Область MPEG-
Рисунок 1. Область MPEG-7.
Чтобы улучшить понимание терминологии введенной выше (т.e. дескриптор, схема описания и DDL), рассмотрите Рисунок 2 и Рисунок 3.

Обратный канал
10.2.8. Обратный канал
Обратный канал (back channel) позволяет передать запрос клиента и/или клиентского терминала серверу. Посредством обратного канала может быть реализована интерактивность. В системе MPEG-4 о необходимости обратного канала (back channel) клиентский терминал оповещается с помощью соответствующего дескриптора элементарного потока, характеризующего параметры этого канала. Терминал клиента открывает этот обратный канал, так же как и обычные каналы. Объекты (например, медиа кодировщики или декодеры), которые соединены через обратный канал известны через параметры, полученные через дескриптор элементарного потока и за счет ассоциации дескриптора элементарного потока с дескриптором объекта. В MPEG-4 аудио, обратный канал обеспечивает обратную связь для настройки скорости передачи, масштабируемости и системы защиты от ошибок.
Общая блок-схема MPEG-аудио
Рисунок 14. Общая блок-схема MPEG-4 аудио
Масштабируемость полосы пропускания является частным случаем масштабируемости скоростей передачи, по этой причине часть потока, соответствующая части спектра полосы пропускания, может быть отброшена при передаче или декодировании.
Масштабируемость сложности кодировщика позволяет кодирующим устройствам различной сложности формировать корректные информационные потоки. Масштабируемость сложности декодера позволяет данному потоку данных быть декодированному приборами с различной сложностью (и ценой). Качество звука, вообще говоря, связано со сложностью используемого кодировщика и декодера Масштабируемость работает в рамках некоторых средств MPEG-4, но может также быть применена к комбинации методик, например, к CELP, как к базовому уровню, и AAC.
Уровень систем MPEG-4 позволяет использовать кодеки, следующие, например, стандартам MPEG-2 AAC. Каждый кодировщик MPEG-4 предназначен для работы в автономном режиме (stand-alone) со своим собственным синтаксисом потока данных. Дополнительная функциональность реализуется за счет возможностей кодировщика и посредством дополнительных средств вне его.
Рисунок 13. Обзор мультимедийных DS
Рисунок 13. Обзор мультимедийных DS MPEG-7
3.5.1.1. Базовые элементы
Спецификация мультимедийных DS MPEG-7 определяет определенное число схемных средств, которые облегчают формирование и выкладку описаний MPEG-7. Схемные средства состоят из корневого элемента, элементов верхнего уровня и средств выкладки (Package Tools). Корневые элементы, которые являются начальными элементами описания MPEG-7, позволяют сформировать полные XML-документы и фрагменты описания MPEG-7. Элементы верхнего уровня, которые позволяют корневым элементам в описании MPEG-7 организовать DS для объектно-ориентированных задач описания, таких как описание изображения, видео, аудио или аудио-визуальный материал, собрания (коллекции), пользователи или семантики мира. Созданы пакетные средства для группирования или ассоциации связанных компонентов DS описаний в каталоги или пакеты. Пакеты полезны для организационных и передающих структур и типов описательной информации MPEG-7 для систем поиска и для помощи при просмотре пользователям, незнакомым с особенностями описаний MPEG-7.
Спецификация мультимедийных DS MPEG-7 определяет также некоторое число базовых элементов, которые используются повторно в качестве фундаментальной конструкции при определении MPEG-7 DS. Многие базовые элементы предоставляют специфические типы данных и математические структуры, такие как вектора и матрицы, которые важны для описания аудио-визуального материала. Они включаются также в качестве элементов для связи медиа файлов и локализации сегментов, областей и т.д. Многие базовые элементы предназначены для специальных нужд описания аудио-визуального материала, таких как описание времени, мест, людей, индивидуальностей, групп, организаций, и других текстовых аннотаций. Из-за их важности для описания аудио-визуального материала, давайте очертим подходы MPEG-7 к описанию временной информации и текстовых аннотаций:
Временная информация: DS для описания времени базируется на стандарте ISO 8601, который был воспринят схемным языком XML. Временные DS предоставляют временную информацию в медиа-потоки и для реального мира.
MPEG- 7 расширяет спецификацию времени ISO 8601 для того, чтобы описать время в терминах стробирования аудио-визуального материала, например, путем подсчета периодов стробирования. Это позволяет поддержать эффективное описание временной информации в больших массивах аудио-визуального материала.
Текстовая аннотация: текстовая аннотация является также важным компонентом многих DS. MPEG-7 предоставляет некоторое число базовых конструкций для текстового аннотирования, включая свободный текст (слова, фразы), структурированный текст (текст плюс назначение слов) и зависимая структурированная аннотация (структурированный текст плюс взаимные связи), для того, чтобы поддерживать широкий диапазон функций текстовых описаний.
3.5.1.2. Управление содержимым
MPEG-7 предоставляет также DS для управления материалом. Эти элементы описывают различные аспекты создания медиа материала, медиа кодирование, запись, форматы файлов и использование материала. Функциональность каждого из этих классов DS представлена ниже [5]:
Создание информации: описывает формирование аудио-визуального материала. Эта информация описывает создание и классификацию аудио-визуального материала и других данных, которые с ним связаны. Информация формирования выдает заголовок (который может быть текстовым или фрагментом аудио-визуального материала), текстовую аннотацию, а также данные о создателях, месте формирования и дате. Классификационная информация описывает, как аудио-визуальный материал классифицируется в таких категориях как жанр, тема, цель, язык и т.д. Она предоставляет также обзор и управляющую информацию, такую как классификация по возрасту, тематический обзор, рекомендации создателей и т.д.. Наконец, информация, сопряженная с материалом, описывает, существует ли другой материал, который связан тематически с данным материалом.
Использование информации: описывает информацию об использовании аудио-визуального материала, такую как права использования, доступность, записи об использовании и финансовая информация.
Правовая информация не включается в описание MPEG-7, вместо этого, предлагаются ссылки на владельцев прав и другие данные, относящиеся к защите авторских прав. Правовые
DS предоставляют эти ссылки в форме уникальных идентификаторов, которые управляются извне. Базовая стратегия описаний MPEG-7 заключается в предоставлении доступа к текущей информации о владельце без возможности непосредственного обсуждения возможных условий доступа к самому материалу. DS доступности и DS записей об использовании предоставляют данные, относящиеся, соответственно к доступности и прошлому использованию материала, такому как широковещательная демонстрация, доставка по требованию, продажа CD и т.д. Наконец, финансовые DS предоставляют информацию, связанную со стоимостью производства и доходами, которые могут результатом использования материала. Информация использования
является обычно динамической, меняющейся за время жизни аудио-визуального материала.
Медиа описание: характеризует характер записи, например, сжатие данных, кодирование и формат записи аудио-визуального материала. DS медиа информации идентифицирует источник материала. Образцы аудио-визуального материала называются медиа профайлами, которые являются версиями исходного материала, полученными возможно посредством другого кодирования или записи в другом формате. Каждый медиа профайл описывается индивидуально в терминах параметров кодирования и положения.
3.5.1.3. Описание содержимого
MPEG-7 предоставляет также DS для описания материала. Эти элементы описывают структуру (области, видео кадры и аудио сегменты) и семантику (объекты, события, абстрактные понятия). Функциональность каждого из классов DS представлена ниже:
Структурные аспекты. DS описывает аудио-визуальный материал с точки зрения его структуры. Структурные
DS формируются на основе DS сегментов, которые представляют пространственную, временную или пространственно-временную структуру аудио-визуального материала. Для получения оглавления или индекса для поиска аудио-визуального материала DS сегменты могут быть организованы в иерархические структуры.
Сегменты могут быть описаны на основе характеристик восприятия с помощью дескрипторов MPEG-7 для цвета, текстуры, формы, движения, аудио параметров и т.д.
Концептуальные аспекты. DS описывает аудио-визуальный материал с точки зрения семантики реального мира и концептуальных представлений. DS семантики включают в себя такие характеристики как объекты, события, абстрактные концепции и отношения. DS структуры и DS семантики имеют отношение к набору связей, который позволяет описать аудио-визуальный материал на основе его структуры и семантики.
3.5.1.4. Навигация и доступ
MPEG-7 предоставляет также DS для облегчения просмотра и извлечения аудио-визуального материала путем определения резюме, разделов, составных частей и вариантов аудио-визуального материала.
Резюме
предоставляет компактное описание аудио-визуального материала, которое призвано облегчить поиск, просмотр, визуализацию и прослушивание аудио-визуального материала. DS резюме содержат два типа режимов навигации: иерархический и последовательный. В иерархическом режиме, информация организована в виде последовательности уровней, каждый из которых описывает аудио-визуальный материал с разной степенью детализации. Вообще, уровни более близкие к корневому предоставляют более общие резюме, периферийные же уровни повествуют о тонких деталях. Последовательные резюме предоставляют последовательность изображений или видео кадров, возможно синхронизованных со звуком, которые могут служить для просмотра слайдов, или аудио-визуальный набросок.
Разделы и декомпозиции описывают различные составляющие аудио-визуального сигнала в пространстве, времени и частоте. Разделы и декомпозиции могут использоваться для описания различных проекций аудио-визуальных данных, которые важны для доступа с разным разрешением.
Вариации предоставляют информацию о различных вариантах аудио-визуальных программ, таких как резюме и аннотации; масштабируемые, сжатые версии и варианты с низким разрешением; а также версии на различных языках– звук, видео, изображение, текст и т.д.
Одной из важных возможностей, обеспечиваемых DS вариации, является выбор наиболее удобной версии аудио-визуальной программы, которая может заменить оригинал, если необходимо, адаптироваться к различным возможностям терминального оборудования, сетевым условиям или предпочтениям пользователя.
3.5.1.5. Организация содержимого
MPEG-7 предоставляет также DS для организации и моделирования собрания аудио-визуального материала, а также его описания. DS собрания организует коллекцию аудио-визуального материала, сегментов, событий, и/или объектов. Это позволяет описать каждое собрание как целое на основе общих характеристик. В частности, для описания значений атрибутов собрания могут быть специфицированы различные модели и статистики.
3.5.1.6. Интеракция с пользователем
Наконец, последний набор DS MPEG-7 имеет отношение к взаимодействию с пользователем. DS взаимодействия с пользователем описывает предпочтения пользователя и историю использования мультимедийного материала. Это позволяет, например, найти соответствие между предпочтениями пользователя и описаниями аудио-визуального материала, для того чтобы облегчить индивидуальный доступ к аудио-визуальному материалу, презентации и пр.
3.5.2. Управление содержимым
Средства управления описанием материала позволяют охарактеризовать жизненный цикл материала.
Материал, охарактеризованный описаниями MPEG-7, может быть доступным в различных форматах и режимах, с разными схемами кодирования. Например, концерт может быть записан в двух разных режимах: звуковом и аудио-визуальном. Каждый из этих режимов может использовать различное кодирование. Это создает несколько медиа профайлов. Наконец, могут быть получены несколько копий одного и того же материала. Эти принципы режимов и профайлов проиллюстрированы на рис 14.

Ограничения пропускной способности для разных типов канала
Рисунок 4.3.7.3. Ограничения пропускной способности для разных типов канала

DSL представляет собой канал ISDN-BRI (Basic Rate Interface; 2*64 + 16 Кбит/c), совместимый с POTS, ISDN и DDS. На Рисунок 4.3.7.3 показаны области применимости различных канальных технологий.
Для 5 Мбит/с при симметричной нагрузке можно работать до расстояний 1500 м (VDSL).
Для 10 Мбит/с при симметричной нагрузке можно работать до расстояний 1200 м.
Для 15 Мбит/с при симметричной нагрузке можно работать до расстояний 1000 м.
Метод модуляции 2B1Q характеризуется четырьмя уровнями амплитудной модуляции (4-PAM; +3, +1, -1 и -3). CAP-модуляция (Carrierless Amplitude and Phase) характеризуется четырьмя уровнями амплитуды и четырьмя фиксированными значениями фазы, что дает в плоскости амплитуда-фаза 16 независимых состояний. DTM-модуляция (Discrete Multi-tone) предполагает использование нескольких смежных, узких частотных диапазонов. На Рисунок 4.3.7.2 показана схема подключения оборудования ADSL для различных оконечных терминалов.

Описание и синхронизация потоков данных для медийных объектов
1.3. Описание и синхронизация потоков данных для медийных объектов
Медиа-объектам может быть нужен поток данных, который преобразуется в один или несколько элементарных потоков. Дескриптор объекта идентифицирует все потоки ассоциированные с медиа-объектом. Это позволяет иерархически обрабатывать кодированные данные, а также ассоциированную медиа-информацию о содержимом (называемом “информация содержимого объекта”).
Каждый поток характеризуется набором дескрипторов для конфигурирования информации, например, чтобы определить необходимые ресурсы записывающего устройства и точность кодированной временной информации. Более тог, дескрипторы могут содержать подсказки относительно QoS, которое необходимо для передачи (например, максимальное число бит/с, BER, приоритет и т.д.)
Синхронизация элементарных потоков осуществляется за счет временных меток блоков данных в пределах элементарных потоков. Уровень синхронизации управляет идентификацией таких блоков данных (модулей доступа) и работой с временными метками. Независимо от типа среды, этот слой позволяет идентифицировать тип модуля доступа (например, видео или аудио кадры, команды описания сцены) в элементарных потоках, восстанавливать временную базу медиа-объекта или описания сцены, и осуществлять их синхронизацию. Синтаксис этого слоя является конфигурируемым самыми разными способами, обеспечивая работу с широким спектром систем.
Описание синтаксиса
8.4. Описание синтаксиса
MPEG-4 определяет язык синтаксического описания чтобы характеризовать точный двоичный синтаксис для двоичных потоков, несущих медиа-объекты и для потоков с информацией описания сцены. Это уход от прошлого подхода MPEG, использовавшего язык псевдо C. Новый язык является расширением C++, и используется для интегрированного описания синтаксического представления объектов и классов медиа-объектов и сцен. Это предоставляет удобный и универсальный способ описания синтаксиса. Программные средства могут использоваться для обработки синтаксического описания и генерации необходимого кода для программ, которые выполняют верификацию.
описывает базовый подход
Рисунок 12 описывает базовый подход алгоритмов MPEG-4 видео к кодированию входной последовательности изображений прямоугольной и произвольной формы.

Особенности стандарта MPEG-
1. Особенности стандарта MPEG-4
Стандарт MPEG-4 предоставляет технологии для нужд разработчиков, сервис-провайдеров и конечных пользователей.
Для разработчиков, MPEG-4 позволяет создавать объекты, которые обладают большей адаптивностью и гибкостью, чем это возможно сейчас с использованием разнообразных технологий, таких как цифровое телевидение, анимационная графика WWW и их расширения. Новый стандарт делает возможным лучше управлять содержимым и защищать авторские права.
Для сетевых провайдеров MPEG-4 предлагает прозрачность данных, которые могут интерпретироваться и преобразовываться приемлемые сигнальные сообщения для любой сети посредством стандартных процедур. MPEG-4 предлагает индивидуальные QoS-дескрипторы (Quality of Service) для различных сред MPEG-4. Точное преобразование параметров QoS для каждой из сред в сетевые значения QoS находится за пределами регламентаций MPEG-4 (оставлено на усмотрение сетевых провайдеров). Передача QoS-дескрипторов MPEG-4 по схеме точка-точка оптимизирует транспортировку данных в гетерогенных средах.
Для конечных пользователей, MPEG-4 предлагает более высокий уровень взаимодействия с содержимым объектов. Стандарт транспортировать мультимедиа данные через новые сети, включая те, которые имеют низкую пропускную способностью, например, мобильные. Описания приложений MPEG-4 можно найти на странице http://www.cselt.it/mpeg.
Стандарт MPEG-4 определяет следующее:
Представляет блоки звуковой, визуальной и аудиовизуальной информации, называемые "медийными объектами". Эти медийные объекты могут быть естественного или искусственного происхождения; это означает, что они могут быть записаны с помощью камеры или микрофона, а могут быть и сформированы посредством ЭВМ;
Описывает композицию этих объектов при создании составных медийных объектов, которые образуют аудиовизуальные сцены;
Мультиплексирование и синхронизацию данных, ассоциированных с медийными объектами, так чтобы они могли быть переданы через сетевые каналы, обеспечивая QoS, приемлемое для природы специфических медийных объектов; и
Взаимодействие с аудиовизуальной сценой, сформированной на принимающей стороне.
1.1. Кодированное представление медийных объектов
Аудиовизуальные сцены MPEG-4 формируются из нескольких медийных объектов, организованных иерархически. На периферии иерархии находятся примитивные медийные объекты, такие как:
статические изображения (например, Фон изображения),
видео-объекты (например, говорящее лицо – без фона)
аудио-объекты (например, голос данного лица);
и т.д.
MPEG-4 стандартизует число таких примитивных медиа-объектов, способных представлять как естественные, так и синтетические типы содержимого, которые могут быть 2- или 3-мерными. Кроме медиа-объектов, упомянутых выше и показанных на Рисунок 1, MPEG-4 определяет кодовое представление объектов, такое как:
• текст и графика;
• говорящие синтезированные головы и ассоциированный текст, использованный для синтеза речи и анимации головы;
• синтезированный звук
Медиа-объекты в его кодированной форме состоит из описательных элементов, которые позволяют обрабатывать его в аудио-визуальной сцене, а также, если необходимо, ассоциированный с ним поток данных. Важно заметить, что кодированная форма, каждого медиа-объекта может быть представлена независимо от его окружения или фона.
Кодовое представление медиа-объектов максимально эффективно с точки зрения получения необходимой функциональности. Примерами такой функциональности являются разумная обработка ошибок, легкое извлечение и редактирование объектов и представление объектов в масштабируемой форме.
Относительное время начала и конца
8.3.2. Относительное время начала и конца
Два или более элементарных потоков или потоков сегментов могут быть синхронизованы друг относительно друга, путем определения того, что они начинаются ("CoStart") или кончаются ("CoEnd") в одно и то же время или завершение одного совпадает с началом другого ("Meet").
Важно заметить, что существует два класса объектов MPEG-4. Синхронизация и рэндеринг объекта MPEG-4, который использует элементарный поток, такого как видео, не определяется одним потоком, но также соответствующими узлами BIFS и их синхронизацией. В то время как синхронизация и рэндеринг объекта MPEG-4, который не использует поток, такой как текст или прямоугольник, определяется только соответствующими узлами BIFS и их синхронизацией.
Модель FlexTime позволяет автору материала выражать синхронизацию объектов MPEG-4 с потоками или сегментами потоков, путем установления временных соотношений между ними.
Временные соотношения (или относительные временные метки) могут рассматриваться как "функциональные" временные метки, которые используются при воспроизведении. Таким образом, действующее лицо FlexTime может:
Компенсировать различные сетевые задержки с помощью поддержки синхронизованной задержки прибытия потока, прежде чем действующее лицо начнет рэндеринг/воспроизведение ассоциированного с ним узла.
Компенсировать различные сетевые разбросы задержки путем поддержки синхронизованного ожидания прибытия сегмента потока.
Синхронизовать большое число медиа/BIFS-узлов с некоторым медиа потоком неизвестной длины или неуправляемым временем прибытия.
Синхронизовать модификации BIFS (например, модификации полей сцены) при наличии большого числа узлов/потоков, когда некоторые потоки имеют неизвестную длину или неуправляемое время прибытия.
Замедлять или ускорять рэндеринг/воспроизведение частей потоков, чтобы компенсировать ситуации не синхронности, вызванные неизвестной длиной, неуправляемым временем прибытия или его вариацией.
Параметрическое кодирование звука
10.2.4. Параметрическое кодирование звука
Средства параметрического аудио-кодирования сочетают в себе низкую скорость кодирования обычных аудио сигналов с возможностью модификации скорости воспроизведения или шага при декодировании без бока обработки эффектов. В сочетании со средствами кодирования речи и звука версии 1, ожидается улучшенная эффективность кодирования для использования объектов, базирующихся на кодировании, которое допускает выбор и/или переключение между разными техниками кодирования.
Параметрическое аудио-кодирование использует для кодирования общих аудио сигналов технику HILN (Harmonic and Individual Lines plus Noise) при скоростях 4 кбит/с, а выше применяется параметрическое представление аудио сигналов. Основной идеей этой методики является разложение входного сигнала на аудио объекты, которые описываются соответствующими моделями источника и представляются модельными параметрами. В кодировщике HILN используются модели объектов для синусоид, гармонических тонов и шума.
Как известно из кодирования речи, где используются специализированные модели источника, основанные на процессе генерации звуков в человеческом голосовом тракте, продвинутые модели источника могут иметь преимущество в частности для схем кодирования с очень низкими скоростями передачи.
Из-за очень низкой скорости передачи могут быть переданы только параметры для ограниченного числа объектов. Следовательно, модель восприятия устроена так, чтобы отбирать те объекты, которые наиболее важны для качества приема сигнала.
В HILN, параметры частоты и амплитуды оцифровываются согласно с "заметной разницей", известной из психо-акустики. Спектральный конверт шума и гармонический тон описан с использованием моделирования LPC. Корреляция между параметрами одного кадра и между последовательными кадрами анализируется методом предсказания параметров. Оцифрованные параметры подвергаются энтропийному кодированию, после чего эти данные вводятся в общий информационный поток.
Очень интересное свойство этой схемы параметрического кодирования происходит из того факта, что сигнал описан через параметры частоты и амплитуды. Эта презентация сигнала позволяет изменять скорость и высоту звука простой вариацией параметров декодера. Параметрический аудио кодировщик HILN может быть объединен с параметрическим кодировщиком речи MPEG-4 (HVXC), что позволит получить интегрированный параметрический кодировщик, покрывающий широкий диапазон сигналов и скоростей передачи. Этот интегрированный кодировщик поддерживает регулировку скорости и тона. Используя в кодировщике средство классификации речи/музыки, можно автоматически выбрать HVXC для сигналов речи и HILN для музыкальных сигналов. Такое автоматическое переключение HVXC/HILN было успешно продемонстрировано, а средство классификации описано в информативном приложении стандарта версии 2.
Перемещения камеры
Рисунок 11. Перемещения камеры
Отрывок, для которого все кадры характеризуются определенным типом перемещения камеры, относящееся к одному виду или нескольким, определяет базовые модули для дескриптора перемещения камеры. Каждый составляющий блок описывает начальный момент, длительность, скорость перемещения изображения и увеличение фокусного расстояния (FOE) (или сокращение фокусного расстояния - FOC). Дескриптор представляет объединение этих составляющих блоков, он имеет опцию описания смеси типов перемещения камеры. Смешанный режим воспринимает глобальную информацию о параметрах перемещения камеры, игнорируя детальные временные данные, путем совместного описания нескольких типов движения, даже если эти типы перемещения осуществляются одновременно. С другой стороны, несмешанный режим воспринимает понятие чистых перемещений и их совмещения на протяжении определенного временного интервала. Ситуации, когда одновременно реализуется несколько типов перемещений, описывается, как суперпозиция описаний чистых независимых типов перемещения. В этом режиме описания, временное окно конкретного элементарного сегмента может перекрываться с временным окном другого элементарного сегмента.
3.4.5.2. Траектория движения
Траектория движения объекта является простой характеристикой высокого уровня, определяемая как позиция, во времени и пространстве, одной репрезентативной точки этого объекта.
Этот дескриптор полезен для поиска материала в объектно-ориентированных визуальных базах данных. Он также эффективен в большинстве специальных приложений. В данном контексте с предварительным знанием ряда параметров, траектория позволяет реализовать некоторые дополнительные возможности. При наблюдении, могут выдаваться сигналы тревоги, если траектория воспринимается, как опасная (например, проходит через запретную зону, движение необычно быстро, и т.д.). В спорте могут распознаваться специфические действия (например, обмен ударами у сетки). Кроме того, такое описание позволяет также улучшить обработку данных: для полуавтоматического редактирования медиа данных, траектория может быть растянута, смещена, и т.д., чтобы адаптировать перемещения объекта для любого контекста.
Дескриптор является списком ключевых точек (x,y,z,t) вместе с набором опционных интерполирующих функций, которые описывают путь объекта между ключевыми точками, в терминах ускорения. Скорость неявно известна с помощью спецификации ключевых точек. Ключевые точки специфицируются путем задания моментов времени или их 2-D или 3-D декартовых координат, в зависимости от приложения. Интерполирующие функции определены для каждого компонента x(t), y(t) и z(t) независимо. Некоторые свойства этого представления перечислены ниже:
оно не зависит от пространственно-временного разрешения материала (например, 24 Hz, 30 Hz, 50 Hz, CIF, SIF, SD, HD, и т.д.), то есть если материал существует во многих форматах одновременно, для описания траектории объекта необходим только один набор дескрипторов данного материала.
оно компактно и масштабируемое. Вместо запоминания координаты объекта для каждого кадра, гранулярность дескриптора выбирается на основе ряда ключевых точек, используемых для каждого из временных интервалов.
оно непосредственно допускает широкое разнообразие применений, типа поиска подобия, или категорирование по скорости (быстрые, медленные объекты), поведению (ускоряется, когда приближается к этой области) или по другим характеристикам движения высокого уровня.
3.4.5.3. Параметрическое движение
Модели параметрического движения были использованы в рамках различных схем анализа и обработки изображения, включая сегментацию перемещения, оценки глобального перемещения, и отслеживание объектов. Модели параметрического перемещения использовались уже в MPEG-4, для оценки перемещения и компенсации. В контексте MPEG-7, перемещение является крайне важной характеристикой, связанный с пространственно-временной структурой видео, относящейся к нескольким специфическим MPEG-7 приложениям, таким как запоминание и поиск в видео базах данных, и для целей анализа гиперсвязей. Движение является также критической характеристикой для некоторых специфических приложений, которые уже рассматривались в рамках MPEG-7.
Базовый принцип состоит из описаний движения объектов в видео последовательности, например, в параметрической 2D-модели. В частности, аффинные модели включают в себя трансляции, вращения, масштабирование и их комбинации, планарные модели перспективы делают возможным учет глобальных деформаций, сопряженных с перспективными проекциями, а квадратичные модели позволяют описать более сложные движения.
Параметрическая модель ассоциирована с произвольными фоновыми объектами или объектами переднего плана, определенными как области (группа пикселей) в изображении в пределах заданного интервала времени. Таким способом, движение объекта записывается компактным образом в виде набора из нескольких параметров. Такой подход ведет к очень эффективному описанию нескольких типов перемещения, включая простые преобразования, вращения и изменения масштаба, или более сложные перемещения, такие как комбинации перечисленных выше элементарных перемещений.
Определение подобия характеристик моделей движения является обязательным для эффективного поиска объектов. Оно также необходимо для поддержки запросов нижнего уровня, полезно и в запросах верхнего уровня, таких как "поиск объектов приближающихся к камере ", или для "объектов, описывающих вращательное движение", или "поиск объектов, перемещающихся влево", и т.д.
3.4.5.4. Двигательная активность
Просмотр человеком видео или анимационной последовательности воспринимается как медленная последовательность, быстро протекающий процесс, последовательность действий и т.д. Дескриптор активности
воспринимает интуитивное понятие ‘интенсивность действия’ или ‘темп действий’ в видео сегменте. Примеры высокой ‘активности’ включают такие сцены, как ‘ведение счета голов в футбольном матче’, ‘автомобильные гонки’ и т.д. С другой стороны сцены, типа ‘чтение новостей’, ‘интервью’, ‘снимок’ и т.д. воспринимаются как кадры низкой активности. Видео материал охватывает диапазон от низкой до высокой активности, следовательно нам нужен дескриптор, который позволяет нам точно выражать активность данной видео последовательности/снимка и всесторонне перекрывать упомянутый выше диапазон.
Дескриптор активности полезен для приложений, таких как видео наблюдение, быстрый просмотр, динамическое видео резюмирование, информационные запросы и т.д. Например, мы можем замедлить темп презентации кадров, если дескриптор активности указывает на высокую активность, так чтобы облегчить просмотр этой активности. Другим примером приложения является нахождения всех кадров высокой активности в новой видео программе, которая может рассматриваться как просмотр, так и абстракцию.
3.4.6. Локализация
3.4.6.1. Локатор области
Этот дескриптор допускает локализацию областей внутри изображения или кадров путем спецификации их с помощью краткого и масштабируемого отображения боксов или многогранников.
3.4.6.2. Пространственно-временной локатор
Локатор описывает пространственно-временные области в видео последовательности, такой как области движущихся объектов, и обеспечивает функцию локализации. Главным его приложением является гипермедиа, где выделенная точка находится внутри объекта. Другим ведущим приложением является поиск объектов путем проверки, прошел ли объект определенные точки. Это может использоваться для наблюдения. Дескриптор SpatioTemporalLocator
может описывать как связанные, так и несвязанные области.

Поддерживаемые форматы
2.4.1. Поддерживаемые форматы
Следующие форматы и скорости передачи будут поддерживаться MPEG-4 версия 1:
• Скорости передачи: обычно между 5 кбит/с и 10 Mбит/с
• Форматы: progressive а также interlaced видео
• Разрешение: обычно от sub-QCIF вплоть до HDTV
Поддержка FlexTime в MPEG-
8.3.3. Поддержка FlexTime в MPEG-4
Модель FlexTime поддерживается в MPEG-4 двумя узлами: TemporalTransform и TemporalGroup, и дескриптором: SegmentDescriptor. Узел TemporalTransform специфицирует временные свойства объекта MPEG-4, который нуждается в синхронизации. Узел TemporalGroup специфицирует временные соотношения между объектами, которые представлены узлами TemporalTransform, а SegmentDescriptor идентифицирует доли потока, которые могут быть синхронизованы.
Поддержка 'кодировочных слов' в программах чтения почты
6. Поддержка 'кодировочных слов' в программах чтения почты
6.1. Распознавание 'кодировочных слов' в заголовках сообщений
Программа чтения почты должна осуществлять разбор сообщения и заголовков секций согласно правилам RFC-822, для того чтобы правильно распознать 'кодировочные слова'.
'кодировочные слова' должны распознаваться как:
| (1) | Поле заголовка любого сообщения или части тела, определенное как '*text', или любое поле заголовка, определенное пользователем, должно разбираться следующим образом: Начало обозначается LWS (HR|SP|CRLF), любая последовательность вплоть до 75 печатных символов (не содержащая LWS) должна рассматриваться как кандидат в 'кодировочные слова' и проверяться на соблюдение правил синтаксиса, описанных в секции 2 данного раздела. Любую другую последовательность печатных символов следует рассматривать как обычный ASCII-текст. |
| (2) | Любое поле заголовка, не определенное как '*text' должно разбираться согласно синтаксическим правилам для данного поля заголовка. Однако любое 'слово', которое появляется в пределах 'фразы' должно обрабатываться как 'кодировочное слово', если оно отвечает синтаксическим правилам секции 2. В противном случае оно должно обрабатываться как обычное 'слово'. |
| (3) | Внутри 'комментария', любая последовательность с длиной до 75 символов (не содержащая LWS), которая отвечает синтаксическим правилам секции 2, должна обрабатываться как 'кодировочное слово'. В противном случае оно должно обрабатываться как обычный текст комментария. |
| (4) | Поле заголовка MIME-Version может отсутствовать в 'кодировочных словах', которые обрабатываются согласно данной спецификации. Причиной этого является то, что программа чтения почты не предполагает разбирать весь заголовок сообщения, прежде чем отображать строки, которые могут содержать 'кодировочные слова'. |
6.2. Отображение кодированных слов
Любые распознанные 'кодированные слова' декодируются и, если возможно, полученный в результате текст отображается с использованием стандартного символьного набора.
Декодирование и отображение закодированных слов происходит, после того как структурные поля тела будут разобраны на лексемы. Следовательно, возможно спрятать 'специальные' символы в 'кодировочных словах', которые при отображении будут неотличимы от 'специальных' символов окружающего текста. По этой и другим причинам вообще невозможно транслировать заголовок сообщения, содержащий 'кодировочные слова', к виду, который может анализироваться программой чтения почты (RFC-822).
При отображении конкретного поля заголовка, который содержит несколько 'кодировочных слов', любой LWS, который разделяет пару смежных 'кодировочных слов', игнорируется.
В случае определения в будущем другого кодирования, которое почтовая программа не поддерживает, она может отобразить 'кодировочное слово', как обычный текст или выдать сообщение, что текст не может быть декодирован.
Если почтовая программа не поддерживает использованный символьный набор, она может отобразить 'кодировочное слово', как обычный текст (т.е., так как оно записано в заголовке), может попробовать отобразить его с использованием имеющегося символьного набора, или выдать сообщение, что текст не может быть отображен.
Если используемый символьный набор реализует технику кодового переключения, отображение кодированного текста начинается в режиме "ASCII". Кроме того, почтовая программа должна проверить, что выходное устройство снова в режиме "ASCII", после того как отображено 'кодировочное слово'.
6.3. Обработка почтовой программой некорректно сформированных 'кодировочных слов'
Возможно, что 'кодировочное слово', которое легально согласно синтаксическим правилам секции 2, не корректно сформировано с точки зрения регламентаций использованного правила кодирования. Например:
| (1) | 'Кодировочное слово', которое содержит символы нелегальные для конкретного кодирования (Например, "-" в "B"-кодировании, или SP и HT в "B"- или "Q"-кодировании), является некорректно сформированным. |
| (2) | Любое 'кодировочное слово', которое кодирует нецелое число символов или октетов является некорректно сформированным. |
Поддержка мобильных сетей
3.4.1. Поддержка мобильных сетей
Спецификация H.245 была расширена (H.245v6), чтобы добавить поддержку систем MPEG-4; спецификация DMIF предоставляет возможность работу с сигналами H.245. Мобильные терминалы могут теперь использоваться системами MPEG-4, такими как BIFS и OD-потоки.
Поддержка обычной функциональности и зависящей от содержимого
9.10. Поддержка обычной функциональности и зависящей от содержимого
MPEG-4 видео поддерживает обычные прямоугольные изображения и видео, а также изображения и видео произвольной формы.
Кодирование обычных изображений и видео сходно с обычным кодированием в MPEG-1/2. Оно включает в себя предсказание/компенсацию перемещений за которым следует кодирование текстуры. Для функциональности, зависящей от содержимого, где входная последовательность изображений может иметь произвольную форму и положение, данный подход расширен с помощью кодирования формы и прозрачности. Форма может быть представлена двоичной маской или 8-битовой компонентой, которая позволяет описать прозрачность, если один VO объединен с другими объектами.
9.11. Видео изображение MPEG-4 и схема кодирования
Подробное техническое описание MPEG-аудио
10. Подробное техническое описание MPEG-4 аудио
MPEG-4 кодирование аудио объектов предлагает средства как для представления естественных звуков (таких как речь и музыка) так и синтетических – базирующихся на структурированных описаниях. Представление для синтетического звука может быть получено из текстовых данных или так называемых инструментальных описаний и параметров кодирования для обеспечения специальных эффектов, таких как реверберация и объемное звучание. Представления обеспечивают сжатие и другую функциональность, такую как масштабируемость и обработку эффектов.
Средства аудио кодирования MPEG-4, охватывающие диапазон от 6кбит/с до 24кбит/с, подвергаются верификационным тестированиям для широковещательных приложений цифрового AM-аудио совместно с консорциумом NADIB (Narrow Band Digital Broadcasting). Было обнаружено, что высокое качество может быть получено для одного и того же частотного диапазона с привлечением цифровых методик и что конфигурации масштабируемого кодировщика могут обеспечить лучшие эксплуатационные характеристики.
Поиск и выборка прикладного
Рисунок 26. Поиск и выборка прикладного типа. Сортированная информация из медиа базы данных получается из описаний и запроса
3.6.5.3. Приложение транскодирования среды
Приложение медиа транскодирования также относится к клиентскому типу. Как показано на Рисунок 27, медиа файлы и их описания загружены. Основываясь на описаниях, медиа данные модифицируются (транскодируются), а новая медиа база данных записывается в файл. Более того, может быть специфицирован запрос, который обрабатывается для описаний до транскодирования.

показывает как потоки
Рисунок 3 показывает как потоки, приходящие из сети (или запоминающего устройства), как потоки TransMux, демультиплексируются в потоки FlexMux и передаются соответствующим демультиплексорам FlexMux, которые извлекают элементарные потоки. Элементарные потоки (ES) анализируются и передаются соответствующим декодерам. Декодирование преобразует данные в AV объект и выполняет необходимые операции для реконструкции исходного объекта AV, готового для рэндеринга на соответствующем аппарате. Аудио и визуальные объекты представлены в их кодированной форме, которая описана в разделах 10 и 9 соответственно. Реконструированный объект AV делается доступным для слоя композиции при рэндеринга сцены. Декодированные AVO, вместе с данными описания сцены, используются для композиции сцены, как это описано автором. Пользователь может расширить возможности, допущенные автором, взаимодействовать со сценой, которая отображается.

Поле заголовка Content-Description
7. Поле заголовка Content-Description
Часто оказывается желательным установить соответствие между описательной информацией и данным телом. Например, может быть полезным пометить тело типа "image" как "изображение старта космического корабля". Такой текст может быть помещен в поле заголовка Content-Description. Это поле всегда является опционным.
description := "Content-Description" ":" *text
Предполагается, что описание дается с использованием символьного набора US-ASCII, хотя механизм, специфицированный в RFC 2047, может быть использован и для значений Content-Description, не соответствующих стандарту US-ASCII.
8. Дополнительные поля заголовка MIME
Будущие документы могут содержать дополнительные поля заголовков MIME для различных целей. Любое новое поле заголовка, которое описывает содержимое сообщения должно начинаться со строки "Content-", для того чтобы такие поля можно было с гарантией отличить от обычных полей заголовков сообщения, следующих стандарту RFC-822.
MIME-extension-field :=
Используя поля заголовка MIME-Version, Content-Type и Content-Transfer-Encoding, можно подключить стандартным образом произвольные типы данных и добиться совместимости с требованиями документа RFC-822. Никакие ограничения введенные документами RFC-821 или RFC-822 не нарушаются, были приняты меры, чтобы исключить проблемы, связанные с дополнительными ограничениями из-за свойств некоторых механизмов пересылки почты по Интернет (см. RFC-2049).
Приложение A -- обзор грамматики
Это приложение содержит грамматические описания всех конструкций, содержащихся в протоколе MIME.
| attribute | := | token | Распознавание атрибутов не зависит от регистра, в котором написаны их имена. |
| composite-type | := | "message" / "multipart" / extension-token | |
| Content | := | "Content-Type" ":" type "/" subtype *(";" parameter) | Распознавание типов среды и субтипов не зависит от регистра, в котором написаны их имена. |
| description | := | "Content-Description" ":" *text | |
| discrete-type | := | "text" / "image" / "audio" / "video" / "application" / extension-token | |
| encoding | := | "Content-Transfer-Encoding" ":" mechanism | |
| entity-headers | := | [ content CRLF ] [ encoding CRLF ] [ id CRLF ] [ description CRLF ] *( MIME-extension-field CRLF ) | |
| extension-token | := | ietf-token / x-token | |
| hex-octet | := | "=" 2(DIGIT / "A" / "B" / "C" / "D" / "E" / "F") | Октет должен использоваться для символов > 127, =, пробелов или TAB в конце строк, и рекомендуется для любого символа вне списка "mail-safe" RFC 2049. |
| iana-token | := | ||
| ietf-token | := | ||
| Id | := | "Content-ID" ":" msg-id | |
| mechanism | := | "7bit" / "8bit" / "binary" / "quoted-printable" / "base64" / ietf-token / x-token | |
| MIME-extension-field | := | ||
| MIME-message-headers | := | entity-headers fields version CRLF | Порядок полей заголовка, заданный в BNF-определении не играет никакой роли. |
| MIME-part-headers | := | Заголовки объекта [поля] | Любое поле, начинающееся с "content-", не имеет строго заданного значения и может игнорироваться. |
| parameter | := | атрибут "=" значение | |
| Ptext | := | hex-octet / safe-char | |
| qp-line | := | *(qp-segment transport-padding CRLF) транспортный заполнитель qp-части | |
| qp-part | := | qp-секция | Максимальная длина 76 символов |
| qp-section | := | [*(ptext / SPACE / TAB) ptext] | |
| qp-segment | := | qp-секция *(SPACE / TAB) "=" | Максимальная длина 76 символов |
| Quoted-printable | := | qp-line *(CRLF qp-line) | |
| safe-char | := | Символы вне списка "mail-safe" в RFC 2049 не рекомендуются. | |
| subtype | := | Лексема расширения / лексема iana | |
| Token | := | 1* | |
| transport-padding | := | *LWSP-char | Программа-отправитель не должна формировать транспортное заполнение ненулевой длины, но получатели должны быть способны обрабатывать такие транспортные заполнители. |
| tspecials | := | "(" / ")" / "" / "@" / "," / ";" / ":" / "\" / "/" / "[" / "]" / "?" / "=" | При использовании в значениях параметров они должны иметь формат закавыченных строк. |
| Type | := | discretetype / compositetype | |
| Value | := | лексема / закавыченная строка | |
| version | := | "MIME-Version" ":" 1*DIGIT "." 1*DIGIT | |
| x-token | := |
/p> II. Типы среды
1. Введение
Поле Content- Type используется для спецификации природы информации в теле MIME-объекта путем присвоения идентификаторов типа и субтипа среды и предоставления дополнительной информации, которая может быть необходима для данной разновидности среды. За именами типа и субтипа среды в поле следует набор параметров, заданных в нотации атрибут/значение. Порядок следования параметров не существенен.
Тип среды верхнего уровня используется для декларации общего типа данных, в то время как субтип определяет специфический формат данного типа информации. Таким образом, тип среды "image/xyz" говорит агенту пользователя, что данные характеризуют изображение и имеют формат "xyz". Такая информация может использоваться, для того чтобы решить, отображать ли пользователю исходные данные нераспознанного субтипа. Такие действия могут быть разумными для нераспознанного фрагмента субтипа "text", но не для субтипов "image" или "audio". По этой причине, зарегистрированные субтипы "text", "image", "audio" и "video" не должны содержать встроенных фрагментов другого типа. Такие составные форматы должны использовать типы "multipart" или "application".
Параметры являются модификаторами субтипа среды, и как таковые не оказывают никакого влияния на содержимое. Набор параметров зависит от типа и субтипа среды. Большинство параметров связано с одним специфическим субтипом. Однако определенный тип среды высшего уровня может определить параметры, которые приложимы к любому субтипу данного типа. Параметры могут быть обязательными или опционными. MIME игнорирует любые параметры, имена которых нераспознаны.
Поле заголовка Content-Type и механизм типа среды спроектированы так, чтобы сохранить масштабируемость, обеспечивая постепенный рост со временем числа пар тип/субтип и сопряженных с ними параметров. Транспортное кодирование MIME, а также типы доступа "message/external-body" со временем могут обрести новые значения.
Для того чтобы гарантировать то, что такие значения разработаны и специфицированы корректно, в MIME предусмотрен процесс регистрации, который использует IANA (Internet Assigned Numbers Authority) в качестве главного органа контролирующего данный процесс (см. RFC 2048). В данном разделе описаны семь стандартизованных типов среды верхнего уровня.
2. Определение типов среды верхнего уровня
Определение типа среды верхнего уровня состоит из:
| (1) | Имя и описание типа, включая критерии, согласно которым можно решить, относится ли данная среда к указанному типу. |
| (2) | Имена и определения параметров, если таковые имеются, которые определены для всех субтипов данного типа, включая то, является ли данный параметр обязательным или опционным. |
| (3) | Как агент пользователя и/или шлюз должен обрабатывать не узнанный субтип данного типа. |
| (4) | Общие соображения о шлюзовании объектов данного типа, если таковые имеются. |
| (5) | Любые ограничения на транспортное кодирование объектов данного типа. |
3. Обзор базовых типов среды верхнего уровня
Имеется пять дискретных типов среды высокого уровня.
| (1) | text | – текстовая информация. Субтип "plain" в частности указывает, что текст не содержит команд форматирования или каких-либо директив. Такой текст нужно отображать, так как он есть. Не нужно никакого специального программного обеспечения для восприятия такого текста, помимо поддержки указанного символьного набора. Другие субтипы должны использоваться для обогащенного текста (enriched) в форме, где прикладное программное обеспечение может улучшить представление текста. Но такая программа не нужна для общей обработки содержимого. Возможные субтипы "text" включают в себя любые форматы, которые могут быть прочитаны без обращения к программе, которая понимает этот формат. В частности, форматы, которые используют встроенное двоичное форматирование, не считаются непосредственно читаемыми. Очень простой и портативный субтип, "richtext", был определен в документе RFC 1341, и позднее пересмотрен в RFC 1896 под именем "enriched". |
| (2) | image | - графические данные. "Image" требует устройства отображения (такого как графический дисплей, графический принтер, или факс) для того чтобы просмотреть информацию. Первичный субтип определен для широко используемого формата изображения JPEG. Субтипы определены для двух широко используемых форматов изображения jpeg и gif. |
| (3) | audio | - звуковые данные. "Audio" требует выходного устройства (такого как громкоговоритель или телефон) для воспроизведения содержимого. |
| (4) | video | – видео данные. "Video" требует выходного устройства, способного воспроизвести движущееся изображение. В данном документе определен первичный субтип "mpeg". |
| (5) | application | – некоторые другие типы данных, обычно не интерпретированные двоичные данные или информация, которая должна быть обработана приложением. Субтип "octet-stream" следует использовать в случае не интерпретируемых двоичных данных, в этом случае простейшей рекомендацией может служить передача этой информации в файл пользователя. Субтип "PostScript" определен для транспортировки PostScript текстов. |
/p> Существует два составных типа среды высшего уровня.
| (1) | multipart | – данные, состоящие из нескольких объектов с различными типами данных. Определены четыре первичных субтипов, включая базовый субтип "mixed", специфицирующий смешанный набор частей, "alternative" - для представления одних и тех же данных в различных форматах, "parallel" - для частей, которые должны представляться одновременно и "digest" - для составных объектов, в которых каждая часть имеет тип по умолчанию "message/rfc822". |
| (2) | message | - инкапсулированное сообщение. Тело типа среды "message" составляет часть или весь объект сообщения некоторого типа. Такие объекты могут содержать в свою очередь другие объекты. Субтип "rfc822" используется, когда инкапсулированное содержимое само является сообщением RFC 822. Субтип "partial" определен для частичных сообщений вида RFC 822, чтобы разрешить по-фрагментную передачу слишком длинных тел сообщения. Другой субтип "external-body" определен для спецификации протяженных тел с помощью ссылок на внешние источники информации. |
4. Дискретные значения типа среды
Пять из семи базовых значений типа среды относятся к дискретным телам. Содержимое этих типов должно обрабатываться с использование механизмов за пределами MIME, они непрозрачны для MIME-процессоров.
4.1. Тип среды Text
Тип среды "text" предназначен для посылки материала, который имеет принципиально текстуальную форму. Параметр "charset" можно использовать для указания символьного набора тела субтипов "text", включая субтип "text/plain", который является общим субтипом для чистого текста. Чистый текст не содержит форматирующих команд, спецификаций атрибутов шрифтов, инструкций обработки, директив интерпретации или разметки. Чистый текст представляет собой последовательность символов, которая может содержать разрывы строк или страниц.
Помимо чистого текста существует много форматов, называемых "богатый" текст ("rich text").
Интересной характеристикой многих таких представлений является то, что они читабельны даже без программы, которая его интерпретирует. Полезно затем отличать их на верхнем уровне от таких нечитабельных данных как изображения, звук или текст, представленный в нечитаемом виде. В отсутствии подходящей интерпретирующей программы разумно показать субтипы "text" пользователю, в то время как это неразумно для большей части нетекстовых данных. Такие форматированные текстовые данные должны представляться с помощью субтипов "text".
4.1.1. Представление разрывов строк
Каноническая форма любого субтипа MIME "text" должна всегда оформлять разрыв строки с помощью последовательности CRLF. Аналогично, любое появление CRLF в тексте MIME должно означать разрыв строки. Использование CR и LF по отдельности вне обозначения разрыва строки запрещено. Это правило работает вне зависимости от используемого символьного набора.
Правильная интерпретация разрывов строк при отображении текста зависит от типа среды. Следует учитывать, что одно и то же оформление разрывов строк при отображении "text/plain" может восприниматься корректно, в то время как для других субтипов "text", например, "text/enriched" [RFC-1896] аналогичные разрывы строк будут восприниматься как неверные. Нет необходимости в добавлении каких-либо разрывов строк при отображении "text/plain", в то время как отображение "text/enriched" требует введения соответствующего оформления разрывов строк.
Некоторые протоколы определяют максимальную длину строки. Например, SMTP [RFC-821] допускает максимум 998 октетов перед последовательностью CRLF. Для того чтобы реализовать транспортировку посредством такого протокола, данные, содержащие слишком длинные сегменты без CRLF, должны быть закодированы с применением соответствующего content-transfer-encoding.
4.1.2. Параметр Charset
Критическим параметром, который может быть специфицирован в поле Content-Type для данных "text/plain", является символьный набор.
Он специфицируется параметром "charset", например, как:
Content-type: text/plain; charset=iso-8859-1
В отличие от других значений параметров, значения параметра символьный набор не чувствительны к регистру, в котором написано его имя. Значением по умолчанию параметра символьный набор равно US-ASCII.
Для других субтипов "text", семантика параметра "charset" должна быть определена аналогично параметрам, заданным для "text/plain", т.e., тело состоит полностью из символов данного набора. В частности, авторы будущих определений субтипов "text" должны обратить особое внимание мультиоктетным символьным наборам. Параметр charset для субтипов "text" дает имя символьному набору, как это определено в RFC 2045.
Заметим, что специфицированный символьный набор включает в себя 8-битовые коды и эти символы используются в теле, поле заголовка Content-Transfer-Encoding и для передачи данных с помощью транспортных протоколов (например, SMTP) необходима соответствующая кодировка, такая как [RFC-821].
Значение символьного набора по умолчанию, равное US-ASCII, являлось причиной многих неурядиц в прошлом. Для того чтобы исключить какие-либо неопределенности в будущем, настоятельно рекомендуется новым агентам пользователя задавать символьный набор в явном виде в качестве параметра типа среды в поле заголовка Content-Type. "US-ASCII" не указывает на произвольный 7-битовый символьный набор, а говорит о том, что все октеты в теле должны интерпретироваться как символы US-ASCII. Национальные и ориентированные на приложения версии ISO 646 [ISO-646] обычно не идентичны US-ASCII, и их непосредственное применение в электронной почте может вызвать проблемы. Имя символьного набора "US-ASCII" относится к кодам, заданным в документе ANSI X3.4-1986 [US- ASCII].
Полный набор символов US-ASCII представлен в ANSI X3.4-1986. Заметим, что управляющие символы, включая DEL (0-31, 127) не имеют определенного значения, исключение составляет комбинация CRLF (US-ASCII значения 13 и 10) обозначающая разрыв строки.
Два символа имеют широко используемые функции, это: FF (12) – продолжить последующий текст с начала новой страницы, и TAB или HT (9) часто (хотя и не всегда) означает "переместить курсор в следующую колонку. Колонки нумеруются, начиная с нуля и их позиции кратны 8. Помимо этих случаев любые управляющие символы или DEL в теле объекта могут появиться при следующих условиях.
| (1) | по причине того, что субтип текста, отличающийся от "plain", приписывает им некоторые дополнительные значения, или |
| (2) | в рамках контекста частного соглашения между отправителем и получателем. |
| (1) | US-ASCII – как это определено в ANSI X3.4-1986 [US-ASCII]. |
| (2) | ISO-8859-X -- где "X" следует замещать как это требуется для частей ISO-8859 [ISO-8859]. Допустимыми подменами "X" являются цифры от 1 до 10. |
Значения символьных наборов "ISO-8859-6" и "ISO-8859-8" специфицируют применение визуального метода [RFC-1556].
Все эти символьные наборы используются как чисто 7-битовые или 8-битовые без модификаций связанных или .
Никакие символьные наборы, отличные от определенных выше, не могут использоваться в электронной почте без публикации и формальной регистрации в IANA. Допустимы частные соглашения, в этом случае имя символьного набора должно начинаться с "X-".
Потребителям не рекомендуется определять новые символьные наборы, если это не диктуется крайней необходимостью. Параметр "charset" был первоначально определен для текстовых данных. Однако возможно его использование и для не текстовой информации, обычно это делается для синтаксической совместимости.
Если широко используемый символьный набор А является подмножеством другого символьного набора Б, а тело содержит только символы из набора А, он должен быть помечен как А.
4.1.3. Субтип Subtype
Простейшим и наиболее важным субтипом "text" является "plain". Он указывает, что текст не содержит форматирующих команд или директив. Чистый текст может отображаться непосредственно без какой-либо обработки. По умолчанию для электронной почты предполагается тип среды "text/plain; charset=us-ascii".
4.1.4. Не распознанные субтипы
Не распознанные субтипы "text" должны обрабатываться как чистый текст ("plain"), поскольку реализация MIME знает, как работать с данным символьным набором. Не распознанные субтипы, которые также специфицируют нераспознаваемый символьный набор, должны обрабатываться как "application/octet- stream".
4.2. Тип среды Image
Тип среды "image" указывает, что тело содержит изображение. Субтип называет имя специфического формата изображения. Эти имена не чувствительны к регистру. Исходным субтипом является "jpeg", который использует кодировку JFIF для формата JPEG [JPEG]. Не распознанные субтипы "image" должны обрабатываться как "application/octet-stream".
4.3. Тип среды Audio
Исходный субтип "basic" специфицирован, для того чтобы удовлетворить требованиям, которые соответствуют самому нижнему в иерархии аудио-форматов. Предполагается, что форматы для более высококачественного воспроизведения и/или низко полосной передачи будут определены позднее.
Содержимое субтипа "audio/basic" представляет собой моноканальное звуковое кодирование, использующее 8-битоый ISDN-стандарт с m-функцией преобразования [PCM] с частотой стробирования 8000 Hz. Не распознанные субтипы "audio" должны обрабатываться как "application/octet-stream".
4.4. Тип среды Type
Тип среды "video" указывает, что тело содержит движущееся изображение, возможно цветное и в сопровождении звука. Термин 'video' используется в самом общем значении, и не подразумевает какого-то конкретного формата. Субтип "mpeg" относится к видео закодированного согласно стандарту MPEG [MPEG].
Не распознанные субтипы "video" должны обрабатываться как "application/octet-stream".
4.5. Тип среды Application
Тип среды "application" следует использовать для дискретных данных, которые не могут быть отнесены ни к какой другой категории, в частности для данных, которые должны быть обработаны какой-то прикладной программой. Это информация, которая должна обрабатываться приложением до того как она станет доступной для просмотра пользователем. К предполагаемым применениям типа среды "application" относится файловый обмен, электронные таблицы, диспетчерские системы, базирующиеся на электронной почте.
Такие приложения могут быть определены как субтипы типа среды "application". В данном документе определены два субтипа:
octet-stream и PostScript.
4.5.1. Субтип Octet-Stream (поток октетов)
Субтип "octet-stream" используется для индикации того, что тело содержит произвольные двоичные данные. В настоящее время определены следующие параметры:
| (1) | TYPE – общий тип или категория двоичных данных. Это параметр предназначен для оператора-получателя, а не для программы обработки. |
| (2) | PADDING – число бит заполнителя, добавленного к потоку бит, представляющему действительное содержимое, для того чтобы получить байт-ориентированный поток. Используется, когда число бит в теле не кратно 8 |
4.5.2. Субтип PostScript
Тип среды "application/postscript" указывает на программу PostScript. В настоящее время допускается два варианта языка PostScript. Исходный вариант уровня 1 описан в [POSTSCRIPT], а более новый вариант уровня 2 рассмотрен в [POSTSCRIPT2].
Описания языка PostScript предоставляет возможности внутренней пометки специфических возможностей данного приложения. Эта пометка, называемая DSC (document structuring conventions) PostScript, предоставляет существенно больше информации, чем уровень языка. Использование DSC рекомендуется даже тогда, когда это непосредственно не требуется, так как обеспечивает более широкую совместимость.
Документы, которые недостаточно структурированы, не могут быть проверены с целью выяснения того, могут ли они работать в данной среде.
Работа универсальных интерпретаторов PostScript представляет серьезную угрозу безопасности, разработчикам не рекомендуется просто посылать тела PostScript имеющимся ("off-the-shelf") интерпретаторам. В то время как посылка PostScript-файла на принтер обычно безопасна, программисты должны рассмотреть все возможные последствия, прежде чем ввести интерактивное отображение тел типа PostScript на их читающих средствах MIME.
Ниже перечислены возможные проблемы, связанные с транспортировкой объектов PostScript.
| (1) |
В список опасных операций языка PostScript входят "deletefile", "renamefile", "filenameforall" и "file". "File" является единственной опасной процедурой, которая применяется для входных/выходных потоков не стандартных данных. Конкретные реализации могут определить не стандартные файловые операторы, которые могут также представлять угрозу безопасности. "Filenameforall", - оператор поиска файлов, может показаться на первый взгляд безобидным. Заметим, что этот оператор может раскрыть информацию о том, к каким файлам имеет доступ пользователь, а эти данные могут облегчить задачу хакеру. Отправители сообщений должны избегать использования потенциально опасных файловых операторов, так как такие операторы, скорее всего, недоступны в PostScript приложениях, где приняты меры по обеспечению безопасности. Программное обеспечение, которое используется для приема и отображения, должно блокировать потенциально опасные файловые операторы или принять меры по ограничению их возможностей. |
| (2) | Язык PostScript предоставляет возможность для выхода из цикла интерпретатора или сервера. Операторы, сопряженные с выходом интерпретатора из цикла могут интерферировать с процедурами последующей обработки документов. Операторы PostScript, которые выводят интерпретатор из цикла, включают в себя серверы выхода и начала задания. Программе отправки сообщения не следует генерировать PostScript, который зависит от функционирования выхода интерпретатора из цикла, так как такая процедура может отсутствовать в реализациях с повышенной безопасностью. Программа приема сообщений должна полностью блокировать работу операторов "startjob" и "exitserver", также какие-либо изменения в среде PostScript на постоянной основе. Если эти операции не могут быть полностью исключены, для их выполнения должен быть организован контролируемый доступ с необходимостью ввода пароля. |
| (3) | PostScript предоставляет операторы для установки системных параметров и специфических параметров внешних устройств. Эти установки параметров могут влиять неблагоприятным образом на работу интерпретатора. Процедуры PostScript, которые устанавливают системные параметры, могут включать в себя операторы "setsystemparams" и "setdevparams". Программа отправки не должна генерировать PostScript-сообщений, которые зависят от установки системных параметров. Программа приема и отображения сообщений должна блокировать изменение системных параметров. Если блокировка по каким-либо причинам невозможна, процедура установки параметров должна требовать специфического пароля. |
| (4) | Некоторые реализации PostScript предоставляют нестандартные возможности для прямой загрузки и исполнения машинных кодов. Такие возможности чреваты злоупотреблениями. Программа отправки сообщений не должна использовать такие возможности. Программа приема и отображения сообщений не должна позволять применение таких операторов, если они имеются. |
| (5) | PostScript является расширяемым языком, и многое, если не большинство, его реализаций предоставляют большое число расширений. Программа отправки сообщений не должна использовать нестандартные расширения. Программа приема и отображения сообщений должна быть уверена, что эти нестандартные расширения не представляют угрозы. |
| (6) | Имеется возможность написания такой PostScript-программы, которая потребует огромных системных ресурсов. Можно также написать PostScript-фрагмент, который реализует бесконечный цикл. Оба варианта представляют угрозу для ничего не подозревающего получателя. Программа отправки сообщений должна избегать создания и распространения таких кодов. Программа приема и отображения сообщений должна предоставлять подходящий механизм для блокировки исполнения и удаления таких программ по истечении некоторого заданного времени. |
| (7) | Существует возможность включения двоичной информации в PostScript-текст. Это не рекомендуется в электронной почте, так как это не поддерживается всеми PostScript-интерпретаторами, потому что сильно усложняет использование транспортного кодирования MIME. |
| (8) | Наконец, в некоторых интерпретаторах PostScript вполне возможны ошибки, которые могут использоваться для получения не авторизованного доступа к системе получателя. |
/p>
4.5.3. Другие субтипы приложений
Ожидается, что в будущем будут определены многие другие субтипы "application". Реализации MIME должны уметь обрабатывать нераспознанные субтипы как "application/octet-stream".
5. Значения типа среды Composite (составной)
Оставшиеся два из семи исходных значений Content-Type относятся к составным объектам. Составные объекты обрабатываются с использованием механизмов MIME -- процессор MIME обрабатывает тело объекта непосредственно.
5.1. Тип среды Multipart
В случае составных объектов, когда один или более различных наборов данных объединяется в одном теле, в заголовке объекта должно присутствовать поле типа среды "multipart". Тело должно тогда содержать одну или более частей, каждая из которых начинается с разделительной строки. За разделительной строкой следует заголовок, пустая строка и тело объекта. Таким образом, часть тела по своему синтаксису аналогична сообщению в RFC-822, но имеет другое назначение.
Часть тела является объектом и, следовательно, не должна интерпретироваться как сообщение RFC-822. Начнем с того, что части тела должны иметь заголовки. Допустимы части тела, которые начинаются с пустой строки. В таком случае отсутствие заголовка Content-Type обычно указывает, что соответствующее тело имеет тип содержимого "text/plain; charset=US-ASCII".
Единственные поля заголовка, которые определяют назначение частей тела, имеют имена, начинающиеся с "Content-". Все другие поля в заголовке части тела могут игнорироваться. Для экспериментальных или частных назначений могут создаваться поля, с именами, начинающимися с "X-". Информация, содержащаяся в этих полях может теряться в некоторых шлюзах.
Различие между сообщением RFC-822 и частью тела не велико, но существенно. Шлюз между Интернет и почтовым сервером X.400, например, должен быть способен различать части тела, содержащие изображение и инкапсулированное сообщение, тело которого представляет собой JPEG-образ.
Для того чтобы представить последнее, часть тела должна иметь "Content-Type: message/rfc822", и ее тело после пустой строки должно представлять собой инкапсулированное сообщение со своим собственным полем заголовка "Content-Type: image/jpeg". Применение подобного синтаксиса способствует преобразованию сообщений в части тела и обратно.
Как было заявлено ранее, каждая часть тела начинается со строки-разграничителя. Разграничитель не должен появляться внутри любой инкапсулированной части, или в качестве префикса любой строки. Это подразумевает, что генерирующий агент способен специфицировать уникальное значение пограничного параметра, которое не содержит в качестве префикса значения разграничительного параметра вкладываемой части.
Все существующие и будущие субтипы типа "multipart" должны использовать идентичный синтаксис. Субтипы могут отличаться по своей семантике и могут вводить дополнительные ограничения на синтаксис, но должны согласовываться с базовым синтаксисом типа "multipart". Это требование гарантирует, что все агенты пользователя будут, по крайней мере, способны распознать и разделить части составного объекта, даже если они относятся к нераспознанным субтипам.
Как задано в определении поля Content-Transfer-Encoding [RFC-2045], никакие кодировки кроме "7bit", "8bit" или "binary" не разрешены для объектов типа "multipart". Граничные разделители и поля заголовков "multipart" всегда представляются как 7-битовые коды US-ASCII, а данные внутри частей тела могут быть закодированы по-разному и иметь свои поля Content-Transfer-Encoding для каждой из частей.
5.1.1. Общий синтаксис
Поле Content-Type для составных объектов требует одного параметра - "boundary". Строка-разделитель определяется как строка, содержащая два символа дефис ("-", десятичный код 45), за которыми следует значение пограничного параметра из поля заголовка Content-Type, опционный строчный пробел и заключительные CRLF.
Символы дефис служат для некоторой совместимости с ранним методом (RFC-934) инкапсуляции сообщений, и для облегчения поиска границ для некоторых приложений. Однако следует заметить, что составные сообщения не вполне совместимы с инкапсуляцией, описанной в RFC-934. В частности, они не подчиняются RFC-934 регламентации использования кавычек для вложенных строк, которые начинаются с дефиса. Этот механизм был выбран помимо RFC-934, потому что при данной схеме происходит удлинение строк для каждого уровня закавычивания. Возрастание длины строк, а также то, что некоторые реализации SMTP осуществляют разрыв строк, делают механизм RFC-934 неприменимым для составных сообщений при большой глубине вложений.
Грамматика для параметров поля Content-type такова, что в строке Content-type часто необходимо помещать пограничный параметр в кавычки. Это необходимо не всегда, но никогда не повредит. Программисты должны тщательно изучить грамматику, для того чтобы избежать генерации некорректных полей Content-type. Таким образом, типичное поле заголовка "multipart" Content-Type может выглядеть как:
Content-Type: multipart/mixed; boundary=gc0p4Jq0M2Yt08j34c0p
Content-Type: multipart/mixed; boundary="gc0pJq0M:08jU534c0p"
Это значение Content-Type указывает, что содержимое состоит из одной или более частей со структурой, которая синтаксически идентична сообщению RFC-822, за исключением того, что область заголовка может быть совершенно пустой, а каждая из частей начинается со строки
--gc0pJq0M:08jU534c0p
Пограничный разделитель должен размещаться в начале строки, т.e., следовать за CRLF, а начальный CRLF рассматривается объединенным со строкой пограничного разделителя, а не частью предшествующей секции. За границей может следовать нуль или более символов строчного пробела (HT, SP). Далее следует еще один CRLF и поля заголовка следующей части, или два CRLF, что означает отсутствие полей заголовка следующей части. Если поле Content-Type отсутствует, предполагается объект типа "message/rfc822" в сообщении "multipart/digest", в противном случае "text/plain".
Граничные разделители не должны появляться внутри инкапсулированного материала и не должны быть длиннее 70 символов, не считая двух начальных символов дефис.
Строка пограничного разделителя, следующая за последней частью тела, является уникальной и указывает, что далее не следует более никаких частей тела. Такая разделительная строка идентична предшествующим с добавлением двух символов дефис после значения граничного параметра.
--gc0pJq0M:08jU534c0p--
Сравнение пограничной строки должно сопоставлять значение пограничного параметра с началом каждой строки-кандидата. Полного совпадения всей строки-кандидата не требуется, достаточно наличия разграничителя, следующего за CRLF.
Имеется место для дополнительной информации перед пограничным разделителем и после оконечного разграничителя. Эти области следует в норме оставлять пустыми, а программные реализации должны игнорировать размещенную там информацию. Некоторые реализации используют эти "ниши" для пересылки сообщений принимающим программам.
Пограничный параметр в выше приведенном примере может быть результатом работы алгоритма, специально созданного для генерации кодов, которые с крайне малой вероятностью могут встретиться в инкапсулируемых данных. Другой алгоритм может выдать более "читаемый" код пограничного разделителя, что может потребовать предварительного просмотра инкапсулируемых данных. Простейшей строкой пограничного разделителя может служить "---", а закрывающим разделителем - "-----".
Ниже представлен простой пример составного сообщения, имеющего две части, каждая из которых содержит чистый текст, введенный явно и неявно:
From: Nathaniel Borenstein
To: Ned Freed
Date: Sun, 21 Mar 1993 23:56:48 -0800 (PST)
Subject: Sample message
MIME-Version: 1.0
Content-type: multipart/mixed; boundary="simple boundary"
Это преамбула. Она будет проигнорирована, но, тем не менее, это удобное место, чтобы отправитель мог поместить сообщение для принимающей стороны, которая не поддерживает MIME.
| простая граница | Это неявно введенный чистый US-ASCII-текст. Он не завершается на данной строке |
| простая граница | Content-type: text/plain; charset=us-ascii. Это явно введенный чистый US-ASCII-текст. Он завершается на данной строке |
| простая граница | Это эпилог. Он также игнорируется |
Практика показала, что тип "multipart" с единственной составной частью полезен для посылки сообщений с нетекстовым типом среды. Он имеет возможность формирования преамбулы, как места, где можно поместить инструкции по декодированию. Кроме того, многие шлюзы SMTP перемещают или удаляют заголовки MIME, и хороший MIME-декодер таким путем может получить необходимую информацию даже в отсутствие заголовка Content-Type и корректно декодировать сообщение.
Единственным обязательным глобальным параметром для типа среды "multipart" является граничный параметр, который состоит из 1 - 70 кодов из символьного набора, который надежен по отношению преобразований, осуществляемых почтовыми шлюзами. Значение параметра не должно завершаться пробелом. Формально это записывается в BNF-представлении следующим образом.
boundary := 0*69 bcharsnospace
bchars := bcharsnospace / " "
bcharsnospace := DIGIT / ALPHA / "'" / "(" / ")" / "+" / "_" / "," / "-" / "." / "/" / ":" / "=" / "?"
Вообще тело объекта "multipart" может быть специфицировано как:
dash-boundary := "--" boundary
; boundary берется из значения граничного параметра поля Content-Type.
multipart-body := [preamble CRLF]
| dash-boundary transport-padding CRLF | |
| body-part *encapsulation | |
| close-delimiter transport-padding | |
| [CRLF epilogue] |
| transport-padding := *LWSP-char | Отправители не должны генерировать транспортные ; заполнители ненулевой длины, но получатели ; должны уметь обрабатывать заполнители, введенные ; при транспортировке. |
delimiter := CRLF dash-boundary
close-delimiter := delimiter "--"
epilogue := discard-text
; не должен появляться где-либо в теле секции. Заметим, что семантика части тела
; отличается от семантики сообщения, как это описано в тексте.
OCTET :=
Введение пробелов (HT, SP) и комментариев RFC 822 между элементами, показанными выше, не допустимо, так как эти BNF не специфицируют структурированное поле заголовка.
В определенных транспортных зонах регламентации RFC 822, такие как ограничение применения каких-либо символов, помимо печатных кодов US-ASCII могут не действовать. Ослабление этих ограничений может рассматриваться как локальное расширение определения тел, например, чтобы включить октеты вне набора US-ASCII, постольку, поскольку эти расширения поддерживаются системой передачи и соответствующим образом документированы в поле заголовка Content-Transfer-Encoding. Однако заголовки ни в коем случае не могут содержать чего-либо помимо кодов US-ASCII.
5.1.2. Обработка вложенных и составных сообщений
Субтип "message/rfc822" не имеет других условий завершения кроме окончания массива данных. Аналогично, некорректно укороченный составной объект не будет иметь завершающего разделителя, что может вызвать нарушение работы почтовой системы.
Существенно, чтобы такие объекты обрабатывались корректно, когда они сами вложены в другие составные структуры. Реализации MIME должны уметь распознавать граничные маркеры на любом уровне вложения.
5.1.3. Субтип Mixed
Субтип "mixed" типа "multipart" предназначен для использования в условиях, когда части тела независимы и должны объединяться в определенном порядке.
Любые субтипы "multipart", которые не распознаны программой, должны восприниматься как субтип "mixed".
5.1.4. Субтип Alternative
Тип "multipart/alternative" синтаксически идентичен "multipart/mixed", но имеет иную семантику. В частности, каждая часть тела является альтернативой одной и той же информации.
Системы должны распознавать, что содержимое различных частей взаимозаменяемы. Системы должны выбрать наилучший тип на основе локального окружения и в некоторых случаях с использованием диалога с пользователем. Как и для "multipart/mixed", порядок частей тела является существенным. В этом случае, альтернативы появляются в порядке возрастания правдоподобия оригинальному содержимому. Вообще наилучшим выбором является последняя часть типа, поддерживаемая локальной средой приемной системы..
"Multipart/alternative" может использоваться, например, для посылки сообщения в любом формате таким образом, чтобы его было легко отобразить:
From: Nathaniel Borenstein
To: Ned Freed
Date: Mon, 22 Mar 1993 09:41:09 -0800 (PST)
Subject: Formatted text mail
MIME-Version: 1.0
Content-Type: multipart/alternative; boundary=boundary42
--boundary42
Content-Type: text/plain; charset=us-ascii
... здесь следует версия сообщения в виде чистого текста ...
--boundary42
Content-Type: text/enriched
... здесь следует версия сообщения RFC 1896 в виде обогащенного текста (text/enriched) ...
--boundary42
Content-Type: application/x-whatever
... здесь следует наиболее причудливая версия сообщения ...
--boundary42--
В этом примере пользователи, чья почтовая система может работать с форматом "application/x-whatever", увидят только причудливую версию сообщения, в то время как другие пользователи увидят версию с обогащенным или чистым текстом, в зависимости от возможностей их системы.
Вообще, агенты пользователя, которые формируют объекты "multipart/alternative" должны размещать части тела в порядке их предпочтения, то есть, предпочтительный формат следует последним.
Посылающий агент пользователя должен поместить простейший формат текста первым, а обогащенный - последним. Принимающие агенты должны воспринять самый последний формат, который они способны отобразить. В случае, когда одной из альтернатив является тип "multipart", который содержит нераспознанные составные части, агент пользователя может отобразить эту альтернативу, более раннюю или даже обе версии сообщения.
Возможен вариант, когда агент пользователя способен распознать и отобразить разные форматы, он может предложить окончательный выбор самому пользователю. Это имеет смысл, например, если сообщение включает графическую и текстовую версии сообщения. Агент пользователя не должен автоматически отображать все версии, какие он воспринял, он должен отобразить последнюю, или предоставить выбор оператору.
Каждая часть объекта "multipart/alternative" представляет одну и ту же информацию, версии не необязательно тождественны. Например, информация теряется, когда осуществляется трансляция ODA в PostScript или в чистый текст. Рекомендуется, чтобы каждая часть имела свое значение Content-ID в тех случаях, когда содержимое частей неэквивалентно. Например, там, где несколько частей типа "message/external-body" специфицируют способы доступа к идентичной информации, следует использовать одни и те же значения поля Content-ID. Возможен вариант, когда одно значение Content-ID может относиться к объекту "multipart/alternative", в то время как одно или более других значений Content-ID будут относиться к частям внутри объекта.
5.1.5. Субтип Digest
Этот документ определяет субтип "digest" типа содержимого "multipart". Этот тип синтаксически идентичен "multipart/mixed", но их семантика различна. В частности, в дайджесте, значение по умолчанию Content-Type для части тела меняется с "text/plain" на "message/rfc822". Это сделано, для того чтобы допустить более читаемый формат дайджеста, совместимый с RFC-934.
Хотя можно специфицировать значение Content-Type для части тела в дайджесте, который отличается от "message/rfc822", такая часть как "text/plain", содержащая описание материала в дайджесте, делает это нежелательным. Тип содержимого "multipart/digest" предназначен для использования при посылке группы сообщений. Если необходима часть "text/plain", она должна быть включена как отдельная компонента сообщения "multipart/mixed". Дайджест в этом формате может выглядеть как.
From: Moderator-Address
To: Recipient-List
Date: Mon, 22 Mar 1994 13:34:51 +0000
Subject: Internet Digest, volume 42
MIME-Version: 1.0
Content-Type: multipart/mixed;
boundary="---- главный разделитель ----"
------ главный разделитель ----
...Вводный текст или содержимое таблицы...
------ главный разделитель ----
Content-Type: multipart/digest;
boundary="---- следующее сообщение ----"
------ следующее сообщение ----
From: someone-else
Date: Fri, 26 Mar 1993 11:13:32 +0200
Subject: my opinion
... здесь размещается тело...
------ следующее сообщение ----
From: someone-else-again
Date: Fri, 26 Mar 1993 10:07:13 -0500
Subject: my different opinion
... здесь размещается следующее тело ...
------ следующее сообщение ------
------ главный разделитель ------
5.1.6. Субтип Parallel
Этот документ определяет субтип "parallel" типа содержимого "multipart". Этот тип синтаксически идентичен "multipart/mixed", но их семантика различна. В частности, в параллельном объекте, порядок частей тела не играет роли.
Представление этого типа заключается в одновременном отображении всех частей с использованием имеющихся оборудования и программ. Однако программа отправитель должна учесть то, что многие приемники почты не способны выполнять операции параллельно и отобразят все части сообщения последовательно.
5.1.7. Прочие субтипы Multipart
В будущем ожидается появление новых субтипов "multipart".
Реализации MIME должны уметь работать с нераспознанными субтипами "multipart" как с "multipart/mixed".
5.2. Тип среды Message
Часто желательно при посылке почты вложить туда какое-то другое сообщение. Для решения этой задачи определен специальный тип среды "message”. В частности, для вложения в сообщения RFC-822 служит субтип "rfc822"
Субтип "message" часто накладывает ограничения на допустимые типы кодирования. Эти ограничения описаны для каждого специфического субтипа. Почтовые шлюзы, системы транспортировки и другие почтовые агенты иногда изменяют заголовки верхнего уровня в сообщениях RFC 822. В частности, они часто добавляют, удаляют и меняют порядок полей заголовков. Эти операции запрещены для заголовков, вложенных в тело сообщения типа "message."
5.2.1. Субтип RFC822
Тип среды "message/rfc822" указывает, что тело содержит инкапсулированное сообщение. Однако в отличие от сообщений верхнего уровня RFC-822, ограничение, связанное с обязательным присутствием в теле "message/rfc822" заголовков "From", "Date", и, по крайней мере, одного адреса места назначения, здесь удалено. Необходимо лишь присутствие одного из заголовков "From", "Subject" или "Date". Следует заметить, что, несмотря на использование чисел "822", объект "message/rfc822" не должен абсолютно следовать регламентациям RFC-822. Более того, сообщение "message/rfc822" может быть статьей новостей или сообщением MIME.
В теле объекта "message/rfc822" не разрешены никакие кодировки помимо "7bit", "8bit" или "binary". Поля заголовка сообщения содержат только US-ASCII в любом регистре, а информация в теле может быть закодирована. Не-US-ASCII-текст в заголовках инкапсулированного сообщения может быть специфицирован с использованием механизма, описанного в документе RFC-2047.
5.2.2. Субтип Partial
Субтип "partial" определен, для того чтобы разрешить разделять на части слишком большие объекты, которые затем доставляются в виде отдельных почтовых сообщений и автоматически восстанавливаются как единое целое принимающим агентом пользователя.
Этот механизм может использоваться, когда промежуточный транспортный агент ограничивает максимальный размер почтового сообщения. Тип среды "message/partial", таким образом, указывает, что тело содержит фрагмент некоторого большого объекта.
Так как данные типа "message" могут не быть закодированны в виде base64 или закавыченной строки печатных символов, может возникнуть проблема, если объекты "message/partial" созданы в среде, которая поддерживает двоичный или 8-битовый обмен. Проблема возникает из-за того, что двоичные данные надо будет разбить на несколько сообщений "message/partial", каждое из которых требует двоичного транспорта. Если такие сообщения встретят по пути шлюз с 7-битовой передачей, не будет никакой возможности перекодировать эти фрагменты для 7-битовой среды. Можно конечно дождаться прихода всех составных частей, собрать исходный объект, закодировать его с помощью, например, base64, после чего начать все с начала. Но даже такой сложный сценарий может оказаться неосуществимым из-за того, что фрагменты могут транспортироваться разными путями. По этой причине, было специфицировано, что объекты типа "message/partial" должны всегда иметь транспортное кодирование “7bit” (по умолчанию). В частности, даже для сред, которые поддерживают двоичный или 8-битовый обмен, использование транспортного кодирования "8bit" или "binary" для MIME-объектов типа "message/partial" запрещено. Это в свою очередь предполагает, что внутреннее сообщение не должно использовать кодирование "8bit" или "binary". Так как некоторые агенты пересылки сообщений могут выбрать автоматическую фрагментацию длинных сообщений, а также из-за того, что эти агенты могут использовать разные пороги фрагментации, может так получиться, что фрагменты после сборки в свою очередь окажутся частями сообщения. Это вполне допустимо.
В поле Content-Type типа "message/partial" необходимо специфицировать три параметра. "id" - уникальный идентификатор, который должен использоваться для привязки фрагментов друг к другу. "number" - целое число, которое является номером фрагмента. "total" - целое число, характеризующее полное число фрагментов.
Число фрагментов является опционным и обязательно присутствует только в последнем фрагменте. Заметим также, что эти параметры могут быть заданы в любом порядке. Таким образом, второй сегмент 3-фрагментного сообщения может иметь поля заголовка одного из следующих видов.
ontent-Type: Message/Partial; number=2; total=3;
| id="oc=jpbe0M2Yt4s@thumper.bellcore.com" |
| id="oc=jpbe0M2Yt4s@thumper.bellcore.com"; | |
| number=2 |
Content-Type: Message/Partial; number=3; total=3;
| id="oc=jpbe0M2Yt4s@thumper.bellcore.com" |
Когда фрагменты объекта, разорванные таким способом, складываются вместе, результатом всегда будет исходный MIME-объект, который может иметь свое собственное поле заголовка Content-Type, и, следовательно, иметь любой другой тип данных.
5.2.2.1. Фрагментация и сборка сообщений
Семантика восстановленных фрагментов сообщений должна соответствовать "внутреннему" сообщению, а не сообщению, в которое оно вложено. Это делает возможным, например, посылку большого аудио-сообщения в виде нескольких сообщений-фрагментов таким образом, что получатель воспримет его как простое аудио-сообщение, а не инкапсулированное сообщение, содержащее аудио-сообщение. Такая инкапсуляция рассматривается как прозрачная. Когда формируются фрагменты и осуществляется сборка составных частей сообщения "message/partial", заголовки инкапсулированного сообщения должны объединяться с заголовками вложенных объектов. При реализации этой процедуры должны выполняться следующие правила:
| (1) | Фрагментирующие агенты должны разделять сообщения только по границам строк. Это ограничение вводится из-за того, что при несоблюдении данного правила возникнет транспортная проблема сохранения семантики сообщения, не заканчивающегося последовательностью CRLF. Многие виды транспорта не способны решить такую задачу. |
| (2) | Все поля заголовка исходного вложенного сообщения, за исключением тех, чьи имена начинаются с "Content-", и специфических полей заголовка "Subject", "Message-ID", "Encrypted" и "MIME-Version", должны копироваться в новое сообщение. |
| (3) | Поля заголовка вложенного сообщения, начинающиеся с "Content-", плюс поля "Subject", "Message-ID", "Encrypted" и "MIME-Version" fields, должны быть добавлены в порядке к полям нового сообщения. Любые поля заголовка, которые не начинаются с "Content-" (за исключением полей "Subject", "Message-ID", "Encrypted" и "MIME-Version") будут проигнорированы и отброшены. |
| (4) | Все поля заголовка второго и любых последующих вложенных сообщений отбрасываются принимающей программой в процессе сборки. |
/p>
5.2.2.2. Пример фрагментации и сборки
Если аудио- сообщение разделено на два фрагмента, первая часть может выглядеть как:
X-Weird-Header-1: Foo
From: Bill@host.com
Subject: Audio mail (part 1 of 2)
Message-ID:
MIME-Version: 1.0
Content-type: message/partial; id="ABC@host.com";
number=1; total=2
X-Weird-Header-1: Bar
X-Weird-Header-2: Hello
Message-ID:
Subject: Audio mail
Content-transfer-encoding: base64
... здесь помещается первая половина закодированных аудио-данных ...
а вторая часть может выглядеть следующим образом:
From: Bill@host.com
>To: joe@otherhost.com
Date: Fri, 26 Mar 1993 12:59:38 -0500 (EST)
Subject: Audio mail (part 2 of 2)
MIME-Version: 1.0
Message-ID:
Content-type: message/partial;
id="ABC@host.com"; number=2; total=2
... здесь помещается вторая половина закодированных аудио-данных ...
Затем, когда фрагментируемое сообщение оказывается собрано, результат, отображаемый для пользователя, должен выглядеть как:
X-Weird-Header-1: Foo
From: Bill@host.com
To: joe@otherhost.com
Date: Fri, 26 Mar 1993 12:59:38 -0500 (EST)
Subject: Audio mail
Message-ID:
MIME-Version: 1.0
Content-type: audio/basic
Content-transfer-encoding: base64
... здесь помещается первая половина закодированных аудио-данных ...
... здесь помещается вторая половина закодированных аудио-данных ...
Включение в заголовки второго и последующих секций фрагментированного сообщения поля "References" (ссылка), которое указывает на Message-Id (идентификатор сообщения) предшествующей секции, может быть полезно для системы чтения почты, которая умеет отслеживать ссылки. Однако генерация полей "References" является опционной.
Наконец, следует заметить, что поле "Encrypted" заголовка является устаревшим из-за внедрения конфиденциальной почты PEM (Privacy Enhanced Messaging; RFC-1421, RFC-1422, RFC-1423, RFC-1424), но правила описанные выше, несмотря ни на что, описывают правильный путь его обработки, если оно встретится в контексте прямого и обратного преобразования фрагментов "message/partial".
5.2.3. Субтип External-Body
Субтип external-body указывает, что в сообщении содержатся не данные, а ссылка на место, где эти данные находятся. В этом случае параметры описывают механизм доступа к внешним данным.
Когда объект MIME имеет тип "message/external-body", он состоит из заголовка, двух последовательностей CRLF, и заголовка для инкапсулированного сообщения. Если появится еще одна пара последовательностей CRLF, это завершит заголовок инкапсулированного сообщения. Однако так как тело инкапсулированного сообщения само является внешним, оно не появится вслед за заголовком. Например, рассмотрим следующее сообщение:
Content-type: message/external-body;
| access-type=local-file; | |
| name="/u/nsb/Me.jpeg" |
Content-ID:
Content-Transfer-Encoding: binary
Это в действительности не тело!
Область в конце, которую можно назвать телом-фантомом, игнорируется для большинства сообщений с внешним телом. Однако оно может использоваться для хранения вспомогательной информации для некоторых таких сообщений, как это действительно бывает, когда тип доступа - "mail-server". Единственный тип доступа, описанный в этом документе и использующий тело-фантом, это "mail-server", но могут быть описаны другие типы в будущем.
Инкапсулированные заголовки во всех объектах "message/external-body" должны включать в себя поле заголовка Content-ID, для того чтобы предоставить уникальный идентификатор, который служит для ссылки на данные. Этот идентификатор может быть использован в процессе кэширования и для распознавания входных данных, когда типом доступа является "mail-server".
Заметим, что, как это специфицировано здесь, лексемы, которые описывают данные внешнего тела, такие как имена файлов и команды почтового сервера, должны быть записаны с использованием символьного набора US-ASCII.
Как с "message/partial", объекты MIME типа "message/external-body" MUST имеют транспортное кодирование 7-бит (по умолчанию).
В частности, даже в среде, которая поддерживает 8- битовую транспортировку, использование транспортного кодирования "8bit" или "binary" категорически запрещено для объектов типа "message/external-body".
5.2.3.1. Общие параметры External-Body
С "message/external- body" могут использоваться следующие параметры:
| (1) | ACCESS-TYPE (тип доступа). Слово, характеризующее поддерживаемый механизм доступа, с помощью которого можно получить файл или данные. Это слово не чувствительно к регистру, в котором напечатано. Параметр может принимать следующие значения "FTP", "ANON-FTP", "TFTP", "LOCAL-FILE" и "MAIL-SERVER". Будущие значения, за исключением экспериментальных, начинающихся с "X-", должны регистрироваться IANA, как это описано в RFC-2048. Данный параметр является обязательным и должен присутствовать в каждом "message/external-body". |
| (2) | EXPIRATION (конец срока действия). Дата (имеет синтаксис "date-time" как в RFC-822, документ RFC-1123 разрешил 4 цифры для обозначения года), после которой существование внешних данных не гарантируется. Этот параметр может использоваться с любым типом доступа и является опционным. |
| (3) | SIZE (размер). Число октетов данных. Этот параметр предназначен, для того чтобы помочь получателю решить, достаточно ли ресурсов памяти для приема этих внешних данных. Заметим, что параметр описывает размер данных в канонической форме, то есть, до использования какого-либо транспортного кодирования или после декодирования. Этот параметр может использоваться с любым типом доступа и является опционным. |
| (4) | PERMISSION (разрешение). Не чувствительное к регистру поле, которое указывает, предполагается ли возможность для клиента переписать данные. По умолчанию или, если разрешение соответствует "read", считается, что это запрещено и что, если данные однажды извлечены, они не потребуются никогда. Если PERMISSION соответствует "read-write", такое предположение не верно. "Read" и "Read-write" являются единственными определенными значениями параметра разрешения. Этот параметр используется с любым типом доступа и является опционным. |
/p>
5.2.3.2. Типы доступа 'ftp' и 'tftp'
Тип доступа FTP или TFTP указывают, что тело сообщения доступно в виде файла с помощью протоколов FTP [RFC-959] или TFTP [RFC- 783], соответственно. Для этих типов доступа необходимы следующие параметры:
| (1) | NAME (имя). Имя файла, который содержит тело данных. |
| (2) | SITE (узел). ЭВМ, с которой может быть получен файл с помощью данного протокола. Это должно быть официально зарегистрированное имя, а не псевдоним. |
| (3) | Прежде чем какие-либо данные будут извлечены с помощью FTP, пользователь должен выполнить процедуру аутентификации (ввести имя и пароль) на машине, указанной в параметре SITE. По соображениям безопасности имя и пароль не специфицируются параметрами типа доступа, они должны быть получены непосредственно от пользователя. |
| (1) | DIRECTORY (каталог). Каталог, из которого должен быть взят файл с именем, заданным параметром NAME. |
| (2) | MODE (режим). Строка символов, не зависящая от регистра ввода и указывающая на режим, который должен использоваться при извлечении информации. Допустимыми значениями параметра для типа доступа "TFTP" являются "NETASCII", "OCTET" и "MAIL", как это определено для протокола TFTP [RFC- 783]. Допустимыми значениями параметра для типа доступа "FTP" являются "ASCII", "EBCDIC", "IMAGE" и "LOCALn", где "n" - целое число, обычно 8. Они соответствуют типам представления "A" "E" "I" и "L n", как это задано протоколом FTP [RFC-959]. Заметим, что "BINARY" и "TENEX" не являются корректными значениями для MODE и что вместо этого следует использовать "OCTET", "IMAGE" или "LOCAL8". Если параметр MODE не задан, значением по умолчанию является "NETASCII" для TFTP и "ASCII" во всех прочих случаях. |
5.2.3.3. Тип доступа 'anon-ftp'
Тип доступа "anon-ftp" идентичен варианту "ftp", за исключением того, что пользователю не нужно предоставлять имя и пароль.
Вместо этого протокол ftp воспользуется именем "anonymous" и паролем, равным почтовому адресу пользователя.
5.2.3.4. Тип доступа 'local-file'
Тип доступа "local-file" указывает, что тело данных доступно в виде файла на локальной ЭВМ. Для этого типа доступа определены два дополнительные параметра:
| (1) | NAME (имя). Имя файла, который содержит тело данных. Этот параметр является обязательным для типа доступа "local-file". |
| (2) | SITE (узел). Спецификатор домена для данной ЭВМ или набора машин, которые имеют доступ к данному информационному файлу. Этот опционный параметр используется для описания локального указателя на данные, т.е., узел или группа узлов, откуда данный файл доступен. В качестве символов подмены в имени домена могут использоваться звездочки, как, например, в "*.bellcore.com", чтобы указать на группу ЭВМ, откуда данные доступны непосредственно. |
Тип доступа "mail-server" указывает, что тело данных доступно на почтовом сервере. Для этого типа доступа определены два дополнительные параметра:
| (1) | SERVER (сервер). Спецификация адреса почтового сервера, с которого может быть получены данные. Этот параметр является обязательным для типа доступа "mail-server". |
| (2) | SUBJECT (тема сообщения). Тема сообщения (subject), которая используется в почтовом сообщении с целью получения данных. Этот параметр является опционным. |
Заметим, что MIME не определяет синтаксис почтового сервера. Скорее, оно позволяет включение произвольных команд почтового сервера в тело-фантом. Программные реализации должны включать тело-фантом в тело сообщения, которое посылается по адресу почтового сервера для получения нужных данных.
В отличие от других типов доступа, доступ к почтовому серверу является асинхронным и происходит в произвольный момент времени. По этой причине важно, чтобы существовал механизм, с помощью которого полученные данные могли быть сопоставлены с исходным объектом "message/external-body". Почтовые серверы MIME должны использовать то же поле Content-ID в сообщении-отклике, которое было использовано в исходных объектах "message/external-body", для того чтобы облегчить такое сопоставление.
5.2.3.6. Соображения безопасности External-Body
Объекты "Message/external-body" подводят к следующим важным соображениям безопасности:
| (1) | Доступ к данным через указатель "message/external-body" эффективно приводит к тому, что получатель сообщения выполняет операцию, которую специфицировал отправитель. Следовательно, отправитель сообщения может заставить получателя выполнить нечто, что тот бы в противном случае не сделал. Например, отправитель может специфицировать процедуру, которая попытается извлечь данные, для получения которых тот не имеет авторизации, принуждая получателя помимо его воли нарушить некоторые правила безопасности. По этой причине агенты пользователя, способные работать с внешними указателями, должны сначала описать процедуру, которую ни хотят предложить выполнить получателю, попросить разрешения и только после этого запускать этот процесс. |
| (2) | Иногда MIME используется в среде, которая предоставляет некоторые гарантии целостности и аутентичности сообщений. В этой ситуации такие гарантии можно отнести только к собственно содержимому сообщения. Что касается механизма MIME "message/external-body", здесь такие гарантии, вообще говоря, могут быть и не реализованы. В частности, имеется возможность разрушить определенные механизмы доступа, даже если сама система доставки сообщений вполне безопасна. |
5.2.3.7. Примеры и дальнейшие расширения
Когда используется механизм внешнего тела в сочетании с типом среды "multipart/alternative", это расширяет функциональность "multipart/alternative", так как включает случай, когда один и тот же объект может быть получен через разные механизмы доступа.
Когда это сделано, отправитель сообщения должен упорядочить части по предпочтительности формата, а затем по механизму доступа.
Для распределенных файловых систем очень трудно знать заранее группу машин, где файл может быть доступен непосредственно. Следовательно, имеет смысл предоставить как имя файла на случай его прямой доступности, так имена одного или нескольких узлов, где может быть доступен этот файл. Программные реализации могут пытаться извлечь удаленные файлы, используя FTP или другой протокол. Если внешнее тело доступно за счет нескольких механизмов, отправитель может включить несколько объектов типа "message/external-body" в секции тела объекта "multipart/alternative".
Однако механизм внешнего тела не ограничивается извлечением файлов, как это показывается типом доступа mail-server. Помимо этого, можно предположить, например, использование видео-сервера для внешнего доступа к видео клипам.
Поля заголовка вложенного сообщения, которые появляются в теле "message/external-body" должны использоваться для декларации типа среды внешнего тела, если оно представляет собой нечто отличное от чистого текста US-ASCII, так как внешнее тело не имеет секции заголовка, чтобы декларировать тип. Аналогично здесь должно быть также декларировано любое транспортное кодирование, отличное от "7bit". Таким образом, полное сообщение "message/external-body", относящееся к объекту в формате PostScript, может выглядеть как:
From: От кого-то
To: Кому-то
Date: Когда-то
Subject: Нечто
MIME-Version: 1.0
Message-ID:
Content-Type: multipart/alternative; boundary=42
Content-ID:
--42
Content-Type: message/external-body; name="BodyFormats.ps";
| site="thumper.bellcore.com"; mode="image"; | |
| access-type=ANON-FTP; directory="pub"; | |
| expiration="Fri, 14 Jun 1991 19:13:14 -0400 (EDT)" |
Content-ID:
--42
Content-Type: message/external-body; access-type=local-file;
| name="/u/nsb/writing/rfcs/RFC-MIME.ps"; | |
| site="thumper.bellcore.com"; | |
| expiration="Fri, 14 Jun 1991 19:13:14 -0400 (EDT)" |
Content-ID:
--42
Content-Type: message/external-body;
| access-type=mail-server | |
| server="listserv@bogus.bitnet"; | |
| expiration="Fri, 14 Jun 1991 19:13:14 -0400 (EDT)" |
Content-ID:
get RFC-MIME.DOC
--42--
Заметим, что в вышеприведенных примерах в качестве транспортного кодирования для Postscript данных предполагается "7bit".
Подобно типу "message/partial", тип среды "message/external-body" предполагается прозрачным, т.е. передается тип данных внешнего тела, а не сообщение с телом данного типа. Таким образом, заголовки внешней и внутренней частей должны быть объединены с использованием правил, изложенных выше для "message/partial". В частности, это означает, что поля Content-type и Subject переписываются, а поле From сохраняется в неизменном виде.
Заметьте, что, так как внешние тела не передаются вместе с указателем, они не должны удовлетворять транспортным ограничениям, которые налагаются на сам указатель. В частности, почтовая транспортная среда Интернет может реализовать 7-битовый обмен и накладывать ограничение на длину строк, но они не распространяются на указатели на двоичное внешнее тело. Таким образом, транспортное кодирование не обязательно, но допустимо.
Заметим, что тело сообщения типа "message/external-body" регламентируется базовым синтаксисом сообщения RFC 822. В частности, все, что размещено перед первой парой CRLF является заголовком, в то время как все, что следует после заголовка, представляет собой данные, которые игнорируются для большинства типов доступа.
6. Экспериментальные значения типа среды
Значение типа среды, начинающееся с символов "X-" представляет собой частное значение, предназначенное для применения системами, которые согласились между собой работать в таком режиме.
Любой формат, не являющийся стандартным, должен иметь имя, начинающееся с префикса "X-", а утвержденные стандартные имена никогда не начинаются с "X-".
Вообще, использование "X-" для типов верхнего уровня категорически не рекомендуется. Разработчики должны придумывать субтипы существующих типов. Во многих случаях субтип "application" будет более уместен, чем новый тип верхнего уровня.
Приложение A -- обзор грамматики
Данное приложение содержит все синтаксические конструкции, описанные в разделе MIME. Сама по себе данная грамматика не может считаться полной. Она базируется на нескольких правилах, определенных в документе RFC 822. Если какой-то термин не определен, его значение предполагается заданным в RFC 822. Сами правила RFC 822 здесь не представлены.
boundary := 0*69 bcharsnospace
bchars := bcharsnospace / " "
bcharsnospace := DIGIT / ALPHA / "'" / "(" / ")" / "+" / "_" / "," / "-" / "." / "/" / ":" / "=" / "?"
body-part :=
close-delimiter := delimiter "--"
dash-boundary := "--" boundary
| boundary берется из значения пограничного параметра из поля Content-Type. |
discard-text := *(*text CRLF); Может игнорироваться или отбрасываться.
encapsulation := delimiter transport-padding CRLF body-part
epilogue := discard-text
multipart-body := [preamble CRLF]
| Dash-boundary transport-padding CRLF | |
| body-part *encapsulation | |
| close-delimiter transport-padding | |
| [CRLF epilogue] |
transport-padding := *LWSP-char
; Отправители не должны генерировать транспортных заполнителей не нулевой
; длины, но получатели должны уметь обрабатывать заполнители, добавленные в
; сообщение при транспортировке.
III. Расширения для заголовков сообщений с не-ASCII текстом
В этом разделе описывается техника кодирования не-ASCII-текста в различных частях заголовка сообщения RFC-822 [2].
Подобно тому, как это рассказано в первом разделе описания MIME, методика сконструирована так, чтобы допустить использование не-ASCII символов в заголовках сообщения так, чтобы даже специфические) удаляют некоторые поля заголовков, сохраняя другие, (b) меняет содержимое адресов в полях To или Cc, (c) меняют вертикальный порядок размещения полей заголовка. Кроме того, некоторые почтовые программы не всегда способны корректно интерпретировать заголовки сообщений, в которых встречаются некоторые редко используемые рекомендации документа RFC 822, например, символы обратной косой черты для выделения специальных символов типа "
Расширения, описанные здесь, не базируются на редко используемых возможностях RFC-822. Вместо этого, определенные последовательности "обычных" печатных ASCII символов (известных как "encoded-words" – кодировочные слова) зарезервированы для использования в качестве кодированных данных. Синтаксис кодированных слов таков, что они вряд ли могут появиться в нормальном тексте заголовков сообщений. Более того, символы, используемые в кодировочных словах, не могут иметь специального назначения в контексте, где появляются эти слова.
Вообще, "encoded-word>" представляет собой последовательность печатных ASCII-символов, которая начинается с "=?", завершается "?=" и имеет два "?" между ними. Оно специфицирует символьный набор и метод кодирования, а также включает в себя оригинальный текст в виде графических ASCII-символов, созданный согласно правилам данного метода кодирования.
Отправители почты, которые используют данную спецификацию, предоставят средства для помещения не-ASCII текста в поля заголовка, но транслируют эти поля (или соответствующие части полей) в кодировочные слова, прежде чем помещать их в заголовок сообщения.
Система чтения почты, которая реализует данную спецификацию, распознает кодировочные слова, когда они встречаются в определенной части заголовка сообщения. Вместо того чтобы отображать кодировочное слово, программа осуществляет декодирование исходного текста с использованием соответствующего символьного набора.
Данный документ в заметной мере базируется на нотации и терминах RFC-822 и RFC-2045. В частности, синтаксис для ABNF, используемый здесь, определен в RFC-822. Среди терминов, определенных в RFC-822 и использованных в данном документе: 'addr-spec' (спецификация адреса), 'атом', 'CHAR', 'комментарий', 'CTL', 'ctext', 'linear-white-space' (HT| SP|CRLF), 'фраза', 'quoted-pair', 'закавыченная строка', 'пробел' и 'слово'. Успешная реализация расширения этого протокола требует тщательного внимания к определениям этих терминов в RFC-822.
Когда в данном документе встречается термин "ASCII", он относится к "7-битовому стандарту, ANSI X3.4-1986. Имя этого символьного набора в MIME "US-ASCII".
Поле заголовка Content-Transfer-Encoding
5. Поле заголовка Content-Transfer-Encoding
Многие типы среды, которые могут передаваться посредством электронной почты, представляются в своем естественном формате, таком как 8-битовые символы или двоичные данные. Такие данные не могут быть переданы посредством некоторых транспортных протоколов. Например, RFC 821 (SMTP) ограничивает почтовые сообщения 7-битовым символьным набором ASCII со строками короче 1000 символов, включая строчные разделители CRLF.
Таким образом, необходимо определить стандартный механизм кодировки таких данных в 7-битный формат с короткими строками. В MIME для этой цели используется поле заголовка "Content-Transfer-Encoding". Это поле не было определено каким-либо прежним стандартом.
5.1. Синтаксис Content-Transfer-Encoding
Значения полей Content-Transfer-Encoding представляют собой лексему, характеризующую тип кодирования, как это описано ниже.
| encoding | := | "Content-Transfer-Encoding" ":" mechanism |
| mechanism | := | "7bit" / "8bit" / "binary" / "quoted-printable" / "base64" / ietf-token / x-token |
Эти значения не чувствительны к регистру, в котором напечатаны. - Base64, BASE64 и bAsE64 эквивалентны. Тип кодировки 7BIT требует, чтобы тело уже имело 7-битовое представление, пригодное для передачи. Это значение по умолчанию, означает, что в отсутствии поля Transfer-Encoding предполагается "Content-Transfer-Encoding: 7BIT".
5.2. Семантика Content-Transfer-Encodings
Лексема Content-Transfer-Encoding предоставляет два вида информации. Она специфицирует, какому виду кодового преобразования подвергнуто тело сообщения и, следовательно, какая процедура декодирования должна использоваться при восстановлении исходного вида сообщения.
Преобразовательная часть любого Content-Transfer-Encodings специфицирует явно или неявно алгоритм декодирования, который либо восстановит исходный вид последовательности или обнаружит ошибку. Преобразования Content-Transfer-Encodings для нормальной работы никогда не требует какой-либо дополнительной внешней информации.
Преобразование заданной последовательности октетов в другую эквивалентную кодовую последовательность совершенно легально.
В настоящее время определены три преобразования: тождественное (никакого преобразования), преобразование в последовательность печатных символов и в последовательность кодов "base64".
Значения Content-Transfer-Encoding "7bit", "8bit" и "binary" означают, что никакого преобразования не произведено. Они указывают на тип тела сообщения, и позволяют предполагать, какое кодирование может потребоваться при передаче данных.
Кодирование в последовательность печатных символов или в кодовую последовательность base64 предполагает преобразование из произвольного исходного формата в представление "7bit", что позволяет передачу через любые транспортные среды.
Всегда должна использоваться корректная метка Content-Transfer-Encoding. Пометка данных, преобразованных программой UUENCODE и содержащих 8-битовые символы, как "7bit" не допустима, такие данные должны помечаться только как "binary".
При прочих равных условиях предпочтительным представлением является последовательность печатных символов или кодов base64.
Передача почтовых сообщений закодированных программой uuencode описана в документе RFC 1652. Но следует иметь в виду, что ни при каких обстоятельствах Content-Transfer-Encoding "binary" нельзя считать приемлемым для e-mail. Однако когда используется MIME, двоичное тело сообщение может быть помечено как таковое.
5.3. Новое значение Content-Transfer-Encodings
Программисты могут, если необходимо, определить частные значения Content-Transfer-Encoding. При этом должны использоваться x-лексемы, которые представляют собой имена с префиксом "X-", что указывает на нестандартный статус, например, "Content-Transfer- Encoding: x-my-new-encoding". Дополнительные стандартизованные значения Content-Transfer-Encoding должны быть специфицированы в официальных документах RFC.
В отличие от типов среды и субтипов, формирование новых значений Content- Transfer-Encoding категорически не рекомендуется, так как может привести к полному выходу из строя системы.
4. Реализация и применение
Если поле заголовка Content-Transfer-Encoding появляется как часть заголовка сообщения, оно относится ко всему телу сообщения. Если поле заголовка Content-Transfer-Encoding появляется в качестве части заголовка объекта, то зоной его действия будет тело этого объекта. Если объект имеет тип "multipart", то Content-Transfer-Encoding не может иметь значение "7bit", "8bit" или "binary". Следует заметить, что большинство типов среды определены в терминах октетов, а не бит, поэтому описываемые механизмы относятся к кодировке произвольных потоков октетов, а не бит. Если необходимо закодировать битовую последовательность, она должна быть преобразована в последовательность октетов с сетевой последовательностью бит ("big-endian"), в которой более ранние биты становятся старшими битами октетов. Битовые потоки, длина которых не кратна 8, должны быть дополнены нулями.
Механизмы кодировки, определенные здесь, осуществляют преобразование любых данных в ASCII. Таким образом, предположим, например, что объект имеет следующие поля заголовка:
Content-Type: text/plain; charset=ISO-8859-1
Content-transfer-encoding: base64
Это должно интерпретироваться так, что тело имеет кодировку base64, а исходные данные имели представление в ISO-8859-1.
Определенные значения Content-Transfer-Encoding могут использоваться только с определенными типами среды. В частности, категорически запрещено использовать любую кодировку отличную от "7bit", "8bit" или "binary" с любым составным типом среды, т.e. включающим и другие поля Content-Type. В настоящее время допустимы составные типы среды "multipart" и "message". Все кодировки, допустимые для тел типа multipart или message должны использоваться на самом внутреннем уровне.
Следует также заметить, что по определению, если составной объект имеет значение transfer-encoding равное "7bit", но один из составляющих объектов имеет менее регламентирующее значение, например, "8bit", тогда либо внешняя метка "7bit" является ошибкой, или внутренняя метка "8bit" устанавливает слишком высокое требование к транспортной системе (следовало проставить 7bit).
Хотя запрет использования content-transfer-encodings для составного тела может показаться чрезмерно регламентирующим, следует избегать вложенных кодирований, в которых данные подвергаются последовательно обработке несколькими алгоритмами. Вложенные кодирования заметно повышают сложность агентов пользователя. Помимо очевидных проблем эффективности при множественном кодировании они могут затемнить базовую структуру сообщения. В частности они могут подразумевать, что необходимо несколько операций декодирования, чтобы определить, какие типы тел содержит сообщение. Запрет вложенных кодировок может осложнить работу некоторых почтовых шлюзов, но это представляется меньшей бедой, чем осложнение жизни агентов пользователя при вложенном кодировании.
Любой объект с нераспознанным значением Content-Transfer-Encoding должен рассматриваться, как если бы он имел код Content-type "application/octet-stream", вне зависимости оттого, что утверждается полем заголовка Content-Type.
Может показаться, что Content-Transfer-Encoding может быть выяснено из характеристик среды, для которой нужно осуществить кодирование или, по крайней мере, что определенное Content-Transfer-Encodings может быть предназначено для использования с определенными типами среды. Есть несколько причин, почему это не так. Во-первых, существующие различные типы транспорта, используемые для почты, некоторые кодирования могут годиться для определенных комбинаций типов среды и транспорта, но быть непригодными для других. Например, при 8-битовой передаче, при определенном символьном наборе для текста не потребуется никакого кодирования, в то время как такое кодирование очевидно необходимо для 7-битового SMTP.
Во-вторых, определенные типы среды могут требовать различного транспортного кодирования при разных обстоятельствах. Например, многие PostScript-тела могут целиком состоять из коротких строк 7-битовых кодов, и, следовательно, совсем не требуют кодирования. Другие тела PostScript (в особенности те, что используют механизм двоичного кодирования уровня 2 PostScript) могут быть представлены с использованием двоичного транспортного кодирования. Наконец, так как поле Content-Type ориентировано на то, чтобы предоставлять открытые механизмы спецификации, строгие ассоциации типов среды и кодирования эффективно соединяют спецификацию прикладного протокола с определенным транспортом нижнего уровня. Это нежелательно, так как разработчики типа среды не должны заботиться обо всех видах транспорта и их особенностях.
5.5. Транслирующее кодирование
Кодирование с использованием закавыченных строк печатных символов и кодов base64 устроено так, чтобы позволить взаимные преобразования. Единственная проблема, которая здесь возникает, это обработка принудительных разрывов строк для закавыченных последовательностей печатных символов. При преобразовании закавыченных строк в коды base64 принудительные разрывы строк отображаются последовательностями CRLF. Аналогично, последовательность CRLF в канонической форме данных, полученной после декодирования из base64, должна преобразоваться в принудительный разрыв строки в случае представления текста в виде закавыченной строки печатных символов. Каноническая модель кодирования представлена в документе RFC 2049.
5.6. Транспортное кодирование содержимого Quoted-Printable
Кодирование Quoted-Printable имеет целью представление данных, состоящих по большей части из октетов, которые соответствуют печатным символам ASCII-набора. Оно преобразует данные таким образом, что результирующие октеты не будут видоизменены при транспортировке почты. Если преобразуемые данные представляют собой ASCII-текст, то после кодирования они сохранят читабельность. Тело, которое целиком состоит из ASCII-кодов, может быть также представлено в виде закавыченной строки печатных символов.
При этом сохраняется целостность текста в процессе прохождении через шлюз, который осуществляет трансляцию символов и/или обработку разрывов строк. При этом кодировании октеты должны определяться согласно изложенным ниже правилам:
| (1) | 8-битовое представление. Любой октет, за исключением CR или LF, которые являются частью последовательности разрыва строки CRLF, канонического (стандартного) формата данных может быть представлен с помощью символом "=", за которым следуют две шестнадцатеричные цифры, характеризующие значение октета. Для этих целей используются цифры шестнадцатеричного алфавита "0123456789ABCDEF". Должны использоваться прописные буквы; использование строчных букв недопустимо. Так, например, десятичное значение 12 (ASCII FF) может быть представлено как "=0C", а десятичное значение 61 (ASCII символ знака равенства) представляется с помощью "=3D". Это правило должно выполняться всегда за исключением случаев, когда правила допускают альтернативное кодирование. |
| (2) | Литеральное представление. Октеты с десятичными кодами в интервале 33 - 60 включительно, и 62 - 126, включительно, могут представляться ASCII-символами, которые соответствуют этим октетам (с ! до < и с > до ~ соответственно). |
| (3) | Пробелы. Октеты со значениями кодов 9 и 32 могут отображаться с помощью ASCII-символов TAB (HT) и пробел, соответственно, но не должны использоваться в конце строки. За любым символом TAB (HT) или пробел в кодируемой строке должен следовать печатный символ. В частности, символ "=" в конце каждой кодируемой строки, обозначающий "мягкий" разрыв строки (смотри правило #5), может следовать за одним или более символами TAB (HT) или SP. Отсюда следует, что октет, равный 9 или 32 появляющийся в конце кодируемой строки должен быть представлен в форме, указанной правилом #1. Это правило необходимо, так как некоторые MTA (Message Transport Agents, программы, которые передают сообщения от одного пользователя другому) дополняют строки пробелами, а другие удаляют пробелы (HT или SP) в конце строки. Следовательно, при декодировании тела, представленного в форме закавыченных печатных последовательностей, любые HT или SP должны быть удалены. |
| (4) |
Разрывы строк. Разрыв строки в теле текста, представленный последовательностью CRLF в канонической форме, для закавыченной печатной строки отмечается CRLF. Последовательности типа "=0D", "=0A", "=0A=0D" и "=0D=0A" появляются в нетекстовых данных, представленных в виде закавыченных строк печатных символов. Заметим, что многие реализации могут выбрать для кодирования непосредственно локальное представление различных типов содержимого, а не преобразование в каноническую форму, кодирование и только затем преобразование в локальное представление. В частности, такая техника может быть применена к простому тексту в системах, которые используют для межстрочных разрывов последовательности, отличные от CRLF. Такая оптимизация конкретной программной реализации вполне допустима, но только когда комбинированный шаг канонизация-кодирование эквивалентен выполнению всех трех шагов отдельно. |
| (5) | Мягкие разрывы строки. Кодирование с помощью закавыченных строк печатных символов требует, чтобы строки содержали не более 76 символов. Если нужно закодировать более длинные строки вводятся “мягкие” разрывы строк. Символ равенства в конце строки как раз и обозначает такой разрыв. |
/p> Так пусть имеется следующий текст, который надо преобразовать:
Now's the time for all folk to come to the aid of their country.
Это может быть представлено следующим образом с помощью закавыченных строк печатных символов:
Now's the time =
Это предоставляет механизм, с помощью которого длинные строки преобразуются таким образом, как они должны быть запомнены агентом пользователя. Ограничение в 76 символов не учитывает завершающие строку CRLF, но включают все прочие символы, включая знаки равенства. Так как символ дефис ("-") может отображаться в закавыченных строках самим собой, нужно следить за тем, чтобы при инкапсуляции закодированного так фрагмента, в одном или более составных объектов пограничные разделители не появились в закодированном теле. Хорошей стратегией является выбор в качестве границы последовательности символов "=_", которая не может встретиться в закавыченной строке печатных символов.
Преобразование в закавыченные строки печатных символов представляет собой компромисс между читабельностью и надежностью при транспортировке. Тела, закодированные с помощью закавыченных строк печатных символов, пропускаются без проблем большинством почтовых шлюзов. Проблемы могут возникать только со шлюзами, осуществляющими трансляцию в коды EBCDIC. Кодирование с помощью base64 обеспечивает более высокий уровень надежности. Методом получения разумно высокой надежности транспортировки через шлюзы EBCDIC является представление символов !"#$@[\]^`{|}~ согласно правилу #1.
Так как закавыченные последовательности печатных символов предполагаются ориентированными на строчное представление, разрывы между строками могут видоизменяться в процессе транспортировки. Если изменение кодов разрыва строк может вызвать искажения или сбои, следует использовать кодирование с помощью base64.
Несколько видов субстрок не могут генерироваться согласно правилам кодирования для представления с помощью закавыченных последовательностей печатаемых символов. Ниже перечисляются эти нелегальные субстроки и предлагаются способы их кодирования.
| (1) | Символ "=", за которым следует две шестнадцатеричные цифры, одна или обе из которых являются строчными символами (abcdef). Надежные реализации могут распознавать их как прописные буквы. |
| (2) | Символ "=", за которым следует символ, не являющийся ни шестнадцатеричной цифрой (включая abcdef), ни CR из комбинации CRLF. Это не может стать частью ASCII-текста, включенного в сообщение, без преобразования в закавыченную последовательность печатных кодов. Разумным решением для надежной реализации может быть включение символа "=" и следующих за ним кодов в декодированную последовательность, без какого-либо преобразования и, если возможно, дать и сигнал агенту пользователя, что декодирование в этом месте оказалось невозможным. |
| (3) | Символ "=" не может быть последним или завершающим символом в кодируемом объекте. Решением проблемы можно считать способ, предложенный в пункте (2). |
| (4) | Управляющие символы, отличные от TAB, CR и LF (в качестве части CRLF) не должны присутствовать. То же справедливо для октетов с десятичными значениями больше чем 126. Если такие коды обнаруживаются в приходящих закавыченных последовательностях печатных символов, корректная реализация может исключить из декодированных данных и предупредить пользователя о том, что обнаружен нелегальный символ. |
| (5) | Закодированные строки не должны быть длиннее 76 символов, не считая завершающие CRLF. Если во входном потоке обнаружены более длинные строки, надежная реализация может их декодировать, но должна предупредить пользователя об ошибке. |
С формальной точки зрения, закавыченные последовательности печатных символов подчиняются следующей грамматике.
| quoted-printable | := | qp-line *(CRLF qp-line) | |
| qp-line | := | *(qp-segment transport-padding CRLF) qp-part transport-padding | |
| qp-part | := | qp-section | ; Максимальна длина 76 символов |
| qp-segment | := | qp-section *(SPACE / TAB) "=" | ; Максимальна длина 76 символов |
| qp-section | := | [*(ptext / SPACE / TAB) ptext] | |
| ptext | := | hex-octet / safe-char | |
| safe-char | := | ; Символы, не включенные в список "mail-safe" RFC 2049, не рекомендуются к применению. | |
| hex-octet | := | "=" 2(DIGIT / "A" / "B" / "C" / "D" / "E" / "F") | ; Октет должен использоваться для символов с кодами > 127, =, SP или TAB в конце строк, и рекомендуются для любого символа не указанного в списке "mail-safe" документа RFC 2049. |
| transport-padding | := | *LWSP-char | ; Составители не должны генерировать заполнители ненулевой длины, но получатели должны быть способны обрабатывать заполнители, добавленные при транспортировке. |
5.7. Транспортное кодирование Base64 (Content-Transfer-Encoding)
Транспортное кодирование на основе Base64 создано для представления произвольной последовательности октетов в форме, которая не обязательно должна быть приемлемой для прочтения человеком. Алгоритмы кодирования и декодирования просты. Это кодирование сходно с тем что используется в почтовом приложении PEM (Privacy Enhanced Mail), как это определено в RFC-1421.
Здесь используется 65-символьный субнабор ASCII, для каждого печатного символа выделено по 6 бит. Дополнительный 65-ый символ "=", используется для обозначения специальных функций обработки.
Этот субнабор имеет важное свойство, которое заключается в том, что он представляется идентично во всех версиях ISO 646, включая US-ASCII, и все символы субнабора имеют аналоги во всех версиях EBCDIC.
Другие популярные кодировки, такие как применение утилиты uuencode, Macintosh binhex 4.0 [RFC-1741] и base85, специфицированная как часть уровня 2 PostScript, имеют отличающиеся свойства и, следовательно, не выполняют условий переносимости, которым должна удовлетворять двоичное транспортное кодирование электронной почты.
При кодировании входные 24-битовые группы преобразуют в 4 символа. Входная группа формируется из трех 8-битовых кодов и обрабатывается слева направо. Эти 24 бита рассматриваются в дальнейшем как 4 6-битовые группы, каждая из которых транслируется в одно число из алфавита base64. Когда кодируется битовый поток с использованием base64, предполагается, что старший бит передается первым. То есть, первый бит потока станет старшим битом первого 8-битового байта, а 8-ой бит станет его последним битом.
Каждая 6-битовая группа используется как индекс массива из 64 печатных символов. Символ, на который указывает индекс, берется из массива и помещается в выходной поток. Эти символы представлены в таблице .1., из их перечня исключены коды, имеющие особое значение для протокола SMTP (например, ".", CR, LF), а также разграничитель секций составного сообщения "-" (RFC-2046).
Поле заголовка Content-Type
4. Поле заголовка Content-Type
Задачей поля Content-Type является описание информации, содержащейся в теле сообщения. Этого описания должно быть достаточно, чтобы принимающий агент пользователя был способен воспринять и отобразить полученные данные. Значение этого поля называется типом среды.
Поле заголовка Content-Type было первым, определенным в документе RFC-1049. В RFC-1049 использовался более простой и менее мощный синтаксис, который, в прочем, вполне согласуется с регламентациями MIME.
Поле заголовка Content-Type специфицирует природу данных в теле объекта, сообщая тип среды и идентификаторы субтипа, а также предоставляя вспомогательную информацию, которая может требоваться для определенного типа среды. После типа среды и имен субтипов может следовать набор параметров, который описывается в нотации атрибут = значение. Порядок параметров не имеет значения. Тип среды верхнего уровня используется для декларирования общего типа данных, в то время как субтип определяет специфический формат информации. Таким образом, типа среды "image/xyz" достаточно, чтобы сообщить агенту пользователя, что данные представляют собой изображение, даже если агент пользователя не имеет представления о формате изображения "xyz". Такая информация может использоваться, например, для того чтобы решить, следует ли показывать пользователю исходные данные нераспознанного субтипа. Такая операция разумна для нераспознанного субтипа текста, но бессмысленна для изображения или звука. По этой причине, зарегистрированные субтипы текста, изображения, аудио и видео не должны содержать вложенной информации другого типа. Такой составной формат должен быть представлен с использованием "multipart" или "application" типов.
Параметры являются модификаторами субтипа среды и по этой причине не могут существенно влиять на природу содержимого. Набор значимых параметров зависит от типа и субтипа среды. Большинство параметров связано с одним специфическим субтипом.
Однако тип среды верхнего уровня может определить параметры, которые применимы к любому субтипу данного типа. Параметры могут быть необходимы для определенных типов и субтипов, могут они быть и опционными. Реализации MIME должны игнорировать любые параметры, если их имена не распознаны.
Например, параметр "charset" применим к любому субтипу "текста", в то время как параметр "boundary" необходим для любого субтипа типа среды "multipart". Не существует параметров, применимых для всех типов среды.
Исходный набор из семи типов среды верхнего уровня определен в документе RFC 2046. Пять из них являются дискретными типами. Остальные два являются составными типами, чье содержимое требует дополнительной обработки процессорами MIME.
Этот набор типов среды верхнего уровня является замкнутым. Предполагается, что необходимые расширения набора могут осуществляться за счет введения субтипов к существующим базовым типам. В будущем, расширение базового набора допустимо лишь при смене стандарта. Если необходим какой-то новый базовый тип среды, его имя должно начинаться с "X-", что указывает на то, что он не является стандартным.
4.1. Синтаксис поля заголовка Content-Type
В нотации BNF, значение поля заголовка Content-Type определяется следующим образом:
| content | := | "Content-Type" ":" type "/" subtype *(";" parameter) | ; Распознавание типа и субтипа среды всегда не зависит от регистра, в котором они напечатаны. |
| type | := | discrete-type / composite-type | |
| discrete-type | := | "text" / "image" / "audio" / "video" / "application" / extension-token | |
| composite-type | := | "message" / "multipart" / extension-token | |
| extension-token | := | ietf-token / x-token | |
| ietf-token | := | ||
| x-token | := | ||
| subtype | := | extension-token / iana-token | |
| iana-token | := | ||
| parameter | := | attribute "=" value | |
| attribute | := | token | ; Распознавание атрибутов не зависит от регистра, в котором они напечатаны. |
| value | := | token / quoted-string | |
| token | := | 1* | |
| tspecials | := | "(" / ")" / "" / "@" / "," / ";" / ":" / "\" / "/" / "[" / "]" / "?" / "=" | ; Должно представлять собой строку в кавычках |
/p> Заметим, что определение "tspecials" совпадает с определением "specials" в RFC 822 с добавлением трех символов "/", "?" и "=" и удалением "." (точка).
Заметим также, что спецификация субтипа является MANDATORY - она не может быть удалена из поля заголовка Content-Type. Не существует субтипов по умолчанию. Тип, субтип и имена параметров не зависят от регистра, в которых они напечатаны. Например, TEXT, Text и TeXt являются эквивалентными типами среды верхнего уровня. Значения же параметров в норме чувствительны к регистру, в котором они напечатаны, но иногда интерпретируются без учета регистра в зависимости от приложения. (Например, границы типа multipart являются чувствительными к регистру, а параметр "access-type" для сообщения message/External-body не чувствителен.)
Обратите внимание, что значение строки в кавычках не включает в себя сами кавычки. В полях заголовка в соответствии с RFC 822 допускаются комментарии. Таким образом, две приведенные ниже формы являются эквивалентными.
Content-type: text/plain; charset=us-ascii (Plain text)
Content-type: text/plain; charset="us-ascii".
Предполагается, что имена субтипов при их применении не вызовут конфликтов. Так недопустимо, чтобы в различных приложениях "Content-Type: application/foobar" означало различные вещи. Существует два приемлемых механизма определения новых субтипов среды.
Частные значения (начинающиеся с "X-") могут быть определены для двух взаимодействующих агентов без официальной регистрации или стандартизации.
Новые стандартные значения должны регистрироваться IANA, как это описано в RFC 2048.
4.2. Значения по умолчанию Content-Type
Сообщения по умолчанию без MIME-заголовка Content-Type согласно протоколу должны содержать простой текст с символьным набором ASCII, который может быть специфицирован явно.
Content-type: text/plain; charset=us-ascii
Это значение подразумевается, если не специфицировано поле заголовка Content-Type.Рекомендуется, чтобы это значение по умолчанию использовалось в случае, когда встретилась нераспознанное значение поля заголовка Content-Type. В присутствии поля заголовка MIME-Version и отсутствии поля Content-Type, принимающий агент пользователя может также предположить, что отправитель предлагает простой текст в ASCII-кодировке. Простой ASCII-текст может предполагаться в отсутствии MIME-Version или в присутствии синтаксически некорректного поля заголовка Content-Type, хотя это может и не совпадать с намерениями отправителя.
Положение интерфейсов в архитектуре MPEG-J
Рисунок 10. Положение интерфейсов в архитектуре MPEG-J
Пользовательские команды с ACK
3.4.3. Пользовательские команды с ACK
Модель DMIF позволяет приложениям партнеров обмениваться любыми сообщениями пользователей (поток управляющих сообщений). В DMIF V2 добавлена поддержка сообщений-откликов.
A Сложный пример составного сообщения
Приложение A. Сложный пример составного сообщения
Данное сообщение содержит пять частей, которые должны быть отображены последовательно: - два вводных объекта чистого текста, встроенное составное сообщение, объект типа text/enriched и завершающее инкапсулированное текстовое сообщение с символьным набором не ASCII типа. Встроенное составное сообщение в свою очередь содержит два объекта, которые должны отображаться в параллель, изображение и звуковой фрагмент.
MIME-Version: 1.0
From: Nathaniel Borenstein
To: Ned Freed
Date: Fri, 07 Oct 1994 16:15:05 -0700 (PDT)
Subject: A multipart example(составной пример)
Content-Type: multipart/mixed;boundary=unique-boundary-1
Это область преамбулы составного сообщения. Программы чтения почты, приспособленные для чтения составных сообщений, должны игнорировать эту преамбулу.
--unique-boundary-1
... Здесь размещается некоторый текст ...
[Заметим, что пробел между границей и началом текста в этой части означает, что не было никаких заголовков и данный текст представлен в символьном наборе US-ASCII.]
--unique-boundary-1
Content-type: text/plain; charset=US-ASCII
Это может быть частью предыдущей секции, но иллюстрирует различие непосредственного и неявного ввода текста частей тела.
--unique-boundary-1
Content-Type: multipart/parallel; boundary=unique-boundary-2
--unique-boundary-2
Content-Type: audio/basic
Content-Transfer-Encoding: base64
... здесь размещаются одноканальные аудио данные, полученные при частоте стробирования 8 кГц, представленные с использованием m-преобразования, и закодированные с привлечением base64 ...
--unique-boundary-2
Content-Type: image/jpeg
Content-Transfer-Encoding: base64
... здесь размещается изображение, закодированное с привлечением base64 ...
--unique-boundary-2--
--unique-boundary-1
Content-type: text/enriched
This is enriched.
как определено в RFC-1896
Isn't it
cool?
-unique-boundary-1
Content-Type: message/RFC-822
From: (mailbox in US-ASCII)
To: (address in US-ASCII)
Subject: (subject in US-ASCII)
Content-Type: Text/plain; charset=ISO-8859-1
Content-Transfer-Encoding: Quoted-printable
Additional text in ISO-8859-1 goes here ...
--unique-boundary-1--
Ссылки
| [ATK] | Borenstein, Nathaniel S., Multimedia Applications Development with the Andrew Toolkit, PrenticeHall, 1990. |
| [ISO-2022] | International Standard -- Information Processing -- Character Code Structure and Extension Techniques, ISO/IEC 2022:1994, 4th ed. |
| [ISO-8859] |
International Standard -- Information Processing -- 8-bit Single-Byte Coded Graphic Character Sets - Part 1: Latin Alphabet No. 1, ISO 8859-1:1987, 1st ed. - Part 2: Latin Alphabet No. 2, ISO 8859-2:1987, 1st ed. - Part 3: Latin Alphabet No. 3, ISO 8859-3:1988, 1st ed. - Part 4: Latin Alphabet No. 4, ISO 8859-4:1988, 1st ed. - Part 5: Latin/Cyrillic Alphabet, ISO 8859-5:1988, 1st ed. - Part 6: Latin/Arabic Alphabet, ISO 8859-6:1987, 1st ed. - Part 7: Latin/Greek Alphabet, ISO 8859-7:1987, 1st ed. - Part 8: Latin/Hebrew Alphabet, ISO 8859-8:1988, 1st ed. - Part 9: Latin Alphabet No. 5, ISO/IEC 8859-9:1989, 1st ed. International Standard -- Information Technology -- 8-bit Single-Byte Coded Graphic Character Sets >- Part 10: Latin Alphabet No. 6, ISO/IEC 8859-10:1992, 1st ed. |
| [ISO-646] | International Standard -- Information Technology – ISO 7-bit Coded Character Set for Information Interchange, ISO 646:1991, 3rd ed.. |
| [JPEG] | JPEG Draft Standard ISO 10918-1 CD. |
| [MPEG] | Video Coding Draft Standard ISO 11172 CD, ISO IEC/JTC1/SC2/WG11 (Motion Picture Experts Group), May, 1991. |
| [PCM] | CCITT, Fascicle III.4 - Recommendation G.711, "Pulse Code Modulation (PCM) of Voice Frequencies", Geneva, 1972. |
| [POSTSCRIPT] | Adobe Systems, Inc., PostScript Language Reference Manual, Addison-Wesley, 1985. |
| [POSTSCRIPT2] | Adobe Systems, Inc., PostScript Language Reference Manual, Addison-Wesley, Second Ed., 1990. |
| [RFC-783] | Sollins, K.R., "TFTP Protocol (revision 2)", RFC-783, MIT, June 1981. |
| [RFC-821] | Postel, J.B., "Simple Mail Transfer Protocol", STD-10, RFC-821, USC/Information Sciences Institute, August 1982. |
| [RFC-822] | Crocker, D., "Standard for the Format of ARPA Internet Text Messages", STD 11, RFC-822, UDEL, August 1982. |
| [RFC-934] | Rose, M. and E. Stefferud, "Proposed Standard for Message Encapsulation", RFC-934, Delaware and NMA, January 1985. |
| [RFC-959] | Postel, J. and J. Reynolds, "File Transfer Protocol", STD 9, RFC-959, USC/Information Sciences Institute, October 1985. |
| [RFC-1049] | Sirbu, M., "Content-Type Header Field for Internet Messages", RFC-1049, CMU, March 1988. |
| [RFC-1154] | Robinson, D., and R. Ullmann, "Encoding Header Field for Internet Messages", RFC-1154, Prime Computer, Inc., April 1990. |
| [RFC-1341] | Borenstein, N., and N. Freed, "MIME (Multipurpose Internet Mail Extensions): Mechanisms for Specifying and Describing the Format of Internet Message Bodies", RFC-1341, Bellcore, Innosoft, June 1992. |
| [RFC-1342] | Moore, K., "Representation of Non-Ascii Text in Internet Message Headers", RFC-1342, University of Tennessee, June 1992. |
| [RFC-1344] | Borenstein, N., "Implications of MIME for Internet Mail Gateways", RFC-1344, Bellcore, June 1992. |
| [RFC-1345] | Simonsen, K., "Character Mnemonics & Character Sets", RFC-1345, Rationel Almen Planlaegning, June 1992. |
| [RFC-1421] | Linn, J., "Privacy Enhancement for Internet Electronic Mail: Part I -- Message Encryption and Authentication Procedures", RFC-1421, IAB IRTF PSRG, IETF PEM WG, February 1993. |
| [RFC-1422] | Kent, S., "Privacy Enhancement for Internet Electronic Mail: Part II -- Certificate-Based Key Management", RFC-1422, IAB IRTF PSRG, IETF PEM WG, February 1993. |
| [RFC-1423] | Balenson, D., "Privacy Enhancement for Internet Electronic Mail: Part III -- Algorithms, Modes, and Identifiers", IAB IRTF PSRG, IETF PEM WG, February 1993. |
| [RFC-1424] | Kaliski, B., "Privacy Enhancement for Internet Electronic Mail: Part IV -- Key Certification and Related Services", IAB IRTF PSRG, IETF PEM WG, February 1993. |
| [RFC-1521] | Borenstein, N., and Freed, N., "MIME (Multipurpose Internet Mail Extensions): Mechanisms for Specifying and Describing the Format of Internet Message Bodies", RFC-1521, Bellcore, Innosoft, September, 1993. |
| [RFC-1522] | Moore, K., "Representation of Non-ASCII Text in Internet Message Headers", RFC-1522, University of Tennessee, September 1993. |
| [RFC-1524] | Borenstein, N., "A User Agent Configuration Mechanism for Multimedia Mail Format Information", RFC-1524, Bellcore, September 1993. |
| [RFC-1543] | Postel, J., "Instructions to RFC Authors", RFC-1543, USC/Information Sciences Institute, October 1993. |
| [RFC-1556] | Nussbacher, H., "Handling of Bi-directional Texts in MIME", RFC-1556, Israeli Inter-University Computer Center, December 1993. |
| [RFC-1590] | Postel, J., "Media Type Registration Procedure", RFC-1590, USC/Information Sciences Institute, March 1994. |
| [RFC-1602] | Internet Architecture Board, Internet Engineering Steering Group, Huitema, C., Gross, P., "The Internet Standards Process -- Revision 2", March 1994. |
| [RFC-1652] | Klensin, J., (WG Chair), Freed, N., (Editor), Rose, M., Stefferud, E., and Crocker, D., "SMTP Service Extension for 8bit-MIME transport", RFC-1652, United Nations University, Innosoft, Dover Beach Consulting, Inc., Network Management Associates, Inc., The Branch Office, March 1994. |
| [RFC-1700] | Reynolds, J. and J. Postel, "Assigned Numbers", STD-2, RFC-1700, USC/Information Sciences Institute, October 1994. |
| [RFC-1741] | Faltstrom, P., Crocker, D., and Fair, E., "MIME Content Type for BinHex Encoded Files", December 1994. |
| [RFC-1896] | Resnick, P., and A. Walker, "The text/enriched MIME Content-type", RFC-1896, February, 1996. |
| [RFC-2045] | Freed, N., and and N. Borenstein, "Multipurpose Internet Mail Extensions (MIME) Part One: Format of Internet Message Bodies", RFC-2045, Innosoft, First Virtual Holdings, November 1996. |
| [RFC-2046] | Freed, N., and N. Borenstein, "Multipurpose Internet Mail Extensions (MIME) Part Two: Media Types", RFC-2046, Innosoft, First Virtual Holdings, November 1996. |
| [RFC-2047] | Moore, K., "Multipurpose Internet Mail Extensions (MIME) Part Three: Representation of Non-ASCII Text in Internet Message Headers", RFC-2047, University of Tennessee, November 1996. |
| [RFC-2048] | Freed, N., Klensin, J., and J. Postel, "Multipurpose Internet Mail Extensions (MIME) Part Four: MIME Registration Procedures", RFC-2048, Innosoft, MCI, ISI, November 1996. |
| [RFC-2049] | Freed, N. and N. Borenstein, "Multipurpose Internet Mail Extensions (MIME) Part Five: Conformance Criteria and Examples", RFC-2049 (this document), Innosoft, First Virtual Holdings, November 1996. |
| [US-ASCII] | Coded Character Set -- 7-Bit American Standard Code for Information Interchange, ANSI X3.4-1986. |
| [X400] | Schicker, Pietro, "Message Handling Systems, X.400", Message Handling Systems and Distributed Applications, E. Stefferud, O-j. Jacobsen, and P. Schicker, eds., North-Holland, 1989, pp. 3-41. |
/p>
фильтрации описаний
Рисунок 28. Приложение фильтрации описаний
3.6.6. Модель ключевого приложения MPEG-7
3.6.6.1. Определение ключевых приложений
Эти приложения называются также ключевыми приложениями, так как они имеют базовый или элементарный тип. Вообще, ключевые приложения необязательно являются приложениями реального мира, так как они используют только репрезентативные и общие задания прикладных сценариев.
Другим важным ограничением программного обеспечения XM является факт, что программы XM являются лишь средствами командной строки, то есть, что приложение, его входы и выходы могут быть специфицированы только, когда работает XM. Ключевые приложения во время работы не поддерживают взаимодействие с пользователем.
3.6.6.2. Модель интерфейса
После идентификации природы ключевых приложений следующим шагом является разработка абстрактной модели такого приложения. Результирующий субнабор входов и выходов показан на Рисунок 29. Возможными входами являются медиа базы данных, базы данных описаний и запросов. Возможными выходами могут быть медиа базы данных и базы данных описаний. В абстрактной модели семантика выхода медиа базы данных не разделена, то есть, список медиа файлов наилучшего соответствия и транскодированной медиа базы данных не рассматриваются как индивидуальные типы выхода.

видео предлагает технологию, которая
9.1. Приложения видео-стандарта MPEG-4
MPEG- 4 видео предлагает технологию, которая перекрывает широкий диапазон существующих и будущих приложений. Низкие скорости передачи и кодирование устойчивое к ошибкам позволяет осуществлять надежную связь через радио-каналы с ограниченной полосой, что полезно, например, для мобильной видеотелефонии и космической связи. При высоких скоростях обмена, имеются средства, позволяющие передачу и запоминание высококачественного видео на студийном уровне.
Главной областью приложений является интерактивное WEB-видео. Уже продемонстрированы программы, которые осуществляют живое видео MPEG-4. Средства двоичного кодирования и работы с видео-объектами с серой шкалой цветов должны быть интегрированы с текстом и графикой.
MPEG-4 видео было уже использовано для кодирования видеозапись, выполняемую с ручной видео-камеры. Эта форма приложения становится все популярнее из-за простоты переноса на WEB-страницу, и может также применяться и в случае работы со статичными изображениями и текстурами. Рынок игр является еще одной областью работы приложений MPEG-4 видео, статических текстур, интерактивности.
Применение го режима сетевого адаптера для целей диагностики
5.3 Применение 6-го режима сетевого адаптера для целей диагностики
Использование 6-го режима работы сетевого интерфейса предоставляет необычные возможности администратору и таит в себе немалые угрозы в случае использования его хакером. Как известно практически любая сетевая карта имеет 6 режимов работы. Обычно она работает в 3-ем режиме, воспринимая все пакеты адресованные ей, а также широковещательные и мультикастинг пакеты. В 6-ом же режиме карта пытается принять все пакеты, следующие по сегменту, вне зависимости от адреса места назначения. Если позволяет загрузка и быстродействие сетевого интерфейса, будут восприняты и обработаны все пакеты, следующие по сегменту, к которому подключена ЭВМ, работающая в 6-ом режиме. Именно по этой причине желательно при осуществлении авторизации использовать шифрованный обмен. В противном случае хакер, чья ЭВМ подключена к сетевому сегменту, может получить все пароли, в том числе и привилегированных пользователей. Если шифрование обмена при авторизации недоступно, привилегированные (root) пользователи должны ограничиться работой через консоль. Выполнение привилегированных операций с удаленной ЭВМ не желательно, так как может привести к раскрытию системного пароля.
6-ой режим позволяет проанализировать распределение пакетов по коду протокола, по адресам отправителей или получателей. Определить парциальные значения трафиков отдельного пользователя для различных видов услуг. Некоторые виды из перечисленных данных можно получить из MIB маршрутизатора (например, Accounting database в случае маршрутизаторов CISCO), но 6-й режим предоставляет большую гибкость и возможности.
6-ой режим позволяет проанализировать распределение пакетов по коду протокола, по адресам отправителей или получателей. Определить парциальные значения трафиков отдельного пользователя для различных видов услуг. Некоторые виды из перечисленных данных можно получить из MIB маршрутизатора (например, accounting database в случае маршрутизаторов Cisco), но 6-й режим предоставляет большую гибкость и возможности.
К сожалению, данная методика применима лишь к пакетам, проходящим через сегмент, к которому подключена ЭВМ, работающая в 6-ом режиме (см. Рисунок 5.3.1).
Пример графа сегмента
Рисунок 19. Пример графа сегмента
3.5.3.2. Описание концептуальных аспектов содержимого
Для некоторых приложений, подход, описанный выше, не приемлем, так как он выделяет структурные аспекты материала. Для приложений, где структура практически не используется, но где пользователь в основном интересуется семантикой материала, альтернативным подходом является семантический
DS. В этом подходе, акцент делается не на сегментах, а на событиях, объектах,
концепциях, месте, времени и абстракции.
Документальная сфера относится к контексту для семантического описания, то есть, это "реальность", в которой описание имеет смысл. Это понятие перекрывает область специфических случаев аудио-визуального материала, а также более абстрактных описаний, представляющих область возможных медиа-вариантов.
Как показано на Рисунок 20, DS SemanticBase
описывает документальные сферы и семантические объекты. Кроме того, несколько специальных DS получается из DS SemanticBase, которые описывают специфические типы семантических объектов, таких как описательные сферы, объекты, объекты агента, события, место и время, например: Семантический
DS описывает документальные сферы (narrative worlds - реальные миры), которые отображаются или сопряжены с аудио-визуальным материалом. Он может использоваться для описания шаблонов аудио-визуального материала. На практике, семантический DS служит для инкапсуляции описания документальной области. DS объекта
описывает воспринимаемый или абстрактный объект. Воспринимаемый объект является сущностью, которая является реальностью, то есть, имеет временное и пространственное протяжение в описываемом мире (например, "Пианино Вани"). Абстрактный объект является результатом абстрагирования воспринимаемого объекта (например, "любое пианино"). Это абстрагирование генерирует шаблон объекта. DS AgentObject расширяет возможности DS объекта. Она описывает человека, организацию, группу людей, или персонализированные объекты (например, "говорящую чашку в анимационном кино").
DS события описывает воспринимаемое или абстрактное событие. Воспринимаемое событие является динамическим отношением, включающим один или более объектов, которые возникают во времени или пространстве описываемого мира (например, "Ваня играет на пианино"). Абстрактное событие является результатом абстрагирования воспринимаемых событий (например, "кто-то играет на пианино"). Эта абстракция позволяет сформировать шаблон события. DS концепции описывает семантическую сущность, которая не может быть описана, как обобщение или абстрагирование специфицированного объекта, события, временного интервала или состояния. Она представляет собой свойство или собрание свойств (например, “гармония” или “готовность”). Эта DS может относиться к среде непосредственно или к другой описываемой семантической сущности. DS SemanticState описывает один или более параметрических атрибута семантической сущности в данное время или в данной точке описываемого мира или в данной позиции среды (например, вес пианино равен 100 кг). Наконец, DS SemanticPlace и SemanticTime
характеризуют соответственно место и время в описываемом мире.
Как и в случае DS сегмента, концепция описания может быть представлена в виде дерева или графа. Структура графа определена набором узлов, представляющих семантические понятия, и набора ребер, специфицирующих отношения между узлами. Ребра описываются DS семантических отношений.
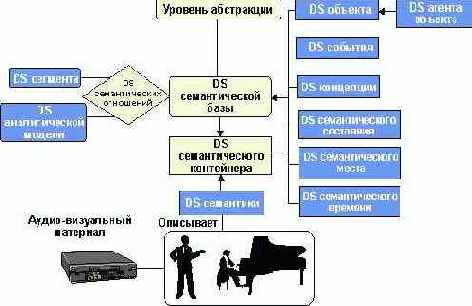
Пример иерархического
Рисунок 22. Пример иерархического резюме видео записи футбольного матча, имеющего многоуровневую иерархию. Иерархическое резюме предполагает достоверность (то есть, f0, f1, …) ключевых кадров с точки зрения видео сегмента следующего более низкого уровня.
На Рисунок 22 показан пример иерархического резюме видео записи футбольного матча. Описание иерархического резюме предоставляет три уровня детализации. Видео запись матча суммирована на одном корневом кадре. На следующем уровне иерархии предлагается три кадра, которые суммируют различные сегменты видеозаписи. Наконец, внизу рисунка показаны кадры нижнего уровня иерархии, отображающие детали, различных сцен сегментов предыдущего уровня.
3.5.4.2. Разделы и декомпозиции
Отображения разделов и декомпозиций описывает различные части аудио-визуального сигнала в пространстве, времени и по частоте. Отображения разделов описывает различные виды аудио-визуального материала, такие как отображения с низким разрешением, пространственных или временных сегментов, или частотных субдиапазонов. Вообще, DS отображения пространства и частоты специфицируют соответствующие разделы в пространственной и частотной плоскостях.
Отображение декомпозиций описывает различные представления аудио-визуального сигнала посредством механизмов графов. Декомпозиции специфицируют узловые элементы информационных структур, базирующихся на графе и соответствующие элементы отношений, которые соответствуют анализу и синтезу внутренних зависимостей отображений.
DS отображений
описывают различные пространственные и частотные отображения аудио-визуальных данных. Определены следующие DS отображения: DS SpaceView описывает пространственное отображение аудио-визуальных данных, например, пространственный сегмент изображения. DS FrequencyView описывает отображение в пределах заданного частотного диапазона, например, частотный субдиапазон звукового сопровождения. DS SpaceFrequencyView специфицирует многомерное отображение аудио-визуальных данных одновременно в пространстве и по частоте, например, частотный субдиапазон пространственного диапазона изображения.
DS ResolutionView специфицирует отображение с низким разрешением, такое как набросок изображения. Концептуально, отображение разрешения является частным случаем частотного отображения, которое соответствует низкочастотному субдиапазону данных. DS SpaceResolutionView
специфицирует отображение одновременно в пространстве и по разрешению, например, отображение изображения пространственного сегмента с низким разрешением.
DS декомпозиции проекции описывают различные пространственные и частотные декомпозиции и организацию отображения аудио-визуальных данных. Определены следующие DS декомпозиции проекций: DS ViewSet описывает набор проекций, который может иметь различные свойства полноты и избыточности, например, набор субдиапазонов, полученный при частотной декомпозиции аудио сигнала, образующего ViewSet. DS SpaceTree описывает дерево декомпозиции данных, например, пространственная декомпозиция квадрантов изображения. DS FrequencyTree
описывает частотную декомпозицию данных, например, волновую декомпозицию изображения DS. SpaceFrequencyGraph описывает декомпозицию данных одновременно в пространстве и по частоте. Здесь отображение использует частотный и пространственный графы. Граф видео отображения специфицирует декомпозицию видео данных в пространстве координата-время-частота, например, декомпозиция видео 3-D-субдиапазона. Наконец, MultiResolutionPyramid специфицирует иерархию проекций аудио-визуальных данных, например, пирамиду изображений с разным разрешением.
На Рисунок 23 приведен пример пространственно-частотного графа декомпозиции изображения. Структура пространственного и частотного графа включает элементы узлов, которые соответствуют различным пространственным и частотным проекциям изображения, состоящего из пространственных проекций (пространственные сегменты), частотных (частотные субдиапазоны), и пространственно-частотных (частотные субдиапазоны пространственных сегментов). Структура пространственного и частотного графа включает также элементы переходов, которые содержат анализ и синтез зависимостей между проекциями.Например, на Рисунок 23, “S” переходы указывают на пространственную декомпозицию, в то время как “F” переходы отмечают частотную или субдиапазонную декомпозицию.
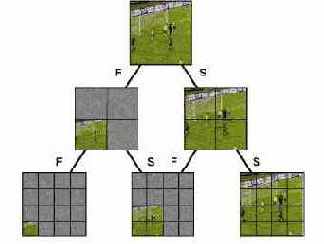
Пример концептуальных аспектов описания
Рисунок 21. Пример концептуальных аспектов описания.
3.5.4. Навигация и доступ
MPEG-7 предоставляет DS, которые облегчают навигацию и доступ к аудио-визуальному материалу путем спецификации резюме, обзоров, разделов и вариаций медиа-данных. DS резюме предоставляет аннотации аудио-визуального материала для того, чтобы обеспечить эффективный просмотр и навигацию в аудио-визуальных данных. Пространственно-частотная проекция дает возможность рассматривать аудио-визуальные данные в пространственно-частотной плоскости. DS вариации специфицируют отношения между различными вариантами аудио-визуального материала, которые позволяют адаптивный выбор различных копий материала при различных условиях доставки и для разных терминалов.
3.5.4.1. Резюме
Аудио-визуальные резюме предоставляют компактные аннотации аудио-визуального материала для облегчения обнаружения, просмотра, навигации, визуализации и озвучивания этого материала. DS резюме
позволяет осуществлять навигацию в рамках аудио-визуального материала иерархическим или последовательным образом. Иерархическая декомпозиция резюме организует материал послойно, так что он на различных уровнях выдает различную детализацию (от грубой до подробной). Последовательные резюме предоставляет последовательности изображений или видео кадров, возможно синхронизованные с аудио и текстом, которые формируют слайд-демонстрации или аудио-визуальные наброски.
HierarchicalSummary
организует резюме нескольких уровней, которые описывают аудио-визуальный материал с разной детализацией. Элементы иерархии специфицируются DS HighlightSummary
и HighlightSegment. Иерархия имеет форму дерева, так как каждый элемент в иерархии кроме корневого имеет прародителя. Элементы иерархии могут опционно иметь дочерние элементы.
HierarchicalSummary сконструирован на основе базового представления временных сегментов AВ-данных, описанных HighlightSegments. Каждый HighlightSegment содержит указатели на AВ-материал, чтобы обеспечить доступ к ассоциированным ключевым видео- и аудио-клипам, к ключевым кадрам и ключевым звуковым составляющим, он может также содержать текстовую аннотацию, относящуюся к ключевым темам. Эти AВ-сегменты группируются в резюме, или рубрики, посредством схемы описания HighlightSummary.
специфицирует резюме, состоящее из последовательности изображений или видео кадров, возможно синхронизованных со звуком или текстом. SequentialSummary может также содержать последовательность аудио-фрагментов. Аудио-визуальный материал, который образует SequentialSummary, может быть записан отдельно от исходного материала, чтобы позволить быструю навигацию и поиск. В качестве альтернативы, последовательные резюме могут связываться непосредственно с исходным аудио-визуальным материалом для того, чтобы ослабить требования к памяти.

Пример приложения реального
Рисунок 30. Пример приложения реального мира, извлекающего два разных описания (XM-Appl1, XM-Appl2). Основываясь на первом описании выбран адекватный набор материала (XM-Appl3), который затем транскодирован с использованием второго описания (XM-Appl4). (MDB = медийная база данных, DDB = база данных описаний).
Ссылки
Имеется большое число документов на базовой странице MPEG http://drogo.cselt.it/mpeg/, включая:
Введение в MPEG-7
ТребованияMPEG-7
ПриложенияMPEG-7
КонцепцияMPEG-7
Документы MPEG-7 CD, WD и XM: системы, DDL, видео, аудио и MMDS.
Информацию, имеющую отношение к промышленной сфере, можно найти на Web-сервере MPEG-7 http://www.mpeg-7.com
(Industry Focus Group).
Приложение А. Словарь и сокращения
|
CD |
Committee Draft - проект комитета |
|
CE |
Cилиe Experiment - центральный эксперимент |
|
CS |
Coding Scheme - схема кодирования |
|
D |
Дескриптор |
|
DDL |
Data Description Language - Язык описания данных |
|
DS |
Description Scheme - Схема описания |
|
FCD |
Final Committee Draft - окончательный проект комитета |
|
FDIS |
Final Draft of International Standard - окончательный проект международного стандарта |
|
IS |
International Standard - Международный стандарт |
|
MMDS |
Multimedia Description Schemes - Схемы описания мультимедиа |
|
MPEG |
Moving Pictures Experts Group - Группа экспертов по движущимся изображениям |
|
WD |
Working Draft - рабочий проект |
|
XM |
eXperimentation Model - модель экспериментирования |
Пример реверсивного кода переменной длины
Рисунок 13. Пример реверсивного кода переменной длины
Пример видео-сегмента и областей для графа, представленного на Рисунок
Рисунок 18. Пример видео-сегмента и областей для графа, представленного на Рисунок 19.
Этот пример демонстрирует момент футбольного матча. Определены два видео-сегмента, одна стационарная область и три движущиеся области. Граф, описывающий структуру материала, показан на Рисунок 19. Видео-сегмент: Обводка & удар включает в себя мяч, вратаря
и игрока. Мяч остается рядом с игроком, движущимся
к вратарю. Игрок появляется справа от вратаря
Видео-сегмент гол включает в себя те же подвижные области плюс стационарную область ворота. В этой части последовательности, игрок
находится слева от вратаря, а мяч движется к воротам. Этот очень простой пример иллюстрирует гибкость данного вида представления. Заметим, что это описание в основном представляется структурным, так как отношения, специфицированные ребрами графа, являются чисто физическими, а узлы, представляющие сегменты, которые являются объектами, определяемыми данными создания, информацией использования и медиа-данными, а также дескрипторами низкого уровня, такими как цвет, форма, движение. В семантически явном виде доступна только информация из текстовой аннотации (где могут быть специфицированы ключевые слова мяч, игрок или вратарь).

Ниже приведены примеры заголовок сообщений,
8. Примеры
Ниже приведены примеры заголовок сообщений, содержащих 'кодировочные слова':
From: =?US-ASCII?Q?Keith_Moore?=
To: =?ISO-8859-1?Q?Keld_J=F8rn_Simonsen?=
CC: =?ISO-8859-1?Q?Andr=E9?= Pirard
Subject: =?ISO-8859-1?B?SWYgeW91IGNhbiByZWFkIHRoaXMgeW8=?=
=?ISO-8859-2?B?dSB1bmRlcnN0YW5kIHRoZSBleGFtcGxlLg==?=
В выше приведенном примере в 'кодировочном слове' поля, последний символ "=" в конце кодированного текста необходим, так как каждое 'кодировочное слово' должно быть самодостаточным (символ "=" завершает группу из 4 символов base64 представляющих 2 октета). Дополнительный октет может быть закодирован в первом 'кодировочном слове' (так чтобы 'кодировочное слово' содержало число октетов кратное трем). Второе 'кодировочное слово' использует символьный набор, не совпадающий с тем, что применен в первом слове.
From: =?ISO-8859-1?Q?Olle_J=E4rnefors?=
To: ietf-822@dimacs.rutgers.edu, ojarnef@admin.kth.se
>Subject: Time for ISO 10646?
To: Dave Crocker
Cc: ietf-822@dimacs.rutgers.edu, paf@comsol.se
From: =?ISO-8859-1?Q?Patrik_F=E4ltstr=F6m?=
Subject: Re: RFC-HDR care and feeding
From: Nathaniel Borenstein
(=?iso-8859-8?b?7eXs+SDv4SDp7Oj08A==?=)
To: Greg Vaudreuil , Ned Freed
, Keith Moore
Subject: Test of new header generator
MIME-Version: 1.0
Content-type: text/plain; charset=ISO-8859-1
Правила несколько отличаются для полей, определенных как '*text' так как "(" и ")" не распознаются в качестве разделителей комментария. [Секция 5, параграф (1)].
В каждом из следующих примеров, если бы одна и та же последовательность встретилась в поле '*text', форма "Отображается как" не рассматривалась бы как кодировочные слова, а была бы идентична форме "Кодированное представление". Это происходит, потому что каждое из 'кодировочных слов' в ниже приведенных примерах соседствуют с символами "(" или ")".
| Кодированное представление | Отображается как |
| (=?ISO-8859-1?Q?a?=) | (a) |
| (=?ISO-8859-1?Q?a?= b) | (a b) |
В пределах 'комментария', HT или SP должны появляться между 'кодировочным словом' и окружающим текстом. [Секция 5, параграф (2)]. Однако HT или SP не нужны между начальным символом "(", который открывает 'комментарий', и 'кодировочным словом'.
| (=?ISO-8859-1?Q?a?= =?ISO-8859-1?Q?b?=) | (ab) |
HT или SP между смежными 'кодировочными словами' не отображаются.
| (=?ISO-8859-1?Q?a?= =?ISO-8859-1?Q?b?=) | (ab) |
Даже кратные пробелы между 'кодировочными словами' игнорируются.
|
(=?ISO-8859-1?Q?a?= =?ISO-8859-1?Q?b?=) |
(ab) |
Любое число LWS между 'кодировочными словами', даже если там содержится CRLF, за которым следует один или более пробелов, игнорируется.
| (=?ISO-8859-1?Q?a_b?=) | (a b) |
Для того чтобы пробел был отображен в пределах кодированного текста, SP должен быть закодирован в качестве части 'кодировочного слова'.
| (=?ISO-8859-1?Q?a?= =?ISO-8859-2?Q?_b?=) | (a b) |
Для того чтобы пробел был отображен между двумя строками кодированного текста, SP может быть закодирован как составная часть одного из 'кодировочных слов'.
Примеры описания изображения с стационарными областями
Рисунок 17. Примеры описания изображения с стационарными областями
Описание структуры материала может выходить за рамки иерархического дерева. Хотя, иерархические структуры, такие как деревья, удобны при организации доступа, поиска и масштабируемого описания, они подразумевают ограничения, которые делают их неприемлемыми для некоторых приложений. В таких случаях DS графа сегмента не используется. Структура графа определяется набором узлов, представляющих сегменты, и набора ребер, определяющих отношения между узлами. Чтобы проиллюстрировать использование графов, рассмотрим пример, представленный на Рисунок 18.

Примеры различной формы
Рисунок 9. Примеры различной формы
Заметим, что черный пиксель в пределах объекта соответствует 1 на изображении, в то время как пиксели белого фона соответствуют 0.
Дескриптор характеризуется малым размером и быстрым временем поиска. Размер данных для представления является фиксированным и равным 17.5 байт.
3.4.4.2. Форма, основанная на контуре
Дескриптор формы, базирующейся на контуре, получает параметры формы объекта или его контур, извлеченный из описания областей. Он использует так называемое Curvature Scale-Space представление, которое воспринимает значимые параметры формы.
Дескриптор формы, базирующейся на контуре объекта, использует Curvature Scale Space представление контура. Это представление имеет несколько важных особенностей, в частности:
Оно извлекает очень хорошие характеристики формы, делая возможным поиск, основанный на сходстве.
Оно отражает свойства восприятия визуальной системы человека и предлагает хорошее обобщение.
Оно устойчиво при плавном движении.
Оно устойчиво при частичном перекрытии формы.
Оно устойчиво по отношению преобразованиям перспективы, которые являются следствием изменения параметров видеокамеры, и представляются общими для изображений и видео.
Оно компактно
Некоторые из выше перечисленных свойств проиллюстрированы на Рисунок 10, каждый кадр содержит весьма сходные с точки зрения CSS изображения, основанные на результате действительного поиска в базе данных MPEG-7.

Примеры разложения сегмента
Рисунок 15. Примеры разложения сегмента на компоненты: a) и b) Декомпозиции сегмента без зазоров и перекрытий; c) и d) Декомпозиции сегмента с зазорами и перекрытиями
Сегмент может также разделен на составные части по медиа-источникам, таким как различным звуковым дорожкам или разным позициям видеокамер. Иерархическая декомпозиция полезна при формировании эффективных стратегий поиска (от глобального до локального). Она также позволяет описанию быть масштабируемым: сегмент может быть описан непосредственно с помощью его набора дескрипторов и DS, а может быть также описан набором дескрипторов и DS, которые относятся к его субсегментам. Заметим, что сегмент может быть разделен на субсегменты различного типа, например, видео сегмент может быть разложен движущиеся области, которые в свою очередь разлагаются на статические области.
Так как это выполняется в пространственно-временном пространстве, декомпозиция должна описываться набором атрибутов, определяющих тип разложения: временное, пространственное или пространственно-временное. Более того, пространственная и временная подсекции могут располагаться с зазором или с перекрытием. Несколько примеров декомпозиций для временных сегментов описано на Рисунок 15.
Примеры сегментов: a)
Рисунок 16. Примеры сегментов: a) и b) сегменты состоят из одного связного компонента; c) и d) сегменты состоят из трех связанных компонентов
- Процесс верификации
Рисунок 6 - Процесс верификации
Кроме элементов описанных в разделе 3.1.2.1, процесс валидации включает определение канонического представления описания материала. В каноническом пространстве, описания материала могут быть сравнены. Процесс валидации работает следующим образом:
Описание материала преобразуется в текстуальный и двоичный форматы без потерь, генерируя два разных представления одного и того же материала.
Два кодированных описания декодируются соответствующими двоичным и текстовым декодерами.
Из реконструированных описаний материала генерируются два канонических описания.
Два канонических описания должны быть эквивалентны.
Описание канонической презентации XML-документа определено в Canonical XML[3].
3.2. Язык описания определений MPEG-7 (DDL)
Главными средствами, используемыми в описаниях MPEG-7 являются DDL (Description Definition Language), схемы описаний (DS) и дескрипторы (D). Дескрипторы связывают характеристики с набором их значений. Схемы описания являются моделями мультимедийных объектов и всего многообразия элементов, которые они представляют, например, модели данных описания. Они специфицируют типы дескрипторов, которые могут быть использованы в данном описании, и взаимоотношения между этими дескрипторами или между данными схемами описания.
DDL образует центральную часть стандарта MPEG-7. Он обеспечивает надежную описательную основу, с помощью которой пользователь может создать свои собственные схемы описания и дескрипторы. DDL определяет семантические правила выражения и комбинации схем описания и дескрипторов.
DDL не является языком моделирования, таким как UML (Unified Modeling Language), а языком схем для представления результатов моделирования аудио-визуальных данных, например, DS и D.
DDL должен удовлетворять требованиям MPEG-7 DDL. Он должен быть способен выражать пространственные, временные, структурные и концептуальные взаимоотношения между элементами DS и между DS. Он должен предоставить универсальную модель для связей и ссылок между одним или более описаниями и данными, которые им описываются.
Кроме того, язык не должен зависеть от платформы и приложения и быть читаемым как машиной, так и человеком. MPEG-7 должен базироваться на синтаксисе XML. Необходима также система разборки DDL (парсинга), которая должна быть способна проверять схемы описания (материал и структуру) и дескрипторы типа данных, как примитивные (целые, текст, дата, время) так и составные (гистограммы, нумерованные типы).
3.2.1. Разработка контекста
Так как схемный язык XML не был специально разработан для аудио-визуального материала, необходимы определенные расширения, для того чтобы удовлетворить всем требованиям MPEG-7 DDL.
3.2.2. Обзор схемы XML
Целью схемы является определение класса XML-документов путем использования конкретных конструкций, чтобы наложить определенные ограничения на их структуру: элементы и их содержимое, атрибуты и их значения, количество элементов и типы данных. Схемы можно рассматривать, как некоторые дополнительные ограничения на DTD.
Главной рекомендацией MPEG-7 AHG было использование схемы, базирующейся на XML. В начале разработки имелось много решений, но ни одно из них не оказалось достаточно стабильным. В исходный момент группа DDL решила разработать свой собственный язык, следуя принципам, используемым группой W3C при подготовке схемы XML. В апреле 2000, рабочая группа W3C XML опубликовала последнюю версию спецификации схемы XML 1.0. Улучшенная стабильность схемного языка XML, его потенциально широкое поле применения, доступность средств и программ разборки, а также его способность удовлетворить большинству требований MPEG-7, привели к тому, что схема XML явилась основой DDL. Однако так как схема XML не была разработана специально для аудио-визуального материала, необходимы некоторые специфические расширения. DDL делится на следующие логические нормативные компоненты:
Схемные структурные компонентыXML;
Схемные компоненты типа данных XML;
Расширениядля XML схемы MPEG-7.
3.2.3. Схема XML: Структуры
Схема XML: Структуры являются частью 2-частной спецификации XML-схемы.
Она предоставляет средства для описания структуры и ограничений, налагаемых на материалы документов XML 1.0. Схема XML состоит из набора компонентов структурной схемы, которые могут быть разделены на три группы. Первичными компонентами являются:
Схема - внешний уровень определений и деклараций;
Определения простых типов;
Определения составных типов;
Декларации атрибутов;
Декларации элементов.
Вторичными компонентами являются:
Определения группы атрибутов;
Определения ограничений идентичности;
Определения группы;
Декларации нотации.
Третья группа образована компонентами “helper”, которые входят в другие компоненты и не могут существовать отдельно:
Аннотации;
Фрагменты (Particles);
Произвольные подстановки (Wildcards).
Определения типа задают внутренние компоненты схемы, которые могут использоваться в других компонентах, таких как элементы, атрибуты деклараций или другие определения типа. Схема XML предоставляет два вида компонентов определения типа:
простые типы - являющиеся простыми типами данных (встроенными или вторичными), которые не могут иметь каких-либо дочерних элементов или атрибутов;
составные типы - которые могут нести в себе атрибуты и иметь дочерние элементы, или быть получены из других простых или составных типов.
Новые типы могут быть также определены на основе существующих типов (встроенных или вторичных) путем расширения базового типа. Детали использования этих компонентов можно найти в проекте DDL или в схеме XML: Спецификация структур.
3.2.4. Схема XML: Типы данных
XML Schema:Datatypes является второй частью 2-частной схемной спецификации XML. Она предлагает возможности определения типов данных, которые могут быть использованы для ограничения свойств типов данных элементов и атрибутов в рамках схем XML. Она предлагает более высокую степень проверки типа, чем доступна для XML 1.0 DTD:
набор встроенных примитивных типов данных;
набор встроенных вторичных типов данных;
механизмы, с помощью которых пользователи могут определить свой собственный вторичный тип данных.
Подробные детали встроенных типов данных и механизмы получения вторичных типов можно найти в окончательном проекте DDL или в спецификации XML Schema:Datatypes.
3.2.5. Расширения схемы XML MPEG-7
Следующие характеристики будет нужно добавить к спецификации языка XML для того, чтобы удовлетворить специфическим требованиям MPEG-7:
Массив и матрица типов - как фиксированного, так и параметризованного размеров;
Встроенные примитивные временные типы данных: basicTimePoint и basicDuration.
Программы разборки, специфические для MPEG-7 будут разработаны путем добавления валидации этих дополнительных конструкций к стандартным схемным разборщикам XML.
3.3. Аудио MPEG-7
Аудио MPEG-7 FCD включает в себя пять технологий: структура аудио описания (которая включает в себя масштабируемые последовательности, дескрипторы нижнего уровня и униформные сегменты тишины), средства описания тембра музыкального инструмента, средства распознавания звука, средства описания голосового материала и средства описания мелодии.
3.3.1. Описание системы аудио MPEG-7
Аудио структура содержит средства нижнего уровня, созданные для обеспечения основы для формирования аудио приложений высокого уровня. Предоставляя общую платформу структуры описаний, MPEG-7 Аудио устанавливает базис для совместимости всех приложений, которые могут быть созданы в рамках данной системы.
Существует два способа описания аудио характеристик нижнего уровня. Один предполагает стробирование уровня сигнала на регулярной основе, другой может использовать сегменты (смотри описание MDS) для пометки сходных и отличных областей для заданного звукового отрывка. Обе эти возможности реализованы в двух типах дескрипторов нижнего уровня (один для скалярных величин, таких как мощность или частота, и один для векторов, таких как спектры), которые создают совместимый интерфейс. Любой дескриптор, воспринимающий эти типы может быть проиллюстрирован примерами, описывающими сегмент одной результирующей величиной или последовательностью результатов стробирования, как этого требует приложение.
Величины, полученные в результате стробирования, сами могут подвергаться последующей обработке с привлечением другого унифицированного интерфейса: они могут образовать масштабируемые ряды (Scalable Series). Дерево шкал может также хранить различные сводные значения, такие как минимальное, максимальное значение дескриптора и его дисперсию.
Аудио дескрипторы нижнего уровня имеют особую важность при описании звука. Существует семнадцать временных и пространственных дескрипторов, которые могут использоваться в самых разных приложениях. Они могут быть грубо поделены на следующие группы:
Базовая: мгновенные значения уровня волнового сигнала и мощности.
Базовая спектральная: частотный спектр мощностей, спектральные характеристики, включая среднее значение, спектральная полоса и спектральная однородность.
Параметры сигнала: фундаментальная частота квазипериодических сигналов и гармоничность сигналов.
Временная группа по тембру: временной центроид
Спектральная группа по тембру: специфические спектральные характеристики в линейном пространстве частот, включая спектральный центроид и спектральные свойства, специфические для гармонической частей сигналов, включая спектральное смещение и спектральную ширину.
Представления спектрального базиса: характеристики, используемые первично для распознавания звука.
Каждый из них может использоваться для описания сегмента с результирующим значением, которое применяется для всего сегмента или для последовательности результатов стробирования. Временная группа по тембру (Timbral Temporal) является исключением, так как ее значения приложимы только к сегменту, как целому.
В то время как аудио дескрипторы нижнего уровня вообще могут служить для многих возможных приложений, дескриптор однородности спектра поддерживает аппроксимацию сложных звуковых сигналов. Приложения включают в себя голосовую идентификацию.
Кроме того, очень простым, но полезным средством является дескриптор тишины. Он использует простую семантику "тишины" (то есть отсутствие значимого звука) для аудио сегмента.
Такой дескриптор может служить для целей дальнейшей сегментации аудио потока.
3.3.2. Средства описания аудио верхнего уровня (D и DS)
Четыре набора средств описания аудио, которые приблизительно представляют области приложения, интегрированы в FCD: распознавание звука, тембр музыкального инструмента, разговорный материал и мелодическая линия.
3.3.2.1. Средства описания тембра музыкальных инструментов
Дескрипторы тембра служат для описания характеристик восприятия звуков. Тембр в настоящее время определен в литературе как характеристика восприятия, которая заставляет два звука, имеющих одну высоту и громкость, восприниматься по-разному. Целью средства описания тембра является представление этих характеристик восприятия сокращенным набором дескрипторов. Дескрипторы относятся к таким понятиям как “атака”, “яркость” или “богатство” звука.
В рамках четырех возможных классов звуков музыкальных инструментов, два класса хорошо детализированы, и являются центральным объектом экспериментального исследования. В FCD представляются гармонические, когерентные непрерывные звуки и прерывистые, ударные звуки. Дескриптор тембра для непрерывных гармонических звуков объединяет спектральные дескрипторы тембра с временным дескриптором log attack. Дескриптор ударных инструментов комбинирует временные дескрипторы тембра с дескриптором спектрального центроида. Сравнение описаний, использующих один из наборов дескрипторов выполняется с привлечением метрики масштабируемого расстояния.
3.3.2.2. Средства распознавания звука
Схемы дескрипторов и описаний распознавания звука, представляют собой наборы средств для индексирования и категорирования звуков, с немедленным использованием для звуковых эффектов. Добавлена также поддержка автоматической идентификации звука и индексация. Это сделано для систематики звуковых классов и средств для спецификации онтологии устройств распознавания звука. Такие устройства могут использоваться для автоматической индексации сегментов звуковых треков.
Средства распознавания используют в качестве основы спектральные базисные дескрипторы низкого уровня.
Эти базисные функции далее сегментируются и преобразуются в последовательность состояний, которые заключают в себя статистическую модель, такую как смешанная модель Маркова или Гаусса. Эта модель может зависеть от своего собственного представления, иметь метку, ассоциированную с семантикой исходного звука, и/или с другими моделями для того, чтобы категоризовать новые входные звуковые сигналы для системы распознавания.
3.3.2.3. Средства описания содержимого сказанного
Средства описания Spoken Content
позволяет детальное описание произнесенных слов в пределах аудио-потока. Учитывая тот факт, что сегодняшнее автоматическое распознавание речи ASR-технологий (Automatic Speech Recognition) имеет свои ограничения, и что всегда можно столкнуться с высказыванием, которого нет в словаре, средства описания Spoken Content жертвует некоторой компактностью ради надежности поиска. Чтобы этого добиться, средства отображают выходной поток и то, что в норме может быть видно в качестве текущего результата автоматического распознавания речи ASR. Средства могут использоваться для двух широких классов сценария поиска: индексирование и выделение аудио потока, а также индексирование мультимедийных объектов аннотированных голосом.
Средства описания Spoken Content поделены на два широких функциональных блока: сетка, которая представляет декодирование, выполненное системой ASR, и заголовок, который содержит информацию об узнанных собеседниках и о самой системе распознавания. Сетка состоит из комбинаций слов голосовых записей для каждого собеседника в аудио потоке. Комбинируя эти сетки, можно облегчить проблему со словами, отсутствующими в словаре, и поиск может быть успешным, даже когда распознавание исходного слова невозможно.
3.3.2.4. Средства описания мелодии
DS мелодического очертания (Melody Contour) является компактным представлением информации о мелодии, которая позволяет эффективно и надежно контролировать мелодическую идентичность, например, в запросах с помощью наигрывания. DS мелодического очертания использует 5-ступенчатый контур (представляющий интервал между смежными нотами), в котором интервалы дискретизированы.
DS мелодического очертания ( Melody Contour DS) предоставляет также базовую информацию ритмики путем запоминания частот, ближайших к каждой из нот, это может существенно увеличить точность проверки соответствия запросу.
Для приложений, требующих большей описательной точности или реконструкции заданной мелодии, DS мелодии
поддерживает расширенный набор дескрипторов и высокую точность кодирования интервалов. Вместо привязки к одному из пяти уровней в точных измерителях используется существенно больше уровней между нотами (100 и более). Точная информация о ритмике получается путем кодирования логарифмического отношения разностей между началами нот способом аналогичным с используемым для кодирования уровней сигнала.
3.4. Визуальный MPEG-7
Средства визуального описания MPEG-7, включенные в CD/XM состоят из базовых структур и дескрипторов, которые охватывают следующие основные визуальные характеристики:
Цвет
Текстура
Форма
Движение
Локализация
Прочее
Каждая категория состоит из элементарных и составных дескрипторов.
3.4.1. Базовые структуры
Существует пять визуально связанных базовых структур: сеточная выкладка, временные ряды (Time Series), многопрекционность (MultiView), пространственные 2D-координаты и временная интерполяция (TemporalInterpolation).
3.4.1.1. Сеточная выкладка
Сетка делит изображение на равные прямоугольные области, так что каждая область может быть описана отдельно. Каждая область сетки описывается посредством других дескрипторов, таких как цвет или текстура. Более того, дескриптор позволяет ассоциировать субдескрипторы со всей прямоугольной областью, или с произвольным набором прямоугольных областей.
3.4.1.2. Многовидовые 2D-3D
Дескриптор 2D/3D специфицирует структуру, которая комбинирует 2D дескрипторы, представляющие визуальные параметры 3D-объекта, видимые с различных точек. Дескриптор образует полное 3D-представление объекта на основе его проекций. Может использоваться любой визуальный 2D-дескриптор, такой как, например, форма контура, форма области, цвет или текстура.
Дескриптор 2D/3D поддерживает интеграцию 2D-дескрипторов, используемых в плоскости изображения для описания характеристик 3D-объектов (реальный мир). Дескриптор позволяет осуществлять сравнение 3D-объектов путем сравнения их проекций.
3.4.1.3. Временные ряды
Этот дескриптор определяет в видео сегменте дескрипторы временных рядов и предоставляет возможность сравнения изображения с видео-кадром и видео-кадров друг с другом. Доступно два типа временных рядов (TimeSeries): RegularTimeSeries и IrregularTimeSeries. В первом, дескрипторы размещаются регулярным образом (с постоянным шагом) в пределах заданного временного интервала. Это допускает простое представление для приложений, которые предполагают ограниченную сложность. Во втором, дескрипторы размещаются нерегулярно (с переменными интервалами) в пределах заданного временного интервала. Это обеспечивает эффективное представление для приложений, которые требуют малой полосы пропускания или малой емкости памяти. Они полезны в частности для построения дескрипторов, которые содержат временные ряды дескрипторов.
3.4.1.4. Пространственные координаты 2D
Это описание определяет 2D пространственную координатную систему, которую следует использовать в других D/DS, где это важно. Оно поддерживает два вида координатных систем: “локальную” и “интегрированную” (Рисунок 7). В “локальной” координатной системе, все изображения привязаны к одной точке. В “интегрированной” координатной системе, каждое изображение (кадр) может быть привязано к разным областям. Интегрированная координатная система может использоваться для представления координат на мозаичном видео снимке.
a) "Локальные" координаты b) "интегрированные" координаты
Продвинутый формат BIFS
8.5.1. Продвинутый формат BIFS
BIFS версия 2 (продвинутый BIFS) включает в себя следующие новые возможности:
Моделирование продвинутой звуковой среды в интерактивных виртуальных сценах, где в реальном времени вычисляются такие характеристики как рефлексы в комнате, реверберация, допплеровсеие эффекты и перегораживание звука объектами, появляющимися между источником и слушателем. Моделирование направленности источника звука позволяет осуществлять эффективное включение звуковых источников в 3-D сцены.
Анимация тела с использованием на уровне декодера модели тела по умолчанию или загружаемой модели. Анимация тела осуществляется путем посылки анимационных параметров в общем потоке данных.
Применение хроматических ключей, которые служат для формирования формы маски и значения прозрачности для изображения или видео последовательности.
Включение иерархических 3-D сеток в BIFS сцен.
Установление соответствия интерактивных команд и медийных узлов. Команды передаются серверу через обратный канал для соответстующей обработки.
PROTOs и EXTERNPROTOs >
Профайл дескриптора объекта
5.6. Профайл дескриптора объекта
Профайл описания объекта включает в себя следующие средства:
Средство описания объекта (OD)
Средство слоя Sync (SL)
Средство информационного содержимого объекта (OCI)
Средство управления и защиты интеллектуальной собственности (IPMP)
В настоящее время определен только один профайл, который включает все эти средства. В контексте слоев для этого профайла могут быть определены некоторые ограничения, например, допуск только одной временной шкалы.
Профайлы графики
5.3. Профайлы графики
Профайлы графики определяют, какие графические и текстовые элементы могут использоваться в данной сцене. Эти профайлы определены в системной части стандарта:
Простой 2-D графический профайл предоставляется только для графических элементов средства BIFS, которым необходимо разместить один или более визуальных объектов в сцене.
Полный 2-D графический профайл предоставляет двухмерные графические функции и supports такие возможности как произвольная двухмерная графика и текст, если требуется, в сочетании с визуальными объектами.
3. Полный графический профайл предоставляет продвинутые графические элементы, такие как сетки и экструзии и позволяет формировать содержимое со сложным освещением. Полный графический профайл делает возможными такие приложения, как сложные виртуальные миры, которые выглядят достаточно реально.
3D аудио графический профайл имеет противоречивое на первый взгляд название, в действительности это не так. Этот профайл не предлагает визуального рэндеринга, а предоставляет графические средства для определения акустических свойств сцены (геометрия, акустическое поглощение, диффузия, прозрачность материала). Этот профайл используется для приложений, которые осуществляют пространственное представление аудио сигналов в среде сцены.
Профайлы MPEG-J
5.5. Профайлы MPEG-J
Существуют два профайла MPEG-J: персональный и главный:
1. Персональный – небольшой пакет для персональных приборов.
Персональный профайл обращается к ряду приборов, включая мобильные и портативные аппараты. Примерами таких приборов могут быть видео микрофоны, PDA, персональные игровые устройства. Этот профайл включает в себя следующие пакеты MPEG-J API:
a) Сеть
b) Сцена
c) Ресурс
1. Главный – включает все MPEG-J API.
Главный профайл обращается к ряду приборов, включая средства развлечения. Примерами таких приборов могут служить набор динамиков, компьютерные системы мультимедиа и т.д. Он является супер набором персонального профайла. Помимо пакетов персонального профайла, этот профайл содержит следующие пакеты MPEG-J API:
a) Декодер
b) Функции декодера
c) Секционный фильтр и сервисная информация
и богатый набор средств для
5. Профайлы в MPEG-4
MPEG-4 предоставляет большой и богатый набор средств для кодирования аудио-визуальных объектов. Для того чтобы позволить эффективную реализацию стандарта, специфицированы субнаборы систем MPEG-4, средств видео и аудио, которые могут использоваться для специфических приложений. Эти субнаборы, называемые ‘профайлами’, ограничивают набор средств, которые может применить декодер. Для каждого из этих профайлов, устанавливается один или более уровней, ограничивающих вычислительную сложность. Подход сходен с MPEG-2, где большинство общеизвестных комбинаций профайл/уровень имеют вид ‘главный_профайл @главный_уровень’. Комбинация профайл@уровень позволяет:
• конфигуратору кодека реализовать только необходимый ему субнабор стандарта,
• проверку того, согласуются ли приборы MPEG-4 со стандартом.
Существуют профайлы для различных типов медиа содержимого (аудио, видео, и графика) и для описания сцен. MPEG не предписывает или рекомендует комбинации этих профайлов, но заботится о том, чтобы обеспечить хорошее согласование между различными областями.
является бесприбыльной организацией, имеющей
7. Промышленный форум MPEG-4
Промышленный форум MPEG- 4 является бесприбыльной организацией, имеющей следующую цель: дальнейшее принятие стандарта MPEG-4, путем установления MPEG-4 в качестве принятого и широко используемого стандарта среди разработчиков приложений, сервис провайдеров, создателей материалов и конечных пользователей. Далее следует не исчерпывающая выдержка из устава M4IF о планах работы:
Целью M4IF будет: продвижение MPEG-4, предоставление информации об MPEG-4, предоставление средств MPEG-4 или указание мест, где эти данные можно получить, формирование единого представления об MPEG-4.
Цели реализуются через открытое международное сотрудничество всех заинтересованных участников.
Деятельность M4IF не преследует целей получения финансовой прибыли.
Любая корпорация и частная фирма, государственный орган или интернациональная организация, поддерживающая цели M4IF может являться членом форума.
Члены не обязаны внедрять или использовать специфические технологические стандарты или рекомендации в качестве следствия своего членства в M4IF.
Не существует каких-либо лицензионных требований, налагаемых членством в M4IF, и M4IF не налагает лицензионных ограничений на использование технологии MPEG-4.
Начальный членский взнос равен 2,000 $ в год.
M4IF имеет свою WEB-страницу: http://www.m4if.org
Деятельность M4IF начинается там, где кончается активность MPEG. Сюда входят позиции, с которыми MPEG не может иметь дело, например, из-за правил ISO, таких как патентная чистота.
Пространственно-частотный
Рисунок 23. Пространственно-частотный граф разлагает изображение или аудио-сигналы в пространстве место-время-частота. Декомпозиция изображений, использующая пространственно-частотный граф, делает возможным эффективный доступ и поиск материала при самом разном разрешении
3.5.4.3. Вариации содержимого
Вариации предоставляют информацию о различных изменениях аудио-визуального материала, такого как резюме, архивированные или версии с малым разрешением, а также версии на различных языках - звук, видео, изображение, текст и т.д.. Одной из главных функций DS вариаций является разрешение серверу, прокси или терминалу выбрать наиболее удобную вариацию аудио-визуального материала, которая может заместить оригинал, если необходимо, адаптировать различные возможности терминального оборудования, сетевых условий или предпочтений пользователя. DS вариаций используется для спецификации различных вариаций аудио-визуальных данных. Вариации могут возникать самыми разными способами, или отражать изменения исходных данных. Значение достоверности вариации определяет ее качество по сравнению с оригиналом. Атрибут типа вариации указывает на характер изменений: резюме, аннотация, язык перевода, уменьшение насыщенности цвета, снижение разрешения, сокращение частоты кадров, архивирование и т.д..
3.5.5. Организация содержимого
MPEG-7 предоставляет DS для организации и моделирования коллекций аудио-визуального материала, сегментов, событий, и/или объектов, и описания их общих свойств. Коллекции могут быть далее описаны, используя различные модели и статистики для того, чтобы характеризовать атрибуты элементов коллекции.
3.5.5.1. Собрания (Collections)
DS структуры коллекции описывает коллекции аудио-визуального материала или отрывков такого материала, например, временные сегменты видео. DS структуры коллекции
группирует аудио-визуальный материал, сегменты, события, или объекты кластеры коллекций и специфицирует свойства, которые являются общими для всех элементов. DS CollectionStructure описывает также статистику и модели значений атрибутов этих элементов, такие как усредненная гистограмма цвета для коллекции изображений. DS CollectionStructure также описывает отношения между кластерами коллекций.
На Рисунок 24 показана концептуальная организация коллекций в DS CollectionStructure. В этом примере, каждая коллекция состоит из набора изображений с общими свойствами, например, каждая отображает сходные события в футбольном матче. Внутри каждой коллекции, могут быть специфицированы отношения между изображениями, такие как степень сходства изображений в кластере. В рамках коллекции, DS CollectionStructure специфицирует дополнительные связи, такие как степень сходства коллекций.

Пространственно-временная область
Рисунок 12. Пространственно-временная область
3.4.7. Прочие
3.4.7.1. Распознавание лица
Дескриптор FaceRecognition может использоваться для получения изображения лиц, которые соответствуют запросу. Дескриптор представляет проекцию вектора лица на набор базовых векторов, которые охватывают пространство возможных векторов лица. Набор параметров FaceRecognition получается из нормализованного изображения лица. Это нормализованное изображения лица содержит 56 строк с 46 значениями уровня в каждой строке. Центры двух глаз на каждом изображении лица размещаются на 24-ом ряду и 16-ой и 31-ой колонке для правого и левого глаз соответственно. Это нормализованное изображение затем используется для получения одномерного вектора лица, который состоит из значений яркости пикселей нормализованного изображения лица, которое получается в результате растрового сканирования, начинающегося в верхнем левом углу и завершающегося в нижнем правом углу изображения. Набор параметров FaceRecogniton вычисляется путем проектирования одномерного вектора лица на пространство, определяемое набором базисных векторов.
3.5. Схемы описания мультимедиа MPEG-7
Дескрипторы MPEG-7 сконструированы для описания следующих типов информации: низкоуровневые аудио-визуальные характеристики, такие как цвет, текстура, движение, уровень звука и т.д.; высокоуровневые семантические объекты, события и абстрактные принципы; процессы управления материалом; информация о системе памяти и т.д. Ожидается, что большинство дескрипторов, соответствующих низкоуровневым характеристикам будут извлекаться автоматически, в то время как человеческое вмешательство будет необходимо для формирования высокоуровневых дескрипторов.
MPEG-7 DS преобразуются в дескрипторы путем комбинирования индивидуальных дескрипторов а также других DS в рамках более сложных структур и определения соотношения составляющих дескрипторов и DS. В MPEG-7 DS категорируются в отношении к аудио или видео областям, или по отношению к описанию мультимедиа. Например, характерные DS соответствуют неизменным метаданным, связанным с формированием, производством, использованием и управлением мультимедиа, а также описанием материала. Обычно мультимедийные DS относятся ко всем типам мультимедиа, в частности к аудио, видео и текстовым данным, в то время как специфичные для области дескрипторы, такие как цвет, текстура, форма, мелодия и т.д., относятся исключительно к аудио или видео областям. Как в случае дескрипторов, реализация DS может в некоторых вариантах базироваться на автоматических средствах, но часто требует вмешательства человека.
3.5.1. Средства организации MDS
На Рисунок 13 представлена схема организации мультимедийных DS MPEG-7 в следующих областях: базовые элементы, описание материала, управление материалом, организация материала, навигация и доступ, взаимодействие с пользователем.

Пространственные характеристики среды
10.2.7. Пространственные характеристики среды
Средства пространственной характеристики среды позволяют создавать аудио сцены с более естественными источниками звука и моделированием звукового окружения, чем это возможно в версии 1. Поддерживается как физический подход, так и подход восприятия. Физический подход основан на описании акустических свойств среды (например, геометрии комнаты, свойств конструкционных материалов, положения источников звука) и может быть использован в приложениях подобно 3-D виртуальной реальности. Подход с позиций восприятия позволяет на высоком уровне описать аудио восприятие сцены, основанное на параметрах, подобных тем, что используются блоком эффекта реверберации. Таким образом, аудио и визуальная сцена могут быть сформированы независимо, как это обычно требуется в случае кинофильмов. Хотя пространственной характеристики среды относятся к аудио, они являются частью описания BIFS (BInary Format for Scene) в системах MPEG-4 и называются продвинутым AudioBIFS.
Проверки масштабируемости
6.1.4. Проверки масштабируемости
6.1.4.1. Простой масштабируемый профайл (версия 1)
Тест масштабируемости для простого масштабируемого профайла был создан для проверки того, что качество, обеспечиваемое средством временной масштабируемости в простом, масштабируемом профайле, сравненное с качеством, предоставляемым одноуровневым кодированием в простом профайле, и с качеством, обеспечиваемым в простом профайле. В этом тесте используются 5 последовательностей с 4 комбинациями скоростей передачи:
a) 24 кбит/с для базового слоя и 40 кбит/с для улучшенного слоя.
b) 32 кбит/с для обоих слоев.
c) 64 кбит/с для базового слоя и 64 кбит/с для улучшенного слоя.
d) 128 кбит/с для обоих слоев.
Формальные верификационные тесты показали, что при всех условиях, кодирование с временной масштабируемостью в простом масштабируемом профайле демонстрирует то же или несколько худшее качество, чем достижимое при использовании однослойного кодирования в простом профайле. Далее, очевидно, что кодирование с временной масштабируемостью в простом масштабируемом профайле обеспечивает лучшее качество, чем симулкастное (одновременная передача по радио и телевидению или передача несколькими потоками с разной скоростью) кодирование в простом профайле для тех же условий.
6.1.4.2. Центральный профайл (core profile версия 1)
Верификационный тест был создан для оценки характеристик средств временной масштабируемости MPEG-4 видео в центральном профайле (Core Profile).
Тестирование было выполнено с использованием метода "Single Stimulus". Тест создавался с использованием 45 субъектов из двух различных лабораторий. Результаты испытаний показывают, что качество последовательностей, закодированных с привлечением средств временного масштабирования сопоставимы по качеству с вариантом без масштабирования. Очевидно также, что средство временного масштабирования в центральном профайле обеспечивает лучшее качество при равных условиях, чем симулкастное кодирование в центральном профайле.
Расширение базы данных mib маршрутизаторов Cisco
Рисунок 4.4.13.1.2. Расширение базы данных mib маршрутизаторов Cisco

Префикс 1.3.6.1.4.1. является стандартным, далее следует расширение, индивидуальное для маршрутизаторов компании Cisco. Например, группа IPcheckpoint accounting позволяет контролировать поток байтов с определенных адресов локальной сети, что бывает важно при работе с коммерческими провайдерами услуг.
Коды-префиксы для различных производителей телекоммуникационного оборудования приведены в таблице 4.4.13.1.7.
с номером расширения версии 2,
4. Расширения MPEG-4 за пределы версии 2
MPEG в настоящее время работает с номером расширения версии 2, в визуальной и системной областях. Никаких работ по расширению MPEG-4 DMIF или Аудио за пределы версии 2 не проводились.
Реальные данные и функции интерполяции
Рисунок 8. Реальные данные и функции интерполяции
3.4.2. Описатели цвета
Существует восемь дескрипторов цвета: цветового пространства, доминантных цветов, цветовой дискретизации, GoF/GoP цвета, цветовой структуры, цветового размещения и масштабируемой гистограммы цветов.
3.4.2.1. Цветовое пространство
Понятие цветового пространства используется в других описаниях, базирующихся на цвете. В текущем описании, поддерживаются следующие цветовые пространства:
R,G,B
Y,Cr,Cb
H,S,V
HMMD
Матрица линейного преобразования с учетом R, G, B
Монохромное
3.4.2.2. Оцифровка цвета
Этот дескриптор определяет дискретизацию цветового пространства и поддерживает линейные и нелинейные преобразователи, а также lookup-таблицы. Число уровней квантования конфигурируемо так, чтобы обеспечить большую гибкость для широкого диапазона приложений. В случае нелинейного АЦП, ширина канала преобразования может также конфигурироваться. Для разумных приложений в контексте MPEG-7, этот дескриптор должен комбинироваться с другими, например, чтобы характеризовать значения в цветовой гистограмме.
3.4.2.3. Доминантный цвет(а)
Этот дескриптор цвета является наиболее удобным для представления локальных характеристик (области объекта или изображения), где для предоставления цветовой информации достаточно малого числа цветов. Могут использоваться и полные изображения, например, картинки флагов или цветных торговых марок. Квантование цвета используется для получения малого числа характерных цветов в каждой области/изображении. Соответственно вычисляется процент каждого дискретизируемого цвета в области. Определяется также пространственная когерентность всего дескриптора.
3.4.2.4. Масштабируемый цвет
Дескриптор масштабируемого цвета (Scalable Color) является гистограммой цветов в цветном пространстве HSV, которая кодируется с помощью преобразования Хара. Ее двоичное представление является масштабируемым с точки зрения числа каналов и числа бит, характеризующих значение точности в широком диапазоне потоков данных.
Дескриптор масштабируемого цвета полезен для сравнения изображений и поиска, базирующегося на цветовых характеристиках. Точность отображения возрастает с увеличением числа бит, используемых для описания.
3.4.2.5. Описатель структуры цвета
Дескриптор цветовая структура (Color Structure) является описателем цветовой характеристики, которая объединяет цветовое содержимое (аналогично цветовой гистограмме) и информацию о структуре материала. Его главная задача сравнение изображений главным образом для статических картинок. Метод выборки вводит данные о цветовой структуре в дескриптор, учитывая локально цвета окрестных пикселей, и не анализирует каждый пиксель отдельно. Дескриптор цветовая структура обеспечивает дополнительную функциональность и улучшенный поиск, базирующийся на подобии естественных изображений.
3.4.2.6. Выкладка цвета
Этот дескриптор специфицирует пространственное распределение цветов для быстрого поиска и просмотра. Его целью является не только сравнение изображений и видео клипов, но также поиск, базирующийся на раскладке цветов, такой как сравнение наброска с изображением, которое не поддерживается другими цветовыми дескрипторами. Этот дескриптор может использоваться для всего изображения или для любой его части. Данный дескриптор может также быть применен для областей произвольной формы.
3.4.2.7. Цвет GoF/GoP
Дескриптор цвета группа_кадров/группа_картинок расширяет возможности дескриптора масштабируемого цвета, который определен для статических изображений, чтобы выполнять цветовое описание видео сегментов или собрания статических изображений. Дополнительные два бита позволяют определить, была ли вычислена цветовая гистограмма, прежде чем было осуществлено преобразование Хара: для усреднения, медианы или пересечения. Усредненная гистограмма, которая соответствует усредненному значению счетчика для каждой ячейки всех кадров или изображений, эквивалентна вычислению совокупной цветовой гистограммы всех кадров или изображений с последующей нормализацией.
Медианная гистограмма соответствует вычислению медианного значения счетчика для каждой ячейки совокупности кадров или изображений. Более надежно округлять ошибки и присутствие выбросов в распределении яркости изображения по сравнению с усредненной гистограммой. Гистограмма пересечения соответствует вычислению минимального значения счетчика для каждой ячейки совокупности кадров или изображений, чтобы получить цветовые характеристики “наименьшего общего” группы изображений. Заметим, что это отличается от гистограммы пересечения, которая является скалярной мерой. Аналогичные меры сходства/различия, которые используются для сравнения масштабируемых цветовых описаний, могут быть применены для сопоставления цветовых дескрипторов GoF/GoP.
3.4.3. Описатели текстуры
Существует три текстурных дескриптора: Edge Histogram, Homogeneous Texture и Texture Browsing.
3.4.3.1. Описатели однородной текстуры
Однородная текстура представляет собой важный визуальный примитив для поиска и просмотра большой коллекции выглядящих сходно образов. Изображение может рассматриваться как мозаика однородных текстур, так что эти текстурные характеристики, соответствующие областям могут использоваться для индексации визуальных данных. Например, пользователь, просматривающий абстрактную базу данных изображений, может захотеть идентифицировать различные блоки в этой коллекции изображений. Блоки с автомашинами, запаркованными регулярным образом являются хорошим примером однородного текстурного образца, рассматриваемого с большого расстояния, как это происходит при аэросъемке. Аналогично, сельскохозяйственные области и участки растительности являются другим примером однородных текстур, встречающихся при аэро и спутниковых наблюдениях. Примеры запросов, которые могут поддерживаться в этом контексте, могут включать в себя "Поиск всех спутниковых изображений Санта Барбары, которые имеют меньше чем 20% облачного покрытия" или "Найти растительный участок, который выглядит как эта область".
Чтобы поддерживать такой поиск изображений, необходимо эффективное представление текстуры. Дескриптор однородной текстуры предоставляет количественное представление, используя 62 числа (по 8 бит каждое), которое удобно для поиска сходства. Получение данных осуществляется следующим образом; изображение сначала обрабатывается посредством набора фильтров Габора, настроенных на определенные ориентации и масштаб (смоделированные с помощью функций Габора). Дескриптор однородной текстуры предоставляет точное количественное описание текстуры, которое может использоваться для поиска. Вычисление этого дескриптора базируется на фильтрации.
3.4.3.2. Просмотр текстуры
Дескриптор просмотра текстуры
(Texture Browsing) полезен для представления однородной текстуры в приложениях, служащих для просмотра, и требует только 12 бит (максимум). Он предоставляет перцептуальную характеристику текстуры, аналогично человеческому описанию в терминах регулярности, шероховатости, ориентированности. Вычисление этого дескриптора осуществляется также как и дескриптора однородной текстуры. Сначала, изображение фильтруется с помощью набора специально настроенных фильтров (смоделированных посредством функций Габора); в отфильтрованном результате идентифицируются два доминантных ориентаций текстуры. Три бита используются для представления каждой из доминантных ориентаций. За этим следует анализ проекций отфильтрованного изображения вдоль доминантных направлений, чтобы определить регулярность (характеризуемую двумя битами) и загрубленность (2 бита x 2). Этот дескриптор совместно с дескриптором однородной текстуры предоставляет масштабируемое решение для представления областей изображения с однородной текстурой.
3.4.3.3. Краевая гистограмма
Дескриптор краевой гистограммы
представляет пространственное распределение пяти типов краев, в частности четырех ориентированных краев и одного неориентированного. Так как края играют важную роль для восприятия изображения, данный дескриптор помогает найти изображения со сходным семантическим значением.
Таким образом, он изначально ориентирован на сравнение изображений (по образцам или наброскам), в особенности на естественные изображения с нерегулярными краями. В этом контексте, свойства системы поиска изображения могут быть существенно улучшены, если дескриптор краевой гистограммы комбинируется с другими дескрипторами, такими как дескриптор цветовой гистограммы. Кроме того, наилучшие характеристики системы поиска изображения, учитывая только этот дескриптор, достигаются путем использования полу-глобальных и глобальных гистограмм, получаемых непосредственно из дескриптора краевых гистограмм.
3.4.4. Описатели формы
Существует четыре типа дескрипторов формы: объектная форма, базирующаяся на областях, форма, базирующаяся на контурах, 3D-форма и 2D-3D множественные проекции.
3.4.4.1. Форма, базирующаяся на областях (Region-Based)
Форма объекта может состоять из одной области или набора областей, а также некоторых отверстий в объектах, как это показано на рис 9. Так как дескриптор формы, базирующейся на областях, использует все пиксели, определяющие форму в пределах кадра, он может описывать любую форму, то есть не только простые формы с односвязными областями, как на Рисунок 9 (a) и (b), но также сложные формы, которые содержат отверстия или несколько не соединенных областей, как показано на Рисунок 9 (c), (d) и (e), соответственно. Дескриптор формы, базирующейся на областях, может не только эффективно описать столь несхожие формы, но и минимизировать искажения на границах объекта.
На Рисунок 9 (g), (h) и (i) показаны очень схожие изображения чашки. Различия имеются только в форме ручки. Форма (g) имеет трещину на нижней части ручки, в то время как в (i) ручка не имеет отверстия. Дескриптор формы, базирующейся на областях, рассматривает (g) и (h) подобными, но отличными от (i), так как там ручка не имеет отверстия. Аналогично, на Рисунок 9(j-l) показана часть видео последовательности, где два диска постепенно разделяются. С точки зрения дескриптора формы, базирующейся на областях, эти картинки схожи.


Регистрация типа среды
2. Регистрация типа среды
Регистрация нового типа среды начинается с формирования регистрационного предложения. Регистрация может произойти в рамках различных регистрационных схем (деревьев), которые предполагают различные требования. Вообще, новое регистрационное предложение оценивается и рассматривается в зависимости от используемой схемы (дерева). Тип среды затем регистрируется, если предложение оказывается приемлемым.
2.1. Деревья регистрации и имена субтипов
Для того чтобы увеличить эффективность и гибкость процесса регистрации различные структуры субтипов имен могут быть зарегистрированы так, чтобы удовлетворить различным естественным требованиям, например, субтип, который будет рекомендованa для широкого использования сообществом Интернет или субтип, который используется для переноса файлов, ассоциированных с некоторой частной программой. Последующие субсекции данного документа определяют регистрационные "деревья", отличающиеся использованием стандартной формы имен (например, имен вида "tree.subtree...type"). Заметим, что некоторые типы среды определены до появления данного документа и их имена не согласуются с данной схемой. Смотри приложение A, где рассматривается эта проблема.
2.1.1. IETF-дерево
Дерево IETF служит для типов, представляющих общий интерес для сообщества Интернет. Регистрация в IETF требует одобрения IESG и публикации данного типа среды в каком-то документе RFC.
Типы среды в IETF-дереве обычно обозначаются именами, которые не оформлены стандартным образом, т.е., не содержат символов точка (".", полный останов).
"Хозяином" регистрации типа среды в рамках дерева IETF предполагается сама группа IETF. Модификации или изменения спецификации требуют той же процедуры, что и регистрация.
2.1.2. Дерево производителя (Vendor Tree)
Дерево производителя используется для типов среды, соответствующих определенным коммерческим продуктам.
Результат регистрации может быть ассоциирован с деревом производителя тем, кто нуждается в замене файлов, сопряженных с определенным программным продуктом.
Однако регистрация формально принадлежит производителю или организации, разработавшей программу или формат.
Регистрация в рамках дерева производителя выделяется с помощью префикса имени "vnd.". Далее может следовать имя известного производителя (например, "vnd.lapot"), адрес производителя или место расположения программы, заключительная секция имени может содержать наименование типа среды (например, vnd.bigcompany.funnypictures).
2.1.3. Частное дерево
Регистрация типов среды, созданных с экспериментальными целями, могут быть зарегистрированы в рамках частного дерева. Регистрация такого вида имеет префикс имени "prs.". Хозяином "частной" регистрации и соответствующих спецификаций является человек или объект, осуществивший регистрацию. Публикация частных типов среды не требуется.
2.1.4. Специальное `x.'-дерево
Для удобства и симметрии со схемой регистрации имена типов среды, начинающиеся с "x." могут использоваться для тех же целей, что и имена, начинающиеся с "x-". Эти типы не являются зарегистрированными и могут использоваться партнерами при взаимном согласии.
Однако при упрощенной процедуре регистрации, описанной выше для частных типов и типов среды производителей трудно себе представить ситуацию, когда бы возникла необходимость использования незарегистрированных типов среды.
2.1.5. Дополнительные регистрационные деревья
От случая к случаю как этого требует сообщество, IANA может по согласованию с IESG, создать новое регистрационное дерево верхнего уровня. Предполагается, что такие деревья могут быть созданы для внешней регистрации и управления, например научными сообществами для их внутреннего использования. Вообще, качество рассмотрения спецификаций для этих деревьев регистрации должно быть столь же тщательным, как и в случае IETF. О создании этих новых деревьев уведомляет публикация RFC, одобренная IESG.
2.2. Требования регистрации
Предложения регистрации среды должны соответствовать требованиям изложенным ниже в последующих разделах.
Заметим, что требования могут иной раз зависеть от дерева регистрации.
2.2.1. Требования функциональности
Типы среды должны функционировать как настоящий формат среды. Регистрация вещей, которые относятся в большей мере к транспортному кодированию, выбору символьного набора не допускается. Например, хотя существуют приложения, которые осуществляют транспортное декодирование base64 [RFC-2045], base64 не может быть зарегистрировано в качестве типа среды. Это требование не зависит от используемого регистрационного дерева.
2.2.2. Требования к именам
Всем зарегистрированным типам среды должны быть присвоены имена типов и субтипов MIME. Комбинация этих имен служит в дальнейшем для идентификации типа среды и формата субтипа.
При выборе имени типа верхнего уровня должна учитываться природа типа среды. Например, среда, используемая для представления статической картинки должна быть субтипом типа изображение, в то время как среда, способная представлять звуковую информацию должна принадлежать аудио типу. Для получения дополнительной информации смотри RFC-2046.
Новые субтипы типов верхнего уровня должны соответствовать регламентациям этого уровня. Например, все субтипы типа составных данных должны использовать один и тот же синтаксис инкапсуляции.
В некоторых случаях новый субтип среды может не вполне согласовываться с определенным на текущий момент типом содержимого верхнего уровня. Если такое произошло, следует определить новый тип верхнего уровня, который бы согласовывался с данным субтипом. Такое определение должно быть выполнено согласно стандартной процедуре и опубликовано в RFC. Это требование не зависит от используемого регистрационного дерева.
2.2.3. Требования к параметрам
Типы среды могут использовать один или более параметров MIME, некоторые параметры могут оказаться автоматически доступными для типа среды в случае, когда они применимы ко всему семейству субтипов. В любом случае имена, величины и назначение любого параметра должны быть полностью специфицированы при регистрации типа среды в рамках дерева IETF.
Они должны быть специфицированы как можно полнее, когда тип среды регистрируется в рамках частного дерева или дерева производителя.
Новые параметры не могут определяться с целью расширения функциональности для типов, зарегистрированных в рамках дерева IETF. Но новые параметры могут быть добавлены для передачи дополнительной информации, которая не изменяет существующую функциональность.
2.2.4. Требования к канонизации и формату
Все зарегистрированные типы среды должны использовать один канонический формат данных вне зависимости от дерева регистрации. Спецификация формата каждого типа среды необходима для всех типов зарегистрированных для дерева IETF, эта информация должна присутствовать и в предложении для регистрации типа среды. Спецификации формата и особенностей обработки могут быть, а могут и не быть общедоступны для типов среды, зарегистрированных для дерева производителя. В предложения регистрации такого вида включаются только спецификации программы и ее версии пригодной для работы с данным типом среды. Включение спецификаций формата или ссылки на них в предложение регистрации желательно, но не обязательно.
Спецификации формата необходимы для регистрации в рамках частного дерева, они могут быть опубликованы в RFC или помещены в депозитарий IANA. Спецификации, помещаемые в депозитарий должны отвечать тем же требованиям, что и регистрируемые.
Некоторые типы среды включают в себя патентованные технологии. Регистрация типа среды, включающего в себя патентованные технологии, также разрешена. Однако устанавливаются ограничения (RFC-1602) на применение патентованных технологий в рамках стандартных протоколов.
2.2.5. Рекомендации по взаимозаменяемости
Типы среды должны быть способны работать с максимально возможным числом систем и приложений. Однако некоторые типы среды неизбежно будут иметь проблемы при работе на некоторых платформах. Могут возникнуть трудности из-за различных версий, порядка байт, специфики работы шлюза и т.д.
Способность работы с любыми типами среды не требуется, но желательно, чтобы были четко описаны границы применимости.
Публикация типа среды не предполагает исчерпывающего обзора возможностей работы с различными платформами и приложениями.
2.2.6. Требования к безопасности
Рассмотрение аспектов безопасности необходимо для всех типов, регистрируемых в рамках IETF-дерева. Аналогичный анализ для типов среды регистрируемых в рамках частного дерева или дерева производителя рекомендуется, но не является обязательным. Однако вне зависимости от того что анализ безопасности мог проводиться или нет, все описания соображений по безопасности должны быть выполнены крайне аккуратно вне зависимости от дерева регистрации. В частности, заявление, что "никакие соображения безопасности не сопряжены с этим типом" не следует путать с "безопасность сопряженная с данным типом не анализировалась и не оценивалась".
Не существует требования, чтобы регистрируемые типы среды были безопасны и не несли в себе каких либо рисков. Несмотря на это, все известные риски должны быть идентифицированы при регистрации типа вне зависимости от используемого дерева.
Секция безопасности подлежит дальнейшему развитию. Некоторые аспекты, которые следует учитывать при анализе безопасности типа среды, перечислены ниже.
| (1) | Комплексные типы среды могут включать в себя директивы, которые определяют действия над файлами или другими ресурсами получателя. Во многих случаях для отправителя перечисляются действия, которые могут вызвать разрушительные последствия. Смотри регистрацию типа среды application/postscript в RFC-2046 в качестве примера таких директив. |
| (2) | Сложные типы среды могут включать директивы, определяющие действия, которые сами по себе безвредны для получателя, но могут вызвать раскрытие конфиденциальных данных или упростить последующие атаки или нарушить конфиденциальность для получателя каким-либо способом. Регистрация типа среды application/postscript иллюстрирует, как следует обрабатывать такие директивы. |
| (3) | Тип среды могут быть ориентированы на применения, которые требуют определенного уровня безопасности, но не предоставляют самих механизмов безопасности. Например, тип среды может быть предназначен для запоминания конфиденциальной медицинской информации, которая в свою очередь требует внешней системы обеспечения секретности. |
/p> В асинхронных почтовых системах, где информация о возможностях удаленного почтового агента часто не доступна для отправителя, максимум взаимодействия может быть достигнут путем ограничения числа типов среды, используемых для общих форматов, которые предполагается широко внедрять. Именно эта концепция, принятая в прошлом, явилась причиной ограничения числа возможных типов среды и привела к формированию процесса регистрации типов среды.
Однако необходимость в "общих" типах среды не требует ограничения регистрации новых типов. Если для определенного приложения рекомендуется ограниченный набор типов среды, это должно быть определено отдельным заявлением применимости для приложения или среды реализации.
2.2.7. Требования к публикации
Предложения для типов среды регистрируемых в рамках IETF-дерева должны публиковаться в виде RFC. RFC-публикации типа среды производителя или частного типа среды желательны, но не обязательны. Во всех случаях IANA сохраняет копии всех предложений по типам среды и публикует их как часть самого регистрационного дерева типов среды.
Дерево IETF существует для типов среды, которые действительно требуют серьезного анализа и стандартного процесса одобрения, в то время как деревья производителей и частные деревья такой процедуры не требуют. Ожидается, что заявления о применимости для конкретных приложений будут публиковаться время от времени для типов среды, которые доказали свою эффективность в определенных контекстах.
Как было обсуждено выше, регистрация типа среды верхнего уровня предполагает стандартную процедуру принятия и, следовательно, обязательную RFC-публикацию.
2.2.8. Дополнительная информация
Различные виды опционной информации могут быть включены в спецификацию типа среды, если таковые имеются:
| (1) | Магические числа (длина, значения октетов). Магические числа представляют собой байтовые последовательности, которые всегда имеются и по этой причине могут использоваться для идентификации объектов, принадлежащих данному типу среды. |
| (2) | Расширения имени файлов, используемые на одной или более платформах для индикации того, что файл содержит данный тип среды. |
| (3) | Код типа файла Macintosh (4 октета) используется для маркировки файлов, содержащих данный тип среды. |
/p> Такая информация часто оказывается весьма полезной и, если имеется, то должна предоставляться.
2.3. Процедура регистрации
Следующая процедура была применена IANA для обзора и одобрения новых типов среды. Для регистрации в рамках дерева IETF, нужно следовать обычной процедуре, осуществляя на первом этапе рассылку интернет-проекта. Для регистрации в рамках частного дерева или дерева производителя осуществляется без широкого обсуждения. Проект непосредственно направляется IANA (по адресу iana@iana.org).
2.3.1. Представление типа среды на суд сообщества
Все начинается с посылки предложения регистрации типа среды лист-серверу ietf-types@iana.org. Отклики ожидаются в течение двух недель. Этот подписной лист был учрежден для целей обсуждения предлагаемых типов среды и доступа. Предложенные типы среды, если они формально не зарегистрированы, не могут быть использованы; префикс "x-", специфицированный в RFC-2045, может применяться до тех пор, пока процесс регистрации не завершится.
Типы среды, регистрируемые в рамках дерева IETF должны представляться на одобрение IESG.
Получив подтверждение, что тип среды отвечает всем требованиям, автор может послать запрос регистрации IANA, которая зарегистрирует тип среды и сделает его доступным для всего сообщества.
2.4. Комментарии по поводу регистрации типа среды
Комментарии по поводу регистрации типа среды могут быть направлены членам сообщества IANA. Эти комментарии будут переданы "хозяину" типа среды. Комментаторы могут потребовать, чтобы их замечания были присовокуплены к материалам регистрации данного типа среды и, если IANA одобрит это, такая процедура будет произведена.
2.5. Расположение списка зарегистрированных типов среды
Материалы регистрации типа среды доступны через анонимный FTP сервер ftp://ftp.isi.edu/in-notes/iana/assignments/media-types/, а все зарегистрированные типы среды будут перечислены в периодически обновляемом документе "Assigned Numbers" RFC [в настоящее время STD-2, RFC-1700].
Описания типа среды и другие материалы могут быть также опубликованы в виде информационных RFC путем посылки документа по адресу "rfc-editor@isi.edu" [RFC-1543].
2.6. Процедура регистрации типа среды в IANA
IANA регистрирует типы среды, принадлежащие дереву IETF. Частные типы и типы среды производителя регистрируются IANA автоматически и без формального обсуждения, если выполнены следующие условия:
| (1) | Типы среды должен функционировать как истинный формат среды. В частности, символьный набор или транспортное кодирование не могут быть зарегистрированы в качестве типа среды. |
| (2) | Все типы среды должны иметь корректно сформированные имена типа и субтипов. Все имена типов должны быть определены стандартным образом. Все имена субтипов должны быть уникальными, должны соответствовать грамматике MIME и содержать корректный префикс дерева. |
| (3) | Типы, регистрируемые в рамках частного дерева, должны быть снабжены спецификацией формата, или указателем на такую спецификацию. |
| (4) | Любые соображения по безопасности должны отражать объективную ситуацию и быть корректными. IANA не проводит экспертизу, но откровенно некомпетентные материалы отбрасываются. |
Раз тип среды опубликован IANA, автор может потребовать изменения его описания. Запрос изменения оформляется также как и сама регистрация:
| (1) | Рассылка пересмотренной заявки регистрации через подписной лист ietftypes. |
| (2) | Ожидание в течение двух недель комментариев. |
| (3) | Публикация после формального обсуждения IANA, если это необходимо. |
Владелец типа содержимого может передать ответственность за него другому лицу или организации, проинформировав об этом IANA и список рассылки ietf-типов. Это может быть сделано без обсуждения.
IESG может переадресовать ответственность за определенный тип среды. Наиболее общим случаем является разрешение изменений в описании типа среды в ситуации, когда автор исходного документа умер, эмигрировал или стал недоступен и не может внести изменения крайне важные для сообщества пользователей.
Регистрации типа среды не могут быть аннулированы. Типы среды, которые не используются более, объявляются устаревшими (OBSOLETE) путем изменения их поля "intended use" (область применения). Такие типы среды будет помечены соответствующим образом и в списках, публикуемых IANA.
2.8. Регистрационный шаблон
To: ietf-types@iana.org
Subject: Registration of MIME media type XXX/YYY(Регистрация типа среды MIME)
| MIME media type name: | (Имя типа среды MIME) |
| MIME subtype name: | (Имя субтипа среды MIME) |
| Required parameters: | (Необходимые параметры) |
| Optional parameters: | (Опционные параметры) |
| Encoding considerations: | (Соображения по кодированию) |
| Security considerations: | (Соображения безопасности) |
| Interoperability considerations: | (Соображения совместимости) |
| Published specification: | (Опубликованная спецификация) |
| Applications which use this media type: | (Приложения, использующие данный тип среды) |
| Additional information: | (Дополнительная информация) |
| Magic number(s): | (Магические числа) |
| File extension(s): | (Расширение имени файла) |
| Macintosh File Type Code(s): | (Код типа файла Macintosh) |
|
Person & email address to contact for further information: |
(Контактный адрес) |
|
Intended usage: (Одно из COMMON, LIMITED USE или OBSOLETE) |
(Возможное применение) |
| Author/Change controller: |
(Автор/ответственный) Сюда может быть добавлена любая другая информация на усмотрение автора. |
Ресинхронизация
9.14.1. Ресинхронизация
Средства ресинхронизации пытаются восстановить синхронизацию между декодером и потоком данных нарушенную в результате ошибки. Данные между точкой потери синхронизации и моментом ее восстановления выбрасываются.
Метод ресинхронизации принятый MPEG-4, подобен используемому в структурах групп блоков GOB (Group of Blocks) стандартов ITU-T H.261 и H.263. В этих стандартах GOB определена, как один или более рядов макроблоков (MB). В начале нового GOB потока помещается информация, называемая заголовком GOB. Этот информационный заголовок содержит стартовый код GOB, который отличается от начального кода кадра, и позволяет декодеру локализовать данный GOB. Далее, заголовок GOB содержит информацию, которая позволяет рестартовать процесс декодирования (т.е., ресинхронизовать декодер и поток данных, а также сбросить всю информацию предсказаний).
Подход GOB базируется пространственной ресинхронизации. То есть, раз в процессе кодирования достигнута позиция конкретного макроблока, в поток добавляется маркер ресинхронизации. Потенциальная проблема с этим подходом заключается в том, что из-за вариации скорости процесса кодирования положение этих маркеров в потоке четко не определено. Следовательно, определенные части сцены, такие как быстро движущиеся области, будут более уязвимы для ошибок, которые достаточно трудно исключить.
Подход видео пакетов, принятый MPEG-4, базируется на периодически посылаемых в потоке данных маркерах ресинхронизации. Другими словами, длина видео пакетов не связана с числом макроблоков, а определяется числом бит, содержащихся в пакете. Если число бит в текущем видео пакете превышает заданный порог, тогда в начале следующего макроблока формируется новый видео пакет.
Маркер ресинхронизации используется чтобы выделить новый видео пакет. Этот маркер отличим от всех возможных VLC-кодовых слов, а также от стартового кода VOP. Информация заголовка размещается в начале видео пакета. Информация заголовка необходима для повторного запуска процесса декодирования и включает в себя: номер макроблока первого макроблока, содержащегося в этом пакете и параметр квантования, необходимый для декодирования данный макроблок.
Номер макроблока осуществляет необходимую пространственную ресинхронизацию, в то время как параметр квантования позволяет заново синхронизовать процесс дифференциального декодирования.
В заголовке видео пакета содержится также код расширения заголовка (HEC). HEC представляет собой один бит, который, если равен 1, указывает на наличие дополнительной информации ресинхронизации. Сюда входит модульная временная шкала, временное приращение VOP, тип предсказания VOP и VOP F-код. Эта дополнительная информация предоставляется в случае, если заголовок VOP поврежден.
Следует заметить, что, когда в рамках MPEG-4 используется средство восстановления при ошибках, некоторые средства эффективного сжатия модифицируются. Например, вся кодированная информация предсказаний заключаться в одном видео пакете так чтобы предотвратить перенос ошибок.
В связи с концепцией ресинхронизацией видео пакетов, в MPEG-4 добавлен еще один метод, называемый синхронизацией с фиксированным интервалом. Этот метод требует, чтобы стартовые коды VOP и маркеры ресинхронизации (т.е., начало видео пакета) появлялись только в легальных фиксированных позициях потока данных. Это помогает избежать проблем, связанных эмуляциями стартовых кодов. То есть, когда в потоке данных встречаются ошибки, имеется возможность того, что они эмулируют стартовый код VOP. В этом случае, при использовании декодера с синхронизацией с фиксированным интервалом, стартовый код VOP ищется только в начале каждого фиксированного интервала.
продемонстрированы свойства обобщения формы
Рисунок 10.
На Рисунок 10 (a) продемонстрированы свойства обобщения формы (внешнее сходство различных форм), (b) устойчивость по отношению к плавному движению (бегущий человек), (c) устойчивость к частичному перекрытию (хвосты или ноги лошадей)
3.4.4.3. 3D-форма
Рассматривая непрерывное развитие мультимедийных технологий, виртуальных миров, 3D-материал становится обычным для современных информационных систем. В большинстве случаев, 3D-информация представляется в виде сетки многоугольников. Группа MPEG-4, в рамках подгруппы SNHC, разрабатывала технологии для эффективного кодирования модели 3D-сеток. В стандарте MPEG-7 необходимы средства для интеллектуального доступа к 3D-информации. Главные приложения MPEG-7 имеют целью поиск, получение и просмотр баз 3D-данных.
Предлагаемый дескриптор 3D-формы имеет целью предоставление внутреннего описания формы сеточных 3D-моделей. Он использует некоторые локальные атрибуты 3D-поверхности.
3.4.5. Дескрипторы перемещения
Существует четыре дескриптора перемещения: перемещение камеры, траектория перемещение объекта, параметрическое движение объекта и двигательная активность.
3.4.5.1. Движение камеры
Этот дескриптор характеризует параметры перемещения 3-D камеры. Он базируется на информационных параметрах 3-D-перемещения камеры, которые могут быть автоматически получены.
Дескриптор движения камеры поддерживает следующие стандартные операции с камерой (см. Рисунок 11): фиксированное положение, панорамное движение (горизонтальное вращение), слежение за движущимся объектом (горизонтальное поперечное перемещение), вертикальное вращение, вертикальное поперечное перемещение, изменение фокусного расстояния, наезд (трансфокация вдоль оптической оси) и вращение вокруг оптической оси.

Сетевое моделирование
4.5.17 Сетевое моделирование
Ни один проект крупной сети со сложной топологией в настоящее время не обходится без исчерпывающего моделирования будущей сети (речь, разумеется, идет не о России). Программы, выполняющие эту задачу, достаточно сложны и дороги. Целью моделирования является определение оптимальной топологии, адекватный выбор сетевого оборудования, определение рабочих характеристик сети и возможных этапов будущего развития. Ведь сеть, слишком точно оптимизированная для решений задач текущего момента, может потребовать серьезных переделок в будущем. На модели можно опробовать влияние всплесков широковещательных запросов или реализовать режим коллапса (для Ethernet), что вряд ли кто-то может себе позволить в работающей сети. В процессе моделирования выясняются следующие параметры:
Предельные пропускные способности различных фрагментов сети и зависимости потерь пакетов от загрузки отдельных станций и внешних каналов.
Время отклика основных серверов в самых разных режимах, в том числе таких, которые в реальной сети крайне нежелательны.
Влияние установки новых серверов на перераспределение информационных потоков (Proxy, Firewall и т.д.).
Решение оптимизации топологии при возникновении узких мест в сети (размещение серверов, DNS, внешних шлюзов, организация опорных каналов и пр.).
Выбор того или иного типа сетевого оборудования (например, 10BaseTX или 100BaseFX) или режима его работы (например, cut-through, store-and-forward для мостов и переключателей и т.д.).
Выбор внутреннего протокола маршрутизации и его параметров (например, метрики).
Определение предельно допустимого числа пользователей того или иного сервера.
Оценка необходимой полосы пропускания внешнего канала для обеспечения требуемого уровня QOS.
Оценка влияния мультимедийного трафика на работу локальной сети, например, при подготовке видеоконференций.
Перечисленные задачи предъявляют различные требования к программам. В одних случаях достаточно провести моделирование на физическом (MAC) уровне, в других нужен уже уровень транспортных протоколов (например, UDP и TCP), а для наиболее сложных задач нужно воспроизвести поведение прикладных программ.
Все это должно учитываться при выборе или разработке моделирующей программы. Ведь нужно учесть, что ваша машина должна в той или иной мере воспроизвести действия всех машин в моделируемой сети. Таким образом, машина эта должна быть достаточно быстродействующей и, несмотря на это, моделирование одной секунды работы сети может занять при определенных условиях не один час.
Результаты моделирования должны иметь точность 10-20%, так как этого достаточно для большинства целей и не требует слишком много машинного времени. Следует иметь в виду, что для моделирования поведение реальной сети, надо знать все ее рабочие параметры: длины кабеля от концентратора до конкретной ЭВМ, задержки используемых кабелей, задержки концентраторов (этот параметр часто отсутствует в документации и его придется брать из документации на сетевой протокол, например из IEEE 802.3). Параметры могут быть определены и прямым измерением. Чем точнее вы воспроизводите поведение сети, тем больше машинного времени это потребует. Кроме того, вам предстоит сделать некоторые предположения относительно распределения загрузки для конкретных ЭВМ и других сетевых элементов, задержек в переключателях, мостах, времени обработки запросов в серверах. Здесь нужно учитывать и характер решаемых на ЭВМ задач. www/ftp-сервер или обычная персональная рабочая станция создают различные сетевые трафики. Определенное влияние на результат могут оказывать и используемые ОС. В случае моделирования реальной сети можно произвести соответствующие измерения, что иногда тоже не слишком просто. Учитывая сложность моделирования на одной ординарной ЭВМ, следует ограничиваться моделированием не более чем одной минуты для каждого из наборов параметров (этого времени достаточно для копирования практически любого файла через локальную сеть). Исключение может составлять моделирование внешнего трафика, но в этом случае весь локальный трафик должен рассматриваться как фоновый.
4.5.17.1 Аналитическое моделирование
Определение характеристик сети до того, как она будет введена в эксплуатацию, имеет первостепенное значение.
Это позволяет отрегулировать характеристики локальной сети на стадии проектирования. Решение этой проблемы возможно путем аналитического или статистического моделирования.
Аналитическая модель сети представляет собой совокупность математических соотношений, связывающих между собой входные и выходные характеристики сети. При выводе таких соотношений приходится пренебрегать какими-то малосущественными деталями или обстоятельствами.
Телекоммуникационная сеть при некотором упрощении может быть представлена в виде совокупности процессоров (узлов), соединенных каналами связи. Сообщение, пришедшее в узел, ждет некоторое время до того, как оно будет обработано. При этом может образоваться очередь таких сообщений, ожидающих обработки. Время передачи или полное время задержки сообщения d равно:
D = Tp + S + W,
где Tp, S и W, соответственно, время распространения, время обслуживания и время ожидания. Одной из задач аналитического моделирование является определение среднего значения D. При больших загрузках основной вклад дает ожидание обслуживания W. Для описания очередей в дальнейшем будет использована нотация Д. Дж. Кенделла: A/B/C/K/m/z,
где А – процесс прибытия: В – процесс обслуживания; С – число серверов (узлов); К – максимальный размер очереди (по умолчанию -
-Сетки
9.8.4. 3D-сетки
Возможности кодирования 3-D сеток включают в себя:
Кодирование базовых 3-D многоугольных сеток делает возможным эффективное кодирование 3-D полигональных сеток. Кодовое представление является достаточно общим, чтобы поддерживать как много- так и одно-сеточный вариант.
Инкрементное представление позволяет декодеру реконструировать несколько лиц в сетке, пропорционально числу бит в обрабатываемом потоке данных. Это, кроме того, делает возможным инкрементный рэндеринг.
Быстрое восстановление при ошибках позволяет декодеру частично восстановить сетку, когда субнабор бит потока данных потерян и/или искажен.
Масштабируемость LOD (Level Of Detail – уровень детализации) позволяет декодеру реконструировать упрощенную версию исходной сетки, содержащей уменьшенное число вершин из субнабора потока данных. Такие упрощенные презентации полезны, чтобы уменьшить время рэндеринга объектов, которые удалены от наблюдателя (управление LOD), но также делает возможным применение менее мощного средства для отображения объекта с ухудшенным качеством.
Схема пересылки электронных почтовых сообщений
Рисунок 4.5.10.1. Схема пересылки электронных почтовых сообщений

Со временем можно ожидать, что электронные адреса станут универсальными, но это произойдет не скоро. Для этого нужно чтобы транспорт и другие службы научились работать с такими адресами. Электронные (IP) адреса удобнее для ЭВМ, чем традиционные, а принимая во внимание, что применение вычислительной техники повсеместно, вывод напрашивается сам собой. То что удобно для ЭВМ, удобно в конечном итоге для всех.
Любое почтовое сообщение можно разделить на три части: "конверт" (RFC-821), заголовки (RFC-822) и собственно текст. Конверт используется почтовым сервером и содержит две команды (тексты после двоеточия приведены в качестве примера):
MAIL From: <semenov@cl.itep.ru>
RCPT To: <king_penguin@antarctic.edu>
Существует девять полей заголовка, используемые почтовой программой пользователя: Received, From, To, Date, Subject, Message-Id, X-Phone, X-Mailer, Reply-To. Каждое из этих полей содержит имя, за которым после двоеточия следует его значение. Документ RFC-822 определяет формат и интерпретацию полей заголовка. Заголовки, начинающиеся с X- являются полями, определяемые пользователем.
При вызове почты (командой mail или mailx) на экране будет распечатан служебный текст, который зависит от конкретной реализации mail, но практически непременным атрибутом любой версии будет являться полное число полученных вами почтовых сообщений (если таковые были). Это могут быть и сообщения, оставленные вами там после предшествующего чтения почты. Непрочитанные вами сообщения так или иначе помечаются (например, символом U на левом поле строки-описания сообщения или N для новых). Далее следует аннотация сообщения, по одной строке на сообщение. Аннотация обычно содержит номер сообщения (нумерация всегда начинается с 1), имя и адрес отправителя, дата и время отправки. После этого следуют (в некоторых реализациях) два числа, разделенных косой чертой ("/"). Они характеризуют размер сообщения в строках и полное число символов.
В заключение следует, если еще есть место, предмет сообщения (Subject:). Ниже приведен пример текста такого аннотационного сообщения (SUN):
Mail version SMI 4.1-OWV3 Mon Sep 23 07:17:24 PDT 1991 Type ? for help.
"/usr/spool/mail/semenov": 4 messages 4 new
>N 1 mw@isds.Duke.EDU Wed Aug 23 14:15 92/4350
N 2 hochreit@informatik.tu-muenchen.de Wed Aug 23 23:54 71/2767 TR announcement: Long Sho
N 3 Voz@dice.ucl.ac.be Thu Aug 24 07:08 501/21416 ELENA Classification data
N 4 S.Renals@dcs.shef.ac.uk Thu Aug 24 07:08 58/2837 AbbotDemo: Continuous Spe
&
Не ленитесь заполнять поле Subject, иначе при большой почте ваш адресат может пропустить ваше сообщение. Среди наиболее значимых для пользователя полей заголовка можно выделить: адрес и имя отправителя (From:), дата отправки (Date:), адрес получателя (To:), адреса и время прохождения промежуточных узлов, списки лиц (Cc:), кому кроме вас послано это сообщение, предмет сообщения (Subject:), некоторая служебная информация и т.д. Число строк заголовка зависит от программы, реализующей функцию почты и от параметров, определенных пользователем, например, путем задания значений системных переменных.
Практически все пакеты электронной почты имеют возможность переадресовать сообщение другому адресату (Forward); отправить ответ (Replay) пославшему вам сообщение человеку (в этом случае в заголовке появится поле Replay-To); стереть сообщение не читая; в случае смены места работы или длительной командировки установить постоянную переадресацию (на ЭВМ SUN для этого нужно указать адрес нового почтового ящика в файле .forward); записать сообщение в файл (Save имя_файла) или отпечатать его на принтере.
Команда обращение к почтовому серверу обычно имеет вид:
mail местный_адрес@имя_домена, (все что записано после команды mail, является электронным адресом адресата). Например, если вы посылаете сообщение автору, то команда приобретает вид: mail semenov@itep.ru.
Использование промежуточного почтового сервера (mail gateway) несколько усложнит запись электронного адреса (это бывает нужно, например, когда кто-то вне Internet хочет послать сообщение клиенту Internet):
semenov%cl.itep.ru@имя_промежуточного_почтового_сервера
При этом предполагается, что промежуточный почтовый сервер возьмет местную часть адреса, заменит символ "%" на традиционный "@" и перешлет полученное сообщение по данному адресу. Встречаются нотации (хотя сегодня их уже смело можно назвать устаревшими), когда адрес имеет вид:
идентификатор_пользователя%имя_домена
или
идентификатор_пользователя:имя_домена.
При возникновении проблем рекомендуется обращаться к администратору вашей локальной сети.
Если вы любопытны и хотите посмотреть, какие служебные команды выдаются при отправке электронного сообщения, воспользуйтесь командой (в качестве адресата (xxxxxxxx) выберите своего друга, коллегу или знакомого, которому вам нужно что-то сообщить):
mail -v xxxxxxxx@cernvm.cern.ch (обращение к почтовой программе пользователя)
| Subject: Test it. | (пользовательская программа предлагает ввести тему почтового сообщения) |
| Privet... | (текст почтового сообщения) |
| . | (команда отправки сообщения) |
220 dxmint.cern.ch Sendmail ready at Thu, 6 Jul 1995 07:43:27 +200
>>> HELO itep.ru
250 dxmint.cern.ch Hello itep.ru, pleased to meet you
>>> MAIL From:<xxxxxxx@itep.ru>
250 <xxxxxxx@itep.ru>... Sender ok
>>> RCPT To:<xxxxxxxx@crnvma.cern.ch>
250 <xxxxxxxx@crnvma.cern.ch>... Recipient ok
>>> DATA
354 Enter mail, end with "." on line by itself
>>> . (команда завершения сообщения и его отправки адресату)
250 Ok
>>> QUIT
221 dxmint.cern.ch closing connection
xxxxxxxx@crnvma.cern.ch... Sent (сессия завершена)
Именно модификация команды mail -v обеспечивает вывод сообщений, отпечатанных ниже строки "Privet...". Для посылки почтового сообщения используется только пять команд: HELO, MAIL, RCPT, DATA и QUIT. Строчки, начинающиеся с >>>, являются командами, которые посланы SMTP-клиентом (xxxxxxx@ns.itep.ru).
Строки же, которые начинаются с трехзначной цифры, представляют собой коды-отклики SMTP-сервера (в данном случае он имеет имя dxmint.cern.ch), тексты же, следующие после кода-отклика необязательны и могут отсутствовать. Процедура отправки сообщения начинается с того, что клиент выполняет операцию active open для TCP-порта 25. Далее клиент идентифицирует себя командой HELO, выдавая в качестве параметра адрес своего домена. Команда MAIL идентифицирует отправителя, команда RCPT - получателя. Число команд RCPT всегда равно числу получателей. Команда DATA служит для передачи сообщения, а QUIT – для завершения этой процедуры и ликвидации TCP-канала. Посмотрим как выглядит посланное выше сообщение после того, как я его переадресовал себе по адресу semenov@itep.ru:
From xxxxxxxx@crnvma.cern.ch Sat Jul 29 12:15:13 1995
Received: from cearn.cern.ch by ns.itep.ru with SMTP id AA25862
(5.67a8/IDA-1.5 for <SEMENOV@NS.ITEP.RU>); Sat, 29 Jul 1995 12:15:08 +0300
Received: from CERNVM.CERN.CH by CEARN.cern.ch (IBM VM SMTP V2R2)
with BSMTP id 3114; Sat, 29 Jul 95 10:07:15 SET
Received: from CERNVM.cern.ch (NJE origin@CERNVM) by CERNVM.CERN.CH (LMail
1.2a/1.8a) with BSMTP id 4132; Sat, 29 Jul 1995 10:11:12 +0200
Resent-Date: Sat, 29 Jul 95 10:10:30 SET
Resent-From: xxxxxxxx@crnvma.cern.ch
Resent-To: SEMENOV@NS.ITEP.RU
Received: from CERNVM (NJE origin SMTPIBM@CERNVM) by CERNVM.CERN.CH
Lmail V1.2a/1.8a) with BSMTP id 4125; Sat, 29 Jul 1995 10:08:44 +0200
Received: from dxmint.cern.ch by CERNVM.CERN.CH (IBM VM SMTP V2R2) with TCP;
Sat, 29 Jul 95 10:08:43 SET
Received: by ns.itep.ru id AA25665
(5.67a8/IDA-1.5 for xxxxxxxx@cernvm.cern.ch); Sat, 29 Jul 1995 12:12:26 +0300
Date: Sat, 29 Jul 1995 12:12:26 +0300
From: Yuri Semenov <semenov>
Message-Id: <199507290912.AA25665@ns.itep.ru>
To: xxxxxxxx@crnvma.cern.ch
Subject: Test it.
Status: R
--------------------------Original message---------------
Privet...
Текст, выделенный курсивом, представляет собой то, что пришло в CERN. "Накладные расходы" даже здесь значительны, ведь собственно текст состоит из одного слова, следующего после надписи "Original message".
Переадресация же увеличивает издержки еще больше.
При описании DNS говорилось о существовании MX-записей, которые являются одной из разновидностей ресурсных рекордов. MX-записи могут использоваться для доставки почтовых сообщений адресатам, не имеющим прямого доступа к Интернет (RFC-974). Еще одним применением MX-записей является предоставление альтернативного получателя почтовых сообщений в случае, когда ЭВМ-получатель вышла из строя. Для выяснение конкретной конфигурации почтовых серверов можно воспользоваться командой host:
host -a -v -t mx cernvm.cern.ch (команда выданная с терминала, ниже следует отклик на эту команду)
Trying domain "itep.ru"
rcode = 3 (Non-existent domain), ancount=0
Trying null domain
rcode = 0 (Success), ancount=3
The following answer is not authoritative:
| cernvm.cern.ch | 30450 | IN | CNAME | crnvma.cern.ch |
| crnvma.cern.ch | 86042 | IN | MX | 20 dxmint.cern.ch |
| crnvma.cern.ch | 86042 | IN | MX | 40 relay.EU.net |
| cern.ch | 198821 | IN | NS | dxmon.cern.ch |
| cern.ch | 198821 | IN | NS | ns.eu.net |
| cern.ch | 198821 | IN | NS | sunic.sunet.se |
| cern.ch | 198821 | IN | NS | scsnms.switch.ch |
| dxmint.cern.ch | 31455 | IN | A | 128.141.1.113 |
| relay.EU.net | 8411 | IN | A | 192.16.202.2 |
| dxmon.cern.ch | 371619 | IN | A | 192.65.185.10 |
| ns.eu.net | 38326 | IN | A | 192.16.202.11 |
| sunic.sunet.se | 331044 | IN | A | 192.36.148.18 |
| sunic.sunet.se | 331044 | IN | A | 192.36.125.2 |
| scsnms.switch.ch | 28536 | IN | A | 130.59.10.30 |
| scsnms.switch.ch | 28536 | IN | A | 130.59.1.30 |
MX-записи с наименьшим предпочтением (код предпочтения следует сразу за MX) указывают, что сначала следует попытаться переслать сообщение ЭВМ dxmint.cern.ch.
Следующий уровень предпочтения соответствует адресу relay.EU.net. Здесь же вы найдете CNAME-запись (канонические имена DNS). Кроме списка альтернативных почтовых серверов эта команда выдает информацию о списке серверов имен (DNS-серверов). В приведенном примере их четыре, они помечены символами NS и обслуживают домен cern.ch (см.
первую колонку). В нижней части полученной таблицы вы можете найти IP-адреса приведенных MX- и NS-серверов (помечены символом A). Пояснения расшифровки содержимого других колонок можно найти выше, в описании DNS-системы (раздел 1.13 ).
При подготовке текста сообщения вы можете сначала воспользоваться традиционным редактором. Текст будет тогда размещен в файле и при отправке вы можете использовать, например, команду send имя_файла (в системе VMS) или командой GET ввести содержимое файла в текст сообщения (с помощью команды ~r имя_файла в UNIX). Чаще текст сообщения печатается в реальном масштабе времени, непосредственно перед отправкой. В этом случае сигналом конца ввода будет Ctrl-D или символ "." (точка) в начале очередной строки (или Ctrl-Z в VAX/VMS). Если по какой-либо причине вы передумали и не хотите отправлять уже набранное сообщение, процедуру можно прервать, нажав Ctrl-C.
При необходимости посылки одного и того же текста нескольким пользователям можно воспользоваться командой:
mail (или mailx) адрес_1 адрес_2 и т.д.
В этом случае сообщение будет послано по всем перечисленным адресам. Формат этой операции заметно варьируется для разных ЭВМ и программных пакетов. Вместо адресов могут использоваться псевдонимы, что несколько облегчает задачу. Для хранения псевдонимов (alias) служит специальный служебный файл. За описанием работы с псевдонимами вынужден отослать вас к описанию почтового пакета, с которым вы работаете.
На последней строке будет напечатан символ &, который указывает, что система ждет ввода команды (просмотр почты). Уход из mail производится по команде q (quit). В ответ на & вы можете ввести следующие команды (набор команд и их синтаксис может варьироваться от ЭВМ к ЭВМ и от реализации к реализации, см. табл. 4.5.10.1).
При работе в Unix в процессе печатания текста сообщения вы можете выдать почтовой программе определенные команды. Такие команды начинаются с символа "~" (тильда). Ниже приведен список таких команд, текст набранный курсивом, означает, что вместо него должны быть впечатаны имена, адреса и т.д.Многоточие показывает, что может быть введено более одного имени, адреса и пр.
Схема подключения модема
Рисунок 4.3.7.2 Схема подключения модема

Модем подключается к ЭВМ (см. Рисунок 4.3.7.2) через последовательный интерфейс RS-232c (существуют версии модемов, способных работать и с параллельным интерфейсом, который обладает почти в 3 раза большим быстродействием). Ниже в таблице представлена разводка для 9- и 25- контактных разъемов (таблица 4.3.7.3), используемых для последовательных интерфейсов (синхронные модемы используют только 25-контактный разъем).
Схема подключения оборудования ADSL (IF – ADSL/Ethernet интерфейс)
Рисунок 4.3.7.4. Схема подключения оборудования ADSL (IF – ADSL/Ethernet интерфейс)
В качестве внешней сети на Рисунок 4.3.7.4 может использоваться практически любая достаточно быстродействующая среда, например ATM. Выбор того или иного внешнего канала зависит от стоящей задачи. Так файл размером 30 Кбайт (среднего размера электронное сообщение) будет передан через модем V.34 за 8,3 сек, по каналу ISDN – за 1,9 сек, по каналу HDSL – за 0,16 сек, а по каналу VDSL – быстрее 0,04 сек. В большинстве случаев вполне приемлемым можно считать уже первые два варианта. Деловой электронный документ имеет размер порядка 250 Кбайт. Здесь для пересылки его указанными способами потребуется уже, соответственно: 69,4; 15,6; 1,3 и 0,3 секунды. Более чем минутное время доставки (в реальности это обычно больше) в некоторых случаях не будет признано удовлетворительным. Время пересылки рентгенограммы (~5 Мбайт) будет пропорционально больше (23 мин, 5,2 мин, 26 сек и 6,5 сек). Считается, что приемлемым временем отклика на команду следует считать 3 секунды, а до 80% трафика локальной сети составляет внешний поток данных. Если же стоит задача организации видеоконференции (384 Кбит/с), то решение проблемы возможно уже только с использованием каналов xDSL. Учитывая стремительный рост потребной пропускной способности каналов, не трудно предсказать перспективность внедрения технологии xDSL.
Пример использования модема ADSL для подключения телевизора и модема к широкополосному каналу представлен на Рисунок 4.3.7.5. Управляющий канал на 16 кбит/с может использоваться для целей интерактивного телевидения (смотри раздел "Методы преобразования и передачи изображения").

Схема подключения телевизора и телефона через модем ADSL
Рисунок 4.3.7.5. Схема подключения телевизора и телефона через модем ADSL
Схема расположения ячеек при сотовой связи
Рисунок 4.1.8.1.1. Схема расположения ячеек при сотовой связи

Светлыми кружками отмечены реальные границы ячеек, их перекрытие должно обеспечить перекрытие всей зоны телекоммуникаций. В центре ячейки находится базовая станция ретранслятор. Такая станция содержит в себе ЭВМ и приемо-передатчик, соединенный с антенной. Такие системы могут обслуживать пейджерную или мобильную телефонную сеть. Пейджерные каналы однонаправлены а телефонные двунапрвлены (см. Рисунок 4.1.8.1.2). Пейджинговые системы требуют небольшой полосы пропускания. А одно сообщение редко содержит более 30 байт. Большинство современных пейджигновых систем работает в частотном диапазоне 930-932 МГц (старые занимали 150-174 МГц).
Схема соединения двух модемов (Ми М через канал
Рисунок 4.3.7.1. Схема соединения двух модемов (М1 и М2) через канал

В качестве последовательного интерфейса может выступать RS-232, V.35, G.703 и т.д.. Все модемы содержат в себе управляющий микропроцессор, постоянную память (ROM), куда записано фирменное программное обеспечение и интерпретатор команд, энергонезависимую память (NVRAM - non-volatile RAM), которая хранит конфигурационные профайлы модема, телефонные номера и т.д., буфер ввода/вывода (128-256 байт), сигнальный процессор (DSP), включающий в себя модулятор и демодулятор, интерфейс для связи с ЭВМ (RS-232) и оперативную память.
Первоначально модемы использовались для связи через традиционные коммутируемые телефонные линии. Так как такие линии содержат только два провода, а информационный обмен должен происходить в обоих направлениях одновременно, возникает проблема отделения передаваемого сигнала от приходящего из вне (подавление эхо; см. раздел 2.1). Для выделенных четырехпроводных линий эта проблема значительно упрощается, здесь прием и передача осуществляется по разным скрученным парам и эхо возникает лишь из-за перекрестных наводок (NEXT). Модемы подключаются к последовательным интерфейсам ЭВМ (COM-порт, RS-232), иногда для подключения модема используется специальная плата расширения, которая имеет дополнительные буферы и помогает достичь большего сжатия информации, существуют модемы, подключаемые и к параллельному порту ЭВМ. Модемы (микромодемы) могут работать не только через общедоступную телефонную сеть, они могут найти применение при соединении терминалов или ЭВМ в пределах организации, если расстояние между ними исчисляются сотнями метров (а иногда и километрами). В этом случае они помогают повысить надежность связи и исключить влияние разностей потенциалов между земляными шинами соединяемого оборудования. Микромодемы не требуют подключения к сети переменного тока, так как получают питание через разъем последовательного интерфейса (RS-232).
Все протоколы модемов утверждаются международным телекоммуникационным союзом (ITU), ранее за это был ответственен Консультативный комитет CCITT. Асинхронные модемы поддерживают определенный набор команд, который был впервые применен фирмой hayes в модеме smartmodem 1200. Модемы, придерживающиеся этого стандарта, называются Hayes-совместимыми. Совместимость предполагает идентичность функций первых 28 управляющих регистров модема (всего модем может иметь более сотни регистров). Почти все внутренние команды начинаются с символов AT (attention) и имеют по три символа. По этой причине их иногда называют AT-командами. Hayes-совместимость гарантирует, что данный модем будет работать со стандартными терминальными программами. Реально набор команд для модемов разных производителей варьируется в широких пределах. Для синхронных модемов набор команд регламентируется стандартом V.25bis. Ниже (таблица 4.3.7.1) приводится перечень стандартных модемных протоколов и стандартов.
Схема связи автономных систем
Рисунок 4.4.11.4.1. Схема связи автономных систем

Пусть имеются две автономные системы ASX и ASY, обменивающиеся маршрутной информацией. ASX знает, как можно достичь сети Net1, которая может и не принадлежать ASX. Аналогично ASY знает, как послать пакет для сети Net2.
net1 .... ASX ASY ...... Net2
Для того чтобы пакеты попали из Net1 в Net2 через ASX и ASY, автономная система ASX должна анонсировать сеть Net1 автономной системе ASY, используя один из внешних протоколов маршрутизации (EGP или BGP), а ASY должна воспринять эту информацию и использовать. Предметом маршрутной политики в этом случае является решение ASX послать маршрутную информацию ASY, а также решение ASY эту информацию принять и использовать. Не существует никаких правил, которые бы вынуждали ASX и ASY к принятию таких решений. Таким образом, протокол маршрутизации определяет формат маршрутной информации, способ ее пересылки и хранения, но решения о ее посылке той или иной AS, а также решение об использовании маршрутной информации, поступающей извне остаются в руках администратора AS.
Так как все существующие протоколы маршрутизации используют при работе с пакетами только адрес места назначения, разделить поток пакетов кроме как по этому параметру не возможно. Если пакеты с одним и тем же адресом места назначения попали в общий маршрутизатор, AS или канал связи, они обречены далее двигаться вместе.
Особый случай составляет топология, при которой две as имеют много возможных маршрутов связи с различными политиками маршрутизации.
Символьный набор
3. Символьный набор
Секция 'charset' кодировочного слова специфицирует символьный набор, соответствующий незакодированному тексту. 'charset' может представлять любой символьный набор, разрешенный параметром "charset" MIME части тела "text/plain", или любой символьный набор с именем, зарегистрированным IANA для использования с типом содержимого text/plain MIME.
Некоторые символьные наборы используют технику переключения кодов для перехода между режимом "ASCII" и другими режимами. Если текст в кодировочном слове содержит последовательность, которая заставляет интерпретатор символьного набора переключиться из режима ASCII, он должен содержать дополнительные управляющие коды, которые переключат систему в ASCII-режим в конце кодировочного слова.
Когда имеется возможность использования более одного символьного набора для представления текста в кодировочном слове и в отсутствии частного соглашения между отправителем и получателем сообщения, рекомендуется, чтобы предпочтительно использовались члены символьного семейства ISO-8859-*.
Синхронизация и описание элементарных потоков
8.2.2. Синхронизация и описание элементарных потоков

Синтаксис кодированных слов (encoded-words)
2. Синтаксис кодированных слов (encoded-words)
'Кодировочное слово' определено согласно следующей ABNF-грамматике. Используется нотация RFC-822, за исключением того, что символы “white space” (HT и SP) не должны появляться между компонентами кодировочного слова.
encoded-word = "=?" charset "?" encoding "?" encoded-text "?="
charset = token |
; см. секцию 3 |
encoding = token |
; см. секцию 4 |
token = 1*
especials = "(" / ")" / "" / "@" / "," / ";" / ":" / " / "/" / "[" / "]" / "?" / "." / "="
encoded-text = 1*
|
; (см. "Использование encoded-words в заголовках сообщений", часть 5) |
Слова 'encoding' и 'charset' не зависят от регистра, в котором напечатаны. Таким образом символьный набор с именем "ISO-8859-1" эквивалентен "ISO-8859-1", а кодирование с именем "Q" может записываться как "Q" или "q".
'Кодировочное слово' (encoded-word) не может быть длиннее 75 символов, включая 'charset', 'encoding', 'encoded-text' и разделители. Если желательно закодировать текст больший, чем 75 символов, можно использовать несколько кодировочных слов, разделенных CRLF SP.
Хотя ограничений на длину многострочного поля заголовка, каждая строка поля заголовка, которая содержит одно или более кодировочных слов, ограничена 76 символами.
Ограничения длины введены, для того чтобы облегчить сетевое взаимодействие различных почтовых шлюзов и упростить работу программ разборки кодировочных слов.
'Кодировочные слова' сконструированы так, чтобы быть узнаваемыми как “атомы” программой грамматического разбора RFC-822. Как следствие, незакодированные символы SP и HT в пределах кодировочных слов запрещены. Например, символьная последовательность
=?iso-8859-1?q?this is some text?=
будет воспринята программой разборки RFC-822 как четыре атома, а не как один атом, или как ''кодировочное слово” (в случае программы разборки, воспринимающей кодировочные слова). Правильный способ закодировать строку "this is some text" – это кодировать и сами пробелы, например:
=?iso-8859-1?q?this=20is=20some=20text?=
Синтетические объекты
9.3. Синтетические объекты
Синтетические объекты образуют субнабор большого класса компьютерной графики, для начала будут рассмотрены следующие синтетические визуальные объекты:
• Параметрические описания
a) синтетического лица и тела (анимация тела в версии 2)
b) Кодирование статических и динамических сеток Static и Dynamic Mesh Coding with texture mapping
• Кодирование текстуры для приложений, зависимых от вида
