Изменение свойств объектов планировщика
Хотя упомянутые JOB, SCHEDULE, PROGRAM, WINDOW и проч., причисляются к объектам хранения БД (и видны в таблицах DBA/ALL/USEROBJECTS), не только их создание и удаление, но и изменение свойств выполняются так, как было удобно разработчику: через API. Для всех перечисленных видов объектов существует довольно много поведенческих свойств, указанию которых нет места в процедурах LIKE 'CREATE_%'. Устанавливать их следует явно единой для всех процедурой SET_ATTRIBUTE. Вот пример, как для задания MY_WINDOW_JOB (а) задать приоритет выполнения (по отношению к другим заданиям своего класса), если на одно время пришлось выполнение нескольких заданий одновременно, и (б) потребовать прекращения (процедурой STOP_JOB), если оно еще не выполнилось, а ресурсное окошко уже закрылось:
EXECUTE DBMS_SCHEDULER.DISABLE ( 'my_window_job', TRUE )
BEGIN DBMS_SCHEDULER.SET_ATTRIBUTE ( name => 'my_window_job' , attribute => 'JOB_PRIORITY' , value => 1 ); DBMS_SCHEDULER.SET_ATTRIBUTE ( name => 'my_window_job' , attribute => 'STOP_ON_WINDOW_CLOSE' , value => TRUE ) ); END; /
EXECUTE DBMS_SCHEDULER.ENABLE ( 'my_window_job' )
Полный список атрибутов и объектов, к которым они применимы, имеется в документации по Oracle.
Планировщик заданий в Oracle
,
преподаватель технологий Oracle
| ...Я старался дознаться у них, почему Нил, начиная от летнего солнцестояния, выходит из берегов и поднимается в течение приблизительно 100 дней; по истечении же этого срока вода снова спадает, ...и затем низкий уровень воды сохраняется целую зиму, вплоть до следующего летнего солнцестояния. Геродот, История |
В статье рассматриваются некоторые свойства и примеры употребления планировщика заданий, появившегося в версии Oracle 10 на смену старому.
Простой пример скомпонованного задания
Из самостоятельно существующих программы и расписания можно составить задание:
BEGIN DBMS_SCHEDULER.CREATE_JOB ( job_name => 'compound_j ob' , program_name => 'simple_program' , schedule_name => 'simple_schedule'
, enabled => TRUE ); END; /
При наличии параметра пример может выглядеть так:
BEGIN DBMS_SCHEDULER.CREATE_JOB ( job_name => 'compound_job1' , program_name => 'simple_program1' , schedule_name => 'simple_schedule' , enabled => FALSE ); END; /
BEGIN DBMS_SCHEDULER.SET_JOB_ANYDATA_VALUE ( job_name => 'compound_job1' , argument_name => 'DELTA' , argument_value => ANYDATA.CONVERTNUMBER ( 3 ) END; /
EXECUTE DBMS_SCHEDULER.ENABLE ( 'compound_job1' )
Обратите внимание, что в этом случае задание сначала создается выключенным, и только после указания значения параметра программе оно может включаться.
Простой запуск задания
Простой запуск задания очень напоминает запуск с помощью процедуры SUBMIT из пакета DBMS_JOB. Однако, в отличие от SUBMIT, он возможен только при наличии привилегии CREATE JOB. В последующих примерах созданием заданий и управлением ими для простоты будет заниматься пользователь SCOTT, хотя в жизни разумно подумать об отдельном администраторе для этой цели. Выдадим пользователю SCOTT нужную привилегию:
CONNECT / AS SYSDBA GRANT CREATE JOB TO scott;
Кроме системных привилегий, использование планировщика регулируется объектными привилегиями EXECUTE, ALTER и ALL, выдача которых применительно (GRANT ... ON) к заданию, программе, расписанию или классу заданий позволяет работать с объектами БД типов JOB, PROGRAM, SCHEDULE и JOB CLASS соответственно, введенных в Oracle 10 вместе с новым планировщиком.
Ввиду того, что в дальнейшем предполагаются эксперименты с изменениями зарплаты сотрудников, будет удобно исходную зарплату сохранить:
CONNECT scott/tiger ALTER TABLE emp ADD ( oldsal NUMBER ); UPDATE emp SET oldsal = sal; COMMIT;
Скомпонованное задание
Более развитая возможность DBMS_SCHEDULER позволяет скомпоновать задание из независимых элементов: программы и расписания. Характерная особенность в том, что оба эти элемента самостоятельны; их можно комбинировать в разных заданиях и изменять, не внося изменений в определения заданий.
Создание и использование ресурсного окошка СУБД для задания
Очередной запуск внутреннего задания может прийтись на время активного использования ресурсов СУБД другими процессами. Это может замедлить выполнение планового задания, обесценить его выполнение и даже поставить его выполнение под угрозу. Справиться с этой проблемой призвано ресурсное окошко. Суть его состоит в одновременном с очередным запуском задания автоматическом переключении СУБД на работу по требуемому ресурсному плану (план поведения для распределителя ресурсов СУБД, resource manager). Сами ресурсные окошки (windows) принадлежат схеме SYS, но создавать их разрешено и другим пользователям при наличии соответствующей привилегии:
CONNECT / AS SYSDBA GRANT MANAGE SCHEDULER TO scott;
Ресурсный план построить несложно, но, чтобы не отвлекаться, воспользуемся встроенным в любую БД планом SYSTEM_PLAN (см. таблицу DBA_RSRC_PLANS). Тогда создание окошка может выглядеть так:
CONNECT scott/tiger
BEGIN DBMS_SCHEDULER.CREATE_WINDOW ( window_name => 'my_job_window' , resource_plan => 'SYSTEM_PLAN' , start_date => SYSTIMESTAMP , repeat_interval => 'FREQ=MINUTELY; INTERVAL=3' , duration => INTERVAL 4' MINUTE END; /
EXECUTE DBMS_SCHEDULER.ENABLE ( 'sys.my_job_window' )
Теперь каждые три минуты на минуту будет включаться ресурсный план SYSTEM_PLAN. Это легко наблюдать, выдав несколько раз от имени SYS:
COL window_name FORMAT A20 COL log_date FORMAT A4 0 SELECT * FROM ( SELECT log_date, window_name, operation FROM dba_scheduler_window_log ORDER BY log_date DESC ) WHERE ROWNUM
Если подгадать момент, когда значение OPERATION для окошка MY_JOB_WINDOW станет OPEN, от имени SYS можно будет удостовериться, что план включен:
SYS> SHOW PARAMETER resource
NAME TYPE VALUE -------------------------------------------------------------------------- resource_limit boolean FALSE resource_manager_plan string SCHEDULER[0xD5A4]:SYSTEM_PLAN
Чтобы связать с этим периодически открывающимся ресурсным окошком задание, пользователю SCOTT достаточно указать его вместо расписания:
BEGIN DBMS_SCHEDULER.CREATE_JOB ( jobname => 'my_window_job' , program_name => 'simple_program' , schedule_name => 'sys.my_job_window' , enabled => FALSE ) ; END; /
EXECUTE DBMS_SCHEDULER.ENABLE ( 'my_window_job' )
С этого момента можно наблюдать уменьшение зарплат сотрудников, осуществляемое каждые три минуты в условиях благоприятного ресурсного плана. В качестве варианта, в процедуре CREATE_WINDOW можно было сослаться и на какое-то существующее расписание.
Так как СУБД в каждый момент времени умеет работать только по одному ресурсному плану, окошки «не умеют» перекрываться, а могут только переопределять своим планом другой, ранее установленный и пришедшийся на то же время.
В качестве развития этой темы Oracle позволяет создавать именованный список существующих окошек и под маркой «группы» (window group) указывать его заданию значением параметра SCHEDULE_NAME, то есть там, где у нас было указано имя окошка.
Создание программы
Простой пример создания программы:
BEGIN DBMS_SCHEDULER.CREATE_PROGRAM ( program_name => 'simple_program'
, program_type => 'STORED_PROCEDURE' , program_action => 'updatesal' , enabled => TRUE ); END; /
Список сведений об имеющихся программах для планировщика имеется в таблицах DBA/ALL/USER_SCHEDULER_PROGRAMS.
Другими значениями параметра PROGRAM_TYPE могут быть 'PLSQL_BLOCK' и 'EXECUTABLE' (см. выше).
При наличии у процедуры параметров их количество потребуется указать особо:
CREATE PROCEDURE salary ( deer NUMBER ) AS BEGIN UPDATE emp SET sal = sal - deer; END; /
BEGIN DBMS_SCHEDULER.CREATE_PROGRAM ( program_name => 'simple_program1'
, program_type => 'STORED_PROCEDURE' , program_action => 'salary' , enabled => FALSE
, number_of_arguments => 1 ) ; END; /
Обратите внимание, что программа создана «отключенной». Дело в том, что указать фактические значения параметрам программе во «включенном» состоянии нельзя, так что последовательность действий будет следующая:
BEGIN DBMS_SCHEDULER.DEFINE_PROGRAM_ARGUMENT ( program_name => 'simple_program1'
, argument_position => 1 , argument_name => 'DELTA' , argument_type => 'NUMBER' ) ; END; /
EXECUTE DBMS_SCHEDULER.ENABLE ( 'simple_program1' )
Создание расписания
Пример создания расписания:
BEGIN DBMS_SCHEDULER.CREATE_SCHEDULE ( schedule_name => 'simple_schedule'
, start_date => SYSTIMESTAMP , repeat_interval => 'FREQ=WEEKLY; BYDAY=MON, TUE, WED, THU, FRI' , end_date => SYSTIMESTAMP + INTERVAL '1' MONTH ) ; END; /
В общем случае язык указания графика для расписания (параметр REPEAT_INTERVAL) допускает ссылаться на ранее созданные таким же образом расписания.
Список сведений об имеющихся расписаниях для планировщика имеется в таблицах DBA/ALL/USER_SCHEDULER_SCHEDULES.
Внешнее задание (для ОС)
Совсем новым в планировщике Oracle 10 является возможность запускать плановые задания в ОС. Однако чтобы это было возможно, в ОС должна быть запущена программа extjob из ПО СУБД. На Windows она запускается службой OracleJobScheduler. Для того чтобы следующий пример проработал, службу необходимо запустить. Вдобавок потребуется выдать пользователю SCOTT еще одну привилегию.
Пример запуска:
CONNECT / AS SYSDBA GRANT CREATE EXTERNAL JOB TO scott;
CONNECT scott/tiger BEGIN DBMS_SCHEDULER.CREATE_JOB ( job_name => 'simple_job' , job_type => 'EXECUTABLE' , jobaction => 'cmd.exe /C dir > \temp\out.txt'
, enabled => TRUE ); END; /
Обратите внимание, что в Windows выдача команды ОС или же запуск командного файла напрямую (без вызова cmd.exe), не проходит.
В Unix аналогичное действие можно записать как 'ls > /tmp/out. txt'.
Внутреннее задание для СУБД
Пример внутреннего задания в виде неименованного блока PL/SQL:
BEGIN DBMS_SCHEDULER.CREATE_JOB
( job_name => 'simple_job' , jobtype => 'PLSQL_BLOCK' , job_action => 'UPDATE emp SET sal = sal +1;' , enabled => TRUE ); END; /
Обратите внимание:
Обрамлять блок словами BEGIN и END не обязательно, так как код пакета DBMS_SCHEDULER это сделает самостоятельно (ради особой программной логики, добавляемой им к тексту пользователя).
Задание запускается в этом же сеансе и сопровождается неявной выдачей COMMIT. В этом легко удостовериться:
COMMIT; UPDATE emp SET sal = sal + 1; BEGIN DBMS_SCHEDULER.CREATE_JOB (... как выше ...) END; ROLLBACK;
Зарплата SAL увеличится на 2. Проверить это в качестве упражнения.
Для хранимой процедуры задание формируется аналогично:
CREATE PROCEDURE updatesal AS BEGIN UPDATE emp SET sal = sal - 1; END;
/
BEGIN DBMS_SCHEDULER.CREATE_JOB ( job_name => 'simple_job' , jobtype => 'STORED_PROCEDURE' , job_action => 'updatesal' , enabled => TRUE ) ; END; /
Обратите внимание, что нам не потребовалось удалять старое задание SIMPLE_JOB, так как при выбранных нами параметрах процедуры CREATE_JOB задания (и первое, и второе) прогонялись однократно, моментально и сразу же удалялись автоматически. Последнее как раз можно и отменить посредством не использованного в примере выше параметра AUTO_DROP.
В случае невозможности запустить задание СУБД, подобно тому, как это делалось для старого планировщика (пакет DBMS_JOB), будет делать повторные попытки, но только по несколько иной схеме: через секунду, затем через 10 секунд, затем через 100 и далее – всего 6 раз, если только до этого не наступит очередной плановый момент.
Возможности запуска, наблюдения, вмешательства
Так же, как для пакета DBMS_JOB, в новом планировщике предусмотрено именно плановое, а не одноразовое исполнение задания. Добавим к последнему вызову параметр:
, start_date => SYSTIMESTAMP + INTERVAL '10' SECOND
В результете корневой файл out.txt получим через 10 секунд после создания задания. Добавим еще параметр:
, repeat_interval => 'FREQ=MONTHLY; BYDAY=SUN, -1 SAT'
В результате задание будет исполняться ежемесячно по воскресениям и последним субботам месяца. В отличие от DBMS_JOB, DBMS_SCHEDULER, в дополнение к возможности употребить выражение на PL/SQL, имеет для формулирования графика запуска еще и специальный язык. Он позволяет указывать частоту, интервал и уточнитель запуска задания. Примеры:
FREQ=HOURLY;INTERVAL=4 каждые 4 часа; FREQ=HOURLY;INTERVAL=4;BYMINUTE=10;BYSECOND=30 каждые 4 часа на 10-й минуте, 30-й секунде; FREQ=YEARLY;BYYEARDAY=-276 каждое 31-е марта; FREQ=YEARLY;BYMONTH=MAR;BYMONTHDAY=31 каждое 31-е марта;
Для проверки правильности составления выражения можно воспользоваться специальной процедурой:
DECLARE next_run_date TIMESTAMP; BEGIN DBMS_SCHEDULER.EVALUATE_CALENDAR_STRING ( 'FREQ=HOURLY;INTERVAL=4;BYMINUTE=10;BYSECOND=30'
, SYSTIMESTAMP , NULL , next_run_date ) ; DBMS_OUTPUT.PUT_LINE ( 'next_run_date: ' next_run_date ); END;
Полное описание языка приводится в документации по Oracle.
Если указать план запуска, задание появится в системе уже надолго. Удалить его при необходимости можно будет так:
EXECUTE DBMS_SCHEDULER.DROP_JOB ( 'simple_job', TRUE )
Информацию об имеющихся заданиях пользователь SCOTT может посмотреть запросом:
SELECT job_name, state, enabled FROM user_scheduler_jobs;
Более подробную информацию SCOTT обнаружит в таблицах USER_SCHEDULER_%, а более общую – в обычной таблице USER_OBJECTS.
и сложный механизм, требующий выполнения
СУБД Oracle — большой и сложный механизм, требующий выполнения определенных плановых работ, таких как сбор статистики о хранимых объектах или сбор/чистка внутренней информации. Необходимость осуществлять плановый запуск работ могут испытывать и пользователи БД.
Первый механизм планового запуска появился в версии 7 для поддержки автоматических обновлений снимков (snapshots), как поначалу именовались нынешние материализованные виртуальные таблицы (materialized views). В версии 8 этот механизм был открыт для обычных пользователей через посредство некоторых параметров СУБД, таблиц словаря-справочника, а также пакета DBMS_JOB. Пакет DBMS_JOB позволял (и позволяет) запускать хранимую процедуру, или же неименованный блок PL/SQL в моменты времени, вычисляемые по указанной пользователем формуле.
К версии 10 такое устройство имевшегося планировщика заданий было сочтено слишком примитивным, и в ней появился новый планировщик, значительно более проработанный. Он использует следующие основные понятия:
Schedule (расписание) Program (программа) Job (плановое задание = расписание + программа)
Кроме того, с ним связаны дополнительные, более специфичные понятия:
Job class (класс заданий) Window и window group (ресурсное «окошко», интервал для автоматического включения ресурсного плана СУБД и группа окошек) Chain (цепочка заданий) Event schedule (возможность запустить задание по событию, зафиксированному по сообщению из очереди AQ)
В отличие от старого планировщика, в новом «программой» может быть не только блок PL/SQL, но и хранимая процедура на PL/SQL или на Java, внешняя процедура на С или даже команда ОС. Последнее означает, что Oracle отменяет необходимость использовать специфичные для разных платформ планировщики заданий ОС (cron, at) при построении БД-центричного приложения. Вдобавок, сам запуск заданий получил возможность учета текущей вычислительной обстановки в СУБД, а также желаемой приоритетности среди прочих заданий.
Как и в случае со старым планировщиком, новый, по сути, представляет собой элемент ядра СУБД, доступ пользователя к которому предоставляется посредством программной логики и элементов схемы БД. Именно, в распоряжении пользователя имеется следующее:
таблицы словаря-справочника LIKE '%SCHEDULER_%' (DBA_SCHEDULER_JOBS, DBA_SCHEDULER_JOB_LOG и прочие); несколько типов объектов хранения, как то:
JOB SCHEDULE PROGRAM JOB CLASS, ряд других; системные привилегии:
CREATE SESSION CREATE JOB CREATE ANY JOB EXECUTE ANY PROGRAM EXECUTE ANY CLASS MANAGE SCHEDULER CREATE EXTERNAL JOB, и объединяющая их роль SCHEDULERADMIN; объектные привилегии:
EXECUTE ALTER ALL, распространяющиеся на объекты типов JOB, SCHEDULE, PROGRAM и JOB CLASS; пакет DBMS_SCHEDULER.
Версия 11 дополнила планировщик возможностями:
запуска «легковесных» заданий, делающей реальным их создание и удаление сотнями за секунду; запуска заданий на удаленных машинах посредством использования специального агента; запуска заданий только на основной БД физического горячего резерва или на страхующей БД логического резерва.
Некоторые ключевые моменты использования планировщика в Oracle 10 рассматриваются ниже на примерах.
с планировщиком Oracle 10 средствами
Помимо использованного выше общения с планировщиком Oracle 10 средствами PL/SQL и SQL, общаться с ним можно через графический интерфейс Oracle Enterprise Manager. По сути, OEM ничего нового не дает, так как в конечном итоге отсылает к СУБД те же команды на PL/SQL и SQL, но выполнение разовых действий через OEM часто администратору быстрее и понятнее. Для автоматизации работ, однако, лучше может подойти работа со сценариями запросов.
После проведенных опытов с планировщиком не забудьте освободить БД от ненужных объектов. Например:
EXECUTE DBMS_SCHEDULER.DROP_JOB ( 'my_window_job', force => TRUE ) EXECUTE DBMS_SCHEDULER.DROP_WINDOW ( 'my_job_window', force => TRUE )
Удаление прочих созданных ранее объектов и изъятие выданных пользователю SCOTT привилегий предлагается сделать самостоятельно в виде упражнения, воспользовавшись таблицами словаря-справочника и, при надобности, документацией. Можно также использовать OEM.
Аннотация
Установленная в БД XML DB позволяет средствами СУБД, без привлечений внешнего контейнера сервлетов, организовать сервлетный доступ к данным в базе. Фактически это означает возможность организовать для доступа к данным сервер web «внутри СУБД». В статье показано на примерах, как это можно сделать.
Создание сервлета на Java
Oracle XML DB поддерживает Java Servlet API версии 2.2 с некоторыми ограничениями, и с возможностью дополнительно установить сервлет поддержки JSP.
Подготовим текст сервлета в файле XMLDBServlet.java:
import java.io.PrintWriter; import java.io.IOException; import javax.servlet.GenericServlet; import javax.servlet.ServletRequest; import javax.servlet.ServletResponse; import javax.servlet.ServletException;
public class XMLDBServlet extends GenericServlet {
public void service ( ServletRequest request
, ServletResponse response
) throws ServletException, IOException {
String s = request.getParameter ( "rex" );
response.setContentType ( "text/xml" );
PrintWriter out = response.getWriter ( ); out.println ( "<?xml version=\"1.0\"?>" ); out.println ( "<html><head>" ); out.println ( "<title>My XMLDBServlet servlet demo</title>" ); out.println ( "</head><body>" ); out.println ( "<h2>Ave, " + s + " !</h2>" ); out.println ( "</body></html>" ); out.close ( ); } }
Пример ради общности рассматривает употребление суперкласса GenericServlet, а не HttpServlet.
Загрузим сервлет в БД одним из возможных способов:
>loadjava -grant public -u scott/tiger -r XMLDBServlet.java
Проверкой легко убедиться, что СУБД не только загрузит в БД исходный текст, но и получит из него класс.
Чтобы сервлет мог вызываться извне, сведения о нем требуется занести в ресурс-файл /xdbconfig.xml в репозитарии XML DB. Это файл с «объектно-реляционным» храненнем, и подправить его можно либо через WebDAV (системами, обеспечивающими такую правку), либо обычными функциями UPDATEXML и прочими. (Именно этот файл не допускает удаления из репозитария, поэтому выгрузить его, подправить и загрузить заново невозможно).
Однако при желании, для удобства правки файла /xdbconfig.xml можно использовать специально созданые для этого подпрограммы пакета DBMS_XDB. Выполним в SQL*Plus от имени пользователя XDB:
DECLARE xval XMLTYPE;
xnode1 XMLTYPE := XMLTYPE ( ' <servlet xmlns="http://xmlns.oracle.com/xdb/xdbconfig.xsd"> <servlet-name>XMLDBServletPrimer</servlet-name> <servlet-language>Java</servlet-language> <display-name>Oracle XML DB Servlet Primer</display-name> <servlet-class>XMLDBServlet</servlet-class> <servlet-schema>SCOTT</servlet-schema> </servlet> ');
xnode2 XMLTYPE := XMLTYPE ( ' <servlet-mapping xmlns="http://xmlns.oracle.com/xdb/xdbconfig.xsd"> <servlet-pattern>/xdbserv</servlet-pattern> <servlet-name>XMLDBServletPrimer</servlet-name> </servlet-mapping> ');
BEGIN SELECT DBMS_XDB.CFG_GET ( ) INTO xval FROM dual;
SELECT INSERTCHILDXML ( xval, '/xdbconfig//servlet-list', 'servlet', xnode1
) INTO xval FROM dual ; SELECT INSERTCHILDXML ( xval, '/xdbconfig//servlet-mappings', 'servlet-mapping', xnode2
) INTO xval FROM dual ;
DBMS_XDB.CFG_UPDATE ( xval ); COMMIT; END; /
Теперь обращение по адресу:
даст результат:
Выдача данных в формате HTML и обращение к БД делается как обычно.
Например, для перехода к HTML в данном случае даже необязательно пользоваться классом HttpServlet. Достаточно в описании сервлета заменить text/xml на text/html и изъять строку out.println ( "<?xml version=\"1.0\"?>" );. Перетранслировав сервлет, получим по тому же адресу:
Обращение в тексте сервлета к данным БД делается как обычно для Java, и оставляется для самостоятельного упражнения.
Технология сервлетов СУБД для доступа к данным БД
,
Преподаватель технологий Oracle
| Люди часто совершают старые ошибки, но при этом ссылаются на новые обстоятельства. А. Эйнштейн. |
Встроенный сервлет DBURIServlet
Сервлет DBURIServlet написан на C и готов для употребления при установленном репозитарии по адресу /oradb/схема_БД/имя_таблицы[...]. Тем не менее он параметризован, и поэтому представляет интерес для конечных потребителей БД.
Пример обращения:
Правила формирования адреса соответствуют правилам типа DBURITYPE.
Упражнение. Проверить работу сервлета DBURIServlet на следующих обращениях:
Сервлет DBURIServlet имеет параметры:
rowsettag - для смены имени корневого элемента, например:
contenttype - для указания типа MIME, например:
transform - для преобразования текста XML средствами XSLT.
Зарегистрируем в качестве ресурса /public/dept.xsl следующий текст:
<?xml version="1.0"?> <xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform" > <xsl:output method="html" />
<xsl:template match="ROW"> <tr> <td><xsl:value-of select="DEPTNO"/></td> <td><xsl:value-of select="DNAME"/></td> <td><xsl:value-of select="LOC"/></td> </tr> </xsl:template>
<xsl:template match="DEPT"> <html><head></head><body><title>Departments</title> <table border="3" bordercolor="green">
<xsl:apply-templates select="ROW"/>
</table> </body></html> </xsl:template>
</xsl:stylesheet>
Теперь обращение к XML DB по адресу:
даст следующий результат:
Текст с определением преобразования XSLT можно разместить и в таблице БД, обратившись за ним опять-таки через DBURITYPE примерно так:
transform=/oradb/SCOTT/XSLTDEFS/ROW[TAB='DEPT']/DEFINITION/text()
Упражнение. Создать таблицу XSLTDEFS с определением преобразования XSLT для таблицы DEPT (столбец TAB для имени таблицы и столбец DEFINITION для текста преобразования) и указать сервлету взять данные преобразования оттуда, а не из ресурса XML DB. Указание: поле DEFINITION определить типом VARCHAR2.
Прочие свойства сервлета приведены в документации по XML DB.
Эта статья является продолжением статей
Эта статья является продолжением статей «XML DB - новое измерение в организации данных в Oracle», и .
Репозитарий XML DB обеспечивает возможность доступа к данным БД на основе технологии сервлетов HTTP/HTTPS. Конфигурацию сервлетов можно наблюдать и устанавливать в ресурсе-файле /xdbconfig.xml.
Создавать сервлеты «внутри БД» можно на C и на Java, однако для первого случая фирма дает в распоряжение пользователям только готовый для употребления сервлет, а во втором - правила самостоятельного построения.
Если говорить о реализации на Java, то это часть возможностей по организации работы СУБД с разнохарактерными программными элементами на Java, имевшихся в Oracle в версиях с 8.1 по 9.0, но выполненных на иной техлогической основе.
Аннотация
В каждом сеансе работы с СУБД можно использовать так называемые контексты, формально представляющие собой именованный набор пар «параметр/значение». Контексты сеансов обладают рядом интересных свойств, существенно повышающих «внутренние» возможности Oracle по созданию приложений. В статье рассматриваются два предопределенных контекста Oracle: USERENV и CLIENTCONTEXT.
Часть 1: предопределенные контексты
,
Преподаватель технологий Oracle,
Узнаю милого по походке.
Поговорка.
Часть 2: создание своими руками
,
Преподаватель технологий Oracle,
Сама садик я садила,
Сама буду поливать,
Сама милого любила,
Сама буду забывать.
Русская народная песня
Глобальный контекст сеанса («контекст приложения»)
«Обычный» контекст сеанса имеет своею областью действия отдельный сеанс. Иногда этого разработчику приложения вполне достаточно, а иногда хочется большего. Можно ли, например, запретить сеансу самостоятельно выставлять значение атрибута и предоставить ему только чтение, а значение задавать из другого сеанса? Такую возможность обеспечивает глобальный контекст сеанса, называемый еще иногда контекстом приложения. Пример его использования показан ниже:
CONNECT / AS SYSDBA
CREATE OR REPLACE CONTEXT globalcontext USING globalcontext_pckg
ACCESSED GLOBALLY
/
CREATE OR REPLACE PACKAGE globalcontext_pckg AS PROCEDURE set_value ( par VARCHAR2 , val VARCHAR2 , usr VARCHAR2
, usrid VARCHAR2
); END; /
CREATE OR REPLACE PACKAGE BODY globalcontext_pckg AS PROCEDURE set_value ( par VARCHAR2 , val VARCHAR2 , usr VARCHAR2 , usrid VARCHAR2 ) AS BEGIN DBMS_SESSION.SET_CONTEXT ( 'globalcontext' , par , val , usr
, usrid
); END; END; /
EXECUTE globalcontext_pckg.set_value - ( 'sesame' , '123', 'SCOTT', 'XYZ32A6' )
Проверка:
SQL> CONNECT scott/tiger Connected. SQL> SELECT SYS_CONTEXT ( 'globalcontext', 'sesame' ) FROM dual;
SYS_CONTEXT('GLOBALCONTEXT','SESAME') --------------------------------------------------------------------
SQL> EXECUTE DBMS_SESSION.SET_IDENTIFIER ( 'XYZ32A6' );
PL/SQL procedure successfully completed.
SQL> SELECT SYS_CONTEXT ( 'globalcontext', 'sesame' ) FROM dual;
SYS_CONTEXT('GLOBALCONTEXT','SESAME') -------------------------------------------------------------------- 123
SQL> EXECUTE DBMS_SESSION.SET_IDENTIFIER ( 'XYZ32A6ZZZ' );
PL/SQL procedure successfully completed.
SQL> SELECT SYS_CONTEXT ( 'globalcontext', 'sesame' ) FROM dual;
SYS_CONTEXT('GLOBALCONTEXT','SESAME') ----------------------------------------------------------------------
Тут есть сразу несколько интересных новшеств.
То, что контекст глобальный, было указано словами ACCESSED GLOBALLY при его создании. В процедуре DBMS_SESSION.SET_CONTEXT именно для глобального контекста существуют два дополнительных параметра. Первый сообщает, сеансам чьего пользователя будет доступен этот контекст (для каждого такого пользователя нужно будет выполнить отдельный вызов SET_CONTEXT), а второй - условное значение, которое необходимо будет сообщить для возможности прочитать установленное другим сеансом значения атрибута, своего рода пароль. Сообщение этого условного значения выполняется специальной процедурой DBMS_SESSION.SET_IDENTIFIER.
Таким образом, мало войти в СУБД под «правильным» пользователем; для того, чтобы получить в сеансе значение желаемого атрибута (глобального контекста), нужно будет еще сообщить условную строку. Излишне напоминать, что очевидным кандидатом на такую строку является cookie сеанса общения с web. И только благодаря этому, а также механизму избирательного доступа к частям таблицы в Oracle («виртуальные частные базы данных», VPD/FGAC) и возможности сервера приложений автоматически выдавать SET_IDENTIFIER при обращении к БД, многочисленные пользователи web, формально подключаемые к СУБД под одними и теми же именами пользователей Oracle, смогут увидеть в базе каждый собственные данные.
Готовый изменяемый контекст сеанса CLIENTCONTEXT
Еще один предопределенный контекст, с именем CLIENTCONTEXT, также не требует специального создания, однако в отличие от USERENV он позволяет сеансу создавать собственные атрибуты и задавать им значения. Особенность этого контекста в том, что он, в дополнение к обычному способу (изнутри сеанса), позволяет устанавливать значения атрибутам заранее, при открытии соединения с СУБД клиентской программой, и передавать их для обработки в сеанс. Делается это
либо через библиотеку OCI с помощью специального вызова OCIAppCtxSet
либо из программы на Java с помощью методов класса oracle.jdbc.internal.OracleConnection.
Тем самым контекст CLIENTCONTEXT способен при открытии сеанса передать информацию, дополнительную к традиционному имени пользователя и к ограниченному кругу сведений (адрес IP клиента, имя компьютера и пр.), доступному из контекста USERENV.
Значения переданных в сеанс атрибутов контекста CLIENTCONTEXT можно читать как обычно функцией SYS_CONTEXT, и изменять, но можно заводить и новые атрибуты:
SQL> CONNECT scott/tiger Connected. SQL> EXECUTE DBMS_SESSION.SET_CONTEXT ( 'CLIENTCONTEXT', 'a', 'b' )
PL/SQL procedure successfully completed.
SQL> SELECT SYS_CONTEXT ('CLIENTCONTEXT', 'a' ) FROM dual;
SYS_CONTEXT('CLIENTCONTEXT','A') -------------------------------------------------------------------- b
Если бы атрибут A был установлен клиентской программой на C или на Java перед установлением соединения, значение B мы бы увидели сразу.
Второе отличительное свойство контекста CLIENTCONTEXT в том, что Oracle разрешает именно для него обращаться к DBMS_SESSION.SET_CONTEXT напрямую (см. выше). Это исключение: контексты, которые разработчик пожелает создавать сам, позволят обращаться к DBMS_SESSION.SET_CONTEXT только из текста своей доверительной программной единицы.
Готовый справочный контекст сеанса USERENV
Один контекст, с названием USERENV, создавать явным образом не требуется. Он доступен любому сеансу связи с СУБД Oracle в виде готового набора значений, разрешающего только прочтение, но не правку. Он позволяет узнать всевозможные сведения о сеансе, полезные для прикладного программирования. Ранее в Oracle существовала одноименная функция, но сейчас она поддерживается ради старых программ.
Пример информации, которую можно получить из контекста USERENV в программу:
COLUMN authent FORMAT A10 COLUMN curr_schema FORMAT A10 COLUMN curr_user FORMAT A10 COLUMN db_name FORMAT A10 COLUMN db_domain FORMAT A10 COLUMN host FORMAT A15 COLUMN ip_address FORMAT A15 COLUMN os_user FORMAT A15
SELECT SYS_CONTEXT ( 'userenv', 'AUTHENTICATION_TYPE' ) authent , SYS_CONTEXT ( 'userenv', 'CURRENT_SCHEMA' ) curr_schema , SYS_CONTEXT ( 'userenv', 'CURRENT_USER' ) curr_user , SYS_CONTEXT ( 'userenv', 'DB_NAME' ) db_name , SYS_CONTEXT ( 'userenv', 'DB_DOMAIN' ) db_domain , SYS_CONTEXT ( 'userenv', 'HOST' ) host , SYS_CONTEXT ( 'userenv', 'IP_ADDRESS' ) ip_address , SYS_CONTEXT ( 'userenv', 'OS_USER' ) os_user FROM dual ;
Полный список атрибутов контекста USERENV можно узнать из документации (в справочнике по SQL, в разделе, посвященному функции SYS_CONTEXT).
Вот пример того, как сведения из этого контекста помогают различить разные условия употребления конкретной программы:
CONNECT scott/tiger
CREATE PROCEDURE whoowns AS BEGIN DBMS_OUTPUT.PUT_LINE ( SYS_CONTEXT ( 'userenv', 'CURRENT_SCHEMA' ) ); DBMS_OUTPUT.PUT_LINE ( SYS_CONTEXT ( 'userenv', 'CURRENT_USER' ) ); DBMS_OUTPUT.PUT_LINE ( user ); END; /
Проверка:
SQL> SET SERVEROUTPUT ON SQL> EXECUTE whoowns SCOTT SCOTT SCOTT
PL/SQL procedure successfully completed.
SQL> ALTER SESSION SET CURRENT_SCHEMA = system;
Session altered.
SQL> EXECUTE scott.whoowns SCOTT SCOTT SCOTT
PL/SQL procedure successfully completed.
SQL> CONNECT / as sysdba Connected. SQL> SET SERVEROUTPUT ON SQL> EXECUTE scott.whoowns SCOTT SCOTT SYS
CREATE OR REPLACE PROCEDURE whoowns
PL/SQL procedure successfully completed.
Перетранслируем процедуру для работы с правами запускающего:
CONNECT scott/tiger
CREATE OR REPLACE PROCEDURE whoowns AUTHID CURRENT_USER
AS BEGIN DBMS_OUTPUT.PUT_LINE ( SYS_CONTEXT ( 'userenv', 'CURRENT_SCHEMA' ) ); DBMS_OUTPUT.PUT_LINE ( SYS_CONTEXT ( 'userenv', 'CURRENT_USER' ) ); DBMS_OUTPUT.PUT_LINE ( user ); END; /
Снова проверка:
SQL> SET SERVEROUTPUT ON SQL> EXECUTE whoowns SCOTT SCOTT SCOTT
PL/SQL procedure successfully completed.
SQL> ALTER SESSION SET CURRENT_SCHEMA = system;
Session altered.
SQL> EXECUTE scott.whoowns SYSTEM SCOTT SCOTT
PL/SQL procedure successfully completed.
SQL> CONNECT / as sysdba Connected. SQL> SET SERVEROUTPUT ON SQL> EXECUTE scott.whoowns SYS SYS SYS
PL/SQL procedure successfully completed.
SQL> ALTER SESSION SET CURRENT_SCHEMA = system;
Session altered.
SQL> EXECUTE scott.whoowns SYSTEM SYS SYS
Примеры поясняют отличие атрибутов CURRENT_SCHEMA и CURRENT_USER контекста USERENV друг от друга и от системной переменной USER.
Как построить контекст сеанса своими руками
Для самостоятельного создания контекста служит специальная команда CREATE CONTEXT. Выдать ее (то есть создать контекст) может сеанс, имеющий полномочие CREATE ANY CONTEXT. Слово ANY в названии полномочия (привилегии) свидетельствует о том, что контекст - внесхемный объект в БД Oracle, такой, например, как роль, и отличный, например, от таблицы.
Для каждого контекста требуется указать специальную «доверительную» программную единицу: процедуру, функцию или пакет. Именно из тела этой программной единицы Oracle разрешит обращаться к процедуре DBMS_SESSION.SET_CONTEXT. Принято такое неочевидное решение во имя безопасности, так как доступ к хранимым программным единицам регулируется уже готовым механизмом привилегий.
Начальные значения атрибутов контекста
Выше было показано, как атрибуты контекстов выставляются в процессе сеанса связи с СУБД. Однако по подобию с CLIENTCONTEXT создаваемый контекст тоже можно обеспечить начальными значениями требуемых атрибутов из программы, открывающий сеанс. Это можно сделать
средствами OCI (вызовы OCIAttrSet и OCISessionBegin) и через сервер имен (каталог) LDAP.
Возможность таких начальных присвоений обеспечивается соответствующими указаниями при создании контекста:
CREATE CONTEXT ... INITIALIZED EXTERNALLY и
CREATE CONTEXT ... INITIALIZED EXTERNALLY
Начальные значения атрибутов контекста для сеансов - очень сильное средство, позволяющее наложить на относительно примитивный механизм внутренних пользователей БД инфраструктуру внешних пользователей, часто более проработанную и универсальную. Например, сервер приложений может поддерживать очень много пользователей web-страниц, обладающих собственными свойствами. Моделировать их отдельными локальными для Oracle пользователями может оказаться крайне неэффективно, и в этом случае возможность предварительного установления атрибутов перед обращением к БД будет давать единственный ключ к построению решения.
Пример создания контекста
Положим, доверительной программной единицей должна быть процедура SET_MYCONTEXT_VALUE:
CONNECT / as sysdba
CREATE OR REPLACE CONTEXT mycontext USING set_mycontext_value;
Обратите внимание, что процедура не обязана существовать в момент создания контекста. Но в конце концов ее-таки потребуется создать:
CREATE OR REPLACE PROCEDURE set_mycontext_value ( par IN VARCHAR2 , val IN VARCHAR2 ) AS BEGIN DBMS_SESSION.SET_CONTEXT ( 'mycontext', par, val ); END; /
GRANT EXECUTE ON set_mycontext_value TO scott;
Проверка:
SQL> CONNECT scott/tiger Connected. SQL> SELECT SYS_CONTEXT ( 'mycontext', 'sesame' ) FROM dual;
SYS_CONTEXT('MYCONTEXT','SESAME') ------------------------------------------------------------
SQL> EXECUTE sys.set_mycontext_value ( 'sesame', '123' )
PL/SQL procedure successfully completed.
SQL> SELECT SYS_CONTEXT ( 'mycontext', 'sesame' ) FROM dual;
SYS_CONTEXT('MYCONTEXT','SESAME') ------------------------------------------------------------ 123
Выше серым фоном выделена пустая строка.
С помощью контекста MYCONTEXT и доступной ему процедуры пользователь SCOTT завел значение, которое сможет читать и переустанавливать в собственном сеансе вплоть до завершения. Другой сеанс пользователя SCOTT создаст и будет использовать с помощью этого же контекста свои значения, то есть значения контекста являются собственностью сеанса.
Значения атрибутов контекста живут не долее пределов сеанса и защищены от доступа из других сеансов. В течение сеанса значения переменных пакета могут пропасть («сброс» пакета, хотя пользователи и нечасто прибегают к нему), и значения атрибутов контекста тоже (с помощью пакета DBMS_SESSION). Этим атрибуты схожи с переменными пакета. Но есть и отличия:
в пакете набор переменных фиксирован, а набор атрибутов контекста произволен переменные пакета могут быть разнообразны по структуре, а значения атрибутов контекста - всего лишь строки текста атрибутам контекста можно устанавливать до сеанса и делать доступными в другом сеансе.
Вот еще пример использования нашего контекста:
SQL> EXECUTE set_mycontext_value - > ( 'start work', TO_CHAR ( SYSDATE, 'hh24:mi:ss' ) )
PL/SQL procedure successfully completed.
SQL> REMARK выполняем работу, после чего смотрим когда начинали ...
SQL> SELECT SYS_CONTEXT ( 'mycontext', 'start work' ) FROM dual;
SYS_CONTEXT('MYCONTEXT','STARTWORK') -------------------------------------------------------------------- 13:58:06
Вариация в технологии: использование доверительного пакета
Если запросить структуру справочной таблицы доступных контекстов, то видно, что поле для доверительной программной единицы названо PACKAGE:
SQL> SELECT * FROM all_context;
NAMESPACE SCHEMA PACKAGE
---------------------- ---------------------- ---------------------- MYCONTEXT SYS SET_CONTEXT_VALUE
Это не случайно: на практике часто более технологично установку контекста выполнять с помощью доверительного пакета, а не самостоятельной процедуры или функции. Ведь в состав пакета можно включить и прочие программные элементы, моделирующие логику предметной области.
Пример:
CONNECT / as sysdba
CREATE OR REPLACE CONTEXT mycontext USING mycontext_pckg;
CREATE OR REPLACE PACKAGE mycontext_pckg IS PROCEDURE set_value ( par VARCHAR2, val VARCHAR2 ); FUNCTION get_value ( par VARCHAR2 ) RETURN VARCHAR2; END; /
CREATE OR REPLACE PACKAGE BODY mycontext_pckg IS PROCEDURE set_value ( par VARCHAR2, val VARCHAR2 ) IS BEGIN DBMS_SESSION.SET_CONTEXT ( 'mycontext', par, val ); END;
FUNCTION get_value ( par VARCHAR2 ) RETURN VARCHAR2 IS BEGIN RETURN SYS_CONTEXT ( 'mycontext', par ); END; END; /
GRANT EXECUTE ON mycontext_pckg TO scott;
Проверка:
SQL> CONNECT scott/tiger Connected. SQL> SELECT sys.mycontext_pckg.get_value ( 'sesame' ) FROM dual;
SYS.MYCONTEXT_PCKG.GET_VALUE('SESAME') ---------------------------------------------------------------------
SQL> EXECUTE sys.mycontext_pckg.set_value ( 'sesame', '123' )
PL/SQL procedure successfully completed.
SQL> SELECT sys.mycontext_pckg.get_value ( 'sesame' ) FROM dual;
SYS.MYCONTEXT_PCKG.GET_VALUE('SESAME') --------------------------------------------------------------------- 123
Пакет можно спроектировать и иначе, закрыв, например, для пользователя имя атрибута или даже контекста. Можно запрограммировать все, что требует логика предметной области.
с СУБД можно использовать так
В каждом сеансе работы с СУБД можно использовать так называемые контексты. Каждый контекст - это именованный набор пар «параметр/значение». Oracle называет каждый конкретный подобный набор пространством имен (namespace), а элементы пространства имен атрибутами, способными принимать значения.
Создаются контексты SQL-предложением CREATE CONTEXT. Из-за этого далее вместо «пространства имен» предпочтение отдается термину «контекст». Параметры контекста («атрибуты») устанавливаются процедурой DBMS_SESSION.SET_CONTEXT, а вот вычитываются в программу стандартной функцией SYS_CONTEXT. Пакет DBMS_SESSION содержит ряд других подпрограмм для работы с контекстами.
Здесь рассматривается лишь формальная сторона контекста сеанса, а способ его применения разработчик может определить сам или почерпнуть из описаний избирательного доступа к данным (FGAC или Label Security) и сервера приложений Oracle.
Использование хранимых шаблонов
, Oracle Certified Professional DBA,
Источник:
,Январь/Февраль 2004

В данной статье описывается один из многих аспектов использования хранимых шаблонов при настройке производительности приложений использующих СУБД Oracle. В частности, приводится пример их использования для настройки приложений, к исходному коду которых, группа сопровождения не имеет доступа. Приводимый пример был испытан в Oracle 9i release 2. Для выполнения SQL выражений использовалась приложение SQL*Plus.
В практике сопровождения довольно часто приходится сталкиваться с задачей настройки производительности приложений, доступ к коду которых не представляется возможным. А производительность приложения сильно страдает из-за нескольких SQL выражений имеющих подсказки оптимизатору (optimizer hints) используя которые оптимизатор выбирает неоптимальный план выполнения SQL выражения. Особенно данная проблема имеет место при переходе организации на новые версии Oracle при использовании уже зарекомендовавших себя с хорошей стороны приложений, к которым все уже привыкли, однако вдруг начавших "жутко тормозить" на новой версии Oracle. Перехватив поток SQL выражений группа ИТ отдела определяет, что причина низкой производительности - подсказки, удалением которых можно добиться восстановления быстродействия. Однако сотрудники ИТ отдела не имеют доступа к исходному коду приложения и поэтому убрать "хинты" не представляется возможным.
Решить подобные проблемы можно используя хранимые шаблоны.
Русскоязычное описание использования хранимых шаблонов для стабилизации плана выполнения SQL выражений хорошо представлено в книге Тома Кайта "Oracle для профессионалов" (Thomas Kyte "Expert One on One: Oracle"), в переводе В. Кравчука, а так же на сайте (http://ln.com.ua/~openxs/projects/oracle/) автора перевода.
Итак, перейдем к примеру. Начнем с постановки задачи. Допустим мы имеем SQL выражение содержащее подсказку /*+ RULE*/. Наша задача - избавиться от этой подсказки.
Подготовим окружение. Создадим таблицу, составной индекс и соберем статистику. Таблица представляет собой некий словарь и содержит список словарей, каждый из которых, содержит некий список сущностей:
dict_id - идентификатор словаря
ItemID - порядковый номер сущности
Name - имя сущности
SQL> create table t1 (
2 dict_id int,
3 itemid int,
4 name varchar2(100)
5 );
Таблица создана.
SQL> create index indx_t1
2 on t1(dict_id, itemid);
Индекс создан.
SQL> analyze table t1 estimate statistics;
Таблица проанализирована.
Включим показ плана выполнения SQL выражений.
SQL> set autotrace on explain
Создадим переменную привязки (bind variable), проинициализируем её и запустим наш оптимизируеммый запрос:
SQL> var itemid number
SQL> begin :itemid:= 0; end;
2 /
Процедура PL/SQL успешно завершена.
SQL> select /*+ rule*/ *
2 from t1
3 where itemid = :itemid;
строки не выбраны
План выполнения
----------------------------------------------------------
0 SELECT STATEMENT Optimizer=HINT: RULE
1 0 TABLE ACCESS (FULL) OF 'T1'
Процедура PL/SQL успешно завершена.
План выполнения показывает полное сканирование таблицы (full table scan, FTS).
Выполним тот же запрос, но "выключив" подсказку (уберем "+"):
SQL> select /* rule*/ *
2 from t1
3 where itemid = :itemid;
строки не выбраны
План выполнения
----------------------------------------------------------
0 SELECT STATEMENT Optimizer=CHOOSE (Cost=2 Card=1 Bytes=78)
1 0 TABLE ACCESS (BY INDEX ROWID) OF 'T1' (Cost=2 Card=1 Bytes=78)
2 1 INDEX (SKIP SCAN) OF 'INDX_T1' (NON-UNIQUE)
План выполнения показывает доступ к данным таблицы посредством индекса 'INDX_T1' . Доступ в пределах индекса осуществляется как INDEX SCIP SCAN ACCESS, впервые представленный в Oracle9i. Исходим из того, что набор данных в таблице таков, что, этот план намного лучше первого. К нему и будем стремится.
Для дальнейшей работы нам потребуются следующие системные привилегии:
create any outline
alter any outline
drop any outline
Выполним следующее:
SQL> alter session set create_stored_outlines = healthy_plans;
Сеанс изменен.
В этом выражении HEALTHY_PLANS - это имя категории, с которой будут связаны наши шаблоны.
Далее, выполним поочередно, два запроса. Первый - "проблемный", тот который мы собираемся оптимизировать(с подсказкой /*+ RULE*/). Второй, тот который мы прооптимизировали, "отключив" подсказку. Однако перед выполнением запросов нам необходимо отключить отображение планов выполнения запросов. Это нужно, чтобы Oracle перехватил, только наши два запроса (иначе будут перехвачены обращения к таблице PLAN_TABLE, содержащей планы выполнения):
SQL> set autotrace off
SQL> select /*+ rule*/ *
2 from t1
3 where itemid = :itemid;
строки не выбраны
SQL>
SQL> select /* rule*/ *
2 from t1
3 where itemid = :itemid;
строки не выбраны
На данном этапе важно отметить, что в отличие от Oracle8i, где сравнение SQL запросов с их аналогами в хранимых шаблонах происходит посимвольно, в Oracle9i оно не имеет столь жесткого критерия. Поэтому, скажем запрос:
select /*+ rule*/ *
from t1
where itemid = :itemid;
с точки зрения использования хранимых шаблонов в Oracle 9i, аналогичен запросу:
select /*+ RULE*/ * from t1 where ItemID = :itemid;
тогда, как в Oracle8i это было бы неверно.
Итак, продолжим.
Отключим автоматическое создание хранимых шаблонов:
SQL> alter session set create_stored_outlines = false;
Сеанс изменен.
Смотрим, что получилось(для удобочитаемости, установим размер буфера отображения LONG полей равным 15):
SQL> set long 15
SQL> select ol_name, sql_text from outln.ol$
2 where category = 'HEALTHY_PLANS';
OL_NAME SQL_TEXT
------------------------------ ---------------
SYS_OUTLINE_031028123825493 select /*+ rule
SYS_OUTLINE_031028123825813 select /* rule*
Полученным шаблонам придадим информативные имена:
SQL> alter outline SYS_OUTLINE_031028123825493 rename to with_plus;
Вариант изменен.
SQL> alter outline SYS_OUTLINE_031028123825813 rename to without_plus;
Вариант изменен.
SQL> select ol_name, sql_text from outln.ol$
2 where category = 'HEALTHY_PLANS';
OL_NAME SQL_TEXT
------------------------------ ----------------------------
WITH_PLUS select /*+ rule
WITHOUT_PLUS select /* rule*
Подсказки хранимых шаблонов находятся в таблице ol$hints схемы OUTLN:
SQL> select ol_name, hint#, hint_text from outln.ol$hints
2 where category = 'HEALTHY_PLANS'
3 order by ol_name desc, hint#;
OL_NAME HINT# HINT_TEXT
------------ ------- -----------------------
WITH_PLUS 1 NO_EXPAND
WITH_PLUS 2 ORDERED
WITH_PLUS 3 NO_FACT(T1)
WITH_PLUS 4 FULL(T1)
WITH_PLUS 5 NOREWRITE
WITH_PLUS 6 NOREWRITE
WITH_PLUS 7 RULE
WITHOUT_PLUS 1 NO_EXPAND
WITHOUT_PLUS 2 ORDERED
WITHOUT_PLUS 3 NO_FACT(T1)
WITHOUT_PLUS 4 INDEX(T1 INDX_T1)
WITHOUT_PLUS 5 NOREWRITE
WITHOUT_PLUS 6 NOREWRITE
13 строк выбрано.
В вышеупомянутых русскоязычных источниках, описываются несколько приемов "обмана" CBO (Cost Based Optimizer), прибегнув к которым мы "заставим" CBO строить нужный нам план. В этой статье я предложу вам еще один подобный прием.
Всё достаточно просто. Что нам нужно? Нам нужно чтобы при выполнении запроса с "хинтом" оптимизатор использовал подсказки из запроса с "отключенным хинтом". Итак, мы просто подменяем подсказки. Делаем это путем изменения имен хранимых шаблонов:
SQL> update outln.ol$
2 set ol_name = 'RIGHT_PLAN'
3 where ol_name = 'WITH_PLUS';
1 строка обновлена.
SQL> update outln.ol$hints
2 set ol_name = 'RIGHT_PLAN'
3 where ol_name = 'WITHOUT_PLUS';
6 строк обновлено.
SQL>
SQL> update outln.ol$hints
2 set ol_name = 'WITHOUT_PLUS'
3 where ol_name = 'WITH_PLUS';
7 строк обновлено.
Ставший ненужным шаблон WITHOUT_PLUS - удаляем (фиксация предыдущих изменений нам не потребуется, т.к. SQL выражение DROP относится к числу изменяющих словарь данных Oracle (Data Definition Language, DDL), что вызывает неявную фиксацию предыдущей транзакции):
SQL> drop outline WITHOUT_PLUS;
Вариант удален.
Вот собственно и всё. Теперь можно проверить наш "проблемный" запрос. Для чистоты эксперимента, посмотрим еще раз на план нашего "проблемного" запроса:
SQL> set autotrace on explain
SQL> select /*+ rule*/ *
2 from t1
3 where itemid = :itemid;
строки не выбраны
План выполнения
----------------------------------------------------------
0 SELECT STATEMENT Optimizer=HINT: RULE
1 0 TABLE ACCESS (FULL) OF 'T1'
Как видим ничего не изменилось, всё тот же FTS. Активируем наш хранимый шаблон:
SQL> alter session set use_stored_outlines=HEALTHY_PLANS;
Сеанс изменен.
И выполним еще раз всё тот же "проблемный" запрос:
SQL> select /*+ rule*/ *
2 from t1
3 where itemid = :itemid;
строки не выбраны
План выполнения
----------------------------------------------------------
0 SELECT STATEMENT Optimizer=HINT: RULE (Cost=2 Card=1 Bytes=78)
1 0 TABLE ACCESS (BY INDEX ROWID) OF 'T1' (Cost=2 Card=1 Bytes=78)
2 1 INDEX (SKIP SCAN) OF 'INDX_T1' (NON-UNIQUE)
Цель достигнута.
Изменив подобным образом все проблемные запросы и активировав соответствующую категорию полученных хранимых шаблонов, можно добиться прежней производительности приложения.
"А что же будет, если мы таким образом подменим план, который был сделан на основе совершенно другой таблицы, либо, скажем, удалим индекс таблицы в существующем примере?" - задаст вопрос проникшийся идеей читатель. Ответ прост - CBO выдаст план, так, как будто бы хранимого шаблона и нет вовсе.
Проводя исследования в данном направлении я наблюдал интересный момент. Вот что я сделал. Я удалил индекс в таблице t1. Проверил реакцию CBO, он проигнорировал хранимый шаблон (как я уже говорил). Вновь создал индекс с тем же именем и на те же поля. И вот тут самое интерестное! Т. к. я не пересобирал статистику на таблицу после создания индекса, то выполнение запроса "без плюсика", привело к FTS, а выполнение нашего "проблемного" запроса, показало прекрасный план, взятый CBO из нашего шаблона. Вот такие дела :). Не забывайте собирать статистику!
Безопасный способ
Кажется, есть только один способ сгенерировать хранимый шаблон, использование которого в длительной перспективе не сопряжено с риском-- надо быть как можно честнее. Генерировать шаблон нужно в той же схеме и для тех же объектов.
В нашем случае, надо удалить индекс по первичному ключу, сгенерировать план, а затем заменить первичный ключ!
Конечно, вы можете и не захотеть делать это в производственной системе, а если и захотите, может оказаться, что шаблон начнет использовать полный просмотр таблицы.
В итоге, чтобы получить требуемый шаблон необходимо иметь запасную копию схемы (с тем же именем и структурой) в другой базе данных и очень осторожно манипулировать объектами в этой схеме. После получения необходимого шаблона, можно экспортировать его из этой базы данных и импортировать в другую.
Например: в запасной базе данных вполне можно будет удалить первичный ключ, чтобы избежать сканирования (unique scan) соответствующего индекса. Если после этого сервер Oracle не начнет использовать другой индекс автоматически, можно всеми возможными способами обманывать его, например:
Изменить режим оптимизации на first_rows.
Создать данные, уникальные по столбцу N1. (Не создавайте, однако, по нему уникальный индекс, иначе в сгенерированном шаблоне будет указано действие unique scan вместо range scan).
Используйте средства пакета dbms_stats чтобы сказать, что индекс имеет фантакстическую степень кластеризации (clustering_factor).
Используйте параметр optimiser_index_caching чтобы сказать, что индекс на 100% кэширован.
Используйте параметр optimiser_index_cost_adj чтобы сказать, что чтение по несколько блоков (multiblock read) в 100 раз медленнее, чем чтение по одному блоку (single block read).
Используйте средства пакета dbms_stats чтобы задать те же утверждения через таблицу aux_stats$, и добавте также утверждение, что обычно при чтении нескольких блоков читается только два блока.
Пересоздайте индекс так, чтобы он включал оба столбца, заданные в конструкции where.
С учетом текущей струтуры таблиц, в которых хранятся шаблоны, подойдет практически любой способ, если не меняется владелец таблицы, тип объекта и уникальность (или неуникальность) индексов. Если вы можете создать набор данных и среду, которые дают требуемый шаблон без внутренних несогласованностей в производственной системе, то, какие именно трюки при этом использовались, уже не важно.
системы для получения необходимого хранимого
Джонатан Льюис,
Перевод
В я рассматривал хранимые шаблоны и описал один механизм "обмана" системы для получения необходимого хранимого шаблона. Я также подчеркнул, что использование этого метода в Oracle 9 сопряжено с определенным риском, поскольку детальность представления информации существенно возросла. В данной статье, продолжающей ту же тему, я представлю законный способ манипулирования ххранимыми шаблонами, который можно использовать как в Oracle 8, так и в Oracle 9. Фактически эта статья основана на экспериментах, проводившихся в стандартно установленных версиях Oracle 8.1.7.0 и Oracle 9.2.0.1.
Изменения
Если подключиться к схеме outln (которая по умолчанию в Oracle 9 заблокирована) и посмотреть список имеющихся таблиц, окажется, что в Oracle 9 добавлена одна таблица. В схему входят следующие таблицы:
ol$ - SQL-операторы ol$hints - подсказки ol$nodes - блоки запроса
Третья таблица - новая; она используется для привязки списка подсказок к различным блокам во (внутренне переписанной) версии SQL-запроса. Также можно обнаружить, что список подсказок (ol$hints) дополнен подпробностями о длине и смещении фрагментов текста.
Столбцы всех трех таблиц представлены на рис. 2, причем, новые столбцы, появившиеся в версии Oracle 9, помечены звездочками.
ol$
OL_NAME VARCHAR2(30) SQL_TEXT LONG TEXTLEN NUMBER SIGNATURE RAW(16) HASH_VALUE NUMBER HASH_VALUE2 NUMBER *** CATEGORY VARCHAR2(30) VERSION VARCHAR2(64) CREATOR VARCHAR2(30) TIMESTAMP DATE FLAGS NUMBER HINTCOUNT NUMBER SPARE1 NUMBER *** SPARE2 VARCHAR2(1000) ***
ol$hints
OL_NAME VARCHAR2(30) HINT# NUMBER CATEGORY VARCHAR2(30) HINT_TYPE NUMBER HINT_TEXT VARCHAR2(512) STAGE# NUMBER NODE# NUMBER TABLE_NAME VARCHAR2(30) TABLE_TIN NUMBER TABLE_POS NUMBER REF_ID NUMBER *** USER_TABLE_NAME VARCHAR2(64) *** COST FLOAT(126) *** CARDINALITY FLOAT(126) *** BYTES FLOAT(126) *** HINT_TEXTOFF NUMBER *** HINT_TEXTLEN NUMBER *** JOIN_PRED VARCHAR2(2000) *** SPARE1 NUMBER *** SPARE2 NUMBER ***
ol$nodes (новая таблица в версии 9)
OL_NAME VARCHAR2(30) CATEGORY VARCHAR2(30) NODE_ID NUMBER PARENT_ID NUMBER NODE_TYPE NUMBER NODE_TEXTLEN NUMBER NODE_TEXTOFF NUMBER
Рис. 2. Таблицы в схеме outln.
Пара нюансов бросается в глаза сразу -- представления, созданные на базе этих таблиц, не включают массу полезной информации. Хотя в таблице ol$hints и появилось 10 новых столбцов, определение представления user_outline_hints не изменилось. Фактически, это представление и в Oracle 8 было слишком урезанным, не включая, в частности, весьма информативный столбец hint#.
Обратите также внимание, что в Oracle 9 теперь есть два столбца hash_value. Если задать два одинаковых оператора на серверах Oracle 8 и Oracle 9, окажется, что значения в столбце hash_value для них совпадают, но вот добавленный в Oracle 9 столбец hash_value2, скорее всего, имеет совсем другое значение.
Также можно обнаружить, что сигнатура (значение столбца signature) в Oracle 9 отличается от соответствующего значения в Oracle 8. Это связано с принципиальным стратегическим изменением в новой версии, направленным на повышение вероятности использования хранимых шаблонов. В Oracle 8 хранимый шаблон использовался только если SQL-оператор совпадал с оператором в шаблоне буквально, с точностью до пробела, регистра символов и перевода строки. В Oracle 9 правила совпадения ослаблены, так что тексты операторов сравниваются после удаления повторяющихся "пробельных символов" и приведения текста к одному регистру. Например, следующие два оператора будут использовать один и тот же шаблон.
select * from t1 where id = 5;
SELECT * FROM T1 WHERE ID = 5;
Это стратегическое изменение привело к изменению сигнатуры для SQL-оператора, для которого первоначально генерируется план. Поэтому при переводе базы данных с сервера Oracle 8 на Oracle 9 придется перегенерировать хранимые шаблоны, - иначе может оказаться, что они более не используются. (На самом деле, пакет outln_pkg с псевдонимом dbms_outln включает специальную процедуру update_signatures
для решения этой проблемы).
Самое же существенное изменение в таблицах версии 9, однако, состоит в намного более детальном описании текста запроса и объектов, которые он затрагивает. Прежде чем читать дальше, выполните операторы в примере, представленном на рис. 3, и просмотрите содержимое таблицы ol$hints.
drop table t1;
create table t1 nologging as select rownum id, rownum n1, object_name, rpad('x',500) padding from all_objects where rownum <= 100;
alter table t1 add constraint t1_pk primary key (id);
create index t1_i1 on t1(n1);
analyze table t1 compute statistics;
create or replace outline demo_1 on select * from t1 where id = 5 and n1 = 10;
Рис. 3. Код примера.
В примере используется небольшая, простая таблица с двумя идентичными столбцами, для одного из которых задано ограничение первичного ключа (и, соответственно, создан уникальный индекс), а по другому - создан обычный, не уникальный индекс. Мы генерируем хранимый шаблон для типичного запроса, а затем посмотрим, что с ним можно будет сделать.
Если выполнить запросы, представленные на рис. 1, к плану demo_1, сгенерированному этим примером, можно обнаружить, что с ним связано шесть следующих подсказок:
STAGE NODE HINT 3 1 NO_EXPAND 3 1 ORDERED 3 1 NO_FACT(T1) 3 1 INDEX(T1 T1_PK) 2 1 NOREWRITE 1 1 NOREWRITE
Как и ожидалось, четвертая строка показывает, что для доступа к таблице используется индекс по первичному ключу (T1_Pk). Но что нам делать с этим хранимым шаблоном, если на самом деле необходимо, чтобы сервер Oracle использовал не уникальный индекс T1_I1? В идеале хотелось бы изменить этот хранимый шаблон так, чтобы строка:
3 1 INDEX(T1 T1_PK)
была заменена строкой:
3 1 INDEX(T1 T1_I1)
Новые возможности
Прежде всего, можно обратить внимание на пакет dbms_outln_edit. Он появился в Oracle 9 и, как следует из его имени, предназначен для редактирования хранимых шаблонов, что выглядит многообещающе.
Однако при просмотре описания пакета и чтении руководств оказывается, что в пакет входят только следующие процедуры, связанные с "редактированием":
CREATE_EDIT_TABLES DROP_EDIT_TABLES CHANGE_JOIN_POS
Первые две процедуры позволяют создавать и удалять локальные копии таблиц, обычно находящихся в схеме outln. Третья позволяет изменять порядок соединения таблиц в сохраненном плане. Нет ни одной процедуры, позволяющей просто изменить одну подсказку. В настоящее время этот пакет кажется практически бесполезным, но он со временем, несомненно, станет более "продвинутым".
Запасной вариант, конечно же, связан с непосредственным изменением таблиц! Если подключиться от имени пользователя outln и изучить содержимое таблицы ol$hints (на базе которой построено представление user_outline_hints), можно попытаться выполнить следующее изменение:
update ol$hintsset hint_text = 'INDEX(T1 T1_I1)' where ol_name = 'demo_1' and hint# = 4;
Снова подключившись к тестовой схеме, сбросив содержимое разделяемого пула и включив использование хранимых шаблонов:
connect test_user/test alter system flush shared_pool; alter session set use_stored_outline=true;
можно убедиться, что измененный таким образом план, действительно, работает как требовалось. Но это решение не идеально, если учесть обычные строгие предупреждения о возможных последствиях "непосредственного изменения словаря данных".
Обзор
Что делать, если известно, как существенно ускорить работу оператора ЯМД, добавив несколько подсказок, но нет доступа к исходному коду, в котором можно было бы вставить эти подсказки?
В предыдущей статье я показал, как можно воспользоваться для этого средствами создания хранимых шаблонов (или стабилизацией плана оптимизатора) сервера.
Хранимый шаблон состоит (грубо говоря) из двух компонентов- SQL-оператора, выполнение которого необходимо контролировать, и списка подсказок, которые сервер Oracle должен применять при каждой оптимизации этого оператора. Оба компонента хранятся в базе данных в схеме outln.
Можно просмотреть список хранимых SQL-операторов м подсказок, которые с ними связаны, с помощью пары запросов, представленных на рис. 1.
select name, used, sql_text from user_outlines where category = 'DEFAULT';
select stage, node, hint from user_outline_hints where name = '{одно из имен}';
Рис. 1. Просмотр хранимых шаблонов.
В предыдущей статье я изложил идею, как "обойти" систему путем создания хранимого шаблона законными методами, а затем - изменения таблиц в схеме outln с помощью пары SQL-операторов, заменяющих полученный результат на данные хранимого шаблона, созданного для аналогичного оператора, но с необходимыми подсказками.
Там же я указал, что этот метод был вполне безопасен в Oracle 8, но может привести к проблемам в Oracle 9 в связи с изменениями в новой версии.
В данной статье рассматриваются эти изменения и описывается законный способ регистрации необходимого набора подсказок для проблемных запросов в таблицах outln.
Ссылки
Oracle 9i Release 2: Database Performance Tuning Guide and Reference -- .
Oracle 9i Release 2: Supplied PL/SQL Packages and Types Reference -- Главы - .
--
Джонатан Льюис () - независимый консультант с более чем 17-летним опытом использования Oracle. Он специализируется на физическом проектировании баз данных и стратегии использования сервера Ortacle. Джонатан - автор книги "Practical Oracle 8i - Designing Efficient Databases", опубликованной издательством Addison-Wesley и один из наиболее известных лекторов среди специалистов по Oracle в Великобритании. Подробнее о его публикациях, презентациях и семинарах можно узнать на сайте , где также находится список ЧаВО The Co-operative Oracle Users' FAQ
по дискуссионным группам Usenet, связанным с СУБД Oracle.
Эта первоначально была опубликована на сайте , сетевом портале, посвященном проблемам различных СУБД и их решениям. Перевод публикуется с разрешения автора.
Старые методы (1)
Наша цель, таким образом, - найти действенный, но достаточно безопасный метод изменения содержимого таблиц шаблонов, не связанный с непосредственным изменением их данных с помощью SQL-операторов.
Исторически (до версии 9) это можно было сделать несколькими способами, основанными на том факте, что содержимое шаблона зависело исключительно от текста выполняемого SQL-оператора, а не от типа или принадлежности упоминаемых в нем объектов.
Первый способ (первоначально описанный, насколько я знаю, Томом Кайтом в его книге "Expert One on One: Oracle") ("Oracle для профессионалов" в моем переводе на русский - прим. переводчика) связан с заменой таблиц представлениями, содержащими необходимые подсказки.
Подключаемся к другой схеме, имеющей доступ к таблице T1, и создаем представление с подсказками с тем же именем, что и исходная таблица:
Create or replace view t1 as Select /*+ index(t1,t1_i1) */ * from test_user.t1;
После создания этого представления, используем эту схему для "перекомпиляции" существующего шаблона с помощью команды:
alter outline demo_1 rebuild;
Учтите, что для успешного выполнения этой команды необходима привилегия alter any outline.
Если вернуться в исходную схему, сбросить содержимое разделяемого пула и включить использование хранимых шаблонов, окажется, что исходный запрос теперь использует индекс T1_I1, что и требовалось.
Почему этот способ работает? Потому что хранимые шаблоны не принадлежат никакой схеме. При пересоздании шаблона по имени demo_1 в новой схеме, имя T1 обозначает локальное представление, содержащее подсказку, поэтому сервер Oracle учитывает эту подсказку в реальном плане выполнения, и, следовательно, в шаблоне. Если обратиться к представлению user_outline_hints, можно обнаружить, что критическая строка действительно имеет вид:
3 1 INDEX(T1 T1_I1)
К сожалению, можно также заметить, что теперь в представлении есть три строки вида:
2 1 NOREWRITE 1 2 NOREWRITE 1 1 NOREWRITE
Первоначально таких строк было только две:
2 1 NOREWRITE 1 1 NOREWRITE
Мы также добавили подсказку, применяющуюся для 'Stage 1, Node 2' ("Стадия 1, Пункт 2"). Я не берусь утверждать, что точно знаю, что это означает, но это должно быть связано с тем, что при анализе и оптимизации запроса из другой схемы сервер Oracle выполнил дополнительный шаг, преобразуя ссылку на представление в ссылку на базовую таблицу.
Хотя пока что это не мешает правильному применению полученного шаблона (по крайней мере, в этом простом случае), кто знает, насколько может измениться в этом отношении сервер Oracle в следующих версиях.
Поскольку использование представлений приводит к аномалии, которая в будущих версиях может обернуться ошибкой, надо использовать более четкое решение. Давайте попробуем выполнить следующее:
Создадим новую схему.
Создадим таблицу T1 в этой схеме.
Создадим ТОЛЬКО индекс T1_I1.
Перестроим шаблон в этой схеме.
Если сравнить содержимое представления user_outline_hints для нашего шаблона до и после перестройки (для этого необходимо будет снова подключиться к исходной схеме), окажется, что они идентичны за исключением той единственной строки, которую мы хотели изменить. Снова подключившись к исходной схеме и, как обычно, сбросив разделяемый пул и включив использование шаблонов, мы увидим, что измененный шаблон успешно используется.
Однако в этом методе есть и скрытая проблема, на этот раз, немного более тонкая. Возвращаясь к рис. 2, на котором представлены определения новых столбцов, появившихся в Oracle 9, - как вы думаете, какая информация содержится в столбце user_table_name? Там хранится уточненное имя таблицы; т.е.:
{имя_пользователя}.{имя_таблицы}
В нашем случае это позволит серверу Oracle понять, что таблица T1, фактически, принадлежит новой схеме, а не исходной. Хотя сервер Oracle и использует полученный хранимый шаблон, информации в таблице достаточно, чтобы он мог понять, что план применяется не для того объекта.
Опять-таки, сейчас этот метод работает, но зачем эта информация вообще сохраняется -- видимо, в связи с планируемыми изменениями в будущих версиях.
в Oracle 9, намного более
Информация, записываемая в хранимый шаблон в Oracle 9, намного более "уязвима", чем в Oracle 8. Раньше "изменять" шаблоны было сравнительно просто и безопасно. Прежние методы работают, но большой объем дополнительной информации, собираемой в Oracle 9, позволяет предположить, что в будущем их использование сопряжено с риском.
Хотя в Oracle 9 и появился пакет для редактирования хранимых шаблонов, сейчас с его помощью можно только поменять порядок просмотра таблиц. При отсуствии второй системы с измененными индексами, средой и "поддельной" статистической информацией менять хранимые шаблоны стало небезопасно.
Интерфейс Siebel => Oracle Server => Express Server
, старший консультант отдела бизнес-анализа и хранилищ данных, Консалтинговая группа "Борлас" (Москва)
Источник:

Долгое время Oracle Express, семейство OLAP-продуктов от Oracle, было лидером в области многомерных баз данных. Кроме стандартных средств OLAP-сервера (Express Server) оно обладает рядом важных и отличительных особенностей, таких как модели, формулы и, самое главное, собственным языком программирования - Express Language, а также рядом инструментов для их использования. В целом, для своего времени прикладные аналитические системы на Oracle Express работали достаточно быстро и эффективно. Одним из самих успешных из них стал продукт Oracle Financial Analyzer (OFA), предназначенный для формирования финансовой отчетности, проведения детального финансового анализа, ведения бюджета, финансового планирования и прогнозирования. Этот продукт получил широкое применение, в частности OFA был включен в состав финансовых модулей семейства Oracle E-Business Suite, и легко интегрировался с ними. В 2000 году корпорацией Oracle было принято решение о "переносе" Express Server в состав реляционной СУБД Oracle 9i, и таким образом в ней появилась OLAP Option. Вместо OFA, для работы в среде этой опции было предложено новое финансовое приложение - Oracle Enterprise Budgeting & Planning (EPB). Но и по сей день OFA (и другие аналитические приложения для среды Oracle Express) продолжают использоваться во многих компаниях.
Многие компании на сегодняшний день используют BI-приложения для сбора и анализа корпоративной информации, хранящийся в различных источниках. Для получения единого взгляда на всю информацию предприятия необходимо создание единой модели ее представления. Несомненно, Express Server и OFA являются важным компонентом в общей модели данных.
Один из клиентов компании "Борлас" решил внедрить у себя систему корпоративной отчетности на основе Oracle Business Intelligence Enterprise Edition. Среди множества всех источников, которые использовались для построения единой модели данных в компании была система бюджетирования OFA. Таким образом, пред нами встала задача интеграции OFA и Oracle BI Suite EE. Поскольку OFA является, по сути, надстройкой над Express Server, мы стали решать общую задачу интеграции Express Server и Oracle BI Suite EE.
Пример использования
Рассмотрим пример построения отчета в Oracle BI Suite EE на основе тестовой базы данных, которая поставляется с Oracle Express - demo.db. Возьмем куб - SALES, построенный по трем измерениям: MONTH, PRODUCT, DISTRICT. В представленных ниже листингах отсутствует Java-код для шлюзового RMI-сервера, RMI-клиента, поскольку они достаточно большие и сложные.
Создадим для него соответствующие структуры в СУБД Oracle:
----------------------------------------------- -- Спецификация объектного типа для ячейки куба ----------------------------------------------- create or replace type t_sales_row as object ( sales number, month date, product varchar2(30), district varchar2(30) ); ----------------------------------------------- -- Спецификация табличного типа ----------------------------------------------- create or replace type t_sales_table as table of t_sales_row;
Для построения конвейерной табличной функции необходимо создать соответствующий тип, который реализовывал бы интерфейс ODCITable ----------------------------------------------- -- ODCITable тип ----------------------------------------------- create or replace type t_sales_rowset as object ( key integer,
-- Статическая функция, необходимая для создания контекста -- query - эапрос в Express static function ODCITableStart(sctx out t_sales_rowset, query varchar2) return number as language java name 'SalesRowset.ODCITableStart( oracle.sql.STRUCT[], java.lang.String) return java.math.BigDecimal',
-- Метод экземпляра, необходимый для получения очередной порции выборки
member function ODCITableFetch(self in out t_sales_rowset, nrows in number, outset out t_sales_table) return number as language java name 'SalesRowset.ODCITableFetch( java.math.BigDecimal, oracle.sql.ARRAY[]) return java.math.BigDecimal',
-- Метод экхемпляра, необходимый для закрытия контекста
member function ODCITableClose(self in t_sales_rowset) return number as language java name 'SalesRowset.ODCITableClose() return java.math.BigDecimal' );
Теперь нам надо создать Java пакет SalesRowset опишем только основные методы, которые необходимы для работы ODCITable типа.
Первая функция ODCITableStart, необходимая для создания контекста и открытия курсора. Для нее входящим параметром будет Express запрос.
static public BigDecimal ODCITableStart(STRUCT[] sctx, String query) throws SQLException { // Соединение текущей сессии Connection conn = new OracleDriver().defaultConnection(); // Создаем контекст запроса, StoredCtx - произвольный класс, его определяем мы сами StoredCtx ctx = new StoredCtx(query); int key; try { // Создаем ключ для нашего контекста key = ContextManager.setContext(ctx); } catch (CountException ce) { return ERROR; } Object[] impAttr = new Object[1]; impAttr[0] = new BigDecimal(key); // Создаем дескриптор для нашего ODCITable типа в базе StructDescriptor rowset = StructDescriptor.createDescriptor("T_SALES_ROWSET", conn); // Заполняем тип
sctx[0] = new STRUCT(rowset, conn, impAttr); : // Далее мы обращаемся к RMI серверу и отправляем запрос Express : return SUCCESS; }
Вторая функция ODCITableFetch необходима для получения новой порции данных из выборки. Для нее входящим параметром будет Express запрос.
public BigDecimal ODCITableFetch(BigDecimal nrows, ARRAY[] outSet) throws SQLException { StoredCtx ctx; try { // Получаем контекст по ключу ctx = (StoredCtx) ContextManager.getContext(key.intValue()); } catch (InvalidKeyException ik) { return ERROR; } Connection conn = new OracleDriver().defaultConnection(); try { ArrayList list = _srv.fetchQuery(ctx.nQueryId, nrowsval);
StructDescriptor cube_row = StructDescriptor. createDescriptor("T_SALES_ROW", conn); ArrayDescriptor cube_table = ArrayDescriptor. createDescriptor("T_SALES_TABLE",conn); ArrayList list = null; : // Получаем в list через обращение к RMI серверу очередную порцию выборки // Пусть она возвращается в виде // { SALES, MONTH , PRODUCT, DISTRICT}, соответствующим типу t_sales_row
:
Object[] table = new Object[list.size()]; int i = 0; // Проходим по всему массиву и заполняем структуру for (Iterator it = list.iterator(); it.hasNext();) { table[i++] = new STRUCT(_cube_row, _conn, (Object[]) it.next()); } // Создаем массив из структуру outSet[0] = new ARRAY(cube_table, conn, table); table = null; list.clear(); list = null; return SUCCESS;
} catch (Exception e) { e.printStackTrace(); System.out.println(e.toString()); } }
Последняя функция ODCITableClose необходима для закрытия курсора и контекста. public BigDecimal ODCITableClose() throws SQLException { StoredCtx ctx; try { ctx = (StoredCtx) ContextManager.clearContext(key.intValue()); } catch (InvalidKeyException ik) { return ERROR; } : // Обращаемся к RMI серверу и закрываем курсор к Express :
ctx = null; return SUCCESS; }
Теперь можно создать конвейерную табличную функцию, для которой тип T_SALES_ROWSET будет реализующим ее. ---------------------------------------------- -- Конвейерная функция на основе t_sales_rowset ----------------------------------------------- create or replace function getExpressSales(query varchar2) return t_sales_table pipelined using t_sales_rowset;
Теперь для того, чтобы создать представление в СУБД на основе этой функции, нам надо сформировать запрос к Express Server. Для создания SNAPI запросов мы создали специальное приложение Express SNAPI Query Builder, с помощью которого мы соединяемся с Express и строим с помощью стандартного Express мастера запрос.
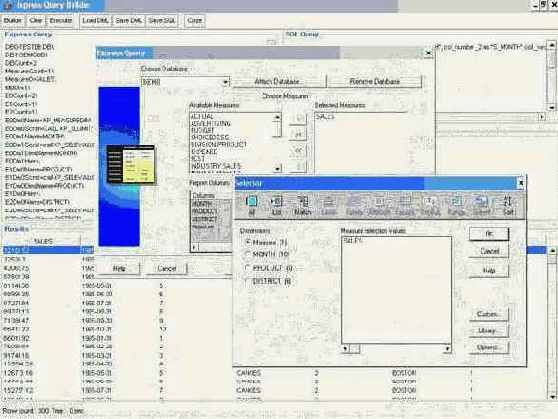
В итоге получаем запрос к Express Server в следующем виде:
DB0=DEMO.DB\ DBCount=1\ MeasureCount=1\ Measure0=SALES\ E0Count=2\ E1Count=1\ E2Count=1\ E0Dim0Name=XP_MEASUREDIM\ E0Dim0Script=CALL XP_SLLIMIT('XP_MEASUREDIM', 'CUBE','SALES')\ E0Dim1Name=MONTH\ E0Dim1Script=call XP_SELEVALUATE( 'MONTH', NA )\ E0Dim1DimLName=MONTH\ E0Dim1Hier=\ E1Dim0Name=PRODUCT\ E1Dim0Script=call XP_SELEVALUATE( 'PRODUCT', NA )\ E1Dim0DimLName=PRODUCT\ E1Dim0Hier=\ E2Dim0Name=DISTRICT\ E2Dim0Script=call XP_SELEVALUATE( 'DISTRICT', NA )\ E2Dim0DimLName=DISTRICT\ E2Dim0Hier=\ QL=1\
Создаем на его основе представление ---------------------------------------------- -- Представление для SALES ----------------------------------------------- create or replace view v_express_sales as select * from table(getExpressSales('DB0=DEMO.DB\ DBCount=1\MeasureCount=1\Measure0=SALES\E0Count=2\E1Count=1\E2Count=1\E0Dim0Name=XP_MEASUREDIM\ E0Dim0Script=CALL XP_SLLIMIT(''XP_MEASUREDIM'', ''CUBE'',''SALES'')\E0Dim1Name=MONTH\ E0Dim1Script=call XP_SELEVALUATE( ''MONTH'', NA )\E0Dim1DimLName=MONTH\ E0Dim1Hier=\E1Dim0Name=PRODUCT\E1Dim0Script=call XP_SELEVALUATE( ''PRODUCT'', NA )\ E1Dim0DimLName=PRODUCT\E1Dim0Hier=\ E2Dim0Name=DISTRICT\E2Dim0Script=call XP_SELEVALUATE( ''DISTRICT'', NA )\ E2Dim0DimLName=DISTRICT\E2Dim0Hier=\QL=1\'));
Результат запроса
select * from v_express_sales;
SALES MONTH PRODUCT DISTRICT ---------- ----------- ------------------------- ------------------------- 32153,52 31.01.1995 TENTS BOSTON 32536,3 28.02.1995 TENTS BOSTON 43062,75 31.03.1995 TENTS BOSTON 57608,39 30.04.1995 TENTS BOSTON 81149,36 31.05.1995 TENTS BOSTON 88996,35 30.06.1995 TENTS BOSTON 87273,84 31.07.1995 TENTS BOSTON 89379,13 31.08.1995 TENTS BOSTON 71388,47 30.09.1995 TENTS BOSTON 66412,33 31.10.1995 TENTS BOSTON 66013,92 31.01.1995 CANOES BOSTON 76083,84 28.02.1995 CANOES BOSTON 91748,16 31.03.1995 CANOES BOSTON 125594,28 30.04.1995 CANOES BOSTON 126713,16 31.05.1995 CANOES BOSTON 147412,44 30.06.1995 CANOES BOSTON 152727,12 31.07.1995 CANOES BOSTON 126433,44 31.08.1995 CANOES BOSTON 122797,08 30.09.1995 CANOES BOSTON
87272,64 31.10.1995 CANOES BOSTON
Создадим отчет в Oracle BI EE Answers с помощью Direct Request.
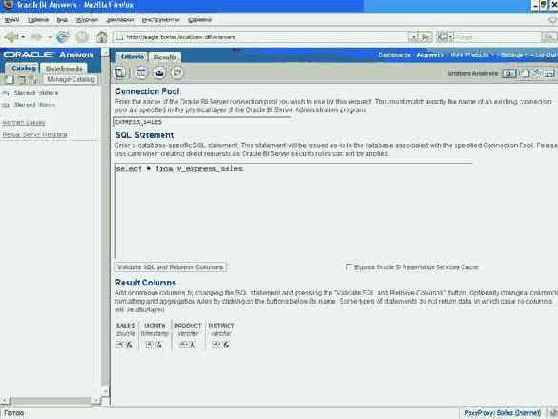
Представим результаты запроса в виде кросс-таблицы

Реализация интерфейса Oracle Server => Express Server
На сегодняшний день Oracle предлагает две аналитические платформы: Standard Edition, бывший Oracle Business Intelligence 10g, и Enterprise Edition, интегрированная платформа для реализации различных методов анализа данных, основанная на платформе Siebel Analytics. Кроме того, существует редакция Oracle Business Intelligence Standard Edition One являющаяся сокращенной версией Enterprise Edition для среднего и малого бизнеса.
Oracle BI Suite Standard Edition состоит из двух основных компонентов:
Oracle Discoverer и Oracle Reports.
Oracle Discoverer позволяет строить произвольные отчеты и формировать нерегламентированные запросы. Он легко интегрируется с СУБД Oracle, в том числе с опцией OLAP. Однако он не имеет никаких адаптеров к Express Server и поэтому не может работать с ним. С другой стороны Oracle Reports, компонент для создания и публикации стандартных регламентированных отчетов, предоставляет доступ к различным источникам данных (SQL, PL/SQL, JDBC, XML-файлы и др.), включая готовый адаптер к Express Server.
Oracle BI Suite Enterprise Edition состоит из набора различных компонентов. В основе лежит Oracle BI Server - сервер, обеспечивающий доступ к источникам данных и представляющий их в виде единой модели данных. Он имеет открытый и расширяемый набор адаптеров, отвечающих за связь с источниками данных. Были созданы индивидуальные адаптеры к различным системам, включая реляционные СУБД (Oracle, DB2, SQL Server, Teradata, Informix и др.), корпоративные приложения (OEBS, Peoplesoft, JD Edwards, SAP R/3, mySAP), OLAP-источники (Oracle OLAP, Microsoft Analysis, SAP BW, Hyperion), XML-источники. Однако адаптеров к Oracle Express не было создано.
Семейство программных продуктов Oracle Express состоит из сервера многомерных баз данных (Express Server, Personal Express), инструментов для администрирования (Express Administrator), инструментальные средства для разработки сложных интегрированных клиентских приложений (Express Analyzer, Express Objects), средства для публикации данных в Интернете (Web Publisher) и многое другое. На рисунке 1 приведена архитектура семейства Oracle Express.
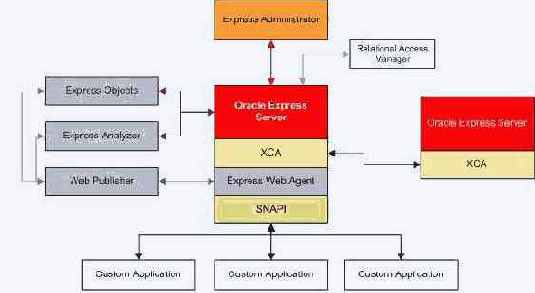
Рис. 1 Архитектура семейства Oracle Express.
В состав семейства продуктов Oracle Express включены следующие интерфейсы:
XCA (eXpress Communications Architecture) - протокол, позволяющий двум Express-системам обмениваться данными; EWA (Express Web Agent) - средство для создания приложений, работа с которыми осуществляется через Web-браузер, обеспечивающий работу с таблицами. Набор хранимых процедур Web Agent Developer's Toolkit обеспечивает базовую архитектуру для построения развитых Web-приложений;
SNAPI (Structured N-dimensional Application Programming Interface) - протокол для работы с многомерной базой данных Express. Представляет собой набор функций и переменных реализованных на языке "C" и помещенный в DLL-библиотеки, позволяющий писать свои собственные приложения.
Следует отметить, что клиентские приложения Express Analyzer, Express Objects, Web Publisher используют в своей работе XCA и/или SNAPI. XCA является закрытым протоколом для внутренней работы самого сервера базы данных и для наших целей не подходит. EWA - это дополнение к Express Server, основной функцией которого является построение данных в Web формате. На рисунке 2 показана схема работы EWA.
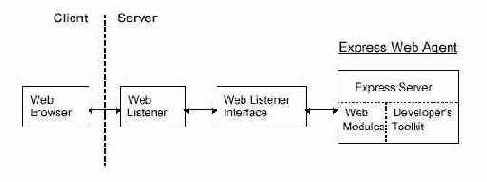
Рис. 2. Cхема работы Express Web Agent
Таким образом, на роль интерфейса доступа к Express из внешних систем и, в частности, Oracle Server подходит только SNAPI.
Поскольку Oracle BI Suite EE может работать с любым ODBC-источником, самым простым решением поставленной задачи было бы создание собственного ODBC-драйвера. Для этого можно воспользоваться готовыми коммерческими библиотеками (Software Developer Kit) для написания ODBC-драйверов. Мы сделали простой ODBC-драйвер на базе SimbaEngine SDK от компании Simba Technologies. При реализации базовых методов мы столкнулись со следующими трудностями:
представление многомерных данных в "плоском" реляционном виде; преобразование SQL-запросов в многомерные запросы Express; поддержка агрегатных функций SQL и сложных преобразований и многое другое.
Поскольку задача требовала достаточно быстрого и надежного решения и, кроме того, написание собственного драйвера было сопряжено со многими рисками, мы решили проработать другие варианты решения.
Oracle BI Suite EE предоставляет интеграцию с множеством продуктов от Oracle, включая всестороннюю поддержку СУБД Oracle Database 10g. Таким образом, если мы бы могли представить данные из Express как таблицы Oracle, то задача была бы решена. Для этого нам требовалось опубликовать Express-кубы в виде представлений (view) на основе табличных функций (table function), которые получали данные из Express Server. Поскольку в состав Oracle Reports входит адаптер к Express Server, мы решили воспользоваться им. Адаптер реализован на Java c использованием технологии Oracle Reports Pluggable Data Source (PDS), позволяющей подключать к Oracle Reports произвольные источники данных. PDS - набор интерфейсов на Java (API). Он описан в Oracle Reports Java API Reference. В состав Oracle Reports входят готовые PDS-адаптеры к XML файлам, JDBC источникам и самое главное к Express Server.
Схема работы PDS-адаптеров к Express Server приведены на рисунке 3.

Рис. 3. Схема работы PDS-адаптеров к Express Server
SNAPI драйвер к Express Server представляет собой библиотеку на языке "C". Для того, чтобы можно было воспользоваться методами этого драйвера в Java, Oracle предложил специальную библиотеку Express Java (XRJ - eXpRess Java), которая является своеобразным мостиком между "натуральным" (компилированным в бинарный код) SNAPI-драйвером и современным Java-драйвером. Библиотека XRJ подключается в Java-пакете Express PDS и осуществляет все взаимодействие с SNAPI-драйвером. Далее будем обозначать как SNAPI/XRJ-драйвер связку из SNAPI-драйвера и XRJ-библиотеки. Аналогичная связка работает и еще в одном продукте Express Spreadsheet Add-In.
Публикация данных из Express Server как представлений в базе данных позволяла решить не только конкретную задачу реализации интерфейса Oracle BI Suite EE и Express Server, но позволяла включить Express Server в общую информационную среду через СУБД Oracle. Кроме того, такой подход оказался простым, эффективным и технологичным, поскольку всей обработкой занималась СУБД Oracle. Благодаря серьезной поддержке Java и широким возможностям самой СУБД Oracle, которая позволяют создавать конвейерные табличные функции на Java, решение задачи построения интерфейса Express Server - Oracle Server оказалось очень изящным.
Рассмотрим более подробно предлагаемое решение, построенное на следующих базовых продуктах: Oracle Express Server 6.4, Oracle Database 10g, Oracle Express PDS 10g.
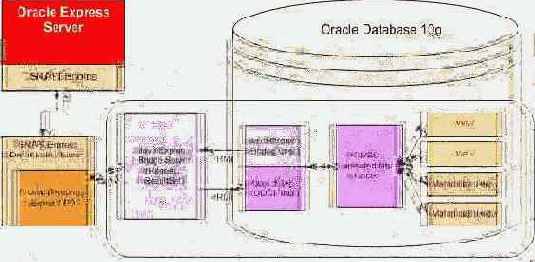
Рис. 4.
Как и в Oracle Reports, в основе решения лежит: SNAPI-драйвер, предоставляющий доступ к базам данным Express Server и специальная XRJ-библиотека, предоставляющая к нему Java-интерфейс. XRJ-библиотека имеет свой собственный синтаксис запросов, (похожий на синтаксис конфигурационных файлов), в котором указывается база данных Express Server, показатели, измерения, иерархии, ограничения на измерения и многое другое. Для построения таких запросов нами было сделано специальное приложение Express SNAPI Query Builder, использующее схожие с Express мастера построения запросов и селектор. С помощью этого приложения можно легко получать запросы к Express в формате XRJ-библиотеки.
Начиная с версии 8i в СУБД Oracle включена полноценная Java-машина, Oracle JVM. На сегодняшний день СУБД Oracle позволяет создавать, хранить и выполнять Java-приложения внутри себя. Кроме того, важным является то, что PL/SQL и Java код могут спокойно сосуществовать вместе в одном приложении. Однако СУБД Oracle запрещает использование JNI (стандартный интерфейс программирования для написания "натуральных", т.е. компилирующихся в бинарный код целевой операционной системы, методов) Несмотря на то, что использование JNI в большинстве случаев ведет к потере многоплатформенности Java-кода, данная возможность расширяет сферу применения самого языка Java на приложения, для которых это условие не является необходимым. В таких системах использование JNI позволяет сочетать современный объектно-ориентированный подход Java с существующим (LEGACY) системно-зависимым кодом на С/С++, каким и является драйвер SNAPI/XRJ. JNI-интерфейс использовалась в Oracle Reports, чтобы подключить XRJ-библиотеку в Java PDS-драйвер. Нам же пришлось реализовать клиент-серверный подход, когда сервер, стоящий отдельно от базы данных, может подключать любые библиотеки, а клиент еще взаимодействует с сервером.
Таким образом, нами был сделан промежуточный буферный сервер, который по JNI подключал SNAPI-драйвер. В его задачи входило получение запросов от клиентов и переправка их дальше SNAPI/XRJ-драйверу, который разбирал этот запрос и выдавал обратно результаты. Далее буферный сервер отдавал результаты клиенту.
В качестве реализации клиент-серверной технологии была выбрана RMI-архитектура. Система Remote Method Invocation (RMI) дает возможность объектам, выполняющимся на одной Java-машине, вызывать методы объекта, выполняющегося на другой. RMI обеспечивает функционал для удаленных коммуникаций между программами, написанными на языке Java.
Для представления кубов в виде таблиц были использованы табличные функции, особый тип функций PL/SQL, которые возвращают не скалярное значение, а массив элементов произвольной структуры. Причем, имеются два вида табличных функций: возвращающие результат в виде массива и контролирующие обработку возвращаемой выборки с помощью реализации интерфейса ODCITable. В нашем решении мы использовали именно ODCITable-интерфейс, поскольку это позволяло реализовать конвейерные табличные функции и получить высокую производительность. Для представления кубов в виде таблиц необходимо было создать специальные структуры в СУБД Oracle, которые представляли результаты выборки данных из Express кубов. Здесь возможно два варианта: либо создается один большой тип, состоящий их максимального числа столбцов всех типов, либо для каждого куба создается свой собственный тип. Далее создаются представления или материализованные представления в СУБД Oracle, которые, используя конвейерные табличные функции, возвращают выборки из кубов.
После того, как Express-кубы, в том числе из OFA, опубликованы как представления (материализованные представления) в СУБД Oracle, на их основе можно строить отчеты средствами Oracle BI Suite EE.
Построенное нами решение позволяет осуществлять
Построенное нами решение позволяет осуществлять прямой доступ к Express Server из СУБД Oracle. Конечно, у такого решения есть свои ограничения. Во-первых, это ограничения, связанные с работой связки SNAPI/XRJ и SNAPI интерфейса Express сервера, а во-вторых, необходимо наличие СУБД Oracle 10g и Oracle Reports 10g. В целом же оно позволяет строить системы, в которых Express Server и OFA, в частности, будут уже не отдельно стоящими приложениями, а интегрированными в общую информационную среду. Причем решение локальной задачи реализации интерфейса OFA -> Oracle BI Suite EE, позволило нам создать общий подход для подключения Express Server к любым приложениям через СУБД Oracle.Таким приложением может быть, например Oracle Discoverer, входящий в состав Oracle BI Suite Standard Edition. Важным является и то, что теперь Express Server можно включать в любые ETL-процессы, т.е. теперь Express становится полноценным источником для построения хранилища данных.
Отдельный самостоятельный ODBC-драйвер или любой другой драйвер стандарта доступа к данным JDBC, ODBO или XMLA, конечно более универсален, поскольку может работать напрямую и иметь свой собственный движок и промежуточный слой. Еще одним важным плюсом отдельного драйвера отсутствие требования в СУБД Oracle 10g и Oracle Reports 10g.
Oracle BI EE и BPEL
По своей сути Oracle Business Intelligence является не монолитным приложением, а набором различных сервисов, которые работают на единой информационной платформе и выполняют каждый свои определенные функции. В Oracle BI EE сервером, на котором реализуются все сервисы, называется Oracle BI Presentation Services. Кроме внутренних сервисов, в нем существует целый набор стандартных SOAP Webсервисов, которые можно использовать при построении различных композитных приложений с использованием BPEL.
По сути, они являются полноценным API, т.е. набором базовых функций для управления всей системой. Они позволяют выполнять следующие задачи:
Получать отчеты и данные из них Доставлять отчеты внешним системам Управлять каталогом метаданных Запускать бизнес-процессы и агенты исполнения (iBot)
См. рисунок
Формальное описание сервисов и методов представлено в WSDL-файл, который находится по адресу http://host:port/analytics/saw.dll?WSDL. XSD-файл для сервисов называется SawServices.xsd и находится в папке \Web\App\Res\Wsdl\Schemas.
Oracle BI предоставляет пользователю следующие 8 сервисов:
HtmlViewService – сервис, позволяющий встраивать отчеты в HTML формате в любые внешние приложения или порталы. Кроме того сервис, позволяет в режиме реального времени изменять конечное представление отчета; iBotService – сервис, позволяющий запускать агенты исполнения (iBot). Создавать или изменять iBot с помощью этого сервиса нельзя; MetadataService – сервис, с помощью которого можно получать метаописания для различных объектов включая ReplicationService – сервис, позволяющий производить экспорт и импорт метаданных из файлов; ReportEditingService – сервис, с помощью которого можно настраивать параметра для отчетов; SAWSessionService – сервис, обслуживающий все сессионные переменные, такие как имя пользователя, пароль, ключ сессия и т.д. Является обязательным и самым первым сервисом в работе; SecurityService – сервис, отвечающий за вопросы безопасности в системе; WebCatalogService – сервис, с помощью которого можно управлять Web-каталогом, позволяет создавать, изменять, удалять любые объекты; XMLViewService – сервис, позволяющий выполнять произвольные запросы к модель данных и получать результаты в XML формате.
Таким образом, интеграция BI с BPEL позволяет решать следующие задачи:
Запускать бизнес процессы из BI системы Интерактивное взаимодействие (Interactive Dashboards, Answers); Регламентированное взаимодействие (Alerts/ iBots);
Встраиваемая в бизнес процессы аналитика Возможность вызова отчетов и получения результатов;
Возможность вызова из бизнес-процессов механизма доставок (Delivers) в Oracle BI.

В качестве примера взаимодействия Oracle
В качестве примера взаимодействия Oracle BI EE и BPEL построим простой процесс, который будет авторизоваться в Oracle BI EE, а затем получать данные из него.
Запускаем JDeveloper 10.1.3.1 и создаем новый BPEL Process Project, в качестве шаблона выбираем Synchronous BPEL Process, получаем готовый шаблон, который мы дальше будем расширять.
Выбираем Invoke метод в списке инструментов и вставляем его между receiveInput и replyOutput. Заходим в его свойства и нажимаем на кнопку обзора Partner Link. В появившемся окне создаем новый Partner Link – BI_SAWSession. В окне редактирования Partner Link в строке WSDL File вписываем путь к Oracle BI EE WSDL файлу в виде http://host:port/analytics/saw.dll?WSDL и нажимаем на копку Parse WSDL. В строке Partner Link Type выбираем SAWSessionServiceSoap_PL, а в строке Partner Role – SAWSessionServiceSoap_Role.

Возвращаемся обратно в свойства Invoke метода. В строке Partner Link должен быть выбран только что созданный объект, в строке Operation выбираем logon. Вводим название BI_Logon_Invoke и нажимаем кнопки для автоматического создания входной и выходной переменной.

Теперь нам надо для вызова операции logon во входную переменную метода BI_Logon_Invoke передать имя пользователя и пароль. Выбираем в палитре инструментов Assign метод, открываем его свойства. На закладку Copy Operation создаем две Copy Operation для параметров ns1: name и ns1:password для входной переменной метода BI_ Logon_Invoke. Значение параметров есть имя пользователя и пароль для входа в Oracle BI EE.
См. рисунок
Таким образом, получаем следующий бизнес процесс, который обращается к Oracle BI EE, авторизуется на сервере и получает ключ авторизации.

Между методом BI_Logon_Invoke и replyOutput вставляем еще один Invoke метод – BI_SQL_Invoke, который будет передавать серверу Oracle BI SQL запрос и получать результат его выполнения. Создаем новый Partner Link – BI_XMLView, в качестве WSDL файл указываем такой же путь как и в предыдущий раз, в Partner Link Type выбираем XmlViewServiceSoap_PL, Partner Role – XmlViewServiceSoap_Role.

В новом методе выбираем операцию executeSQLQuery и создаем автоматически входную и выходную переменную.

Между методами BI_Logon_Invoke и BI_SQL_Invoke вставляем новый Assign метод – Assign_SQL. Создаем в нем три Copy операции:
Для sessionID из выходной переменной метода BI_Logon_Invoke;
См. рисунок
Для передачи SQL запроса: select Markets.Region, “Sales Measures”.Units from Paint
См. рисунок
Для установки значения параметра async
См. рисунок
Последнее что, надо создать, это Assign метод между методом BI_SQL_Invoke и replyOutput, чтобы скопировать результаты работы SQL запроса в выходную переменную всего бизнес процесса.
См. рисунок
BPEL процесс целиком готов, теперь если разместить его на Application Server и запустить из BPEL Process Manager, получим следующий результат:
См. рисунок
Т.е. мы получили данные из стандартной схемы Paint, которая поставляется вместе с Oracle BI EE.
Совершенно аналогичным образом можно вызывать и другие сервисы, входящие в Oracle BI, строить на основе них сложные бизнес процессы тем самым внедряя ту самую аналитику.
Сервис-ориентированный подход в бизнес-аналитике от Oracle
Антон Шмаков, ведущий консультант-разработчик IBS Borlas
Oracle Magazine - Русское издание
[От редакции OM/RE: Когда эта статья нашего постоянного автора Антона Шмакова была уже принята к публикации в очередном (февральском) выпуске «Oracle Magazine/Русское Издание», на сайте публикаций корпорации Oracle появилась статья Марка Риттмана (Mark Rittman, Oracle ACE Director) и Джоэл Крисп (Joel Crisp) «Integrating Oracle Business Intelligence Enterprise Edition Plus with SOA» на ту же тему, что и работа А.Шмакова. Естественно, что статья А.Шмакова абсолютно независима от публикации М.Риттмана, хотя Антон не скрывает, что для введения в предлагаемую читателям данную работу он пользовался блогом метра-директора коллегии «Асы Oracle».
Перевод статьи M.Rittman и J.Crisp «Integrating Oracle Business Intelligence Enterprise Edition Plus with SOA» планируется к публикации в следующем выпуске журнала OM/RE.]
SOA архитектура в Oracle BI EE
BI системы последнего поколения представляют собой не просто отдельную программу, в которой пользователи строят и публикуют отчеты, а обширный комплекс технологий и приложений, созданный для удовлетворения всех потребностей BI. Именно таким продуктом и является Oracle Business Intelligence Enterprise Edition (подробнее см. «Oracle BI Suite EE — самая «всеядная» и «интеллектуальная» из аналитических платформ», Oracle Magazine RE, Октябрь 2007.
В целом подход Oracle к созданию сервис ориентированной бизнес аналитике (Service Oriented Business Intelligence) следующий. Одной из основных характеристик платформы Oracle BI EE является понятие “всепроникающей” (Pervasive) бизнес аналитики, что позволяет принимать более обдуманные и взвешенные решения на различных уровнях. Т.е. можно выделить следующие тенденции в развитие SO BI:
Включение BI в бизнес процессы компаний позволяет добавить аналитическую составляющую в Work?ow и обработку различных событий. Интеграция BI-систем и бизнес приложений позволяет объединить транзакционную и аналитическую обработку данных в едином интерфейсе; Интеграция исторических и данных реального времени позволяет строить хранилища данных нового типа, заниматься мониторингом различных аналитических показателей в режиме реального времени. Создание проактивной аналитики позволяет инициировать бизнес процессы из BI систем.
Если говорить про SOA архитектуру, то основными составляющими ее являются следующие компоненты:
Бизнес-процессы (Business Processes) и BPEL – язык формального описания бизнес процессов и протоколов их взаимодействия между собой; Бизнес правила (Business Rules); Бизнес события (Business Events) и корпоративная сервисная шина (ESB); Мониторинг бизнес деятальности (BAM). Внедрение BI в SOA среду позволяет расширить каждый из перечисленных выше компонентов: Аналитические бизнес процессы (Analytic BPEL, ABPEL)
Использование различных аналитические условий и метрики в BPEL процессах; Заниматься оркестровкой сервисов с использованием данных из BI систем;
Аналитические бизнес правила (Analytic Business Rules) Аналитическое управление бизнес событиями (Analytic Business Event Routing):
Возможность генерации бизнес событий (в том числе в шину данных) из агентов (Alert) в BI системах; Использование данных и отчетов для генерации бизнес событий; Возможность строить отчеты и запускать аналитические модели и вычисления из BPEL процессов; Интеллектуальная маршрутизация бизнес событий;
Аналитический мониторинг бизнес деятельности (Analytic BAM).
продолжает активно развиваться. За последние
Технология Business Intelligence (BI) продолжает активно развиваться. За последние несколько лет компании стали представлять свои хранилища данных и BI-системы как web-сервисы для использования другими приложениями и процессами, связанными сервисно-ориентированной архитектурой (SOA) или ПО промежуточного уровня, таким как корпоративная сервисная шина (enterprise service bus — ESB). В целом SOA предлагает компаниям многочисленные преимущества, как с точки зрения бизнеса, так и информационных технологий. SOA позволяет связать различные системы, существующие на предприятии и формализовать бизнес процессы их взаимодействия. В центре внимания СОА находятся не данные, а сервисы, которые являются бизнес-функциями, предназначенными для обеспечения согласованной работы больших, состоящих из множества частей приложений. С другой стороны в фокусе BI находятся данные, которые надо обрабатывать и отображать. Технология SOA имеет очень хороший потенциал в отношении BI-систем. Она позволяет обеспечить прозрачный доступ к информации, собранной в “виртуальное” хранилище данных из различных операционных и аналитических источников в реальном времени. Кроме того, использование сервисов как основы для построения BI системы позволяет преодолеть многие трудности связанные с клиент-серверной архитектурой. Так например, становится возможным управлять событиями, выполнять многие задачи в режиме реального времени, автоматизировать анализ и обработку информации, делать легко масштабируемые и “интегрируемые” системы.
В этой статье рассматривается применение и реализация SOA технологий в Oracle Business Intelligence Enterprise Edition.
Вызов BPEL из Oracle BI EE
В предыдущем примере мы показали, как можно вызывать Oracle BI сервисы из BPEL, но существует возможность вызова BPEL процессов из самого Oracle BI EE. Это можно сделать из Oracle BI Delivers. При создании iBot на закладке Advanced можно выбрать дополнительное действие, которое будет отрабатываться при выполнении или невыполнении условий агента. В качестве возможных вариантов можно выбрать:
iBot – возможность запустить другой агент Custom Script – выполнить любой скрипт на JavaScript или VBScript; Work?ow – запустить Siebel CRM Work?ow; Custom Java Program – выполнить произвольный Java код.

В качестве интеграции с BPEL подходят два варианта: Custom Script или Custom Java Program.
В первом случае можно написать небольшую программу, например на JavaScript, которая будет обращаться к некому сервлету (Servlet) и передавать ему параметры, а он будет запускать BPEL процессы. Если BPEL Process имеет HTTP форму запуска, то JavaScript может напрямую обращаться к BPEL процессу и передавать ему параметры.

Второй вариант взаимодействия через Custom Java Program позволяет писать на Java абсолютно любые вызовы и обработки.
В скором времени Oracle обещает добавить полноценную поддержку BPEL в Oracle BI EE, тогда в списке возможных действий в iBot появится еще один пункт BPEL.

В качестве некого заключение хочется
В качестве некого заключение хочется отметить, что общая тенденция к созданию приложений и систем, работающих в реальном времени, способных реагировать на различные бизнес события и инициировать бизнес процессы становится абсолютно очевидной. Для Oracle одним из главных приоритетов становится интеграция SOA технологий во все решения и продукты, не является исключением и BI. Думается, что уже в 2008 году выйдет релиз Oracle BI, который будет полностью интегрирован с SOA и BPEL.
