Программная модель пользователя и супервизора
Программная модель пользователя представлена на рис. 7.1.

Рис. 7.1. Программная модель пользователя
Программная модель супервизора дополняется:
указателем стека супервизора A7;регистром состояния SR.
В нормальном состоянии ЦП находится в режиме пользователя. Переход из этого режима в режим супервизора возможен только при нарушении нормальной работы специальной инструкцией или внешним событием. Такая ситуация называется исключением, а сама процедура перехода - обработкой исключения.
Исключение - это любое нарушение нормальной работы МП.
Исключения могут вызываться внутренними (адресные ошибки, неправильные результаты обработки и выполнения инструкций, трассировка) и внешними (сигнал сброса, ошибка магистрали, прерывания) причинами.
Исключения разделяются по приоритетам. Их обработка осуществляется подпрограммами, адреса которых вычисляет ЦП с использованием номера вектора исключения, генерируемого самим ЦП или передаваемым ему в цикле подтверждения прерывания.
Прерывания являются частным случаем исключений.
Режим работы ЦП определяется специальным битом в регистре состояния (бит S), переключение которого возможно только в режиме супервизора.
Переход из режима супервизора в режим пользователя происходит только по инструкции, воздействующей на бит S регистра состояния.
В режимах пользователя и супервизора различаются:
адресные пространства, в которых работает ЦП;программные модели;набор допустимых инструкций;активные стеки.
Распараллеливание функций в структуре микропроцессоров фирмы Motorola
В первом же МП семейства MC 68000 фирма Motorola использовала один из самых эффективных методов повышения производительности - распараллеливание функций с помощью относительно автономно работающих блоков.
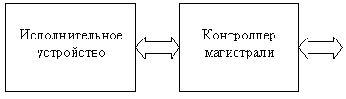
Рис. 7.2. Структура МП МС 68000

Рис. 7.3. Структура МП МС 68020

Рис. 7.4. Структура МП МС 68030

Рис. 7.5. Структура МП МС 68040
Устройство памяти инструкций (данных) включает:
устройство управления памятью инструкций (данных);кэш инструкций (данных) - 4 Кбайт;устройство снупинга инструкций (данных).
Механизм снупинга позволяет альтернативному владельцу магистрали получать доступ к содержимому внутрикристального кэша данных.
Система арбитра, служащая для определения владельца магистрали, включает сигналы:
запроса магистрали;передачи управления магистралью;подтверждения приема магистрали.
В ЦП MC68000 - 68030 основным владельцем магистрали и одновременно устройством, осуществляющим арбитраж, является сам ЦП. В ЦП MC68040, 68060 - внешний арбитр.
SC1, SC2 - входные сигналы, определяющие операцию снупа, которая должна быть проведена для альтернативного владельца магистрали. При снупе в циклах чтения MC68040 может включиться в пересылку, выставив данные из кэша данных и обеспечив владельца достоверными данными, когда копия в памяти устарела.

Рис. 7.6. Структура МП МС 68060
Сравнительные характеристики микропроцессоров i8086 фирмы Intel и MC68000 фирмы Motorola
Первым микропроцессором фирмы Motorola, получившим широкое применение, был 8-битный MC6800. Он состоял из одного устройства, обеспечивающего взаимодействие, декодирование и выполнение инструкций, вычисление эффективного адреса и взаимодействие с внешней магистралью. Микропроцессор MC6800 имел классическую последовательную архитектуру.
Программная модель MC6800:
16-битный программный счетчик;8-битный регистр-аккумулятор;8-битный регистр флагов;два 8-битных индексных регистра.
Практически одновременно с появлением i8086 фирма Motorola выпускает свой микропроцессор MC 68000.
Таблица 7.1. Сравнительные характеристики процессоров i8086 и MC 68000
Характеристикаi8086MC 68000| Адресное пространство | 1 Мбайт | 16 Мбайт |
| Внутренняя ШД | 16 бит | 32 бита |
| Внешняя ШД | 16 бит | 16 бит |
| Количество РОН | 8 | 16 |
| Аппаратная поддержка защиты памяти | нет | есть |
Основные концепции семейства MC 6800x (MC 68008, MC 68010, MC68020, MC68030, MC68040, MC68060) были заложены в первом же МП MC 68000.
Одной из важнейших особенностей является обеспечение защиты информации от несанкционированного доступа путем организации возможности работы в одном из двух режимов: пользователя и супервизора.
В режиме пользователя программе были доступны регистры программной модели пользователя и большая часть инструкций.
В режиме супервизора в дополнение к регистрам программной модели пользователя становились доступны регистры программной модели супервизора, а также дополнительные инструкции, влияющие на безопасность системы.
Как обеспечивается защита информации от
Сравните МП i8086 и MC68000 фирмы Motorola.Программная модель MC6800. Как обеспечивается защита информации от несанкционированного доступа в МП фирмы Motorola?Как происходит переход из режима супервизора в режим пользователя?Какова программная модель супервизора.Что различают в режимах пользователя и супервизора?Какой метод повышения производительности использовала фирма Motorola?Что позволяет сделать механизм снупинга?
Математические сопроцессоры для ЦП фирмы Motorola
Для своих ЦП MC680x0 фирма Motorola разработала специальный сопроцессорный интерфейс (рис. 8.3). Интерфейс сопроцессора отличается от, например, интерфейса периферийного устройства тем, что сопроцессор добавляет в систему новые инструкции, дополнительные регистры и типы данных, которые обычно не предусматриваются программной моделью целочисленного устройства ЦП. Тем не менее, коммуникационный протокол между ЦП и сопроцессором прозрачен для программиста, т.к. реализован аппаратно. Этот коммуникационный протокол слабо привязан к архитектуре ЦП, так что любой сопроцессор, реализующий данный протокол, может быть использован в системе с ЦП MC680x0. В то же время архитектура ЦП этого семейства свободна от каких-либо априорных предположений о возможностях сопроцессора. Это, очевидно, дает определенную свободу при построении систем с сопроцессором на основе ЦП MC680x0.

Рис. 8.3. Сопроцессорный интерфейс MC680х0
Обмен информацией между процессором и сопроцессором происходит через внешнюю шину ЦП, не привлекая специальных сигнальных линий:
A19-A13 - определяют операцию и тип сопроцессора;FC2-FC0 - передают функциональный код (статус) сопроцессора;А4-А0 - передают номер регистра интерфейса CIR;AS-строб адреса (показывает достоверность адреса на шине адреса);DS-строб данных;R/W-определяет направление пересылки;DSACK1, DSACK2 - подтверждают пересылку и размер операнда (служат для определения пересылки и динамического определения ширины шины данных).
При этом некоторые модели ЦП, например MC68020, допускают для сопроцессора асинхронные циклы шины, так что ЦП и сопроцессор могут работать на разных частотах, сбалансировав, таким образом, свою производительность.
Коммуникационный протокол для передачи сопроцессору инструкций для выполнения использует группу интерфейсных регистров - CIR (Coprocessor Interface Registers). Через эти же регистры сопроцессор сообщает ЦП о своем состоянии (табл. 8.4).
Таблица 8.4. Регистры сопроцессорного интерфейса (CIR)
АдресНазначение| 31 16 | 15 0 | |
| $00 | Регистр ответа | Регистр управления |
| $04 | Регистр сохранения | Регистр восстановления |
| $08 | Слово операции | Регистр команды |
| $0C | резерв. | Регистр условия |
| $10 | Регистр операнда | |
| $14 | Регистр выбора | резерв. |
| $18 | Регистр адреса инструкции | |
| $1C | Регистр адреса операнда | |
Программная модель сопроцессоров Motorola MC68881/MC68882, реализующих описанный выше сопроцессорный интерфейс, соответствует стандарту IEEE-754, а поэтому весьма схожа с программной моделью сопроцессоров семейства Intel x87.
Математические сопроцессоры фирмы Intel
Современные процессоры архитектуры IA-32 содержат блок операций с вещественными числами (Floating Point Unit - FPU). Функционирование этого блока во многом основано на архитектуре первого представителя семейства математических сопроцессоров Intel - 8087.
Сопроцессор 8087 был разработан в 1980 г. Структура сопроцессора 8087 показана на рис. 8.1. В схеме сопроцессора 8087 можно выделить две подсистемы: устройство шинного интерфейса и устройство с плавающей точкой. Развитием этого семейства стал сопроцессор 80287, созданный в 1985 году. Основные изменения произошли только в устройстве шинного интерфейса. В отличие от 8087, сопроцессор 80287 не имеет доступа к шине адреса, поэтому все обращения к памяти выполняет ЦП. В сопроцессоре 80387 изменения коснулись устройства с плавающей точкой: изменилась схема обработки ошибок, а также был реализован больший набор трансцендентных функций.

Рис. 8.1. Структура сопроцессора 8087
Выпуск очередного поколения ЦП фирмы Intel ознаменовался внедрением блока вещественной арифметики в структуру ЦП. Первым таким представителем семейства процессоров стал i486DX.
В пятом поколении процессоров интеграция блока FPU в суперскалярную архитектуру позволила значительно повысить эффективность выполнения операций с вещественными числами. Блок FPU может выполнять одну операцию с плавающей точкой в каждом такте или же получать и одновременно выполнять 2 команды с плавающей точкой, одной из которых должна быть команда обмена. Команды с плавающей точкой проходят по целочисленному конвейеру (обычно только по U-конвейеру - 5 ступеней) и передаются на исполнительные ступени конвейера FPU (3 ступени). В целом же, несмотря на то, что блок FPU интегрирован в центральный процессор, этот блок работает независимо и одновременно с устройством целочисленных вычислений.
Дальнейшее развитие этого семейства сопровождалось дополнением набора команд блока FPU специальными функциональными подмножествами: MMX, SSE, SSE2.
В целом базовая программная модель всех перечисленных сопроцессоров и блока FPU у IA-32 сходная (рис. 8.2): регистровый стек (восемь 80-битных регистров R0-R7), слово тегов, регистр управления, регистр состояния, указатель команды и указатель данных.

Рис. 8.2. Программная модель сопроцессоров семейства Intel х87
Для хранения данных в сопроцессоре предназначены регистры R0-R7. Эти регистры организованы в стек, и доступ к ним производится относительно вершины стека - ST. Номер регистра, соответствующего вершине стека, хранится в регистре состояния (поле TOS). Как и у ЦП, стек сопроцессора растет к регистрам с меньшими адресами. Команды, которые производят запоминание и извлечение из стека, передают данные из текущего регистра ST, а затем производят инкремент поля TOS в регистре состояния. Многие команды сопроцессора допускают неявное обращение к вершине стека, обозначаемой ST или ST(0). Для указания i-го регистра относительно вершины используется обозначение ST(i), где I = 0,:,7. Например, если поле TOS регистра состояния содержит значение 0112 (вершиной стека является регистр R3), то команда FADD ST,ST(2) суммирует содержимое регистров R3 и R5. Стековая организация упрощает программирование подпрограмм, допуская передачу параметров в регистровом стеке сопроцессора.
Старший байт регистра состояния содержит:
Бит занятости B (бит 15), сигнализирующий, свободен ли сопроцессор (B=0) или занят выполнением численной команды (B = 1). Команды сопроцессора, которые используют регистровый стек, требуют, чтобы перед началом их выполнения сопроцессор не был занят. В FPU этот бит дублирует значение флага сигнализации особого случая.Поле TOS "Top-Of-the-Stack" (биты 11-13), которое содержит номер регистра, являющегося логической вершиной стека. При помещении в регистровый стек нового числа это значение уменьшается. Если это поле достигает значения 0, возможны две ситуации: произойдет заворачивание стека на регистры с большими номерами (т.е. R7) или, если заворачивание приведет к затиранию несохраненного значения, возникнет особый случай сопроцессора "переполнение стека".4 бита кода условия (биты 14, 10, 9, 8), аналогичные флажкам состояния FLAGS у IA-32, отражающие результат арифметических операций.
Эти флажки могут быть использованы для условных переходов.
Младший байт регистра состояния содержит флажки особых случаев сопроцессора: переполнение стека, потеря точности, потеря значащих разрядов, численное переполнение, деление на ноль, денормализация, недействительная операция. Если соответствующий особый случай возник и не был замаскирован (в слове управления), это приведет к генерации центральным процессором особого случая сопроцессора (#16).
Младшее слово регистра управления содержит биты масок особых случаев. Сопроцессор допускает индивидуальное маскирование особых случаев. Если тот или иной особый случай замаскирован, при возникновении соответствующей ситуации сопроцессор выполняет некоторые заранее определенные внутренние действия, которые зачастую приемлемы для большинства применений. Например, если замаскирован особый случай деления на ноль, то выполнение операции 85,32/0 даст результат + ?.
Старшее слово регистра управления содержит два поля: управление точностью PC (биты 8 и 9) и управление округлением RC (биты 10 и 11). Биты управления точностью можно использовать для понижения точности вычислений. По умолчанию используется расширенная точность (PC = 112), можно также использовать двойную точность (PC = 102) и одинарную точность (PC = 002) по стандарту IEEE-754.
Если результат численной операции не может быть точно представлен в выбранном формате, сопроцессор выполняет округление в соответствии с полем RC (табл. 8.3). По умолчанию RC = 00. В примерах в табл. 7.3 сделана попытка представить числа +2,23 и +2,05 в виде двоичных вещественных чисел с 3-битной дробной частью мантиссы. В этом формате нельзя подобрать точное двоичное значение для этих чисел. Ближайшие к ним представимые числа - +2,00 (+1,000E21) и +2,25 (+1,001E21).
Таблица 8.3. Режимы округления сопроцессоров Intel x87
| RC | Режим | Пример 1 1,000E21 < 2,23E100 < 1,001E21 -1,001E21 < -2,23E100 < -1,000E21 | Пример 2 1,000E21 < 2,05E100 < 1,001E21 -1,001E21 < -2,05E100 < -1,000E21 |
| 00 | Округление к ближайшему (или четному) | 2,23E100 ? 1,001E21-2,23E100 ? -1,001E21 | 2,05E100 ? 1,000E21-2,05E100 ? -1,000E21 |
| 01 | Округление вниз (к ?) | 2,23E100 ? 1,000E21-2,23E100 ? -1,001E21 | 2,05E100 ? 1,000E21-2,05E100 ? -1,001E21 |
| 10 | Округление вверх (к +?) | 2,23E100 ? 1,001E21-2,23E100 ? -1,000E21 | 2,05E100 ? 1,001E21-2,05E100 ? -1,000E21 |
| 11 | Округление к нулю (усечение) | 2,23E100 ? 1,000E21-2,23E100 ? -1,000E21 | 2,05E100 ? 1,000E21-2,05E100 ? -1,000E21 |
Регистр тегов содержит 8 тегов - признаков, характеризующих содержимое соответствующего численного регистра сопроцессора. Тег может принимать следующие значения:
00 - в регистре находится действительное число;
01 - нулевое число в регистре;
10 - недействительное число (бесконечность, денормализованное число, нечисло);
11 - пустой регистр.
Сопроцессор использует теги, чтобы определить переполнение или опустошение стека. Если при помещении в стек очередного числа окажется, что декрементированный TOS указывает на непустой регистр (соответствующий тег не равен 112), сопроцессор сигнализирует о переполнении стека. Если при извлечении из стека числа окажется, что инкрементированный TOS указывает на пустой регистр (соответствующий тег равен 112), сопроцессор сигнализирует об опустошении стека.
Указатель команд и указатель данных содержат логические адреса (селектор сегмента и смещение) последней команды и ее операнда. (это 32-битные регистры у 8087 и 80287 и 48-битные - у 80387 и FPU). Эта информация используется обработчиком особых случаев сопроцессора.
Для команд сопроцессора выделена группа кодов, начинающаяся с 11011ххх. В ассемблерах мнемоники команд сопроцессора начинаются с "F": FADD (сложение), FCOM (сравнение), FCOS (косинус), FDIV (деление) и т.п.
Параллельная работа ЦП и сопроцессора ставит перед программистом проблемы синхронизации. Например:
mem DW 0 : FILD mem INC mem FSQRT
В данном примере, команда FILD преобразует 16-битное целое число в памяти в формат сопроцессора и сохраняет его в ST, затем целочисленная команда INC увеличивает это значение на 1, после чего сопроцессор вычисляет квадратный корень ST (FSQRT).
Для внешних сопроцессоров (8087, 80287, 80387) ЦП начнет выполнять команду INC раньше, чем сопроцессор закончит FILD, а, следовательно, в стек сопроцессора может попасть неверное значение. Встроенный блок FPU у IA-32 лишен этого недостатка, т. к. ЦП отслеживает обращения к памяти и не начнет выполнять целочисленную команду, если она обращается к ячейке памяти, с которой в данный момент работает блок FPU.
Однако остается нерешенной другая проблема. Если при выполнении инструкции FPU возникает ситуация, соответствующая одному из незамаскированных особых случаев, FPU прекращает выполнение инструкции и сигнализирует об особом случае. Однако соответствующее исключение процессора будет вызвано только при очередном обращении процессора к блоку FPU, а до этого момента целочисленный блок может изменить ячейку памяти, значение которой привело к исключению, так что обработчик исключения не сможет правильно интерпретировать причину особого случая.
Описанная ситуация говорит о необходимости использовать в таких случаях средства синхронизации. Например, команда FWAIT приостанавливает работу целочисленного устройства до тех пор, пока не будет завершена работа выполняемой сопроцессором инструкции или не будет вызвано исключение, если при выполнении последней инструкции FPU возник особый случай. Для этих же целей можно использовать любую другую инструкцию сопроцессора, кроме специальных "неожидающих" инструкций: FNINIT - сброс сопроцессора без ожидания, FNSTCW/FNSTSW - сохранение регистра управления/состояния без ожидания, FNCLEX - сбросить флаги особых случаев без ожидания, FNSAVE/FNSTENV - сохранение состояния (контекста) сопроцессора без ожидания.
Таким образом, для решения проблемы синхронизации приведенный выше пример следует переписать так:
FILD mem FSQRT INC mem
Математический сопроцессор: основные функции
Один из наиболее распространенных типов сопроцессоров - математический сопроцессор. Математический сопроцессор предназначен для быстрого выполнения арифметических операций с плавающей точкой, предоставления часто используемых вещественных констант (

Большинство современных математических сопроцессоров для представления вещественных чисел используют стандарт IEEE 754-1985 "IEEE1) Standard for Binary Floating-Point Arithmetics". Старший разряд двоичного представления вещественного числа всегда кодирует знак числа. Остальная часть разбивается на две части: экспоненту и мантиссу. Вещественное число вычисляется как: (-1)S·2E·M, где S - знаковый бит числа, E - экспонента, M - мантисса. Если 1

Стандарт IEEE-754 определяет три основных способа кодирования (типа) вещественных чисел.
Таблица 8.1. Типы (способы кодирования) вещественных чисел
ТипДиапазон значений(по модулю)Двоичное представление| вещественное ординарной точности (single precision) - 32 бит | 1,18·10-38... 3,40·1038 |
 | |
| вещественное двойной точности (double precision) - 64 бит | 2,23·10-308... 1,79·10308 |
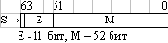 | |
| вещественное расширенной точности (extended precision) - 80 бит | 3,37·10-4932... 1,18·104392 |
 |
Приведем пример кодирования вещественного числа 178,625:
178,62510 = 128 + 32 + 16 + 2 + 0,5 + 0,125 = = 1·27 + 0·26 + 1·25 + 1·24 + + 0·23 + 0·22 + 1·21 + 0·20 + + 1·2-1 + 0·2-2 + 1·2-3 = 10110010,1012
Для представления этого числа в соответствии с IEEE-754 его нужно нормализовать (привести в экспоненциальный вид):
Сопроцессоры. Способы обмена информацией между ЦП и сопроцессором
Сопроцессор - это специализированная интегральная схема, которая работает в содружестве с ЦП, но менее универсальна. В отличие от ЦП, сопроцессор не имеет счетчика команд. Сопроцессор предназначен для выполнения специфического набора функций, например: выполнение операций с вещественными числами - математический сопроцессор, подготовка графических изображений и трехмерных сцен - графический сопроцессор, цифровая обработка сигналов - сигнальный сопроцессор и др.
Использование сопроцессоров с различной функциональностью позволяет решать проблемы широкого круга:
обработка экономической информации;моделирование;графические преобразования;промышленное управление;системы числового управления;роботы;навигация;сбор данных и др.
Можно выделить два способа обмена информацией между ЦП и сопроцессором:
прямое соединение входных и выходных портов (ЦП имеет специальный интерфейс для взаимодействия с сопроцессором);с обменом через память (обмен информацией между ЦП и сопроцессором происходит благодаря доступу сопроцессора к оперативной памяти через системную магистраль).
Назовите основные способы обмена информацией
Что такое сопроцессор? Назовите основные способы обмена информацией между процессором и сопроцессором.Перечислите функции математического сопроцессора.Опишите форматы чисел с плавающей точкой по стандарту IEEE-754.Назовите основное отличие структуры сопроцессора 8087 от 80287.
BEDO DRAM
Данная технология является развитием конвейерной архитектуры. В структуру памяти, кроме регистра-защелки, был внедрен счетчик адреса колонок для пакетного цикла, что позволяет выставлять адрес колонки только в его начале, а в последующих передачах лишь запрашивать очередные данные. В результате удлинения конвейера выходные данные как бы отстают на один сигнал CAS#, зато следующие появляются без тактов ожидания. При этом стартовый адрес следующего пакета пересылается вместе с последним CAS#-сигналом предыдущего. Если чипсет способен генерировать обращения к памяти в режиме смежных циклов, то можно достичь выигрыша в производительности, соответствующего режиму чтения 5-1-1-1.
EDO DRAM
По сравнению с FPM DRAM, в микросхемах памяти данной технологии для каждого банка добавлен регистр-защелка, в котором сохраняются выходные данные. Считывание из него производится внешними схемами вплоть до спада следующего импульса CAS#. Время доступа внутри страницы снижается до 25 нс, повышая производительность на 40%, что соответствует режиму чтения 5-2-2-2.
Установка регистра-защелки практически не увеличивает стоимость микросхемы, однако ее применение дает эффект, соизмеримый с установкой внешнего асинхронного кэша.
FPM DRAM
Данная технология широко использовалась в системах на основе Intel-386 и Intel-486. С появлением МП Pentium была вытеснена EDO DRAM. Ее эффективность обусловлена конвейерной организацией МП. Контроллер памяти позволял выставлять на шину адрес только один раз при чтении пакета из 4 байт, при этом сигнал RAS# удерживается на низком уровне. Типичное время доступа при частоте системной шины 66 МГц - 60 нс (35 нс - внутри строки), что соответствует режиму 5-3-3-3 (5 циклов шины на чтение первого байта строки и по 3 цикла шины при чтении последующих байт).
Кэш-память
Кэш-память представляет собой быстродействующее ЗУ, размещенное на одном кристалле с ЦП или внешнее по отношению к ЦП. Кэш служит высокоскоростным буфером между ЦП и относительно медленной основной памятью. Идея кэш-памяти основана на прогнозировании наиболее вероятных обращений ЦП к оперативной памяти. В основу такого подхода положен принцип временной и пространственной локальности программы.
Если ЦП обратился к какому-либо объекту оперативной памяти, с высокой долей вероятности ЦП вскоре снова обратится к этому объекту. Примером этой ситуации может быть код или данные в циклах. Эта концепция описывается принципом временной локальности, в соответствии с которым часто используемые объекты оперативной памяти должны быть "ближе" к ЦП (в кэше).
Для согласования содержимого кэш-памяти и оперативной памяти используют три метода записи:
Сквозная запись (write through) - одновременно с кэш-памятью обновляется оперативная память.Буферизованная сквозная запись (buffered write through) - информация задерживается в кэш-буфере перед записью в оперативную память и переписывается в оперативную память в те циклы, когда ЦП к ней не обращается.Обратная запись (write back) - используется бит изменения в поле тега, и строка переписывается в оперативную память только в том случае, если бит изменения равен 1.
Как правило, все методы записи, кроме сквозной, позволяют для увеличения производительности откладывать и группировать операции записи в оперативную память.
В структуре кэш-памяти выделяют два типа блоков данных:
память отображения данных (собственно сами данные, дублированные из оперативной памяти);память тегов (признаки, указывающие на расположение кэшированных данных в оперативной памяти).
Пространство памяти отображения данных в кэше разбивается на строки - блоки фиксированной длины (например, 32, 64 или 128 байт). Каждая строка кэша может содержать непрерывный выровненный блок байт из оперативной памяти. Какой именно блок оперативной памяти отображен на данную строку кэша, определяется тегом строки и алгоритмом отображения.
По алгоритмам отображения оперативной памяти в кэш выделяют три типа кэш-памяти:
полностью ассоциативный кэш;кэш прямого отображения;множественный ассоциативный кэш.
Для полностью ассоциативного кэша характерно, что кэш-контроллер может поместить любой блок оперативной памяти в любую строку кэш-памяти (рис. 9.1). В этом случае физический адрес разбивается на две части: смещение в блоке (строке кэша) и номер блока. При помещении блока в кэш номер блока сохраняется в теге соответствующей строки. Когда ЦП обращается к кэшу за необходимым блоком, кэш-промах будет обнаружен только после сравнения тегов всех строк с номером блока.
Одно из основных достоинств данного способа отображения - хорошая утилизация оперативной памяти, т.к. нет ограничений на то, какой блок может быть отображен на ту или иную строку кэш-памяти. К недостаткам следует отнести сложную аппаратную реализацию этого способа, требующую большого количества схемотехники (в основном компараторов), что приводит к увеличению времени доступа к такому кэшу и увеличению его стоимости.

увеличить изображение
Рис. 9.1. Полностью ассоциативный кэш 8х8 для 10-битного адреса
Альтернативный способ отображения оперативной памяти в кэш - это кэш прямого отображения (или одновходовый ассоциативный кэш). В этом случае адрес памяти (номер блока) однозначно определяет строку кэша, в которую будет помещен данный блок. Физический адрес разбивается на три части: смещение в блоке (строке кэша), номер строки кэша и тег. Тот или иной блок будет всегда помещаться в строго определенную строку кэша, при необходимости заменяя собой хранящийся там другой блок. Когда ЦП обращается к кэшу за необходимым блоком, для определения удачного обращения или кэш-промаха достаточно проверить тег лишь одной строки.
Очевидными преимуществами данного алгоритма являются простота и дешевизна реализации. К недостаткам следует отнести низкую эффективность такого кэша из-за вероятных частых перезагрузок строк. Например, при обращении к каждой 64-й ячейке памяти в системе на рис. 9.2 кэш-контроллер будет вынужден постоянно перегружать одну и ту же строку кэш-памяти, совершенно не задействовав остальные.

увеличить изображение
Рис. 9.2. Кэш прямого отображения 8х8 для 10-битного адреса
Несмотря на очевидные недостатки, данная технология нашла успешное применение, например, в МП Motorola MC68020, для организации кэша инструкций первого уровня (рис. 9.3). В данном микропроцессоре реализован кэш прямого отображения из 64 строк по 4 байт. Тег строки, кроме 24 бит, задающих адрес кэшированного блока, содержит бит значимости, определяющий действительность строки (если бит значимости 0, данная строка считается недействительной и не вызовет кэш-попадания). Обращения к данным не кэшируются.

увеличить изображение
Рис. 9.3. Схема организации кэш-памяти в МП Motorola MC68020
Компромиссным вариантом между первыми двумя алгоритмами является множественный ассоциативный кэш или частично-ассоциативный кэш (рис. 9.4). При этом способе организации кэш-памяти строки объединяются в группы, в которые могут входить 2, 4, : строк. В соответствии с количеством строк в таких группах различают 2-входовый, 4-входовый и т.п. ассоциативный кэш. При обращении к памяти физический адрес разбивается на три части: смещение в блоке (строке кэша), номер группы (набора) и тег. Блок памяти, адрес которого соответствует определенной группе, может быть размещен в любой строке этой группы, и в теге строки размещается соответствующее значение. Очевидно, что в рамках выбранной группы соблюдается принцип ассоциативности. С другой стороны, тот или иной блок может попасть только в строго определенную группу, что перекликается с принципом организации кэша прямого отображения. Для того чтобы процессор смог идентифицировать кэш-промах, ему надо будет проверить теги лишь одной группы (2/4/8/: строк).

увеличить изображение
Рис. 9.4. Двухвходовый ассоциативный кэш 8х8 для 10-битного адреса
Данный алгоритм отображения сочетает достоинства как полностью ассоциативного кэша (хорошая утилизация памяти, высокая скорость), так и кэша прямого доступа (простота и дешевизна), лишь незначительно уступая по этим характеристикам исходным алгоритмам.
Именно поэтому множественный ассоциативный кэш наиболее широко распространен (табл. 9.2).
Таблица 9.2. Характеристики подсистемы кэш-памяти у ЦП IA-32Intel486PentiumPentium MMXP6Pentium 4
| L1 кэш команд | |||||
| Тип | 4-вх. ассоц. | 2-вх. ассоц. | 4-вх. ассоц. | 4-вх. ассоц. | 8-вх. ассоц. |
| Размер строки, байт | 16 | 32 | 32 | 32 | - |
| Общий объем, Кбайт | 8/16 | 8 | 16 | 8/16 | 12Кmops |
| L1 кэш данных | |||||
| Тип | Общий с кэш инструкций | 2-вх. ассоц. | 4-вх. ассоц. | 2/4-вх. ассоц. | 4-вх. ассоц. |
| Размер строки, байт | 32 | 32 | 32 | 64 | |
| Общий объем, Кбайт | 8 | 16 | 8/16 | 8 | |
| L2 кэш | |||||
| Тип | Внешний | внешний 4-вх. ассоц. | 4-вх. ассоц. | 8-вх. ассоц. | |
| Размер строки, байт | 32 | 32 | 64 | ||
| Общий объем, Кбайт | 256/512 | 128-2048 | 256/512 | ||
Для организации кэш-памяти можно использовать принстонскую архитектуру (смешанный кэш для команд и данных, например, в Intel-486). Это очевидное (и неизбежное для фон-неймановских систем с внешней по отношению к ЦП кэш-памятью) решение не всегда бывает самым эффективным. Разделение кэш-памяти на кэш команд и кэш данных (кэш гарвардской архитектуры) позволяет повысить эффективность работы кэша по следующим соображениям:
Многие современные процессоры имеют конвейерную архитектуру, при которой блоки конвейера работают параллельно. Таким образом, выборка команды и доступ к данным команды осуществляется на разных этапах конвейера, а использование раздельной кэш-памяти позволяет выполнять эти операции параллельно.Кэш команд может быть реализован только для чтения, следовательно, не требует реализации никаких алгоритмов обратной записи, что делает этот кэш проще, дешевле и быстрее.
Именно поэтому все последние модели IA-32, начиная с Pentium, для организации кэш-памяти первого уровня используют гарвардскую архитектуру.
Критерием эффективной работы кэша можно считать уменьшение среднего времени доступа к памяти по сравнению с системой без кэш-памяти.
В таком случае среднее время доступа можно оценить следующим образом:
Tср = (Thit x Rhit) + (Tmiss x (1 Rhit))
где Thit - время доступа к кэш-памяти в случае попадания (включает время на идентификацию промаха или попадания), Tmiss - время, необходимое на загрузку блока из основной памяти в строку кэша в случае кэш-промаха и последующую доставку запрошенных данных в процессор, Rhit - частота попаданий.
Очевидно, что чем ближе значение Rhit к 1, тем ближе значение Tср к Thit. Частота попаданий определяется в основном архитектурой кэш-памяти и ее объемом. Влияние наличия и отсутствия кэш-памяти и ее объема на рост производительности ЦП показано в табл. 9.3.
Таблица 9.3. Размер и эффективность кэш-памятиРазмер кэш-памятиЧастота попаданий, %Рост производительности, %
| Нет кэш-памяти, DRAM с 2 TW | - | 0 |
| 16 Кб | 81 | 35 |
| 32 Кб | 86 | 38 |
| 64 Кб | 88 | 39 |
| 128 Кб | 89 | 39 |
| Нет кэш-памяти, SRAM без TW | - | 47 |
Организация подсистемы памяти в ПК
Запоминающие устройства (ЗУ) подсистемы памяти ПК можно выстроить в следующую иерархию (табл. 9.1):
Таблица 9.1. Иерархия подсистемы памяти ПК
№Тип ЗУ1985 г.2000 г.Время выборкиТипичный объемЦена / байтВремя выборкиТипичный объемЦена / байт| 1 | Сверхоперативные ЗУ (регистры) | 0,2 5 нс | 16/32 бит | $ 3 - 100 | 0,01 1 нс | 32/64/128 бит | $ 0,1 10 |
| 2 | Быстродействующее буферное ЗУ (кэш) | 20 100 нс | 8Кб - 64Кб | ~ $ 10 | 0,5 - 2 нс | 32Кб 1Мб | $ 0,1 - 0,5 |
| 3 | Оперативное (основное) ЗУ | ~ 0,5 мс | 1Мб - 256Мб | $ 0,02 1 | 2 нс 20 нс | 128Мб - 4Гб | $ 0,01 0,1 |
| 4 | Внешние ЗУ (массовая память) | 10 - 100 мс | 1Мб - 1Гб | $ 0,002 - 0,04 | 5 - 20 мс | 1Гб - 0,5Тб | $ 0,001 - 0,01 |
Регистры процессора составляют его контекст и хранят данные, используемые исполняющимися в конкретный момент командами процессора. Обращение к регистрам процессора происходит, как правило, по их мнемоническим обозначениям в командах процессора.
Кэш используется для согласования скорости работы ЦП и основной памяти. В вычислительных системах используют многоуровневый кэш: кэш I уровня (L1), кэш II уровня (L2) и т.д. В настольных системах обычно используется двухуровневый кэш, в серверных - трехуровневый. Кэш хранит команды или данные, которые с большой вероятностью в ближайшее время поступят процессору на обработку. Работа кэш-памяти прозрачна для программного обеспечения, поэтому кэш-память обычно программно недоступна.
Оперативная память хранит, как правило, функционально-законченные программные модули (ядро операционной системы, исполняющиеся программы и их библиотеки, драйверы используемых устройств и т.п.) и их данные, непосредственно участвующие в работе программ, а также используется для сохранения результатов вычислений или иной обработки данных перед пересылкой их во внешнее ЗУ, на устройство вывода данных или коммуникационные интерфейсы.
Каждой ячейке оперативной памяти присвоен уникальный адрес. Организационные методы распределения памяти предоставляют программистам возможность эффективного использования всей компьютерной системы. К таким методам относят сплошную ("плоскую") модель памяти и сегментированную модель памяти.
При использовании сплошной модели ( flat model) памяти программа оперирует единым непрерывным адресным пространством линейным адресным пространством, в котором ячейки памяти нумеруются последовательно и непрерывно от 0 до 2n-1, где n - разрядность ЦП по адресу. При использовании сегментированной модели (segmented model) для программы память представляется группой независимых адресных блоков, называемых сегментами. Для адресации байта памяти программа должна использовать логический адрес, состоящий из селектора сегмента и смещения. Селектор сегмента выбирает определенный сегмент, а смещение указывает на конкретную ячейку в адресном пространстве выбранного сегмента.
Организационные методы распределения памяти позволяют организовать вычислительную систему, в которой рабочее адресное пространство программы превышает размер фактически имеющейся в системе оперативной памяти, при этом недостаток оперативной памяти заполняется за счет внешней более медленной или более дешевой памяти (винчестер, флэш-память и т.п.) Такую концепцию называют виртуальной памятью. При этом линейное адресное пространство может быть отображено на пространство физических адресов либо непосредственно (линейный адрес есть физический адрес), либо при помощи механизма страничной трансляции. Во втором случае линейное адресное пространство делится на страницы одинакового размера, которые составляют виртуальную память. Страничная трансляция обеспечивает отображение требуемых страниц виртуальной памяти в физическое адресное пространство.
Кроме реализации системы виртуальной памяти внешние ЗУ используются для долговременного хранения программ и данных в виде файлов.
RDRAM
В основе технологии RDRAM лежит многофункциональный протокол обмена данными между микросхемами, который позволяет передачу данных по упрощенной шине, работающей на высокой частоте. RDRAM представляет собой интегрированную на системном уровне технологию. Ключевыми элементами RDRAM являются:
модули DRAM, базирующиеся на Rambus;ячейки Rambus ASIC (RACs);схема соединения чипов, называемая Rambus Channel.
Rambus, впервые использованный в графических рабочих станциях в 1995 году, использует уникальную технологию RSL (Rambus Signal Logic - сигнальная логика Rambus), позволяющую использовать частоты передачи данных до 600MHz на обычных системах и материнских платах. Rambus использует низковольтные сигналы и обеспечивает передачу данных по обоим фронтам сигнала системного таймера. RDRAM использует 8-битовый интерфейс, в то время как EDO RAM и SDRAM используют 4-, 8- и 16-битовый интерфейс. Технологии Rambus запатентованы, поэтому лицензионные отчисления делают производство микросхем памяти этой технологии достаточно дорогим.
Расширением технологии RDRAM является Direct Rambus. Схемотехника Direct Rambus использует те же уровни сигналов (RSL), но более широкую шину (16 бит), более высокие частоты (выше 800MHz) и улучшенный протокол (эффективность выше на 90%). Однобанковый модуль RDRAM обеспечивает скорость передачи 1,6 Гбайт/с, двухбанковый - 3,2 Гбайт/с. Direct Rambus использует два 8-битных канала для передачи 1,6 Гбайт и 3 канала для получения 2,4 Гбайт (рис. 9.5).

увеличить изображение
Рис. 9.5. Архитектура памяти Direct Rambus
SDRAM
Особенностью технологии SDRAM (Synchronous DRAM) является синхронная работа микросхем памяти и процессора. Тактовый генератор, задающий скорость работы микропроцессором, также управляет работой SDRAM. При этом уменьшаются временные задержки в процессе циклов ожидания, и ускоряется поиск данных. Эта синхронизация позволяет контроллеру памяти точно знать время готовности данных. Таким образом, скорость доступа увеличивается благодаря тому, что данные доступны во время каждого такта таймера. Технология SDRAM позволяет использовать множественные банки памяти, функционирующие одновременно, дополнительно к адресации целыми блоками. Микросхемы SDRAM имеют программируемые параметры и свои наборы команд. Длина пакетного цикла чтения-записи может программироваться (1, 2, 4, 8, 256 элементов). Цикл может быть прерван специальной командой без утери данных. Конвейерная организация позволяет инициировать следующий цикл чтения до окончания предыдущего.
SDRAM II (DDR)
Synchronous DRAM II, или DDR (Double Data Rate - удвоенная скорость передачи данных), является развитием SDRAM. Технология DDR основана на тех же принципах, что и SDRAM, однако включает некоторые усовершенствования, позволяющие увеличить быстродействие. DDR дает возможность читать данные по нарастающему и спадающему фронтам тактового сигнала, выполняя два доступа за время одного обращения стандартной SDRAM, что фактически увеличивает скорость доступа вдвое по сравнению с SDRAM, используя при этом ту же частоту. Кроме того, DDR использует DLL (Delay-Locked Loop - цикл с фиксированной задержкой) для выдачи сигнала DataStrobe, означающего доступность данных на выходных контактах. Используя один сигнал DataStrobe на каждые 16 выводов, контроллер может осуществлять доступ к данным более точно и синхронизировать входящие данные, которые поступают из разных модулей, находящихся в одном банке.
Технологии оперативной памяти
Современные технологии оперативной памяти (табл. 9.4) в основном используют два схемотехнических решения для повышения быстродействия DRAM:
включение в микросхемы динамической памяти некоторого количества статической памяти;синхронная работа памяти и ЦП, т.е. использование внутренней конвейерной архитектуры и чередование адресов.
Таблица 9.4. Современные технологии оперативной памяти
| CDRAM (Cache DRAM) | Добавление SRAM (8, 16 Кб) |
| EDRAM (Enhanced DRAM ) | |
| SDRAM (Synchronous DRAM) | 3-х ступенчатый конвейер, 2 банка памяти с доступом типа "пинг-понг" |
| RDRAM (Rambus DRAM) | Функционирует по протоколу расщепления транзакций |
| EDO (Extended Data Out) DRAM | Добавлен набор регистров-защелок |
| BEDO DRAM (Burst EDO DRAM) | |
| DDR400SDRAM | Double Data Rate - данные передаются по переднему и заднему фронтам импульса |
в чем состоит принцип временной
Какая память в ПК является самой быстрой?Объясните, в чем состоит принцип временной и пространственной локальности программы.Какие способы существуют для согласования содержимого кэш-памяти и основной памяти?Перечислите типы кэш-памяти.Какие схемотехнические решения используются для повышения быстродействия DRAM?В каких микросхемах динамической памяти используется включение некоторого количества статической памяти?В каких микросхемах динамической памяти используется внутренняя конвейерная архитектура?В каких микросхемах динамической памяти используются множественные банки памяти, функционирующие одновременно?В каких микросхемах динамической памяти передача данных происходит по обоим уровням сигнала системного таймера?
Области применения RISC-процессоров
Современные RISC-процессоры находят применение как:
рабочие станции высшего ценового класса (12-15 тысяч долларов). Работают под ОС VMS, Unix;персональные рабочие станции (3-7 тыс. $). ОС: Windows NT, Solaris;серверы;RISC ПК.
Основные черты RISC-процессоров
В 70-е годы XX века ученые выдвинули революционную по тем временам идею создания микропроцессора, "понимающего" только минимально возможное количество команд.
Замысел RISC- процессора (Reduced Instruction Set Computer, компьютер с сокращенным набором команд) родился в результате практических исследований частоты использования команд программистами, проведенных в 70-х годах в США и Англии. Их непосредственный итог - известное "правило 80/20": в 80% кода типичной прикладной программы используется лишь 20% простейших машинных команд из всего доступного набора.
Первый "настоящий" RISC-процессор с 31 командой был создан под руководством Дэвида Паттерсона из Университета Беркли, затем последовал процессор с набором из 39 команд. Они включали в себя 20-50 тыс. транзисторов. Плодами трудов Паттерсона воспользовалась компания Sun Microsystems, разработавшая архитектуру SPARC с 75 командами в конце 70-х годов. В 1981 г. в Станфордском университете стартовал проект MIPS по выпуску RISC-процессора с 39 командами. В итоге была основана корпорация Mips Computer в середине 80-х годов и сконструирован следующий процессор уже с 74 командами.
По данным независимой компании IDC, в 1992 году архитектура SPARC занимала 56% рынка, далее следовали MIPS - 15% и PA-RISC - 12,2%
Примерно в то же время Intel разработала серию 80386, последних "истинных" CISC-процессоров в семействе IA-32. В последний раз повышение производительности было достигнуто только за счет усложнения архитектуры процессора: из 16-разрядной она превратилась в 32-разрядную, дополнительные аппаратные компоненты поддерживали виртуальную память, и добавился целый ряд новых команд.
Основные особенности RISC-процессоров:
Сокращенный набор команд (от 80 до 150 команд).Большинство команд выполняется за 1 такт.Большое количество регистров общего назначения.Наличие жестких многоступенчатых конвейеров.Все команды имеют простой формат, и используются немногие способы адресации.Наличие вместительной раздельной кэш-памяти.Применение оптимизирующих компиляторов, которые анализируют исходный код и частично меняют порядок следования команд.
Пиковая производительность RISC-процессоров
Пиковая производительность RISC - процессоров представлена в табл. 10.2.
Таблица 10.2. Пиковая производительность RISC - процессоров
МикропроцессорЧастота, МГцПроизводительность, MFLOPS| DEC Alpha 21164 | 700 | 1400 |
| DEC Alpha 21264 | 800 | 1600 |
| HP PA-8000 | 180 | 720 |
| HP PA-8200 | 236 | 944 |
| HP PA-8500 | 400 | 1600 |
| SGI/MIPS R10000 | 250 | 500 |
| SGI/MIPS R12000 | 300 | 600 |
| Sun Ultra SPARC II | 300 | 600 |
| Sun Ultra SPARC III | 600 | 1200 |
Процессоры PA-RISC компании Hewlett-Packard
Процессор PA-8000 вобрал в себя все известные методы ускорения выполнения команд. В его основе лежит концепция "интеллектуального выполнения", которая базируется на принципе внеочередного выполнения команд. Это свойство позволяет PA-8000 достигать пиковой производительности благодаря широкому использованию механизмов автоматического разрешения конфликтов по данным и управлению аппаратными средствами. Эти средства хорошо дополняют другие архитектурные компоненты, заложенные в структуру кристалла: большое число исполнительных функциональных устройств, средства прогнозирования направления переходов и выполнения команд по предположению, оптимизированная организация кэш-памяти и высокопроизводительный шинный интерфейс.
Высокая производительность PA-8000 во многом определяется наличием большого набора функциональных устройств. В состав PA-8000 входят 10 исполнительных устройств: два арифметико-логических устройства (АЛУ) для выполнения целочисленных операций, два устройства для выполнения операций сдвига/слияния данных, два устройства для выполнения умножения/сложения чисел с плавающей точкой, два устройства деления/вычисления квадратного корня и два устройства выполнения операций загрузки/записи.
Средства внеочередного выполнения команд процессора PA-8000 обеспечивают аппаратное планирование загрузки конвейеров и лучшее использование функциональных устройств. В каждом такте на выполнение могут выдаваться до четырех команд, которые поступают в 56-строчный буфер переупорядочивания. Этот буфер позволяет поддерживать постоянную занятость функциональных устройств и обеспечивает эффективную минимизацию конфликтов по ресурсам.
Кристалл может анализировать все 56 командных строк одновременно и выдавать в каждом такте по 4 готовых для выполнения команды в функциональные устройства. Это позволяет процессору автоматически выявлять параллелизм уровня выполнения команд.
Суперскалярный процессор PA-8000 обеспечивает полный набор средств выполнения 64-битовых операций, включая адресную арифметику, а также арифметику с фиксированной и плавающей точкой. При этом кристалл полностью сохраняет совместимость с 32-битовыми приложениями и с предыдущими и будущими реализациями PA-RISC. Это первый процессор, в котором реализована 64-битовая архитектура PA-RISC.
RISC-процессоры 3-го поколения
Самыми крупными разработчиками RISC-процессоров считаются Sun Microsystems (архитектура SPARC - Ultra SPARC), IBM (многокристальные процессоры Power, однокристальные PowerPC - PowerPC 620), Digital Equipment (Alpha - Alpha 21164), Mips Technologies (семейство Rxx00 -- R 10000), а также Hewlett-Packard (архитектура PA-RISC - PA-8000).
Все RISC-процессоры третьего поколения:
являются 64-х разрядными и суперскалярными (запускаются не менее 4-х команд за такт);имеют встроенные конвейерные блоки арифметики с плавающей точкой;имеют многоуровневую кэш-память. Большинство RISC-процессоров кэшируют предварительно дешифрованные команды;изготавливаются по КМОП-технологии с 4 слоями металлизации.
Для обработки данных применяется алгоритм динамического прогнозирования ветвлений и метод переназначения регистров, что позволяет реализовать внеочередное выполнение команд.
Повышение производительности RISC-процессоров достигается за счет повышения тактовой частоты и усложнения схемы кристалла. Представителями первого направления являются процессоры Alpha фирмы DEC, наиболее сложными остаются процессоры компании Hewlett-Packard. Рассмотрим процессоры этих фирм более подробно.
Процессор Alpha 21264 отличается значительной
Процессор Alpha 21264 отличается значительной новизной по сравнению с предшественником 21164. Он обладает кэш-памятью первого уровня большего объема, дополнительными функциональными блоками, более эффективными средствами предсказания ветвлений, новыми инструкциями обработки видеоданных и широкой шиной.
Alpha 21264 читает до четырех инструкций за один такт и может одновременно исполнять до шести инструкций. Самое большое его отличие от модели 21164 - это способность выполнять команды (впервые для Alpha) с изменением их очередности (Out-of-Order).
Эффективность выполнения Out-of-Order определяется количеством инструкций, которыми может манипулировать ЦП в целях определения оптимального порядка выполнения команд. Чем больше инструкций ЦП может для этого использовать, тем лучше, тем дальше он может заглядывать вперед. Процессоры Intel класса Р6 (Pentium Pro, Pentium II, Xeon) могут одновременно обращаться не менее чем с 40 командами. У других процессоров данный показатель значительно больше: PA-8000 фирмы HP оперирует 56 командами, а процессор Alpha справляется с 80 командами.
Как и большинство RISC-процессоров, Alpha содержит набор из 32 целочисленных и 32 регистров с плавающей запятой, все они имеют разрядность 64 бита. Для повышения эффективности внеочередного выполнения команд процессор 21264 дополнительно к обычному набору регистров снабжен еще 48 целочисленными регистрами и 40 регистрами с плавающей запятой.
Каждый регистр может временно хранить значения текущих команд. Если обрабатывается какая-либо инструкция, нет необходимости перегружать результат в целевой регистр - вместо этого ЦП просто переименовывает временный регистр (Register Renaming).
Подобное переименование регистров есть и в других процессорах. Однако в 21264 реализована уникальная "хитрость" - он имеет задублированный набор целочисленных регистров, каждый из 80 целочисленных регистров дублируется еще раз. Таким образом, на чипе в целом - 160 целочисленных регистров. Это одна из причин, почему, несмотря на сложность выполнения Out-of-Order, допустима высокая частота процессора 21264.
Блоки целочисленных операций в обеих группах идентичны не полностью. Одна из них содержит блок умножения, а вторая - специальную логику для обработки движущихся изображений (MPEG). Для этого набор команд Alpha был дополнен пятью новыми командами. Самая интересная из них - PERR - служит для оценки движения, т.е. выполнения задачи, возникающей как при сжатии, так и декомпрессии MPEG. Команда PERR выполняет работу девяти обычных инструкций. Таким образом, процессор 21264 может декодировать видеопоследовательности MPEG-2, а также DVD-аудиоданные AC-3 в режиме реального времени без использования дополнительных периферийных устройств.
В процессоре 21264, в отличие от его предшественников практически полностью реорганизована иерархия кэш-памяти. Он снабжен одним 64-Кбайт кэшем первого уровня (L1) для инструкций и еще одним 64-Кбайт кэшем первого уровня для данных; оба являются двукратно-ассоциативными. Кэш-память второго уровня (L2) была вынесена за пределы чипа - к ней можно обращаться через 128-бит backside-шину.
Сравнительные характеристики Alpha 21164 и 21264 приведены в табл. 10.1.
Таблица 10.1. Сравнительные характеристики Alpha 21164 и 21264ЦПAlpha 21164Alpha 21264
| Тактовая частота, МГц | 600 | 600 |
| Кэш L1 | Емкость:8(I)+8(D) | Емкость: 64(I)+64(D) |
| Блокируется при числе непопаданий, равном | 2 | 8 |
| Число ФИУ | 4 | 6 |
| Емкость файла | 32 (I) | 80 (I), 2 копии |
| Регистров | 32 (FP) | 72 (FP) |
| Переименование регистров | нет | да |
| Внеочередное выполнение команд | нет | да |
| Динамическое предсказание переходов | да | усовершенствованное |
| Шина верхнего кэша | системная | выделенная |
| Поддержка мультимедиа | нет | да |
| Число транзисторов | 9,3 млн | 15,2 млн |
| Площадь, мм2 | 298 | 302 |
Структура процессора Alpha 21064 представлена
Структура процессора Alpha 21064 представлена на рис. 10.1.

Рис. 10.1. Структура процессора Alpha 21064
Основные функциональные блоки процессора Alpha 21064:
I-cache - кэш команд.IRF - регистровый файл целочисленной арифметики.F-box - устройство арифметики с плавающей точкой.E-box - устройство целочисленной арифметики (7 ступеней конвейера).I-box - командное устройство (управляет кэш команд, выборкой и дешифрацией команд).A-box - устройство управления загрузкой/сохранением данных. Управляет процессом обмена данными м/у IRF, FRF, кэш данных и внешней памятью.Write Buffer - буфер обратной записи.D-cache - КЭШ данных.BIU - интерфейсный блок, с помощью которого подключаются внешняя кэшпамять, размером 128 Кб-8 Мб.
С чем связано появление
С чем связано появление RISC-процессоров?Основные особенности RISC-процессоров.Назовите фирмы-разработчики RISC процессоров.Архитектурные особенности процессоров Alpha.Архитектурные особенности процессора PA-8000.Области применения RISC-процессоров.
История появления параллелизма в архитектуре ЭВМ
Все современные процессоры используют тот или иной вид параллельной обработки. Изначально эти идеи внедрялись в самых передовых, а потому единичных компьютерах своего времени:
1953 г. - IBM 701, 1955 г. - IBM 704: разрядно параллельная память и арифметика, АЛУ с плавающей точкой.1958 г. - IBM 709: независимые процессоры ввода/вывода (т.е. контроллеры ВУ).1961 г. - IBM STRETCH: опережающий просмотр вперед, расслоение памяти на 2 банка.1963 г. - ATLAS: реализована конвейерная обработка данных - конвейер команд.1964 г. - CDC 6600: независимые функциональные устройства.1969 г. - CDC 7600: конвейерные независимые функциональные устройства (8 конвейеров).1974 г. - ALLIAC: матричные процессоры (УУ + матрица из 64 процессоров).1976 г. - CRAY1: векторно-конвейерные процессоры. Введение векторных команд, работающих с целыми массивами независимых данных.
Классы параллельных систем
I. Векторно-конвейерные компьютеры (PVP). Имеют MIMD-архитектуру (множество инструкций над множеством данных).
Основные особенности:
конвейерные функциональные устройства;набор векторных инструкций в системе команд;зацепление команд (используется как средство ускорения вычислений).
Характерным представителем данного направления является семейство векторно-конвейерных компьютеров CRAY.
Рассмотрим, например, суперкомпьютер CRAY Y-MP C90, имеющий следующие характеристики:
Максимальная конфигурация - 16 процессоров, время такта - 4,1 нс, что соответствует тактовой частоте почти 250 МГц.Разделяемые ресурсы процессора: Оперативная память (ОП) разделяется всеми процессорами и секцией ввода/вывода, разделена на множество банков, которые могут работать одновременно.Секция ввода/вывода. Компьютер поддерживает три типа каналов с разной скоростью передачи:
Low-Speed Channels - 6 Мбайт/с
High-Speed Channels - 200 Мбайт/с
Very High-Speed Channels - 1800 Мбайт/с
Секция межпроцессорного взаимодействия содержит регистры и семафоры, предназначенные для передачи данных и управляющей информации.Вычислительная секция процессора состоит из: регистров (адресных, скалярных, векторных);функциональных устройств;сети коммуникаций.Секция управления.
Команды выбираются из ОП блоками и заносятся в буфера команд.
Параллельное выполнение программ.
Все основные операции, выполняемые процессором - обращение в память, обработка команд и выполнение инструкций - являются конвейерными.
II. Массивно-параллельные компьютеры с распределенной памятью. Объединяется несколько серийных микропроцессоров, каждый со своей локальной памятью, посредством некоторой коммуникационной среды.
Достоинств у такой архитектуры много: если нужна высокая производительность, то можно добавить еще процессоров; если ограничены финансы или заранее известна требуемая вычислительная мощность, то легко подобрать оптимальную конфигурацию и т.д.
Каждый процессор имеет доступ лишь к своей локальной памяти, а если программе нужно узнать значение переменной, расположенной в памяти другого процессора, то задействуется механизм передачи сообщений.
Блоки целочисленных операций в обеих группах идентичны не полностью. Одна из них содержит блок умножения, а вторая - специальную логику для обработки движущихся изображений (MPEG). Для этого набор команд Alpha был дополнен пятью новыми командами. Самая интересная из них - PERR - служит для оценки движения, т.е. выполнения задачи, возникающей как при сжатии, так и декомпрессии MPEG. Команда PERR выполняет работу девяти обычных инструкций. Таким образом, процессор 21264 может декодировать видеопоследовательности MPEG-2, а также DVD-аудиоданные AC-3 в режиме реального времени без использования дополнительных периферийных устройств.
В процессоре 21264, в отличие от его предшественников практически полностью реорганизована иерархия кэш-памяти. Он снабжен одним 64-Кбайт кэшем первого уровня (L1) для инструкций и еще одним 64-Кбайт кэшем первого уровня для данных; оба являются двукратно-ассоциативными. Кэш-память второго уровня (L2) была вынесена за пределы чипа - к ней можно обращаться через 128-бит backside-шину.
Сравнительные характеристики Alpha 21164 и 21264 приведены в табл. 10.1.
| Тактовая частота, МГц | 600 | 600 |
| Кэш L1 | Емкость:8(I)+8(D) | Емкость: 64(I)+64(D) |
| Блокируется при числе непопаданий, равном | 2 | 8 |
| Число ФИУ | 4 | 6 |
| Емкость файла | 32 (I) | 80 (I), 2 копии |
| Регистров | 32 (FP) | 72 (FP) |
| Переименование регистров | нет | да |
| Внеочередное выполнение команд | нет | да |
| Динамическое предсказание переходов | да | усовершенствованное |
| Шина верхнего кэша | системная | выделенная |
| Поддержка мультимедиа | нет | да |
| Число транзисторов | 9,3 млн | 15,2 млн |
| Площадь, мм2 | 298 | 302 |
Оценки производительности супер-ЭВМ
Большинство оценочных характеристик производительности супер-ЭВМ связано с вычислениями над вещественными числами. К ним относится пиковая производительность (ПП), измеряемая в млн. операций с плавающей точкой, которые компьютер теоретически может выполнить за 1 с (MFLOPS).
ПП - величина, практически не достижимая. Это связано с проблемами заполнения функциональных конвейерных устройств. Чем больше конвейер, тем больше надо "инициализационного" времени для того, чтобы его заполнить. Такие конвейеры эффективны при работе с длинными векторами. Поэтому для оценки векторных супер-ЭВМ было введено такое понятие, как длина полупроизводительности - длина вектора, при которой достигается половина пиковой производительности.
Более реальные оценки производительности базируются на временах выполнения различных тестов. Самыми хорошими тестами являются реальные задачи пользователя. Однако такие оценки, во-первых, весьма специфичны, а во-вторых, часто вообще недоступны или отсутствуют. Поэтому обычно применяются более универсальные тесты.
Поскольку большую часть времени выполнения программ обычно занимают циклы, иногда именно они применяются в качестве тестов, например, известные ливерморские циклы.
Наиболее популярным тестом производительности является Linpack, который представляет собой решение системы N линейных уравнений методом Гаусса. Так как известно, сколько операций с вещественными числами нужно проделать для решения системы, то, зная время расчета, можно вычислить выполняемое в секунду количество операций.
Имеется несколько модификаций этих тестов. Обычно фирмы-производители компьютеров приводят результаты при N = 100.
Свободно распространяется стандартная программа на Фортране, которую надо выполнить на суперкомпьютере, чтобы получить результат тестирования. Эта программа не может быть изменена, за исключением замены вызовов подпрограмм, дающих доступ к процессорному времени выполнения.
Другой стандартный тест относится к случаю N = 1000, предполагающему использование длинных векторов.
Эти тесты могут выполняться на компьютерах при разном числе процессоров, давая также оценки качества распараллеливания.
Для MPP-систем более интересным является тест Linpack-parallel, в котором производительность измеряется при больших N и большом количестве процессоров. Здесь лидером является 6768-процессорный Intel Paragon (281 GFLOPS при N = 128600). Что касается производительности процессоров, то при N = 100 лидирует Cray T916 (522 MFLOPS), при N = 1000 и по пиковой производительности - Hitachi S3800 (соответственно 6431 и 8000 MFLOPS). Для сравнения, процессор в AlphaServer 8400 имеет 140 MFLOPS при N =100 и 411 MFLOPS при N = 1000.
Для высокопараллельных суперкомпьютеров в последнее время все больше используются тесты NAS parallel benchmark, которые особенно хороши для задач вычислительной газо- и гидродинамики. Их недостатком является фиксация алгоритма решения, а не текста программы.
14 ноября 2005 года была опубликована 26-я редакция списка 500 наиболее мощных компьютеров мира Top500.
На первом месте в 26-й редакции списка остался прототип будущего суперкомпьютера IBM BlueGene/L, число процессоров которого увеличилось до 131072, а производительность на Linpack - до 280.6 Tflop/s.
На втором месте осталась другая инсталляция суперкомпьютера IBM BlueGene/L, установленная в Thomas J. Watson Research Center, на основе 40960 процессоров с производительностью на Linpack 91.29 Tflop/s.
На третье место в новой редакции списка вышел суперкомпьютер ASC Purple производства IBM на основе 10240 процессоров p5 575 1.9 ГГц с производительностью на Linpack 63.39 Tflop/s.
На 5-ом месте оказался суперкомпьютер Thunderbird производства Dell на основе 8000 процессоров PowerEdge 1850 3.6 ГГц с производительностью на Linpack 38.27 Tflop/s. На 6-ом месте - суперкомпьютер Red Storm производства Cray на основе технологии XT3 с производительностью на Linpack 36.19 Tflop/s.
Суперкомпьютер Earth Simulator, долгое время возглавлявший список, оказался в новой редакции уже на 7-м месте.
Суперкомпьютер Earth Simulator предназначен для моделирования климатических изменений на основе данных, которые поступают со спутников.
Параллельная обработка данных на ЭВМ
Оксфордский толковый словарь по вычислительной технике, изданный в 1986 году, сообщает, что суперкомпьютер - это очень мощная ЭВМ с производительностью свыше 10 MFLOPS. Сегодня этот результат перекрывают уже не только рабочие станции, но, по пиковой производительности, и ПК. В начале 1990-х годов границу проводили уже около отметки в 300 MFLOPS. В 2001 году специалисты двух ведущих "суперкомпьютерных" стран, США и Японии, договорились о подъеме планки до 5 GFLOPS.
Таким образом, основные признаки, характеризующие супер-ЭВМ, следующие:
самая высокая производительность;самый современный технологический уровень (например, GaAs-технология);специфические архитектурные решения, направленные на повышение быстродействия (например, наличие операций над векторами);цена, обычно свыше 1-2 млн. долларов.
Какой из факторов является решающим в достижении современных фантастических показателей производительности? Обратимся к историческим фактам. На одном из самых первых компьютеров EDSAC (1949 г.), имевшем время такта 2 мкс, можно было выполнить в среднем 100 арифметических операций в секунду. А пиковая производительность суперкомпьютера CRAY C90 с временем такта порядка 4 нс - около 1 миллиарда арифметических операций в секунду. Таким образом, производительность компьютеров за этот период возросла примерно в 10 миллионов раз, а время такта уменьшилось лишь в 500 раз. Следовательно, увеличение производительности происходило и за счет других факторов, важнейшим среди которых является использование новых архитектурных решений, в частности - принципа параллельной обработки данных.
Параллельная обработка данных имеет две разновидности: конвейерность и параллельность.
Идея конвейерной обработки заключается в выделении отдельных этапов выполнения общей операции, причем так, чтобы каждый этап, выполнив свою работу, передавал бы результат следующему, одновременно принимая новую порцию входных данных. Выигрыш в скорости обработки данных получается за счет совмещения прежде разнесенных во времени операций.
Параллельная обработка данных предполагает наличие нескольких функционально независимых устройств.
Технологии параллельного программирования
Средства программирования: параллельные расширения и диалекты языков - Fortran, C/C++, ADA и др.
Самым крупным достижением в деле создания программного обеспечения была стандартизация интерфейса передачи сообщений MPI (Message Passing Interface). Набор функций этого интерфейса вобрал в себя лучшие черты своих предшественников. Основные достоинства MPI:
поддержка нескольких режимов передачи данных;предусматривает гетерогенные вычисления;передача типизированных сообщений;построение библиотек - MPICH, LAM MPI;наличие вариантов для языков программирования C/C++, Fortran;поддерживает коллективные операции: широковещательную передачу, разборку/сборку, операции редукции;совместимость с многопоточностью.
Когда впервые реализована конвейерная обработка
Когда впервые реализована конвейерная обработка данных?Перечислите способы параллельной обработки данных.Сформулируйте следствие из закона Амдала.Назовите классы параллельных систем.Основные особенности векторно-конвейерных компьютеров.К какому классу параллельных систем относятся компьютеры Intel Paragon и CRAY T3D?В каких классах параллельных систем оперативная память разделяется между несколькими процессорами?Перечислите особенности MPI-интерфейса.Что представляет собой тест оценки производительности суперЭВМ Linpack?Какие тесты оценки производительности супер-ЭВМ вы знаете?
Закон Амдала
Закон Амдала
S<= 1/ [f + (1-f)/p]
где S - ускорение, f - доля операций, которые нужно выполнить последовательно, p - число процессоров.
Следствие из закона Амдала: для того чтобы ускорить выполнение программы в q раз, необходимо ускорить не менее чем в q раз и не менее чем (1-1/q)-ую часть программы. Следовательно, если нужно ускорить программу в 100 раз по сравнению с ее последовательным вариантом, то необходимо получить не меньшее ускорение на не менее чем 99,99 % кода!
