Аннотация
Статья продолжает статью , в которой было показано как средствами Oracle Text строить полнотекстовый индекс типа CTXSYS.CONTEXT к текстовым документам, хранимым в БД, и как делать запросы по индексу. Здесь показано, как можно индексировать документы в полях CLOB, вне БД, а также документы, представленные другими форматами, нежели чем простым текстовым.
Другие форматы документов
В том же каталоге файловой системы есть версии содержимого readme.txt в других форматах: это readme.htm и readme.pdf. Файл формата HTML имеет следующий вид:
Выполним:
TRUNCATE TABLE docs; DROP INDEX docs_bfiledoc_idx; ALTER TABLE docs DROP COLUMN bfiledoc; ALTER TABLE docs ADD ( htmldoc BFILE );
INSERT INTO docs VALUES ( 1, BFILENAME ( 'DOCS_DIR', 'readme.htm' ) );
CREATE INDEX docs_htmldoc_idx ON docs ( htmldoc ) INDEXTYPE IS CTXSYS.CONTEXT PARAMETERS ( 'filter CTXSYS.NULL_FILTER section group CTXSYS.HTML_SECTION_GROUP' );
В последней команде потребовалось нарушить предшествовавшую практику использования умолчаний и открыто указать в определении текстового индекса некоторые его параметры.
Проверка:
CTX> SELECT CONTAINS ( htmldoc, 'oracle support' ) AS score FROM docs;
SCORE ---------- 12
Файл формата PDF имеет следующий вид:
Выполним:
TRUNCATE TABLE docs; DROP INDEX docs_htmldoc_idx; ALTER TABLE docs DROP COLUMN htmldoc; ALTER TABLE docs ADD ( autodoc BFILE );
INSERT INTO docs VALUES ( 1, BFILENAME ( 'DOCS_DIR', 'readme.pdf' ) );
CREATE INDEX docs_autodoc_idx ON docs ( autodoc ) INDEXTYPE IS CTXSYS.CONTEXT PARAMETERS ( 'filter CTXSYS.AUTO_FILTER section group CTXSYS.AUTO_SECTION_GROUP' );
Вместо CTXSYS.AUTO_FILTER в параметрах индекса можно указать CTXSYS.INSO_FILTER. До версии 10 только так и нужно было поступать, однако с версии 10 фирма советует использовать новый AUTO-фильтр как более современную и совершенную реализацию старого INSO-фильтра (купленного в свое время фирмой Oracle у фирмы Inso). Фильтр используется СУБД для предварительной обработки текста перед построением индекса.
Проверка:
CTX> SELECT CONTAINS ( autodoc, 'oracle support' ) AS score FROM docs;
SCORE ---------- 6
Обратите внимание на отличный от предыдущих примеров показатель соответствия документа запрашиваемой комбинации слов (6 против 12). Ручная проверка показывает, что сочетание 'oracle support' в каждом из текстов встречается одинаковое число раз, четырежды, так что степень соответствия всех документов должна быть одинакова. Последний результат является следствием особенности обработки документов PDF фильтром CTXSYS.AUTO_FILTER (до версии 10 CTXSYS.INSO_FILTER), примененном в построении индекса, и особенностями конкретного документа. В частности, согласно документации Oracle по версии 10, фильтр CTXSYS.AUTO_FILTER не замечает или «не обязательно правильно» обрабатывает:
адреса в сети и электронной почты встроенные в документ шрифты версии PDF вне диапазона 1.1 (Acrobat 2.0) - 1.5 (Acrobat 6.0) (это относится к версии Oracle 10).
В нашем документе использована версия PDF 1.4, однако сам документ составлен неоднородно, что приводит к игнорированию при построении индекса последнего абзаца документа и его заголовка, в которых имеется два вхождения комбинации 'oracle support' из общих четырех (об этом напоминает и внешний вид последнего абзаца):
Если бы документ readme.pdf был составлен «правильно», показатель его соответствия нашему запросу также был бы 12.
Досадные шероховатости обработки документов PDF компенсируются универсальностью AUTO/INSO-фильтра. Это универсальный фильтр, способный обработать при индексации документов большой перечень разных форматов, в том числе (помимо PDF) простой текстовый, HTML, DOC, RTF и ряд прочих (общим количеством более полутора сотен). Например, выполним:
INSERT INTO docs VALUES ( 2, BFILENAME ( 'DOCS_DIR', 'readme.txt' ) ); INSERT INTO docs VALUES ( 3, BFILENAME ( 'DOCS_DIR', 'readme.htm' ) );
EXECUTE CTX_DDL.SYNC_INDEX ( 'docs_autodoc_idx' )
Проверка:
CTX> SELECT CONTAINS ( autodoc, 'oracle support' ) AS score FROM docs;
SCORE ---------- 6 12 12
В порядке упражнения предлагается проверить работу фильтра AUTO/INSO на файлах форматов DOC и RTF.
Конкретный формат документа фильтр AUTO распознает автоматически. Тем не менее, для некоторых популярных форматов фирма Oracle ради лучшей эффективности советует использовать специфичные фильтры: например, для формата HTML - тот, что был применен в примере выше. Фильтры (и прочие параметры текстового индекса) для форматов HTML и XML позволяют делать запросы с учетом разметки документов.
Другие источники документов
Пример таблицы, рассмотренной в , не вполне реалистичен, так как размер документов в нем ограничивался максимум четырьмя тысячами байтов для типа VARCHAR2. В то же время Oracle позволяет создавать индекс типа CTXSYS.CONTEXT еще на поля типа CLOB, XMLTYPE и даже BFILE и URITYPE. Выполним:
TRUNCATE TABLE docs; DROP INDEX docs_vc2doc_idx; ALTER TABLE docs DROP COLUMN vc2doc; ALTER TABLE docs ADD ( clobdoc CLOB );
INSERT INTO docs VALUES ( 1, 'Mary had a little lamb' ); INSERT INTO docs VALUES ( 2, 'Twinkle, twinkle little star' ); INSERT INTO docs VALUES ( 3, 'This Lamb is my lamb' );
CREATE INDEX docs_clobdoc_idx ON docs ( clobdoc ) INDEXTYPE IS ctxsys.context;
Проверка:
CTX> SELECT CONTAINS ( clobdoc, 'little' ) AS score FROM docs;
SCORE ---------- 4 4 0
Следующий пример показывает, что Oracle позволяет создавать в БД текстовый индекс на документы, находящиеся вне базы.
Пусть на сервере имеется каталог c:\distr\ora102\docdisk с документацией по Oracle. Там есть простой текстовый файл readme.txt:
Создадим в БД указатель на каталог и переопределим таблицу DOCS:
CONNECT / AS SYSDBA
CREATE OR REPLACE DIRECTORY docs_dir AS 'c:\distr\ora102\docdisk'; GRANT READ ON DIRECTORY docs_dir TO ctx; CONNECT ctx/ctx TRUNCATE TABLE docs; DROP INDEX docs_clobdoc_idx; ALTER TABLE docs DROP COLUMN clobdoc; ALTER TABLE docs ADD ( bfiledoc BFILE );
INSERT INTO docs VALUES ( 1, BFILENAME ( 'DOCS_DIR', 'readme.txt' ) );
CREATE INDEX docs_bfiledoc_idx ON docs ( bfiledoc ) INDEXTYPE IS ctxsys.context;
Проверка:
CTX> SELECT CONTAINS ( bfiledoc, 'oracle support' ) AS score FROM docs;
SCORE ---------- 12
Обратите внимание, что в отличие от предыдущих примеров здесь документы хранятся в файловой системе, а в БД создается текстовый индекс; именно его и использует СУБД для вычисления результатов, несмотря на то, что формально запрос обращается к документам. Это может приводить к ошибкам при попытке извлечь сам документ ввиду его исчезновения уже после создания индекса - картина вполне привычная для тех, кто пользуется поисковыми машинами в интернете.
Как и раньше, изменения в документах не отразятся в индексе сами собой. Однако при хранении документов в БД система имела возможность фиксировать факт их изменения и предоставляла информацию о рассогласовании содержимого индекса и документов, чем можно было пользоваться, решая, стоит ли обновить индекс; в случае же внешнего хранения документов сведения о возможных рассогласованиях накапливаться в БД не могут.
Параметры индекса
Параметры индекса позволяют задавать разные свойства индекса, например:
фильтры для документа тип местонахождения документа тип лексического анализатора обеспечение индексом морфологического, нечеткого поиска; хранение префиксов учет структуры документа, такой как предложения, параграфы или разметка HTML/XML список неиндексируемых слов.
Иное название для параметров текстового индекса в Oracle - «предпочтения» (preferences).
Пример использования в качестве свойства индекса более удобного, чем в примерах выше, учета местонахождения документа:
TRUNCATE TABLE docs; DROP INDEX docs_autodoc_idx; ALTER TABLE docs DROP COLUMN autodoc; ALTER TABLE docs ADD ( docname VARCHAR2 ( 100 ) );
INSERT INTO docs VALUES ( 1, 'c:\distr\ora102\docdisk\readme.txt' ); INSERT INTO docs VALUES ( 2, 'c:\distr\ora102\docdisk\readme.htm' ); INSERT INTO docs VALUES ( 3, 'c:\distr\ora102\docdisk\readme.pdf' );
CREATE INDEX docs_docname_idx ON docs ( docname ) INDEXTYPE IS CTXSYS.CONTEXT PARAMETERS ( 'filter CTXSYS.AUTO_FILTER section group CTXSYS.AUTO_SECTION_GROUP datastore CTXSYS.FILE_DATASTORE' );
Проверка:
CTX> COLUMN docname FORMAT A35 CTX> SELECT docname, CONTAINS ( docname, 'oracle support' ) FROM docs;
DOCNAME CONTAINS(DOCNAME,'ORACLESUPPORT') ----------------------------------- --------------------------------- c:\distr\ora102\docdisk\readme.txt 12 c:\distr\ora102\docdisk\readme.htm 12 c:\distr\ora102\docdisk\readme.pdf 6
Более того, с каждым параметром связан один или более атрибутов. Однако явное указание атрибутов добавляет организационной сложности, так как производится техникой вызовов системных процедур, и не оформляется запросом SQL.
Поддержка текстовым индексом документов на русском
Приведенные выше примеры были для текстов на английском. Обработка текстов на разных языках имеет различия соответственно различиям устройства самих языков. Стандартная поставка Oracle Text способна работать со всеми языками, поддерживаемыми Oracle, но в рамках сравнительно простого контекстного поиска (о нем и шла речь выше), для которого различия языков несущественны. То есть контекстный поиск возможен и для документов на русском - это легко проверить в порядке упражнения. В этом отношении русский ничем не лучше эстонского или, скажем, языка телугу. Больше того, контекстный поиск в документах, по заверению документации Oracle, возможен не только для языков, перечисленных в таблице V$NLS_VALID_VALUES, но и для любого языка, кодировка которого включена в Unicode. Для этого, правда, требуется, чтобы Unicode была основной кодировкой для БД (это потребуется указать при создании базы).
В то же время продвинутый набор возможностей, включающий морфологический анализ, нечеткий поиск и другое, присутствует в готовом виде только для шести западноевропейских языков. Русского среди них нет.
Для тех, кому не повезло, разработчики Oracle Text дали механизм для самостоятельного построения продвинутых возможностей запросов. Мне известна всего одна попытка применить этот механизм к русскому языку, завершившаяся созданием готового продукта. Подробности можно найти по . Там же имеется на русском языке ряд материалов общего характера по обработке текстовых документов. Материалы вполне подтверждают догадку о том, что в конечном итоге сложность обработки текстовых документов сопоставима со сложностью естественных языков, то есть что работа с текстовыми документами в Oracle и где бы то ни было - это очень сложно.
Текстовые документы в Oracle: разнообразие источников, форматов, запросов
,
преподаватель технологий Oracle
| Вы думаете, мне это легко далось? Я работал над источниками. | |
| И. Ильф, Е. Петров. Золотой теленок. РАССКАЗ БУХГАЛТЕРА БЕРЛАГИ. |
Индекс по нескольким полям
Особенностью «каталожного» индекса является то, что он позволяет учитывать дополнительные, помимо основного, столбцы. В качестве такого столбца рассмотрим дату новости; этот же реальный пример заодно покажет и некоторые «овраги», не всегда заметные на «бумаге» фирменной документации Oracle.
Формат представления даты новости очевиден из показанных выше исходного документа XML и ответа на запрос к таблице. К сожалению, он не годится для нашей цели - включить поле PUBDATE в состав индексируемых, - и по двум причинам: (а) текст PUBDATE слишком длинен и (б) он не допускает сравнения значений времени как строк текста. Это можно рассматривать как ограничения языка запросов оператора CATSEARCH и индекса типа CTXSYS.CTXCAT, разрешающих использовать только дополнительные столбцы типа «число» и «строка», да и то, во втором случае не очень длинная. Поэтому, чтобы продемонстрировать индексирование по нескольким полям, нам придется этот столбец переделать. В качестве упрощения сочтем, что даты новостей всегда приводятся относительно Гринвичского часового пояса (как это есть в имеющихся данных), а далее и вовсе не будем принимать часовой пояс во внимание.
Удалим старый индекс и добавим новый столбец таблице:
DROP INDEX otnnews_idx;
ALTER TABLE otnnews ADD ( pubtime VARCHAR2 ( 30 ) );
UPDATE otnnews SET pubtime = TO_CHAR ( TO_TIMESTAMP_TZ ( pubdate, 'Dy, DD Mon YYYY HH24:MI:SS TZD' ) , 'YYYY:MM:DD:HH24' ) ;
Учет в дополнительных полей оформляется через механизм параметров индекса, а необходимые параметры заводятся последовательностью вызовов системных процедур:
BEGIN CTX_DDL.CREATE_INDEX_SET ( 'otntab_fields' ); CTX_DDL.ADD_INDEX ( 'otntab_fields', 'pubtime' ); -- CTX_DDL.ADD_INDEX ( 'otntab_fields', '...' ); -- если надо, и другие столбцы
END; /
Сформированное «предпочтение» OTNTAB_FIELDS укажем параметром новому индексу:
CREATE INDEX otnnews_idx ON otnnews ( description ) INDEXTYPE IS CTXSYS.CTXCAT PARAMETERS ( 'index set OTNTAB_FIELDS' ) ;
В качестве упражнения, для созданного индекса можно устроить проверку типа выполнявшейся выше для «простого» «каталожного» индекса и убедиться в том, что добавление дополнительных столбцов индексации несколько усложняет техническую организацию индекса.
Исходные данные и план действий
В качестве исходных данных возьмем реальную ленту новостей с содержанием на момент написания статьи:
Документ имеет общее описание канала новостей (разметка title, link, description, copywrite и т. д.) и перечисление сведений об отдельных новостях элементами title:
<title> <link>...</link> <description>...</description> <category>...</category> ... </title>
План дальнейших действий таков:
Перенесем эти данные в БД в таблицу с полями LINK, DESCRIPTION и PUBTIME, данные в которых описывают каждую конкретную новость. Построим «каталожный» индекс типа CTXSYS.CTXCAT по полю DESCRIPTION. Приведем примеры запросов.
Для лучшего понимания существа сам пример будет использовать ряд технических упрощений и исходных допущений. В частности, обратите внимание, что
исходные данные представлены в формате RSS 2.0, и в статье не учитывается возможность существования в прочих каналах новостей других форматов RSS с иной разметкой; в конкретном новостном канале элемент description невелик по объему и лучше подходит под «краткое содержание», нежели чем элемент title.
Кроме того, некоторых целей, преследуемых далее, можно достичь иными путями. Так, первое, что приходит в голову - программирование, которого дальше, однако, я сознательно избегаю.
Для удобства занесем адрес канала в переменную SQL*Plus:
VARIABLE url VARCHAR2 ( 1000 ) EXECUTE :url := 'http://www.oracle.com/technology/syndication/rss_otn_news.xml'
Если обращение в интернет будет осуществляться через приближенный (proxy) сервер, требуется предварительно выдать что-то вроде:
EXECUTE UTL_HTTP.SET_PROXY ('http://имя:пароль@адрес:порт')
Как работать с картотекой (набором данных с краткими описаниями)
,
преподаватель технологий Oracle
| ... в отделе «Что случилось за день» нонпарелью было напечатано:
Попал под лошадь. Вчера на площади Свердлова попал под лошадь извозчика №8974 гражданин О. Бендер. Пострадавший отделался легким испугом. | ||
| И. Ильф, Е. Петров. Двенадцать стульев |
Проверка запросами
Первый запрос ничем не отличается от одного из предыдущих ни по форме, ни по результату:
CTX> @catsearch "'java | web'" NULL
DESCRIPTION --------------------------------------------------------------------------- Get an introduction to using Oracle Data Integrator, Java-based middleware Learn how to secure PHP-based Web applications via database-based authentic
Следующий запрос показывает возможность сформировать критерий упорядочения, включающий обращение к дополнительному индексированному столбцу, в третьем аргументе оператора CATSEARH:
CTX> @catsearch "'java | web'" "'order by pubtime desc'"
DESCRIPTION --------------------------------------------------------------------------- Learn how to secure PHP-based Web applications via database-based authentic Get an introduction to using Oracle Data Integrator, Java-based middleware
Следующий запрос показывает возможность сформировать условное выражение, включающее обращение к дополнительному индексированному столбцу, в третьем аргументе оператора CATSEARH:
CTX> VARIABLE texpr VARCHAR2 ( 256 ) CTX> BEGIN 2 :texpr := TO_CHAR ( SYSDATE - 35, 'YYYY:MM:DD:HH24' ); 3 :texpr := 'pubtime < ''' :texpr ''''; 4 DBMS_OUTPUT.PUT_LINE ( :texpr ); 5* END; CTX> / pubtime < '2007:05:31:15'
PL/SQL procedure successfully completed.
CTX> @catsearch "'java | web'" :texpr
DESCRIPTION --------------------------------------------------------------------------- Get an introduction to using Oracle Data Integrator, Java-based middleware
К сожалению, формулировки выражений для третьего аргумента CATSEARCH могут быть только очень простыми; в частности, в отличие от выражений SQL, они не терпят обращений к функциям. Тем не менее, возможно объединение фразы упорядочения и фильтрующего условного выражения.
Упражнение. Проверить это, сформировав уточнение запроса следующим значением третьего аргумента CATSEARCH: «order by pubtime desc AND pubtime < '2007:05:31:15'».
Реакция СУБД на ошибки работы с каталожным индексом (а в примерах выше их не было) может изнурить программиста, к чему надо быть готовым.
Создание индекса
В простом случае индекс создается просто:
CREATE INDEX otnnews_idx ON otnnews ( description ) INDEXTYPE IS CTXSYS.CTXCAT
;
Вот какие структуры БД и сегменты хранения появились в результате:
CTX> COLUMN object_name FORMAT A30 CTX> COLUMN object_type FORMAT A30 CTX> COLUMN segment_name FORMAT A30 CTX> COLUMN segment_type FORMAT A30 CTX> SELECT object_name, object_type FROM user_objects ORDER BY 2, 1;
OBJECT_NAME OBJECT_TYPE ------------------------------ ------------------------------ DR$OTNNEWS_IDX$R INDEX DR$OTNNEWS_IDX$X INDEX OTNNEWS_IDX INDEX DR$OTNNEWS_IDX$I TABLE
OTNNEWS TABLE DR$OTNNEWS_IDXTC TRIGGER
OTNNEWS_VIEW VIEW
CTX> SELECT segment_name, segment_type FROM user_segments ORDER BY 2, 1;
SEGMENT_NAME SEGMENT_TYPE ------------------------------ ------------------------------ DR$OTNNEWS_IDX$R INDEX DR$OTNNEWS_IDX$X INDEX DR$OTNNEWS_IDX$I TABLE OTNNEWS TABLE
Очевидно, что формально индекс типа CTXSYS.CTXCAT компактнее индекса типа CTXSYS.CONTEXT: он реализован не из черырех, а из трех служебных таблиц, вдобавок не имеющих полей LOB. Еще одно отличие: создание «каталожного» индекса сопряжено с автоматическим появлением триггерной процедуры (в нашем случае DR$OTNNEWS_IDXTC) вида AFTER EACH ROW INSERT OR UPDATE, связанной с базовой таблицей (все это легко установить в качестве самостоятельного упражнения). Наличие этой триггерной процедуры дает основание предположить, что еще одно отличие «каталожного» индекса от полнотекстового в том, что он автоматически корректируется при изменении данных в таблице. Это предположение легко проверяется.
в документах, объем которых может
Помимо полнотекстового поиска в документах, объем которых может быть очень велик, встроенная в СУБД Oracle текстовая машина («Oracle Text») отдельно обеспечивает возможность поиска информации для одного специального случая. Речь идет о поиске в наборе записей, содержащих краткие текстовые описания. Подобное устройство данных хорошо известно по традиционным картотекам, постепенно уходящим в прошлое, но еще встречающимся в унаследованых институтах, таких как библиотеки. Там картотеки организованы в виде продолговатых ящичков, где хранятся карточки с кратким описанием единиц хранения и указанием месторасположения. Более современный пример того же устройства данных - каналы новостей , придавшие своим появлением заметный импульс динамике информации в интернете. Сама же фирма Oracle использует для именования такого устройства данных метафору «каталога», образованного записями с описаниями, помимо прочих реквизитов, объектов каталогизации.
Если подобную картотеку/каталог промоделировать таблицею в БД Oracle, сама собой возникает мысль проиндексировать поля с такими описаниями предметным (DOMAIN) индексом типа CTXSYS.CONTEXT и воспользоваться для запросов к данным возможностями оператора CONTAINS. Однако если описания кратки (одна - две строки), это неэкономно: индекс получается чрезмерно большим, а возможности запросов избыточными. Для такого случая и предложен специальный тип предметного индекса: CTXSYS.CTXCAT. Он дает одновременно и большую по отношению к полнотекстовому индексу компактность, и более простой (в основном варианте) язык запросов, обеспеченный специальным оператором CATSEARCH.
Ниже рассматривается пример организации в БД «картотеки», построения предметного индекса типа CTXSYS.CTXCAT и составления запросов к данным.
Загрузка данных в БД
Загрузка данных о новостях будет осуществляться с помощью функции по форме, а по сути - процедуры, DBMS_XMLSTORE.INSERTXML. Она требует привести данные для загрузки к следующему виду:
<ROWSET> <ROW> <link>...</link><description>...</description><pubDate>...</pubDate> </ROW> <ROW> <link>...</link><description>...</description><pubDate>...</pubDate> </ROW> ... </ROWSET>
Это будет сделано с помощью преобразования XQUERY, но для того, чтобы не усложнять его формулу, я использую следующий трюк. Создадим таблицу с полями LINK, DESCRIPTION и PUBDATE, а загрузку произведем в однотипную производную таблицу (view), имена столбцов которых сохраняют регистр букв соответствующих меток в исходном документе. Объекты для хранения и для загрузки:
CREATE TABLE otnnews ( link VARCHAR2 ( 4000 ) , description VARCHAR2 ( 4000 ) , pubdate VARCHAR2 ( 30 ) );
CREATE VIEW otnnews_view ( "link", "description", "pubDate" ) AS SELECT * FROM otnnews ;
В следующем блоке на PL/SQL сначала оператор SELECT берет из интернета документ XML и преобразует его в требуемый вид, а последующая серия вызовов подпрограмм пакета DBMS_XMLSTORE организует занесение данных (элемент title) из полученного документа XML в таблицу OTNNEWS_VIEW; фактически - в OTNNEWS:
VARIABLE rowsnumber NUMBER
DECLARE xmltypedoc XMLTYPE; updatecontext DBMS_XMLSTORE.CTXTYPE; BEGIN SELECT XMLQUERY ( '<ROWSET> { for $a in /rss/channel/item return <ROW>{$a/link, $a/description, $a/pubDate}</ROW> } </ROWSET>' PASSING HTTPURITYPE ( :url ).GETXML ( ) RETURNING CONTENT ) INTO xmltypedoc
FROM dual ;
updatecontext := DBMS_XMLSTORE.NEWCONTEXT ( 'CTX.OTNNEWS_VIEW' );
DBMS_XMLSTORE.CLEARUPDATECOLUMNLIST ( updatecontext ); DBMS_XMLSTORE.SETUPDATECOLUMN ( updatecontext, 'link' ); DBMS_XMLSTORE.SETUPDATECOLUMN ( updatecontext, 'description' ); DBMS_XMLSTORE.SETUPDATECOLUMN ( updatecontext, 'pubDate' );
:rowsnumber := DBMS_XMLSTORE.INSERTXML ( updatecontext, xmltypedoc );
DBMS_XMLSTORE.CLOSECONTEXT ( updatecontext ); END; /
В таблице OTNNEWS появилось 11 записей. Вот, например, даты новостей:
CTX> SELECT pubdate FROM otnnews;
PUBDATE ------------------------------ Fri, 29 Jun 2007 21:18:44 GMT Mon, 25 Jun 2007 22:23:05 GMT Tue, 19 Jun 2007 16:18:01 GMT Tue, 12 Jun 2007 15:26:52 GMT Fri, 01 Jun 2007 16:24:42 GMT Fri, 01 Jun 2007 16:23:00 GMT Fri, 25 May 2007 15:37:53 GMT Fri, 25 May 2007 15:34:52 GMT Tue, 15 May 2007 23:11:50 GMT Tue, 15 May 2007 23:09:37 GMT Fri, 01 Jun 2007 16:16:47 GMT
11 rows selected.
Запросы
Оператором для предъявления запроса (формально к таблице, а фактически - к индексу), является CATSEARCH. В отличие от CONTAINS, он может употребляться в SQL только в составе условного выражения. В основном применении он допускает собственные обозначения операторов запроса (логические AND, OR и NOT, обозначаемые через «пробел», | и -; * для произвольной подстановки и заключения в кавычки). Тем не менее, синтаксис, применяемый в CONTAINS, тоже допускается, но путем определенных ухищрений, из-за которых эта возможность здесь не рассматривается.
Выдадим:
SELECT description FROM otnnews WHERE CATSEARCH ( description, &1, &2 ) > 0 . SAVE catsearch COLUMN description FORMAT A75 TRUNCATED SET VERIFY OFF
Примеры запросов:
CTX> @catsearch "'java'" NULL
DESCRIPTION --------------------------------------------------------------------------- Get an introduction to using Oracle Data Integrator, Java-based middleware
CTX> @catsearch "'java | web'" NULL
DESCRIPTION --------------------------------------------------------------------------- Get an introduction to using Oracle Data Integrator, Java-based middleware Learn how to secure PHP-based Web applications via database-based authentic
CTX> @catsearch "'(java | web) - php'" null
DESCRIPTION --------------------------------------------------------------------------- Get an introduction to using Oracle Data Integrator, Java-based middleware
В виде упражнения можно выдать следующие команды и сравнить результаты запросов:
VARIABLE query1 VARCHAR2 ( 1000 ) VARIABLE query2 VARCHAR2 ( 1000 ) EXECUTE :query1 := 'oracle *developer' EXECUTE :query2 := '"oracle *developer"' @catsearch :query1 NULL @catsearch :query2 NULL
Глубинный анализ данных в режиме реального времени: Oracle Real Time Decisions
, старший консультант отдела бизнес-анализа и хранилищ данных, Консалтинговая группа "Борлас" (Москва)
Источник:
ODM и ORTD
Корпорация Oracle на сегодняшний день предлагает два решения класса Data Mining - ODM (Oracle Data Mining), решение на основе Data Mining опции базы данных, и Oracle Real-Time Decisions. Опция для анализа данных Data Mining является мощным движком, который располагается в ядре базы данных и поэтому рассчитан на обработку экстремально больших объемов данных. Именно поэтому Data Mining удобно применять регламентировано при формировании хранилищ данных или при историческом анализе данных и выявлении тенденций, закономерностей и зависимостей. Для Data Mining источником и приемником информации являются таблицы базы данных. С другой стороны, Oracle RTD является продуктом другой категории. Его удобно применять в режиме реального времени, когда объемы поступающих данных не столь велики, но скорость выдачи результатов должна быть высокой. Обычно такая практика распространена в бизнес-приложениях (учетных системах), когда по поступающей информации в режиме реального времени надо делать заключения и выдавать рекомендации.
На сегодняшний день самым развитым способом интеграции приложений является SOA-архитектура. Поэтому ORTD и рассчитан на SOA-среду. Следует отметить, что отличается у двух продуктов и методика работы самого движка, в ODM разработчик должен четко и правильно настроить модели для анализа данных. С другой стороны, ORTD предоставляет механизмы, в котором модели могут самостоятельно настраиваться и меняться. В целом ситуация с ODM и ORTD похожа на ситуацию, которая сложилась с Oracle-продуктами для построения хранилищ данных Oracle Warehouse Builder (OWB) и Oracle Data Integrator (ODI). ODM является аналогом OWB, поскольку работает на уровне базы данных Oracle. RTD, соответственно, является аналогом ODI, рассчитан на работу в SOA-среде, имеет готовые механизмы для настройки модели. Т.е. Oracle предлагает продукты двух категорий: один для разработчиков базовых технологий, которые знают SQL, PL/SQL, Java, и для разработчиков новых и "модных" систем, которые используют SOA-стандарты XML, WSDL и т.д. В соответствии с этим RTD можно легко и просто интегрировать в BPEL-процессы. Еще одной отличительной особенностью этих двух продуктов является то, что ODM предназначен для непосредственного анализа данных, в то время как ORTD предназначен в большей степени для интеграции анализа данных в бизнес-приложения.
Oracle Real-Time Decisions
Сервер
Опция базы данных, представляет собой набор готовых процедур и пакетов
J2EE приложение
Платформы
Сервер - платформы, на которых существует Oracle Database
Клиент - любая платформа с поддержкой Java
Сервер - любой J2EE-сервер
Клиенты - любая платформа с поддержкой Java
Интерфейс
PL/SQL API, Java API
Web-сервисы, Java API
Алгоритмы
Алгоритмы классификации, кластеризации, поиск существенных атрибутов, регрессия, поиск ассоциаций, выделений признаков
Сложные модели прогнозирования на основе классификации
Клиенты
Oracle Data Miner - "толстый" Java-клиент для создания, отладки, запуска моделей
Decision Studio - "толстый" Java-клиент для проектной работы
Decision Center - Web-приложение для мониторинга, запуска и администрирования проектов
Интеграция
На уровне базе данных
На уровне Web-сервисов
Возможности настройки моделей
Только настройка параметров
Гибкая настройка моделей на Java
Описание Oracle RTD
Oracle RTD
- это продукт линейки Data Mining, созданный для прогностической аналитики в режиме реального времени. Он построен полностью на SOA-архитектуре. Oracle RTD публикует наружу различные Web-сервисы, через которые осуществляется работа с сервером. Он состоит из пяти основных компонентов:
Decision Studio - специальный инструмент, построенный на основе движка Eclipse, в котором ведется вся разработка; Real-Time Decision Server - движок всей системы, представляющий собой сервер, работающий на J2EE-сервере; Decision Center - приложение для среды J2EE, которое обеспечивает доступ к проектам через Web. Позволяет бизнес-пользователям просматривать и администрировать проекты, следить за работой всей системы, собирать статистику; Administration (JMX) - интерфейс для сетевого администрирования. Настройка всей системы ведется с помощью приложения JConsole, входящего в состав Java SE 1.5; Load Generator - специальный инструмент для моделирования нагрузки на серверы, нужен для тестирования проектов.
Проект в RTD называется Inline Service. Разработка проектов ведется в Decision Studio. Вообще сама разработка моделей в RTD очень схожа с программированием на Java. В конечном итоге весь проект представляет собой набор Java-классов, которые выполняются на сервере приложений. Основным компонентами Inline Service являются
Application - описывает свойства всего приложения; Performance goals - набор ключевых показателей, за которыми надо следить и оптимизировать; Choices - это различные альтернативные предложения, которые являются атрибутами проекта (например: причины звонка с службу поддержки); Rules - различные бизнес правила. Бывают правила для вычисления применимостей каждого из предложений или расчета показателей;
Decisions - реакции на конкретное предложение. Высчитывается степень влияния каждого из возможных предложений и выбирается наилучшее исходя из ключевых показателей; Selection functions - функции для выбора подходящих предложений; Entities - сущности всей системы (например: клиент, звонок и т.д.); Data sources - описываются источники информации; Integration points - объекты, в которых описывается как Inline Service взаимодействует с внешними системами: либо получая новую порцию данных, либо отправляя реакцию на полученные данные. Существует два типа таких объектов:
Informants - получают данные из внешних систем (например: данные о клиенте);
Advisors - посылают ответ (совет) в зависимости от ключевых показателей обратно.
Модели - самообучающиеся модели, которые позволяют стечением времени улучшать прогностические способности аналитических приложений и быстро приспосабливаться к меняющимся условиям бизнеса; Statistical collectors - специальный модели, используемые для сбора статистических данных; Categories - категории для сегментации данных при отображении в Decision Center.
Oracle RTD может оказаться особенно полезными для реализации адаптируемых бизнес-процессов, т. е. процессов, логика которых определяется не набором фиксированных бизнес-правил, а может меняться со временем. Одно из главных преимуществ этого продукта - функции самообучения. И поскольку основная задача таких приложений - анализ данных, содержащихся в базах предприятия с целью определения намечающихся трендов деятельности, то раннее выявление подобных трендов позволяет принимать решения точнее и быстрее.
Результаты исследований, проведенных компаниями Gartner

Для реализации технологий извлечения знаний в состав СУБД Oracle Database включена специальная опция - Oracle Data Mining, основу которой составляют процедуры, реализующие различные алгоритмы построения моделей, средства подготовки данных, оценки результатов, применения моделей. Использовать все эти возможности можно как на программном уровне с помощью Java API или PL/SQL API, так и с помощью графической среды Oracle Data Miner (ODM). Продукт ODM и Data Mining опция существуют достаточно давно и хорошо известны сообществу Oracle.
Oracle, купив в 2005 году компанию Siebel Systems, приняла решение, что корпоративная линейка средств Business Intelligence (BI) корпорации будет базироваться на Siebel Analytics, а ее CRM-системы - на Siebel CRM. В состав продуктов Siebel Analytics и Siebel CRM в рамках OEM-соглашения включался Real-Time Decisions - специальный инструмент для Data Mining от компании Sigma Dynamics. Эта компания была разработчиком средств так называемой прогнозной аналитики (predictive analytics), позволяющих предсказывать, к примеру, реакцию конкретного заказчика на то или иное коммерческое предложение, опираясь на анализ накопленных ранее данных и принимая во внимание оперативную информацию, поступающую в режиме реального времени. Задачи такого рода стоят перед пользователями CRM-систем (кросс-продажи, удержание клиентов), call-центров (интеллектуальная маршрутизация вызовов), средств обеспечения безопасности (выявление мошенничества) и т. д. Таким образом, очередным шагом корпорации Oracle в этом направлении стало приобретение активов компании Sigma Dynamics. Так появился новый продукт Oracle Real-Time Decisions (Oracle RTD). Рассмотрим основные особенности этого продукта.
Time Decisions представляется очень интересным
Oracle Real- Time Decisions представляется очень интересным продуктом для расширения аналитических возможностей бизнес-приложений и BI-систем. Он идеально подходит для SOA-среды и легко интегрируется в любые бизнес-процессы на предприятии. Основной его плюс - это самонастраивающиеся прогностические модели, которые можно оперативно запускать через Web-сервисы. С другой стороны, Oracle Data Mining идеально подходит для глубокого и всестороннего анализа больших объемов информации. Его плюсы - большое количество различных алгоритмов для анализа, позволяющих производить тонкую настройку и делать различные пред- и пост- обработки данных. ORTD - это в большей степени законченное бизнес-приложение, которое надо настроить и адаптировать для конкретных бизнес-задач. ODM - это мощный инструмент и технология, которая позволяет строить сложные и разносторонние системы для анализа данных.
В настоящее времени отдел бизнес-анализа и хранилищ данных Консалтинговой группы "Борлас" занимается изучением продукта Oracle Real-Time Decisions. В следующих номерах OM/RE мы покажем на примерах, как работает данный продукт и выполним небольшой бизнес-пример.
Алгоритм вычисления свертки пароля
Алгоритм вычисления свертки пароля перед помещением его в словарь-справочник БД и при проверки подлинности (аутентичности) официально фирмой-изготовителем не опубликован. Тем не менее вызывающие доверие источники:
[1]
[2]
сообщают о следующей последовательности действий:
К имени пользователя приклеивается справа текст пароля. В получившейся строке буквам повышается регистр. Символы строки переводятся в двухбайтовый формат дополнением слева нулевым значением 0x00 (для символов ASCII), и справа строка дописывается нулевыми байтами до общей длины 80. Получившаяся строка шифруется алгоритмом DES в режиме сцепления блоков шифротекста (CBC) ключом 0x0123456789ABCDEF. Из последнего блока результата удаляются разряды четности и полученная строка (56 разрядов) используется для нового шифрования исходной строки тем же способом. Последний блок результата переводится в знаки шестнадцатиричной арифметики и объявляется конечным результатом - сверткой.
Особенности такого алгоритма:
Свертка не зависит от регистра букв. Например, пары SCOTT/TIGER, Scott/Tiger, scoTT/TigeR дадут одну и ту же свертку F894844C34402B67. Одинаковые склеенные пары имя_пользователя/пароль дают одинаковую свертку. Например, пары SCOTT/TIGER, SCOT/TTIGER, SCOTTTIG/ER дадут одну и ту же свертку F894844C34402B67. Свертка не зависит от БД. Например, где бы мы ни создавали БД Oracle, свертка для пользователя SCOTT и пароля TIGER всегда будет F894844C34402B67. Используется шифрование DES.
Аннотация
В статье рассматриваются некоторые собенности парольной защиты Oracle, способствующие несанкционированному проникновению в БД и меры по снижению риска подобного проникновения.
Хранение пароля
Заданный для пользователя Oracle командой CREATE/ALTER USER пароль подвергается преобразованию и попадает в словарь-справочник в виде свертки (password hash). При указании пароля в момент установления соединения с СУБД Oracle заново вычислит свертку и сравнит ее с хранимой в БД. В открытом виде пароли в БД не хранятся.
Основное место хранения свертки пароля - таблица словаря-справочника SYS.USER$. Над этой таблицей как базовой построена производная, SYS.DBA_USERS. Если в профиле (profile) пользователя включен параметр PASSWORD_REUSE_TIME, свертки пароля также хранятся в SYS.USER_HISTORY$.
Увидеть свертки логически можно, выдав например:
SQL> CONNECT / AS SYSDBA Connected. SQL> SELECT username, password FROM dba_users;
USERNAME PASSWORD ------------------------------ ------------------------------ MGMT_VIEW 34D8B04B40368661 SYS 8A8F025737A9097A SYSTEM 2D594E86F93B17A1 DBSNMP FFF45BB2C0C327EC SYSMAN 2CA614501F09FCCC XDB FD6C945857807E3C SCOTT F894844C34402B67
ADAM DC8670031DD24E45 PROF 3D2DEE6D12BD13D2 FORD 0805304F10B59B54 XTEST 5E3A5B0B1B1B4755 STREAMADMIN 77079477FD902BB1 OUTLN 4A3BA55E08595C81 EXFSYS 66F4EF5650C20355 WMSYS 7C9BA362F8314299 DIP CE4A36B8E06CA59C TSMSYS 3DF26A8B17D0F29F ANONYMOUS anonymous
18 rows selected.
Последняя строка в приведенной выдаче является иллюстрацией применения недокументированной, но широко известной возможности Oracle занести в БД на место свертки в БД непосредственное значение:
SQL> ALTER USER scott IDENTIFIED BY VALUES 'Это не свертка никакого пароля';
User altered.
SQL> SELECT username, password FROM dba_users WHERE username = 'SCOTT';
USERNAME PASSWORD ------------------------------ ------------------------------ SCOTT Это не свертка никакого пароля
Фактически это обесценивает привилегию CREATE SESSION, если таковая имеется (соединение все равно невозможно). Возможность занести в БД непосредственно свертку позволяет обладателю привилегии ALTER USER подменить на время пароль, чтобы за законных основаниях войти в систему под чужим именем. Однако если это пользователь SYS, замененный таким образом ему "пароль" не фиксируется в файле PWD.ORA, так что особой проблемы с доступностью это свойство не создает.
Если параметр СУБД O7_DICTIONARY_ACCESSIBILITY имеет значение TRUE (умолчание в версии 8), к трем указанным таблицам может обратиться любой обладатель системной привилегии SELECT ANY DICTIONARY; в противном случае - только владелец SYS.
Физически свертки можно наблюдать в файлах ОС: "парольном" PWD.ORA; табличного пространства SYSTEM, где хранятся SYS.USER$ и SYS.USER_HISTORY$ (часто это SYSTEM01.DBF); полного экспорта; архивированных журналов.
Как взломать парольную защиту Oracle или как ее обойти
,
Преподаватель технологий Oracle
| ЦАРСКОСЕЛЬСКАЯ СТАТУЯ
Урну с водой уронив, об утес ее дева разбила. Дева печально сидит, праздный держа черепок. Чудо! не сякнет вода, изливаясь из урны разбитой: Дева над вечной струей вечно печальна сидит. Александр Сергеевич Пушкин Чуда не вижу я тут. Генерал-лейтенант Захаржевский, В урне той дно просверлив, воду провел чрез нее. Алексей Константинович Толстой |
Обход парольной защиты
Не следует забывать, что подсоединение к СУБД может быть выполнено в обход проверки подлинности паролем. В Unix доверительное подключение пользователя SYS, не требующее указания пароля, возможно при работе от имени пользователя ОС, входящего в группу ОС dba, а в Windows - входящего в группу ORA_DBA, но еще при дополнительном условии, что в файлах sqlnet.ora на клиентской машине и на сервере имеется значение NTS для параметра SQLNET.AUTHENTICATION_SERVICES. При заведении ПО Oracle на Windows это значение этого параметра устанавливается автоматически, что часто игнорируется начинающими администраторами Oracle на Windows и составляет одну из наиболее популярных ошибок.
Возможно беспарольное подключение и других пользователей при условии, что имена таких пользователей в Oracle соотнесены именам пользователей ОС или же употреблены в справочнике каталогов LDAP. Устанавливаются такие свойства командами типа:
CREATE/ALTER USER ... IDENTIFIED EXTERNALLY ...
CREATE/ALTER USER ... IDENTIFIED GLOBALLY AS ...
В любом случае речь идет о передаче задачи аутентификации внешним по отношению к Oracle средам: ОС или серверу каталогов, и ответственность за несанкционированное проникновение перекладывается на них. Иногда (но не обязательно) это позволяет обеспечить даже лучшую защищенность, чем ту, что дает СУБД Oracle.
Пользователи Oracle с подобными свойствами тоже могут обладать привилегией SELECT ANY TABLE, позволяющей читать любые свертки (с учетом оговорки, сделанной выше).
Кроме того, привилегией SELECT ANY TABLE обладают и многие пользователи-схемы, штатно включаемые в состав БД в Oracle. Если администратор не изменит исходно установленные для них пароли, возникает риск несанкционированного прочтения свертки паролей прочих пользователей. Список исходных паролей для многих штатных пользователей Oracle можно найти на www.cirt.net и в документе на www.oracle.com.
Ответ фирмы Oracle на слабости парольной защиты
В ответ на опубликование 18 октября 2005 года [1] фирма Oracle 10 ноября того же года опубликовала Note:340240.1 на metalink.oracle.com.
Фирма рекомендует использовать управление паролями с помощью профилей, в частности, часто менять пароль и выбирать пароли не короче 12 символов.
Пример функции проверки выставляемых паролей давно имеется в штатной поставке Oracle в файле utlpwdmg.sql. Пример употребления может выглядеть так:
SQL> CONNECT / AS SYSDBA
Connected. SQL> @?/rdbms/admin/utlpwdmg
Function created.
Profile altered.
SQL> ALTER USER scott IDENTIFIED BY tiger;
ALTER USER scott IDENTIFIED BY tiger * ERROR at line 1: ORA-28003: password verification for the specified password failed ORA-20003: Password should contain at least one digit, one character and one punctuation SQL> ALTER USER scott IDENTIFIED BY tiger_1234567;
User altered.
SQL> SELECT * FROM user_history$;
USER# PASSWORD PASSWORD_ ---------- ------------------------------ --------- 38 F1A76B5340C01290 25-APR-07
(Сценарий utlpwdmg.sql не только заводит функцию SYS.VERIFY_FUNCTION проверки выбираемого пользователем пароля, но и определяет парольные параметры профиля DEFAULT, в частности PASSWORD_REUSE_TIME. Чтобы отменить их действие, потребуется выставить командой ALTER PROFILE default : значения парольных параметров в UNLIMITED).
Во-вторых, фирма рекомендует защищать все файлы, где может оказаться значение сверток паролей (см. выше).
В-третьих, фирма советует защищать передачу данных по Oracle Net, и в-четвертых - полагаться на внешние системы аутентификации ("беспарольное", с точки зрения СУБД, подключение, см. выше).
В этом же пояснении фирмы приводится ссылка на находящийся в открытом доступе документ с названием "Oracle Database Security Checklist", говорящем за себя. Документ датирован уже январем 2007 года; знакомство с ним систематизирует многое из рассмотренного выше.
Неизменным пока остается самое уязвимое место в парольной защите Oracle: алгоритм вычисления свертки. Вероятное решение этой проблемы - дождаться версии 11 СУБД Oracle. По неофициальным сведениям в этой версии будет-таки введено различие больших и малых букв в пароле и алгоритм DES заменен на более современный, SHA-1 или AES. Обработка паролей в версиях вплоть до 10.2, вероятно, меняться не будет.
Оба стихотворения маститых поэтов, написанные с разрывом в несколько десятков лет, посвящены одной и той же статуе, доныне сидящей в парке близ Екатерининского дворца в Царском селе, расположенном неподалеку от кажется большого города, но без названия, вместо которого на карте находится другой город, всего за 300 лет пять раз принимавший четыре разных исторических названия, два из которых пока что русские, а два - немецкие. Одна из рекомендаций, приводимых в статье - почаще и разнообразнее менять пароли пользователей.
Реализация парольной защиты в Oracle
Основным принятым средством аутентификации (проверки подлинности) пользователя Oracle и включаемой/выключаемой роли является указание пароля. Так, пароль указывается при выполнении соединения с СУБД (например, в SQL*Plus в команде CONNECT), в предложении SQL создании пользователя или в полном определении связи с посторонней БД (database link).
СУБД Oracle, подобно всем, реально
СУБД Oracle, подобно всем, реально конкурирующим с ней, является старой системой, создание которой происходило, как и продолжается ныне развитие, в рыночных условиях. В этой СУБД, как и у конкурентов, есть целый ряд конструктивных решений, принятых в свое время второпях, и со временем ставших неудовлетворительными. Что-то удается усовершенствовать: например механизмы выделения динамической памяти для текущих нужд СУБД, регулирования доступа к общим ресурсам СУБД или буферизации блоков данных. Однако некоторые заложенные на ранних стадиях развития механизмы или же не удается изменить вовсе (недоразвитое понятие схемы БД) или удается, но с большим запозданием. К числу последних относится механизм парольной защиты пользователей (user) и ролей (role). Особенности парольной защиты Oracle, способствующие несанкционированному проникновению в БД, затронуты в этой статье.
Приведенный материал существенно использует сведения из red-database-security.com, petefinnigan.com, isc.sans.org.
Взлом пароля
Подбор пароля в Oracle облегчается свойствами принятого алгоритма вычисления свертки ([1]).
А) Сведение алфавита к одним только большим буквам существенно упрощает перебор. Имея в виду 26 больших букв латинского алфавита и 10 цифр, разных паролей длиною n может быть 36n; если же буквы могуг быть и большие, и маленькие, их полное число становится 52, и паролей может быть 62n. (Может показаться, что эти числа чуть преувеличены, так как Oracle не позволяет начинать пароль с цифры, однако такую проверку СУБД делает в момент установления пароля, а это легко нейтрализовать:
SQL> ALTER USER scott IDENTIFIED BY a;
User altered.
SQL> ALTER USER scott IDENTIFIED BY 1;
ALTER USER scott IDENTIFIED BY 1 * ERROR at line 1: ORA-00988: missing or invalid password(s)
SQL> ALTER USER scott IDENTIFIED BY 1a;
ALTER USER scott IDENTIFIED BY 1a * ERROR at line 1: ORA-00988: missing or invalid password(s)
SQL> ALTER USER scott IDENTIFIED BY "1";
User altered.
SQL> CONNECT scott/1
Connected.
Но даже если бы такое ограничение существовало, оно бы не делало погоды в сокращении объемов перебора).
Б) Знание свертки и имени пользователя позволяет сократить перебор вариантов.
В) Свертка вычисляется только на основе имени и пароля, так что сам подбор можно осуществлять в собственной базе, "на стороне", не оставляя следов в исходной базе и не испытывая проблем соединения с ней.
Г) Хотя сложность взлома шифрования DES достаточно велика, по нынешним меркам этот алгоритм уже не считается достаточно стойким.
Сам подбор возможен как на основе списков наиболее употребимых паролей, так и грубым перебором.
На red-database-security.com приводится пример программы, подбирающей пароль перебором, отталкиваясь от известного имени пользователя и известной свертки. Еще одна ссылка на подобную программу приведена в [1]: это программа RainbowCrack . Приведенное время распознавания 8-символьного пароля для пользователя SYSTEM последней программой примерно 4 минуты; тем не менее оригинальная программа потребовала корректировки. Есть и другие подобные программы.
Использование кириллицы в PDF-отчётах Oracle Reports на Unix-платформах
Алексей Золотарёв,
Консультант по программным продуктам Oracle компании
Источник:
Настройка Oracle Reports на примере простого документа
Рассмотрим настройку сервера отчётов на примере конфигурирования системы для формирования отчёта на основе файла report.rdf, содержащего символы кириллицы.
Формируем отчёты без претензий к внешнему виду документа
На этом шаге мы выполняем набор действий, который позволяет нам получить PDF-документ в качестве отчёта и убедиться в том, что отчёт всё-таки формируется. Кириллица, скорее всего, будет представлена в виде каких-либо нечитаемых символов, но на это пока обращать внимания не стоит.
Копируем файл report.rdf в отдельный каталог:
cp report.rdf ~/reports Редактируем файл $ORACLE_HOME/bin/reports.sh и изменяем строки с настройками для переменных окружения REPORTS_PATH и NLS_LANG:
REPORTS_PATH=~/reports; export REPORTS_PATH NLS_LANG=RUSSIAN_CIS.CL8MSWIN1251; export NLS_LANG
Выполняем операцию по замене значения поля EncodingScheme с AdobeStandardEncoding на FontSpecific в AFM-файлах (см. Metalink Note:300416.1, где даётся объяснение необходимости этого действия). Это проще всего выполнить при помощи простого скрипта:
#!/bin/sh for i in `ls $ORACLE_HOME/guicommon9/tk/admin/AFM/*` ; do cat "$i" | sed 's/AdobeStandardEncoding/FontSpecific/g' > "${i}.replaced" mv "${i}.replaced" "$i" done
Запускаем сервер приложений:
$ORACLE_HOME/opmn/bin/opmnctl startall
Получаем PDF-документ, обратившись по адресу:
http://yourhost:port/reports/rwservlet?report=report.rdf&destype=cache&desformat=pdf
Отчёт будет выглядеть примерно так:

Настраиваем механизм Font Subsetting
Теперь нужно сконфигурировать сервер отчётов таким образом, чтобы в получаемых PDF-документах можно было распознать кириллицу и прочитать текст. Для этого требуется использовать механизм Font Subsetting, который заставляет сервер отчётов на этапе формирования документа встроить в файл описание глифов символов.
Суть данной настройки состоит в том, что мы должны разместить на сервере ttf-файлы с шрифтами и произвести сопоставление шрифта в документе с конкретным ttf-файлом в операционной системе.
Размещаем файлы в каталоге операционной системы.
Я для решения этой задачи воспользовался готовым пакетом msttcorefonts-1.2-3.noarch.rpm, который размещает в каталоге /usr/X11R6/lib/X11/fonts/msttcorefonts ttf-файлы ряда популярных шрифтов. Нас интересуют следующие файлы:
Шрифт Arial: arialbd.ttf arialbi.ttf ariali.ttf arial.ttf Шрифт Courier: courbd.ttf courbi.ttf couri.ttf cour.ttf Шрифт Times New Roman: timesbd.ttf timesbi.ttf timesi.ttf times.ttf
Если у вас возникли проблемы с поиском этого пакета, то вы можете воспользоваться ttf-файлами шрифтов, взятыми из-под операционной системы Windows.
Редактируем файл $ORACLE_HOME/bin/reports.sh, сообщая через переменную REPORTS_PATH серверу отчётов месторасположение файлов шрифтов:
REPORTS_PATH=~/reports:/usr/X11R6/lib/X11/fonts/msttcorefonts; export REPORTS_PATH
Указываем серверу отчётов, в каких файлах содержатся шрифты. Для этого нужно сопоставить в конфигурационном файле имя шрифта, используемого в отчёте, с именем ttf-файла. Данная операция выполняется путём редактирования конфигурационного файла $ORACLE_HOME/ guicommon9/tk/admin/uifont.ali. В этом файле уже по умолчанию прописан ряд настроек, который определяет псевдонимы для шрифтов. Нам необходимо в разделе [ PDF:Subset ] сопоставить псевдоним с именем ttf-файла шрифта:
times..Italic.Bold.. = "timesbi.ttf" times...Bold.. = "timesbd.ttf" times..Italic... = "timesi.ttf" times..... = "times.ttf"
helvetica..Italic.Bold.. = "arialbi.ttf" helvetica...Bold.. = "arialbd.ttf" helvetica..Italic... = "ariali.ttf" helvetica..... = "arial.ttf"
courier..Italic.Bold.. = "courbi.ttf" courier...Bold.. = "courbd.ttf" courier..Italic... = "couri.ttf" courier..... = "cour.ttf"
Перезапускаем сервер отчётов:
$ORACLE_HOME/opmn/bin/opmnctl restartproc process-type=OC4J_BI_Forms
Обращаемся к серверу отчётов по адресу
http://yourhost:port/reports/rwservlet?report=report.rdf&destype=cache&desformat=pdf
мы увидим отчёт с кириллицей, но текст будет не выровнен:

Итак, мы убедились, что в документ попала информация шрифтов и она используется программой Acrobat Reader при отображении. То, что кириллица не выровнена, это нормально на данном этапе, поскольку мы только настроили включение информации шрифтов в PDF-документ, но не сообщали серверу отчётов о метриках шрифтов для корректной разметки отчёта.
Настраиваем сервер отчётов на использование метрик новых шрифтов
Получаем файлы метрик. Это можно сделать с помощью пакета ttf2pt1, который можно скачать здесь и который позволяет сгенерировать AFM-файл метрик из ttf-файла шрифта. Так, например, для шрифта Arial из файла arial.ttf нужно выполнить такую команду:
ttf2pt1 -l cyrillic -G A arial.ttf - > Arial
Обратите внимание на название AFM-файла, которое нужно сделать равным полю FullName этого файла.
Таким образом для наших 12 шрифтов мы получим 12 AFM файлов
Arial Arial Italic Arial Bold Arial Bold Italic
Courier New Courier New Italic Courier New Bold Courier New Bold Italic
Times New Roman Times New Roman Italic Times New Roman Bold Times New Roman Bold Italic
Эти файлы следует разместить в каталоге $ORACLE_HOME/guicommon9/tk/admin/AFM
Вносим в файл $ORACLE_HOME/guicommon9/tk/admin/uiprint.txt определение нового принтера, добавив строку:
cyrillic:Postscript:1:Configure your uiprint.txt file:cyrillic.ppd:
Под термином “принтер” здесь далее имеется ввиду логический принтер, который позволяет корректно отформатировать данные, которые в дальнейшем будут отправлены на физический принтер. В частности, этот логический принтер предоставляет серверу отчётов информацию о шрифтах физического принтера, отступах в документе, и прочие данные.
Создаём файл cyrillic.ppd, описывающий принтер. Его можно создать на основе файла datap462.ppd:
cd $ORACLE_HOME/guicommon9/tk/admin/PPD cp datap462.ppd cyrillic.ppd
В описании принтера определяем его шрифты. Этот принтер будет использовать шрифты, содержащие кириллицу.
В файле $ORACLE_HOME/guicommon9/tk/admin/PPD/cyrillic.ppd заменяем строки:
*% Font Information ==================== *DefaultFont: Courier *Font Courier: Standard "(001.004)" Standard ROM *Font Courier-Bold: Standard "(001.001)" Standard ROM *Font Courier-BoldOblique: Standard "(001.001)" Standard ROM *Font Courier-Oblique: Standard "(001.001)" Standard ROM *Font Helvetica: Standard "(001.001)" Standard ROM *Font Helvetica-Bold: Standard "(001.001)" Standard ROM *Font Helvetica-BoldOblique: Standard "(001.001)" Standard ROM *Font Helvetica-Oblique: Standard "(001.001)" Standard ROM *Font Symbol: Special "(001.001)" Special ROM *Font Times-Bold: Standard "(001.001)" Standard ROM *Font Times-BoldItalic: Standard "(001.001)" Standard ROM *Font Times-Italic: Standard "(001.001)" Standard ROM *Font Times-Roman: Standard "(001.001)" Standard ROM
на
*% Font Information ==================== *DefaultFont: Courier New * Font Times New Roman: Standard "(001.001)" Standard ROM *Font Times New Roman Bold: Standard "(001.001)" Standard ROM *Font Times New Roman Bold Italic: Standard "(001.001)" Standard ROM *Font Times New Roman Italic: Standard "(001.001)" Standard ROM *Font Arial: Standard "(001.004)" Standard ROM *Font Arial Bold: Standard "(001.004)" Standard ROM *Font Arial Bold Italic: Standard "(001.004)" Standard ROM *Font Arial Italic: Standard "(001.004)" Standard ROM *Font Courier New: Standard "(001.004)" Standard ROM *Font Courier New Bold: Standard "(001.001)" Standard ROM *Font Courier New Bold Italic: Standard "(001.001)" Standard ROM *Font Courier New Italic: Standard "(001.001)" Standard ROM
Поскольку для шрифтов в описании принтера cyrillic мы используем полные имена шрифтов, то файл псевдонимов $ORACLE_HOME/guicommon9/tk/admin/uifont.ali нуждается в модификации. Мы можем в файле убрать определения всех псевдонимов и привести его к такому виду:
[ Global ] [ Printer ] [ Printer:PostScript1 ] [ Printer:PostScript2 ] [ Printer:PCL5 ] [ Display ] [ Display:Motif ] [ Display:CM ] [ PDF ] [ PDF:Embed ] [ PDF:Subset ]
"Times New Roman"..Italic.Bold.. = "timesbi.ttf" "Times New Roman"...Bold.. = "timesbd.ttf" "Times New Roman"..Italic... = "timesi.ttf" "Times New Roman"..... = "times.ttf"
Arial..Italic.Bold.. = "arialbi.ttf" Arial...Bold.. = "arialbd.ttf" Arial..Italic... = "ariali.ttf" Arial..... = "arial.ttf"
"Courier New"..Italic.Bold.. = "courbi.ttf" "Courier New"...Bold.. = "courbd.ttf" "Courier New"..Italic... = "couri.ttf" "Courier New"..... = "cour.ttf"
Таким образом, сервер отчётов, зная через файл описания принтера о том, что принтер обладает соответствующим шрифтами, содержащими кириллицу, всё-таки встраивает в PDF-документ шрифты. И эти встроенные шрифты будут использоваться при печати или просмотре документа. То есть, мы специально создаём ситуацию, когда, с одной стороны, вроде бы принтер и обладает шрифтами и знает что-то про них (метрики), но с другой стороны, мы специально добиваемся того, чтобы шрифты попали в документ, поскольку маловероятно, что реальный физический принтер или программа Acrobat Reader всё-таки будут иметь эти шрифты на своей стороне.
В файле $ORACLE_HOME/bin/reports.sh указываем, что сервер отчётов должен использовать принтер cyrillic при формировании отчёта. Для этого мы должны в файле закомментировать строку, устанавливающую значение переменной REPORTS_NO_DUMMY_PRINTER:
#REPORTS_NO_DUMMY_PRINTER=TRUE; export REPORTS_NO_DUMMY_PRINTER
Добавить две строки, устанавливающие значения переменных TK_PRINTER и TK_PRINT_STATUS:
TK_PRINTER=cyrillic; export TK_PRINTER TK_PRINT_STATUS=echo; export TK_PRINT_STATUS
Перезапускаем сервер отчётов:
$ORACLE_HOME/opmn/bin/opmnctl restartproc process-type=OC4J_BI_Forms
Обратившись к серверу отчётов по адресу
http://yourhost:port/reports/rwservlet?report=report.rdf&destype=cache&desformat=pdf
мы получаем корректно сформированный отчёт, в котором присутствует кириллица и текст выровнен в соответствии с размерами символов:

Обзор используемого решения
Если администратор сервера приложений в процессе настройки сервера отчётов выполнил только минимальный набор действий по настройке, то при попытке сформировать PDF-отчёт, который должен содержать кириллицу, пользователь получит документ, который при просмотре через программу Acrobat Reader будет нечитаемым или неверно размеченным.
Почему так происходит? Даже если документ с точки зрения сервера Oracle Reports был сформирован корректно, то всё равно существует целый комплекс причин, из-за которых внешний вид текста в PDF-документе может отличаться от ожидаемого результата. Основными причинами являются:
Acrobat Reader не находит шрифтов для отображения кириллицы. Во время формирования документа сервер отчётов пользовался неверными файлами метрик шрифтов.
Рассмотрим эти вопросы более детально:
Для того, чтобы корректно отобразить кириллицу на экране, программа Acrobat Reader должна откуда-то взять описания глифов символов в PDF-документе. Существуют два варианта решения:
В документе указано название шрифта, а сам шрифт будет найден в среде Acrobat Reader, либо в операционной системе Шрифт встроен в PDF-документ.
Первый вариант является очень ненадёжным, потому что он предполагает наличие на стороне клиента определённой конфигурации в виде “правильной” версии Acrobat Reader.
Второй вариант решения хоть и увеличивает размер документа за счёт наличия в нём шрифтов, но он даёт определённую гарантию того, что PDF-отчёт будет корректно отображён у каждого пользователя, независимо от того, есть ли у него необходимые шрифты на машине или нет. Надо сказать, что существуют два способа встраивания шрифта в документ: шрифт может быть включён в документ полностью с описанием всех глифов, либо шрифт может быть встроен частично, когда в PDF-файле присутствуют описания и глифы только тех символов, которые присутствуют в документе. Каждый из этих методов имеет свои недостатки и преимущества, детальное обсуждение которых выходит за рамки статьи.
Как правило, в PDF-документах очень редко используются моноширинные шрифты, все символы которых имеют одинаковую ширину, поэтому важным фактором при формировании документа сервером отчётов является предоставление информации о размерах используемых шрифтов в виде AFM-файлов метрик. В них содержатся такие данные шрифта, как ширина, высота, стиль символов, и эта информация позволяет серверу отчётов на этапе формирования PDF-файла верно рассчитать месторасположение строк на листе документа.
Таким образом, конфигурируя сервер отчётов на работу с шрифтами, содержащими кириллицу, мы должны уделить особое внимание настройке двух опций сервера отчётов:
Встраивание используемого шрифта с кириллицей в PDF-документ. Предоставление AFM-файлов метрик шрифтов серверу отчётов
Обзор процесса настройки
Процесс настройки сервера отчётов на использование кириллицы при формировании отчётов целесообразно разбивать на три этапа:
Настраиваем сервер отчётов на создание документов, не затрагивая вопросы корректного отображения символов. Настраиваем сервер отчётов на включение в PDF-документ информации о шрифтах, используя механизм Font Subsetting. Настраиваем сервер отчётов на использование информации о метриках шрифтов, содержащих кириллицу, при построении PDF-документа.
Следование этим действиям позволяет наиболее аккуратно и последовательно настроить сервер отчётов. При возникновении каких-либо несоответствий на том или ином этапе мы можем однозначно диагностировать причину проблемы.
Одним из ключевых факторов, влияющих
Одним из ключевых факторов, влияющих на принятие решение выбора операционной системы для использования в ней компонента Oracle Reports сервера приложений OracleAS, является корректность работы сервера отчётов с русским языком на той или иной платформе.
К большому сожалению, процесс настройки сервера отчётов на полноценное восприятие кириллицы не является прозрачным для Unix-платформ. Причина кроется в том, что имеется принципиальная разница между архитектурой механизма формирования документов в среде Oracle Reports в операционных системах Windows и Unix. Как результат, в Unix-системах администратор сервера приложений должен выполнить ряд действий для того, чтобы получать в качестве результата работы сервера отчётов качественные документы. Большая гибкость настройки сервера отчётов и, как следствие, обширная информация по методике настройке в стандартной документации и публикациях на сайте Metalink (сайт технической поддержки Oracle) играет, как ни странно, плохую шутку с администраторами сервера отчётов в Unix-платформах – читая документы, очень легко запутаться и так и остаться с нерешённым вопросом по настройке сервера отчётов для формирования документов, содержащих кириллицу.
Цель данной статьи состоит в том, чтобы продемонстрировать основные действия, которые необходимо выполнить на Unix-платформе для получения качественных отчётов Oracle Reports, содержащих кириллицу. В статье для демонстрации используется операционная система Red Hat Linux Advanced Server и “чистый” сервер приложений Oracle Application Server 10.1.2.0.2.
Подготовка к выдаче
Пусть из программы, работающей от имени пользователя SCOTT, требуется выдать данные в формате MS Word. Для этого пользователь SCOTT должен обладать определенными правами и быть владельцем определенных объектов.
Войдем в SQL*Plus как SYS и выдадим привилегию:
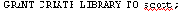
Привилегия CREATE LIBRARY относительно редкая и используется в связи с т. н. “библиотекой”, обеспечивающей общение с внешними программами на C, но здесь к ее выдаче можно отнестись чисто прагматически, не вдаваясь в детали.
Следующим шагом войдем в схему SCOTT и подготовим в схеме инфраструктуру для COM Automation:
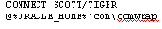
Проследите по таблице USER_OBJECTS появившиеся новые объекты. Они позволят организовать работу и с другими COM-объектами: Excel, PowerPoint и MAPI.
Выполним конкретно для MS Word:
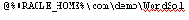
Снова проверьте изменения в схеме по таблице USER_OBJECTS.
Рабочая платформа и общие положения
Возможность выдавать данные в формате Word реализована через механизм обращения к COM Automation. Как и следовало ожидать, использовать ее можно только в СУБД Oracle, работающей на платформе Windows. Для того, чтобы она была осуществима, требуется выполнить некоторые подготовительные действия:
установить компоненты COM Automation при установке программной среды СУБД
подготовить конфигурацию Oracle Net
прогнать в конкретной схеме общий сценарий для возможности взаимодействия с COM Automation
прогнать в этой же схеме специальный сценарий для возможности экспорта данных в MS Word
в силу его простоты, большого
PL/SQL, в силу его простоты, большого программного задела и эффективностью доступа к данным в БД, продолжает оставаться активным языком разработки прикладного ПО в Oracle. Поэтому естественно и нередко возникает желание использовать его не только для обработки данных, но и для связи с внешним, по отношению к Oracle, миром. В принципе такие возможности в PL/SQL достаточно широки благодаря праву обратиться из программ на этом языке ко внешним процедурам на C, к программам на Java и некоторым системным пакетам типа DBMS_PIPE. Однако в общем случае это будут довольно громоздкие решения, которые требуют от разработчика определенной квалификации. В то же время для некоторых частных задач в PL/SQL могут существовать и более простые методы. Здесь будет рассмотрен один такой пример: способ выдачи данных из программы на PL/SQL в файл формата MS Word.
Выдача данных из программы на PL/SQL в формате MS Word
,
координатор Евро-Азиатской Группы Пользователей Oracle,
преподаватель
с помощью Oracle Universal Installer
Когда вы выполните с помощью Oracle Universal Installer шаг 1, в %ORACLE_HOME% появится каталог com с примерами и объяснениями на английском языке. Там же, в каталоге %ORACLE_HOME%\com\demo лежат примеры и для выдачи из PL/SQL в MS Excel, MAPI и PowerPoint. Эти примеры устроены аналогично более востребованному примеру для MS Word, рассматриваемому в этой статье.
Взаимодействие с COM Automation реализуется в Oracle через внешние программы, а общение с ними из PL/SQL выполняется средствами сетевой поддержки. Поэтому чтобы все работало, нужно изменить конфигурационные файлы Oracle Net: listener.ora на сервере и tnsnames.ora на клиенте. В последних версиях Oracle этим специально можно не заниматься, так как обычно они содержат нужные настройки автоматически, после установки ПО Oracle на компьютер.
Тем не менее, нелишне проверить следующее.
В файле listener.ora должен быть примерно следующий фрагмент:

В файле tnsnames.ora должен быть следующий фрагмент:
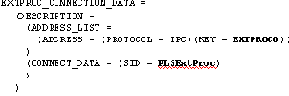
Если у вас на компьютере каталог ORACLE_HOME или название LISTENER процесса-“привратника” другие, нужно проставить то, что есть.
Шаги 3 и 4 рассматриваются ниже.
Выводим список сотрудников из БД в Word
Выполним в SQL*Plus:


В каталоге c:\ должен появиться файл worddemo со списком сотрудников в формате MS Word.
Черный ход в черный ящик
Если вы - АБД, отвечающий за работу приложения стороннего производителя на базе СУБД Oracle, то, наверняка, испытывали разочарование, обнаружив в библиотечном кэше пару крайне медленно работающих и пожирающих массу ресурсов SQL-операторов, которые очень легко можно настроить,- если бы только можно было добавить пару подсказок оптимизатору в исходный код.
Начиная с Oracle 8.1, вам больше не надо переписывать SQL-операторы, чтобы добавить подсказки - можно передать оптимизатору подсказки, не меняя код. Эта возможность известна как использование хранимых шаблонов (Stored Outlines) или стабилизация плана оптимизатора (Plan Stability), причем, сонвная ее идея весьма проста: вы сохраняете в базе данных информацию типа: "если встречается SQL-оператор типа XXX, то перед его выполнением надо вставить вот такие подсказки в следующих местах..."
Эта возможность дает вам три потенциальных преимущества. Прежде всего, можно оптимизировать ту самую пару пожирающих ресурсы операторов. Далее, если есть друшгие операторы, которые сервер Oracle дольше оптимизирует, чем выполняет, можно сэкономить время и уменьшить количество конфликтов на стадии оптимизации. Наконец, можно использовать новый параметр конфигурации cursor_sharing, не рискуя потерять оптимальные пути выполнения операторов.
Есть несколько проблем в Oracle 8i, которые при этом придется как-то обходить (они практически решены в Oracle 9i), но, в общем случае, использовать хранимые шаблоны очень легко. В этой статье описаны некоторые возможности, которые при этом открываются.
Что хочет сделать приложение?
Теперь, когда исследуемое приложение готово, можно запустить его, включив, пожалуй, предварительно sql_trace, чтобы понять, что происходит. Неудивительно, если окажется, что SQL-оператор выполняет полный просмотр таблицы для получения необходимых данных.
В этом небольшом тесте полный просмотр, скорее всего, является самым эффективным способом выполнения запроса, но, предположим, мы доказали, что более высокая производительность достигается, когда сервер Oracle использует план на базе одностолбцовых индексов и опции and-equal. Как заставить сервер выполнять запрос именно так, не добавляя в код подсказки оптимизатору?
После появления хранимых шаблонов ответ простой. На самом деле, есть есть несколько способов добиться этого, так что не рассматривайте данный пример как единственно возможную стратегию. С каждой новой версией возможности сервера Oracle расширяются, чтобы упростить жизнь пользователям, и описанный далее механизм, наверняка, не понадобится в следующих версиях.
Что, по вашему, должно делать приложение?
Чтобы заставить сервер Oracle делать то, что нужно нам, необходимо пройти три этапа:
Начинаем новый сеанс и повторно выполняем процедуру, потребовав предварительно от сервера Oracle перехватывать каждый поступающий SQL-оператор вместе с информацией о плане его выполнения. Эти "планы" станут нашим первым примером хранимых шаблонов.
Создаем более подходящие шаблоны для всех проблемных SQL-операторов и заменяем "плохие" хранимые шаблоны хорошими.
Начинаем новый сеанс и требуем от сервера Oracle начать использовать новые хранимые шаблоны вместо обычных методов оптимизации при обработке соответствующих SQL-ператоров. Затем снова выполняем процедуру.
Надо завершать текущий и начинать новый сеанс, чтобы гарантировать, что существующие курсоры не остались открытыми в кэше pl/sql. Хранимые шаблоны генерируются и/или применяются только при анализе операторов, так что надо гарантировать, что уже существующие курсоры для аналогичных операторов закрыты.
Итак, начнем сеанс и выполним следующую команду:
alter session set create_stored_outlines = demo;
Затем выполним небольшой анонимный блок, вызывающий процедуру, например:
declare m_value varchar2(10); begin get_value(1, 1, m_value); end; /
Теперь прекращаем сбор планов выполнения (иначе несколько следующих SQL-операторов тоже окажутся в таблицах хранимых шаблонов, что усложнит выполнение дальнейших действий).
alter session set create_stored_outlines = false;
Для просмотра результатов выполненных действий можно сделать запросы к представлениям, позволяющим получить детальную информацию о шаблонах, автоматически созданных и сохраненных сервером Oracle:
select name, category, used, sql_text from user_outines where category = 'DEMO';
NAME CATEGORY USED ------------------------------ ------------------------------ ------- SQL_TEXT --------------------------------------------------------------------- SYS_OUTLINE_020503165427311 DEMO UNUSED SELECT V1 FROM SO_DEMO WHERE N1 = :b1 AND N2 = :b2
select name, stage, hint from user_outline_hints where name = ' SYS_OUTLINE_020503165427311';
NAME STAGE HINT ------------------------------ ---------- ------------------------------ SYS_OUTLINE_020503165427311 3 NO_EXPAND SYS_OUTLINE_020503165427311 3 ORDERED SYS_OUTLINE_020503165427311 3 NO_FACT(SO_DEMO) SYS_OUTLINE_020503165427311 3 FULL(SO_DEMO) SYS_OUTLINE_020503165427311 2 NOREWRITE SYS_OUTLINE_020503165427311 1 NOREWRITE
Как видите, есть категория, demo, включающая всего лишь один хранимый шаблон, а посмотрев на sql_text для этого шаблона можно увидеть нечто похожее на SQL-оператор в исходном PL/SQL-коде, но не точно совпадающее с ним. Это существенно, поскольку сервер Oracle будет рассматривать возможность использования хранимого шаблона только если сохраненное значение sql_text очень близко к тексту SQL-оператора, который требуется выполнить. Фактически, в Oracle 8i тексты должны совпадать буквально, и первоначально это было большой проблемой при экспериментах с хранимыми шаблонами.
По листингу видно, что хранимые шаблоны представляют собой набор подсказок, описывающих действия сервера Oracle, который он выполнил (или должен выполнить) при выполнении соответствующего SQL-оператора. Данный план использует полный просмотр таблицы. Не правда ли, сервер Oracle используем немало подсказок, чтобы гарантировать выполнение настолько простого действия, как полный просмотр таблицы?..
Обратите внимание, что хранимый шаблон всегда относится к определенной категории, в данном случае, к категории demo, которую мы задали в исходной команде alter session. Если в исходной команде просто указать true вместо demo, хранимые шаблоны окажутся в категории по имени default.
Хранимые шаблоны тоже имеют имена, и эти имена должны быть уникальными во всей базе данных. Имя шаблона не может совпадать с именем другого шаблона, даже сгенерированного другим пользователем. Фактически, у шаблонов нет владельцев, - есть только создатели. Если кто-то создал хранимый шаблон, соответствующий выполняемому мной в дальнейшем SQL-оператору, сервер Oracle применит соответствующий набор подсказок к моему тексту, даже если эти подсказки лишены смысла в контексте моей схемы. (Это дает нам несколько абсолютно новых возможностей для формирования хранимых шаблонов, и заслуживает отдельной статьи). Можно заметить, что когда сервер Oracle автоматически генерирует хранимые шаблоны, имена имеют простой формат и включают временную отметку (время создания) с точностью до миллисекунды.
Продолжая процесс "настройки" нашего проблематичного SQL-оператора, мы решаем, что если добавить подстказку /*+ and_equal(so_demo, sd_i1, sd_i2) */, сервер Oracle будет использовать необходимый нам план выполнения, так что, теперь мы явно создает хранимый шаблон следующим образом:
create or replace outline so_fix for category demo on select /*+ and_equal(so_demo, sd_i1, sd_i2) */ v1 from so_demo where n1 = 1 and n2 = 2;
Этот оператор создает хоранимый шаблон с явно заданным именем so_fix в категории demo. Вид хранимого шаблона можно получить, повторив запросы к user_outlines и user_outline_hints с добавлением условия name = 'SO_FIX'.
NAME CATEGORY USED ------------------------------ --------------------- --------- SQL_TEXT --------------------------------------------------------------- SO_FIX DEMO UNUSED select /*+ and_equal(so_demo, sd_i1, sd_i2) */ v1 from so_demo where n1 = 1 and n2 = 2
NAME STAGE HINT ------------------------------ ---------- -------------------------------- SO_FIX 3 NO_EXPAND SO_FIX 3 ORDERED SO_FIX 3 NO_FACT(SO_DEMO) SO_FIX 3 AND_EQUAL(SO_DEMO SD_I1 SD_I2) SO_FIX 2 NOREWRITE SO_FIX 1 NOREWRITE
Обратите внимание, в частности, что строка FULL(SO_DEMO)
заменена строкой AND_EQUAL(SO_DEMO SD_I1 SD_I2), что и требовалось.
Теперь надо "поменять местами" эти два хранимых шаблона. Мы хотим, чтобы сервер Oracle использовал наш новый список подсказок при выполнении оператора с исходным текстом; и для этого придется прибегнуть к трюку. Представления user_outlines и user_outline_hints
созданы на основе двух таблиц (ol$ и ol$hints, соответственно), принадлежащих схеме outln, и мы собираемся изменять эти таблицы непосредственно; для этого подключаемся от имени пользователя outln или пользователя, имеющего привилегию изменения этих таблиц.
К счастью, таблицы outln не имеют включенных декларативных ограничений целостности ссылок. Нам на руку то, что взаимосвязь между таблицами ol$ (шаблоны) и ol$hints (подсказки) задается по имени шаблона (которое хранится в столбце ol_name). Поэтому, особо внимательно проверяя имена, мы можем поменять подсказки в хранимых шаблонах, меняя местами имена в таблице ol$hints следующим образом:
update outln.ol$hints set ol_name = decode( ol_name, 'SO_FIX','SYS_OUTLINE_020503165427311', 'SYS_OUTLINE_020503165427311','SO_FIX' ) where ol_name in ('SYS_OUTLINE_020503165427311','SO_FIX');
Вас может смущать непосредственное изменение данных, настолько близких к ядру сервера Oracle, особенно с учетом комментариев в руководствах-- но такое изменение, фактически, санкционировано документом Metalink Note: 92202.1 от 5 июня 2000 года. Однако в этом документе не сказано, что может понадобиться и другой оператор update, гарантирующий согласованность количества подсказок в каждом из хранимых шаблонов с самими подсказками. Если его не обеспечить, может оказаться, что некоторые из хранимых шаблонов повреждены или уничтожены в ходе экспорта/импорта.
update outln.ol$ ol1 set hintcount = ( select hintcount from ol$ ol2 where ol2.ol_name in
('SYS_OUTLINE_020503165427311',' SO_FIX') and ol2.ol_name != ol1.ol_name ) where ol1.ol_name in
('SYS_OUTLINE_020503165427311','SO_FIX');
После замены можно подключиться в новом сеансе, потребовать использовать хранимые шаблоны, повторно выполнить процедуру и завершить сеанс. С помощью sql_trace снова можно будет узнать, как же сервер Oracle фактически обрабатывал SQL-операторы. Чтобы потребовать от сервера Oracle использовать (измененный) шаблон, выполните команду:
alter session set use_stored_outline = demo;
Просмотрев файл трассировки, вы должны обнаружить, что для выполнения SQL-оператора теперь используется план с and_equal. (Если вы используете утилиту tkprof для обработки и изучения файла трассировки, то можете обнаружить в результатах два противоречащих друг другу плана. Первый, правильный, план должен показывать, что используется and_equal, а второй, скорее всего, будет показывать полный просмотр таблицы, поскольку хранимый шаблон мог и не использоваться когда утилита tkprof выполняла explain plan для протрассированного SQL-оператора).
Есть множество других деталей, которые
Есть множество других деталей, которые необходимо учитывать при работе с хранимыми шаблонами. Хранимые шаблоны в версии Oracle 8i имеют ряд неприятных и ограничивающих возможности особенностей. К счастью, многие проблемы решены в Oracle 9.
Самой тривиальной и очевидной проблемой при использовании хранимых шаблонов в Oracle 8 было то, что они могли использоваться только если сохраненный текст в точности совпадал с поступившим. В Oracle 9 применяется "нормализация", ослабляющая это требование совпадения; тексты операторов перед сравнением преобразуются в верхний регистр и все лишние пробелы убираются. Это повышает вероятность, что незначительно отличающиеся SQL-операторы смогут использовать тот же хранимый шаблон.
Есть также ряд проблем с более сложными планами выполнения, включающих несколько блоков запросов -- корпорация Oracle решила их в Oracle 9, добавив третью таблицу в схему outln, ol$nodes. Она помогает серверу Oracle разбивать на части список подсказок в таблице ol$hints и учитывать их в соответствующих фрагментах обрабатываемого SQL-оператора. Это, конечно, хорошо, но может повлиять на стратегию замены подсказок одного хранимого шаблона на подсказки другого, поскольку в таблице ol$hints появились дополнительные детали о длине и смещении фрагментов текста. При переходе на Oracle 9 придется использовать другие методы создания хранимых шаблонов, такие как отдельные схемы со специально подобранными наборами данных или отсутствующими индексами, или представлениями со встроенными подсказками, имена которых совпадают с именами таблиц в тексте настраиваемых операторов.
Также в Oracle 9 появились дополнительные возможности создания требуемых хранимых шаблонов, в том числе, предварительная версия пакета, позволяющего непосредственно редактировать хранимые шаблоны. Важнее, однако, что появилась возможность более безопасной работы с планами, хранящимися в производственной системе. Хотя в производственной среде экспериментировать не любит никто, иногда производственная система - единственное место, где можно получить реальные распределения и объемы данных, позволяющие найти оптимальный план выполнения проблемного SQL-оператора. В Oracle 9 можно создать собственную копию таблиц outln и выбрать в них "общедоступные" хранимые шаблоны для "частных" экспериментов, не рискуя сделать один из экспериментальных хранимых шаблонов видимым для кода конечного пользователя. Лично я выполнял бы такую настройку только в крайнем случае, но вполне могу представить себе ситуацию, когда она может понадобиться. Менее опасно будет экспериментировать в отдельной тестовой системе или в системе разработчика, а там эта возможность позволит выполнять независимое тестирование.
Обзор основных возможностей
Чтобы продемонстрировать, как лучше всего использовать хранимые шаблоны, мы начнем с хранимой процедуры, исходный код которой нельзя изменить, выполняющей (теоретически) ряд крайне неэффективных SQL-операторов.
Мы увидим, как перехватить выполняемые SQL-операторы и особенности текущего пути их выполнения в базе данных, подобрать подсказки, повышающие производительность этих SQL-операторов, а затем заставить сервер Oracle использовать эти подсказки при дальнейшем выполнении этих SQL-операторов.
По ходу демонстрации мы создадим пользователя, таблицу в схеме этого пользователя и процедуру, обращающуюся к этой таблице, - но, ради развлечения, мы применим к процедуре утилиту wrap, чтобы ее код нельзя было увидеть. Затем мы поставим себе задачу настройки производительности SQL-операторов, выполняемых этой процедурой.
При демонстрации мы предполагаем, что все необходимое для использования хранимых шаблонов было установлено автоматически при создании базы данных.
От разработки - к внедрению
Теперь, когда нам удалось создать нужный шаблон, необходимо перенести его в производственную среду. Есть множество небольших полезных особенностей хранимых шаблонов, которые при этом пригодятся. Например, можно переименовать хранимый шаблон, экспортировать его с сервера разработчика, импортировать в производственной системе, проверить, что и там он работает правильно, поместив его в категорию 'test', а затем перевести в производственную категорию. При этом пригодятся команды:
alter outline SYS_OUTLINE_020503165427311
rename to AND_EQUAL_SAMPLE; alter outline AND_EQUAL_SAMPLE
change category to PROD_CAT;
Для экспортирования шаблона из среды разработки в производственную систему можно воспользоваться возможностью добавлять конструкцию where в файле параметров экспорта, что позволяет создать следующий файл:
userid=outln/outln tables=(ol$, ol$hints, ol$nodes) # ol$nodes
существует только в версии 9
file=so.dmp consistent=y # очень важно
rows=yes query='where ol_name = ''AND_EQUAL_SAMPLE'''
Предварительные действия
Создаем пользователя с привилегиями: create session, create table, create procedure, create any outline и alter session. Подключаемся от имени этого пользователя и выполняем следующие операторы для создания таблицы:
create table so_demo ( n1 number, n2 number, v1 varchar2(10) );
insert into so_demo values (1,1,'One');
create index sd_i1 on so_demo(n1); create index sd_i2 on so_demo(n2);
analyze table so_demo compute statistics;
Теперь необходимо создать процедуру, обращающуюся к этой таблице. Создаем сценарий c_proc.sql, содержащий следующий код:
create or replace procedure get_value ( i_n1 in number, i_n2 in number, io_v1 out varchar2 ) as begin select v1 into io_v1 from so_demo where n1 = i_n1 and n2 = i_n2; end; /
Можно, конечно, просто выполнить этот сценарий для построения процедуры, но, для большей эффектности, давайте выполним следующую команду в окне командной строки операционной системы:
wrap iname=c_proc.sql
В ответ вы должны получить:
Processing c_proc.sql to c_proc.plb
Вместо выполнения сценария c_proc.sql для генерации процедуры, выполните неочевидный сценарий c_proc.plb, и вы обнаружите, что никаких следов использованного SQL-оператора в представлении user_source нет.
Проблемы
Эта статья предоставляет достаточно информации для начала экспериментов с хранимыми шаблонами, но есть ряд нюансов, о которых надо знать, прежде чем начать применять шаблоны в производственной системе.
Во-первых, в Oracle 8i стандартный пароль для outln (схемы, которой принадлежат таблицы, используемые для размещения хранимых шаблонов) широко известен, а сама учетная запись имеет очень опасные привилегии. Обязательно поменяйте пароль этой учетной записи. В Oracle 9i вы обнаружите, что эта учетная запись заблокирована.
Во-вторых, таблицы, используемые для размещения хранимых шаблонов, создаются в табличном пространстве system. В производственной системе окажется, что при создании хранимых шаблонов вы используете очень много пространства в табличном пространстве system. Имеет смысл перенести эти таблицы в другое табличное пространство, предпочтительно, - специально для них созданное. К сожалению, одна из таблиц содержит столбец типа long, поэтому для переноса в новое табличное пространство, вероятно, придется использовать exp/imp.
В-третьих, хотя хранимые шаблоны и весьма полезны для решения критических проблем производительности, их использование не дается даром. При активации хранимых шаблонов сервер Oracle проверяет, нет ли подходящего шаблона при анализе каждого нового оператора. Если для множества операторов хранимых шаблонов нет, надо сопоставлять расходы на это дополнительное действие с преимуществами, которые получаются от использования хранимых шаблонов для нескольких избранных операторов. Правда, это, скорее всего, придется учитывать только в системе, имеющей другие, более существенные проблемы производительности.
Стабилизация плана оптимизатора в Oracle 8i/9i
Джонатан Льюис,
Перевод
Узнайте, как с помощью "хранимых шаблонов" (stored outlines) можно повысить производительность приложения, даже если нельзя менять его исходный код, систему индексации и параметры конфигурации системы...
Инструментальные средства: Для упрощения экспериментов, в статье рассматривается только простой SQL- и PL/SQL-код, выполняемый в сеансе SQL*Plus. Читателю необходимы будут привилегии, которые типичным конечным пользователям обычно не предоставляют, но, в остальном, понадобится только знание основ языка SQL. Статья начинается с описания возможностей версии Oracle 8i, но затем автор переходит к Oracle 9i, в котором появилось ряд дополнительных возможностей генерации хранимых шаблонов и работы с ними.
Использование хранимых шаблонов может дать
Использование хранимых шаблонов может дать потрясающие результаты. Если нельзя менять исходный код или стратегию индексирования, хранимый шаблон может оказаться единственным способом заставить приложение стороннего производителя работать эффективно.
Доводя идею до крайности, если перед вами все еще стоит проблема перевода системы с оптимизатора, основанного на правилах, на использование стоимостного оптимизатора, использование хранимых шаблонов может оказаться наиболее выгодным и надежным вариантом ее решения.
Если необходимо получить от хранимых шаблонов максималоную отдачу, используйте версии Oracle 9, в которых имеется ряд расширений, позволяющих покрыть дополнительные классы SQL-операторов, сократить накладные расходы, а также обеспечивающих больше возможностей при тестировании, управлении и установке хранимых шаблонов.
--
Джонатан Льюис () - независимый консультант с более чем 17-летним опытом проектирования и настройки баз данных Oracle. Он - автор книги "Optimizing Oracle 8i", опубликованной издательством Addison-Wesley, разработчик и ведущий семинара "Optimizing Oracle - Performance by Design", а также составитель списка ЧаВО The Co-operative Oracle Users' FAQ, который можно найти на сайте .
Эта первоначально была опубликована на сайте , сетевом портале, посвященном проблемам различных СУБД и их решениям. Перевод публикуется с разрешения автора.
Пользователь или схема?
,
координатор Евро-Азиатской Группы Пользователей Oracle,
преподаватель
СУБД Oracle, как и все ее реальные конкуренты - старая система. Недавно праздновали ее 25-летие. Такое долголетие было бы невозможно без ряда технических решений, удачно (с этой точки зрения) предложенных еще в стародавние времена. Но наряду с этим в системе есть и примеры дефектов начального проектирования. Когда-то они не казались таковыми, а потом исправлять их стало очень сложно, так что только в самых последних версиях, например в 9-ой, стали прощупываться пути решения нечаянно запрограммированной проблемы. Такой является проблема "пользователей" и "схем".
Проблема
В Oracle понятия "схема" и "пользователь" нераздельно слились воедино. Формально два разных слова "user" и "schema" используются в Oracle для обозначения одного и того же: "схемы-пользователя". Документация на этот счет стыдливо говорит, что "при заведении пользователя [с помощью предложения CREATE USER - автор] автоматически создается схема с таким же именем". С другой стороны, отдельных манипуляций со схемами в Oracle не предусмотрено (команда CREATE SCHEMA в Oracle обманчива; она не создает схему, как можно было бы подумать), вот и выходит, в системе понятий Oracle "схема" = "пользователь".
Для разработчика же эти два понятия не идентичны. Так, схема представляет собой своего рода контейнер хранимых в БД объектов, несущий традиционно двойную функциональную нагрузку: как средства организации данных (объектов в базе много, но не всем приложениям все они интересны) и как средство защиты данных от посторонних приложений. Пользователь же, по своей изначальной идее - это конкретное лицо, которое может подключаться к СУБД для работы с теми или иными данными, проверяться на наличие полномочий, контролироваться на предмет совершаемых действий и т. д.
Данные принадлежат информационной системе, предприятию, а пользователи могут наниматься и увольняться. Как сымитировать такой способ работы в Oracle?
Решение
Возможно, кто- то уже придумал свое решение этой проблемы. Если нет - можно воспользоваться предлагаемым ниже.
(1)
Для хранения объектов "отдела кадров" создаем схему (-пользователя) HR:
CREATE USER hr IDENTIFIED BY hr;
Далее по мере необходимого уточняем все свойства этой схемы, например:
ALTER USER hr DEFAULT TABLESPACE hr_ts DEFAULT TABLESPACE temp; и так далее.
(2)
Для физических лиц создаем пользователей Oracle, например:
CREATE USER pete IDENTIFIED BY thisismepete;
CREATE USER mary IDENTIFIED BY maryiam;
…
Далее пользователям нужно приписать необходимые свойства. В типичном случае все они одинаковы, так что имеет смысл написать один-единственный сценарий, который наделял бы каждого нового "Петю" или "Машу" требуемыми полномочиями. Что туда должно входить ? Как минимум, системная привилегия CREATE SESSION. Но кроме этого, для доступа к своим таблицам от имени HR следует выдать что-то вроде
GRANT SELECT, INSERT, UPDATE, DELETE ON main_hr_table TO pete;
(3)
Это еще не все. Пользователь PETE действительно теперь сможет подключаться к СУБД от своего имени и работать с таблицей MAIN_HR_TABLE, однако ссылаться на нее он будет вынужден по полному имени: HR.MAIN_HR_TABLE, так как это не его таблица. Можно ли избежать этого и заставить его чувствовать себя "как дома"? Можно. Ему достаточно выдать:
ALTER SESSION SET CURRENT_SCHEMA=hr;
Удобнее, однако, эту команду "завернуть" в триггер, срабатывающий при подключении к "схеме" PETE, то есть выдать, например, от имени SYS:
CREATE OR REPLACE TRIGGER set_hr_schema_for_pete
AFTER LOGON ON pete.SCHEMA
BEGIN
EXECUTE IMMEDIATE 'ALTER SESSION SET
CURRENT_SCHEMA=hr';
END;
/
Теперь, подключаясь к СУБД, пользователь PETE будет видеть объекты HR "как свои", по короткому имени, правда свои собственные таблицы он вынужден будет называть "целиком", например PETE.MY_PETE_TABLE, но нам, кажется, это и не важно.
Особенности предложенного решения
- его надо автоматизировать
- невозможно создавать и удалять объекты
- можно использовать системный аудит
Альтернатива
Предложена в Oracle 9.0: "корпоративные пользователи" и сервер имен.
