Базовое приложение
Начнем с создания базового приложения, класса с именем OrderProcessor.
import javax.xml.parsers.DocumentBuilder; import javax.xml.parsers.DocumentBuilderFactory; import java.io.File; import org.w3c.dom.Document; public class OrderProcessor { public static void main (String args[]) { File docFile = new File("orders.xml"); Document doc = null; try { DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance(); DocumentBuilder db = dbf.newDocumentBuilder(); doc = db.parse(docFile);
} catch (Exception e) { System.out.print("Problem parsing the file: "+e.getMessage()); } } }
Сначала Java-код импортирует необходимые классы, а затем создает приложение OrderProcessor. Примеры в этом учебнике рассматривают один файл, так что для краткости приложение содержит прямую ссылку на него.
Так как объект Document может быть использован позже, приложение определяет его вне блока try-catch.
В блоке try-catch приложение создает объект DocumentBuilderFactory, который затем используется для создания DocumentBuilder. Наконец, DocumentBuilder разбирает файл для создания Document.
Базовые типы узлов: документ, элемент, атрибут и текст
Наиболее распространенными типами узлов в XML являются:
Элементы: Элементы являются базовыми строительными блоками XML. Обычно элементы имеют потомков, которыми являются другие элементы, текстовые узлы или их комбинация. Элементные узлы также являются единственным типом узлов, имеющим атрибуты. Атрибуты: Узлы атрибутов содержат информацию об элементном узле, но не рассматриваются как потомки элемента, как в:
<customerid limit="1000" >12341</customerid>
Текст: Текстовый узел - это именно текст. Он может содержать информацию или только пропуск. Документ: Узел документа является общим предком для всех других узлов в документе.
Базовый XML-файл
Примеры во всем этом учебнике используют XML-файл, который содержит приведенный ниже пример кода, представляющий заказы, проходящие через торговую систему. Кратко, основными частями XML-файла являются:
XML-объявление: Основное объявление <?xml version"1.0"?> определяет этот файл, как XML-документ. Не является общепринятым задание кодировки в объявлении, как показано ниже. Здесь не имеет значения, какой язык или кодировку использует XML-файл, парсер в состоянии читать его правильно, пока он понимает данную кодировку. Объявление DOCTYPE: XML является удобным способом для обмена данными между людьми и машинами, но чтобы обмен работал гладко, необходим общий словарь. Необязательное объявление DOCTYPE может быть использовано для указания документа - в данном случае, orders.dtd - с которым файл может быть сравнен, чтобы убедиться, что в нем нет лишней или недостающей информации (например, отсутствует userid или ошибочное имя элемента). Документы, обработанные таким образом, называются правильными (valid) документами. Успешная проверка правильности не является обязательной для XML, и я фактически буду оставлять объявление DOCTYPE за документом в последующих примерах. Сами данные: Данные в XML-документе должны содержаться внутри единственного корневого элемента, такого, как элемент orders ниже. Чтобы XML-документ мог обрабатываться, он должен быть правильно форматированным (well-formed).
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE ORDERS SYSTEM "orders.dtd"> <orders>
<order> <customerid limit="1000">12341</customerid> <status>pending</status> <item instock="Y" itemid="SA15"> <name>Silver Show Saddle, 16 inch</name> <price>825.00</price> <qty>1</qty> </item> <item instock="N" itemid="C49"> <name>Premium Cinch</name> <price>49.00</price> <qty>1</qty> </item> </order> <order> <customerid limit="150">251222</customerid> <status>pending</status> <item instock="Y" itemid="WB78"> <name>Winter Blanket (78 inch)</name> <price>20</price> <qty>10</qty> </item> </order> </orders>
В DOM работа с XML-информацией означает разбиение ее сначала по узлам.
Что такое DOM?
Основой Расширяемого Языка Разметки, Extensible Markup Language или XML является DOM. XML-документы содержат иерархию информационных единиц, называемых узлами; DOM является способом описания этих узлов и отношений между ними.
Вдобавок к ее роли концептуального описания XML-данных, DOM является серией Рекомендаций, вырабатываемых Консорциумом World Wide Web (W3C). DOM начиналась как способ для Web-браузеров для идентификации и манипулирования элементами на странице - функциональности, которая еще предшествовала вовлечению в нее W3C и известна, как "DOM, Уровень 0".
Действующая Рекомендация DOM, сейчас она находится на Уровне 2 (на момент написания учебника Уровень 3 находится на последнем этапе разработки), является API, который определяет объекты, представляемые в XML-документе, а также методы и свойства, которые используются для доступа к ним и манипулирования ими.
Этот учебник демонстрирует API Ядра DOM (DOM Core) как средство чтения и манипулирования XML-данными на примере серии заказов в системе торговли. Он также обучает вас, как создавать объекты DOM в вашем собственном проекте для хранения данных и работы с ними.
Что такое пространство имен?
Одно из главных усовершенствований между DOM Уровня 1 и DOM Уровня 2 является добавление поддержки пространств имен. Поддержка пространств имен позволяет разработчикам использовать информацию из разных источников или в разных целях без конфликтов.
Концептуально пространства имен являются зонами, в которых все имена должны быть уникальны.
Например, я работаю в офисе и у меня то же имя, что и у клиента. Если я где-то в офисе, и секретарь говорит: "Ник, возьми трубку на 1-й линии", - каждый понимает, что она имеет в виду меня, потому что я нахожусь в "пространстве имен офиса". Аналогично, если она говорит "Ник звонит по 1-й линии", - каждый знает, что она говорит о клиенте, потому что звонящий находится вне пространства имен офиса.
С другой стороны, если я нахожусь вне офиса, и она делает такое же заявление, возможно недоразумение, поскольку существуют две возможности.
Те же проблемы возникают, когда XML-данные из разных источников комбинируются (как в информации о кредитоспособности в файле-примере, подробно рассматриваемом в этом учебнике позже).
Для обучения
Для изучения основ XML прочитайте учебник "" на (developerWorks, август 2002). Перевод на нашем сайте - "" Посмотрите страницу для Рекомендаций DOM для , и . В советах Brett McLaughlin "" изучается, как перемещать узлы из одного документа в другой без возникновения общих исключений (developerWorks, март 2001). В советах Brett McLaughlin "" объясняется, как превратить Document DOM в поток SAX или в документ JDOM (developerWorks, апрель 2001). Прочитайте советы Read Nicholas ""(developerWorks, октябрь 2002), там есть альтернативный способ просмотра документа при помощи модуля DOM Уровня 2 Traversal, и его же совет "", где эта возможность расширяется (developerWorks, ноябрь 2002). Одной из альтернатив DOM является Simple API for XML или SAX. SAX дающий вам возможность обрабатывать документ по мере его чтения, что исключает необходимость ожидать, пока все будет сохранено, прежде, чем предпринимать действия. Больше о SAX вы можете найти в учебнике на developerWorks "" (изменено в июле 2003). Перевод на нашем сайте - "" Закажите книгу Nicholas Chase "", автора этого учебника (http://www.amazon.com/exec/obidos/ASIN/0672324229/ref=nosim/thevanguardsc-20). Посмотрите, как вы можете стать (http://www-1.ibm.com/certify/certs/adcdxmlrt.shtml).
Для получения продуктов и технологий
Выгрузите Java 2 SDK, Standard Edition версии 1.4.2 (). Если вы используете более старую версию технологии Java, выгрузите с проекта Apache Xerces-Java () или Sun Java API for XML Parsing (JAXP), часть Java Web Services Developer Pack (). Выгрузите Xerces parser for C++ из проекта Apache XML (). Выгрузите Xerces parser for Perl из проекта Apache XML (). Получите СУБД IBM DB2 (), которая обеспечивает не только хранилище реляционных баз данных, но также и относящиеся XML инструменты, такие как DB2 XML Extender (), которые обеспечивают мост между XML и реляционными системами. Посетите DB2 content area, чтобы больше узнать о DB2 (/db2).
Добавление узлов: добавление узлов в документ
Вы можете создать новый Node многими способами, и этот пример применяет несколько из них. Во-первых, объект Document может создавать новый текстовый узел со значением totalString. Новый Node теперь существует, но еще никуда не присоединен к Document. Новый элемент total создается аналогично, и он также поначалу свободный.
Другой способ добавление узла - применение appendChild(), как показано здесь для нового элемента total.
Наконец, приложение может использовать insertBefore() для добавления нового элемента Document, указывая новый Node и предшествующий Node.
Прохождение через документ проверяет изменения.
... changeOrder(root, "status", "processing"); NodeList orders = root.getElementsByTagName("order"); for (int orderNum = 0; orderNum < orders.getLength(); orderNum++) { ... String totalString = new Double(total).toString(); Node totalNode = doc.createTextNode(totalString); Element totalElement = doc.createElement("total"); totalElement.appendChild(totalNode); thisOrder.insertBefore(totalElement, thisOrder.getFirstChild());
} stepThrough(root);
...

Добавление узлов: подготовка данных
Иногда необходимо не изменить существующий узел, а добавить узел, и у вас есть несколько способов сделать это. В нашем примере приложение вычисляет общую стоимость каждого заказа и добавляет в order элемент total. Оно получает общую стоимость, выбирая каждый заказ и проходя через все его составляющие, чтобы получить стоимость составляющей, а затем итоговую стоимость их всех. Затем приложение добавляет новый элемент в заказ (см. код ниже).
Сначала приложение выбирает элементы order так же, как оно выбирало элементы status. Затем перебирает каждый из этих элементов.
Для каждого из этих order приложению нужен NodeList из его составляющих item, так что приложение должно сначала преобразовать узел (Node) order в Element, чтобы использовать getElementsByTagName().
Приложение затем может перебрать составляющие item для выбранного order. Каждая из них преобразуется в Element, так что из него можно выбрать по имени price и qty. Приложение делает это при помощи метода getElementsByTagName(), и поскольку их всего по одному в каждом item, оно может прямо брать item(0), первую составляющую результирующего NodeList. Этот первый элемент представляет элемент price (или qty). Из него извлекается значение текстового узла.
Значение текстового узла имеет тип String, приложение затем преобразует его в double, чтобы сделать возможным вычисление.
Когда приложение заканчивает проверку всех составляющих для каждого заказа, total типа double представляет итоговое значение. Затем total преобразуется в String, так что оно может использоваться как содержимое нового элемента, <total>, который в конечном счете присоединяется к order.
... changeOrder(root, "status", "processing"); NodeList orders = root.getElementsByTagName(" order "); for (int orderNum = 0; orderNum < orders.getLength(); orderNum++) { Element thisOrder = (Element)orders.item(orderNum); NodeList orderItems = thisOrder.getElementsByTagName("item"); double total = 0; for (int itemNum = 0; itemNum < orderItems.getLength(); itemNum++) { // Total up cost for each item and // add to the order total //Get this item as an Element Element thisOrderItem = (Element)orderItems.item(itemNum); //Get pricing information for this Item String thisPrice = thisOrderItem.getElementsByTagName("price").item(0) .getFirstChild().getNodeValue(); double thisPriceDbl = new Double(thisPrice).doubleValue(); //Get quantity information for this Item String thisQty = thisOrderItem.getElementsByTagName("qty").item(0) .getFirstChild().getNodeValue(); double thisQtyDbl = new Double(thisQty).doubleValue(); double thisItemTotal = thisPriceDbl*thisQtyDbl; total = total + thisItemTotal; } String totalString = new Double(total).toString();
} ...
DOM как API
Начиная с DOM Уровня 1, DOM API содержит интерфейсы, которые представляют всевозможные типы информации, которые могут быть найдены в XML-документе, такие, как элементы и текст. Он также включает в себя методы и свойства, необходимые для работы с этими объектами.
Уровень 1 включает в себя поддержку XML 1.0 и HTML, в которой каждый элемент HTML представляется как интерфейс. Он включает в себя методы для добавления, редактирования, перемещения и чтения информации, содержащейся в узлах и т.д. Он, однако, не включает в себя поддержку пространств имен XML, которые обеспечивают возможность сегментировать информацию внутри документа.
Поддержка пространств была добавлена в DOM Уровня 2. Уровень 2 расширяет Уровень 1, позволяя разработчикам обнаруживать и использовать информацию пространств имен, которая может быть применима к узлу. Уровень 2 добавляет также несколько модулей поддержки Каскадируемых Таблиц Стилей, Cascading Style Sheets (CSS), событий и расширенных манипуляций с деревом.
DOM Уровня 3, в настоящее время находящийся на последнем этапе разработки, включает в себя улучшенную поддержку объекта Document (предыдущие версии оставляли это на усмотрение приложений, что делало затруднительным создание родовых приложений), расширенную поддержку пространств имен, и новые модули для загрузки и сохранения документов, проверки правильности и XPath, средства для выбора узлов, используемые в XSL Transformations и других технологиях XML.
Модуляризация DOM означает для разработчиков, что вы должны знать, поддерживаются ли те возможности, которые вы хотите использовать, той реализацией DOM, с которой вы работаете.
DOM как структура
Прежде, чем начинать работу с DOM, стоит получить представление о том, что она на самом деле представляет. Объект DOM Document является коллекцией узлов или порций информации, организованных в иерархию. Эта иерархия позволяет разработчику двигаться по дереву в поисках нужной информации. Анализ структуры обычно требует, чтобы был загружен полный документ, и иерархия была построена до начала работы. Поскольку DOM основывается на иерархии информации, про нее говорят, что она древовидно-базированная или объектно-базированная.
Для исключительно больших документов разбор и загрузка полного документа может быть медленной и ресурсоемкой, так что для работы с такими данными могут оказаться лучшими другие средства. Событийно-базированные модели, такие, как Simple API for XML (SAX), работают на потоке данных, обрабатывая его по мере поступления. (SAX является темой другого учебника и других статей в XML-зоне developerWorks. Дополнительную информацию см. в .) Событийно-базированный API обходит необходимость построения дерева в памяти, но фактически не позволяет разработчику изменять данные в исходном документе.
С другой стороны, DOM также обеспечивает API, который позволяет разработчику добавлять или удалять узлы в любой точке дерева в надлежащим образом созданном приложении.
Инструменты
Примеры в этом учебнике, если вы решите их выполнить, требуют установки и правильной работы следующего инструментария. Выполнение примеров не является обязательным требованием для понимания.
Текстовый редактор: XML-файлы являются простым текстом. Для создания и чтения их все, что вам нужно, это - текстовый редактор. Java 2 SDK, Standard Edition version 1.4.x: поддержка DOM встроена в последние версии технологии Java (доступны на ), так что у вас нет необходимости устанавливать какие-либо дополнительные классы. (Если вы используете более раннюю версию языка Java, такую, как Java 1.3.x, вам также нужен XML-парсер, такой, как Xerces-Java из проекта Apache (доступен на ), или Java API for XML Parsing (JAXP) фирмы Sun, часть Java Web Services Developer Pack (доступен на ). Другие языки: Если вы решите адаптировать примеры, реализации DOM также доступны и в других языках программирования. Вы можете выгрузить реализации парсера Xerces для C++ и Perl с Apache Project на .
Исключения парсера
При всех разнообразных возможностях в создании парсера многие вещи могут быть неправильно сделаны. Как показано в примере, приложение сводит все это в единственное родовое Exception, которое не может быть достаточно полезным в смысле отладки.
Чтобы лучше диагностировать проблемы, вы можете вылавливать специфические исключения, относящиеся к различным аспектам создания и использования парсера:
... try { DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance(); DocumentBuilder db = dbf.newDocumentBuilder(); doc = db.parse(docFile); } catch (javax.xml.parsers.ParserConfigurationException pce) { System.out.println("The parser was not configured correctly."); System.exit(1); } catch (java.io.IOException ie) { System.out.println("Cannot read input file."); System.exit(1); } catch (org.xml.sax.SAXException se) { System.out.println("Problem parsing the file."); System.exit(1); } catch (java.lang.IllegalArgumentException ae) { System.out.println("Please specify an XML source."); System.exit(1);
} ...
Когда парсер создал документ, приложение может проходить через него для обработки данных.
Использование getFirstChild() и getNextSibling()
Отношения предок-потомок и братские отношения предлагают альтернативный способ для перебора всех потомков данного узла, который может быть более подходящим в некоторых ситуациях, например, когда для понимания данных важны отношения и порядок, в котором появляются потомки.
На Шаге 3, цикл for начинается с первого потомка корня. Приложение перебирает "братьев" первого потомка, пока все они не будут обработаны. При выполнении каждой итерации цикла приложение выбирает объект Node, выводит его имя и значение. Заметьте, что в число пяти потомков orders входят элементы order и три текстовых узла. Заметьте также, что элементы имеют значение null, а не текст, как ожидалось. Эти текстовые узлы являются потомками элементов, которые имеют в качестве своих значений реальное содержимое.
... import org.w3c.dom.Node;
... //STEP 3: Step through the children for (Node child = root.getFirstChild(); child != null; child = child.getNextSibling()) { System.out.println(start.getNodeName()+" = " +start.getNodeValue()); }
} } ...
Изменение значения в узле
Просмотр содержимого XML-документ полезен, но когда вы имеете дело с полнофункциональным приложением, вам может понадобиться изменять данные, добавляя, перемещая или удаляя информацию. Возможность редактирования данных также важна при создании новых XML-документов. Простейшим из таких изменений является изменение текстового содержания элемента.
Нашей целью является изменить значение текстового узла элемента, в данном случае установкой status для каждого order в "processed", а затем вывести новые значения на экран.
Метод changeOrder() вызывается с передачей ему начального узла (root) в качестве параметра, а также имени изменяемого элемента и измененного значения.
changeOrder() сначала проверяет имя узла, чтобы увидеть, тот ли элемент, который редактируется. Если это так, приложению нужно изменить значение не этого узла, а его первого потомка, поскольку этот первый потомок является текстовым узлом, который на самом деле содержит содержимое элемента.
В противном случае приложение проверяет каждый потомок так же, как это делалось при прохождении по документу в первый раз.
Когда изменения выполнены, значение проверяются при помощи getElementsByTagName(). Этот метод возвращает список всех дочерних элементов с заданным именем, таким, как status. Приложение может затем проверить значения в списке, чтобы убедиться, что метод changeOrder() работает.
... public class OrderProcessor { private static void changeOrder (Node start, String elemName, String elemValue) { if (start.getNodeName().equals(elemName)) { start.getFirstChild().setNodeValue(elemValue); } for (Node child = start.getFirstChild(); child != null; child = child.getNextSibling()) { changeOrder(child, elemName, elemValue); } }
... public static void main (String args[]) { ... // Change text content changeOrder(root, "status", "processing"); NodeList orders = root.getElementsByTagName("status"); for (int orderNum = 0; orderNum < orders.getLength(); orderNum++) { System.out.println(orders.item(orderNum) .getFirstChild().getNodeValue()); }
} }

Заметьте, что приложение выбирает узлы status даже, несмотря на то, что они являются "внуками" корневого элемента, а не непосредственными его "детьми". getElementsByTagName() проходит через документ и находит все элементы с определенным именем.
Карта DOM

Работа с DOM затрагивает несколько концепций, которые работают вместе. Вы изучите отношения между ними в этом учебнике.
Парсер - это программное приложение, которое предназначено для того, чтобы анализировать документ - в нашем случае XML-файл - и делать что-то определенное с его информацией. В событийно-базированном API, таком, как SAX, парсер события некоторому слушателю. В древовидно-базированном API , таком, как DOM, парсер строит в памяти дерево данных.
Менее распространенные типы узлов: CDATA, комментарии, инструкции обработки и фрагменты документа
Другие типы узлов используются не так часто, но все равно важны в некоторых ситуациях. В их число входят:
CDATA: Сокращение от Character Data (символьные данные), это узел, содержащий информацию, которая не должна анализироваться парсером. Вместо этого она должна просто передаваться как обычный текст. Например, в ней может быть записан HTML для специальных целей. При нормальных обстоятельствах процессор должен пытаться создать элементы из каждого записанного тега, который даже может не быть правильно форматированным. Эти проблемы могут быть обойдены применением секций CDATA. Эти секции записываются в специальной нотации:
<[CDATA[
<b>Important: Please keep head and hands inside ride at <i>all times</i>. </b> ]]>
Комментарии: Комментарии включают в себя информацию о данных и обычно игнорируются приложением. Они записываются как:
<!-- This is a comment. -->
Инструкции обработки: Инструкции обработки - это информация, специально адресованная приложению. Некоторыми примерами являются коды, которые должны быть выполнены, или информация о том, где найти таблицу стилей. Например:
<? xml-stylesheet type="text/xsl" href="foo.xsl"? >
Фрагменты документа: Чтобы быть правильно форматированным, документ должен иметь только один корневой элемент. Иногда при работе с XML должны временно создаваться группы элементов, для которых нет необходимости удовлетворять этому требованию. Фрагмент документа выглядит так:
<item instock="Y" itemid="SA15"> <name>Silver Show Saddle, 16 inch</name> <price>825.00</price> <qty>1</qty> </item> <item instock="N" itemid="C49"> <name>Premium Cinch</name> <price>49.00</price> <qty>1</qty> </item>
Другие типы узлов включают в себя сущности, узлы ссылок на сущности и нотации. Одним из способов дополнительной организации XML-данных является применение пространств имен.
Нужен ли мне этот учебник?
Этот учебник предназначен для разработчиков, которые понимают базовые концепции XML и готовы переходить к кодированию приложений для манипулирования XML при помощи DOM. Мы предполагаем, что вы знакомы с такими концепциями, как правильное форматирование и теговой природой XML документа. (Если нужно, вы можете узнать об основах XML из учебника .)
Все примеры в этом учебнике приводятся для языка Java, но вы можете выработать понимание DOM даже, если вы не выполните сами эти примеры. Концепции и API для кодирования приложений, которые манипулируют XML-данными в DOM, одни и те же для любого языка или платформы и е включают в себя программирования графического пользовательского интерфейса.
Об авторе
Nicholas Chase, автор , участвовал в разработке Web-сайтов для таких компаний, как Lucent Technologies, Sun Microsystems, Oracle и Tampa Bay Buccaneers. Nick был преподавателем физики в высшей школе, менеджером низшего звена по использованию радиоактивных отходов, редактором онлайнового журнала научной фантастики, инженером по мультимедиа и инструктором по Oracle. В последнее время он - руководитель технического отдела фирмы Site Dynamics Interactive Communications в Clearwater, Florida, USA и автор четырех книг по Web-разработке, включая (Sams). Он любит слышать отзывы читателей, с ним можно связаться по адресу nicholas@nicholaschase.com.
Определение доступности свойств
Модульная структура Рекомендаций DOM дает возможность производителям реализаций перебирать и выбирать, какой раздел включать в их продукт, так что может быть необходимым определить, доступно ли данное конкретное свойство, прежде чем пытаться использовать его. Этот учебник использует только API Ядра DOM (Core DOM) Уровня 2, но вам стоит понимать, как может быть свойство обнаружено, когда вы перейдете к собственным проектам.
Одним из интерфейсов, определенных в DOM, является DOMImplementation. Используя метод hasFeature(), вы можете определить, поддерживается или нет конкретное свойство. В DOM Уровня 2 нет стандартного способа создания DOMImplementation, но следующий код демонстрирует, как применить hasFeature() для определения, поддерживается ли модуль CSS DOM Уровня 2 в приложении Java.
import javax.xml.parsers.DocumentBuilderFactory; import javax.xml.parsers.DocumentBuilder; import org.w3c.dom.DOMImplementation; public class ShowDomImpl { public static void main (String args[]) { try { DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance(); DocumentBuilder docb = dbf.newDocumentBuilder(); DOMImplementation domImpl = docb.getDOMImplementation(); if (domImpl.hasFeature("StyleSheets", "2.0") ) { System.out.println("Style Sheets are supported."); } else { System.out.println("Style Sheets are not supported."); } } catch (Exception e) {} } }
(DOM Уровня 3 будет включать в себя стандартные средства для создания DOMImplementation.)
Этот учебник использует один документ для демонстрации объектов и методов API Ядра DOM.
Определение пространств имен
Для данных могут быть определены также и другие пространства имен. Например, созданием пространства имен rating вы можете добавить информацию оценки кредитоспособности в текст заказа, не беспокоясь об имеющихся данных.
Пространство имен вместе с алиасом создаются обычно (но не обязательно) в корневом элементе документа. Этот алиас используется как префикс для элементов и атрибутов - при необходимости, если используется более одного пространства имен, - чтобы задать правильное пространство имен.
Рассмотрим код, приведенный ниже. Пространство имен и алиас, rating, использованы для создания элемента creditRating.
<?xml version="1.0" encoding="UTF-8"?> <orders xmlns="http://www.nicholaschase.com/orderSystem.html" xmlns:rating="http://www.nicholaschase.com/rating.html" > <order> <customerid limit="1000"> 12341 <rating: creditRating>good</rating: creditRating> </customerid> <status> pending </status> <item instock="Y" itemid="SA15"> <name> Silver Show Saddle, 16 inch </name> <price> 825.00 </price> <qty> 1 </qty> </item> ... </orders>
Информация пространства имен может быть получена для узла после того, как документ был разобран.
Подготовка данных
Мы в нашем учебнике рассмотрели, как выбирать, работать и манипулировать с XML-данными. Для завершения цикла вы должны также уметь выводить XML.
В случае этого учебника целевым выводом является файл, в котором просто перечисляются все заказы по мере того, как они поступают или отвергаются на основе кредита покупателя и customerid.
<?xml version="1.0" encoding="UTF-8"?> <processedOrders> <order> <status>PROCESSED</status> <customerid>2341</customerid> <amount>874.00</amount> </order> <order> <status>REJECTED</status> <customerid>251222</customerid> <amount>200.00</amount> </order> </processedOrders>
Сначала приложение создает объект Document для вывода. Для удобства тот же самый DocumentBuilder, который создавал исходный Document, может создавать и новый.
... public static void main (String args[]) { File docFile = new File("orders.xml"); Document doc = null; Document newdoc = null;
try { DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance(); DocumentBuilder db = dbf.newDocumentBuilder(); doc = db.parse(docFile); newdoc = db.newDocument();
} catch (Exception e) { System.out.print("Problem parsing the file: "+e.getMessage()); } ... thisOrder.insertBefore(totalElement, thisOrder.getFirstChild()); } Element newRoot = newdoc.createElement("processedOrders"); NodeList processOrders = doc.getElementsByTagName("order"); for (int orderNum = 0; orderNum < processOrders.getLength(); orderNum++) { Element thisOrder = (Element)processOrders.item(orderNum); Element customerid = (Element)thisOrder.getElementsByTagName("customerid") .item(0); String limit = customerid.getAttributeNode("limit").getNodeValue(); String total = thisOrder.getElementsByTagName("total").item(0) .getFirstChild().getNodeValue(); double limitDbl = new Double(limit).doubleValue(); double totalDbl = new Double(total).doubleValue(); Element newOrder = newdoc.createElement("order"); Element newStatus = newdoc.createElement("status"); if (totalDbl > limitDbl) { newStatus.appendChild(newdoc.createTextNode("REJECTED")); } else { newStatus.appendChild(newdoc.createTextNode("PROCESSED")); } Element newCustomer = newdoc.createElement("customerid"); String oldCustomer = customerid.getFirstChild().getNodeValue(); newCustomer.appendChild(newdoc.createTextNode(oldCustomer)); Element newTotal = newdoc.createElement("total"); newTotal.appendChild(newdoc.createTextNode(total)); newOrder.appendChild(newStatus); newOrder.appendChild(newCustomer); newOrder.appendChild(newTotal); newRoot.appendChild(newOrder); } newdoc.appendChild(newRoot); System.out.print(newRoot.toString());
...
После обработки orders. xml приложение создает новый элемент, processedOrders, который в конечном счете станет корневым элементом нового документа. Затем оно проходит через каждый заказ. Для каждого заказа оно выделяет информацию total и limit.
Далее приложение создает новые элементы для заказа: order, status, customerid и amount. Оно заполняет status на основе того, превышает ли итог кредит покупателя, и в соответствии с этим заполняет остальное.
После того, как приложение создало элементы, оно должно собрать их вместе. Сначала оно добавляет состояние, информацию о покупателе и итог в новый элемент order. Затем оно добавляет новый order в элемент newRoot.
Пока все это происходит, элемент newRoot на самом деле не присоединен к родительскому узлу. Когда приложение завершит обработку всех заказов, newRoot присоединяется к новому документу.
Наконец, приложение выводит данные, преобразовывая newRoot в String и просто посылая его в System.out.
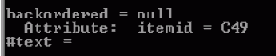
Получение корневого элемента
Если документ разобран и создан Document, приложение может двигаться по структуре для обзора, поиска и отображения информации. Эта навигация является основой для многих операций, выполняемых на объекте Document.
Прохождение через документ начинается с корневого элемента. Правильно форматированный документ имеет только один корневой элемент, называемый также DocumentElement. Сначала приложение выбирает этот элемент.
import javax.xml.parsers.DocumentBuilder; import javax.xml.parsers.DocumentBuilderFactory; import java.io.File; import org.w3c.dom.Document; import org.w3c.dom.Element;
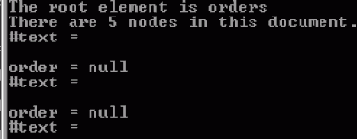
public class OrderProcessor { ... System.exit(1); } //STEP 1: Get the root element Element root = doc.getDocumentElement(); System.out.println("The root element is " + root.getNodeName());
} }
Компиляция и выполнение приложения выведет имя корневого элемента, orders.

Получение потомка элемента
Если приложение определило корневой элемент, оно выбирает список потомков корневого элемента как NodeList. Класс NodeList является серией компонентов, которую приложение может перебирать. В данном примере для краткости приложение получает дочерние узлы и проверяет выборку, показывая, сколько элементов появляется в результирующем NodeList.

Заметьте, что документ имеет только два элемента, но NodeList содержит пять потомков, включая три текстовых узла, которые содержат переводы строк.
... import org.w3c.dom.NodeList;
... //STEP 1: Get the root element Element root = doc.getDocumentElement(); System.out.println("The root element is "+root.getNodeName()); //STEP 2: Get the children NodeList children = root.getChildNodes(); System.out.println("There are "+children.getLength() +" nodes in this документ.");
} }
Различие между элементами и узлами
Фактически, элементы являются только одним типом узлов, и они даже не выделены на предыдущем рисунке. Элементный узел - это контейнер для информации. Эта информация может быть другими элементными узлами, текстовыми узлами, узлами атрибутов или другого типа. Более правильная картина для документа показана ниже:

Прямоугольники представляют элементные узлы, а овалы представляют текстовые узлы. Если один узел содержит в себе другой, то последний рассматривается как потомок этого узла.
Заметьте, что элемент orders имеет не двух, а пять потомков: два элемента order и текстовые узлы между ними и вокруг них. Несмотря на то, что они не имеют содержимого, пропуски между элементами order составляют текстовый узел. Аналогично, item имеет семь потомков: name, price, qty и четыре текстовых узла вокруг них.
Заметьте также, что то, что может рассматриваться как содержимое элемента, например, "Premium Cinch", на самом деле является содержимым текстового узла, который является потомком элемента name.
(Даже этот рисунок не является законченным, оставляя вне сферы внимания, помимо прочего, узлы атрибутов.)
Рекурсия через многие уровни потомков
Код в подразделе показывает потомка первого уровня, но это трудно для всего документа. Чтобы увидеть все элементы, функциональность предыдущего примера должна быть оформлена в метод и должна вызываться рекурсивно.
Приложение начинает с корневого элемента и печатает имя и значение на экране. Затем приложение проходит через каждый его потомок так же, как и раньше. Но для каждого потомка приложение также проходит через каждый его потомок, проверяя всех "детей" и "внуков" корневого элемента.
... public class OrderProcessor { private static void stepThrough (Node start) {
System.out.println(start.getNodeName()+" = "+start.getNodeValue()); for (Node child = start.getFirstChild(); child != null; child = child.getNextSibling()) { stepThrough(child);
} }
public static void main (String args[]) { File docFile = new File("orders.xml"); ... System.out.println("There are "+children.getLength() +" nodes in this документ."); //STEP 4: Recurse this functionality stepThrough(root);
} }

независимый API, разработанный для работы
DOM - это языково- и платформенно- независимый API, разработанный для работы с XML-данными. Это API, который загружает все данные в память в виде иерархии узлов предков-потомков, которыми могут быть элементы, текст, атрибуты или другие типы узлов.
API DOM дает разработчику возможность читать, создавать и редактировать XML-данные. В этом учебнике были рассмотрены концепции DOM и проиллюстрированы примерами Java-кода. Реализации DOM также доступны в C++, Perl и других языках.
Создание и установка атрибутов
Конечно, что хорошего в элементе backordered, если не видно, какую компоненту он представляет? Одним из способов исправить недостаток информации является добавление атрибутов в элемент.
Сначала приложение создает атрибут itemid. Затем оно определяет значение itemid из исходного элемента item, а затем устанавливает значение в сам атрибут. Наконец, оно добавляет элемент в документ, так же, как и раньше.
... if (thisOrderItem.getAttributeNode("instock") .getNodeValue().equals("N")) { Element backElement = doc.createElement("backordered"); backElement.setAttributeNode(doc.createAttribute("itemid")); String itemIdString = thisOrderItem.getAttributeNode("itemid").getNodeValue(); backElement.setAttribute("itemid", itemIdString);
Node deadNode = thisOrderItem.getParentNode().replaceChild(backElement, thisOrderItem); } else { ...

Важно заметить, что setAttribute() создает узел атрибута, если атрибут с таким именем не существует, так что в этом случае приложение может совсем пропустить createAttribute().
Создание иерархии
DOM, в сущности, является коллекцией узлов. При том, что в документе потенциально содержатся разные типы информации, определено и несколько типов узлов.
При создании иерархии для XML-файла естественно выработать нечто концептуальное, наподобие приведенной выше структуры. Хотя она правильно описывает состав включенных в концепцию данные, она не дает описания данных с точки зрения их представления в DOM. Это потому, что она представляет элементы, а не узлы.

Создание пространства имен
Поскольку идентификаторы для пространств имен должны быть уникальными, они обозначаются при помощи Унифицированных Идентификаторов Ресурсов, Uniform Resource Identifiers или URI. Например, пространство имен по умолчанию для данных примера будет обозначено при помощи атрибута xmlns:
<?xml version="1.0" encoding="UTF-8"?> <orders xmlns="http://www.nicholaschase.com/orderSystem.html" > <order> <customerid limit="1000">12341<customerid> ... </orders>
(Многоточие представляет несущественный фрагмент.)
Любые элементы, для которых не указано пространство имен, находятся в пространстве имен по умолчанию, http://www.nicholaschase.com/orderSystem.html. В действительности сам URI ничего не означает. Информация может находиться или не находиться по этому адресу, но что важно, так это то, что он уникален.
Важно отметить громадную разницу между пространством имен по умолчанию и отсутствием пространства имен вообще. В этом случает элементы, которые не имеют префикса пространства имен, находятся в пространстве имен по умолчанию. Если же не существует пространства имен по умолчанию, такие элементы находятся вне пространства имен.
Вы можете также создавать вторичные пространства имен и добавлять в них элементы или атрибуты.
Создание XML-файла
Теперь нам ясно, как приложение должно создавать новую информацию и выводить ее в файл.
Та же логика используется для данных, но вместо того, чтобы выводить на экран, приложение посылает их в файл.
Важное обстоятельство, которое стоит здесь отметить, состоит в том, что поскольку XML-данные являются просто текстом, они могут быть форматированы любым способом. Например, вы можете создать разновидность stepThroughAll() которая будет создавать версию с отступами, красивую для печати. Только помните, что это будет создавать лишние узлы пропусков (текстовые).
... import java.io.FileWriter;
... try { File newFile = new File("processedOrders.xml"); FileWriter newFileStream = new FileWriter(newFile); newFileStream.write ("<?xml version=\"1.0\"?>"); newFileStream.write ("<!DOCTYPE "+doc.getDoctype().getName()+" "); if (doc.getDoctype().getSystemId() != null) { newFileStream.write (" SYSTEM "); newFileStream.write (doc.getDoctype().getSystemId()); } if (doc.getDoctype().getPublicId() != null) { newFileStream.write (" PUBLIC "); newFileStream.write (doc.getDoctype().getPublicId()); } newFileStream.write (">"); newFileStream.write (newRoot.toString()); newFileStream.close(); } catch (IOException e) { System.out.println("Can't write new file."); }
...
Тождественные преобразования
В простом Document, подобном тому, который рассматривается в нашем учебнике, легко предположить, что выводимый XML прост, но помните, что следует рассматривать многие факторы, которые могут привести к усложнению - редко встречающиеся, такие, как файлы, содержимое которых определяется DTD или схемой. В большинстве случаев лучше полагаться на приложение, которое уже принимает все такие возможности во внимание.
Одним из способов, который разработчики часто выбирают для сериализации их объектов Document DOM состоит в создании тождественного преобразования. Это XSL Transformation, которая включает в себя таблицы стилей. Например:
... import javax.xml.transform.TransformerFactory; import javax.xml.transform.Transformer; import javax.xml.transform.dom.DOMSource; import javax.xml.transform.stream.StreamResult; import java.io.FileOutputStream;
... newdoc.appendChild(newRoot); try { DOMSource source = new DOMSource(newdoc); StreamResult result = new StreamResult(new FileOutputStream("processed.xml")); TransformerFactory transFactory = TransformerFactory.newInstance(); Transformer transformer = transFactory.newTransformer(); transformer.transform(source, result); } catch (Exception e){ e.printStackTrace(); }
} }
Здесь вы создаете источник и результат, но поскольку вы работаете с тождественным преобразованием, вы не создаете объект для представления таблицы стилей. Если бы это было настоящее преобразование, в создании Transformer должна была бы использоваться таблица стилей. Вместо этого Transformer просто принимает источник (Document) и посылает его в результат (файл processed.xml).
Трехшаговый процесс
Чтобы работать с информацией в XML-файле, файл должен быть разобран для создания объекта Document.
Объект Document является интерфейсом, так что его экземпляр не может быть создан непосредственно, обычно вместо этого приложение использует фабрику. Подробности этого процесса различаются от реализации к реализации, но идеи одни и те же. (Опять-таки, Уровень 3 стандартизирует эту задачу.) Например, в среде Java разбор файла является 3-шаговым процессом:
Создание DocumentBuilderFactory. Этот объект создает DocumentBuilder. Создание DocumentBuilder. DocumentBuilder действительно выполняет разбор для создания объекта Document. Разбор файла для создания объекта Document.
Теперь вы можете начать построение приложения.
Удаление атрибута
Приложение может также удалить атрибут. Например, может быть нежелательным показывать на выходе информацию о кредите покупателя, так что приложение может временно удалить ее из документа.
Удаление информации выполняется явным образом при помощи removeAttribute() для удаления данных.
... Element thisOrder = (Element)orders.item(orderNum); Element customer = (Element)thisOrder.getElementsByTagName("customerid") .item(0); customer.removeAttribute("limit");
NodeList orderItems = thisOrder.getElementsByTagName("item"); ...

Однако следующий шаг использует информацию о кредите, так что вам следует удалить последние изменения прежде, чем двигаться дальше.
Удаление узла
Вместо того, чтобы заменять элемент, приложение может удалить его совсем. В данном примере приложение проверяет, имеется ли составляющая на складе. Если нет, оно удаляет составляющую из заказа вместо того, чтобы прибавлять ее к итогу.
Перед добавлением стоимости составляющей к итогу приложение проверяет значение атрибута instock. Если оно N, то вместо добавления к итогу составляющая полностью удаляется. Чтобы это сделать, приложение применяет метод removeChild(), но сначала определяет предка этого orderItem при помощи getParentNode(). code>Node удаляется из документа, но метод также возвращает его, так что, при желании, он может быть перемещен.
... //Get this item as an Element Element thisOrderItem = (Element)orderItems.item(itemNum); if (thisOrderItem.getAttributeNode("instock") .getNodeValue().equals("N")) { Node deadNode = thisOrderItem.getParentNode().removeChild(thisOrderItem); } else {
//Get pricing information for this Item String thisPrice = thisOrderItem.getElementsByTagName("price").item(0) .getFirstChild().getNodeValue(); ... total = total + thisItemTotal; }
} String totalString = new Double(total).toString(); ...

Установки парсера
Одно из преимуществ создания парсеров при помощи DocumentBuilder состоит в управлении различными установками парсера, создаваемого при помощи DocumentBuilderFactory. Например, парсер может быть установлен на проверку правильности документа:
... try { DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance(); dbf.setValidating(true);
DocumentBuilder db = dbf.newDocumentBuilder(); doc = db.parse(docFile); } catch (Exception e) { ...
Java-реализация DOM Уровня 2 обеспечивает управление параметрами парсера через следующие методы:
setCoalescing(): Определяет, превращает ли парсер узлы CDATA в текст и соединяет ли их с окружающими текстовыми узлами (если возможно). Значение по умолчанию - false. setExpandEntityReferences(): пределяет, расширяются ли внешние ссылки на сущности. Если true, внешние данные вставляются в документ. Значение по умолчанию - true. (Приемы работы с внешними сущностями см. в .) setIgnoringComments(): Определяет, игнорируются ли комментарии в файле. Значение по умолчанию - false. setIgnoringElementContentWhitespace(): Определяет, игнорируются ли пропуски между элементами (аналогично тому, как браузер интерпретирует HTML). Значение по умолчанию - false. setNamespaceAware(): Определяет, обращает ли парсер внимание на информацию пространства имен. Значение по умолчанию - false. setValidating(): По умолчанию парсер не проверяет правильность документов. Установите здесь true для проверки правильности.
Включение атрибутов
Метод stepThrough(), как он был написан до сих пор, может проходить через большинство типов узлов, но в нем полностью отсутствуют атрибуты, поскольку они не являются потомками никаких узлов. Чтобы показывать атрибуты, модифицируем метод stepThrough() для проверки элементных узлов на наличие атрибутов.
Приведенный ниже модифицированный код проверяет каждый узел на то, является ли он элементом, путем сравнения его nodeType с константой ELEMENT_NODE. Объект Node имеет в своем составе константы, которые представляют каждый тип узла, такие, как ELEMENT_NODE или ATTRIBUTE_NODE. Если nodeType соответствует ELEMENT_NODE, он является элементом.
Для каждого найденного им элемента приложение создает объект NamedNodeMap, содержащий все атрибуты элемента. Приложение может перебирать NamedNodeMap, печатая имя и значение каждого атрибута, так же, как оно перебирало NodeList.
... import org.w3c.dom.NamedNodeMap;
... private static void stepThroughAll (Node start) { System.out.println(start.getNodeName()+" = "+start.getNodeValue()); if (start.getNodeType() == start.ELEMENT_NODE) { NamedNodeMap startAttr = start.getAttributes(); for (int i = 0; i < startAttr.getLength(); i++) { Node attr = startAttr.item(i); System.out.println(" Attribute: "+ attr.getNodeName() +" = "+attr.getNodeValue()); } }
for (Node child = start.getFirstChild(); child != null; child = child.getNextSibling()) { stepThroughAll(child); } }

Замена узла
Конечно, не имеет смысла удалять компоненту заказа, если она не выполнена. Вместо этого приложение заменяет ее компонентой backordered.
Вместо removeChild() просто используйте replaceChild(). Заметьте, что в данном случае метод также возвращает старый узел, так что он может быть перенесен, если это необходимо, возможно, в новый Document, перечисляющий невыполненные компоненты.
Заметьте, что поскольку никакое содержимое не было добавлено в элемент, этот элемент является пустым. Пустой элемент не имеет содержимого и может быть записан в сокращенном виде:
<backordered />
Косая черта (/) устраняет необходимость в закрывающем теге (</backordered>).
... if (thisOrderItem.getAttributeNode("instock") .getNodeValue().equals("N")) { Element backElement = doc.createElement("backordered");
Node deadNode = thisOrderItem.getParentNode() .replaceChild ( backElement, thisOrderItem);
} else { ...