPF (Open Shortest Path First, открытый протокол «кратчайший путь первыми)
является достаточно современной реализацией алгоритма состояния связей (он принят в 1991 году) и обладает многими особенностями, ориентированными на применение в больших гетерогенных сетях.
В OSPF процесс построения таблицы маршрутизации разбивается на два крупных этапа. На первом этапе каждый маршрутизатор строит граф связей сети, в котором вершинами графа являются маршрутизаторы и IP-сети, а ребрами - интерфейсы маршрутизаторов. Все маршрутизаторы для этого обмениваются со своими соседями той информацией о графе сети, которой они располагают к данному моменту времени. Этот процесс похож на процесс распространения векторов расстояний до сетей в протоколе RIP, однако сама информация качественно другая - это информация о топологии сети. Эти сообщения называются router links advertisement - объявление о связях маршрутизатора. Кроме того, при передаче топологической информации маршрутизаторы ее не модифицируют, как это делают RIP-маршрутизаторы, а передают в неизменном виде. В результате распространения топологической информации все маршрутизаторы сети располагают идентичными сведениями о графе сети, которые хранятся в топологической базе данных маршрутизатора.
Второй этап состоит в нахождении оптимальных маршрутов с помощью полученного графа. Каждый маршрутизатор считает себя центром сети и ищет оптимальный маршрут до каждой известной ему сети. В каждом найденном таким образом маршруте запоминается только один шаг - до следующего маршрутизатора, в соответствии с принципом одношаговой маршрутизации. Данные об этом шаге и попадают в таблицу маршрутизации. Задача нахождения оптимального пути на графе является достаточно сложной и трудоемкой. В протоколе OSPF для ее решения используется итеративный алгоритм Дийкстры. Если несколько маршрутов имеют одинаковую метрику до сети назначения, то в таблице маршрутизации запоминаются первые шаги всех этих маршрутов.
После первоначального построения таблицы маршрутизации необходимо отслеживать изменения состояния сети и вносить коррективы в таблицу маршрутизации.
Для контроля состояния связей и соседних маршрутизаторов OSPF-маршрутиза- торы не используют обмен полной таблицей маршрутизации, как это не очень рационально делают МР-маршрутизаторы. Вместо этого они передают специальные короткие сообщения HELLO. Если состояние сети не меняется, то OSPF-мар-шрутизаторы корректировкой своих таблиц маршрутизации не занимаются и не посылают соседям объявления о связях. Если же состояние связи изменилось, то ближайшим соседям посылается новое объявление, касающееся только данной связи, что, конечно, экономит пропускную способность сети. Получив новое объявление об изменении состояния связи, маршрутизатор перестраивает граф сети, заново ищет оптимальные маршруты (не обязательно все, а только те, на которых отразилось данное изменение) и корректирует свою таблицу маршрутизации. Одновременно маршрутизатор ретранслирует объявление каждому из своих ближайших соседей (кроме того, от которого он получил это объявление).
При появлении новой связи или нового соседа маршрутизатор узнает об этом из новых сообщений HELLO. В сообщениях HELLO указывается достаточно детальная информация о том маршрутизаторе, который послал это сообщение, а также о его ближайших соседях, чтобы данный маршрутизатор можно было однозначно идентифицировать. Сообщения HELLO отправляются через каждые 10 секунд, чтобы повысить скорость адаптации маршрутизаторов к изменениям, происходящим в сети. Небольшой объем этих сообщений делает возможной такое частое тестирование состояния соседей и связей с ними.
Так как маршрутизаторы являются одними из вершин графа, то они обязательно должны иметь идентификаторы.
Протокол OSPF обычно использует метрику, учитывающую пропускную способность сетей. Кроме того, возможно использование двух других метрик, учитывающих требования к качеству обслуживания в IP-пакете, - задержки передачи пакетов и надежности передачи пакетов сетью. Для каждой из метрик протокол OSPF строит отдельную таблицу маршрутизации. Выбор нужной таблицы происходит в зависимости от требований к качеству обслуживания пришедшего пакета (см.
рис. 5.27).

Рис. 5.27. Построение таблицы маршрутизации по протоколу OSPF
Маршрутизаторы соединены как с локальными сетями, так и непосредственно между собой глобальными каналами типа «точка-точка».
Данной сети соответствует граф, приведенный на рис. 5.28.
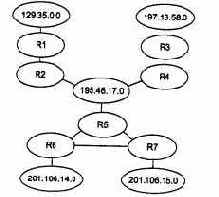
Рис. 5.28. Граф сети, построенный протоколом OSPF
Протокол OSPF в своих объявлениях распространяет информацию о связях двух типов: маршрутизатор - маршрутизатор и маршрутизатор - сеть. Примером связи первого типа служит связь «R3 - R4», а второго - связь «R4 - 195.46.17.0». Если каналам «точка-точка» дать IP-адреса, то они станут дополнительными вершинами графа, как и локальные сети. Вместе с IP-адресом сети передается также информация о маске сети.
После инициализации OSPF-маршрутизаторы знают только о связях с непосредственно подключенными сетями, как и RIP-маршрутизаторы. Они начинают распространять эту информацию своим соседям. Одновременно они посылают сообщения HELLO по всем своим интерфейсам, так что почти сразу же маршрутизатор узнает идентификаторы своих ближайших соседей, что пополняет его топологическую базу новой информацией, которую он узнал непосредственно. Далее топологическая информация начинает распространяться по сети от соседа к соседу и через некоторое время достигает самых удаленных маршрутизаторов.
Каждая связь характеризуется метрикой. Протокол OSPF поддерживает стандартные для многих протоколов (например, для протокола Spanning Tree) значения расстояний для метрики, отражающей производительность сетей: Ethernet - 10 единиц, Fast Ethernet - 1 единица, канал Т1 - 65 единиц, канал 56 Кбит/с - 1785 единиц и т. д.
При выборе оптимального пути на графе с каждым ребром графа связана метрика, которая добавляется к пути, если данное ребро в него входит. Пусть на приведенном примере маршрутизатор R5 связан с .R6 и R7 каналами Tl, a R6 и R7 связаны между собой каналом 56 Кбит/с. Тогда R7 определит оптимальный маршрут до сети 201.106.14.0 как составной, проходящий сначала через маршрутизатор R5, а затем через R6, поскольку у этого маршрута метрика будет равна 65+65 = 130 единиц.
Непосредственный маршрут через R6 не будет оптимальным, так как его метрика равна 1785. При использовании хопов был бы выбран маршрут через R6, что не было бы оптимальным.
Протокол OSPF разрешает хранить в таблице маршрутизации несколько маршрутов к одной сети, если они обладают равными метриками. Если такие записи образуются в таблице маршрутизации, то маршрутизатор реализует режим баланса загрузки маршрутов (load balancing), отправляя пакеты попеременно по каждому из маршрутов.
У каждой записи в топологической базе данных имеется срок жизни, как и у маршрутных записей протокола RIP. С каждой записью о связях связан таймер, который используется для контроля времени жизни записи. Если какая-либо запись топологической базы маршрутизатора, полученная от другого маршрутизатора, устаревает, то он может запросить ее новую копию с помощью специального сообщения Link-State Request протокола OSPF, на которое должен поступить ответ Link-State Update от маршрутизатора, непосредственно тестирующего запрошенную связь.
При инициализации маршрутизаторов, а также для более надежной синхронизации топологических баз маршрутизаторы периодически обмениваются всеми записями базы, но этот период существенно больше, чем у RIP-маршрутизаторов.
Так как информация о некоторой связи изначально генерируется только тем маршрутизатором, который выяснил фактическое состояние этой связи путем тестирования с помощью сообщений HELLO, а остальные маршрутизаторы только ретранслируют эту информацию без преобразования, то недостоверная информация о достижимости сетей, которая может появляться в RIP-маршрутиэаторах, в OSPF-маршрутизаторах появиться не может, а устаревшая информация быстро заменяется новой, так как при изменении состояния связи новое сообщение генерируется сразу же.
Периоды нестабильной работы в OSPF-сетях могут возникать. Например, при отказе связи, когда информация об этом не дошла до какого-либо маршрутизатора и он отправляет пакеты сети назначения, считая эту связь работоспособной.
Однако эти периоды продолжаются недолго, причем пакеты не зацикливаются в маршрутных петлях, а просто отбрасываются при невозможности их передать через неработоспособную связь.
К недостаткам протокола OSPF следует отнести его вычислительную сложность, которая быстро растет с увеличением размерности сети, то есть количества сетей, маршрутизаторов и связей между ними. Для преодоления этого недостатка в протоколе OSPF вводится понятие области сети (area) (не нужно путать с автономной системой Internet). Маршрутизаторы, принадлежащие некоторой области, строят граф связей только для этой области, что сокращает размерность сети. Между областями информация о связях не передается, а пограничные для областей маршрутизаторы обмениваются только информацией об адресах сетей, имеющихся в каждой из областей, и расстоянием от пограничного маршрутизатора до каждой сети. При передаче пакетов между областями выбирается один из пограничных маршрутизаторов области, а именно тот, у которого расстояние до нужной сети меньше. Этот стиль напоминает стиль работы протокола RIP, но нестабильность здесь устраняется тем, что петлевидные связи между областями запрещены. При передаче адресов в другую область OSPF-маршрутизаторы агрегируют несколько адресов в один, если обнаруживают у них общий префикс.
OSPF-маршрутизаторы могут принимать адресную информацию от других протоколов маршрутизации, например от протокола RIP, что полезно для работы в гетерогенных сетях. Такая адресная информация обрабатывается так же, как и внешняя информация между разными областями.
Протоколы канального уровня для выделенных линий
Выделенные каналы используются для прямой связи между собой локальных сетей или отдельных компьютеров. Для маршрутизатора или моста выделенная линия предоставляет чаще всего либо канал с известной полосой пропускания, как в случае выделенных аналоговых линий, либо канал с известным протоколом физического уровня, как в случае цифровых выделенных каналов. Правда, так как аналоговый канал требует модема для передачи данных, протокол физического уровня также определен для этой линии - это протокол модема. Поэтому для передачи данных между маршрутизаторами, мостами или отдельными компьютерами с помощью выделенного канала необходимо решить, какие протоколы уровней выше физического необходимы для передачи сообщений с нужной степенью надежности и с возможностями управления потоком кадров для предотвращения переполнения соседних узлов.
Если выделенный канал соединяет сети через маршрутизаторы, то протокол сетевого уровня определен, а протокол канального уровня маршрутизатор может использовать любой, в том числе и протокол канального уровня локальной сети, например Ethernet. Мост должен передавать кадры канального протокола из одной локальной сети в другую, при этом ему тоже можно непосредственно использовать протокол локальной сети (Ethernet, Token Ring, FDDI) поверх физического уровня канала.
Однако ни мосты, ни маршрутизаторы на выделенных каналах с протоколами канального уровня локальных сетей не работают. Они, с одной стороны, избыточны, а с другой стороны, в них отсутствуют некоторые необходимые процедуры, очень полезные при объединении сетей по глобальному выделенному каналу.
Избыточность проявляется в процедурах получения доступа к разделяемой среде, а так как выделенная линия постоянно находится в распоряжении соединяющихся с ее помощью конечных узлов, процедура получения доступа к ней не имеет смысла. Среди отсутствующих процедур можно назвать процедуру управления потоком данных, процедуру взаимной аутентификации удаленных устройств, что часто необходимо для защиты сети от «подставного» маршрутизатора или моста, отводящего корпоративный трафик не по назначению. Кроме того, существует ряд параметров, которые полезно автоматически согласовывать при удаленном взаимодействии, - например, максимальный размер поля данных (MTU), IP-адрес партнера (как для безопасности, так и для автоматического конфигурирования стека TCP/IP на удаленных одиночных компьютерах).
Протоколы маршрутизации
Задача маршрутизации решается на основе анализа таблиц маршрутизации, размещенных во всех маршрутизаторах и конечных узлах сети. Каким же образом происходит формирование этих таблиц? Какими средствами обеспечивается адекватность содержащейся в них информации постоянно изменяющейся структуре сети? Основная работа по созданию таблиц маршрутизации выполняется автоматически, но и возможность вручную скорректировать или дополнить таблицу тоже, как правило, предусматривается.
Для автоматического построения таблиц маршрутизации маршрутизаторы обмениваются информацией о топологии составной сети в соответствии со специальным служебным протоколом. Протоколы этого типа называются протоколами маршрутизации (или маршрутизирующими протоколами). Протоколы маршрутизации (например, RIP, OSPF, NLSP) следует отличать от собственно сетевых протоколов (например, IP, IPX). И те и другие выполняют функции сетевого уровня модели OSI - участвуют в доставке пакетов адресату через разнородную составную сеть. Но в то время как первые собирают и передают по сети чисто служебную информацию, вторые предназначены для передачи пользовательских данных, как это делают протоколы канального уровня. Протоколы маршрутизации используют сетевые протоколы как транспортное средство. При обмене маршрутной информацией пакеты протокола маршрутизации помещаются в поле данных пакетов сетевого уровня или даже транспортного уровня, поэтому с точки зрения вложенности пакетов протоколы маршрутизации формально следовало бы отнести к более высокому уровню, чем сетевой.
В том, что маршрутизаторы для принятия решения о продвижении пакета обращаются к адресным таблицам, можно увидеть их некоторое сходство с мостами и коммутаторами. Однако природа используемых ими адресных таблиц сильно различается. Вместо MAC - адресов в таблицах маршрутизации указываются номера сетей, которые соединяются в интерсеть. Другим отличием таблиц маршрутизации от адресных таблиц мостов является способ их создания. В то время как мост строит таблицу, пассивно наблюдая за проходящими через него информационными кадрами, посылаемыми конечными узлами сети друг другу, маршрутизаторы по своей инициативе обмениваются специальными служебными пакетами, сообщая соседям об известных им сетях в интерсети, маршрутизаторах и о связях этих сетей с маршрутизаторами.
Обычно учитывается не только топология связей, но и их пропускная способность и состояние. Это позволяет маршрутизаторам быстрее адаптироваться к изменениям конфигурации сети, а также правильно передавать пакеты в сетях с произвольной топологией, допускающей наличие замкнутых контуров.
С помощью протоколов маршрутизации маршрутизаторы составляют карту связей сети той или иной степени подробности. На основании этой информации для каждого номера сети принимается решение о том, какому следующему маршрутизатору надо передавать пакеты, направляемые в эту сеть, чтобы маршрут оказался рациональным. Результаты этих решений заносятся в таблицу маршрутизации. При изменении конфигурации сети некоторые записи в таблице становятся недействительными. В таких случаях пакеты, отправленные по ложным маршрутам, могут зацикливаться и теряться. От того, насколько быстро протокол маршрутизации приводит в соответствие содержимое таблицы реальному состоянию сети, зависит качество работы всей сети.
Протоколы маршрутизации могут быть построены на основе разных алгоритмов, отличающихся способами построения таблиц маршрутизации, способами выбора наилучшего маршрута и другими особенностями своей работы.
Во всех описанных выше примерах при выборе рационального маршрута определялся только следующий (ближайший) маршрутизатор, а не вся последовательность маршрутизаторов от начального до конечного узла. В соответствии с этим подходом маршрутизация выполняется по распределенной схеме - каждый маршрутизатор ответственен за выбор только одного шага маршрута, а окончательный маршрут складывается в результате работы всех маршрутизаторов, через которые проходит данный пакет. Такие алгоритмы маршрутизации называются одношаговыми.
Существует и прямо противоположный, многошаговый подход - маршрутизация от источника (Source Routing). В соответствии с ним узел-источник задает в отправляемом в сеть пакете полный маршрут его следования через все промежуточные маршрутизаторы. При использовании многошаговой маршрутизации нет необходимости строить и анализировать таблицы маршрутизации.
Это ускоряет прохождение пакета по сети, разгружает маршрутизаторы, но при этом большая нагрузка ложится на конечные узлы. Эта схема в вычислительных сетях применяется сегодня гораздо реже, чем схема распределенной одношаговой маршрутизации. Однако в новой версии протокола IP наряду с классической одношаговой маршрутизацией будет разрешена и маршрутизация от источника.
Одношаговые алгоритмы в зависимости от способа формирования таблиц маршрутизации делятся на три класса:
алгоритмы фиксированной (или статической) маршрутизации;
алгоритмы простой маршрутизации;
алгоритмы адаптивной (или динамической) маршрутизации.
В алгоритмах фиксированной маршрутизации все записи в таблице маршрутизации являются статическими. Администратор сети сам решает, на какие маршрутизаторы надо передавать пакеты с теми или иными адресами, и вручную (например, с помощью утилиты route ОС Unix или Windows NT) заносит соответствующие записи в таблицу маршрутизации. Таблица, как правило, создается в процессе загрузки, в дальнейшем она используется без изменений до тех пор, пока ее содержимое не будет отредактировано вручную. Такие исправления могут понадобиться, например, если в сети отказывает какой-либо маршрутизатор и его функции возлагаются на другой маршрутизатор. Различают одномаршрутные таблицы, в которых для каждого адресата задан один путь, и многомаршрутные таблицы, определяющие несколько альтернативных путей для каждого адресата. В многомаршрутных таблицах должно быть задано правило выбора одного из маршрутов. Чаще всего один путь является основным, а остальные - резервными. Понятно, что алгоритм фиксированной маршрутизации с его ручным способом формирования таблиц маршрутизации приемлем только в небольших сетях с простой топологией. Однако этот алгоритм может быть эффективно использован и для работы на магистралях крупных сетей, так как сама магистраль может иметь простую структуру с очевидными наилучшими путями следования пакетов в подсети, присоединенные к магистрали.
В алгоритмах простой маршрутизации таблица маршрутизации либо вовсе не используется, либо строится без участия протоколов маршрутизации.
Выделяют три типа простой маршрутизации:
случайная маршрутизация, когда прибывший пакет посылается в первом попавшем случайном направлении, кроме исходного;
лавинная маршрутизация, когда пакет широковещательно посылается по всем возможным направлениям, кроме исходного (аналогично обработке мостами кадров с неизвестным адресом);
маршрутизация по предыдущему опыту, когда выбор маршрута осуществляется по таблице, но таблица строится по принципу моста путем анализа адресных полей пакетов, появляющихся на входных портах.
Самыми распространенными являются алгоритмы адаптивной (или динамической) маршрутизации. Эти алгоритмы обеспечивают автоматическое обновление таблиц маршрутизации после изменения конфигурации сети. Протоколы, построенные на основе адаптивных алгоритмов, позволяют всем маршрутизаторам собирать информацию о топологии связей в сети, оперативно отрабатывая все изменения конфигурации связей. В таблицах маршрутизации при адаптивной маршрутизации обычно имеется информация об интервале времени, в течение которого данный маршрут будет оставаться действительным. Это время называют временем жизни маршрута (Time To Live, TTL).
Адаптивные алгоритмы обычно имеют распределенный характер, который выражается в том, что в сети отсутствуют какие-либо выделенные маршрутизаторы, которые собирали бы и обобщали топологическую информацию: эта работа распределена между всеми маршрутизаторами.
ПРИМЕЧАНИЕ В последнее время наметилась тенденция использовать так называемые серверы маршрутов. Сервер маршрутов собирает маршрутную информацию, а затем раздает ее по запросам маршрутизаторам, которые освобождаются в этом случае от функции создания таблиц маршрутизации, либо создают только части этих таблиц. Появились специальные протоколы взаимодействия маршрутизаторов с серверами маршрутов, например Next Hop Resolution Protocol (NHRP).
Адаптивные алгоритмы маршрутизации должны отвечать нескольким важным требованиям. Во-первых, они должны обеспечивать, если не оптимальность, то хотя бы рациональность маршрута.
Во-вторых, алгоритмы должны быть достаточно простыми, чтобы при их реализации не тратилось слишком много сетевых ресурсов, в частности они не должны требовать слишком большого объема вычислений или порождать интенсивный служебный трафик. И наконец, алгоритмы маршрутизации должны обладать свойством сходимости, то есть всегда приводить к однозначному результату за приемлемое время.
Адаптивные протоколы обмена маршрутной информацией, применяемые в настоящее время в вычислительных сетях, в свою очередь делятся на две группы, каждая из которых связана с одним из следующих типов алгоритмов:
дистанционно-векторные алгоритмы (Distance Vector Algorithms, DVA);
алгоритмы состояния связей (Link State Algorithms, LSA).
В алгоритмах дистанционно-векторного типа каждый маршрутизатор периодически и широковещательно рассылает по сети вектор, компонентами которого являются расстояния от данного маршрутизатора до всех известных ему сетей. Под расстоянием обычно понимается число хопов. Возможна и другая метрика, учитывающая не только число промежуточных маршрутизаторов, но и время прохождения пакетов по сети между соседними маршрутизаторами. При получении вектора от соседа маршрутизатор наращивает расстояния до указанных в векторе сетей на расстояние до данного соседа. Получив вектор от соседнего маршрутизатора, каждый маршрутизатор добавляет к нему информацию об известных ему других сетях, о которых он узнал непосредственно (если они подключены к его портам) или из аналогичных объявлений других маршрутизаторов, а затем снова рассылает новое значение вектора по сети. В конце концов, каждый маршрутизатор узнает информацию обо всех имеющихся в интерсети сетях и о расстоянии до них через соседние маршрутизаторы.
Дистанционно-векторные алгоритмы хорошо работают только в небольших сетях, В больших сетях они засоряют линии связи интенсивным широковещательным трафиком, к тому же изменения конфигурации могут отрабатываться по этому алгоритму не всегда корректно, так как маршрутизаторы не имеют точного представления о топологии связей в сети, а располагают только обобщенной информацией - вектором дистанций, к тому же полученной через посредников.
Работа маршрутизатора в соответствии с дистанционно- векторным протоколом напоминает работу моста, так как точной топологической картины сети такой маршрутизатор не имеет.
Наиболее распространенным протоколом, основанным на дистанционно-векторном алгоритме, является протокол RIP, который распространен в двух версиях - RIP IP, работающий с протоколом IP, и RIP IPX, работающий с протоколом IPX.
Алгоритмы состояния связей
обеспечивают каждый маршрутизатор информацией, достаточной для построения точного графа связей сети. Все маршрутизаторы работают на основании одинаковых графов, что делает процесс маршрутизации более устойчивым к изменениям конфигурации. «Широковещательная» рассылка (то есть передача пакета всем непосредственным соседям маршрутизатора) используется здесь только при изменениях состояния связей, что происходит в надежных сетях не так часто. Вершинами графа являются как маршрутизаторы, так и объединяемые ими сети. Распространяемая по сети информация состоит из описания связей различных типов: маршрутизатор - маршрутизатор, маршрутизатор - сеть,
Чтобы понять, в каком состоянии находятся линии связи, подключенные к его портам, маршрутизатор периодически обменивается короткими пакетами HELLO со своими ближайшими соседями. Этот служебный трафик также засоряет сеть, но не в такой степени как, например, RIP-пакеты, так как пакеты HELLO имеют намного меньший объем.
Протоколами, основанными на алгоритме состояния связей, являются протоколы IS-IS (Intermediate System to Intermediate System) стека OSI, OSPF (Open Shortest Path First) стека TCP/IP и недавно реализованный протокол NLSP стека Novell.
Протоколы с гибким форматом кадра
Для большей части протоколов характерны кадры, состоящие из служебных полей фиксированной длины. Исключение делается только для поля данных, с целью экономной пересылки как небольших квитанций, так и больших файлов. Способ определения окончания кадра путем задания длины поля данных, рассмотренный выше, как раз рассчитан на такие кадры с фиксированной структурой и фиксированными размерами служебных полей.
Однако существует ряд протоколов, в которых кадры имеют гибкую структуру. Например, к таким протоколам относятся очень популярный прикладной протокол управления сетями SNMP, а также протокол канального уровня РРР, используемый для соединений типа «точка-точка». Кадры таких протоколов состоят из неопределенного количества полей, каждое из которых может иметь переменную длину. Начало такого кадра отмечается некоторым стандартным образом, например с помощью флага, а затем протокол последовательно просматривает поля кадра и определяет их количество и размеры. Каждое поле обычно описывается двумя дополнительными полями фиксированного размера. Например, если в кадре встречается поле, содержащее некоторую символьную строку, то в кадр вставляются три поля:

Дополнительные поля «Тип» и «Длина» имеют фиксированный размер в один байт, поэтому протокол легко находит границы поля «Значение». Так как количество таких полей также неизвестно, для определения общей длины кадра используется либо общее поле «Длина», которое помещается в начале кадра и относится ко всем полям данных, либо закрывающий флаг.
Протоколы семейства HDLC
Долгое время основным протоколом выделенных линий был протокол HDLC (High-level Data Link Control), имеющий статус стандарта ISO. Протокол HDLC на самом деле представляет собой семейство протоколов, в которое входят известные протоколы: LAP-B, образующий канальный уровень сетей Х.25, LAP-D - канальный уровень сетей ISDN, LAP-M - канальный уровень асинхронно-синхронных модемов, LAP-F - канальный уровень сетей frame relay.
Основные принципы работы протокола HDLC: режим логического соединения, контроль искаженных и потерянных кадров с помощью метода скользящего окна, управление потоком кадров с помощью команд RNR и RR, а также различные типы кадров этого протокола были уже рассмотрены в главе 3 при изучении еще одного представителя семейства HDLC - протокола LLC2.
Однако сегодня протокол HDLC на выделенных каналах вытеснил протокол «точка-точкам», Point-to-Point Protocol, PPP.
Дело в том, что одна из основных функций протокола HDLC - это восстановление искаженных и утерянных кадров. Действительно, применение протокола HDLC обеспечивает снижение вероятности искажения бита (BER) с 10-3, что характерно для территориальных аналоговых каналов, до 10-9.
Однако сегодня популярны цифровые каналы, которые и без внешних процедур восстановления кадров обладают высоким качеством (величина BER составляет10-8-10-9). Для работы по такому каналу восстановительные функции протокола HDLC не нужны. При передаче по аналоговым выделенным каналам современные модемы сами применяют протоколы семейства HDLC (синхронные модемы - HDLC, а асинхронно-синхронные с асинхронным интерфейсом - LAP-M, который также принадлежит семейству HDLC). Поэтому использование HDLC на уровне маршрутизатора или моста становится неоправданным.
Прозрачность
Прозрачность (transparency) сети достигается в том случае, когда сеть представляется пользователям не как множество отдельных компьютеров, связанных между собой сложной системой кабелей, а как единая традиционная вычислительная машина с системой разделения времени. Известный лозунг компании Sun Microsystems: «Сеть - это компьютер» - говорит именно о такой прозрачной сети.
Прозрачность может быть достигнута на двух различных уровнях - на уровне пользователя и на уровне программиста. На уровне пользователя прозрачность означает, что для работы с удаленными ресурсами он использует те же команды и привычные ему процедуры, что и для работы с локальными ресурсами. На программном уровне прозрачность заключается в том, что приложению для доступа к удаленным ресурсам требуются те же вызовы, что и для доступа к локальным ресурсам. Прозрачность на уровне пользователя достигается проще, так как все особенности процедур, связанные с распределенным характером системы, маскируются от пользователя программистом, который создает приложение. Прозрачность на уровне приложения требует сокрытия всех деталей распределенности средствами сетевой операционной системы.
Сеть должна скрывать все особенности операционных систем и различия в типах компьютеров. Пользователь компьютера Macintosh должен иметь возможность обращаться к ресурсам, поддерживаемым UNIX-системой, а пользователь UNIX должен иметь возможность разделять информацию с пользователями Windows 95. Подавляющее число пользователей ничего не хочет знать о внутренних форматах файлов или о синтаксисе команд UNIX. Пользователь терминала IBM 3270 должен иметь возможность обмениваться сообщениями с пользователями сети персональных компьютеров без необходимости вникать в секреты трудно запоминаемых адресов.
Концепция прозрачности может быть применена к различным аспектам сети. Например, прозрачность расположения означает, что от пользователя не требуется знаний о месте расположения программных и аппаратных ресурсов, таких как процессоры, принтеры, файлы и базы данных. Имя ресурса не должно включать информацию о месте его расположения, поэтому имена типа mashinel : prog.c или \\ftp_serv\pub прозрачными не являются. Аналогично, прозрачность перемещения означает, что ресурсы должны свободно перемещаться из одного компьютера в другой без изменения своих имен. Еще одним из возможных аспектов прозрачности является прозрачность параллелизма, заключающаяся в том, что процесс распараллеливания вычислений происходит автоматически, без участия программиста, при этом система сама распределяет параллельные ветви приложения по процессорам и компьютерам сети. В настоящее время нельзя сказать, что свойство прозрачности в полной мере присуще многим вычислительным сетям, это скорее цель, к которой стремятся разработчики современных сетей.
Расчет PDV
Для упрощения расчетов обычно используются справочные данные IEEE, содержащие значения задержек распространения сигналов в повторителях, приемопередатчиках и различных физических средах. В табл. 3.5 приведены данные, необходимые для расчета значения PDV для всех физических стандартов сетей Ethernet. Битовый интервал обозначен как bt.
Таблица 3.5. Данные для расчета значения PDV

Комитет 802.3 старался максимально упростить выполнение расчетов, поэтому данные, приведенные в таблице, включают сразу несколько этапов прохождения сигнала. Например, задержки, вносимые повторителем, состоят из задержки входного трансивера, задержки блока повторения и задержки выходного трансивера. Тем не менее в таблице все эти задержки представлены одной величиной, названной базой сегмента. Чтобы не нужно было два раза складывать задержки, вносимые кабелем, в таблице даются удвоенные величины задержек для каждого типа кабеля.
В таблице используются также такие понятия, как левый сегмент, правый сегмент и промежуточный сегмент. Поясним эти термины на примере сети, приведенной на рис. 3.13. Левым сегментом называется сегмент, в котором начинается путь сигнала от выхода передатчика (выход Тх на рис. 3.10) конечного узла. На примере это сегмент 1. Затем сигнал проходит через промежуточные сегменты 2-5 и доходит до приемника (вход Rх на рис. 3.10) наиболее удаленного узла наиболее удаленного сегмента 6, который называется правым. Именно здесь в худшем случае происходит столкновение кадров и возникает коллизия, что, и подразумевается в таблице.

Рис. 3.13. Пример сети Ethernet, состоящей из сегментов различных физических стандартов
С каждым сегментом связана постоянная задержка, названная базой, которая зависит только от типа сегмента и от положения сегмента на пути сигнала (левый, промежуточный или правый). База правого сегмента, в котором возникает коллизия, намного превышает базу левого и промежуточных сегментов.
Кроме этого, с каждым сегментом связана задержка распространения сигнала вдоль кабеля сегмента, которая зависит от длины сегмента и вычисляется путем умножения времени распространения сигнала по одному метру кабеля (в битовых интервалах) на длину кабеля в метрах.
Расчет заключается в вычислении задержек, вносимых каждым отрезком кабеля (приведенная в таблице задержка сигнала на 1 м кабеля умножается на длину сегмента), а затем суммировании этих задержек с базами левого, промежуточных и правого сегментов. Общее значение PDV не должно превышать 575.
Так как левый и правый сегменты имеют различные величины базовой задержки, то в случае различных типов сегментов на удаленных краях сети необходимо выполнить расчеты дважды: один раз принять в качестве левого сегмента сегмент одного типа, а во второй - сегмент другого типа. Результатом можно считать максимальное значение PDV. В нашем примере крайние сегменты сети принадлежат к одному типу - стандарту 10Base-T, поэтому двойной расчет не требуется, но если бы они были сегментами разного типа, то в первом случае нужно было бы принять в качестве левого сегмент между станцией и концентратором 1, а во втором считать левым сегмент между станцией и концентратором 5.
Приведенная на рисунке сеть в соответствии с правилом 4-х хабов не является корректной - в сети между узлами сегментов 1 и 6 имеется 5 хабов, хотя не все сегменты являются сегментами lOBase-FB. Кроме того, общая длина сети равна 2800 м, что нарушает правило 2500 м. Рассчитаем значение PDV для нашего примера.
Левый сегмент 1/ 15,3 (база) + 100 * 0,113= 26,6.
Промежуточный сегмент 2/33,5 + 1000 * 0,1 = 133,5.
Промежуточный сегмент 3/ 24 + 500 * 0,1 = 74,0.
Промежуточный сегмент 4/24 + 500 * 0,1 = 74,0.
Промежуточный сегмент 5/ 24 + 600 * 0,1 = 84,0.
Правый сегмент 6/165 + 100 * 0,113 = 176,3.
Сумма всех составляющих дает значение PDV, равное 568,4.
Так как значение PDV меньше максимально допустимой величины 575, то эта сеть проходит по критерию времени двойного оборота сигнала несмотря на то, что ее общая длина составляет больше 2500 м, а количество повторителей - больше 4-х.
Расчет PW
Чтобы признать конфигурацию сети корректной, нужно рассчитать также уменьшение межкадрового интервала повторителями, то есть величину PW.
Для расчета PW также можно воспользоваться значениями максимальных величин уменьшения межкадрового интервала при прохождении повторителей различных физических сред, рекомендованными IEEE и приведенными в табл. 3.6.
Таблица 3.6. Сокращение межкадрового интервала повторителями

В соответствии с этими данными рассчитаем значение PVV для нашего примера.
Левый сегмент 1 10Base-T: сокращение в 10,5 bt.
Промежуточный сегмент 2 10Base-FL: 8.
Промежуточный сегмент 3 10Base-FB: 2.
Промежуточный сегмент 4 10Base-FB: 2.
Промежуточный сегмент 5 10Base-FB: 2.
Сумма этих величин дает значение PW, равное 24,5, что меньше предельного значения в 49 битовых интервала.
В результате приведенная в примере сеть соответствует стандартам Ethernet по всем параметрам, связанным и с длинами сегментов, и с количеством повторителей.
Распределение используемых сетевых протоколов
Эта статистическая группа относится к протоколам сетевого уровня. На дисплее отображается список основных протоколов в убывающем порядке относительно процентного соотношения кадров, содержащих пакеты данного протокола к общему числу кадров в сети.
Распределенная магистраль на коммутаторах
В сетях больших зданий или кампусов структура с коллапсированной магистралью не всегда рациональна или возможна. Такая структура приводит к протяженным кабельным системам, связывающим конечные узлы или коммутаторы сетей рабочих групп с центральным коммутатором, шина которого и является магистралью сети. Высокая плотность кабелей и их высокая стоимость ограничивают применение стянутой в точку магистрали в таких сетях. Иногда, особенно в сетях кампусов, просто невозможно стянуть все кабели в одно помещение из-за ограничений на длину связей, накладываемых технологией (например, все реализации технологий локальных сетей на витой паре ограничивают протяженность кабелей в 100 м).
Поэтому в локальных сетях, покрывающих большие территории, часто используется другой вариант построения сети - с распределенной магистралью. Пример такой сети приведен на рис. 4.45.

Рис. 4.45. Структура сети с распределенной магистралью
Распределенная магистраль - это разделяемый сегмент сети, поддерживающий определенный протокол, к которому присоединяются коммутаторы сетей рабочих групп и отделов. На примере распределенная магистраль построена на основе двойного кольца FDDI, к которому подключены коммутаторы этажей. Коммутаторы этажей имеют большое количество портов Ethernet, трафик которых транслируется в трафик протокола FDDI, когда он передается по магистрали с этажа на этаж.
Распределенная магистраль упрощает связи между этажами, сокращает стоимость кабельной системы и преодолевает ограничения на расстояния.
Однако скорость магистрали в этом случае будет существенно ниже скорости магистрали на внутренней шине коммутатора. Причем скорость эта фиксированная и в настоящее время чаще всего не превышает 100 Мбит/с. Поэтому распределенная магистраль может применяться только при невысокой интенсивности трафика между этажами или зданиями. Широкое распространение в недалеком будущем технологии Gigabit Ethernet может снять это ограничение, что очень положительно скажется на структуре крупных сетей.
Пример на рис. 4.45 демонстрирует сочетание двух базовых структур, так как на каждом этаже сеть построена с использованием магистрали на внутренней шине коммутатора.
Распределенные программы
Сетевые службы всегда представляют собой распределенные программы. Распределенная программа - это программа, которая состоит из нескольких взаимодействующих частей (в приведенном на рис. 1.5 примере - из двух), причем каждая часть, как правило, выполняется на отдельном компьютере сети.

Рис. 1.5. Взаимодействие частей распределенного приложения
До сих пор речь шла о системных распределенных программах. Однако в сети могут выполняться и распределенные пользовательские программы - приложения. Распределенное приложение также состоит из нескольких частей, каждая и которых выполняет какую-то определенную законченную работу по решению прикладной задачи. Например, одна часть приложения, выполняющаяся на компьютере пользователя, может поддерживать специализированный графический интерфейс вторая - работать на мощном выделенном компьютере и заниматься статистической обработкой введенных пользователем данных, а третья - заносить полученные результаты в базу данных на компьютере с установленной стандартной СУБД. Распределенные приложения в полной мере используют потенциальные возможности распределенной обработки, предоставляемые вычислительной сетью, и поэтому часто называются сетевыми приложениями.
Следует подчеркнуть, что не всякое приложение, выполняемое в сети, является сетевым. Существует большое количество популярных приложений, которые не являются распределенными и целиком выполняются на одном компьютере сети. Тем не менее и такие приложения могут использовать преимущества сети за счет встроенных в операционную систему сетевых служб. Значительная часть истории локальных сетей связана как раз с использованием таких нераспределенных приложений. Рассмотрим, например, как происходила работа пользователя с известной в свое время СУБД dBase. Обычно файлы базы данных, с которыми работали все пользователи сети, располагались на файловом сервере. Сама же СУБД хранилась на каждом клиентском компьютере в виде единого программного модуля.
Программа dBase была рассчитана на обработку только локальных данных, то есть данных, расположенных на том же компьютере, что и сама программа.
Пользователь запускал dBase на своем компьютере, и она искала данные на локальном диске, совершенно не принимая во внимание существование сети. Чтобы обрабатывать с помощью dBase данные на удаленном компьютере, пользователь обращался к услугам файловой службы, которая доставляла данные с сервера на клиентский компьютер и создавала для СУБД эффект их локального хранения.
Большинство приложений, используемых в локальных сетях в середине 80-х годов, являлись обычными, нераспределенными приложениями. И это понятно - они были написаны для автономных компьютеров, а потом просто были перенесены в сетевую среду. Создание же распределенных приложений, хотя и сулило много преимуществ (уменьшение сетевого трафика, специализация компьютеров), оказалось делом совсем не простым. Нужно было решать множество дополнительных проблем - на сколько частей разбить приложение, какие функции возложить на каждую часть, как организовать взаимодействие этих частей, чтобы в случае сбоев и отказов оставшиеся части корректно завершали работу, и т. д., и т. п. Поэтому до сих пор только небольшая часть приложений является распределенными, хотя очевидно, что именно за этим классом приложений будущее, так как они в полной мере могут использовать потенциальные возможности сетей по распараллеливанию вычислений.
Расширяемость и масштабируемость
Термины расширяемость и масштабируемость иногда используют как синонимы, но это неверно - каждый из них имеет четко определенное самостоятельное значение.
Расширяемость (extensibility) означает возможность сравнительно легкого добавления отдельных элементов сети (пользователей, компьютеров, приложений, служб), наращивания длины сегментов сети и замены существующей аппаратуры более мощной. При этом принципиально важно, что легкость расширения системы иногда может обеспечиваться в некоторых весьма ограниченных пределах. Например, локальная сеть Ethernet, построенная на основе одного сегмента толстого коаксиального кабеля, обладает хорошей расширяемостью, в том смысле, что позволяет легко подключать новые станции. Однако такая сеть имеет ограничение на число станций - их число не должно превышать 30-40. Хотя сеть допускает физическое подключение к сегменту и большего числа станций (до 100), но при этом чаще всего резко снижается производительность сети. Наличие такого ограничения и является признаком плохой масштабируемости системы при хорошей расширяемости.
Масштабируемость (scalability) означает, что сеть позволяет наращивать количество узлов и протяженность связей в очень широких пределах, при этом производительность сети не ухудшается. Для обеспечения масштабируемости сети приходится применять дополнительное коммуникационное оборудование и специальным образом структурировать сеть. Например, хорошей масштабируемостью обладает многосегментная сеть, построенная с использованием коммутаторов и маршрутизаторов и имеющая иерархическую структуру связей. Такая сеть может включать несколько тысяч компьютеров и при этом обеспечивать каждому пользователю сети нужное качество обслуживания.
Размер адресной таблицы
Максимальная емкость адресной таблицы определяет предельное количество MAC-адресов, с которыми может одновременно оперировать коммутатор. Так как коммутаторы чаще всего используют для выполнения операций каждого порта выделенный процессорный блок со своей памятью для хранения экземпляра адресной таблицы, то размер адресной таблицы для коммутаторов обычно приводится в расчете на один порт. Экземпляры адресной таблицы разных процессорных модулей не обязательно содержат одну и ту же адресную информацию - скорее всего, повторяющихся адресов будет не так много, если только распределение трафика каждого порта между остальными портами не полностью равновероятно. Каждый порт хранит только те наборы адресов, с которыми он работал в последнее время.
Значение максимального числа МАС - адресов, которое может запомнить процессор порта, зависит от области применения коммутатора. Коммутаторы рабочих групп обычно поддерживают всего несколько адресов на порт, так как они предназначены для образования микросегментов. Коммутаторы отделов должны поддерживать несколько сотен адресов, а коммутаторы магистралей сетей - до нескольких тысяч, обычно 4000-8000 адресов.
Недостаточная емкость адресной таблицы может служить причиной замедления работы коммутатора и засорения сети избыточным трафиком. Если адресная таблица процессора порта полностью заполнена, а он встречает новый адрес источника в поступившем пакете, процессор должен вытеснить из таблицы какой-либо старый адрес и поместить на его место новый. Эта операция сама по себе отнимет у процессора часть времени, но главные потери производительности будут наблюдаться при поступлении кадра с адресом назначения, который пришлось удалить из адресной таблицы. Так как адрес назначения кадра неизвестен, то коммутатор должен передать этот кадр на все остальные порты. Эта операция будет создавать лишнюю работу для многих процессоров портов, кроме того, копии этого кадра будут попадать и на те сегменты сети, где они совсем не обязательны.
Некоторые производители коммутаторов решают эту проблему за счет изменения алгоритма обработки кадров с неизвестным адресом назначения. Один из портов коммутатора конфигурируется как магистральный порт, на который по умолчанию передаются все кадры с неизвестным адресом. В маршрутизаторах такой прием применяется давно, позволяя сократить размеры адресных таблиц в сетях, организованных по иерархическому принципу.
Передача кадра на магистральный порт производится в расчете на то, что этот порт подключен к вышестоящему коммутатору при иерархическом соединении коммутаторов в крупной сети, который имеет достаточную емкость адресной таблицы и знает, куда нужно передать любой кадр.
Реализация межсетевого взаимодействия средствами TCP/IP
В настоящее время стек TCP/IP является самым популярным средством организации составных сетей. На рис. 5.4 показана доля, которую составляет тот или иной стек протоколов в общемировой инсталляционной сетевой базе. До 1996 года бесспорным лидером был стек IPX/SPX компании Novell, но затем картина резко изменилась - стек TCP/IP по темпам роста числа установок намного стал опережать другие стеки, а с 1998 года вышел в лидеры и в абсолютном выражении. Именно поэтому дальнейшее изучение функций сетевого уровня будет проводиться на примере стека TCP/IP.

Рис. 5.4. Стек TCP/IP становится основным средством построения составных сетей
Реализация скользящего окна в протоколе TCP
В рамках установленного соединения правильность передачи каждого сегмента должна подтверждаться квитанцией получателя. Квитирование - это один из традиционных методов обеспечения надежной связи. В протоколе TCP используется частный случай квитирования - алгоритм скользящего окна. Идея этого алгоритма была изложена в главе 2, «Основы передачи дискретных данных».
Особенность использования алгоритма скользящего окна в протоколе TCP состоит в том, что, хотя единицей передаваемых данных является сегмент, окно определено на множестве нумерованных байтов неструктурированного потока данных, поступающих с верхнего уровня и буферизуемых протоколом TCP. Получающий модуль TCP отправляет «окно» посылающему модулю TCP. Данное окно задает количество байтов (начиная с номера байта, о котором уже была выслана квитанция), которое принимающий модуль TCP готов в настоящий момент принять.
Квитанция (подтверждение) посылается только в случае правильного приема данных, отрицательные квитанции не посылаются. Таким образом, отсутствие квитанции означает либо прием искаженного сегмента, либо потерю сегмента, либо потерю квитанции. В качестве квитанции получатель сегмента отсылает ответное сообщение (сегмент), в которое помещает число, на единицу превышающее максимальный номер байта в полученном сегменте. Это число часто называют номером очереди.
На рис. 5.24 показан поток байтов, поступающий на вход протокола TCP. Из потока байтов модуль TCP нарезает последовательность сегментов. Для определенности на рисунке принято направление перемещения данных справа налево. В этом потоке можно указать несколько логических границ. Первая граница отделяет сегменты, которые уже были отправлены и на которые уже пришли квитанции. Следующую часть потока составляют сегменты, которые также уже отправлены, так как входят в границы, определенные окном, но квитанции на них пока не получены. Третья часть потока - это сегменты, которые пока не отправлены, но могут быть отправлены, так как входят в пределы окна.
И наконец, последняя граница указывает на начало последовательности сегментов, ни один из которых не может быть отправлен до тех пор, пока не придет очередная квитанция и окно не будет сдвинуто вправо.

Рис. 5.24. Особенности реализации алгоритма скользящего окна в протоколе TCP
Если размер окна равен W, а последняя по времени квитанция содержала значение N, то отправитель может посылать новые сегменты до тех пор, пока в очередной сегмент не попадет байт с номером N+W. Этот сегмент выходит за рамки окна, и передачу в таком случае необходимо приостановить до прихода следующей квитанции.
Надежность передачи достигается благодаря подтверждениям и номерам очереди. Концептуально каждому байту данных присваивается номер очереди. Номер очереди для первого байта данных в сегменте передается вместе с этим сегментом и называется номером очереди для сегмента. Сегменты также несут номер подтверждения, который является номером для следующего ожидаемого байта данных, передаваемого в обратном направлении. Когда протокол TCP передает сегмент с данными, он помещает его копию в очередь повторной передачи и запускает таймер. Когда приходит подтверждение для этих данных, соответствующий сегмент удаляется из очереди. Если подтверждение не приходит до истечения срока, то сегмент посылается повторно.
Выбор времени ожидания (тайм-аута) очередной квитанции является важной задачей, результат решения которой влияет на производительность протокола TCP. Тайм-аут не должен быть слишком коротким, чтобы по возможности исключить избыточные повторные передачи, которые снижают полезную пропускную способность системы. Но он не должен быть и слишком большим, чтобы избежать длительных простоев, связанных с ожиданием несуществующей или «заблудившейся» квитанции.
При выборе величины тайм-аута должны учитываться скорость и надежность физических линий связи, их протяженность и многие другие подобные факторы. В протоколе TCP тайм-аут определяется с помощью достаточно сложного адаптивного алгоритма, идея которого состоит в следующем.
При каждой передаче засекается время от момента отправки сегмента до прихода квитанции о его приеме (время оборота). Получаемые значения времени оборота усредняются с весовыми коэффициентами, возрастающими от предыдущего замера к последующему. Это делается с тем, чтобы усилить влияние последних замеров. В качестве тайм-аута выбирается среднее время оборота, умноженное на некоторый коэффициент. Практика показывает, что значение этого коэффициента должно превышать 2. В сетях с большим разбросом времени оборота при выборе тайм-аута учитывается и дисперсия этой величины.
Поскольку каждый байт пронумерован, то каждый из них может быть опознан. Приемлемый механизм опознавания является накопительным, поэтому опознавание номера Х означает, что все байты с предыдущими номерами уже получены. Этот механизм позволяет регистрировать появление дубликатов в условиях повторной передачи. Нумерация байтов в пределах сегмента осуществляется так, чтобы первый байт данных сразу вслед за заголовком имел наименьший номер, а следующие за ним байты имели номера по возрастающей.
Окно, посылаемое с каждым сегментом, определяет диапазон номеров очереди, которые отправитель окна (он же получатель данных) готов принять в настоящее время. Предполагается, что такой механизм связан с наличием в данный момент места в буфере данных.
Варьируя величину окна, можно влиять на загрузку сети. Чем больше окно, тем большую порцию неподтвержденных данных можно послать в сеть. Но если пришло большее количество данных, чем может быть принято программой TCP, данные будут отброшены. Это приведет к излишним пересылкам информации и ненужному увеличению нагрузки на сеть и программу TCP.
С другой стороны, указание окна малого размера может ограничить передачу данных скоростью, которая определяется временем путешествия по сети каждого посылаемого сегмента. Чтобы избежать применения малых окон, получателю данных предлагается откладывать изменение окна до тех пор, пока свободное место не составит 20-40 % от максимально возможного объема памяти для этого соединения.
Но и отправителю не стоит спешить с посылкой данных, пока окно не станет достаточно большим. Учитывая эти соображения, разработчики протокола TCP предложили схему, согласно которой при установлении соединения заявляется большое окно, но впоследствии его размер существенно уменьшается.
Если сеть не справляется с нагрузкой, то возникают очереди в промежуточных узлах - маршрутизаторах и в конечных узлах-компьютерах.
При переполнении приемного буфера конечного узла «перегруженный» протокол TCP, отправляя квитанцию, помещает в нее новый, уменьшенный размер окна. Если он совсем отказывается от приема, то в квитанции указывается окно нулевого размера. Однако даже после этого приложение может послать сообщение на отказавшийся от приема порт. Для этого сообщение должно сопровождаться пометкой «срочно». В такой ситуации порт обязан принять сегмент, даже если для этого придется вытеснить из буфера уже находящиеся там данные. После приема квитанции с нулевым значением окна протокол-отправитель время от времени делает контрольные попытки продолжить обмен данными. Если протокол-приемник уже готов принимать информацию, то в ответ на контрольный 'запрос он посылает квитанцию с указанием ненулевого размера окна.
Другим проявлением перегрузки сети является переполнение буферов в маршрутизаторах. В таких случаях они могут централизованно изменить размер окна, посылая управляющие сообщения некоторым конечным узлам, что позволяет им дифференцированно управлять интенсивностью потока данных в разных частях сети.
Рекомендуемая литература
Стандарты по локальным вычислительным сетям: Справочник. В. К. Щер-бо, В. М. Киреичев, С. И. Самойленко; под ред. С. И. Самойленко. - М.: Радио и связь, 1990.
Практическая передача данных: Модемы, сети и протоколы. Ф. Дженнингс; перев. с англ. - М.: Мир, 1989.
Сети ЭВМ: протоколы стандарты, интерфейсы. Ю. Блэк; перев. с англ. - М.: Мир, 1990.
Fast Ethernet. Л. Куинн, Р. Рассел. - BHV-Киев, 1998.
Коммутация и маршрутизация IP/IPX трафика. М. В. Кульгин, АйТи. - М.: Компьютер-пресс, 1998.
Волоконная оптика в локальных и корпоративных сетях связи. А. Б. Семенов, АйТи. - М.: Компьютер-пресс, 1998.
Протоколы Internet. С. Золотов. - СПб.: BHV - Санкт-Петербург, 1998,
Персональные компьютеры в сетях TCP/IP. Крейг Хант; перев. с англ. - BHV-Киев, 1997.
Вычислительные системы, сети и телекоммуникации. Пятибратов и др. - ФИС, 1998.
Высокопроизводительные сети. Энциклопедия пользователя. Марк А. Спортак и др.; перев. с англ. - Киев, ДиаСофт, 1998.
Средства связи для «последней мили». Денисьев и Мирошников, -Эко-Трендз, 1998.
Синхронные цифровые сети SDH. Н. Н. Слепов. - Эко-Трендз, 1998.
Сети предприятий на основе Windows NT для профессионалов. Стерн, Монти; перев. с англ. - СПб.: Питер, 1999.
Networking Essentials. Сертификационный экзамен - экстерном (экзамен 70-058). Дж. Стюарт, Эд Титтель, Курт Хадсон; перев с англ. - СПб.: Питер Ком, 1999.
Основы построения сетей. Учебное руководство для специалистов MCSE (+CD-ROM). Дж. Челлис, Ч. Перкинс, М. Стриб; перевод с англ. - Лори, 1997.
Компьютерные сети. Учебный курс, 2-е изд. (+CD-ROM). - MicrosoftPress, Русская редакция, 1998.
Сетевые средства Microsoft Windows NT Server 4.0; перев. с англ. СПб.: - BHV - Санкт-Петербург, 1997.
Ресурсы Microsoft Windows NT Server 4.0. Книга 1; перев. с англ. СПб.: - BHV -Санкт-Петербург, 1997.
Толковый словарь по вычислительной технике; перев. с англ. - М.: Издательский отдел «Русская редакция» ТОО «Channel Trading Ltd.», 1995.
Emerging Communications Technologies, 2/e, Uyless Black, Prentice Hall Professional, 1997.
Telecommunications for Managers, 3/e, Stanford H. Rowe, Prentice Hall, 1995.
Data and Computer Communications, 5/e, William Stallings, Prentice Hall, 1997.
ISDN and Broadband ISDN with Frame Relay and ATM, 3/e, William Stallings, Prentice Hall, 1995.
Data Communications, Computer Networks and Open Systems, Fred Halsall, Adisson-Wesley, 1996.
Internetworking with TCP/IP: Principles, Protocols, and Architecture, Duglas E. Comer, Prentice Hall, 1995.
TCP/IP Network Administration, 2/e, Craig Hunt, O'Reilly & Associates, 1998.
27. Computer Networks, Andrew S. Tanenbaum, Prentice Hall, 1996.
Сеансовый уровень
Сеансовый уровень (Session layer) обеспечивает управление диалогом: фиксирует, какая из сторон является активной в настоящий момент, предоставляет средства синхронизации. Последние позволяют вставлять контрольные точки в длинные передачи, чтобы в случае отказа можно было вернуться назад к последней контрольной точке, а не начинать все с начала. На практике немногие приложения используют сеансовый уровень, и он редко реализуется в виде отдельных протоколов, хотя функции этого уровня часто объединяют с функциями прикладного уровня и реализуют в одном протоколе.
Сегменты и потоки
Единицей данных протокола TCP является сегмент. Информация, поступающая к протоколу TCP в рамках логического соединения от протоколов более высокого уровня, рассматривается протоколом TCP как неструктурированный поток
байтов. Поступающие данные буферизуются средствами TCP. Для передачи на сетевой уровень из буфера «вырезается» некоторая непрерывная часть данных, которая и называется сегментом (см. рис. 5.23). В отличие от многих других протоколов, протокол TCP подтверждает получение не пакетов, а байтов потока.
Не все сегменты, посланные через соединение, будут одного и того же размера, однако оба участника соединения должны договориться о максимальном размере сегмента, который они будут использовать. Этот размер выбирается таким образом, чтобы при упаковке сегмента в IP-пакет он помещался туда целиком, то есть максимальный размер сегмента не должен превосходить максимального размера поля данных IP-пакета, В противном случае пришлось бы выполнять фрагментацию, то есть делить сегмент на несколько частей, чтобы разместить его в IP-пакете,
Сетевая статистика
В этой группе собраны наиболее важные статистические показатели - коэффициент использования сегмента (utilization), уровень коллизий, уровень ошибок и уровень широковещательного трафика. Превышение этими показателями определенных порогов в первую очередь говорят о проблемах в том сегменте сети, к которому подключен многофункциональный прибор.
Сетевой уровень
Сетевой уровень (Network layer) служит для образования единой транспортной системы, объединяющей несколько сетей, причем эти сети могут использовать совершенно различные принципы передачи сообщений между конечными узлами и обладать произвольной структурой связей. Функции сетевого уровня достаточно разнообразны. Начнем их рассмотрение на примере объединения локальных сетей.
Протоколы канального уровня локальных сетей обеспечивают доставку данных между любыми узлами только в сети с соответствующей типовой топологией, например топологией иерархической звезды. Это очень жесткое ограничение, которое не позволяет строить сети с развитой структурой, например, сети, объединяющие несколько сетей предприятия в единую сеть, или высоконадежные сети, в которых существуют избыточные связи между узлами. Можно было бы усложнять протоколы канального уровня для поддержания петлевидных избыточных связей, но принцип разделения обязанностей между уровнями приводит к другому решению. Чтобы с одной стороны сохранить простоту процедур передачи данных для типовых топологий, а с другой допустить использование произвольных топологий, вводится дополнительный сетевой уровень.
На сетевом уровне сам термин сеть наделяют специфическим значением. В данном случае под сетью понимается совокупность компьютеров, соединенных между собой в соответствии с одной из стандартных типовых топологий и использующих для передачи данных один из протоколов канального уровня, определенный для этой топологии.
Внутри сети доставка данных обеспечивается соответствующим канальным уровнем, а вот доставкой данных между сетями занимается сетевой уровень, который и поддерживает возможность правильного выбора маршрута передачи сообщения даже в том случае, когда структура связей между составляющими сетями имеет характер, отличный от принятого в протоколах канального уровня. Сети соединяются между собой специальными устройствами, называемыми маршрутизаторами. Маршрутизатор
- это устройство, которое собирает информацию о топологии межсетевых соединений и на ее основании пересылает пакеты сетевого уровня в сеть назначения.
Чтобы передать сообщение от отправителя, находящегося в одной сети, получателю, находящемуся в другой сети, нужно совершить некоторое количество транзитных передач между сетями, или хопов (от hop
- прыжок), каждый раз выбирая подходящий маршрут. Таким образом, маршрут представляет собой последовательность маршрутизаторов, через которые проходит пакет.
На рис. 1.27 показаны четыре сети, связанные тремя маршрутизаторами. Между узлами А и В данной сети пролегают два маршрута: первый через маршрутизаторы 1 и 3, а второй через маршрутизаторы 1, 2 и 3.

Рис. 1.27. Пример составной сети
Проблема выбора наилучшего пути называется маршрутизацией, и ее решение является одной из главных задач сетевого уровня. Эта проблема осложняется тем, что самый короткий путь не всегда самый лучший. Часто критерием при выборе маршрута является время передачи данных по этому маршруту; оно зависит от пропускной способности каналов связи и интенсивности трафика, которая может изменяться с течением времени. Некоторые алгоритмы маршрутизации пытаются приспособиться к изменению нагрузки, в то время как другие принимают решения на основе средних показателей за длительное время. Выбор маршрута может осуществляться и по другим критериям, например надежности передачи.
В общем случае функции сетевого уровня шире, чем функции передачи сообщений по связям с нестандартной структурой, которые мы сейчас рассмотрели на примере объединения нескольких локальных сетей. Сетевой уровень решает также задачи согласования разных технологий, упрощения адресации в крупных сетях и создания надежных и гибких барьеров на пути нежелательного трафика между сетями.
Сообщения сетевого уровня принято называть пакетами (packets). При организации доставки пакетов на сетевом уровне используется понятие «номер сети». В этом случае адрес получателя состоит из старшей части - номера сети и младшей - номера узла в этой сети. Все узлы одной сети должны иметь одну и ту же старшую часть адреса, поэтому термину «сеть» на сетевом уровне можно дать и другое, более формальное определение: сеть - это совокупность узлов, сетевой адрес которых содержит один и тот же номер сети.
На сетевом уровне определяются два вида протоколов. Первый вид - сетевые протоколы (routed protocols) - реализуют продвижение пакетов через сеть. Именно эти протоколы обычно имеют в виду, когда говорят о протоколах сетевого уровня. Однако часто к сетевому уровню относят и другой вид протоколов, называемых протоколами обмена маршрутной информацией или просто протоколами маршрутизации (routing protocols). С помощью этих протоколов маршрутизаторы собирают информацию о топологии межсетевых соединений. Протоколы сетевого уровня реализуются программными модулями операционной системы, а также программными и аппаратными средствами маршрутизаторов.
На сетевом уровне работают протоколы еще одного типа, которые отвечают за отображение адреса узла, используемого на сетевом уровне, в локальный адрес сети. Такие протоколы часто называют протоколами разрешения адресов - Address Resolution Protocol, ARP. Иногда их относят не к сетевому уровню, а к канальному, хотя тонкости классификации не изменяют их сути. Примерами протоколов сетевого уровня являются протокол межсетевого взаимодействия IP стека TCP/IP и протокол межсетевого обмена пакетами IPX стека Novell.
Сетевые анализаторы
Сетевые анализаторы представляют собой эталонные измерительные приборы для диагностики и сертификации кабелей и кабельных систем. Они могут с высокой точностью измерить все электрические параметры кабельных систем, а также работают на более высоких уровнях стека протоколов. Сетевые анализаторы генерируют синусоидальные сигналы в широком диапазоне частот, что позволяет измерять на приемной паре амплитудно-частотную характеристику и перекрестные наводки, затухание и суммарное затухание. Сетевой анализатор представляет собой лабораторный прибор больших размеров, достаточно сложный в обращении.
Многие производители дополняют сетевые анализаторы функциями статистического анализа трафика - коэффициента использования сегмента, уровня широковещательного трафика, процента ошибочных кадров, а также функциями анализатора протоколов, которые обеспечивают захват пакетов разных протоколов в соответствии с условиями фильтров и декодирование пакетов.
Сетевые службы
Для конечного пользователя сеть - это не компьютеры, кабели и концентраторы и даже не информационные потоки, для него сеть - это, прежде всего, тот набор сетевых служб, с помощью которых он получает возможность просмотреть список имеющихся в сети компьютеров, прочитать удаленный файл, распечатать документ на «чужом» принтере или послать почтовое сообщение. Именно совокупность предоставляемых возможностей - насколько широк их выбор, насколько они удобны, надежны и безопасны - определяет для пользователя облик той или иной сети.
Кроме собственно обмена данными, сетевые службы должны решать и другие, более специфические задачи, например, задачи, порождаемые распределенной обработкой данных. К таким задачам относится обеспечение непротиворечивости нескольких копий данных, размещенных на разных машинах (служба репликации), или организация выполнения одной задачи параллельно на нескольких машинах сети (служба вызова удаленных процедур). Среди сетевых служб можно выделить административные, то есть такие, которые в основном ориентированы не на простого пользователя, а на администратора и служат для организации правильной работы сети в целом. Служба администрирования учетных записей о пользователях, которая позволяет администратору вести общую базу данных о пользователях сети, система мониторинга сети, позволяющая захватывать и анализировать сетевой трафик, служба безопасности, в функции которой может входить среди прочего выполнение процедуры логического входа с последующей проверкой пароля, - все это примеры административных служб.
Реализация сетевых служб осуществляется программными средствами. Основные службы - файловая служба и служба печати - обычно предоставляются сетевой операционной системой, а вспомогательные, например служба баз данных, факса или передачи голоса, - системными сетевыми приложениями или утилитами, работающими в тесном контакте с сетевой ОС. Вообще говоря, распределение служб между ОС и утилитами достаточно условно и меняется в конкретных реализациях ОС.
При разработке сетевых служб приходится решать проблемы, которые свойственны любым распределенным приложениям: определение протокола взаимодействия между клиентской и серверной частями, распределение функций между ними, выбор схемы адресации приложений и др.
Одним из главных показателей качества сетевой службы является ее удобство. Для одного и того же ресурса может быть разработано несколько служб, по-разному решающих в общем-то одну и ту же задачу. Отличия могут заключаться в производительности или в уровне удобства предоставляемых услуг. Например, файловая служба может быть основана на использовании команды передачи файла из одного компьютера в другой по имени файла, а это требует от пользователя знания имени нужного файла. Та же файловая служба может быть реализована и так, что пользователь монтирует удаленную файловую систему к локальному каталогу, а далее обращается к удаленным файлам как к своим собственным, что гораздо более удобно. Качество сетевой службы зависит и от качества пользовательского интерфейса - интуитивной понятности, наглядности, рациональности.
При определении степени удобства разделяемого ресурса часто употребляют термин «прозрачность». Прозрачный доступ - это такой доступ, при котором пользователь не замечает, где расположен нужный ему ресурс - на его компьютере или на удаленном. После того как он смонтировал удаленную файловую систему в свое дерево каталогов, доступ к удаленным файлам становится для него совершенно прозрачным. Сама операция монтирования также может иметь разную степень прозрачности - в сетях с меньшей прозрачностью пользователь должен знать и задавать в команде имя компьютера, на котором хранится удаленная файловая система, в сетях с большей степенью прозрачности соответствующий программный компонент сети производит поиск разделяемых томов файлов безотносительно мест их хранения, а затем предоставляет их пользователю в удобном для него виде, например в виде списка или набора пиктограмм.
Для обеспечения прозрачности важен способ адресации (именования) разделяемых сетевых ресурсов.Имена разделяемых сетевых ресурсов не должны зависеть от их физического расположения на том или ином компьютере. В идеале пользователь не должен ничего менять в своей работе, если администратор сети переместил том или каталог с одного компьютера на другой. Сам администратор и сетевая операционная система имеют информацию о расположении файловых систем, но от пользователя она скрыта. Такая степень прозрачности пока редко встречается в сетях, - обычно для получения доступа к ресурсам определенного компьютера сначала приходится устанавливать с ним логическое соединение. Такой подход применяется, например, в сетях Windows NT.
Сетезависимые и сетенезависимые уровни
Функции всех уровней модели OSI могут быть отнесены к одной из двух групп: либо к функциям, зависящим от конкретной технической реализации сети, либо к функциям, ориентированным на работу с приложениями.
Три нижних уровня - физический, канальный и сетевой - являются сетезависимыми, то есть протоколы этих уровней тесно связаны с технической реализацией сети и используемым коммуникационным оборудованием. Например, переход на оборудование FDDI означает полную смену протоколов физического и канального уровней во всех узлах сети.
Три верхних уровня - прикладной, представительный и сеансовый - ориентированы на приложения и мало зависят от технических особенностей построения сети. На протоколы этих уровней не влияют какие бы то ни было изменения в топологии сети, замена оборудования или переход на другую сетевую технологию. Так, переход от Ethernet на высокоскоростную технологию l00VG-AnyLAN не потребует никаких изменений в программных средствах, реализующих функции прикладного, представительного и сеансового уровней.
Транспортный уровень является промежуточным, он скрывает все детали функционирования нижних уровней от верхних. Это позволяет разрабатывать приложения, не зависящие от технических средств непосредственной транспортировки сообщений. На рис. 1.28 показаны уровни модели OSI, на которых работают различные элементы сети. Компьютер с установленной на нем сетевой ОС взаимодействует с другим компьютером с помощью протоколов всех семи уровней. Это взаимодействие компьютеры осуществляют опосредовано через различные коммуникационные устройства: концентраторы, модемы, мосты, коммутаторы, маршрутизаторы, мультиплексоры. В зависимости от типа коммуникационное устройство может работать либо только на физическом уровне (повторитель), либо на физическом и канальном (мост), либо на физическом, канальном и сетевом, иногда захватывая и транспортный уровень (маршрутизатор). На рис. 1.29 показано соответствие функций различных коммуникационных устройств уровням модели OSI.

Рис. 1.28. Сетезависимые и сетенезависимые уровни модели OSI

Рис.1.29. Соответствие функций различных устройств сети уровням модели OSI
Модель OSI представляет хотя и очень важную, но только одну из многих моделей коммуникаций. Эти модели и связанные с ними стеки протоколов могут отличаться количеством уровней, их функциями, форматами сообщений, службами, поддерживаемыми на верхних уровнях, и прочими параметрами.
Сети кампусов
Сети кампусов получили свое название от английского слова campus - студенческий городок. Именно на территории университетских городков часто возникала необходимость объединения нескольких мелких сетей в одну большую сеть. Сейчас это название не связывают со студенческими городками, а используют для обозначения сетей любых предприятий и организаций.
Главными особенностями сетей кампусов являются следующие (рис. 1.32). Сети этого типа объединяют множество сетей различных отделов одного предприятия в пределах отдельного здания или в пределах одной территории, покрывающей площадь в несколько квадратных километров. При этом глобальные соединения в сетях кампусов не используются. Службы такой сети включают взаимодействие между сетями отделов, доступ к общим базам данных предприятия, доступ к общим факс-серверам, высокоскоростным модемам и высокоскоростным принтерам. В результате сотрудники каждого отдела предприятия получают доступ к некоторьм файлам и ресурсам сетей других отделов. Важной службой, предоставляемой сетями кампусов, стал доступ к корпоративным базам данных независимо от того, на каких типах компьютеров они располагаются.
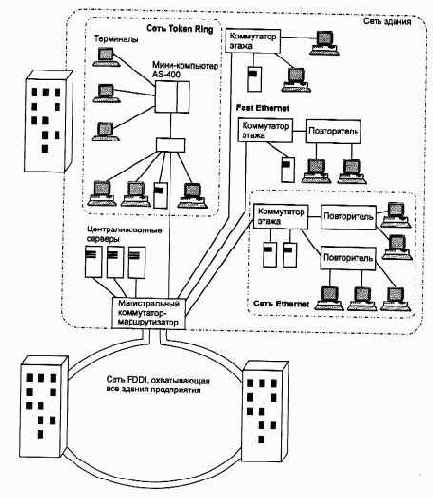
Рис. 1.32. Пример сети кампуса
Именно на уровне сети кампуса возникают проблемы интеграции неоднородного аппаратного и программного обеспечения. Типы компьютеров, сетевых операционных систем, сетевого аппаратного обеспечения могут отличаться в каждом отделе. Отсюда вытекают сложности управления сетями кампусов. Администраторы должны быть в этом случае более квалифицированными, а средства оперативного управления сетью - более совершенными.
Сети отделов
Сети отделов - это сети, которые используются сравнительно небольшой группой сотрудников, работающих в одном отделе предприятия. Эти сотрудники решают некоторые общие задачи, например ведут бухгалтерский учет или занимаются маркетингом. Считается, что отдел может насчитывать до 100-150 сотрудников.
Главной целью сети отдела является разделение локальных ресурсов, таких как приложения, данные, лазерные принтеры и модемы. Обычно сети отделов имеют один или два файловых сервера и не более тридцати пользователей (рис. 1.31). Сети отделов обычно не разделяются на подсети. В этих сетях локализуется большая часть трафика предприятия. Сети отделов обычно создаются на основе какой-либо одной сетевой технологии - Ethernet, Token Ring. Для такой сети характерен один или, максимум, два типа операционных систем. Чаще всего - это сеть с выделенным сервером, например NetWare, хотя небольшое количество пользователей делает возможным использование одноранговых сетевых ОС, таких, например, как Windows 95.

Рис. 1.31. Пример сети масштаба отдела
Задачи управления сетью на уровне отдела относительно просты: добавление новых пользователей, устранение простых отказов, инсталляция новых узлов и установка новых версий программного обеспечения. Такой сетью может управлять сотрудник, посвящающий обязанностям администратора только часть своего времени. Чаще всего администратор сети отдела не имеет специальной подготовки, но является тем человеком в отделе, который лучше всех разбирается в компьютерах, и само собой получается так, что он занимается администрированием сети.
Существует и другой тип сетей, близкий к сетям отделов, - сети рабочих групп. К таким сетям относят совсем небольшие сети, включающие до 10-20 компьютеров, Характеристики сетей рабочих групп практически не отличаются от описанных выше характеристик сетей отделов. Такие свойства, как простота сети и однородность, здесь проявляются в наибольшей степени, в то время как сети отделов могут приближаться в некоторых случаях к следующему по масштабу типу сетей - сетям кампусов.
Сети отделов, кампусов и корпораций
Еще одним популярным способом классификации сетей является их классификация по масштабу производственного подразделения, в пределах которого действует сеть. Различают сети отделов, сети кампусов и корпоративные сети.
Схема менеджер - агент
В основе любой системы управления сетью лежит элементарная схема взаимодействия агента с менеджером. На основе этой схемы могут быть построены системы практически любой сложности с большим количеством агентов и менеджеров разного типа.
Схема «менеджер - агент» представлена на рис. 7.2.

Рис. 7.2. Взаимодействие агента, менеджера и управляемого ресурса
Агент является посредником между управляемым ресурсом и основной управляющей программой-менеджером. Чтобы один и тот же менеджер мог управлять различными реальными ресурсами, создается некоторая модель управляемого ресурса, которая отражает только те характеристики ресурса, которые нужны для его контроля и управления. Например, модель маршрутизатора обычно включает такие характеристики, как количество портов, их тип, таблицу маршрутизации, количество кадров и пакетов протоколов канального, сетевого и транспортного уровней, прошедших через эти порты.
Менеджер получает от агента только те данные, которые описываются моделью ресурса. Агент же является некоторым экраном, освобождающим менеджера от ненужной информации о деталях реализации ресурса. Агент поставляет менеджеру обработанную и представленную в нормализованном виде информацию. На основе этой информации менеджер принимает решения по управлению, а также выполняет дальнейшее обобщение данных о состоянии управляемого ресурса, например, строит зависимость загрузки порта от времени.
Для получения требуемых данных от объекта, а также для выдачи на него управляющих воздействий агент взаимодействует с реальным ресурсом некоторым нестандартным способом. Когда агенты встраиваются в коммуникационное оборудование, то разработчик оборудования предусматривает точки и способы взаимодействия внутренних узлов устройства с агентом. При разработке агента для операционной системы разработчик агента пользуется теми интерфейсами, которые существуют в этой ОС, например интерфейсами ядра, драйверов и приложений. Агент может снабжаться специальными датчиками для получения информации, например датчиками релейных контактов или датчиками температуры.
Менеджер и агент должны располагать одной и той же моделью управляемого ресурса, иначе они не смогут понять друг друга. Однако в использовании этой модели агентом и менеджером имеется существенное различие. Агент наполняет модель управляемого ресурса текущими значениями характеристик данного ресурса, и в связи с этим модель агента называют базой данных управляющей информации - Management Information Base, MIB. Менеджер использует модель, чтобы знать о том, чем характеризуется ресурс, какие характеристики он может запросить у агента и какими параметрами можно управлять.
Менеджер взаимодействует с агентами по стандартному протоколу. Этот протокол должен позволять менеджеру запрашивать значения параметров, хранящихся в базе MIB, а также передавать агенту управляющую информацию, на основе которой тот должен управлять устройством. Различают управление inband, то есть по тому же каналу, по которому передаются пользовательские данные, и управление out-of-band, то есть вне канала, по которому передаются пользовательские данные. Например, если менеджер взаимодействует с агентом, встроенным в маршрутизатор, по протоколу SNMP, передаваемому по той же локальной сети, что и пользовательские данные, то это будет управление inband. Если же менеджер контролирует коммутатор первичной сети, работающий по технологии частотного уплотнения FDM, с помощью отдельной сети Х.25, к которой подключен агент, то это будет управление out-of-band. Управление по тому же каналу, по которому работает сеть, более экономично, так как не требует создания отдельной инфраструктуры передачи управляющих данных. Однако способ out-of-band более надежен, так как он предоставляет возможность управлять оборудованием сети и тогда, когда какие-то элементы сети вышли из строя и по основным каналам оборудование недоступно. Стандарт многоуровневой системы управления TMN имеет в своем названии слово Network, подчеркивающее, что в общем случае для управления телекоммуникационной сетью создается отдельная управляющая сеть, которая обеспечивает режим out-of-band.
Обычно менеджер работает с несколькими агентами, обрабатывая получаемые от них данные и выдавая на них управляющие воздействия. Агенты могут встраиваться в управляемое оборудование, а могут и работать на отдельном компьютере, связанном с управляемым оборудованием по какому-либо интерфейсу. Менеджер обычно работает на отдельном компьютере, который выполняет также роль консоли управления для оператора или администратора системы.
Модель менеджер - агент лежит в основе таких популярных стандартов управления, как стандарты Internet на основе протокола SNMP и стандарты управления ISO/OSI на основе протокола CMIP.
Агенты могут отличаться различным уровнем интеллекта - они могут обладать как самым минимальным интеллектом, необходимым для подсчета проходящих через оборудование кадров и пакетов, так и весьма высоким, достаточным для выполнения самостоятельных действий по выполнению последовательности управляющих действий в аварийных ситуациях, построению временных зависимостей, фильтрации аварийных сообщений и т. п.
Символьно-ориентированные протоколы
Символьно-ориентированные протоколы используются в основном для передачи блоков отображаемых символов, например текстовых файлов. Так как при синхронной передаче нет стоповых и стартовых битов, для синхронизации символов необходим другой метод. Синхронизация достигается за счет того, что передатчик добавляет два или более управляющих символа, называемых символами SYN, перед каждым блоком символов. В коде ASCII символ SYN имеет двоичное значение 0010110, это несимметричное относительно начала символа значение позволяет легко разграничивать отдельные символы SYN при их последовательном приеме. Символы SYN выполняют две функции: во-первых, они обеспечивают приемнику побитную синхронизацию, во-вторых, как только битовая синхронизация достигается, они позволяют приемнику начать распознавание границ символов SYN. После того как приемник начал отделять один символ от другого, можно задавать границы начала кадра с помощью другого специального символа. Обычно в символьных протоколах для этих целей используется символ STX (Start of TeXt, ASCII 0000010). Другой символ отмечает окончание кадра - ЕТХ (End of TeXt, ASCII 0000011).
Однако такой простой способ выделения начала и конца кадра хорошо работал только в том случае, если внутри кадра не было символов STX и ЕТХ. При подключении к компьютеру алфавитно-цифровых терминалов такая задача действительно не возникала. Тем не менее синхронные символьно-ориентированные протоколы позднее стали использоваться и для связи компьютера с компьютером, а в этом случае данные внутри кадра могут быть любые, если, например, между компьютерами передается программа. Наиболее популярным протоколом такого типа был протокол BSC компании IBM. Он работал в двух режимах - непрозрачном, в котором некоторые специальные символы внутри кадра запрещались, и прозрачном, в котором разрешалась передачи внутри кадра любых символов, в том числе и ЕТХ. Прозрачность достигалась за счет того, что перед управляющими символами STX и ЕТХ всегда вставлялся символ DLE (Data Link Escape). Такая процедура называется стаффингом символов (stuff - всякая всячина, заполнитель). А если в поле данных кадра встречалась последовательность DLE ЕТХ, то передатчик удваивал символ DLE, то есть порождал последовательность DLE DLE ЕТХ. Приемник, встретив подряд два символа DLE DLE, всегда удалял первый, но оставшийся DLE уже не рассматривал как начало управляющей последовательности, то есть оставшиеся символы DLE ЕТХ считал просто пользовательскими данными.
Синхронизация
При выполнении запросов к нескольким объектам используется одна из двух схем синхронизации: атомарная или «по возможности». При атомарной схеме запрос выполняется только в том случае, когда все объекты, попадающие в область действия обзора или фильтра, могут успешно выполнить данный запрос. Синхронизация «по возможности» подразумевает передачу запроса всем объектам, к которым запрос относится. Операция завершается при выполнении запроса любым количеством объектов.
Протокол CMIP представляет собой набор операций, прямо соответствующих услугам CMIS. Таким образом, в протоколе CMIP определены операции M-GET, M-SET, M-CREATE
и т. д. Для каждой операции определен формат блока данных, переносимых по сети от менеджера агенту, и наоборот.
Формат протокольных блоков данных CMIP описывается нотацией ASN.1 и имеет гораздо более сложную структуру, чем блоки SNMP. Например, блок данных операции M-GET
имеет поля для задания имен атрибутов, значения которых запрашивает менеджер, а также поля задания параметров обзора и фильтрации, определяющих множество экземпляров объектов, на которые будет воздействовать данный запрос. Имеются также поля для задания параметров прав доступа к объекту.
Синхронные символьно-ориентированные и бит-ориентированные протоколы
В синхронных протоколах между пересылаемыми символами (байтами) нет стартовых и стоповых сигналов, поэтому отдельные символы в этих протоколах пересылать нельзя. Все обмены данными осуществляются кадрами, которые имеют в общем случае заголовок, поле данных и концевик (рис. 2.21). Все биты кадра передаются непрерывным синхронным потоком, что значительно ускоряет передачу данных.

Рис. 2.21. Кадры синхронных протоколов
Так как байты в этих протоколах не отделяются друг от друга служебными сигналами, то одной из первых задач приемника является распознавание границы байт. Затем приемник должен найти начало и конец кадра, а также определить границы каждого поля кадра - адреса назначения, адреса источника, других служебных полей заголовка, поля данных и контрольной суммы, если она имеется.
Большинство протоколов допускает использование в кадре поля данных переменной длины. Иногда и заголовок может иметь переменную длину. Обычно протоколы определяют максимальное значение, которое может иметь длина поля данных. Эта величина называется максимальной единицей передачи данных (Maximum Transfer Unit, MTU). В некоторых протоколах задается также минимальное значение, которое может иметь длина поля данных. Например, протокол Ethernet требует, чтобы поле данных содержало по крайней мере 46 байт данных (если приложение хочет отправить меньшее количество байт, то оно обязано дополнить их до 46 байт любыми значениями). Другие протоколы разрешают использовать поле данных нулевой длины, например FDDI.
Существуют также протоколы с кадрами фиксированной длины, например, в протоколе АТМ кадры фиксированного размера 53 байт, включая служебную информацию. Для таких протоколов необходимо решить только первую часть задачи - распознать начало кадра.
Синхронные протоколы канального уровня бывают двух типов: символьно-ориентированные (байт-ориентированные) и бит-ориентированные. Для обоих характерны одни и те же методы синхронизации бит. Главное различие между ними заключается в методе синхронизации символов и кадров.
Система доменных имен DNS
Соответствие между доменными именами и IP-адресами может устанавливаться как средствами локального хоста, так и средствами централизованной службы. На раннем этапе развития Internet на каждом хосте вручную создавался текстовый файл с известным именем hosts. Этот файл состоял из некоторого количества строк, каждая из которых содержала одну пару «IP-адрес - доменное имя», например 102.54.94.97 - rhino.acme.com.
По мере роста Internet файлы hosts также росли, и создание масштабируемого решения для разрешения имен стало необходимостью.
Таким решением стала специальная служба - система доменных имен (Domain Name System, DNS). DNS - это централизованная служба, основанная на распределенной базе отображений «доменное имя - IP-адрес». Служба DNS использует в своей работе протокол типа «клиент-сервер». В нем определены DNS-серверы и DNS-кли-енты. DNS-серверы поддерживают распределенную базу отображений, а DNS-клиен-ты обращаются к серверам с запросами о разрешении доменного имени в IP-адрес.
Служба DNS использует текстовые файлы почти такого формата, как и файл hosts, и эти файлы администратор также подготавливает вручную. Однако служба DNS опирается на иерархию доменов, и каждый сервер службы DNS хранит только часть имен сети, а не все имена, как это происходит при использовании файлов hosts. При росте количества узлов в сети проблема масштабирования решается созданием новых доменов и поддоменов имен и добавлением в службу DNS новых серверов.
Для каждого домена имен создается свой DNS-сервер. Этот сервер может хранить отображения «доменное имя - IP-адрес» для всего домена, включая все его поддомены. Однако при этом решение оказывается плохо масштабируемым, так как при добавлении новых поддоменов нагрузка на этот сервер может превысить его возможности. Чаще сервер домена хранит только имена, которые заканчиваются на следующем ниже уровне иерархии по сравнению с именем домена. (Аналогично каталогу файловой системы, который содержит записи о файлах и подкаталогах, непосредственно в него «входящих».) Именно при такой организации службы DNS нагрузка по разрешению имен распределяется более-менее равномерно между всеми DNS-серверами сети.
Например, в первом случае DNS- сервер домена mmtru будет хранить отображения для всех имен, заканчивающихся на mmt.ru: wwwl.zil.mmt.ru, ftp.zil.mmt.ru, mail.mmt.ru и т. д. Во втором случае этот сервер хранит отображения только имен типа mail.mmt.ru, www.mmt.ru, а все остальные отображения должны храниться на DNS-сервере поддомена zil.
Каждый DNS-сервер кроме таблицы отображений имен содержит ссылки на DNS-серверы своих поддоменов. Эти ссылки связывают отдельные DNS-серверы в единую службу DNS. Ссылки представляют собой IP-адреса соответствующих серверов. Для обслуживания корневого домена выделено несколько дублирующих друг друга DNS-серверов, IP-адреса которых являются широко известными (их можно узнать, например, в InterNIC).
Процедура разрешения DNS-имени во многом аналогична процедуре поиска файловой системой адреса файла по его символьному имени. Действительно, в обоих случаях составное имя отражает иерархическую структуру организации соответствующих справочников - каталогов файлов или таблиц DNS. Здесь домен и доменный DNS-сервер являются аналогом каталога файловой системы. Для доменных имен, так же как и для символьных имен файлов, характерна независимость именования от физического местоположения.
Процедура поиска адреса файла по символьному имени заключается в последовательном просмотре каталогов, начиная с корневого. При этом предварительно проверяется кэш и текущий каталог. Для определения IP-адреса по доменному имени также необходимо просмотреть все DNS-серверы, обслуживающие цепочку поддоменов, входящих в имя хоста, начиная с корневого домена. Существенным же отличием является то, что файловая система расположена на одном компьютере, а служба DNS по своей природе является распределенной.
Существуют две основные схемы разрешения DNS-имен. В первом варианте работу по поиску IP-адреса координирует DNS-клиент:
DNS-клиент обращается к корневому DNS-серверу с указанием полного доменного имени;
DNS-сервер отвечает, указывая адрес следующего DNS-сервера, обслуживающего домен верхнего уровня, заданный в старшей части запрошенного имени;
DNS-клиент делает запрос следующего DNS-сервера, который отсылает его к DNS-серверу нужного поддомена, и т. д., пока не будет найден DNS-сервер, в котором хранится соответствие запрошенного имени IP-адресу. Этот сервер дает окончательный ответ клиенту.
Такая схема взаимодействия называется нерекурсивной или итеративной, когда клиент сам итеративно выполняет последовательность запросов к разным серверам имен. Так как эта схема загружает клиента достаточно сложной работой, то она применяется редко.
Во втором варианте реализуется рекурсивная процедура:
DNS-клиент запрашивает локальный DNS-сервер, то есть тот сервер, который обслуживает поддомен, к которому принадлежит имя клиента;
если локальный DNS-сервер знает ответ, то он сразу же возвращает его клиенту; это может соответствовать случаю, когда запрошенное имя входит в тот же поддомен, что и имя клиента, а также может соответствовать случаю, когда сервер уже узнавал данное соответствие для другого клиента и сохранил его в своем кэше;
если же локальный сервер не знает ответ, то он выполняет итеративные запросы к корневому серверу и т. д. точно так же, как это делал клиент в первом варианте; получив ответ, он передает его клиенту, который все это время просто ждал его от своего локального DNS-сервера.
В этой схеме клиент перепоручает работу своему серверу, поэтому схема называется косвенной или рекурсивной. Практически все DNS-клиенты используют рекурсивную процедуру.
Для ускорения поиска IP-адресов DNS-серверы широко применяют процедуру кэширования проходящих через них ответов. Чтобы служба DNS могла оперативно отрабатывать изменения, происходящие в сети, ответы кэшируются на определенное время - обычно от нескольких часов до нескольких дней.
Системы пакетной обработки
Системы пакетной обработки, как правило, строились на базе мэйнфрейма - мощного и надежного компьютера универсального назначения. Пользователи подготавливали перфокарты, содержащие данные и команды программ, и передавали их в вычислительный центр. Операторы вводили эти карты в компьютер, а распечатанные результаты пользователи получали обычно только на следующий день (рис. 1.1). Таким образом, одна неверно набитая карта означала как минимум суточную задержку.

Рис. 1.1. Централизованная система на базе мэйнфрейма
Конечно, для пользователей интерактивный режим работы, при котором можно с терминала оперативно руководить процессом обработки своих данных, был бы гораздо удобней. Но интересами пользователей на первых этапах развития вычислительных систем в значительной степени пренебрегали, поскольку пакетный режим - это самый эффективный режим использования вычислительной мощности, так как он позволяет выполнить в единицу времени больше пользовательских задач, чем любые другие режимы. Во главу угла ставилась эффективность работы самого дорогого устройства вычислительной машины - процессора, в ущерб эффективности работы использующих его специалистов.
Сканирование кабеля
Функция позволяет измерять длину кабеля, расстояние до самого серьезного дефекта и распределение импеданса по длине кабеля. При проверке неэкранированной витой пары могут быть выявлены следующие ошибки: расщепленная пара, обрывы, короткое замыкание и другие виды нарушения соединения.
Для сетей Ethernet на коаксиальном кабеле эти проверки могут быть осуществлены на работающей сети.
Функция определения распределения кабельных жил.
Осуществляет проверку правильности подсоединения жил, наличие промежуточных разрывов и перемычек на витых парах. На дисплей выводится перечень связанных между собой контактных групп.
Скорость фильтрации и скорость продвижения
Скорость фильтрации и продвижения кадров - это две основные характеристики производительности коммутатора. Эти характеристики являются интегральными показателями, они не зависят от того, каким образом технически реализован коммутатор.
Скорость фильтрации (filtering)
определяет скорость, с которой коммутатор выполняет следующие этапы обработки кадров:
прием кадра в свой буфер;
просмотр адресной таблицы с целью нахождения порта для адреса назначения кадра;
уничтожение кадра, так как его порт назначения и порт источника принадлежат одному логическому сегменту.
Скорость фильтрации практически у всех коммутаторов является неблокирующей - коммутатор успевает отбрасывать кадры в темпе их поступления.
Скорость продвижения (forwarding)
определяет скорость, с которой коммутатор выполняет следующие этапы обработки кадров.
прием кадра в свой буфер;
просмотр адресной таблицы с целью нахождения порта для адреса назначения кадра;
передача кадра в сеть через найденный по адресной таблице порт назначения.
Как скорость фильтрации, так и скорость продвижения измеряются обычно в кадрах в секунду. Если в характеристиках коммутатора не уточняется, для какого протокола и для какого размера кадра приведены значения скоростей фильтрации и продвижения, то по умолчанию считается, что эти показатели даются для протокола Ethernet и кадров минимального размера, то есть кадров длиной 64 байт (без преамбулы) с полем данных в 46 байт. Если скорости указаны для какого-либо определенного протокола, например Token Ring или FDDI, то они также даны для кадров минимальной длины этого протокола (например, кадров длины 29 байт для протокола FDDI). Применение в качестве основного показателя скорости работы коммутатора кадров минимальной длины объясняется тем, что такие кадры всегда создают для коммутатора наиболее тяжелый режим работы по сравнению с кадрами другого формата при равной пропускной способности переносимых пользовательских данных. Поэтому при проведении тестирования коммутатора режим передачи кадров минимальной длины используется как наиболее сложный тест, который должен проверить способность коммутатора работать при наихудшем сочетании параметров трафика.
Кроме того, для пакетов минимальной длины скорость фильтрации и продвижения максимальна, что имеет немаловажное значение при рекламе коммутатора.
Пропускная способность коммутатора измеряется количеством пользовательских данных (в мегабитах в секунду), переданных в единицу времени через его порты. Так как коммутатор работает на канальном уровне, для него пользовательскими данными являются те данные, которые переносятся в поле данных кадров протоколов канального уровня - Ethernet, Token Ring, FDDI и т. п. Максимальное значение пропускной способности коммутатора всегда достигается на кадрах максимальной длины, так как при этом доля накладных расходов на служебную информацию кадра гораздо ниже, чем для кадров минимальной длины, а время выполнения коммутатором операций по обработке кадра, приходящееся на один байт пользовательской информации, существенно меньше. Поэтому коммутатор может быть блокирующим для кадров минимальной длины, но при этом иметь очень хорошие показатели пропускной способности.
Задержка передачи кадра
измеряется как время, прошедшее с момента прихода первого байта кадра на входной порт коммутатора до момента появления этого байта на его выходном порту. Задержка складывается из времени, затрачиваемого на буферизацию байт кадра, а также времени, затрачиваемого на обработку кадра коммутатором, - просмотра адресной таблицы, принятия решения о фильтрации или продвижении и получения доступа к среде выходного порта.
Величина вносимой коммутатором задержки зависит от режима его работы. Если коммутация осуществляется «на лету», то задержки обычно невелики и составляют от 5 до 40 мкс, а при полной буферизации кадров - от 50 до 200 мкс (для кадров минимальной длины).
Коммутатор - это многопортовое устройство, поэтому для него принято все приведенные выше характеристики (кроме задержки передачи кадра) давать в двух вариантах. Первый вариант - суммарная производительность коммутатора при одновременной передаче трафика по всем его портам, второй вариант - производительность, приведенная в расчете на один порт.Обычно производители коммутаторов указывают общую максимальную пропускную способность устройства.
Скрэмблирование
Перемешивание данных скрэмблером перед передачей их в линию с помощью потенциального кода является другим способом логического кодирования.
Методы скрэмблирования заключаются в побитном вычислении результирующего кода на основании бит исходного кода и полученных в предыдущих тактах бит результирующего кода. Например, скрэмблер может реализовывать следующее соотношение:

где Bi - двоичная цифра результирующего кода, полученная на i-м такте работы скрэмблера, Ai - двоичная цифра исходного кода, поступающая на i-м такте на вход скрэмблера, Bi-з и Bi-5 - двоичные цифры результирующего кода, полученные на предыдущих тактах работы скрэмблера, соответственно на 3 и на 5 тактов ранее текущего такта,

- операция исключающего ИЛИ (сложение по модулю 2). Например, для исходной последовательности 110110000001 скрэмблер даст следующий результирующий код: B1 = А1 = 1 (первые три цифры результирующего кода будут совпадать с исходным, так как еще нет нужных предыдущих цифр)

Таким образом, на выходе скрэмблера появится последовательность 110001101111, в которой нет последовательности из шести нулей, присутствовавшей в исходном коде.
После получения результирующей последовательности приемник передает ее дескрэмблеру, который восстанавливает исходную последовательность на основании обратного соотношения:

Различные алгоритмы скрэмблирования отличаются количеством слагаемых, дающих цифру результирующего кода, и сдвигом между слагаемыми. Так, в сетях ISDN при передаче данных от сети к абоненту используется преобразование со сдвигами в 5 и 23 позиции, а при передаче данных от абонента в сеть - со сдвигами 18 и 23 позиции.
Существуют и более простые методы борьбы с последовательностями единиц, также относимые к классу скрэмблирования.
Для улучшения кода Bipolar AMI используются два метода, основанные на искусственном искажении последовательности нулей запрещенными символами.
На рис. 2.17 показано использование метода B8ZS (Bipolar with 8-Zeros Substitution) и метода HDB3 (High-Density Bipolar 3-Zeros) для корректировки кода AMI.
Исходный код состоит из двух длинных последовательностей нулей: в первом случае - из 8, а во втором - из 5.

Рис. 2.17. Коды B8ZS и HDB3. V - сигнал единицы запрещенной полярности; 1*-сигнал единицы корректной полярности, но заменившей 0 в исходном коде
Код B8ZS исправляет только последовательности, состоящие из 8 нулей. Для этого он после первых трех нулей вместо оставшихся пяти нулей вставляет пять цифр: V-1*-0-V-1*. V здесь обозначает сигнал единицы, запрещенной для данного такта полярности, то есть сигнал, не изменяющий полярность предыдущей единицы, 1* - сигнал единицы корректной полярности, а знак звездочки отмечает тот факт, что в исходном коде в этом такте была не единица, а ноль. В результате на 8 тактах приемник наблюдает 2 искажения - очень маловероятно, что это случилось из-за шума на линии или других сбоев передачи. Поэтому приемник считает такие нарушения кодировкой 8 последовательных нулей и после приема заменяет их на исходные 8 нулей. Код B8ZS построен так, что его постоянная составляющая равна нулю при любых последовательностях двоичных цифр.
Код HDB3 исправляет любые четыре подряд идущих нуля в исходной последовательности. Правила формирования кода HDB3 более сложные, чем кода B8ZS. Каждые четыре нуля заменяются четырьмя сигналами, в которых имеется один сигнал V. Для подавления постоянной составляющей полярность сигнала V чередуется при последовательных заменах. Кроме того, для замены используются два образца четырехтактовых кодов. Если перед заменой исходный код содержал нечетное число единиц, то используется последовательность 000V, а если число единиц было четным - последовательность 1*00V.
Улучшенные потенциальные коды обладают достаточно узкой полосой пропускания для любых последовательностей единиц и нулей, которые встречаются в передаваемых данных. На рис. 2.18 приведены спектры сигналов разных кодов, полученные при передаче произвольных данных, в которых различные сочетания нулей и единиц в исходном коде равновероятны. При построении графиков спектр усреднялся по всем возможным наборам исходных последовательностей.
Естественно, что результирующие коды могут иметь и другое распределение нулей и единиц. Из рис. 2.18 видно, что потенциальный код NRZ обладает хорошим спектром с одним недостатком - у него имеется постоянная составляющая. Коды, полученные из потенциального путем логического кодирования, обладают более узким спектром, чем манчестерский, даже при повышенной тактовой частоте (на рисунке спектр кода 4В/5В должен был бы примерно совпадать с кодом B8ZS, но он сдвинут в область более высоких частот, так как его тактовая частота повышена на 1/4 по сравнению с другими кодами). Этим объясняется применение потенциальных избыточных и скрэмблированных кодов в современных технологиях, подобных FDDI, Fast Ethernet, Gigabit Ethernet, ISDN и т. п. вместо манчестерского и биполярного импульсного кодирования.

Рис. 2.18. Спектры потенциальных и импульсных кодов
Служба коммутируемых цифровых каналов Switched
Если все коммутаторы телефонной сети работают по технологии цифровой коммутации TDM, то кажется, что перевод абонентского окончания на передачу данных в цифровой форме - не такая уж сложная вещь. И, имея сеть цифровых телефонных коммутаторов, нетрудно сделать ее полностью цифровой. Однако это не так. Передача данных со скоростью 64 Кбит/с в дуплексном режиме требует либо прокладки между жилыми домами и АТС новых кабелей, либо специальных усилителей-регенераторов на обоих концах абонентского окончания, то есть в том числе и в квартирах. Оба способа связаны с большими затратами труда и материальных средств, так как аналоговые телефонные сети вполне довольствуются тем медным проводом, который в больших количествах уже проложен между АТС и домами того района города, который данная АТС обслуживает и который заканчивается пассивной телефонной розеткой, а не усилителем-регенератором.
Поэтому массовый переход на полностью цифровые телефонные сети связан с большими капиталовложениями и требует значительного времени для его осуществления, что и показала жизнь.
Однако для некоторых особо требовательных абонентов, которые согласны заплатить за повышения качества и скорости коммутируемых каналов, телефонные компании уже достаточно давно предлагают цифровые коммутируемые службы. Обычно такими абонентами являются корпоративные абоненты, которым нужен быстрый и качественный доступ к корпоративной информации.
Одной из первых служб такого рода стала служба Switched 56, предлагаемая различными телекоммуникационными компаниями в США, Англии и некоторых других странах. Технология этой службы (которая в разных странах имеет разное название, например, в Англии - Kilostream) основана на 4-проводном окончании каналов Т1. Абонент для подключения к сети должен установить у себя соответствующее оборудование, представляющее собой DSU/CSU со встроенным блоком автовызова. Использование 8-го бита для передачи номера вызываемого абонента, а также для других служебных целей ограничивает скорость передачи данных до 56 Кбит/с.
Типичная схема функционирования службы Switched 56 показана на рис. 6.15.
Рис. 6.15.
Функционирование службы Switched 56
Абонентами обычно являются компьютеры или локальные сети, подключаемые к сети с помощью маршрутизатора или удаленного моста. Местные станции соединяются с некоторой центральной станцией, которая коммутирует цифровые потоки Т1/Е1. Сеть является полностью цифровой и поддерживает различные скорости передачи данных - от 2400 бит/с до 56 Кбит/с. Абоненты службы Switched 56 подключаются также к общей публичной телефонной сети, однако соединения со скоростью 56 Кбит/с возможны только в том случае, когда оба абонента пользуются этой службой.
Стандарты службы Switched 56 разные в разных компаниях и разных странах. Сегодня этот вид службы вытесняется сетями ISDN, стандарты которых являются международными, хотя в этой области также имеются проблемы совместимости сетей разных стран.
Сочетание коммутаторов и концентраторов
При построении небольших сетей, составляющих нижний уровень иерархии корпоративной сети, вопрос о применении того или иного коммуникационного устройства сводится к вопросу о выборе между концентратором или коммутатором.
При ответе на этот вопрос нужно принимать во внимание несколько факторов. Безусловно, немаловажное значение имеет стоимость в пересчете за порт, которую нужно заплатить при выборе устройства. Из технических соображений в первую очередь нужно принять во внимание существующее распределение трафика между узлами сети. Кроме того, нужно учитывать перспективы развития сети: будут ли в скором времени применяться мультимедийные приложения, будет ли модернизироваться компьютерная база. Если да, то нужно уже сегодня обеспечить резервы по пропускной способности применяемого коммуникационного оборудования. Использование технологии intranet также ведет к увеличению объемов трафика, циркулирующего в сети, и это также необходимо учитывать при выборе устройства.
При выборе типа устройства - концентратор или коммутатор - нужно еще определить и тип протокола, который будут поддерживать его порты (или протоколов, если идет речь о коммутаторе, так как каждый порт может поддерживать отдельный протокол).
Сегодня выбор делается между протоколами трех скоростей - 10, 100 и 1000 Мбит/с. Поэтому, сравнивая применимость концентратора или коммутатора, необходимо рассмотреть варианты концентратора с портами на 10,100 и 1000 Мбит/с, а также несколько вариантов коммутаторов с различными комбинациями скоростей на портах.
Рассмотрим для примера вопрос о применимости коммутатора в сети с одним сервером и несколькими рабочими станциями, взаимодействующими только с сервером (рис. 4.43). Такая конфигурация сети часто встречается в сетях масштаба рабочей группы, особенно в сетях NetWare, где стандартные клиентские оболочки не могут взаимодействовать друг с другом.

Рис. 4.43. Сеть с выделенным сервером
Если коммутатор имеет все порты с одинаковой пропускной способностью, например 10 Мбит/с, в этом случае пропускная способность порта в 10 Мбит/с будет распределяться между всеми компьютерами сети.
Возможности коммутатора по повышению общей пропускной способности сети оказываются для такой конфигурации невостребованными. Несмотря на микросегментацию сети, ее пропускная способность ограничивается пропускной способностью протокола одного порта, как и в случае применения концентратора с портами 10 Мбит/с. Небольшой выигрыш при использовании коммутатора будет достигаться лишь за счет уменьшения количества коллизий - вместо коллизий кадры будут просто попадать в очередь к передатчику порта коммутатора, к которому подключен сервер.
Чтобы коммутатор работал в сетях с выделенным сервером более эффективно, производители коммутаторов выпускают модели с одним высокоскоростным портом на 100 Мбит/с для подключения сервера и несколькими низкоскоростными портами на 10 Мбит/с для подключения рабочих станций. В этом случае между рабочими станциями распределяется уже 100 Мбит/с, что позволяет обслуживать в неблокирующем режиме 10-30 станций в зависимости от интенсивности создаваемого ими трафика.
Однако с таким коммутатором может конкурировать концентратор, поддерживающий протокол с пропускной способностью 100 Мбит/с, например Fast Ethernet. Его стоимость в пересчете за порт будет несколько ниже стоимости за порт коммутатора с одним высокоскоростным портом, а производительность сети примерно та же.
Очевидно, что выбор коммуникационного устройства для сети с выделенным сервером достаточно сложен. Для принятия окончательного решения нужно принимать во внимание перспективы развития сети в отношении движения к сбалансированному трафику. Если в сети вскоре может появигься взаимодействие между рабочими станциями или же второй сервер, то выбор необходимо делать в пользу коммутатора, который сможет поддержать дополнительный трафик без ущерба по отношению к основному.
В пользу коммутатора можег сыграгь и фактор расстояний - применение коммутаторов не ограничиваег максимальный диаметр сети величинами в 2500 м или 210 м, которые определяют размеры домена коллизий при использовании концентраторов Ethernet и Fast Ethernet.
В целом существует тенденция постепенного вытеснения концентраторов коммутаторами, которая наблюдается примерно с 1996 года, который был назван весьма авторитетным журналом Data Communications «годом коммутаторов» в ежегодном прогнозе рынка сетевого оборудования.
Соединения
Для организации надежной передачи данных предусматривается установление логического соединения
между двумя прикладными процессами. Поскольку соединения устанавливаются через ненадежную коммуникационную систему, основанную на протоколе IP, то во избежание ошибочной инициализации соединений используется специальная многошаговая процедура подтверждения связи.
Соединение в протоколе TCP идентифицируется парой полных адресов обоих взаимодействующих процессов - сокетов. Каждый из взаимодействующих процессов может участвовать в нескольких соединениях.
Формально соединение можно определить как набор параметров, характеризующий процедуру обмена данными между двумя процессами. Помимо полных адресов процессов этот набор включает и параметры, значения которых определяются в результате переговорного процесса модулей TCP двух сторон соединения. К таким параметрам относятся, в частности, согласованные размеры сегментов, которые может посылать каждая из сторон, объемы данных, которые разрешено передавать без получения на них подтверждения, начальные и текущие номера передаваемых байтов. Некоторые из этих параметров остаются постоянными в течение всего сеанса связи, а некоторые адаптивно изменяются.
В рамках соединения осуществляется обязательное подтверждение правильности приема для всех переданных сообщений и при необходимости выполняется повторная передача. Соединение в TCP позволяет вести передачу данных одновременно в обе Стороны, то есть полнодуплексную передачу.
Соотношение коммутации и маршрутизации в корпоративных сетях
До недавнего времени сложившимся информационным потокам корпоративной сети наилучшим образом соответствовала следующая иерархическая структура. На нижнем уровне (уровне отделов) располагались сегменты сети, построенные на быстро работающих повторителях и коммутаторах. Сегменты включали в себя как рабочие станции так и серверы. В большинстве случаев было справедливо эмпирическое соотношение 80/20, в соответствии с которым основная часть трафика (80 %) циркулировала внутри сегмента, то есть порождалась запросами пользователей рабочих станций к серверам своего же сегмента.
На более высоком уровне располагался маршрутизатор, к которому подключалось сравнительно небольшое количество внутренних сетей, построенные на коммутаторах. Через порты маршрутизатора проходил трафик обращений рабочих станций одних сетей к серверам других сетей. Известно, что маршрутизатор затрачивает больше времени на обработку каждого пакета, чем коммутатор, поскольку он выполняет более сложную обработку трафика, включая интеллектуальные алгоритмы фильтрации, выбор маршрута при наличии нескольких возможных путей и т. п. С другой стороны, трафик, проходящий через порты маршрутизатора был менее интенсивный, чем внутрисегментный, поэтому сравнительно низкая производительность маршрутизатора не делала его узким местом.
Сегодня ситуация в корпоративных сетях быстро меняется. Количество пользователей стремительно растет. Пользователи избавляются от устаревающих текстовых приложений, отдавая предпочтение Web-интерфейсу. А завтра эти же пользователи будут работать с аудио, видео, push и другими, абсолютно новыми приложениями, основанными на новых технологиях распространения пакетов, таких как IP Multicast и RSVP. Не работает и старое правило 80/20, сегодня большое количество информации берется из публичных серверов Internet, а также из Web-серверов других подразделений предприятия, создавая большой межсетевой трафик. Существующие сети не оптимизировались для таких непредсказуемых потоков тра-фика, когда каждый может общаться почти с каждым. А с проникновением в корпоративные сети технологии Gigabit Ethernet эта проблема обострится еще больше.
Таким образом, сегодня образовался большой разрыв между производительностью типичного маршрутизатора и типичного коммутатора. В этой ситуации возможны два решения: либо отказаться вообще от маршрутизации, либо увеличить ее производительность.
Соответствие уровней стека TCP/IP семиуровневой модели ISO/OSI
Так как стек TCP/IP был разработан до появления модели взаимодействия открытых систем ISO/OSI, то, хотя он также имеет многоуровневую структуру, соответствие уровней стека TCP/IP уровням модели OSI достаточно условно (рис. 5.6). Рассматривая многоуровневую архитектуру TCP/IP, можно выделить в ней, подобно архитектуре OSI, уровни, функции которых зависят от конкретной технической реализации сети, и уровни, функции которых ориентированны на работу с приложениями (рис. 5.7).

Рис. 5.6.
Соответствие уровней стека TCP/IP семиуровневой модели OSI

Рис. 5.7.
Сетезависимые и сетенезависимые уровни стека TCP/IP
Протоколы прикладного уровня стека TCP/IP работают на компьютерах, выполняющих приложения пользователей. Даже полная смена сетевого оборудования в общем случае не должна влиять на работу приложений, если они получают доступ к сетевым возможностям через протоколы прикладного уровня.
Протоколы транспортного уровня уже более зависят от сети, так как они реализуют интерфейс к уровням, непосредственно организующим передачу данных по сети. Однако, подобно протоколам прикладного уровня, программные модули, реализующие протоколы транспортного уровня, устанавливаются только на конечных узлах. Протоколы двух нижних уровней являются сетезависимыми, а следовательно, программные модули протоколов межсетевого уровня и уровня сетевых интерфейсов устанавливаются как на конечных узлах составной сети, так и на маршрутизаторах.
Каждый коммуникационный протокол оперирует с некоторой единицей передаваемых данных. Названия этих единиц иногда закрепляются стандартом, а чаще просто определяются традицией. В стеке TCP/IP за многие годы его существования образовалась устоявшаяся терминология в этой области (рис. 5.8).

Рис. 5.8.
Название единиц данных, используемые в TCP/IP
Потоком называют данные, поступающие от приложений на вход протоколов транспортного уровня TCP и UDP.
Протокол TCP нарезает из потока данных сегменты.
Единицу данных протокола UDP часто называют дейтаграммой
(или датаграммой). Дейтаграмма - это общее название для единиц данных, которыми оперируют протоколы без установления соединений. К таким протоколам относится и протокол межсетевого взаимодействия IP.
Дейтаграмму протокола IP называют также пакетом.
В стеке TCP/IP принято называть кадрами (фреймами)
единицы данных протоколов, на основе которых IP-пакеты переносятся через подсети составной сети. При этом не имеет значения, какое название используется для этой единицы данных в локальной технологии.
Сосуществование АТМ с традиционными технологиями локальных сетей
Технология АТМ разрабатывалась сначала как «вещь в себе», без учета того факта, что в существующие технологии сделаны большие вложения и поэтому никто не станет сразу отказываться от установленного и работающего оборудования, даже если появляется новое, более совершенное. Это обстоятельство оказалось не столь важным для территориальных сетей, которые в случае необходимости могли предоставить свои оптоволоконные каналы для построения сетей АТМ. Учитывая, что стоимость высокоскоростных оптоволоконных каналов, проложенных на большие расстояния, часто превышает стоимость остального сетевого оборудования, переход на новую технологию АТМ, связанный с заменой коммутаторов, во многих случаях оказывался экономически оправданным.
Для локальных сетей, в которых замена коммутаторов и сетевых адаптеров равнозначна созданию новой сети, переход на технологию АТМ мог быть вызван только весьма серьезными причинами. Гораздо привлекательнее полной замены существующей локальной сети новой сетью АТМ выглядела возможность «постепенного» внедрения технологии АТМ в существующую на предприятии сеть. При таком подходе фрагменты сети, работающие по новой технологии АТМ, могли бы мирно сосуществовать с другими частями сети, построенными на основе традиционных технологий, таких как Ethernet или FDDI, улучшая характеристики сети там, где это нужно, и оставляя сети рабочих групп или отделов в прежнем виде. Применение маршрутизаторов IP, реализующих протокол Classical IP, решает эту проблему, но такое решение не всегда устраивает предприятия, пользующиеся услугами локальных сетей, так как, во-первых, требуется обязательная поддержка протокола IP во всех узлах локальных сетей, а во-вторых, требуется установка некоторого количества маршрутизаторов, что также не всегда приемлемо. Отчетливо ощущалась необходимость способа согласования технологии АТМ с технологиями локальных сетей без привлечения сетевого уровня.
В ответ на такую потребность АТМ Forum разработал спецификацию, называемую LAN emulation, LANE (то есть эмуляция локальных сетей), которая призвана обеспечить совместимость традиционных протоколов и оборудования локальных сетей с технологией АТМ.
Эта спецификация обеспечивает совместную работу этих технологий на канальном уровне. При таком подходе коммутаторы АТМ работают в качестве высокоскоростных коммутаторов магистрали локальной сети, обеспечивая не только скорость, но и гибкость соединений коммутаторов АТМ между собой, поддерживающих произвольную топологию связей, а не только древовидные структуры.
Спецификация LANE определяет способ преобразования кадров и адресов МАС - уровня традиционных технологий локальных сетей в ячейки и коммутируемые виртуальные соединения SVC технологии АТМ, а также способ обратного преобразования. Всю работу по преобразованию протоколов выполняют специальные компоненты, встраиваемые в обычные коммутаторы локальных сетей, поэтому ни коммутаторы АТМ, ни рабочие станции локальных сетей не замечают того, что они работают с чуждыми им технологиями. Такая прозрачность была одной из главных целей разработчиков спецификации LANE.
Так как эта спецификация определяет только канальный уровень взаимодействия, то с помощью коммутаторов АТМ и компонентов эмуляции LAN можно образовать только виртуальные сети, называемые здесь эмулируемыми сетями, а для их соединения нужно использовать обычные маршрутизаторы.
Рассмотрим основные идеи спецификации на примере сети, изображенной на рис. 6.34.

Рис. 6.34.
Принципы работы технологии LAN emulation
Основными элементами, реализующими спецификацию, являются программные компоненты LEC (LAN Emulation Client) и LES (LAN Emulation Server). Клиент LEC выполняет роль пограничного элемента, работающего между сетью АТМ и станциями некоторой локальной сети. На каждую присоединенную к сети АТМ локальную сеть приходится один клиент LEC.
Сервер LES ведет общую таблицу соответствия МАС - адресов станций локальных сетей и АТМ - адресов пограничных устройств с установленными на них компонентами LEC, к которым присоединены локальные сети, содержащие эти станции. Таким образом, для каждой присоединенной локальной сети сервер LES хранит один АТМ - адрес пограничного устройства LEC и несколько МАС - адресов станций, входящих в эту сеть.
Клиентские части LEC динамически регистрируют в сервере LES МАС - адреса каждой станции, заново подключаемой к присоединенной локальной сети.
Программные компоненты LEC и LES могут быть реализованы в любых устройствах — коммутаторах, маршрутизаторах или рабочих станциях АТМ.
Когда элемент LEC хочет послать пакет через сеть АТМ станции другой локальной сети, также присоединенной к сети АТМ, он посылает запрос на установление соответствия между МАС - адресом и АТМ - адресом серверу LES. Сервер LES отвечает на запрос, указывая АТМ - адрес пограничного устройства LEC, к которому присоединена сеть, содержащая станцию назначения. Зная АТМ - адрес, устройство LEC исходной сети самостоятельно устанавливает виртуальное соединение SVC через сеть АТМ обычным способом, описанным в спецификации UNI. После установления связи кадры MAC локальной сети преобразуются в ячейки АТМ каждым элементом LEC с помощью стандартных функций сборки-разборки пакетов (функции SAR) стека АТМ.
В спецификации LANE также определен сервер для эмуляции в сети АТМ широковещательных пакетов локальных сетей, а также пакетов с неизвестными адресами, так называемый сервер BUS (Broadcast and Unknown Server). Этот сервер распространяет такие пакеты во все пограничные коммутаторы, присоединившие свои сети к эмулируемой сети.
В рассмотренном примере все пограничные коммутаторы образуют одну эмулируемую сеть. Если же необходимо образовать несколько эмулируемых сетей, не взаимодействующих прямо между собой, то для каждой такой сети необходимо активизировать собственные серверы LES и BUS, а в пограничных коммутаторах активизировать по одному элементу LEC для каждой эмулируемой сети. Для хранения информации о количестве активизированных эмулируемых сетей, а также АТМ - адресах соответствующих серверов LES и BUS вводится еще один сервер — сервер конфигурации LECS (LAN Emulation Configuration Server).
Спецификация LANE существует сегодня в двух версиях. Вторая версия ликвидировала некоторые недостатки первой, связанные с отсутствием механизма резервирования серверов LES и BUS в нескольких коммутаторах, что необходимо для надежной работы крупной сети, а также добавила поддержку разных классов трафика.
На основе технологии LANE работает новая спецификация АТМ Forum - Multiprotocol Over АТМ, МРОА. Эта спецификация АТМ определяет эффективную передачу трафика сетевых протоколов - IP, IPX, DECnet и т. п. через сеть АТМ, По назначению она близка к спецификации Classical IP, однако решает гораздо больше задач. Технология МРОА позволяет пограничным коммутаторам 3-го уровня, поддерживающим какой-либо сетевой протокол, но не строящим таблицы маршрутизации, находить кратчайший путь через сеть АТМ. МРОА использует для этого серверный подход, аналогичный тому, что применен в LANE. Сервер МРОА регистрирует адреса (например, IP-адреса) сетей, обслуживаемых пограничными коммутаторами 3-го уровня, а затем по запросу предоставляет их клиентам МРОА, встроенным в эти коммутаторы. С помощью технологии МРОА маршрутизаторы или коммутаторы 3-го уровня могут объединять эмулируемые сети, образованные на основе спецификации LANE.
Совместимость
Совместимость или интегрируемость
означает, что сеть способна включать в себя самое разнообразное программное и аппаратное обеспечение, то есть в ней могут сосуществовать различные операционные системы, поддерживающие разные стеки коммуникационных протоколов, и работать аппаратные средства и приложения от разных производителей. Сеть, состоящая из разнотипных элементов, называется неоднородной или гетерогенной, а если гетерогенная сеть работает без проблем, то она является интегрированной. Основной путь построения интегрированных сетей - использование модулей, выполненных в соответствии с открытыми стандартами и спецификациями.
Современные тенденции
Сегодня вычислительные сети продолжают развиваться, причем достаточно быстро. Разрыв между локальными и глобальными сетями постоянно сокращается во многом из-за появления высокоскоростных территориальных каналов связи, не уступающих по качеству кабельным системам локальных сетей. В глобальных сетях появляются службы доступа к ресурсам, такие же удобные и прозрачные, как и службы локальных сетей. Подобные примеры в большом количестве демонстрирует самая популярная глобальная сеть - Internet.
Изменяются и локальные сети. Вместо соединяющего компьютеры пассивного кабеля в них в большом количестве появилось разнообразное коммуникационное оборудование - коммутаторы, маршрутизаторы, шлюзы. Благодаря такому оборудованию появилась возможность построения больших корпоративных сетей, насчитывающих тысячи компьютеров и имеющих сложную структуру. Возродился интерес к крупным компьютерам - в основном из-за того, что после спада эйфории по поводу легкости работы с персональными компьютерами выяснилось, что системы, состоящие из сотен серверов, обслуживать сложнее, чем несколько больших компьютеров. Поэтому на новом витке эволюционной спирали мэйнфреймы стали возвращаться в корпоративные вычислительные системы, но уже как полноправные сетевые узлы, поддерживающие Ethernet или Token Ring, а также стек протоколов TCP/IP, ставший благодаря Internet сетевым стандартом де-факто.
Проявилась еще одна очень важная тенденция, затрагивающая в равной степени как локальные, так и глобальные сети. В них стала обрабатываться несвойственная ранее вычислительным сетям информация - голос, видеоизображения, рисунки. Это потребовало внесения изменений в работу протоколов, сетевых операционных систем и коммуникационного оборудования. Сложность передачи такой мультимедийной информации по сети связана с ее чувствительностью к задержкам при передаче пакетов данных - задержки обычно приводят к искажению такой информации в конечных узлах сети. Так как традиционные службы вычислительных сетей - такие как передача файлов или электронная почта - создают малочувствительный к задержкам трафик и все элементы сетей разрабатывались в расчете на него, то появление трафика реального времени привело к большим проблемам.
Сегодня эти проблемы решаются различными способами, в том числе и с помощью специально рассчитанной на передачу различных типов трафика технологии АТМ, Однако, несмотря на значительные усилия, предпринимаемые в этом направлении, до приемлемого решения проблемы пока далеко, и в этой области предстоит еще много сделать, чтобы достичь заветной цели - слияния технологий не только локальных и глобальных сетей, но и технологий любых информационных сетей - вычислительных, телефонных, телевизионных и т. п. Хотя сегодня эта идея многим кажется утопией, серьезные специалисты считают, что предпосылки для такого синтеза уже существуют, и их мнения расходятся только в оценке примерных сроков такого объединения - называются сроки от 10 до 25 лет. Причем считается, что основой для объединения послужит технология коммутации пакетов, применяемая сегодня в вычислительных сетях, а не технология коммутации каналов, используемая в телефонии, что, наверно, должно повысить интерес к сетям этого типа, которым и посвящена данная книга.
