Аннотация
Статья является продолжением статьи и рассматривает некоторые дополнительные возможности пакета DBMS_SQLTUNE по выполнению углубленного анализа отдельных запросов и групп запросов.
Автоматизация настройки запросов в версии Oracle 10g: некоторые дополнительные возможности
,
Преподаватель технологий Oracle,
| "Уж мы его - и этак и раз-этак, - Буржуя энтого... которого... в Крыму..." И клены морщатся ушами длинных веток, И бабы охают в немую полутьму. С. Есенин. Русь советская. | ||
| Уж я к ней и так, и этак, Со словами и без слов! Обломал немало веток, Наломал немало дров! М. Танич. Страдание. |
Групповая настройка запросов
Средствами DBMS_SQLTUNE можно провести углубленный анализ (с построением, если возможно, профиля) сразу для групп запросов - например, поступающих из заданного приложения, или выбранных из рабочей области SQL в SGA СУБД. Ниже приводится пример второго.
Построим набор запросов, поступавших от пользователя SCOTT:
EXECUTE DBMS_SQLTUNE.CREATE_SQLSET ( 'my_workload' )
DECLARE cur DBMS_SQLTUNE.SQLSET_CURSOR;
BEGIN OPEN cur FOR SELECT VALUE ( P ) FROM TABLE ( DBMS_SQLTUNE.SELECT_CURSOR_CACHE ( basic_filter => 'parsing_schema_name = ''SCOTT''' , attribute_list => 'ALL' ) ) P ;
DBMS_SQLTUNE.LOAD_SQLSET ( sqlset_name => 'my_workload'
, populate_cursor => cur ); END; /
Табличная функция SELECT_CURSOR_CACHE возвращает вложенную таблицу объектов типа DBMS_SQLTUNE.SQLSET_ROW, каждый из которых содержит сведения о запросах, отобранных из рабочей области SQL в SGA. Загрузка "набора запросов" выполняется процедурой LOAD_SQLSET через ссылку на курсор, сформированый после преобразования вложенной таблицы в список объектов функцией TABLE. Фильтр для отбора строк в набор запросов из области SQL строится как условное выражение по полям таблицы V$SQLAREA и может быть гораздо более сложным. Тип SQLSET_CURSOR есть просто тип нестрогой ссылки на курсор, то же, что SYS_REFCURSOR, однако зачем-то определен самостоятельно в пакете DBMS_SQLTUNE и здесь употреблен по инерции.
Построим задание для углубленного анализа созданого набора запросов:
VARIABLE ttask VARCHAR2 ( 100 )
BEGIN :ttask := DBMS_SQLTUNE.CREATE_TUNING_TASK ( sqlset_name => 'my_workload' , task_name => 'my_sqlset_task'
); END; /
Выполним анализ:
EXECUTE DBMS_SQLTUNE.EXECUTE_TUNING_TASK ( :ttask )
Средствами пакета можно формировать наборы запросов для анализа и иначе, например по данным репозитария рабочей нагрузки (Automatic Workload Repository).
Настройка запроса по ссылке в рабочей области SQL в SGA
Углубленный анализ запроса можно выполнить, сославшись на его идентификатор в рабочей области SQL в SGA, на SQL_ID (V$SQLAREA). Например, в нашем случае можно было бы создать задание так:
DECLARE my_task_name VARCHAR2 ( 30 );
BEGIN my_task_name := DBMS_SQLTUNE.CREATE_TUNING_TASK ( sql_id => '3dcfttkf1kwmn'
, task_name => 'a_very_hard_sql_task' ); END; /
Получение рекомендаций в виде готового сценария
Вместо представления в повествовательной форме (с помощью функции REPORT_TUNUNG_TASK) рекомендации можо получить в виде готового сценария для SQL*Plus:
SELECT DBMS_SQLTUNE.SCRIPT_TUNING_TASK ( 'my_sql_tuning_task' ) FROM dual;
Получим примерно такой результат:
DBMS_SQLTUNE.SCRIPT_TUNING_TASK('MY_SQL_TUNING_TASK') ------------------------------------------------------------------------------------- ----------------------------------------------------------------- -- Script generated by DBMS_SQLTUNE package, advisor framework -- -- Use this script to implement some of the recommendations -- -- made by the SQL tuning advisor. -- -- -- -- NOTE: this script may need to be edited for your system -- -- (index names, privileges, etc) before it is executed. -- ----------------------------------------------------------------- execute dbms_stats.gather_table_stats(ownname => 'SCOTT', tabname => 'DEPT', estimate_percent => DBMS_STATS.AUTO_SAMPLE_SIZE, method_opt => 'FOR ALL COLUMNS SIZE AUTO', cascade => TRUE); execute dbms_sqltune.accept_sql_profile(task_name => 'my_sql_tuning_task', replace => TRUE);
(Здесь приведены две команды EXECUTE, слишком длинные, чтобы каждой поместиться в одной строке экрана).
Возможна и более ограниченная выдача, например:
SELECT DBMS_SQLTUNE.SCRIPT_TUNING_TASK ( 'my_sql_tuning_task', 'STATISTICS, INDEXES' ) FROM dual ;
в реляционной системе для разработчика
|
Вроде - гляну - все в порядке, А выходит ерунда! М. Танич. Страдание. |
В светлом прошлом отцы-основатели реляционного подхода к моделированию баз данных ("моделирование с помощью отношений") полагали, что в реляционной системе для разработчика приложения нет понятия "настройка запроса". Считалось, что разработчик будет формулировать запросы так, как ему удобнее их читать, а оптимизацией выполнения запроса займется СУБД.
Равно как и все прочие разработчики СУБД, использовавшие прилагательное "реляционная" для своих систем, фирма Oracle назвалась груздем, а в кузов полезать не торопилась. Настройкой запросов в Oracle заниматься приходилось с самого начала этой СУБД. Первый оптимизатор запросов (часть СУБД, отвечающая за выработку плана обработки запроса), rule-based, был прост, скор и... неадекватен. Частые плохие планы требовали ручной работы по анализу и переформулировке. Пока нагрузки на БД были невелики, это можно было терпеть, но со временем потребовалось разработать новый вариант оптимизатора - cost-based. Он решил многие проблемы оптимизатора доступа, но ручной работы вряд ли убавил, породив целый класс специалистов по "подсказкам" оптимизатору. Тем не менее, появившись в последних выпусках версии 7, он все-таки совершенствовался от версии к версии.
Наконец, третий существенный шаг по отработке долгосрочного кредита, получаемого в течение многих лет от покупателей своей системы, фирма Oracle сделала как раз в версии 10. Углубленный анализ действительно позволяет делать много нового, например, обнаруживать декартовы произведения, поступающие от приложений (проверьте!), за что ему уже можно ставить памятник. Однако не надо забывать, что он, подобно сбору статистики для объектов запроса (таблиц, ...) осуществляется вручную и требует своевременного (когда ?...) повторения.
Надо надеяться, что в следующих версиях фирма еще больше приблизится к тому, что замышлялось создателями реляционного подхода 30 лет назад. Для этого потребуется самая малость: сделать ручное выполнение углубленного анализа запроса автоматическим и основным!
Архитектура Oracle Streams
Oracle Streams реализован на основе системы обмена очередями сообщений Oracle Advanced Queuing. При конфигурировании Oracle Streams в каждой БД, участвующей в обмене информацией, запускаются дополнительные процессы и создаются дополнительные структуры данных, необходимые для поддержки потоков информации.
Единица информации, помещаемая в поток, называется событием (event). Этот универсальный элемент потока может быть либо стандартного типа (он называется LCR – Logical Change Record) и содержит информацию о DDL или DML изменениях в исходной БД, либо произвольного типа – тогда это просто пользовательское сообщение, за помещение которого в поток и извлечение из потока отвечают пользовательские программы. Т. е. в одном потоке можно передавать как информацию об изменениях данных и структур, так и произвольные сообщения. Причем в один и тот же поток могут помещать свои элементы различные БД и приложения. А в целевых узлах из этого потока будет извлечены только те элементы, которые нужны данному узлу.
Поток данных может течь как внутри одной БД (таким образом удобно поддерживать копии объектов, материализованные представления (snapshots), реализовывать систему извещения о событиях), так и между различными БД. В этом случае область хранения (Staging Area) целевой БД просто “подписывается” на информацию из Staging Area исходной БД. После этого необходимая информация автоматически течет из исходной БД в целевую.
Извещение о событиях
Очень часто необходимо в автоматическом режиме извещать пользователей приложения о каких-либо событиях или изменениях, происходящих в БД или приложении. Например, система Orbitz посылает на пейджер пользователей информацию о задержках авиарейсов. Система CNET Shopper отслеживает изменение цен на товары и при снижении цен извещает об этом пользователей. CRM приложения могут оповещать продавцов о покупках, совершаемых наиболее важными заказчиками.
Oracle Streams позволяет легко создать приложение такого типа в БД. Для этого используется следующая архитектура:
Неявный захват e
хранение e
явное извлечение из потока
Пользовательская программа извлекает из потока данные об изменениях, формирует на их основе сообщения для пользователей и отправляет эти сообщения на пейджер, телефон, по электронной почте и т д.
Обмен информацией
При построении современных информационных систем пользователи редко ограничиваются одним компьютером с одной базой данных (БД). Гораздо чаще приходится использовать многосерверные архитектуры. Причины этого кроются в задачах, которые приходится решать, и в архитектурах создаваемых прикладных систем. Например, типичная архитектура информационной системы крупного предприятия имеет такие элементы, как центральная БД и БД филиалов или регионов. И эти узлы должны обмениваться информацией. Другой пример – интеграция старых информационных систем, успешно работающих на предприятии, и вновь создаваемых на других компьютерах информационных систем. Типичный пример многосерверной архитектуры возникает и в тех случаях, когда в организации создается хранилище данных, собирающее информацию из нескольких оперативных систем, или для повышения надежности прикладной системы предприятие организует резервные информационные центры. Информацией могут обмениваются не только различные СУБД (возможно выпускаемые различными фирмами). Информацией должны обмениваться и приложения и пользователи. Причем они обмениваются не только информацией об изменении данных в одной из систем, но также информацией о выполненных транзакциях, произошедших событиях, сообщениями и т д.
Если в старых системах приложение, которому требовалась информация из другого приложения, кодировалось так, что оно просто время от времени явно запрашивало это второе приложение об изменениях, то в современных информационных системах необходимо, чтобы процесс обмена информацией происходил автоматически, не требовал программирования. Надо чтобы передавалась только та информация, которая нужна, в то время и в то место, когда и где она действительно нужна, не перегружая при этом сеть и исходную БД.
Многие компании для решения задачи обмена информацией приобретают специальные программные пакеты разных фирм для поддержки этих функций. В этом случае им приходится приобретать сервер репликации, пакет для работы с очередями сообщений, средства загрузки данных в хранилища и витрины данных, ПО для нотификации (извещения о событиях) и управления событиями и т д. Иногда достаточно приобрести только часть этих средств. Не будем говорить о стоимости этого дополнительного программного обеспечения и недостатках многих из этих пакетов. Главная проблема здесь – интеграция. Сложность интеграции этих разнородных систем с различной архитектурой, языками, средствами доступа и т д настолько велика, что большинство интеграционных проектов оканчивается неудачей.
Пользователям СУБД Oracle несколько проще, поскольку средства для репликации, обмена сообщениями, организации резервной БД, захвата изменений и загрузки хранилищ и витрин данных входят в состав сервера Oracle 9i без дополнительной платы (см. табл. 1). Однако и у такого подхода есть много недостатков.
Таблица 1. Типичные решения для обмена информацией
| Купить у разных фирм | Oracle |
| Replication Tools | Advanced Replication |
| Messaging Software | Advanced Queueing |
| Warehouse Loaders | CMC + Loader + WB |
| HA, Performance SW | Standby |
| Middleware | Integration in iAS |
| Event Management apps | ---- |
| Notification apps | ---- |
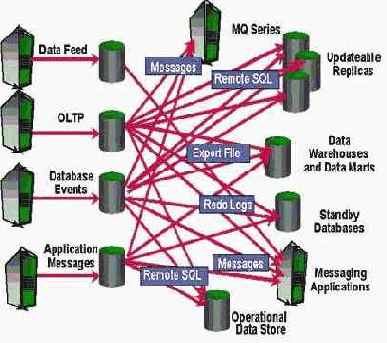
Рис 1. Традиционная интеграция данных
В такую архитектуру трудно встроить приложения, построенные на основе чужих (не Oracle) СУБД, в ней трудно реализовать систему извещения пользователей о событиях и управления событиями (это требует написания программного кода). А если мы во время эксплуатации системы решим, например, не реплицировать в резервную БД изменения отдельных объектов, а поддерживать полноценную копию всей исходной БД, то это потребует большого объема работы со стороны администратора БД, т е наша архитектура не является гибкой.
Поэтому Oracle решил создать новый универсальный гибкий механизм обмена информацией, свободный от этих недостатков и позволяющий одновременно реализовать репликацию, обмен сообщениями, загрузку хранилищ данных, работу с событиями, поддержку резервной БД (логический Standby). Этот механизм называется Oracle Streams.
Oracle Streams состоит из трех основных элементов: захват изменений (Capture) складирование, хранение и распространение изменений (Staging) применение изменений (Consumption или Apply)
Теперь в исходной системе вся необходимая для различных механизмов обмена информация автоматически захватывается, упорядочивается, преобразуется в универсальный формат и помещается в область хранения. Далее она автоматически перемещается между областями хранения и в тех целевых узлах, где она нужна, эта информация используется Apply процессами, которые выполняют репликацию или загружают хранилище данных или обновляют резервную БД и т д. Приложениям – потребителям достаточно просто подписаться на необходимую им информацию и они будут ее автоматически получать, а Apply процессы будут ее автоматически применять. Мы видим, что теперь картинка с рисунка 1 значительно упростилась (см рис. 2). Количество связей уменьшилось, механизм упростился. Заказчик теперь должен покупать, изучать, конфигурировать и поддерживать только один продукт, добавление новых публикаторов (добавляющих информацию об изменениях в поток) и новых подписчиков (потребляющих информацию из потока) осуществляется легко, замена одного механизма обмена информацией на другой выполняется просто. И главное, падает нагрузка на сеть и эксплуатационную систему. Oracle Streams захватывает информацию об изменениях из журнальных файлов, не нагружая эксплуатационную систему, причем он захватывает и передает ее только один раз, не дублируя информацию. Кстати Oracle Streams входит в состав сервера Oracle без дополнительной платы.
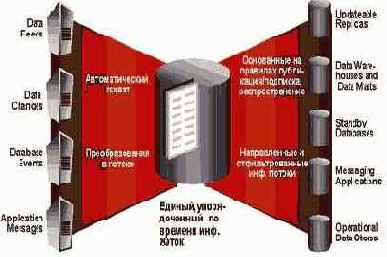
Рис. 2. Интеграция данных в Oracle Streams
Очереди сообщений
Oracle Streams построен на основе системы передачи сообщений Oracle Advanced Queuing и поддерживает все функции развитой системы обмена сообщениями, такие как публикация и подписка на основе правил, очереди со многими потребителями (multi-consumer), что уменьшает загрузку сети, подписка на основе контента сообщения.. Уникальная возможность интеграции в одной очереди данных для репликации и сообщений позволяет реализовать единую модель работы для передачи транзакций и сообщений, единую модель безопасности, повысить надежность системы. Oracle Streams поддерживает автоматическое преобразование информации о DDL и DML операциях в формат сообщений.
В случае работы с сообщениями используется архитектура:
Явный захват e
хранение e
перемещение e
явное извлечение
Построенная на основе Oracle Streams система очередей сообщений позволяет легко интегрировать разнородные системы, легко разрабатывать приложения, обмениваться сообщениями с Message Queuing системами различных фирм.
Oracle Streams - универсальное средство обмена информацией
Статья была опубликована в журналах "BYTE/Россия" и
Правила
Как уже упоминалось ранее, не все изменения выбираются из журналов БД, не все изменения притекают в конкретные узлы и не все изменения применяются к конкретной БД. Фильтрация изменений реализуется за счет того, что подписка на изменения основана на правилах. Правила регламентируют, какую информацию надо захватывать, транспортировать, применять. Причем эти правила используют содержимое элемента потока, т е мы можем указать, что в конкретный узел попадают только изменения для конкретных объектов. Кроме того, изменение, например, значения поля “Страна” в записи с “UK” на “Russia” приведет к тому, что эти изменения потекут и будут применены не в Англии, а в российских узлах.
Машина правил существует в сервере Oracle независимо от Oracle Streams. Пользовательские приложения, так же как Oracle Streams, могут использовать ее, передавая ей оцениваемую строку и имя набора правил и получая ответ (истина/ложь). Правила описываются пользователем как обычное условие, напоминающее предикат SQL выражения WHERE и являются объектами БД. Из отдельных правил набираются наборы правил , т н RULE SETS, которые машина правил и применяет для оценки. Кстати с помощью правил можно не только отфильтровать изменения, относящиеся к отдельным объектам БД или схемам, DDL или DML операции, но, также, наложить условие на изменения таблицы, применяемые в конкретном узле, порождая, таким образом, разные подмножества одной таблицы в разных БД.
Конфигурирование маршрута потока независимо от конфигурирования Apply процессов конкретных узлов. Благодаря этому и системе правил мы можем управлять движением потока. Например, поток может течь через некоторые узлы не меняя их БД. Это позволяет уменьшить нагрузку на сеть, т к все изменения не текут от исходной БД во все целевые БД, создавая много “широких” потоков. Вместо этого мы имеем широкий поток, который затем расщепляется на несколько более мелких. Например, если в Нью- Йорке в таблицу записываются данные, часть из которых должна быть отреплицирована в БД Англии, часть в БД Италии, а часть в БД Франции, то мы можем направить весь поток из Америки через океан в Европу (в Лондон). Там изменения для Англии будут извлечены и обработаны, а поток расщепится и часть изменений пойдет в Италию, а часть – во Францию (см. рис. 3).
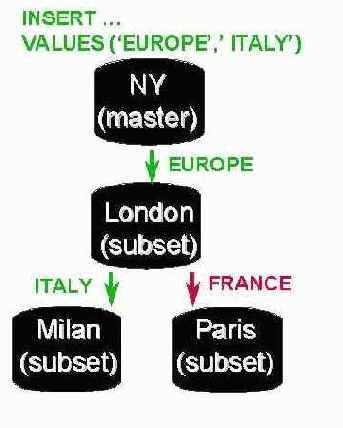
Рис. 3. Расщепление потока
Поскольку Apply процесс БД Oracle может через Database Link и шлюз вносить изменения в чужие БД или передавать сообщения в чужие системы управления сообщениями, а приложения, работающие с чужими СУБД и системами сообщений могут помещать LCRы и сообщения в поток Oracle, механизм Oracle Streams удобно использовать для обмена информацией и интеграции разнородных приложений построенных как на платформе Oracle, так и на платформах других компаний. Шлюз Message Gateway позволяет работать с сообщениями потока Oracle Streams из пакета MQ Series.
Установка, конфигурирование и поддержка Oracle Streams в различных режимах может осуществляться через дружелюбный графический интерфейс штатного инструмента администратора Oracle – Oracle Enterprise Manager.
Преимущества Oracle Streams
Итак Oracle Streams обеспечивает репликацию, обмен сообщениями, поддержку логической резервной БД, загрузку хранилищ и витрин данных, извещение о событиях. Однако он не только реализует эти отдельно существовавшие механизмы обмена информацией, но и обеспечивает им ряд дополнительных преимуществ, которыми они ранее не обладали.
Применение изменений
Когда поток достигает Staging Area целевой БД, на него “набрасываются” Apply процессы этой целевой БД (если они там имеются), подписавшиеся на этот поток Они извлекают предназначенные для данного узла элементы потока и применяют их к своей БД. Apply процессов в БД может быть несколько. Для извлечения пользовательских сообщений из потока пишутся пользовательские Apply процессы, которые явно извлекают сообщения из потока (очереди). Эти пользовательские приложения пишутся на Java (JMS), C, PL/SQL, SOAP (XML/HTTP), XML/SMTP.
Более интересны, однако, автоматически срабатывающие т н “дефолтные” Apply процессы. Они читают LCRы из потока, преобразуют их в команды DML или DDL и автоматически применяют эти SQL команды к БД. Причем команды SQL могут применяться как к таблицам и объектам локальной БД, так и через Database Link и шлюз (Gateway) к таблицам чужих (не Oracle) СУБД.
Поскольку целевая БД кроме участия в обмене информацией может быть открыта для изменений другими приложениями, мы можем получить ситуацию, когда одни и те же данные одновременно изменены и в исходной и в целевой БД. Т. е. мы сталкиваемся с конфликтами обновления и должны уметь их разрешать. Oracle Streams умеет автоматически определять и разрешать такие конфликты. Имеется ряд стандартных механизмов разрешения конфликтов (берется минимальное или максимальное значение, последнее по времени изменение и т д), можно написать свои собственные процедуры разрешения конфликтов.
Для ускорения работы по применению изменений к БД Apply процесс фактически выступает в роли координатора этой работы. Он порождает параллельно работающие подпроцессы, которые читают LCRы из потока, собирают их в транзакции, а потом параллельно применяют к БД. Если в потоке сосуществуют LCRы из разных узлов, захваченные разными Capture процессами, то для их применения в данном узле надо создать несколько Apply процессов (для каждого Capture – свой Apply).
Кроме того, “дефолтный” Apply процесс может не только формировать команды SQL на основе LCRов, но и выполнять более сложную обработку. В этом случае для него указывается имя пользовательской Apply функции, которая получает LCRы, обрабатывает их и применяет к БД. Эти функции можно писать на PL/SQL, Java, C, C++. Такие функции кроме применения LCR к БД могут, например, выполнять дополнительные преобразования данных, исключать из изменения некоторые колонки, нормализовывать/денормализовывать данные, записывать дополнительную информацию в другие колонки и таблицы (не указанные в LCR) и т д.
Репликация
В случае репликации используется следующая архитектура:
Неявный захват e
хранение e
перемещение e
неявный дефолтный Apply
Это самый простой вид использования Oracle Streams. Он легко конфигурируется и поддерживает автоматическую асинхронную репликацию многих копий объекта. Причем реплицироваться могут данные как между одинаковыми объектами (весь объект или часть объекта), так данные между объектами с разной структурой (через преобразования или Apply функцию).
Oracle Streams автоматически захватывает, передает и применяет DDL и DDL изменения, определяет и разрешает конфликты, позволяет выполнять репликацию с объектами в чужих СУБД, снижает нагрузку на сеть и эксплуатационную систему по сравнению с обычной репликацией, за счет извлечения информации из журналов.
Резервная БД (Logical Standby)
Для защиты прикладной системы от катастрофических сбоев, приводящих к выходу из строя не отдельного компьютера, а всего вычислительного центра, где находится основная эксплуатационная БД, используются резервные БД, расположенные вдалеке от здания основной БД. Такая резервная БД должна принимать и применять все изменения из основной БД, а в случае катастрофического сбоя быстро и без потерь заменить основную БД. Практически обновление резервной БД – это частный случай репликации, поскольку реплицируются все изменения в БД и изменения передаются в одну сторону – от эксплуатационной БД к резервной БД.
В случае использования Oracle Streams для поддержки резервной БД используется архитектура, несколько отличная от предыдущих. Перенос журналов Oracle (или информации об изменениях) из узла в узел осуществляется вне Oracle Streams с помощью механизма Oracle Data Guard. А вот на узле, где расположена резервная БД, архитектура Oracle Streams имеет следующий вид:
Неявный захват e
неявный дефолтный Apply
Oracle Streams позволяет реализовать на резервном узле т. н. Режим логического Standby. Т е резервная БД во время применения изменений открыта на чтение. Изменение производятся за счет применения обычных SQL операций. Поэтому резервная БД может одновременно и догонять основную БД и использоваться для построения отчетов, выполнения аналитических задач и т д, разгружая эксплуатационную БД. Для повышения эффективности выполнения этих дополнительных задач в резервной БД можно создать дополнительные индексы, таблицы, материализованные представления и т д, т е структура может отличаться от структуры эксплуатационной БД. Кроме того, эксплуатационная и резервная БД могут работать на разных платформах (операционная система и компьютер) и даже немного различаться по версиям сервера БД. Для конфигурирования и сопровождения такой логической резервной БД используется графический интерфейс компоненты Oracle Data Guard, входящей в состав Oracle Enterprise Manager.
Таким образом новое средство Oracle сервер для обмена информацией - Oracle Streams обеспечивает удобный гибкий универсальный автоматически работающий механизм интеграции приложений и баз данных.
Складирование, хранение и распространение изменений
Вся захваченная информация хранится в областях хранения (Staging Area). Они реализуются в виде очередей сообщений, поэтому для работы с ними можно использовать стандартный API Advanced Queuing. Однако, поскольку в этой очереди хранятся не только сообщения стандартных типов, но и информация об изменениях различных типов данных в БД, Oracle ввел поддержку нового самоописывающегося типа данных Sys.AnyData. В этом типе данных могут храниться самые разные типы информации. Он позволяет совмещать в одной очереди (потоке) различные типы данных. Методы этого объектного типа позволяют извлекать информацию о типе хранящегося экземпляра объекта, сам экземпляр объекта, его элементы, модифицировать экземпляр объекта, преобразовывать другие типы в Sys.AnyData и т д.
Все элементы потока, помещенные в Staging Area, хранятся в ней до тех пор, пока все подписчики, подписавшиеся на эти элементы, не используют их. Напомним, что подписчиками могут быть не только Apply процессы, но и другие Staging Area или пользовательские приложения. Использованные элементы потока автоматически уничтожаются, однако можно отменить уничтожение и оставлять их в Staging Area, например, для выполнения аудита.
При помещении элементов потока в Staging Area, при их извлечении из нее и при перемещении в другую Staging Area можно выполнять преобразование элементов. Преобразования выполняются автоматически, необходимо лишь указать при конфигурировании какие процедуры будут выполнять преобразование и для каких элементов потока эти процедуры надо вызывать. Каждая процедура преобразования получает на входе элемент потока (LCR или сообщение), модифицирует его и возвращает модифицированный элемент потока. Например, такая процедура может изменить формат или тип данных реплицируемой колонки, изменить имя колонки или таблицы и т. д. Это позволяет использовать Oracle Streams для репликации данных между объектами разной структуры.
Загрузка хранилищ и витрин данных
В случае загрузки хранилищ и витрин данных используется следующая архитектура:
Неявный захват e
хранение e
перемещение e
неявный Apply с помощью пользовательской функции
В этом случае обновления захватываются автоматически из оперативной БД. Кроме того, в поток можно помещать информацию об изменениях в чужих СУБД или пользовательские сообщения о функционировании оперативной БД (можно, например, создать хранилище сообщений). Операции очистки и преобразования данных, типичные для хранилищ данных, могут быть выполнены в виде процедур преобразования при помещении/извлечении из/в Staging Area.
Обычно данные из оперативных систем перегружаются в хранилища в пакетном режиме. Между загрузками проходит много времени и хранилище или Operating Data Store (ODS) отстают от БД оперативных систем. В случае Oracle Streams можно организовать непрерывную подпитку хранилища или ODS “тонкой струйкой” изменений, при этом отставание ODS или хранилища от оперативной системы будет минимальным и эту целевую БД можно использовать для получения отчетов или анализа данных почти в реальном времени.
Поскольку изменения захватываются из журналов, нет необходимости давать администраторам хранилища или ODS доступ к оперативным системам, что очень порадует администраторов оперативных систем.
Захват изменений
Захват информации об изменениях и сообщений в исходном узле может выполняться явно или неявно. В случае неявного захвата сконфигурированный процесс захвата (Capture) автоматически считывает из оперативных или архивных журналов БД (redologs) информацию об изменениях в БД, используя механизм утилиты LogMiner. Далее считанная информация фильтруется в соответствии с заданными условиями захвата (например, захватываются только изменения в конкретных таблицах или схемах, только DDL или только DML изменения и т. д.). Отфильтрованная информация преобразуется в формат LCR и помещается в Staging Area.
В случае явного захвата информации необходимо писать пользовательские приложения, которые захватывают информацию из Oracle или других систем и сами, используя API, помещают эту информацию в Staging Area. Для создания этих приложений можно использовать Java (JMS), C, PL/SQL, SOAP (XML/HTTP), XML/SMTP. Если информация явно помещена в поток в виде LCR, то она может далее автоматически применяться к целевой БД Apply процессами. Если же она помещена в поток в виде сообщений, то необходимо написать процедуру извлечения этих сообщений из потока (очереди) и установить эту процедуру на целевом узле (узлах).
Формирование потоков
Создадим очередь для передачи событий в БД-источнике и очередь для применения событий в БД-получателе, например:
EXECUTE DBMS_STREAMS_ADM.SET_UP_QUEUE ( )
CONNECT streamadmin/streamadmin@destination
EXECUTE DBMS_STREAMS_ADM.SET_UP_QUEUE ( )
Коли указано специально, очереди в обеих БД (и таблицы для данных этих очередей) получили умолчательные названия. Их можно наблюдать так:
SQL> CONNECT streamadmin/streamadmin@source
Connected.
SQL> SELECT name, queue_table FROM user_queues;
NAME QUEUE_TABLE ------------------------------ ------------------------------ STREAMS_QUEUE STREAMS_QUEUE_TABLE
AQ$_STREAMS_QUEUE_TABLE_E STREAMS_QUEUE_TABLE
Очередь AQ$_*_E создается автоматически для сообщений об ошибках обработки событий.
Для возможности передавать потоком изменения в исходной таблице SCOTT.EMP требуется заявить расширенную журнализацию хотя бы для этой таблицы:
CONNECT scott/tiger@source
ALTER TABLE emp ADD SUPPLEMENTAL LOG DATA ( PRIMARY KEY ) COLUMNS;
Проверка:
SQL> SELECT always, table_name, log_group_type FROM user_log_groups;
ALWAYS TABLE_NAME LOG_GROUP_TYPE ----------- ------------------------------ ------------------- ALWAYS EMP PRIMARY KEY LOGGING
Теперь правка любого поля в таблице EMP будет сопровождаться (безусловно) занесением в журнал не только старого и нового значений этого поля, но также и значения ключевого поля (то есть EMPNO).
В БД-источнике создадим процесс захвата изменений, одновременно указав правила отбора изменений в очередь:
CONNECT streamadmin/streamadmin@source
BEGIN DBMS_STREAMS_ADM.ADD_TABLE_RULES ( table_name => 'scott.emp' , streams_type => 'capture' , streams_name => 'capture_stream' , include_ddl => TRUE ); END; /
Проверка:
SQL> SELECT capture_name, queue_name, queue_owner, status 2 FROM all_capture;
CAPTURE_NAME QUEUE_NAME QUEUE_OWNER STATUS ------------------ ------------------ ------------------ -------- CAPTURE_STREAM STREAMS_QUEUE STREAMADMIN DISABLED
Среди прочих умолчаний при создании процесса захвата изменений выше использовано подразумеваемое молчаливо имя очереди STREAMS_QUEUE. В нашем случае это можно было бы обозначить явно, указав параметр QUEUE_NAME => 'streamadmin.streams_queue'. Этим же параметром можно воспользоваться, когда процесс захвата потребуется связать с очередью под иным именем.
Правила отбора изменений в очередь STREAMS_QUEUE также были построены автоматически, но могли бы быть дополнены, или даже выписаны явно с помощью других параметров процедуры ADD_TABLE_RULES.
Создадим процесс переноса изменений:
BEGIN DBMS_STREAMS_ADM.ADD_TABLE_PROPAGATION_RULES ( table_name => 'scott.emp' , streams_name => 'maindb_to_subdb1' , source_queue_name => 'streamadmin.streams_queue' , destination_queue_name => 'streamadmin.streams_queue@subdb1.class' , source_database => 'maindb.class' , include_ddl => TRUE ); END; /
Проверка:
SQL> SELECT propagation_name, source_queue_name, 2 destination_queue_name, status 3 FROM dba_propagation;
PROPAGATION_NAME SOURCE_QUEUE_NAME DESTINATION_QUEUE_NAM STATUS ---------------- ----------------- --------------------- ------- MAINDB_TO_SUBDB1 STREAMS_QUEUE STREAMS_QUEUE ENABLED
Теперь для правильного воспроизведения изменений в принимающей БД требуется передать ей в качестве "точки отсчета" номер изменений в БД-источнике. Передаваться получателям будут только изменения в EMP с номерами более поздними:
BEGIN DBMS_APPLY_ADM.SET_TABLE_INSTANTIATION_SCN@subdb1.class ( source_object_name => 'scott.emp' , source_database_name => 'maindb.class' , instantiation_scn => DBMS_FLASHBACK.GET_SYSTEM_CHANGE_NUMBER
); END; /
Убедиться в учете процессом применения для таблиц точки отсчета можно запросом:
SQL> COLUMN source_database FORMAT A20 SQL> SELECT 2 source_object_name, source_object_type, instantiation_scn 3 FROM dba_apply_instantiated_objects@subdb1.class;
SOURCE_OBJECT_NAME SOURCE_OBJE INSTANTIATION_SCN ------------------------------ ----------- ----------------- EMP TABLE 1200698
Принимающая БД готова к активации процесса применения изменений:
CONNECT streamadmin/streamadmin@destination
BEGIN DBMS_STREAMS_ADM.ADD_TABLE_RULES ( table_name => 'scott.emp' , streams_type => 'apply' , streams_name => 'apply_stream' , source_database => 'maindb.class' , include_ddl => TRUE ); END; /
Проверка:
SQL> SELECT apply_name, queue_name, status FROM all_apply;
APPLY_NAME QUEUE_NAME STATUS ------------------------ ------------------------ -------- APPLY_STREAM STREAMS_QUEUE DISABLED
Для удобства отключим реакцию на ошибки, иначе процесс применения изменений может самопроизвольно прекращаться:
BEGIN DBMS_APPLY_ADM.SET_PARAMETER ( apply_name => 'apply_stream' , parameter => 'disable_on_error' , value => 'N' ); END; /
Осталось запустить процессы захвата и примения изменений:
CONNECT streamadmin/streamadmin@source
EXECUTE DBMS_CAPTURE_ADM.START_CAPTURE ( 'capture_stream' )
EXECUTE - DBMS_APPLY_ADM.START_APPLY@subdb1.class ( 'apply_stream' )
Проверка:
SQL> CONNECT streamadmin/streamadmin@source
Connected. SQL> SELECT empno FROM scott.emp MINUS 2 SELECT empno FROM scott.emp@subdb1.class
3 . SQL> SAVE delta REPLACE Wrote file delta.sql SQL> @delta
no rows selected
SQL> INSERT INTO scott.emp ( empno ) VALUES ( 3333 );
1 row created.
SQL> @delta
EMPNO ---------- 3333
SQL> COMMIT;
Commit complete.
SQL> @delta
no rows selected
Заметьте, что поток переносит изменения только в одну сторону. Таблица-приемник при этом не закрыта от обычной правки. Однако же такую правку следует выполнять осмотрительно, поскольку она может привести к ошибкам при автоматическом изменении данных потоком (эта проблема решается специально седствами разрешении конфликтов). Вдобавок учтите, что множественные операции INSERT, UPDATE, DELETE применяются в принимающей БД в рамках одной (автономной) транзакции (невзирая на то, что в журнале БД множественные изменения фиксируются набором однострочных изменений). Следовательно ошибка хотя бы в изменении одной-единственной строки приведет к отказу изменений всей множественной операции.
Упражнение. Внести изменения в таблицу SCOTT.EMP на принимающей БД. Убедиться в сохраняющихся расхождениях в таблицах БД-источника и БД-получателя.
Упражнение. Проверить передачу изменений DDL. Добавить столбец в таблицу SCOTT.EMP@MAINDB.CLASS. Наблюдать результат в SCOTT.EMP@SUBDB1.CLASS. Изменить тип столбца, наблюдать результат в базе-получателе.
1 До версии 10 использовалось название Advanced Queuing (AQ).
1 Начиная с версии 10.2.
Конфигурация БД
БД, поддерживающая процесс захвата изменений, должна работать в режиме архивирования.
БД, поддерживающая процесс захвата изменений, должна обеспечить на уровне отдельных таблиц или всей БД режим расширенной журнализации (supplemental logging). В этом режиме журнальные записи об изменениях в таблицах заносятся в расширенном формате, включая данные старых и новых значений полей (независимо от того, какие поля фактически изменялись) для того, чтобы процесс применения изменения в принимающей СУБД смог однозначно воспроизвести изменение.
Расширенную журнализацию можно включать не обязательно для всей БД, но достаточно для реплицируемых таблиц. Значение столбца в таблице исходной БД должно безусловно (ALWAYS, unconditionally) попадать в журнал, если соответствующий столбец в таблице принимающей БД:
индексирован (хотя бы вследствие имеющегося ограничения целостности) участвует в правиле преобразования данных или обрабатывается программой обработки (handler)
Как БД-источник, так и БД-получатель используют рабочие таблицы для хранения данных очередей и прочих нужд. Для их размещения целесообразно выделить отдельные табличные пространства. В БД-источнике желательно назначить процессу LogMiner табличное пространство, иное, чем SYSTEM.
Основные понятия
В потоковой передаче данных участвуют следующие основные элементы:
Процесс захвата изменений (Capture Process). Фоновый процесс, постоянно просматривает средствами LogMiner рабочие и архивированные журналы; выбирает из них требуемые записи об изменениях в исходной таблице/схеме/БД (INSERT, UPDATE, DELETE, MERGE, обновления полей LOB); формирует из этих записей логическую запись об изменении, Logical Change Record (LCR); помещает LCR в качестве события в очередь, сформированную средствами Streams Advanced Queuing (SAQ)1. Процесс передачи изменений (Propagation Process). Постоянно выбирает события из очереди в исходной БД и передает их в очереди на принимающих БД через Oracle Net. Процесс внесения, применения изменений (Apply Process). Постоянно выбирает события из очереди в принимающей СУБД. LCR либо применяются непосредственно к таблицам принимающей БД, либо передаются программе обработки, написанной пользователем на свое усмотрение. Очередь (queue). Она может складываться из упорядоченного множества (списка) объектов конкретного типа, но чаще используются очереди из объектов типа SYS.ANYDATA. В очередь попадают LCR (автоматически, в соответствии с заданными правилами, или же явным добавлением из программы) или более общие сообщения (вставляются и извлекаются вручную). Очередь моделируется с помощью специально создаваемых служебных таблиц, но для автоматически размещаемых в очереди событий LCR дополнительно имеется буфер в SGA.
Параметры СУБД
Для организации потоков данных нужно иметь должные значения целого ряда параметров СУБД, однако чаще всего достаточно удостовериться в следующем:
COMPATIBLE >= 9.2
Далее предполагается >= 10.1.0.
GLOBAL_NAMES = TRUE
для каждой БД, участвующей в переносе данных.
STREAMS_POOL_SIZE >= 200m
Параметр существует с версии 10.1 и задает область памяти для временного размещения захваченных событий. Если STREAMS_POOL_SIZE = 0, будет использована память из shared pool, вплоть до 10% от этой области.
При расчете нужно учитывать следующее:
+ 10m для каждого нового уровня параллелизма процесса захвата + 1m для каждой степени параллелизма процесса применения + 10m для каждой новой очереди захваченных событий.
В версии 9.2 нагрузка на выделение памяти под нужды потоков ложится на shared pool.
SHARED_POOL_SIZE
Каждый процесс захвата требует 10M в памяти shared pool для буфера очереди; в то же время все нужды Oracle Streams в shared pool не могут занимать более 10% этой области.
SGA_MAX_SIZE
(Если речь идет о версии 10). Значение должно учитывать нужды частей SGA (см. выше), особенно для выполнения захвата изменений с помощью LogMiner. Пример, приводимый ниже, в силу его простоты работает даже при значении SGA_MAX_SIZE = 400m.
Подготовка
Переведем БД-источник в режим архивирования журнальных файлов:
CONNECT /@source AS SYSDBA
STARTUP MOUNT FORCE
ALTER DATABASE ARCHIVELOG;
ALTER DATABASE OPEN;
Создадим рабочие табличные пространства в обоих БД, например:
CREATE TABLESPACE streams_ts
DATAFILE 'C:\oracle\oradata\maindb\streams_ts.dbf' SIZE 25m;
CONNECT /@destination AS SYSDBA
CREATE TABLESPACE streams_ts
DATAFILE 'C:\oracle\oradata\subdb1\streams_ts.dbf' SIZE 25m;
В версия 9.2 в БД-источнике желательно назначить процессу LogMiner табличное пространство, иное, чем SYSTEM (в версия 10 оно уже SYSAUX), например:
CONNECT /@source AS SYSDBA
EXECUTE DBMS_LOGMNR_D.SET_TABLESPACE ( 'TOOLS' )
В обеих базах создадим администратора потоков:
CONNECT /@source AS SYSDBA
CREATE USER streamadmin IDENTIFIED BY streamadmin
DEFAULT TABLESPACE streams_ts
TEMPORARY TABLESPACE temp
QUOTA UNLIMITED ON streams_ts
;
GRANT dba TO streamadmin;
EXECUTE DBMS_STREAMS_AUTH.GRANT_ADMIN_PRIVILEGE ( 'streamadmin' )
Повторить те же действия для SUBDB1.CLASS.
В БД-источнике заведем связь с БД-получателем. Так как БД-получатель именована глобально, имя связи обязано совпадать с этим глобальным именем:
CONNECT streamadmin/streamadmin@source
CREATE DATABASE LINK subdb1.class
CONNECT TO streamadmin
IDENTIFIED BY streamadmin
USING 'destination'
;
Потоки данных в Oracle - это очень просто
Преподаватель технологий Oracle
www.ccas.ru/prz/
| Знает названье потока лишь тот, кто вблизи обитает. Теогония, Гесиод От Махачкалы до Баку | |||
Пример построения потока изменений
В этом примере БД-источник потока носит имя MAINDB.CLASS, БД-приемник потока носит имя SUBDB1.CLASS. Сетевые имена баз в Oracle Net соответственно SOURCE и DESTINATION. Предполагается, что в обеих БД имеется схема SCOTT.
Пример приводится для версии 10.2. Предполагается, что команды выдаются в SQL*Plus.
Системные пакеты
Технологически организация потоков осуществляется через употребление ряда встроенных пакетов из схемы SYS:
DBMS_APPLY_ADM
DBMS_CAPTURE_ADM
DBMS_PROPAGATION_ADM
DBMS_STREAMS_ADM
DBMS_STREAMS
DBMS_STREAMS_MESSAGING
DBMS_RULE_ADM
DBMS_RULE
DBMS_STREAMS_AUTH
DBMS_STREAMS_TABLESPACE_ADM
модель организации непрерывного переноса данных
Потоки данных в Oracle - более поздняя, чем "обычная" репликация (односторонняя, двусторонняя и многосторонняя), модель организации непрерывного переноса данных как внутри БД, так и между базами. Это значительно упрощенная реализация идей, изложенных, например, в http://www-db.stanford.edu/~widom/stream.ppt: в частности реализация Oracle Streams не предлагает языкового оформления, а только на уровне API. Технически потоки Oracle Streams опираются на созданный независимо и ранее аппарат организации очередей передачи сообщений, известный под названием Oracle Advanced Queuing.
Потоки данных появились в Oracle версии 9, а в версии 10 получили свое развитие в возможностях (например, Down Stream) и в организации (например, собственный источник памяти streams pool).
В отличие от "обычной" репликации Oracle Streams не требует заведения особых структур в БД (журналов таблиц, materialized views). Подбно механизму репликации, давно использовавшемуся в Sybase, репликация в Oracle Streams основана на обработке информации из журнала БД.
Хотите добавить к данным "соль"?
Шифрование предназначено для сокрытия данных, но иногда значение зашифрованных данных легко угадать, если это значение многократно повторяется в исходном незашифрованном тексте. Например, таблица с информацией о зарплате может содержать повторяющиеся значения. В этом случае зашифрованные значения будут также совпадать, и злоумышленник может определить все записи с одинаковой зарплатой. Для предотвращения этого к данным добавляется "соль" (salt), которая делает зашифрованные значения разными, даже если входные данные совпадают. Средства TDE по умолчанию применяют "соль".
Тем не менее, если вы попытаетесь создать индекс зашифрованного столбца, вы не сможете включить в него "соль". Для удаления "соли", например, из столбца SSN выполните следующий оператор:
alter table accounts modify (ssn encrypt no salt);
Если вы попытаетесь создать индекс по столбцу, который зашифрован с "солью", вы получите ошибку:
SQL> create index in_acc_01 on accounts (ssn);
ORA-28338: cannot encrypt indexed column(s) with salt
(нельзя шифровать с "солью" индексированный столбец (столбцы))
Такую же ошибку вы получите, если попытаетесь зашифровать с "солью" индексированный столбец. Также вы не можете использовать "соль", если выполняется неявное создание индексов, например, когда столбцы входят в первичный ключ или определены как уникальные. Также вы не можете использовать "соль", если столбцы входят во внешний ключ.
Использование утилит Data Pump в среде TDE
По умолчанию, если вы используете утилиту экспорта Data Pump (EXPDP) для экспорта данных из таблиц с зашифрованными столбцами, то данные будут выводиться в результирующий дамп-файл обычном текстом, даже данные зашифрованных столбцов. Следующий оператор экспортирует таблицу ACCOUNTS (с зашифрованными столбцами) и возвращает предупреждение:
$ expdp arup/arup tables=accounts
ORA-39173: Encrypted data has been stored unencrypted in dump file set
(зашифрованные данные сохранены в наборе дамп-файлов незашифрованными)
Это – только предупреждение, не ошибка; строки будут экспортироваться.
Для защиты ваших данных зашифрованных столбцов в дамп-файлах утилиты EXPDP вы может при экспорте таблицы защитить эти дамп-файлы паролем. Этот пароль, задаваемый параметром ENCRYPTION_PASSWORD в команде EXPDP, применяется только в этом процессе экспорта; это не пароль бумажника. На листинге 1 показана команда EXPDP, выполняемая с паролем "pooh". Обратите внимание, что в выводе этой команды на листинге 1 не показан пароль "pooh" – он скрыт строкой звездочек. Результирующий дамп-файл для столбцов, зашифрованных средствами TDE, не будет иметь видимых данных в обычном тексте.
$ expdp arup/arup ENCRYPTION_PASSWORD=pooh tables=accounts
Export: Release 10.2.0.0.0 - Beta on Friday, 01 July, 2005 16:14:06
Copyright (c) 2003, 2005, Oracle. All rights reserved.
Connected to: Oracle Database 10g Enterprise Edition Release 10.2.0.0.0 - Beta With the Partitioning, OLAP and Data Mining options Starting "ARUP"."SYS_EXPORT_TABLE_01": arup/******** ENCRYPTION_PASSWORD=********* tables=accounts Estimate in progress using BLOCKS method... Processing ...
ЛИСТИНГ 1. Экспорт в дамп-файл, защищенный паролем.
При импорте этого зашифрованного дамп-файла вы должны будете предоставить тот же самый пароль, который был использован при экспорте, как это показано на листинге 2.
$ expdp arup/arup ENCRYPTION_PASSWORD=pooh tables=accounts
Export: Release 10.2.0.0.0 - Beta on Friday, 01 July, 2005 16:14:06
Copyright (c) 2003, 2005, Oracle. All rights reserved.
Connected to: Oracle Database 10g Enterprise Edition Release 10.2.0.0.0 - Beta With the Partitioning, OLAP and Data Mining options Starting "ARUP"."SYS_EXPORT_TABLE_01": arup/******** ENCRYPTION_PASSWORD=********* tables=accounts Estimate in progress using BLOCKS method... Processing ...
ЛИСТИНГ 2. Импорт дамп-файла, защищенного паролем.
Если при импорте вы опустите параметр ENCRYPTION_PASSWORD, результат будет следующим:
$ impdp arup/arup tables=accounts
ORA-39174: Encryption password must be supplied
(должен быть указан пароль шифрования).
Если вы укажете неправильный пароль, результат будет следующим:
$ impdp arup/arup ENCRYPTION_PASSWORD =piglet tables=accounts
ORA-39176: Encryption password is
incorrect
(неправильный пароль шифрования).
Первоначальная утилита экспорта (EXP) не может экспортировать таблицы с зашифрованными столбцами.
Как это работает
Основы шифрования в сервере Oracle Database 10g я изложил в статье "Encrypt Your Data Assets", опубликованной в журнале Oracle Magazine, январь-февраль 2005 г. (прим. пер.: имеется русский перевод – ). Повторяем основные положения: для шифрования входных данных с обычным текстом вам нужно применять алгоритм и ключ шифрования; для успешного дешифрования зашифрованного текста вы должны знать этот же алгоритм и ключ.
В той статье я описал, как строить инфраструктуру шифрования с помощью инструментов шифрования, поставляемых на дистрибутиве Oracle. В среде сервера Oracle Database 10g Release 2 и шифрования TDE, однако, вам не нужно создавать эту инфраструктуру. Все, что вы должны сделать – определить столбец, который будет шифроваться, и сервер Oracle Database 10g создаст криптографически стойкий ключ шифрования для таблицы, содержащей этот столбец, и зашифрует данные обычного текста в этом столбце, используя указанный вами алгоритм шифрования. Защита этого ключа таблицы имеет очень важное значение; сервер Oracle Database 10g шифрует его, используя главный ключ, который хранится в безопасном месте, называемом бумажником (wallet), который может быть файлом сервера базы данных. Зашифрованные ключи таблиц размещаются в словаре данных. Когда пользователь вставляет данные в столбец, определенный как зашифрованный, сервер Oracle Database 10g извлекает из бумажника главный ключ, расшифровывает ключ шифрования для этой таблицы, находящийся в словаре данных, использует этот ключ для шифрования входного значения и сохраняет зашифрованные данные в базе данных, как показано на рис. 1.
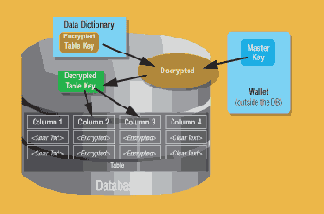
Рисунок 1. Как работает механизм прозрачного шифрования данных
Надписи на рисунке:
Data Dictionary – словарь данных;
Encrypted Table Key – зашифрованный ключ таблицы;
Master Key – главный ключ;
Decrypted – расшифрованный;
Wallet (outside the DB) – бумажник (за пределами базы данных);
Decrypted Table Key – расшифрованный ключ таблицы;
Column – столбец;
Clear Text – обычный текст;
Encrypted – зашифрованный;
Table – таблица;
Database – база данных.
Вы можете шифровать любой или все столбцы таблицы. Если таблица имеет четыре столбца и столбцы 2 и 3 шифруются (как это показано на рис. 1), сервер Oracle Database 10g генерирует один зашифрованный ключ таблицы и использует его для шифрования этих столбцов. На диске значения столбцов 1 и 4 хранятся в виде обычного текста, а значения двух других столбцов – в шифрованном формате. Данные хранятся зашифрованными, поэтому все компоненты нижнего уровня, такие, как резервные копии и архивные журнальные файлы, также имеют шифрованный формат.
Когда пользователь выбирает зашифрованные столбцы, сервер Oracle Database 10g прозрачно извлекает из словаря данных зашифрованный ключ таблицы, а главный ключ – из бумажника и расшифровывает ключ таблицы. Затем сервер базы данных расшифровывает зашифрованные на диске данные и возвращает пользователю обычный текст.
Благодаря такому шифрованию, если данные будут украдены с диска, они не могут быть извлечены без главного ключа, который находится в бумажнике, не входящим в украденные данные. Даже если украден и бумажник, главный ключ не может быть извлечен из него без знания пароля бумажника. Следовательно, вор не сможет расшифровать данные, даже если он украл диски или копии файлов данных. Это удовлетворяет требованиям соответствия многим нормативным и руководящим документам. И все это было сделано без изменения приложения или написания сложной системы шифрования и управления ключами. Теперь я покажу вам, как включать TDE и использовать его возможности.
Одноразовая настройка
Перед тем, как начать использовать возможности TDE, вы должны определить местоположение бумажника, установить его пароль и открыть бумажник.
Определите местоположение бумажника.
Перед включением возможностей TDE вы должны создать бумажник, в котором будет храниться главный ключ. По умолчанию бумажник создается в каталоге $ORACLE_BASE/admin/$ORACLE_SID/wallet. Так, если $ORACLE_BASE –/u01/app/oracle, а $ORACLE_SID – SWBT4, то бумажник будет храниться в каталоге /u01/app/oracle/admin/swbt4/wallet. Вы можете также выбрать другой каталог, указывая его в файле sqlnet.ora, который находится в каталоге $ORACLE_HOME/network/admin. Например, если вы хотите, чтобы бумажник находился в каталоге /orawall, вставьте в файл sqlnet.ora следующие строки:
ENCRYPTION_WALLET_LOCATION = (SOURCE= (METHOD=file) (METHOD_DATA= (DIRECTORY=/orawall)))
В нашем примере мы предполагаем, что выбрано местоположение по умолчанию. Вы должны также включить местоположение бумажника в процедуры резервного копирования.
Откройте бумажник
Бумажник создается только один раз, поэтому вы больше не должны повторять два предыдущих шага. Тем не менее после запуска экземпляра сервера базы данных бумажник необходимо открывать явно. Когда вы создаете бумажник (как выше на шаге 2), вы также открываете бумажник для работы с ним. После создания бумажника и установки его пароля каждый раз, когда вы открываете базу данных, вы должны открывать и бумажник, используя его пароль:
alter system set encryption wallet open authenticated by "remnant";
Вы можете закрывать бумажник, используя оператор:
alter system set encryption wallet close;
Чтобы средства TDE работали, бумажник должен быть открытым. В противном случае, вы сможете получить доступ только ко всем незашифрованным столбцам, но не к зашифрованным.
Шифруйте конфиденциальные данные
Самый большой кошмар вашей организации: кто-то украл ленты с резервной копией вашей базы данных. Несомненно, вы построили защищенную систему, зашифровали наиболее конфиденциальные ресурсы, разместили серверы баз данных за межсетевыми экранами. Но вор выбрал доступный ему способ: он взял ленты с резервной копией, чтобы, вероятно, скопировать вашу базу данных на другом сервере, запустить экземпляр сервера этой базы данных, а затем не спеша просмотреть все ваши данные. Защита содержимого базы данных от такого воровства представляет собой не только хорошую практику; это – требование многих нормативно-правовых и нормативно-технических документов. Как же вы можете защитить вашу базу данных от этой опасности?
Одно решение состоит в том, чтобы зашифровать в базе данных конфиденциальные данные и хранить ключи шифрования в другом месте; без этих ключей любые украденные данные не будут иметь никакого значения. Тем не менее, вы должны найти баланс между двумя противоречащими понятиями: удобство доступа приложений к ключам шифрования и защита, требуемая для предотвращения воровства этих ключей. Причем соблюдение корпоративных и государственных нормативных требований предполагает немедленное принятие решения, без использования какого-либо сложного кодирования.
Новая функциональная возможность сервера Oracle Database 10g Release 2 позволяет вам сделать это: вы можете объявить столбец шифруемым, не написав при этом никаких строк кода приложения. Когда пользователи вставляют данные, сервер базы данных прозрачно шифрует эти данные и сохраняет их в столбце. Точно так же, когда пользователи выбирают этот столбец, сервер базы данных автоматически расшифровывает его. Так как все это делается прозрачно без какого-либо изменения кода приложения, эта функциональная возможность имеет соответствующее название: прозрачное шифрование данных (TDE, Transparent Data Encryption).
Создайте бумажник.
Теперь вы должны создать бумажник и установить пароль для доступа к нему. Для этого как пользователь с привилегией ALTER SYSTEM выполните следующий оператор:
alter system set encryption key authenticated by "remnant";
Этот оператор:
создает бумажник в каталоге, который был определен на шаге 1;
устанавливает пароль бумажника – "remnant";
открывает бумажник для хранения и извлечения главного ключа средствами TDE.
Пароль зависит от регистра, и его необходимо заключать в двойные кавычки. Заметим, пароль "remnant" не показывается в виде обычного текста ни в каких динамических представлениях производительности или журнальных файлах.
Управление ключами и паролями
Что, если кто-то узнал ваши ключи таблиц, или вы подозреваете, что кто-то, возможно, расшифровал зашифрованные ключи таблиц? В этом случае вы можете просто, используя несложный оператор, создать новый ключ для таблицы или, другими словами, сменить ключ таблицы (rekey table), и вновь создать зашифрованные значения столбцов, используя этот новый ключ таблицы. Делая это, вы можете также выбрать другой алгоритм шифрования, такой, как AES256. Вы можете сделать все это следующим образом:
alter table accounts rekey using 'aes256';
Что, если кто-то узнал пароль бумажника? Вы можете изменить его с помощью диспетчера бумажников Oracle Wallet Manager. Для запуска этого графического инструмента введите в командной строке OWM (см. рис. 2). В главном меню выберите Wallet -> Open (бумажник -> открыть) и выберите местоположение бумажника, которое вы определили, а затем задайте пароль бумажника. После этого для изменения пароля выберите Wallet -> Change Password (бумажник -> изменить пароль). Заметим, что изменение пароля бумажника не изменяет ключи.
См.
Вопросы производительности
Операции шифрования и дешифрования потребляют время центрального процессора, поэтому вы должны рассмотреть их влияние на производительность. Когда вы обращаетесь к незашифрованным столбцам таблицы, производительность нисколько не отличается от производительности при работе с таблицами, для которых не используются средства TDE. Когда же вы обращаетесь к зашифрованным столбцам, возникают небольшие накладные расходы на дешифрование во время выборки данных и шифрование во время вставки, так что вы можете захотеть шифровать столбцы выборочно. Если вам больше не нужно шифровать столбец, вы можете выключить шифрование следующим образом:
alter table account modify (ssn decrypt);
Также проанализируйте использование индексов. Предположим, в вышерассмотренном примере есть индекс столбца SSN с именем in_accounts_ssn. Если запрос к таблице ACCOUNTS имеет предикат равенства:
select * from accounts where ssn = '123456789';
то индекс in_accounts_ssn используется. Если же в запросе указан предикат LIKE:
select * from accounts where ssn like '123%';
то индекс будет игнорироваться и будет использоваться полный просмотр таблицы. Причина проста. Структура B-дерева индекса гарантирует, что значения с совпадающими первыми символами физически размещаются близко друг от друга. Обрабатывая предикат LIKE, сервер Oracle Database 10g ищет записи индекса, сопоставимые с образцом, и физическая близость помогает ускорить поиск по индексу, который выполняется быстрее полного просмотра таблицы.
Однако если столбец зашифрован, фактические значения в индексе будут совсем другими (поскольку они зашифрованы), и, следовательно, разбросаны по всему индексу. Это делает просмотры индекса более дорогими по сравнению с полными просмотрами таблиц. Поэтому в этом примере запроса с предикатом LIKE сервер Oracle Database 10g будет игнорировать индекс и выполнять полный просмотр таблицы.
В случае предикатов равенства ищется конкретная запись индекса, а не множество значений, соответствующих образцу. Поэтому план выполнения с использованием индекса быстрее плана с полным просмотром таблицы, и оптимизатор решает использовать индекс. Когда вы принимаете решение, какие столбцы шифровать, учитывайте влияние шифрования на индексы и знайте, что вам, возможно, придется переписать некоторые запросы, в которых используются зашифрованные столбцы.
Защита ваших данных от атак
Защита ваших данных от атак и соблюдение бесчисленных законов, которые регламентируют бизнес, – не тривиальная задача. Средства TDE позволяют вам безотлагательно обеспечить шифрование данных и соответствие нормативным документам без какого-либо кодирования и сложности управления ключами, так что вы можете сосредоточиться на задачах своей работы, для решения которых необходим более сложный стратегический подход.
ЧИТАЙТЕ более подробно о шифровании
Шифруем свои ресурсы данных
Protect from Prying Eyes: Encryption in Oracle 10g
более подробно о прозрачном шифровании данных
Oracle Database Advanced Security Administrator's Guide
Арап Нанда (Arup Nanda) ( ) – главный администратор баз данных компании Starwood Hotels and Resorts (White Plains, New York). Он – соавтор книги Oracle Privacy Security Auditing (издательство Rampant TechPress, 2003) – "Средства аудита в СУБД Oracle, обеспечивающие информационную безопасность".
Зашифруйте столбцы
Чтобы шифровать столбцы, используя средства TDE, все, что вы должны сделать, это добавить к определениям столбцов простое предложение – ENCRYPT. А до этого вы должны решить, какой вы будете использовать тип шифрования и длину ключа. Для детального обсуждения этой проблемы обратитесь к моей статье "Шифруем свои ресурсы данных", упомянутой выше.
Предположим, что у вас в обычной схеме имеется таблица владельцев банковских счетов ACCOUNTS, определенная следующим образом:
ACC_NO NUMBER ACC_NAME VARCHAR2(30) SSN VARCHAR2(9)
В настоящее время все данные этой таблицы хранятся в виде обычного текста. Вы хотите преобразовать столбец SSN (Social Security Number, номер социального страхования), чтобы он хранился в зашифрованном виде. Для этого вы можете выполнить оператор:
alter table accounts modify (ssn encrypt);
Этот оператор делает две вещи:
создает ключ шифрования для таблицы. Если вы измените другой столбец этой же таблицы, чтобы он также хранился в зашифрованном виде, будет использоваться этот же ключ таблицы;
преобразовывает все значения столбца SSN в зашифрованный формат.
Этот оператор не изменяет тип данных или размер столбца, и он также не создает никаких триггеров или представлений.
По умолчанию для шифрования используется алгоритм AES (Advanced Encryption Standard, усовершенствованный стандарт шифрования) с 192-битовым ключом. Вы можете также выбрать другой алгоритм, указывая в операторе соответствующее дополнительное предложение.
Например, чтобы использовать 128-битовое шифрование по алгоритму AES, вы можете выполнить оператор:
alter table accounts modify (ssn encrypt using 'AES128');
Вы можете использовать предложения AES128, AES192, AES256 или 3DES168 (168-bit Triple DES , трехкратное применение алгоритма DES (Data Encryption Standard, стандарт шифрования данных) с 168-битовым ключом).
После шифрования столбца вы увидите в описании таблицы следующее:
SQL> desc accounts
Name Null? Type ------------ ------------ -------------------------- ACC_NO NUMBER ACC_NAME VARCHAR2(30) SSN VARCHAR2(9) ENCRYPT
Обратите внимание на ключевое слово ENCRYPT, указанное после типа данных. Для поиска в базе данных зашифрованных столбцов можно воспользоваться представлением словаря данных DBA_ENCRYPTED_COLUMNS. (Средства TDE нельзя применять к таблицам схемы SYS.)
Анализ показателей на основе Oracle Balanced Scorecard
Андрей Хомяков, ведущий консультант,
группа компаний TopS Business Integrator
(www.topsbi.ru)
Источник: .
СОДЕРЖАНИЕ
Архитектура BSC
Oracle Balanced Scorecard использует 3-х слойную архитектуру, которая состоит из уровня базы данных, уровня web-сервера и уровня интерфейса пользователя. Пользователи могут использовать любой браузер с поддержкой java. Web-сервер отвечает за бизнес-логику и генерирует динамические web-страницы.
Инструментарий дизайнера состоит из Performance Management Designer (PMD) и BSC Architecture Modules. Приложения, входящие в Architecture Modules работают в клиент-серверной архитектуре. PMD - дизайнер с web-интерфейсом, призванный в будущем полностью заменить клиент-серверные приложения. Сейчас часть функциональности реализована в PMD, а часть в Architecture Modules.
Architecture Modules требуют установки клиентской части Oracle версии 8.0.6 (Oracle 9i Release 2 для пользователей Windows XP). Они включают два приложения Architect и Manager.
BSC Manager предназначен для загрузки данных в таблицы BSC и задания прав доступа к системам сбалансированных показателей и контрольным показателям деятельности. Большая часть функциональности подмодуля уже перенесена в Performance Management Designer. Загрузчик данных (BSC Loader) обеспечивает занесение данных из различных исходных систем, включая MS Excel. Позволяет загружать фактические и плановые данные, имеющие различные уровни агрегации по времени (факт - месячный, план - квартальный). Возможно использование менеджера параллельных программ для загрузки данных в соответствии с заданным расписанием.
BSC Architect используется для создания ключевых показателей деятельности, позволяет проводить настройку дополнительных свойств показателей, которые невозможно настроить через web-интерфейс. С помощью Architect можно создавать деревья моделирования (simulation-tree). На стадии проектирования меняются только метаданные. Реальная структура таблиц для хранения данных остается неизменной. На этой стадии в интерфейсе пользователя используется генератор случайных чисел, позволяющий создавать прототип системы и осуществлять её быстрое развитие.
Для завершения процесса проектирования и создания структуры таблиц для пользовательских данных используется подмодуль Metadata Optimizer. Он анализирует все показатели и размерности и создает несколько наборов таблиц:
1) Таблицы размерностей (Dimension tables) содержат значения измерений. Например, значений для измерения Регион могут быть следующие: Юг, Север, Восток и Запад. Пример таблицы измерения: Field Type Size Description CODE NUMBER Code USER_CODE VARCHAR2 5 User code NAME VARCHAR2 15 Name LANGUAGE VARCHAR2 4 SOURCE_LANG VARCHAR2 4 REG_CODE NUMBER See BSC_D_REG.CODE REG_CODE_USR VARCHAR2 5 See BSC_D_REG.USER_CODE
Где,
CODE - системный идентификатор, присваиваемый автоматически,
USER_CODE - числовой код значения измерения, заданный пользователем,
NAME - значение измерения,
REG_CODE - ссылка на значение другого (родительского) измерения.
2) Набор пустых таблиц (Input tables), в которые пользователь должен загрузить данные. Структура этих таблиц оптимизирована для простоты занесения данных. Пример таблицы:
Field Type Size Description REG_CODE VARCHAR2 5 User code (See BSC_D_REG) YEAR NUMBER 5 Year: 2001,:,actual year TYPE NUMBER 3 Type: 0: Actual, 1: Plan PERIOD NUMBER 5 PeriodPeriod: 1 To 12 PROFIT NUMBER Internal Column EBIT NUMBER Internal Column TAX NUMBER Internal Column
Где,
REG_CODE - значение измерения, для которого заносятся данные в эту запись,
YEAR - год,
TYPE - тип записи: 0 - фактические данные, 1 - плановые данные,
PERIOD - месяц от 1 до 12,
Остальные поля содержат значения соответствующих показателей.
3) Metadata Optimizer также создает системные таблицы (System tables) в базе данных и конфигурирует загрузчик данных (BSC Loader). Загрузчик переносит данные из Input tables в системные таблицы. При переносе производятся все необходимые вычисления и денормализация данных. Системные таблицы оптимизированы для чтения данных при построении графиков.
Дерево моделирования "что-если"
Уникальная функция OBCS - дерево моделирования - позволяет оценивать влияние изменения значений исходных данных на значение показателя. Значения исходных данных, на основании которых рассчитывается тот или иной показатель, могут быть изменены/промоделированы для любого периода (текущего, прошлого или будущего) путем ввода процентного значения изменения. На основании введенных значений моделируется расчет результирующего показателя (цели). Возможно предоставление результатов анализа другим пользователям, имеющим доступ.
Performance Management Designer
Основной процесс разработки осуществляется в Performance Management Designer. PMD предназначен для создания Систем сбалансированных показателей (Scorecards), Показателей (Measures), Измерений (Dimensions) и Контрольных показателей деятельности (KPI). Дизайнер включает модули администрирования для загрузки данных и управления безопасностью.
Performance Management Designer отвечает за создание объектов следующих типов:
Dimension Values (Значения объектов размерностей) - значения измерений. Например, Москва, Уфа, Ростов Dimension Object (Объект размерности) - уровни для контрольных показателей и сбалансированных карт. Например, Города, Регионы, Магазины Dimension (Размерность) - набор из одного или нескольких Объектов размерности. Размерности определяются обычно в контексте контрольных показателей деятельности (КПД). Пример 1: Город, Тип продукта, Тип клиента. Пример 2: Тип продукта, Тип клиента Dimension Set (Набор размерностей) - состоит из нескольких размерностей. Используется при добавлении показателя в КПД для указания набора размерностей KPI (КПД) - контрольный показатель деятельности. Содержит набор Analysis options Analysis option - не имеет самостоятельного значения. Служит для представления показателя в контексте КПД Measure (Показатель) - каждому показателю соответствует колонка в таблице, сгенерированной при помощи Metadata Optimizer. Показатель может присоединяться к одному или нескольким КПД Scorecard (Карта показателей) - система сбалансированных показателей. Включает набор КПД и представлений.
Существует четыре встроенных типа представлений: Scorecard Views, Strategy Map Views, Detailed Views, Tree View. Также можно создавать пользовательские представления (Custom Views). Одно представление назначается основным (выбираемым по умолчанию). Представление может содержать КПД, ссылки на Web-страницы, ссылки на другие представления. Можно использовать любую картинку в качестве фона (подложки) для страницы отображения Карты Показателей. Это позволяет более наглядно иллюстрировать стратегию и цели компании в привязке к конкретным KPI. Поддерживаются неограниченные возможности расположения KPI на пользовательской Карте Показателей.
Процесс проектирования
Типичный процесс реализации системы сбалансированных показателей состоит из следующих шагов:
Концептуальное проектирование - определение целей, показателей и метрик для достижения стратегии Проектирование прототипа - непосредственно создание объектов метаданных: сбалансированных карт, показателей, размерностей. Переход от прототипа к промышленной эксплуатации - генерация таблиц в базе данных, настройка прав доступа и загрузка реальных данных.
Управление доступом и защита информации
В BSC могут быть использованы все средства разграничения доступа и защиты информации, доступные в Приложениях Oracle R11i. Разработчики не имеют доступа к реальным данным. Есть возможность назначения пользователям или группам пользователей одного из трех уровней доступа:
Разграничение прав доступа на сбалансированные наборы показателей деятельности Разграничение прав доступа отдельные показатели эффективности Определение прав доступа на отдельные уровни иерархии измерений
Визуализация значений КПД
Возможность представления значений КПД, как в графической, так и в табличной форме Возможность сравнения фактических данных с планом, фактом за прошлые периоды Возможность выбора различных вариантов цветового кодирования диапазонов фактических значений Возможность динамического изменения диаграммы (тренд, сравнительная, круговая) Возможность ввода комментариев для организации совместных обсуждений Навигация на основе причинно-следственных связей между КПД Возможность выбора вычислений (разность, вклад, рост) Динамически вычисляемые КПД, в соответствии с заданными формулами Возможность представления значений КПД, как в графической, так и в табличной форме Возможность сравнения фактических данных с планом, фактом за прошлые периоды Возможность выбора различных вариантов цветового кодирования диапазонов фактических значений Возможность динамического изменения диаграммы (тренд, сравнительная, круговая) Возможность ввода комментариев для организации совместных обсуждений Навигация на основе причинно-следственных связей между КПД Возможность выбора вычислений (разность, вклад, рост) Динамически вычисляемые КПД, в соответствии с заданными формулами.
Информационные окна ключевых показателей деятельности позволяют вводить, а затем отображать на экране дополнительную (качественную) информации для любого количественного показателя. Данная информация может быть следующего характера: качественная оценка данного KPI, комментарий общего характера, отношение данного KPI к корпоративной стратегии, объяснение определения показателя, объяснение формулы, по которой вычисляется данный KPI; ответственное лицо, предпринимаемые действия

предназначен для отображения стратегии организации
Модуль Oracle Balanced Scorecard (BSC) предназначен для отображения стратегии организации в сбалансированном наборе показателей деятельности. В модуле определяются ключевые показатели деятельности (КПД), их взаимосвязи и стратегические карты показателей. OBSC входит в набор приложений Oracle Business Intelligence. Модуль обеспечивает менеджеров ясным пониманием, как их решения влияют не только на непосредственную зону ответственности, но и на другие подразделения и всю компанию в целом. За счёт возможности определения многоуровневой детализации ключевых показателей деятельности, модуль превращает концепцию КПД в активный инструмент мониторинга и управления на всех организационных уровнях.
BSC предоставляет следующие возможности:
Доступ и навигация через интернет как для конечного пользователя, так и для разработчика Стандартизованный пользовательский интерфейс Навигация по наборам сбалансированных карт Представление КПД в классической форме сбалансированных карт показателей деятельности Мастер ключевых показателей эффективности. Конечный пользователь может настраивать отображение показателей в удобном для себя виде Удобный интерфейс для моделирования любых сбалансированных систем показателей Отображение связей и причинно-следственных отношений между показателями или стратегическими целями Деревья моделирования для сценарного анализа "что, если..." Средства разграничения доступа к информации Многоязыковая поддержка.
Архитектура приложения, созданного с применением MapViewer
Приложение, созданное с применением MapViewer, включает:
Контент, управляемый через Oracle Spatial, такой как: сети улиц, административные границы и месторасположения офисов; Метаданные карты в представлениях базы данных, включающих список поименованных карт, набор тем, которые составляют каждую карту, и правила стилей и картографические символы, используемые для визуализации (rendering – рендеринг) тем; Сконфигурированный, установленный и действующий экземпляр MapViewer, “прислушивающийся” к запросам; Web-клиент, который выдает XML-запросы к карте, обрабатывает соответствующий XML-ответ и показывает результирующее изображение карты.
Этот Web-клиент может использовать либо Java-библиотеку MapViewer-клиента, либо библиотеку JSP-тэгов для упрощения процесса выдачи запросов к карте с обработкой ответа и управлением взаимодействия пользователя с изображением карты, а также для управления состоянием — таким как текущее положение центра карты и масштаб — между запросами. Этот процесс показан в следующем приложении-примере.
Как установить MapViewer
Простейший способ начала работы с MapViewer – скачать Quick Start kit for Oracle Application Server 10g 10.1.2 MapViewer из сети Oracle Technology Network (OTN). Этот набор содержит предварительно сконфигурированный автономный (standalone) OC4J с MapViewer.
Карта отвечает с помощью Oracle Application Server 10g
Уже в течение ряда лет на Web-сайтах пользователи вводят адрес и получают карту заданного района. Добавление карты к адресу расширяет контекст заданного места за рамки названия улицы и номера дома. Карты с бизнес-информацией могут повышать ценность данных о названиях и номерах, они находят применение при анализе и планировании, в интерфейсах с пользователями для многих типов бизнес-приложений и при формировании отчетов.
В этой статье представлен MapViewer, компонент сервера приложений Oracle Application Server 10g, и приложение-пример, включающее описание наборов данных, базы данных и установки Oracle Application Server Containers for J2EE (OC4J), которые используются компонентом MapViewer для показа актуальной информации, определяемой месторасположением.
Данное приложение-пример – это чистое Web-приложение на HTML, которое показывает на карте актуальную информацию, определяемую местоположением, связанную как с главным, так и с другими (полевыми) офисами компании, как показано на . Каждый полевой офис представлен градуированным кружком (graduated circle), чей цвет и размеры определяются списком офисов. Как только пользователь перемещает курсор на кружок полевого офиса, дополнительное окно показывает избранные атрибуты этого офиса. Возможные дополнительные операции позволяют получить более подробную информацию о ближайшем полевом офисе, о любом заданном местоположения (такого, как адрес клиента) на этой карте.
Обзор MapViewer
MapViewer – это компонент сервера приложений Oracle Application Server 10g. Это “легкий” (lightweight), но мощный сервлет для визуализации геопространственных (geospatial) данных, управляемых компонентом Oracle Spatial. Он включает тематическую картографию деловых данных, связанных географией.
Карта формируется из набора тем (themes) или слоев (layers). Каждая тема – это запрос, содержащий столбец пространственных данных (spatial column) типа SDO_GEOMETRY и другие столбцы в списке SELECT, а также правило стиля, определяющее ее представление. MapViewer получает запрос на карту и создает и формирует ее изображение (render) ее образ с применением стилей и правил стиля, хранимых в базе данных.
Вы можете установить MapViewer на Oracle Application Server 10g или на автономном экземпляре OC4J.
Организация кода
Весь код приложения-примера находится в файлах директории oramap/Project/public_html. Главные файлы:
main.jsp toolbar.js toolbar.html infotip.js style_theme.sql myicons (directory) legend.xml
Так как целью приложения-примера является иллюстрация использования API на стороне клиента, то и логика представления, и основной код приложения размещены в файле main.jsp. При разработке более масштабных Web-приложений вы должны использовать более продвинутую среду разработки, такую как Oracle Application Development Framework (ADF).
Файлы toolbar.js и toolbar.html предназначены для реализации инструментальной панели (toolbar) с ее одновременно нажимаемыми (rollover) кнопками благодаря применению стандартного кода класса JavaScript.
Файл infotip.js содержит JavaScript-код для дополнительного (info-tip) окна, которое показывает подробные атрибуты полевого офиса в тот момент, когда курсор вашей мыши находится над ним. Этот код дополняет встроенную в MapViewer поддержку для генерации карты как HTML-изображения для любого изображения карты. HTML-изображение карты – это набор областей, вызываемых щелчком мыши, определенных на изображении, которое просматривается в браузере. Изображение карты, созданное средствами MapViewer, не имеет HTML-изображения карты, связанного с ним.
Директория myicons содержит все иконки, используемые в этой инструментальной панели, легенду карты и файл legend.xml содержит запрос к карте для легенды карты.
Подготовка параметров
В секции подготовки параметров файла main.jsp объявляются переменные и присваиваются значения параметров, используемых при конструировании запросов к карте. Ключевой входной параметр, action (действие), связан с текущим действием с картой, выбранным пользователем. Его значение (pan, zoomin, zoomout, zoombox или id) отмечает действие, которое MapViewer должен выполнить.
Переменная mvurl специфицирует расположение сервера MapViewer. Предположим, что MapViewer размещен на локальном автономном экземпляре OC4J и, следовательно, используем адрес http://localhost:8888/mapviewer/omserver.
Другие параметры в секции подготовки параметров файла main.jsp включают центральную точку карты (center point of the map) и размер (size) (в десятых долях градусов по вертикали карты). Если пользователь ранее уже кликал по этой карте, расположение этой отметки также берется из входного HTTP-запроса в относительной системе координат этого устройства изображения. По этой информации вы запрашиваете новую карту у MapViewer.
Поиск геопространственных данных
- ведущий разработчик продукта MapViewer.
- технический директор по продукту Oracle Spatial.
Источник:
Содержание файла main.jsp
Файл main.jsp содержит наиболее важный код в этом приложении-примере. Основные секции кода файла main.jsp таковы (в порядке следования):
Environment setup (Установка среды). Импортирует необходимые Java-классы и пакеты, такие как MapViewer Client API, и включает файлы JavaScript-кода, реализующие инструментальную панель и info-tip features на стороне клиента. Preparing map parameters (Подготовка параметров карты). Инициализирует или получает значения для основных параметров из текущей Web-сессии. К этим параметрам относятся центр карты (map center), размеры карты (map size), название карты (map title), определяемые пользователем действия с картой: pan, zoom in, zoom out и identify a feature, а также где пользователь щелкал по карте в предыдущем сеансе. Rendering a new map (Рендеринг новой карты). Конструирует и посылает запрос к карте, сформированный, исходя из действия пользователя и параметров карты. Presenting the result page (Представление страницы результата). Представляет результирующую карту браузеру клиента.
Последовательность, поток этого кода характерна, как правило, для любого Web-приложения на базе MapViewer. Такое приложение посылает запрос к MapViewer и представляет результирующую карту. Конечный пользователь выполняет некоторые действия с этой картой, и приложение посылает новые запросы к серверу MapViewer и представляет новую результирующую карту.
Полный текст файла main.jsp находится по этому адресу.
Установка среды
Секция установки среды файла main.jsp импортирует нужные классы и JavaScript. Ниже приведен импорт класса, содержащегося в mvclient.jar, который представляет that represents your client handle when you are working with MapViewer:
<%@ page import= "oracle.lbs.mapclient.MapViewer" %>
Он посылает запросы к карте и обрабатывает ответы от сервера MapViewer server.
Нижеследующие предложения импортируют JavaScript, который реализует инструментальную панель на стороне клиента и info-tip механизмы:
<script type="text/javascript" src="toolbar.js"> </script>
<script type="text/javascript" src="infotip.js"> </script>
Далее следует адаптированная (customizable) функция customMapClicked():
function customMapClicked( action, x, y, w, h) { document.omv_mapform.map_action .value = action; document.omv_mapform.map_click_x .value = x; document.omv_mapform.map_click_y .value = y; document.omv_mapform.map_box_w .value = w; document.omv_mapform.map_box_h .value = h; document.omv_mapform.submit(); return false; }
Она гарантирует, что новый запрос будет выдан с правильными параметрами, когда пользователь щелкнет где-нибудь на карте (за исключением областей карты с HTML-изображением). Обработчики событий “щелчок мыши”, определенные в toolbar.js, вызывают эту функцию.
Щелчок на области HTML-изображения этой карты, например, полевой офис, приводит к вызову следующей функции на стороне клиента:
function areaClicked(event, info) { alert(info); }
Параметр info содержит ключевые атрибуты полевого офиса. Определение темы FIELD OFFICE специфицирует эти параметры. Адаптирование функции areaClicked позволяет реализовать более изощренную обработку, такую как открытие нового отчета или создание графиков об определенном объекте карты.
Далее в секции установки среды файла main.jsp, вы объявляете два объекта типа DIV, названных tbar_rect и infotip_window в HTML-заголовке. Вы используете tbar_rect для поддержки zooming к области в пределах box и infotip_window для показа дополнительного окна.
Визуализация новой карты
Код в секции "rendering a new map" (рендеринг новой карты) файла main.jsp формирует запрос к карте и посылает его к серверу MapViewer. Большая часть логики, имеющей отношение к карте, а также ваши собственные геопространственные запросы выполняются здесь через клиентский Java API.
Чтобы выполнить рендеринг новой карты, вы сначала берете две ссылки к экземплярам клиентов MapViewer из текущей пользовательской сессии. Как правило, только один такой клиент требуется, чтобы посылать запросы к карте и получать ответы. Наше приложение-пример, однако, использует поддержку нового HTML-изображения карты, так что вам нужен отдельный MapViewer-клиент, чтобы послать несколько другой запрос к карте.
Создание новых клиентов MapViewer. Для новой сессии браузера или вы не можете получить доступ к существующему экземпляру клиента MapViewer, если, например, время сессии истекло, вы создаете новые экземпляры этого клиента с применением кода листинга 1.
Код листинга 1: Создание экземпляров клиента
if (mv == null newSession) // new session { mv = new MapViewer(mvURL); // one for the main map request session.setAttribute("oramap", mv); // keep client handle in the session
mv.setDataSourceName(dataSrc); // specify the data source (database) mv.setImageFormat(MapViewer.FORMAT_PNG_URL); // PNG Image mv.setMapTitle(title); // set map title // specify marker symbol denoting map center mv.setDefaultStyleForCenter("M.IMAGE89_BW", null, null, null); mv.setAntiAliasing(true); //make map look nicer mv.setCenterAndSize(cx, cy, size); // initial center & size mv.setDeviceSize(new Dimension(width, height)); // window size // Specify themes to display. States, Cities, and field office locations mv.addPredefinedTheme("THEME_DEMO_STATES"); mv.addPredefinedTheme("THEME_DEMO_BIGCITIES"); mv.addPredefinedTheme("FIELD OFFICE");
// now create MapViewer instance for handling HTML image maps clkmv = new MapViewer(mvURL); // for "FIELD OFFICE CLK" theme. clkmv.setDataSourceName(dataSrc); // same data source clkmv.setCenterAndSize(cx, cy, size); // and center and size // but different image format. We use SVG to construct the image map clkmv.setSVGFragmentType(MapViewer.SVG_LAYERS_WITH_LABELS) ; clkmv.setSVGFragmentInDeviceCoord(true);
clkmv.setDeviceSize(new Dimension(width, height)); // specify the theme. FIELD OFFICE CLK lists the attributes // that show up in an info-tip clkmv.addPredefinedTheme("FIELD OFFICE CLK"); session.setAttribute("oramap_clk", clkmv);
// submit the two map requests mv.run(); clkmv.run(); }
Эти два экземпляра клиента MapViewer (иначе называемые handles или beans) -- mv и clkmv. Первый, mv, служит главным клиентом для конструирования и посылки регулярных запросов к карте, в то время как clkmv посылает запросы к HTML-изображениям карты.
Темы и стили: Как отображаются полевые офисы. Запросы к карте клиента mv включают три предопределенных темы. Ключевая тема – это FIELD OFFICE, которая определяется в USER_SDO_THEMES:
SQL> select base_table, geometry_column, styling_rules from user_sdo_themes where name='FIELD OFFICE';
Результат этого запроса:
FIELD_OFFICES LOCATION <?xml version="1.0" standalone="yes"?> <styling_rules> <rule column="HEADCOUNT" order_by="HEADCOUNT" sort_order="DESC"> <features style= "OFFICE_STYLE"> </features>
<label column="NAME" style="T.STREET NAME"> headcount - 250 </label> </rule> </styling_rules>
Так что FIELD_OFFICES – это базовая таблица для этой темы и столбец LOCATION содержит данные о расположении каждого офиса.
Определение STYLING_RULES специфицирует, что столбцы HEADCOUNT, NAME и LOCATION запрашиваются из FIELD_OFFICES. Оно также предусматривает, что результат сортируется в убывающем порядке значения HEADCOUNT. Это важно, так как вы показываете полевые офисы, как кружки переменных размеров, определяемых значениями HEADCOUNT. Если расположения двух офисов близки друг к другу, вы захотите, чтобы MapViewer выполнил рендеринг сначала большего кружка, а затем поверх него меньшего.
Некий объект обладает меткой только тогда, когда числовое значение столбца LABEL больше, чем 0. Элемент <label> выше имеет условие "headcount - 250," так что MapViewer присваивает метки, только если его head count больше чем 250.
Единственное назначение клиента clkmv – посылать запрос к карте, содержащий тему FIELD OFFICE CLK. Это весьма похоже на тему FIELD OFFICE, используемую клиентом mv, единственное отличие в том, что он сортирует офисы в возрастающем порядке перечисления, так что большие области HTML-изображения карты, сгенерированные для полевых офисов, появляются в списке областей после малых. Тема FIELD OFFICE CLK также имеет элемент <hidden_info>:
<styling_rules > <hidden_info> <field column="NAME" name="Office" /> <field column="HEADCOUNT" name="#Employee" /> <field column="ADDRESS" name="Address" />
<field column="CITY" name="City" /> <field column="STATE" name="State" /> </hidden_info> ... </rule>
MapViewer выбирает столбцы, запрошенные в элементе <hidden_info>, как часть запроса и включает их в ответ (результат) карты.
Клиент mv просит сервер выполнить рендеринг карты в PNG-файл, сохранить его на сервере-хосте и возвратить URL для файла-изображения, который будет представлен в браузере. Клиент clkmv, в свою очередь, использует файловый формат Scalable Vector Graphics (SVG):
clkmv.setSVGFragmentType( MapViewer.SVG_STYLED_LAYERS_WITH_LABELS) ; clkmv.setSVGFragmentInDeviceCoord(true);
Эти два метода “говорят” MapViewer о создании SVG-карты по запросу и возврате SVG-документа, содержащего данные карты в системе координат устройства. Эти координаты используются для генерации областей HTML-изображений карты.
Создав обоих клиентов, вы вызываете метод run(), который посылает запрос серверу. Клиенты ждут ответа и извлекают нужную информацию, такую как URL сгенерированного изображения карты, используя методы доступа.
Теперь, когда вы знаете, как специфицируются контент карты и формат, можно рассмотреть, как выполняется рендеринг расположений полевых офисов. Правила стиля для двух полевых офисов ссылаются на стиль OFFICE_STYLE, который можно назвать продвинутым, основанным на участах памяти (bucket-based). OFFICE_STYLE содержит набор участков (buckets), каждый из них соответствует диапазону значений, такому как 250 < headcount < 500, со примитив-стилем (primitive style), таким как красный кружок (red circle). Для тем FIELD OFFICE каждое значение упорядоченности (head count) определяет его участок и стиль.
Обработка действий пользователя (Processing user actions). Параметр action в файле main.jsp содержит информацию о взаимодействии с пользователем. Если значение параметра action - pan, zoomin, zoomout или zoombox, вы повторно выдаете запрос к карте, вызывая соответствующие методы, такие как pan(), с новыми параметрами центра и размеров. Вы всегда вызываете эти методы на обоих клиентах, так что карта с HTML-изображениями, сгенерированная в clkmv, синхронизирована с изображением показываемой карты.
Обработка ID-функции (Processing the ID function). Действие ID инициируется тогда, когда пользователь щелкает по кнопке ID на инструментальной панели и затем щелкает где-нибудь на карте. Фактически эта обработка происходит на стороне сервера.
Листинг 2 показывает соответствующий сегмент кода для обработки ID-действия.
Код листинга 2: Обработка ID-действия
else if("id".equals(action)) { String[] columns = new String[]{"NAME Nearest_Office", "City", "State", "a.location.sdo_point.x X", "a.location.sdo_point.y Y", "Headcount"};
//find out the office nearest to where user clicked on the map officeInfo = mv.identify(dataSrc, "field_offices a", //the table name columns, // columns in SELECT clause "location", // geometry column name srid, // spatial reference system id mapClickX, mapClickY //mouse click position ); Point2D officeLoc = null; if(officeInfo!=null) { // identify() returns a String[][] of row, column values // row 0 is the column name list, row 1 on are values // columns are named in the "columns" parameter // so here column 0 is Name, 1 is City, 2 is State, // 3 is X, and 4 is Y String x = officeInfo[1][3]; String y = officeInfo[1][4]; officeLoc = new Point2D.Double(Double.parseDouble(x), Double.parseDouble(y)); }
// mark user click on the map with a PIN marker Point2D p2 = mv.getUserPoint(mapClickX, mapClickY); mv.addPointFeature(p2.getX(), p2.getY(), srid, "M.CYAN PIN", //a PIN marker style null, null, null);
//add a leader line from user click to nearest office if(officeLoc!=null) mv.addLinearFeature(new double[]{p2.getX(), p2.getY(), officeLoc.getX(), officeLoc.getY()}, srid, "NEAREST_LINE_STY", null, null, false);
/* For identify: use previously generated map as backdrop and avoid rerendering all base themes. */ if(mv.getBackgroundImageURL()==null) mv.setBackgroundImageURL(mv.getGeneratedMapImageURL()); String[] enabledThemes = mv.getEnabledThemes(); mv.setAllThemesEnabled(false); //temporarily disable themes
mv.run(); // reissue map request to draw a PIN marker // reenable all themes mv.enableThemes(enabledThemes);
mv.removeAllPointFeatures(); // clean up PIN marker mv.removeAllLinearFeatures(); // clean up leader line as well } // end id action
Код в листинге 2 сначала находит полевой офис, ближайший к расположению, заданному пользователем, используя метод identify(). Входные параметры – это имя целевой таблицы (FIELD_OFFICES), по которой будет производиться поиск, список возвращаемых столбцов и расположение мыши в системе координат экрана.
Далее, код определяет координаты основания, соответствующие расположению этого клика мыши:
Point2D p2 = mv.getUserPoint( mapClickX, mapClickY);
Затем код добавляет символ маркера PIN к этому расположению:
mv.addPointFeature( p2.getX(), p2.getY(), srid, "M.CYAN PIN", //a PIN marker style null, null, null);
Далее, код добавляет линию, соединяющую эти два расположения с новой картой:
mv.addLinearFeature( new double[]{p2.getX(), p2.getY(), officeLoc.getX(), officeLoc.getY()}, srid, "NEAREST_LINE_STY", null, null, false);
Так как вы добавляете только PIN и линейные объекты к новой карте, то расточительно повторно генерировать все это хозяйство. Поэтому вы просто используете предыдущую карту как фон, временно дезактивируя все другие темы, и выдаете запрос к карте таким образом:
if(mv.getBackgroundImageURL()==null) mv.setBackgroundImageURL( mv.getGeneratedMapImageURL()); String[] enabledThemes = mv.getEnabledThemes(); mv.setAllThemesEnabled(false); //temporarily disable themes mv.run(); // reissue map request to // draw PIN and line
Как только вы сгенерируете новую карту, вы повторно активируете темы и убираете PIN и линейные объекты:
mv.enableThemes(enabledThemes); mv.removeAllPointFeatures(); // clean up the PIN marker mv.removeAllLinearFeatures(); // clean up leader line as well
И теперь у вас есть новая карта, получите атрибуты ближайшего офиса, и она готова к представлению информации.
Представление результирующей страницы
Секция представления результирующей страницы файла main.jsp содержит простые HTML-тэги. Инструментальная панель показана в листинге 3.
Код листинга 3: Представление инструментальной панели результирующей страницы
<!-- Left column : toolbar and map image --> <TD width="<%=width%>" bgcolor="#d4d0c8"> <% // pick up the correct icon file for the toolbar buttons String[] toolbarNames = new String[]{"zoomin", "pan", "zoomout", "zoombox", "id"}; String[] toolbarImgs = new String[toolbarNames.length]; for(int i=0; i<toolbarImgs.length; i++) { if(toolbarNames[i].equals(action)) toolbarImgs[i] = "myicons/" + toolbarNames[i] + "_dn.png"; else toolbarImgs[i] = "myicons/"+toolbarNames[i]+".png"; } %> <%@ include file="toolbar.html" %> </TD>
Предложение <%@ include file="toolbar.html" %> определяет положение кнопок инструментальной панели. Для каждой кнопки должен быть выбран реальный файл-иконка, способный отображать текущий статус кнопки (то есть, щелкнули по ней или нет). JSP-код в листинге 3 в цикле обрабатывает список имен кнопок и выбирает из директории myicons нужный файл для кнопочной иконки. Если по кнопке, такой как "pan," щелкнули, вы используете файл <button_name>_dn.png (в данном случае pan_dn.png). Имена этих файлов собраны в файле toolbar.html file.
Представление изображения сгенерированной карты
Код листинга 4 представляет изображение сгенерированной карты.
Код листинга 4: Представление карты
<% // Get the HTML AREA definition of selected theme's Image Map. String areas = clkmv.getThemeAsHTMLAreas( "FIELD OFFICE CLK", true) ; %> <MAP NAME="omv_infomap">
<%= areas==null?"":areas %> </MAP> <div id="infotip_window"></div> <div id="display" style="position:relative"> <!? now for the actual map image --> <img id="oramap" src="<%=mv.getGeneratedMapImageURL()%>" border="1" usemap="#omv_infomap" onload="changeActionButton('<%=action%>')" /> </div> <div id="tbar_rect"></div>
Этот код - по существу HTML-тэг <img> с src-изображением, полученным от mv по методу getGeneratedMapImageURL(). Он использует HTML-изображение карты с названием omv_infomap, контент которой возвращается от метода call getThemeAsHTMLAreas() от clkmv и размещается между тэгом <MAP> и тэгом <img> . Наконец, тэг <img> окружается различными элементами типа <DIV>, включая infotip_window и tbar_rect, для дополнительного окна и изменения масштаба (box-based zoom), соответственно.
Когда MapViewer представляет изображение карты, пользователь может щелкнуть по навигационным кнопкам карты ("pan" или "zoom") или по карте для идентификации показанной особенности. Так как некоторая информация состояния или значения параметров должны сохраняться между запросами, то HTML FORM содержит текущие значения параметров. Когда пользователь щелкает по карте, функция JavaScript использует эти параметры для выдачи нового запроса к карте.
Загрузка данных
В примере-приложении используются следующие темы MapViewer:
Основные (базовые) темы, включая границы штатов и большие города; Темы полевых офисов.
Определения таких тем обычно хранятся в словаре базы данных в представлении каждого пользователя - USER_SDO_THEMES. Вы можете также создать динамические темы на основе представлений, сконструированных во время выполнения, и получать результаты таких запросов на карте. Этот процесс показан в демопримере jview.jsp, который является частью MapViewer Quick Start kit.
Все базовые темы находятся наборе данных этого демопримера (mvdemo.dmp), доступного на сайте MapViewer на OTN. Этот набор включает пространственную информацию о штатах, графствах, дорогах и городах США.
Все данные для используемого в этой статье приложения-примера находятся в архиве MapViewer.zip. MapViewer.zip содержит файл field_offices.dmp file — экспорт таблицы FIELD_OFFICES из пользовательской схемы MVDEMO. MapViewer.zip также содержит файл oramap.zip, который включает исходный код приложения, скрипты, библиотеки и рабочее пространство (workspace) Oracle JDeveloper 10g. Наконец, MapViewer.zip включает файл формата readme.
После того, как вы импортировали файлы mvdemo.dmp и field_offices .dmp, выполните скрипт style_theme.sql для создания нужных стилей и тем.
Как выполнять это приложение
Откройте файл рабочего пространства oramap.jws, в Oracle JDeveloper (9.0.5 или старше), и просмотрите исходный код. При локально работающем сервисе MapViewer (или mapviewer.ear, размещенным на автономном OC4J и загруженным при старте), выполняйте JSP-файл main.jsp под проектом по имени Project. Вы должны добавить клиентскую Java-библиотеку MapViewer - $OC4J_HOME/j2ee/home/applications/mapviewer/web/WEB-INF/lib/mvclient.jar – в путь библиотек вашего проекта.
Альтернативно, чтобы выполнить наше приложение-пример без Oracle JDeveloper, скопируйте все из директории oramap/Project/public_html в новую директорию там, где размещен MapViewer (типа $OC4J_HOME/j2ee/home/applications/mapviewer/web/oramap) и с работающим сервисом MapViewer, направьте ваш браузер по адресу http://localhost:8888/mapviewer/oramap/main.jsp.
в Oracle 10g, для управления
MapViewer дает разработчикам Web-приложений продвинутое средство интеграции и визуализации карт с бизнес-данными. Он использует возможности, включенные в Oracle 10g, для управления отображением географических данных и скрывает от разработчиков приложений сложность запросов к пространственным данным и процесса рендеринга.
Следующие шаги
Читайте больше о MapViewer more about MapViewer
Скачайте
MapViewer
this article's sample application
main.jsp
