Большие объекты
СУБД Oracle9i предоставляет типы LOB (large object, большой объект) для решения проблем хранения изображений, видеоклипов, документов и других видов неструктурированных данных. Большие объекты хранятся таким образом, чтобы было оптимизировано использование пространства памяти и обеспечен эффективный доступ к ним. Конкретнее, большие объекты состоят из указателей (locators) и связанных с ними двоичных и/или символьных данных. Указатели этих объектов хранятся в строках таблиц вместе со значениями других столбцов. Если применяются внутренние большие объекты (BLOB, CLOB и NCLOB), их данные размещаются в отдельной области хранения. Для внешних же объектов (BFILE) их данные хранятся вне базы данных в файлах операционной системы.
Генерация XML
Пакет DBMS_XMLGEN может принять любой SQL-запрос и отобразить его результаты в XML. Тем самым, весь результирующий набор, возвращенный этим запросом, преобразуется в единый XML-документ. Этот пакет имеет несколько параметров для управления различными аспектами генерации XML, включая генерацию схемы XML Schema, ассоциированной с этим документом (аналогично описанию функциональности), и ограничение числа выбранных строк. Например, следующий фрагмент кода представляет результаты запроса в форме XML-документа, как показано ниже.
qryCtx := dbms_xmlgen.getContextHandle("select * from scott.emp"); result := dbms_xmlgen.getXMLClob(qryCtx); <?xml version="1.0" encoding="SHIFT_JIS"?> <ROWSET> <ROW> <EMPNO>30</EMPNO> <ENAME>Scott</ENAME> <SALARY>20000</SALARY> </ROW> <ROW> <EMPNO>30</EMPNO> <ENAME>Mary</ENAME> <AGE>40</AGE> </ROW> </ROWSET>
Для реляционных данных результаты представляют собой плоский XML-документ без вложенности. Чтобы получить вложенные XML-структуры, можно использовать объектно-реляционные данные. Объект отображается в XML-элемент с атрибутами отображения этого объекта на подэлементы родительского элемента. Экземпляр коллекции также отображается в XML-элемент с элементами коллекции, появляющимися как повторяющиеся экземпляры подэлементов.
Хранение XML-документов
Для облегчения "чистого" (native) хранения и доступа к XML-документам был введен новый тип данных, называемый XMLType. Пользователи могут создавать экземпляры и столбцы этого типа данных и использовать методы типа для извлечения, обхода и трансформации XML-документов.
В столбце типа XMLType можно хранить документы либо в целостном виде (как данные типа CLOB), либо в декомпозированном объектно-реляционном виде. Этот тип позволяет выполнять операции запросов XML-документов: extract() – обход документа и извлечение его фрагмента на основе выражения пути и existsNode() – проверка существования узла, удовлетворяющего заданному условию. Пользователь может также определить текстовый индекс Oracle interMedia по этому столбцу и запрашивать этот XML-документ с применением операции Contains и других операций для работы с текстом.
-- выбрать имя заказчика (custname) из всех сообщений, которые -- являются срочными(urgent) и имеют в PO заказчика (customer) SELECT extract(e.msgVal, "/po/cust/custname") FROM message_tab e WHERE CONTAINS(e.msgVal, "URGENT") > 0 AND existsNode(e.msgVal,"//po/cust") > 0;
Интерфейсы JDBC и SQLJ, утилита JPub
Объектно-реляционные возможности предоставляют более естественный и продуктивный способ для поддержания согласованной структуры набора Java-классов на уровне приложения и модели данных на уровне хранения данных. В СУБД Oracle объектно-реляционные возможности тесно интегрированы со средой Java с помощью стандартных интерфейсов прикладного программирования JDBC и SQLJ. Объектные типы SQL могут быть отображены в Java-классы. Утилита JPublisher (JPub) автоматически генерирует файлы для JDBC или SQLJ с определениями Java-классов, реализующих эти отображения. Каждый сгенерированный Java-класс содержит определенные для него методы чтения состояния объектов с сервера базы данных и записи состояния на сервер. В свою очередь, Java-приложения могут использовать эти сгенерированные Java-классы для сохранения объектов в базе данных и их выборки из базы.
(Прим. ред. О стандарте JDBC см. например, [7]. О спецификациях SQLJ см. например, [8].)
Далее представлены фрагменты кода Java-класса, сгенерированные утилитой JPub.
// Создать Java-класс, который реализует интерфейс SQLData
public class JPurchaseOrder implements SQLData
{
…
public void readSQL (SQLInput stream, String typeName)
throws SQLException {…}
public void writeSQL (SQLOutput stream)
throws SQLException {…}
…
}
Этот Java-класс JPurchaseOrder может быть далее использован в следующей Java-программе для выборки объектов из базы данных.
// Экземпляры объекта можно рассматривать как Java-объекты
ResultSet rs = stmt.executeQuery("select value(p) from
purchase_order_tab p");
rs.next();
JPurchaseOrder jp = (JPurchaseOrder) rs.getObject(1);
String streetName = jp.shipAddr.street;
Эволюция типов
Использование типа позволяет пользователю развивать бизнес-логику, зафиксированную в поведении этого типа. Эволюция типов– это механизм, который позволяет пользователю изменять тип и распространять эти изменения на другие объекты схемы, которые ссылаются на модифицированный тип. К числу объектов схемы, которые могут ссылаться на тип, относятся другие типы, подтипы, объекты-строки, объекты-столбцы (column objects), программные блоки (пакеты, функции, процедуры), представления, функциональные индексы и триггеры.
Поддерживаемые операции эволюции типов:
Операции над атрибутами типов:
добавление атрибута для типа; удаление атрибута типа; модификация типа атрибута (увеличение его длины, точности или масштаба).
Операции над методами типов:
добавление метода для типа; удаление метода типа.
Изменение свойств INSTANTIABLE (абстрактный/не абстрактный тип – не допускает или допускает непосредственное порождение экземпляров объектов) и FINAL (терминальный/нетерминальный тип – нельзя создавать подтипы или можно) объектного типа SQL. Поддержка явного распространения изменений типа на зависимые от него типы и таблицы.
Эти изменения при эволюции типов являются либо структурными (structural), либо неструктурными (non-structural). Структурные изменения воздействуют на состояние объекта; это, например, добавление или удаление атрибута. Неструктурные изменения не затрагивают состояния объекта. Например, переименование атрибута или добавление метода.
Рассмотрим следующий пример: CREATE TYPE address_t AS OBJECT ( street VARCHAR(100), zip_code NUMBER); CREATE TYPE person_t AS OBJECT ( first_name VARCHAR(50). last_name VARCHAR(50), age NUMBER, address address_t); CREATE TABLE person_tab OF person_t;
В этом примере таблица person_tab создается со столбцом для каждого атрибута типа person_t, а также с одним столбцом для каждого атрибута адреса (тип address_t). Рассмотрим следующий пример изменения типа:
ALTER TYPE address_t ADD ATTRIBUTE (country NVARCHAR(100), int_postal_code NVARCHAR(20)) CASCADE;
Результатом этого изменения будет добавление двух столбцов к таблице person_tab, соответствующих только что добавленным атрибутам. Ключевое слово CASCADE распространяет изменения этого типа на зависимые типы и таблицы.
Мастер JPublisher
В состав JDeveloper входит интерфейс Database Browser (браузер базы данных), который позволяет разработчикам получать доступ к содержимому схем своих баз данных и находить объекты Oracle9i. С помощью этого интерфейса можно запустить мастер JPublisher для генерации классов-адаптеров Java (Java wrapper classes) для объектов Oracle9i. Мастер JPublisher облегчает использование объектов Oracle9i в Java-программах, автоматически генерируя определения соответствующих Java-классов. Сгенерированные мастером JPublisher классы-адаптеры включают методы для преобразования данных из SQL в Java и из Java в SQL, а также методы для чтения и записи значений атрибутов этих объектов. Мастер JPublisher повышает производительность труда разработчиков, обеспечивая в то же время гибкость для расширения сгенерированных классов с целью удовлетворения потребностей заказчиков.
После завершения разработки Java-приложения с использованием мастера JDeveloper оно может быть развернуто в различных целевых архитектурах с помощью сервера базы данных Oracle9i и сервера приложений Oracle9i, которые являются универсальными программными платформами для приложений с высокими требованиями.
Механизм сохраняемости, управляемой контейнером с применением объектов Oracle9i
СУБД Oracle9i управляет сохраняемостью компонентов-сущностей EJB, используя таблицы базы данных. Каждый экземпляр компонента-сущности соответствует строке в таблице, и каждое CMP-поле соответствует столбцу в этой таблице. Для класса компонента-сущности также нужен первичный ключ, соответствующий одному или нескольким столбцам этой таблицы, который позволяет осуществлять выборку экземпляров с помощью метода findByPrimaryKey().
Два компонента Business Components for Java соответствуют этим таблицам:
Объект развертывания EJB/9i (deployment object), который очень похож на стандартный объект-сущность и обозначает таблицу, которая управляет сохраняемостью.
Объект-представление (view object), который выбирает релевантные столбцы этой таблицы и присваивает им псевдонимы EJB-полей.
CMP-компоненты могут также использовать классы других бизнес-компонентов: домены, которые позволяют EJB-полям базироваться на объектных типах Oracle, и вторичные объекты-представления, соответствующие методам механизма поиска EJB.
Наследование
Наследование типов (Type inheritance) – это фундаментальная концепция в любой объектно-ориентированной системе. Наследование типов позволяет совместно использовать похожие свойства различных типов, а также расширять их характеристики.
Во многих объектно-ориентированных приложениях объекты организованы в типы, а типы – в иерархии типов. Эмпирически вполне достаточно организовать иерархии типов в виде набора деревьев. Тем самым, простого наследования достаточно для поддержки организации типов в большинстве приложений. Java – это объектно-ориентированный язык программирования, поддерживающий простое наследование. С помощью простого наследования тип может расширять один супертип (наследовать от одного супертипа). Такой тип, называемый подтипом (subtype), наследует все атрибуты и методы своего супертипа (supertype). Подтипу можно также добавлять новые атрибуты и методы или переопределять унаследованные методы. СУБД Oracle поддерживает модель простого наследования. А это очень близко соответствует стандарту ANSI SQL:99. (Прим. ред. Этот стандарт ANSI принят одновременно с официальным международным стандартом ISO/IEC SQL:1999 и тождественен ему.) В следующих нескольких разделах поддержка наследования типов в Oracle обсуждается более подробно.
Иерархия типов
Корневой тип иерархии создается с помощью оператора CREATE TYPE, в котором должен быть указано ключевое слово NOT FINAL (нетерминальный).
CREATE TYPE Person_t AS OBJECT( name VARCHAR2(100), dob DATE, MEMBER FUNCTION age() RETURN number, MEMBER FUNCTION print() RETURN varchar2) NOT FINAL;
Под нетерминальным типом может быть создан подтип. Он наследует все атрибуты и методы от своего супертипа. В нем можно добавить новые атрибуты и методы и/или переопределить унаследованные методы.
CREATE TYPE Employee_t UNDER Person_t( salary NUMBER, bonus NUMBER, MEMBER FUNCTION wages() RETURN number, OVERRIDING MEMBER FUNCTION print() RETURN varchar2);
В Oracle Common Schema имеется более сложный пример иерархии наследования типов. Как показано на рис. 1, класс Category и его подклассы моделируются элегантной, но простой конструкцией, представляющей иерархии "часть-целое" (part-whole) с древовидной структурой. Этот пример более детально раскрывает основные преимущества системы объектных типов Oracle9i при сохранении всех аспектов объектной модели приложения.
create type category_typ as object ( category_name varchar2(50) , category_description varchar2(1000) , category_id number(2) ) NOT INSTANTIABLE NOT FINAL; create type subcategory_ref_list_typ as table of ref category_typ; create type product_ref_list_typ as table of number(6); / create type corporate_customer_typ under customer_typ ( account_mgr_id number(6) ); create type leaf_category_typ under category_typ ( product_ref_list product_ref_list_typ ); create type composite_category_typ under category_typ ( subcategory_ref_list subcategory_ref_list_typ ) NOT FINAL; create type catalog_typ under composite_category_typ ( member function getCatalogName return varchar2 );
Иерархия представлений
Объектное представление может быть создано как подпредставление другого объектного представления, создавая тем самым иерархию представлений. Преимущества иерархии представлений вытекают из того факта, что строки иерархии объектных представлений включают все строки их подпредставлений. Благодаря этому свойству, можно запрашивать объекты типов, принадлежащих к некоторой иерархии, осмысленным образом.
CREATE VIEW Persons OF Person_t WITH OBJECT ID (name) AS SELECT name, dob FROM r_persons; CREATE VIEW Employees OF Employee_t UNDER Persons AS SELECT name, dob, salary, bonus from r_employees;
Запрос к представлению Persons выберет всех лиц, включая служащих.
SELECT VALUE(p) FROM Persons p;
Oracle предоставляет возможность выполнения новых операторов для определения наиболее специализированного типа (most-specific-type) некоторого экземпляра объекта и преобразования объекта супертипа Т в объект подтипа T (если это возможно).
(Прим. ред. Связь "тип-подтип" в объектных моделях данных позволяет моделировать иерархию двойственных видов абстракций типов сущностей предметной области – абстракции обобщения (generalization) и специализации (specialization). При этом супертип является обобщением своего подтипа, а подтип – специализацией супертипа. Естественно назвать подтип нижнего уровня иерархии "наиболее специализированным типом" или "самым специализированным типом". Важно заметить, что это свойство является относительным – оно имеет место относительно заданной иерархии типов.)
Например, следующий запрос выбирает всех персон с заданной датой рождения (date of birth, dob), которые являются служащими.
SELECT TREAT(VALUE(p) AS Employee_t) FROM Persons p WHERE dob = '01-01-1970' AND VALUE(p) IS OF(Employee_t);
Некоторые другие свойства иерархии представлений:
тип суперпредставления должен быть непосредственным супертипом для типа создаваемого объектного представления; подпредставление наследует объектный идентификатор OID от своего суперпредставления.
Свойство подстановочности
Одно из наиболее значительных преимуществ наследования – это подстановочность (substitutability). Подстановочность – это основная характеристика полиформизма типов (type polymorphism), которая позволяет использовать значение некоторого подтипа там, где ожидается значение супертипа (например, параметры метода), причем в этом случае не требуется предварительных конкретных знаний о подтипе. (Прим. ред. Более подробно о подстановочности см. например [4].). В этой статье, к сожалению, уже нельзя исправить термин "подставляемость" на общеупотребительный термин "подстановочность".)
Подстановочность экземпляра (Instance substitutability) – это возможность использования значения некоторого объекта подтипа в контексте, объявленном в терминах супертипа. Подстановочность ссылки REF – это возможность использовать ссылку REF на подтип в контексте, объявленном в терминах ссылки на супертип. По умолчанию, объектные столбцы и объектные таблицы обладают свойством подстановочности. Базовая модель хранения – это единая плоская таблица со столбцами, которые соответствуют всем атрибутам всех возможных подтипов. В столбце идентификатора типа (type id column) хранится информация о наиболее специализированном типе данного типа.
CREATE TABLE dept (id NUMBER, mgr Person_t); INSERT INTO dept VALUES(1, Employee_t(…));
Динамическая диспетчеризация методов (Dynamic Method Dispatch)
Метод – это процедура или функция, которая является частью определения объектного типа. Методы могут выполняться в среде исполнения Oracle9i или передаваться для выполнения в другую среду. Методы могут быть реализованы с применением ряда языков, в том числе – PL/SQL, C/C++ и Java.
Подтип может переопределять любой из нетерминальных методов экземпляра (non-final member methods), определенных для его супертипа, и предоставлять другую реализацию. Когда вызывается метод некоторого экземпляра объекта, осуществляется диспетчеризация метода и вызов конкретной реализации в зависимости от наиболее специализированного типа данного экземпляра. СУБД Oracle поддерживает возможность мультиязыковой динамической диспетчеризации методов. Когда на некотором экземпляре объекта вызывается метод, осуществляется его диспетчеризация и вызов конкретной его реализации, основанной на наиболее специализированном типе данного экземпляра.
Объектно-ориентированная разработка приложений
Со времени своего появления в 1960-х годах объектно-ориентированная технология становилась все более зрелой. Поскольку появились индустриальные стандарты, обеспечившие ее повсеместное принятие, разработка объектно-ориентированных приложений стала в настоящее время доминирующей в области ИТ. Наиболее важные из этих стандартов:
UML (Unified Modeling Language) – унифицированный язык моделирования для объектно-ориентированного анализа и проектирования (Прим. ред. Общие сведения о языке UML можно найти, например, в статье [1]. В ней также приведен список рекомендуемой литературы по этому языку.); стандарт объектно-реляционных баз данных SQL:1999 (Прим. ред. Более подробно со стандартом SQL:1999 можно ознакомиться по статьям [2] и [3]. О дальнейшем развитии стандарта SQL читайте [12]); стандарты языков объектно-ориентированного программирования Java и C++. Прежде чем приступить к рассмотрению реализации стандарта SQL:1999 в СУБД Oracle9i и соответствующих ему объектно-ориентированных интерфейсов прикладного программирования для Java и C++, необходимо сначала обсудить UML.
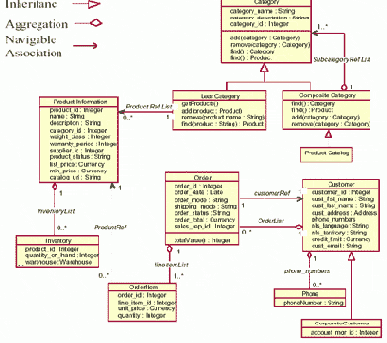
Надписи на рисунке:
Inheritance – наследование (Прим.ред.: на рис. опечатка: "inheritanc" вместо "inheritance"); Aggregation – агрегирование; Navigable Association – навигационная ассоциация.
Спецификации UML – это сплав лучших результатов, достигнутых в индустрии объектно- ориентированных технологий. Текущей является версия 1.4 этих спецификаций от Object Management Group (OMG), международной организации, разрабатывающей стандарты объектных технологий. (Прим. ред. В июне 2003 г. консорциум OMG принял новую версию этого стандарта – UML 2.0.) UML определяет стандартные конструкции для описания объектно-ориентированного программного обеспечения как объектной модели. Например, UML-диаграмма на рис. 1 изображает объектную модель приложения "Оперативный каталог", которое корпорация Oracle разработала как часть нового проекта Common Schema (общая схема). В этой объектной модели есть несколько классов (например, Category, leafCategory). Каждый из этих классов обладает рядом атрибутов и операций. Например, класс Category обладает атрибутами category_name и category_description, а также операциями add() и remove().
Классы также связаны между собой различными связями. Например:
класс leafCategory наследует от класса Category; класс compositeCategory может агрегировать объекты класса Category; а класс leafCategory имеет навигационную ассоциацию с классом Product_Information (то есть, классы leafCategory ссылаются на список объектов Product_Information).
Как только приложение проанализировано и спроектировано с применением UML, результирующая объектная модель может быть отображена в целевую реализацию с заданным языком программирования и сохраняемостью данных. После этого реализованное приложение готово для развертывания в рамках заданной целевой архитектуры. Преимущества объектно-реляционной технологии СУБД Oracle9i становятся очевидными по мере развертывания такого объектно-ориентированного процесса разработки. Как описано в следующем разделе, система объектных типов Oracle9i позволяет осуществлять отображение "один-к-одному" конструкций объектной модели UML в соответствующую объектно-реляционную схему.
Объектные представления
С другой стороны, СУБД Oracle9i также позволяет пользователю рассматривать реляционные данные как объекты. Объектные представления (Object Views) позволяют синтезировать бизнес-объект из данных, которые продолжают храниться в реляционных таблицах. А именно, можно:
определять объекты, которые вы можете использовать в своих приложениях, без миграции каких-либо существующих реляционных данных; различными способами комбинировать объекты, разработанные для одного приложения, для использования их другими приложениями. Объектные представления обладают примерно той же функциональностью, что и объектные таблицы. Они могут обладать методами, принадлежать коллекциям, ссылаться друг на друга, обладать свойством индивидуальности объектов (object identity), к ним можно получать доступ как через SQL, так и навигационным путем (path traversal). Более того, корпорация Oracle расширила механизм представлений, чтобы использовать специальные триггеры INSTEAD OF для поддержки полностью обновляемых представлений.

Рис. 3. Объектные представления добавляют гибкость при доступе к унаследованным данным.
Надписи на рисунке:
Relational Applications – реляционные приложения; Object Applications – объектные приложения; Object Views – объектные представления; Relational Data – реляционные данные; Objects – объекты; One Database – одна база данных.
Объектные типы
Корпорация Oracle расширила SQL (как DDL, так и DML), чтобы позволить пользователям: определять свои собственные типы (которые представляют их бизнес-объекты) и связи (например, наследование и агрегирование) между этими определяемыми пользователями типами; хранить их экземпляры (то есть, объекты) в базе данных (либо в столбцах таблиц, либо как сами таблицы); запрашивать, вставлять и изменять эти экземпляры.
Бизнес-объект:
может содержаться внутри другого бизнес-объекта; на него может ссылаться другой объект (используя конструкцию, называемую REF); к нему можно получить доступ; с ним можно манипулировать как с коллекциями (collections) или наборами (sets), используя структуры, называемые массивами переменной длины (VARRAYS) и вложенными таблицами (Nested Tables).
Пользователи могут определять операции над бизнес-объектами как методы (methods) определяемых пользователями типов. Методы могут быть реализованы как хранимые процедуры на языках Java или PL/SQL. Объекты также обладают глобально уникальными идентификаторами, называемыми объектными идентификаторами (Object ID), которые могут быть использованы для поддержки ссылок между объектами.
СУБД Oracle9i позволяет пользователям рассматривать объектные данные как реляционные. Например, пользователи могут использовать SQL для запросов объектных данных точно так же, как для запросов реляционных данных. Пользователи могут получать доступ к объекту, используя операторы SQL DML, к его атрибутам и методам, используя расширенные выражения путей (например, объект.атрибут). Они могут также использовать SQL для выполнения явных соединений (explicit joins) объектов в таблицах. Кроме того, Oracle9i позволяет пользователям выполнять неявные соединения (implicit joins) объектов, путем обхода (traversing) или навигации по ссылкам от одного объекта к другому. Объекты можно индексировать, применяя методы MAP или ORDER для преобразования их в скалярные значения, которые затем могут быть индексированы.
Объектно-реляционные конструкции СУБД Oracle9i весьма близки к реляционным, которые хорошо знакомы пользователям СУБД Oracle. Например, ссылка REF очень похожа на внешний (foreign) ключ, методы – это хранимые процедуры (которые могут быть написаны на языках Java, PL/SQL или C/C++), модели безопасности и транзакций, оперирующие с объектными типами, являются точно такими же, как и модели, определенные для реляционных таблиц.
Рис. 2. Определяемые пользователями объектные типы позволяют использовать конструкции предметной области.
Рассматриваемая система объектных типов существенно повышает уровень абстракции, на котором пишутся программы для работы с базами данных. Вместо оперирования типами данных NUMBER, CHAR и т.д., эти программы могут работать с конструкциями предметной области, такими, как Customer, Portfolio или Money. Из этого проистекают многие преимущества, не последним из которых является лучшее моделирование вашего бизнеса в базе данных.
Объектные типы в SQLJ
В СУБД Oracle9i введена возможность "бесшовно" отображать заданный Java-класс в некоторый объект SQL. Согласно части 2 стандарта SQLJ, SQLJ Object Types (Объектные типы SQLJ), определяется отображение между некоторым объектом SQL и соответствующей реализацией Java-класса. Спецификации SQLJ Object Types находятся в процессе стандартизации в качестве расширения стандарта SQL:99. (Прим. ред. В июле 2002 г. указанное расширение стандарта SQL:1999 было принято в качестве части 13 этого стандарта под названием SQL/JRT, где аббревиатура JRT расшифровывается как Java Routines and Types.)
Рассмотрим следующий пример:
CREATE TYPE ADDRESS_T AS OBJECT EXTERNAL NAME "Address" LANGUAGE JAVA USING SQLDATA ( STREET VARCHAR(50) EXTERNAL NAME "street", ZIP_CODE VARCHAR(10) EXTERNAL NAME "zip", STATIC FUNCTION GET_CITY (VARCHAR zip) RETURN VARCHAR EXTERNAL NAME "get_city(java.lang.String) RETURN java.lang.String", STATIC FUNCTION GET_STATE (VARCHAR zip) RETURN VARCHAR EXTERNAL NAME "get_state(java.lang.String) RETURN java.lang.String", MEMBER FUNCTION CITY RETURN VARCHAR EXTERNAL NAME "getCity() RETURN java.lang.String", MEMBER FUNCTION STATE RETURN VARCHAR EXTERNAL NAME "getState() RETURN java.lang.String");
В данном примере в операторе CREATE TYPE предложение EXTERNAL NAME специфицирует внешнее имя, которое определяет Java-класс, используемый в реализации. Предложение USING специфицирует интерфейс, используемый для доступа к состоянию объекта.
Для каждого атрибута данного объектного типа необязательное предложение EXTERNAL NAME задает имя соответствующего Java-поля. Для методов предложение EXTERNAL NAME определяет имя соответствующей Java-функции и ее сигнатуру.
Приведенная выше информация об отображении хранится как часть метаданных данного типа. Она обеспечивает "бесшовный" доступ к объектам SQL из Java через JDBC, не требуя от пользователя явного применения интерфейса SQLData или регистрации этого класса с помощью отображения типов Java (Java typemap).
Иерархия объектных типов в SQLJ может быть отображена в иерархию наследования Java. Диспетчеризация методов, включая переопределение этих типов, осуществляется в процессе исполнения Java-программы.
Определяемые пользователями конструкторы
Определяемые пользователями конструкторы исключают проблемы с конструктором значений атрибутов (attribute-value constructor), так как они не должны явно устанавливать значение для каждого атрибута типа. Определяемый пользователем конструктор может иметь любое число параметров любого типа, которые не должны в обязательном порядке непосредственно отображаться в атрибуты типов. В определении конструктора можно устанавливать любые подходящие значения атрибутов. Атрибутам, для которых значения не заданы, будет установлено значение NULL.
Oracle XML DB
В СУБД Oracle9i Release 2 введена опция Oracle9i XML Database (Oracle XML DB). Она расширяет СУБД Oracle средствами поддержки XML, делая XML-данные и модели содержимого непосредственно доступными приложениям Oracle9i. Oracle XML DB, высокопроизводительная технология хранения и выборки XML-данных, предоставляется в сервере базы данных Oracle9i Release 2. Она основана на модели данных W3C XML (Прим. ред. В спецификации стандарта XML и других стандартов W3C, основанных на этом языке, часто употребляется термин “модель данных XML”. Однако при этом под “моделью данных” понимается лишь структурный аспект этого понятия. Язык XML не определяет полной модели данных. В частности, в нем не предлагаются какие-либо средства манипулирования XML-данными. Он выполняет лишь функции языка определения данных.) и обеспечивает преимущества двух технологий:
объектно-реляционной технологии баз данных;
XML-технологии.
Oracle XML DB – это "чистая" база данных XML. Она предоставляет инфраструктуру для управления данными, независимую от хранения, содержимого и языков программирования. Хотя она тесно интегрирована с SQL-машиной СУБД Oracle, в ней воплощены концепции, никогда ранее не реализованные в реляционных СУБД. Например, объектная модель XML-документов – XML Document Object Model (DOM) – встроена в ядро СУБД Oracle, так что большинство операций с XML-данными может быть выполнено как часть традиционной обработки данных в базе данных. А это позволяет избежать двухшаговой модели – извлечь и обработать.
Благодаря тесной интеграции с объектно-реляционной технологией Oracle и языком PL/SQL, Oracle XML DB одновременно демонстрирует мощность объектно-реляционных баз данных и гибкость XML.
Отображение объектных типов Oracle в CMP-поля
Таблица базы данных, управляющая CMP-сохраняемостью, может включать столбцы, содержащие объектные типы Oracle. В JDeveloper мастер Domain Wizard помогает создавать объекты-домены из объектных типов Oracle.
Отображение объектов SQL в C++
Интерфейс уровня вызовов Oracle для C++ (Oracle C++ Call Interface, OCCI) специфицирует отображение объектных типов в C++. Таким образом, можно получить доступ к экземплярам объектных типов в базе данных, и их можно модифицировать из объектов C++ в приложении. Навигационный интерфейс OCCI позволяет получать доступ к объектно-реляционным данным и модифицировать их как объекты C++ без явного использования SQL.
Транслятор объектных типов Object Types Translator (OTT) генерирует по умолчанию классы C++, соответствующие объектным типам, включая иерархии типов. Он также предоставляет по умолчанию реализации методов, необходимых для чтения объектов из базы данных и их записи в базу данных.
Для примера рассмотрим следующую иерархию объектных типов:
CREATE TYPE Person AS OBJECT (name VARCHAR2(100), age NUMBER) NOT FINAL; CREATE TYPE Student UNDER Person(dept VARCHAR2(50), advisor REF Person);
Далее приведены классы C++, сгенерированные OTT для этой иерархии типов. Класс OCCIPObject предоставляется интерфейсом OCCI как базовый класс для классов, обладающих сохраняемыми (persistent) или временными объектами.
class Person : public OCCIPObject { … void *operator new(size_t size, const OCCIConnection& con, const OCCIString& table); static void readSQL(const OCCIAnyData& stream, Person *obj); static void writeSQL(const Person *obj, OCCIAnyData& stream); …} class Student : public Person {… static void readSQL(const OCCIAnyData& stream, Student *obj); static void writeSQL(const Student *obj, OCCIAnyData& stream); …}
Фрагменты кода, соответствующие двум методам, приведены ниже:
void Person::readSQL(const OCCIAnyData& stream, Person *obj){ obj->name = stream.getString(1); obj->age = stream.getNumber(2); } void Student::readSQL(const OCCIAnyData& stream, Student *obj) { Person::readSQL(stream, obj); obj->dept = stream.getString(3); obj->advisor = stream.getRef(4); }
Таблица отображения типов поддерживает ассоциацию между именами типов SQL и именами классов C++, и она используется во время исполнения для определения класса, чьи подпрограммы readSQL и writeSQL должны быть вызваны. OTT также обеспечивает для пользователей гибкость расширения сгенерированных классов для добавления дополнительных выполняемых функций.
Следующий фрагмент кода иллюстрирует выборку объекта SQL в экземпляре класса C++:
OCCIResultSet *resultSet = stmt->executeQuery("select VALUE(p) from person_tab p where name = "Joe""); /* выборка объекта создает соответствующий экземпляр класса */ Student *joe = (Student *)resultSet.getObject(1); /* dereferencing the REF value yields the object */ Person *joe_advisor = joe->advisor->ptr();
Отображение объектов SQL в XML
Расширяемый язык разметки XML (Extensible Markup Language) – это метаязык, который быстро становится стандартом де-факто для обмена данными между приложениями и областями бизнеса. (Прим. ред. О языке XML см. например, [9-11].) Язык определения схемы для XML-документов, XML Schema, специфицирует структуру XML-документа в терминах типов данных и композицию каждого элемента в этом документе. СУБД Oracle поддерживает эффективные и гибкие механизмы для отображения объектов SQL в XML, и наоборот.
Поддержка объектно-реляционной технологии в JDeveloper
Корпорация Oracle предоставляет мощные инструментальные средства для поддержки объектно-ориентированной разработки приложений. Для Java-разработчиков в среде JDeveloper предлагается два способа интегрированной поддержки разработки приложений, которые используют объектно-реляционную технологию Oracle. В первом случае для отображения доменов в объектные типы Oracle9i и объектов-сущностей (entity objects) в объектные таблицы и объектные представления используется интегрированная среда Oracle Business Components for Java (бизнес-компоненты Oracle для среды Java). Объекты-сущности могут быть развернуты как компоненты Enterprise JavaBeans (EJB) с применением механизма сохраняемости, управляемой контейнером (CMP, Container Managed Persistence). Во втором случае для генерации Java-классов из объектных типов Oracle9i используется мастер JPublisher. Разработчики используют Java-классы, сгенерированные мастером JPublisher, для доступа и манипулирования объектами-строками и объектами-столбцами Oracle9i.
и лаконично изложены основные принципы
В данном документе четко и лаконично изложены основные принципы объектно- реляционной технологии, воплощенной в новом продукте компании Oracle – в сервере баз данных Oracle9i. Редакция журнала считает необходимым познакомить с ним читателей. Вместе с тем, подготовка и публикация перевода этого документа была в определенной степени инициирована также терминологической дискуссией, сопровождавшей перевод на русский язык документации Oracle9i, который выполнялся специалистами компаний РДТЕХ (www.rdtex.ru) и ITI Ltd. (www.iti.ru). Некоторые фрагменты этой дискуссии отражены в последних публикациях колонки "О чистоте русского языка и точности терминологии". В ходе дискуссии ее участники неоднократно указывали на вольности с терминологией в документации Oracle. В отличие от документации Oracle9i данный документ безупречен в части терминологии.
К сожалению, авторы документа не приводят никаких сведений о соотношении объектных возможностей, предусмотренных в Oracle 9i и в стандартах SQL:1999, а также SQL:200n – новой версии международного официального стандарта языка SQL, разработка которой завершается в настоящее время.
Все стандарты, на которые имеются ссылки в данном документе, подробно рассмотрены в книге М.Р.Когаловского "Энциклопедия технологий баз данных" (М: "Финансы и статистика", 2002). Там же содержатся необходимые ссылки на соответствующие официальные документы и другие публикации, включая отечественные. Кроме того, полезные публикации по затрагиваемым в статье вопросам указываются в примечаниях редакторов перевода.
,
,
Простые стратегии для сложных данных: объектно-реляционная технология Oracle9i
Источник: Geoff Lee и др., An Oracle Technical White Paper, май 2002
Перевод Алексея Резниченко
Развертывание объектно-ориентированных приложений на интернет-платформах Oracle
Завершив разработку приложения с помощью объектно-реляционной технологии Oracle9i, можно использовать ряд способов его развертывания и управления. Сервер приложений Oracle9i AS (Application Server) и сервер базы данных Oracle9i Database Server предоставляют все необходимое для развертывания и управления приложениями электронного бизнеса. Сервер Oracle9i AS и сервер базы данных Oracle9i Database Server вместе составляют простую, полную и интегрированную интернет-платформу.
Простота. Серверы Oracle9i AS и Oracle9i Database Server просто купить, просто инсталлировать и просто сопровождать. Все ключевые сервисы среднего звена программного обеспечения Oracle были интегрированы в Oracle9i AS, обеспечивая пользователям построение и развертывание порталов, транзакционных приложений и средств бизнес-интеллекта в едином продукте. Полный набор сервисов Oracle9i AS доступен сразу после инсталляции. Управление серверами Oracle9i AS и Oracle9i Database Server осуществляется при помощи единого инструмента управления.
Полнота. Интернет-платформа Oracle, включающая сервер Oracle9i для управления данными и Oracle9i AS для выполнения приложений – это полное решение для построения и развертывания любого типа веб-приложений, включая управление содержимым, OLTP-приложения, мобильные приложения, приложения бизнес-интеллекта и приложения интеграции на уровне предприятия. Серверы Oracle9i AS и Oracle9i Database Server обеспечивают масштабируемую инфраструктуру с высокой степенью доступности, которая позволяет заказчикам легко адаптироваться к растущему числу пользователей без необходимости переработки их приложений.
Интегрированность. Сервер Oracle9i AS – это лучший сервер приложений для сервера базы данных Oracle9i Database Server. Используя общий технологический стек, Oracle9i AS может прозрачно масштабировать сервер базы данных Oracle9i Database Server, кешируя данные и логику приложений в среднем звене. Кроме того, Oracle9i AS в значительной степени наследует свою мощную масштабируемость и свойства высокой доступности от продвинутой технологии сервера базы данных Oracle9i Database Server.
Синонимы типов
Точно так, как можно создавать синонимы таблиц, представлений и других различных объектов схемы, можно создавать синонимы определяемых пользователями типов. Синонимы этих типов обладают теми же преимуществами, что и синонимы других объектов схемы: они предоставляют независимый от местонахождения способ ссылки на объекты схемы. Приложение, использующее синонимы общедоступных типов, можно развернуть без какого-либо изменения любой схемы базы данных. При этом не нужно квалифицировать имя типа именем схемы, в которой этот тип был определен.
Система объектных типов СУБД Oracle9i
Исторически приложения разрабатывались с прицелом на доступ и модификацию корпоративных данных, которые хранятся в таблицах, составленных из "родных" для SQL типов данных, таких, как INTEGER, NUMBER, DATE и CHAR. Но, начиная с СУБД Oracle8, поддерживаются не только эти, но также и новые объектные типы данных, которые теперь являются частью действующего стандарта ANSI SQL:99. В этом разделе дан краткий обзор основных характеристик системы объектно-реляционных типов Oracle.
Среда Oracle Business Components for Java
Среда Oracle Business Components for Java отображает ее домены в объектные типы Oracle9i, а объекты-сущности – в объектные таблицы и объектные представления. Мастер JDeveloper может создавать объекты-сущности из объектных таблиц Oracle9i или объектных представлений. Объект-сущность может быть развернут как EJB с применением механизма сохраняемости, управляемой контейнером – CMP.
Ссылки к русскому переводу
Кузнецов С. Д. "Концептуальное проектирование реляционных баз данных с использованием языка UML" – http://www.citforum.ru/database/articles/umlbases.shtml
Айзенберг Э. и Мелтон Д. "SQL:1999, ранее известный как SQL3" – Открытые системы, #01/1999, http://www.osp.ru/os/1999/01/52.htm
Айзенберг Э. и Мелтон Д. "Cтандартизация SQL: следующие шаги" – Открытые системы, #11-12/1999, http://www.osp.ru/os/1999/11-12/080.htm
Фернстайн С. "Подставляемость и преобразование объектных типов в иерархии" – Oracle Magazine/Russian Edition, июнь 2002, http://www.oracle.com/ru/oramag/june2002/index.html?dev_subst.html
Калиниченко Л.А. "Стандарт систем управления объектными базами данных ODMG-93: краткий обзор и оценка состояния" – Открытые системы, #1/1996, http://www.osp.ru/dbms/1996/01/46.htm
Айзенберг Э. и Мелтон Д. "Связывания для объектных языков" – Открытые системы, #04/1999, http://www.osp.ru/os/1999/04/10.htm
Орлик С. "Обзор спецификации JDBC" – Системы управления базами данных, #03/1997, http://www.osp.ru/dbms/1997/03/21.htm
Айзенберг Э. и Мелтон Д. "SQLJ – Часть 1: SQL-программы, использующие язык программирования JAVA" – Открытые системы, #09-10/1999, http://www.osp.ru/os/1999/09-10/061.htm
Когаловский М. Р. "XML: возможности и перспективы. Ч. 1. Платформа XML и составляющие ее стандарты" – Директор информационной службы, #01/2001, http://www.osp.ru/cio/2001/01/024.htm
Когаловский М. Р. "XML: возможности и перспективы. Ч. 2. Базы данных XML, семантика XML-документов, перспективы" – #02/2001, Директор информационной службы, http://www.osp.ru/cio/2001/02/016.htm
Когаловский М. Р. "XML: сферы применений" – Директор информационной службы, #04/2001, http://www.osp.ru/cio/2001/04/010.htm
Черняк Л. "Джим Мелтон о судьбе стандарта SQL" – Открытые системы, #06/2003, http://www.osp.ru/os/2003/06/065.htm
Ссылочные типы
Если вы создаете объектную таблицу или объектное представление в СУБД Oracle9i, то можно получить ссылку (или указатель базы данных, pointer) на соответствующий объект-строку (row object). Ссылки важны для моделирования связей и навигации по экземплярам объектов, в частности, в приложениях на стороне клиента.
Связывания для языков программирования
Полная поддержка объектно-реляционной системы типов Oracle доступна в связываниях для ряда языков программирования, включая PL/SQL, Java и C/C++. К экземплярам типов можно получить доступ, и с ними можно манипулировать через интерфейсы прикладного программирования, такие, как JDBC (Java DataBase Connectivity) и OCCI (Oracle C++ Call Interface). Корпорация Oracle предоставляет также инструменты, подобные утилите JPublisher и транслятору объектных типов Object Type Translator (OTT), для отображения иерархий объектных типов в языки Java и C++. Кроме того, в средах этих языков также поддерживается подстановочность экземпляров и ссылок REF.
(Прим. ред. О связывании для языков программирования (language binding) в объектных СУБД, соответствующих стандарту объектных баз данных ODMG, см. например, [5]. О спецификациях связывания SQL для объектных языков программирования, принятых в октябре 2000г., см. например, [6].)
Типы-коллекции
Коллекции – это типы данных SQL, составляющие элементы которых представляют собой множественные элементы. Каждый элемент или значение для коллекции обладает тем же самым подстановочным типом данных. В Oracle предусмотрено два типа коллекций – массивы переменной длины (Varrays) и вложенные таблицы (Nested Tables).
Массив переменной длины содержит переменное число упорядоченных элементов. Типы данных VARRAY могут быть использованы для столбцов таблиц или атрибутов объектных типов.
С помощью Oracle SQL можно создавать указанные выше типы таблиц. Они могут использоваться как вложенные таблицы для реализации семантики неупорядоченной коллекции. Так же как и VARRAY, типы вложенных таблиц могут быть использованы для столбцов таблиц или атрибутов объектных типов.
Многоуровневые коллекции
СУБД Oracle9i поддерживает множественные уровни вложенности коллекций, например, вложенные таблицы или массивы переменной длины, встроенные в некоторую вложенную таблицу или массив переменной длины. В Oracle Common Schema есть отличный пример, показывающий преимущества поддержки многоуровневых коллекций. В UML-диаграмме на рис. 1, класс Customer показан как имеющий агрегат класса Order, который, в свою очередь, имеет агрегат класса Order_Item. Следующий пример показывает, как отобразить эти конструкции, создавая тип customer_typ, который содержит коллекцию вложенных таблиц типа order_typ, который, в свою очередь, включает коллекцию вложенных таблиц типа order_item_typ.
create type order_item_typ as object ( order_id number(12) , line_item_id number(3) , unit_price number(8,2) , quantity number(8) , product_ref REF product_information_typ ) ; create type order_item_list_typ as table of order_item_typ; create type customer_typ; create type order_typ as object ( order_id number(12) , order_mode varchar2(8) , customer_ref REF customer_typ , order_status number(2) , order_total number(8,2) , sales_rep_id number(6) , order_item_list order_item_list_typ ) ; create type order_list_typ as table of order_typ; create or replace type customer_typ as object ( customer_id number(6) , cust_first_name varchar2(20) , cust_last_name varchar2(20) , cust_address cust_address_typ , phone_numbers phone_list_typ , nls_language varchar2(3) , nls_territory varchar2(30) , credit_limit number(9,2) , cust_email varchar2(30) , cust_orders order_list_typ );
В том же самом примере из Oracle Common Schema создается объектное представление для многоуровневых коллекций.
create or replace view oc_customers of customer_typ with object oid (customer_id) as select c.customer_id, c.cust_first_name, c.cust_last_name, c.cust_address, c.phone_numbers,c.nls_language, c.nls_territory,c.credit_limit, c.cust_email, cast(multiset(select o.order_id, o.order_mode, make_ref(oc_customers,o.customer_id), o.order_status, o.order_total,o.sales_rep_id, cast(multiset(select l.order_id,l.line_item_id, l.unit_price,l.quantity, make_ref(oc_product_information, l.product_id) from order_items l where o.order_id = l.order_id) as order_item_list_typ) from orders o where c.customer_id = o.customer_id) as order_list_typ) from customers c;
в СУБД для всех типов
СУБД Oracle9i ™ быстро превратилась в СУБД для всех типов данных – от простых до сложных. Мультимедийные типы данных, такие, как изображения, карты, видео- и аудио- клипы, редко обрабатывались неспециализированным программным обеспечением. Но в настоящее время многие веб-приложения требуют от своих серверов баз данных управления такими данными. Иные программные решения были также необходимы для хранения данных, которыми оперируют:
финансовые инструменты; технические диаграммы; молекулярные структуры.
Для удовлетворения этих потребностей сервер баз данных Oracle9i ™ предоставляет объектно-реляционную технологию, которая обеспечивает простые методы разработки, развертывания и управления приложениями, оперирующими со сложными данными.
Сервер Oracle9i ™ с объектно-реляционной технологией может быть "подогнан" разработчиками для создания их собственных специфических для области применения (application-domain-specific) типов данных. СУБД Oracle9i ™ была расширена для поддержки полных возможностей объектного моделирования, включая наследование (inheritance) и многоуровневые коллекции (multi-level collections), а также эволюции типов данных (type evolution). Например, можно создать новые типы данных, представляющие клиентов (customers), финансовые портфели (financial portfolios), фотографии и телефонные сети – и, тем самым, обеспечить, чтобы ваши приложения баз данных оперировали абстракциями, свойственными вашей предметной области (application domain). Кроме того, весьма желательно интегрировать эти новые типы с сервером баз данных настолько тесно, насколько это возможно, чтобы они обрабатывались наравне со встроенными типами данных, такими, как NUMBER или VARCHAR.

Рис. 0. Объектно-реляционная архитектура СУБД Oracle9i.
И, наконец, СУБД Oracle9i ™ предлагает большой набор интерфейсов прикладного программирования (API), реализующих связывания для различных языков. Для Java и PL/SQL предлагается "прямая" (native) поддержка внутри самой СУБД с тесной интеграцией между системой объектно-реляционных типов и хранимыми процедурами, написанными на Java или PL/SQL. Так как XML быстро становится стандартом для обмена информацией, то используя объектно-реляционную среду, можно "напрямую" хранить данные XML и эффективно манипулировать ими, индексировать их и эффективно обрабатывать запросы. Можно также поддерживать отображение между типами языка SQL и клиентских языков программирования (Java и C++), чтобы обеспечить "бесшовный" доступ к экземплярам типов данных SQL из приложений, написанных на Java или C++.
реляционная технология корпорации Oracle за
Объектно- реляционная технология корпорации Oracle за ряд лет достигла зрелости и обеспечивает полную систему объектных типов, большой набор API, реализующих связывания для различных языков программирования, а также богатый набор утилит и инструментальных средств. Эта полная система объектных типов основана на действующем стандарте ANSI SQL:99. Корпорация Oracle оптимизировала производительность работы с объектными типами в сервере базы данных для объектно-ориентированных приложений. Интерфейсы прикладного программирования Oracle для языков Java, C/C++ и XML обеспечивают непосредственные интерфейсы для системы объектных типов сервера базы данных. Эти API с исчерпывающими функциональными возможностями поддерживают самые последние стандарты доступа к сервисам системы объектных типов базы данных. Сопутствующий богатый набор утилит для объектно-реляционных данных включает средства экспорта и импорта, тиражирования данных, SQL-загрузчик и т.д.
Кроме того, предлагается ряд средств разработки, которые поддерживают объектно-реляционную технологию Oracle для разработки объектно-ориентированного программного обеспечения, таких, как Oracle JDeveloper BC4J (Business Components for Java), и другие продукты от партнеров Oracle. Корпорация Oracle также предлагает высокопроизводительные, надежные и масштабируемые интернет-платформы для развертывания и управления приложениями, а именно, сервер базы данных Oracle9i Database Server и сервер приложений Oracle9i Application Server.
ИТ-индустрия, сталкиваясь с быстрыми изменениями, требует практичных решений проблем обработки различных типов данных в сложных приложениях. Объектно-реляционная технология Oracle решает эти проблемы с помощью наиболее развитого комплекта средств для разработки, развертывания и управления такими приложениями. Корпорация Oracle стала лидером объектно-реляционной технологии. Oracle будет продолжать удовлетворять потребности своих партнеров и заказчиков, предлагая им лучшую объектно-реляционную технологию.
Копирование файлов динамических модулей
В соответствии с указанным в php.ini значением параметра extension_dir скопируем файлы:
c:
cd \php\php-4.3.0-Win32
move php4ts.dll sapi
move extensions\php_oci8.dll sapi
move extensions\php_oracle.dll sapi
Некоторые возможности PHP
PHP, конечно, не столь универсальный язык, как Java, используемая в JavaServer Pages, но достаточно богат. Описание его можно найти в книгах, например в , или на вышеуказанной официальной странице PHP в интернете. Вот некоторые особенности языка.
Вставки PHP в текст HTML можно оформлять не только как <?php ... ?> (см. выше), но и проще как <? ... ?> (что не рекомендуется) или же как <script language="php"> ... </script> (что длиннее).
phpinfo() в примере выше – встроенная функция PHP. Регистр, которым набираются имена функций в PHP несущественен, а для переменных (предваряются знаком $, $currtime и $currtimestr в примере выше) наоборот, существенен.
Переменные могут быть типов целого, плавающего, строка, массив, объект и булевского. Возможно явное преобразование типов. Выражения и операторы похожи на используемые в C и Perl.
Набор функций достаточно широк и позволяет производить вычисления (в том числе с произвольной точностью), обращаться к файлам ОС и к различным базам данных, к сетевым ресурсам (например, по ftp) и к серверам LDAP, рисовать изображения и динамически выводить данные в формате pdf и многое другое. Вот несколько примеров функций, на вскидку:
- string crypt(string str, [, string salt]) – шифрование строки по алгоритму DES, наприме перед помещением ее в БД (для шифрования разными методами есть и другие функции)
- int syslog(int priority, string message) – посылка сообщения в журнал ОС
- int xml_parse(int parser, string data[, int is_final]) – синтаксический разбор документа XML
Посмотрим, как может выполняться обращение к данным в Oracle.
Oracle, да не только
Как говорилось выше, PHP имеет функции обращения к данным отнюдь не только в Oracle. Наличие этих функций дает возможным использования этого инструмента достаточно экзотично, например для переноса данных между Oracle и другими системами. Например, нередко стоит задача переноса из формата dbf в БД под управлением Oracle или наоборот. Вот как ее можно решить «на коленке». Обратите внимание, что перенос инициируется из окошка браузера, а выполняется целиком на узле web.
Составим файл dbase.php:
<html>
<head><title>Access from php to different
data bases</title></head>
<body>
<h3>Distant data transfer from
Oracle to dbf:</h3>
<?php $dbname = "c:/fromoracle.dbf";
$def = array( array("ename", "C", 10), array("sal", "N", 7, 2) );
$dbid = dbase_create($dbname, $def); if (!$dbid) echo "Failed to open dbf." ?>
<?php if ($c=OCILogon("scott", "tiger", "orcl")) {
$s = OCIParse($c, "select ename,
sal from emp"); OCIExecute($s, OCI_DEFAULT); while (OCIFetch($s)) { $rec[1] = ociresult($s, "ENAME"); $rec[2] = ociresult($s, "SAL"); if (!dbase_add_record($dbid,
array($rec[1],$rec[2]))) echo "Failed to add a record. "; } OCILogoff($c);
} ?>
Done. <hr/>
</body>
</html>
Поместим файл в htdocs и обратимся по адресу . В каталоге с: должен появиться файл fromoracle.dbf с данными, полученными из Oracle. Обратное преобразование можно проделать в качестве упражнения.
Таким же образом можно обращаться к mySQL, PostgreSQL, Sybase, SQL Server и другим системам управления данными и по ODBC.
Oracle и PHP - это очень просто
, преподаватель технологий Oracle
... Он бежит себе в волнах
На раздутых парусах.
PHP – простое в употреблении, легкое и бесплатное средство для динамического построения страниц HTML на сервере, перед передачей клиенту в браузер. PHP умеет обращаться в СУБД Oracle, и это делает его хорошим кандидатом для разработки приложений web на основе Oracle малой и средней сложности.
Перезапуск Apache и проверка
Осталось перезапустить Apache. Это можно сделать либо с помощью меню Start, либо через останов и запуск службы Windows. Если все проделано правильно, при запуске не будет ошибок.
Составим файл test.php:
<html>
<head><title>My test for php</title></head>
<body>
<h3>This is a test how php works</h3>
<?php phpinfo()?>
<?php
$currtime = time ();
$currtimestr = strftime ("%H:%M:%S", $currtime);
echo "The current time is: $currtimestr";
?>
</body>
</html>
Поместим файл в %ORACLE_HOME%\Apache\Apache\htdocs. Наберем в браузере адрес (в версии Oracle 8 номер порта или убрать, или указать 80).
Правка файла конфигурации Apache
Найдите файл httpd.conf. Скорее всего он в каталоге %ORACLE_HOME%\Apache\Apache\conf. Добавьте строки:
LoadModule php4_module C:/php/php-4.3.6-Win32/sapi/php4apache.dll
AddModule mod_php4.c
AddType application/x-httpd-php .php
Последний параметр уже присутствует в виде комментария, и для него достаточно просто знак комментария снять.
Правка файла конфигурации PHP
Найдите файл php.ini. Скорее всего он в каталоге c:\WINNT. Найдите параметр extension_dir и проставьте
extension_dir = "C:\php\php-4.3.6-Win32\sapi"
Снимите комментарии со строк
;extension=php_oci8.dll
;extension=php_oracle.dll
;extension=php_dbase.dll
Последний параметр требуется раскомментарить только если вы намерены проиграть следующий далее пример с записью данных в формате dbf.
Работа с Oracle
Обращение с помощью PHP к данным в Oracle может осуществляться через CGI или через специальные функции. Первая возможность рискована с точки зрения безопасности и здесь не рассматривается.
Вторая, в свою очередь, реализуется двумя имеющимися библиотеками: php_oracle и php_oci8, из которых вторая считается более эффективной. Продемонстрировать ту и другую можно на примере файла employees.php:
<html>
<head><title>Access to Oracle from php</title></head>
<body>
<h3>The two types of Access to Oracle from php:</h3>
<?php if ($c = OCILogon("scott", "tiger", "orcl")) {
$s = OCIParse($c, "select ename, sal from emp"); OCIExecute($s, OCI_DEFAULT); while (OCIFetch($s)) { echo "ename = " . ociresult($s, "ENAME") . ", sal = " . ociresult($s, "SAL") . "<br/>"; } OCILogoff($c);
} else { $err = OCIError(); echo "Oracle
Connect Error " . $err[text]; } ?>
<hr/>
<?php if ($c = ora_logon("scott@orcl","tiger")) {
$curs = ora_do($c, "SELECT ename, sal FROM emp"); while (ora_fetch($curs)) { echo "ename = " . ora_getcolumn($curs, 0) . ", sal = " . ora_getcolumn($curs, 1) . "<br/>"; } ora_logoff($c);
} else { echo "Oracle Connect Error " . ora_error(); } ?>
<hr/>
</body>
</html>
Снова поместим файл в htdocs и обратимся по адресу .
Этот пример для наглядности упрощен, а в жизни нужно будет больше уделить места обработке ошибок и структуризации кода.
Вот пример вставки записи в БД. Данные передаются через строку запроса HTTP. Это позволяет организовать в приложении содержательный диалог, подключив средства ввода форм HTML.
Подготовим файл insert.php:
<html>
<head><title>Access to Oracle from php</title></head>
<body>
<h3>INSERT example:</h3>
<?php if ($c = OCILogon("scott", "tiger", "orcl")) {
$name = (string)$_REQUEST['empname']; $no = (int)$_REQUEST['empno'];
$query = "INSERT INTO emp (ename, empno)
VALUES (:bind1, :bind2)"; $s = OCIParse($c, $query); OCIBindByName($s, ":bind1", $name); OCIBindByName($s, ":bind2", $no);
OCIExecute($s, OCI_DEFAULT); OCICommit($c); OCILogoff($c);
} ?>
Done. <hr/>
</body>
</html>
Поместим файл в htdocs и обратимся по адресу . В SQL*Plus или предыдущей страницей PHP можно проверить результат. Обратите внимание на то, что в приведенном примере никак не обрабатывается (а) блокировка строк, возможно мешающая вставке и (б) возможный конфликт первичного ключа.
Установка PHP
Дальнейшие примеры будут приведены для связки Windows + Apache. Удобнее всего использовать версию Apache со штатного установочного комплекта СУБД Oracle (в версии Oracle 10.1 – на Companion CD). Дежурное напоминание: для промыщленного использования сервера web лучше все же взять последнюю версию Apache из сети, так как она более функциональна, надежна и защищена.
Версию PHP можно скачать с узла . Там же имеются документация, учебные материалы, форумы и ссылки на ресурсы, в числе которых есть русскоязычные. К примеру, для Windows можно скачать файл php-4.3.6-Win32.zip. Его нужно поместить в каталог, например c:\php, и разархивировать. Далее можно следовать инструкциям в install.txt, однако само ПО PHP уже установлено. В Unix еще потребуется построить библиотеки программой make.
СУБД Oracle, когда против желания
СУБД Oracle, когда против желания фирмы-изготовителя, а когда согласно – в зависимости от направления политических ветров в конкретные периоды времени, – никогда, кроме начального периода своего существования, не была полностью закрытой системой. Например, с момента возникновения движения свободного ПО, разработки, ведущиеся открытым образом («открытыми текстами»), все время держали эту СУБД в зоне своих интересов. Когда некоторые представители такого ПО стали достаточно зрелыми, фирма Oracle, подобно другим крупным фирмам, «легализовала» связь своей СУБД с ними: ОС Linux входит в число стратегических платформ для Oracle, web-сервер Apache входит в состав штатной поставки; там же можно обнаружить следы Perl и Tcl, нашедших себе место во внутреннх процессах установки (OUI) и администрирования (OEM). Эти средства помогают организовать взаимодействие с Oracle вместо средств собственной разработки (например, Developer) или в дополнение к ним.
PHP принадлежит к числу средств открытого ПО, не самых популярных, но вполне состоявшихся, востребованность которых непрерывно растет (см. ). PHP позволяет динамически формировать страницы HTML на сервере web. В этом качестве он занимает нишу, общую с EmbPerl, Mason, Aquaruim (все – свободное ПО) и сервлетами (например, с JavaServer Pages). Сервером web может быть Apache, IIS или же еще несколько разновидностей. Здесь нам важно, что PHP умеет обращаться к СУБД Oracle и что это легкая и простая система.
Аннотация
Встроенная в СУБД Oracle текстовая поисковая машина Oracle Text способна не только выполнять полнотекстовый поиск в документах и по кратким описаниям, но и делать проверку на соответствие заданным по желанию условиям. Для этого применяется разновидность CTXSYS.CTXRULE текстового индекса и оператор MATCHES. В статье показаны примеры их употребления. Статью удобно рассматривать как продолжение статей , и .
Иные форматы
Использованный выше способ классификации можно применять только к документам, представленным простым текстом (plain text), либо в формате HTML. К другим форматам представления документа оператор MATCHES напрямую не применим. Если выясняется, что новостная ссылка указывает на документ в ином формате (например, PDF, - а выяснение этого уже требует дополнительного программирования), остается только привести документ перед анализом в текстовый вид с помощью процедуры CTX_DOC.IFILTER. (Неявно как раз эта процедура выполняет преобразование документа при полнотекстовом индексировании и при использовании в индексе типа CTXSYS.CONTEXT фильтра CTXSYS.AUTO_FILTER). Это технически возможно, но требует дальнейшего дополнительного программирования и увеличит расходование ресурсов СУБД на выполнение анализа.
Как классифицировать текстовые документы в Oracle
,
преподаватель технологий Oracle
| Писание же твое приято бысть и разумлено внятельно. | |
| Первое послание Ивана Грозного Курбскому |
Подготовка и проведение опыта с запросами
Построим таблицу с набором запросов, которую потом будем использовать в качестве таблицы «правил», или же «таблицы классификации» документов. Выдадим в SQL*Plus:
CREATE TABLE rules ( id NUMBER PRIMARY KEY, query VARCHAR2 ( 1000 ) );
INSERT INTO rules VALUES ( 1, 'lamb' ); INSERT INTO rules VALUES ( 2, 'little OR lamb' ); INSERT INTO rules VALUES ( 3, 'lamb NOT mary' ); INSERT INTO rules VALUES ( 4, 'little lamb' ); INSERT INTO rules VALUES ( 5, 'lamb little' ); INSERT INTO rules VALUES ( 6, 'lamb NEAR mary' );
Строим индекс и готовим сценарный файл для опытов:
CREATE INDEX rules_idx ON rules ( query ) INDEXTYPE IS CTXSYS.CTXRULE;
COLUMN category FORMAT 99999 COLUMN query FORMAT A50 SELECT id category, query FROM rules WHERE MATCHES ( query, '&1' ) > 0 . SAVE matches REPLACE SET VERIFY OFF
Проверяем соответствие трех «документов» шести заведенным «классификационным признакам»:
CTX> @matches 'Mary had a little lamb'
CATEGORY QUERY -------- -------------------------------------------------- 1 lamb
6 lamb NEAR mary
2 little OR lamb
4 little lamb
CTX> @matches 'Twinkle, twinkle little star'
CATEGORY QUERY -------- -------------------------------------------------- 2 little OR lamb
CTX> @matches 'This Lamb is my lamb'
CATEGORY QUERY -------- -------------------------------------------------- 1 lamb
2 little OR lamb
3 lamb NOT mary
Дальнейшие опыты рекомендуется провести самостоятельно. При необходимости следует воспользоваться известной из предыдущего материала процедурой CTX_DDL.SYNC_INDEX перестройки индекса. Также рекомендуется удостовериться, что в плане обработки наших запросов стоит обращение к индексу RULES_IDX (имеющийся там шаг обращения к таблице RULES вызван нашим желанием выдать значение поля ID строки из этой таблицы; если этого не сделать, обращение к таблице RULES пропадет).
Получаем документ из Интернета
Если обращение в интернет будет осуществляться через приближенный (proxy) сервер, требуется предварительно выдать что-то вроде:
EXECUTE UTL_HTTP.SET_PROXY ('http://имя:пароль@адрес:порт')
Для извлечения документа из интернета мне очень хотелось бы воспользоваться типом HTTPURITYPE, но проверка показывает, что этот тип не способен посылать запросы HTTP методом POST, а для нашей страницы, как опять-таки показывает проверка, требуется именно это. Притом, страница динамическая: обратите внимание на завершение адреса текстом ?rssid=rss_otn_news. (Несложная проверка параметров ответа при обращении по этому адресу показывает, что получателем запроса является сервлет на Oracle Application Server). Поэтому придется прибегнуть к пакету UTL_HTTP и программированию.
Для удобства занесем основную часть адреса и параметры в переменные SQL*Plus:
VARIABLE url VARCHAR2 ( 1000 ) VARIABLE parameters VARCHAR2 ( 1000 ) VARIABLE length VARCHAR2 ( 1000 )
EXECUTE :url := - 'http://www.oracle.com/technology/pub/articles/hunter_rac10gr2_iscsi.html' EXECUTE :parameters := 'rssid=rss_otn_news' EXECUTE :length := '18'
Для простоты количество символов в подстроке параметров (18) я посчитал вручную.
Заведем переменную SQL*Plus для хранения документа:
VARIABLE htmlclob CLOB EXECUTE :htmlclob := EMPTY_CLOB ( )
При работе учтите, что значение переменной SQL*Plus типа CLOB потеряется, как только вы завершите сеанс связи с СУБД, например в результате выдачи CONNECT. (В действительности, переменная HTMLCLOB есть переменная-«локатор», указывающий на временный LOB-объект со временем жизни сеанса; этот-то LOB-объект и пропадает без нашей воли по завершению сеанса, после чего локатор начнет указывать «в никуда»).
Следующий блок на PL/SQL прочтет по нужному адресу в интернете документ и разместит его в переменной SQL*Plus:
DECLARE req UTL_HTTP.REQ; resp UTL_HTTP.RESP; name VARCHAR2 ( 256 ); value VARCHAR2 ( 4000 );
BEGIN req := UTL_HTTP.BEGIN_REQUEST ( :url, method => 'POST' ); UTL_HTTP.SET_HEADER ( r => req, name => 'Content-Type', value => 'text/html' ); UTL_HTTP.SET_HEADER ( r => req, name => 'Content-Length', value => :length ); UTL_HTTP.WRITE_LINE ( r => req, data => :parameters ); resp := UTL_HTTP.GET_RESPONSE ( req );
DBMS_OUTPUT.PUT_LINE ( 'HTTP response status code: ' resp.status_code ); DBMS_OUTPUT.PUT_LINE ( 'HTTP response reason: ' resp.reason_phrase );
LOOP UTL_HTTP.READ_LINE ( resp, value, TRUE ); :htmlclob := :htmlclob value; END LOOP;
EXCEPTION WHEN UTL_HTTP.END_OF_BODY THEN UTL_HTTP.END_RESPONSE ( resp ); END; /
Выдача на экран добавлена для контроля. Проверить, что документ действительно прочитался, можно, например, так:
CTX> EXECUTE DBMS_OUTPUT.PUT_LINE ( DBMS_LOB.GETLENGTH ( :htmlclob ) ) 166426
PL/SQL procedure successfully completed.
При желании можно было пометить документ в таблицу, но здесь довольно и оставить его в переменной SQL*Plus.
Пример с реальными документами
Простой пример выше позволяет понять логику классификации и технические моменты. Теперь попытаемся рассмотреть более жизненный пример. Жизненной будет ситуация, в то время как технологически для лучшего понимания существенного далее все же будет сделан ряд допущений и технических упрощений.
В статье рассматривалось заведение в БД и индексирование «картотеки» с краткими описаниями новостей, полученных из канала RSS в интернете для Oracle Technology Network, и со ссылками на источник. Возьмем одну такую ссылку:
CTX> COLUMN link FORMAT A75 CTX> SELECT link FROM otnnews WHERE ROWNUM = 1;
LINK --------------------------------------------------------------------------- http://www.oracle.com/technology/pub/articles/hunter_rac10gr2_iscsi.html?rs sid=rss_otn_news
Вот начало документа HTML, расположенного по этой ссылке:
Проделаем следующее:
Извлечем по этой ссылки документ в БД. Построим более реальный набор классификационных правил. Проверим документ на соответствие правилам.
Простой пример
Существенным технологическим отличием «оборотного» индекса CTXSYS.CTXRULE от CTXSYS.CONTEXT является то, что последний можно строить для документов как внутри БД, так и вне ее (файловая система, интернет), а первый - только для документов, «внутри», то есть хранящихся либо в переменной программы, либо в столбце типа VARCHAR2 или же CLOB таблицы БД (только эти два типа и допускает оператор MATCHES). Причина такого ограничения разработчиками не раскрывается. В этом простом примере будем считать, что документы хранятся в программе, в строке типа VARCHAR2.
Проводим классификацию
Создадим таблицу классификации, заполним ее правилами и построим индекс:
CREATE TABLE category ( id NUMBER, query VARCHAR2 ( 2000 ) );
INSERT INTO category VALUES ( 1, 'rac | "real application clusters"' ); INSERT INTO category VALUES ( 2, 'linux | unix' ); INSERT INTO category VALUES ( 3, 'installation | configuration' ); INSERT INTO category VALUES ( 4, 'ms windows OR microsoft NEAR windows' ); INSERT INTO category VALUES ( 5, 'standby AND switchover' );
CREATE INDEX category_idx ON category ( query ) INDEXTYPE IS CTXSYS.CTXRULE;
Проверка:
CTX> COLUMN query FORMAT A60 CTX> SELECT id, query FROM category WHERE MATCHES ( query, :htmlclob ) > 0;
ID QUERY ---------- ---------------------------------------- 1 rac | "real application clusters" 2 linux | unix 3 installation | configuration 4 ms windows OR microsoft NEAR windows
В данном случае документ удовлетворяет четырем категориям имеющейся классификации под номерами 1 - 4 и не удовлетворяет категории под номером 5.
«Словесный шум»
Если документ, как в нашем случае, представлен страницей HTML в интернете, он, как правило, содержит не относящуюся к делу информацию (то есть, для нас - шум), в том числе в виде текста. Ненужные нам слова могут появиться вследствие желания разработчиков места в интернете показать на странице направления дальнейшей навигации, или же попросту могут относиться к рекламе. Рассмотренный способ фактически анализирует текст страницы HTML, а не документа, и как отфильтровать не относящиеся к делу слова, мне неизвестно. Остается только надеяться, что подобное словесное сопровождение документа, как это нередко бывает, будет порождаться средствами JavaScript и программой чтения «документа» (страницы) останется незамеченным.
Если документ представлен файлом формата PDF, RTF, простого текста или иным, проблема попадания в поле зрения не относящихся к документу слов не возникает.
Составной документ
Вернемся воочию к документу, который только что проанализировали. Обратите внимание на его завершение:
Интерес привлекает фрагмент в конце страницы, который я обвел эллипсом. Судя по всему, наш документ не исчерпывается одной страницей HTML и состоит на деле из трех страниц! Фактический переход по ссылкам Page 2 и Page 3 подтверждает эту догадку. Это - одна из сложностей, которая может нас подстерегать при организации автоматического классифицирования.
Технически проблему документа, логически единого, но разнесенного по нескольким страницам, можно учесть дополнительным программированием, включающим выявление подобного рода продолжений, но при этом мы вынуждены будем учитывать особенности вполне конкретного канала новостей RSS, так как в другом канале ссылки на продолжение документа могут оказаться организованы совсем иначе. Это лишит создаваемую программу автоматического классифицирования общности.
Техническая организация индекса
Обращение к таблицам USER_OBJECTS и USER_SEGMENTS позволяет уточнить технику реализации индекса типа CTXSYS.CTXRULE. Вот примерно каким в нашем случае будет список логических объектов, возникших в результате выдачи команды CREATE INDEX rules_idx ...:
OBJECT_NAME OBJECT_TYPE ------------------------------ ----------------------- DR$RULES_IDX$I TABLE DR$RULES_IDX$K TABLE DR$RULES_IDX$N TABLE DR$RULES_IDX$R TABLE RULES TABLE DR$RULES_IDX$X INDEX RULES_IDX INDEX SYS_IOT_TOP_53386 INDEX SYS_IOT_TOP_53391 INDEX SYS_LOB0000053383C00006$$ LOB SYS_LOB0000053388C00002$$ LOB
А вот примерно какие появятся структуры хранения:
SEGMENT_NAME SEGMENT_TYPE ------------------------------ ----------------------------- DR$RULES_IDX$X INDEX SYS_C005906 INDEX SYS_IOT_TOP_53386 INDEX SYS_IOT_TOP_53391 INDEX SYS_IL0000053383C00006$$ LOBINDEX SYS_IL0000053388C00002$$ LOBINDEX SYS_LOB0000053383C00006$$ LOBSEGMENT SYS_LOB0000053388C00002$$ LOBSEGMENT DR$RULES_IDX$I TABLE DR$RULES_IDX$R TABLE RULES TABLE
Очевидно, техническая организация индекса типа CTXSYS.CTXRULE почти та же, что и для типа CTXSYS.CONTEXT, то есть это четыре таблицы и необходимые для них служебные структуры. (Почти - потому что в таблице DR$RULES_IDX$I в нашем случае появилось дополнительное поле TOKEN_EXTRA. Дальнейшее изучение предлагается предпринять самостоятельно).
В наборах из нескольких запросов-«правил», подобно нашему случаю, это приводит к чудовищному перерасходу дисковой памяти; очевидно, сама возможность рассчитана на большие наборы.
В жизни может быть сложнее
Реальность нередко оказывается сложнее, чем хотелось бы. Вот примеры.
в СУБД Oracle поисковая текстовая
В настоящее время встроенная в СУБД Oracle поисковая текстовая машина Oracle Text поддерживает работу с тремя разновидностями предметного (DOMAIN), текстового индекса: типов CTXSYS.CONTEXT, CTXSYS.CTXCAT и CTXSYS.CTXRULE. Первые два обеспечивают поиск, соответственно, полнотекстовый - в полноценных документах, и в «картотеке» с краткими описаниями (так сказать, в «каталоге») - по предъявленному к тексту запросу. Тип же индекса CTXSYS.CTXRULE по отношению к ним не совсем обычен и может рассматриваться как «оборотный» к типу CTXSYS.CONTEXT. Он строится по набору запросов, а не по документам, и его назначение - определить результативность каждого запроса из этого набора применительно к предъявляемому документу. Запросы в наборе, по которому строится индекс, вольно иначе назвать «правилами» (отсюда слово rule в названии индекса ), и проверку соответствия определенного документа тому или иному правилу вольно, опять-таки, рассматривать как классифицирование документа.
Некоторые основные возможности использования индекса типа CTXSYS.CTXRULE будут рассмотрены ниже на двух примерах: простом и более реалистичном.
а также трех предшествующих, посвященных
Материала настоящей статьи, а также трех предшествующих, посвященных возможностям Oracle Text, достаточно для понимания того, как запрограммировать автоматический сбор новостей из интернета и выполнять автоматическую классификацию.
Выполнять полнотекстовый поиск, а также классификацию, можно к тому же применительно к документам, находящимся не только в интернете, но и в БД, и в файловой системе.
В то же время затронутые возможности являются базовыми, начальными, и не исчерпывают содержание Oracle Text. Например, за рамками рассмотрения оказались средства «интеллектуального анализа» документов, которые по аналогии с Data Mining получили название Text Mining. Описывать эти средства мимоходом нереально.
| 1(к тексту) | Возможно более уместно здесь было бы привести для слова rule другой, более специфичный перевод "направляющая". |
Аннотация
Oracle Text есть штатная возможность СУБД Oracle хранить в общей БД наряду с обычными данными документы и строить запросы, как к этим документам, так и к хранимым в файлах ОС или в интернете. Документы могут быть представлены разными форматами. Рассматриваются начала работы с Oracle Text на основе использования текстового индекса типа CTXSYS.CONTEXT и оператора CONTAINS.
Oracle: работать с текстовыми документами очень просто
,
преподаватель технологий Oracle
| Все началось с маленькой бумажки, которую принес в брезентовой разносной книге ленивый скороход из коммунотдела. | |
| И. Ильф, Е. Петров. Золотой теленок. |
Планы выполнения запросов
Неуклюжесть (отчасти вынужденная) правки текстового индекса компенсируется высокой скоростью обращения к нему при запросах к СУБД. Однако наблюдать план выполнения запроса приходится в этом случае своеобразно. Обычная команда EXPLAIN PLAN много не даст, но обращение к текстовому («прикладному») индексу она отметит:
CTX> EXPLAIN PLAN FOR 2 SELECT * FROM docs 3 WHERE CONTAINS ( vc2doc, 'twinkle AND star' ) > 0;
Explained.
CTX> SELECT * FROM TABLE ( dbms_xplan.display );
PLAN_TABLE_OUTPUT --------------------------------------------------------------------------------------
Plan hash value: 3477406887
-------------------------------------------------------------------------------------- | Id | Operation | Name |Rows|Bytes|Cost (%CPU)|Time | -------------------------------------------------------------------------------------- | 0| SELECT STATEMENT | | 1| 2027| 4 (0)|00:00:01| | 1| TABLE ACCESS BY INDEX ROWID| DOCS | 1| 2027| 4 (0)|00:00:01| |* 2| DOMAIN INDEX | DOCS_VC2DOC_IDX | | | 4 (0)|00:00:01| --------------------------------------------------------------------------------------
Predicate Information (identified by operation id): ---------------------------------------------------
2 - access("CTXSYS"."CONTAINS"("VC2DOC",'twinkle AND star')>0)
Note ----- - dynamic sampling used for this statement
(Форма выдачи плана соответствует версии 10, по которой готовился материал).
Детали отработки самого текстового (не SQL) запроса наблюдаются через специальную таблицу, а не привычную PLAN_TABLE. Создать ее можно примерно так:
CREATE GLOBAL TEMPORARY TABLE ctx_explain ( explain_id VARCHAR2 ( 30 ) , id NUMBER , parent_id NUMBER , operation VARCHAR2 ( 30 ) , options VARCHAR2 ( 30 ) , object_name VARCHAR2 ( 64 ) , position NUMBER , cardinality NUMBER ) ON COMMIT PRESERVE ROWS ;
Просмотр плана для конкретного обращения к конкретному индексу делается через специальную процедуру из системного пакета CTX_QUERY:
BEGIN ctx_query.explain ( index_name => 'docs_vc2doc_idx' , text_query => 'twinkle AND star' , explain_table => 'ctx_explain' , explain_id => 'twinkle star' ); END; /
Пример просмотра сформированного в CTX_EXPLAIN плана обработки текстового запроса:
CTX> SELECT 2 explain_id 3 , id 4 , parent_id 5 , operation 6 , options 7 , object_name 8 , position 9 FROM 10 ctx_explain 11 ORDER BY 12 id 13 /
EXPLAIN_ID ID PARENT_ID OPERATION OPTIONS OBJECT_NAME POSITION -------------- --- ---------- --------- ------- -------------- ---------- twinkle star 1 0 AND 1 twinkle star 2 1 WORD TWINKLE 1 twinkle star 3 1 WORD STAR 2
Подготовка данных
Для удобства создадим специального пользователя:
> CONNECT / AS SYSDBA
SYS> CREATE USER ctx IDENTIFIED BY ctx DEFAULT TABLESPACE users;
SYS> GRANT connect, resource, ctxapp TO ctx;
SYS> CONNECT ctx/ctx
CTX>
Роли CONNECT и RESOURCE приписаны пользователю CTX для простоты примера, и использовать их в рабочей БД неправильно; роль же CTXAPP употреблена по существу, так как без нее пользоваттель CTX не сможет обращаться к необходимым объектам схемы CTXSYS. Выполним:
CREATE TABLE docs ( doc_id NUMBER ( 10 ), vc2doc VARCHAR2 ( 4000 ) );
INSERT INTO docs VALUES ( 1, 'Mary had a little lamb' ); INSERT INTO docs VALUES ( 2, 'Twinkle, twinkle little star' ); INSERT INTO docs VALUES ( 3, 'This Lamb is my lamb' );
CREATE INDEX docs_vc2doc_idx ON docs ( vc2doc ) INDEXTYPE IS ctxsys.context;
Обратите внимание: индекс DOCS_VC2DOC_IDX - не простой, а «прикладной» (domain); точнее - предопределенного типа CTXSYS.CONTEXT, то есть «текстовый». В общем случае создание такого индекса содержит указание ряда специальных параметров (примеры будут далее), но для первого знакомства довольно положиться на умолчательные характеристики.
Примеры запросов
Основой для запросов к документам по индексу типа CTXSYS.CONTEXT является «оператор» CONTAINS. По своему употреблению оператор Oracle SQL практически не отличается от функции. Оператор CONTAINS возвращает меру, иначе степень, соответствия документа текстовому запросу («relevance»).
Несколько поясняющих примеров. Подготовка:
SELECT CONTAINS ( vc2doc, '&1' ) AS score, vc2doc FROM docs . SAVE simplequestion REPLACE COLUMN vc2doc FORMAT A60 SET VERIFY OFF
Проверка:
CTX> @simplequestion 'star'
SCORE VC2DOC ---------- ------------------------------------------------------------ 0 Mary had a little lamb 4 Twinkle, twinkle little star
0 This Lamb is my lamb
CTX> @simplequestion 'little'
SCORE VC2DOC ---------- ------------------------------------------------------------ 4 Mary had a little lamb 4 Twinkle, twinkle little star 0 This Lamb is my lamb
CTX> @simplequestion 'twinkle'
SCORE VC2DOC ---------- ------------------------------------------------------------ 0 Mary had a little lamb 9 Twinkle, twinkle little star 0 This Lamb is my lamb
CTX> @simplequestion 'lamb'
SCORE VC2DOC ---------- ------------------------------------------------------------ 4 Mary had a little lamb
0 Twinkle, twinkle little star 7 This Lamb is my lamb
CTX> @simplequestion 'mary AND lamb'
SCORE VC2DOC ---------- ------------------------------------------------------------ 4 Mary had a little lamb
0 Twinkle, twinkle little star 0 This Lamb is my lamb
CTX> @simplequestion 'mary lamb'
SCORE VC2DOC ---------- ------------------------------------------------------------ 0 Mary had a little lamb
0 Twinkle, twinkle little star 0 This Lamb is my lamb
Обратите внимание, что степень соответствия документа запросу не является простой частотой употребления в документе слова. Она зависит также от общего количества запрашиваемых документов и от количества документов, где есть искомые словоформы. Ее вычисление в Oracle основано на . Результат, который дает формула, отображается на диапазон целых чисел между 0 и 100.
Следующие несколько примеров, выполненных самостоятельно, помогут пояснить поведение оператора CONTAINS и получить представление о некоторых дополнительных возможностях контекстного запроса:
@simplequestion 'MARY AND LAMB' @simplequestion 'MaRy AnD lAmB' @simplequestion '%le' @simplequestion 'lamb NOT mary' @simplequestion 'NEAR ((lamb, mary) ,3)' @simplequestion 'NEAR ((lamb, mary) ,2)' @simplequestion 'mary ACCUM lamb' @simplequestion 'mary ACCUM little' @simplequestion 'mary ACCUM little lamb' @simplequestion 'lamb OR little'
Полный перечень и описания реализованых операторов для составления контекстного запроса по документам (название «оператор» здесь неудачно совпадает с именованием «оператором» самой функции CONTAINS) имеется в документации по Oracle.
Текстовый индекс
Практически обработку текстовой информации в Oracle Text обеспечивает текстовый индекс. Содержательно он организует хранение «обращенного списка», который по предъявленному поисковому слову выдает список пар <документ, словоместо>. Для этого он хранит список документов, позиций словоформ в документах и одно или несколько индексируемых слов в каждой позиции.
Технически текстовый индекс устроен сложнее обычных B-древовидного или же поразрядного индексов хотя бы тем, что реализован сразу группой объектов и группой структур хранения. В этом легко удостовериться:
CTX> COLUMN object_name FORMAT A30 CTX> COLUMN object_type FORMAT A30 CTX> COLUMN segment_name FORMAT A30 CTX> COLUMN segment_type FORMAT A30 CTX> SELECT object_name, object_type FROM user_objects ORDER BY 2, 1;
OBJECT_NAME OBJECT_TYPE ------------------------------ ------------------------------ DOCS_VC2DOC_IDX INDEX DR$DOCS_VC2DOC_IDX$X INDEX SYS_IOT_TOP_51619 INDEX SYS_IOT_TOP_51624 INDEX SYS_LOB0000051616C00006$$ LOB SYS_LOB0000051621C00002$$ LOB DOCS TABLE DR$DOCS_VC2DOC_IDX$I TABLE DR$DOCS_VC2DOC_IDX$K TABLE DR$DOCS_VC2DOC_IDX$N TABLE DR$DOCS_VC2DOC_IDX$R TABLE
CTX> SELECT segment_name, segment_type FROM user_segments ORDER BY 2, 1;
SEGMENT_NAME SEGMENT_TYPE ------------------------------ ------------------------------ DR$DOCS_VC2DOC_IDX$X INDEX SYS_IOT_TOP_51619 INDEX SYS_IOT_TOP_51624 INDEX SYS_IL0000051616C00006$$ LOBINDEX SYS_IL0000051621C00002$$ LOBINDEX SYS_LOB0000051616C00006$$ LOBSEGMENT SYS_LOB0000051621C00002$$ LOBSEGMENT DOCS TABLE DR$DOCS_VC2DOC_IDX$I TABLE DR$DOCS_VC2DOC_IDX$R TABLE
В обоих запросах все объекты БД и структуры хранения, кроме DOCS, принадлежат текстовому индексу. Точнее, в результате команды CREATE INDEX docs_vc2doc_idx ... индекс DOCS_VC2DOC_IDX (типа DOMAIN) появился только как логический объект в БД; технически его реализуют четыре возникшие служебные таблицы:
Таблица DR$DOCS_VC2DOC_IDX$I.
Хранит перечень всех словоформ, попавших в индекс, внутренний номер документа («DOCID») и список позиций словоформ в документе. Вторичные, связанные с ней объекты:
индекс DR$DOCS_VC2DOC_IDX$X (обычный, типа NORMAL), сегменты типа LOBSEGMENT и LOBINDEX для хранения данных поля TOKEN_INFO типа BLOB.
Таблица DR$DOCS_VC2DOC_IDX$K.
Хранит соответствие DOCID адресу ROWID строки с текстом или ссылкой на текст. Индексно-организованная таблица, хранится в структуре индекса. Таблица DR$DOCS_VC2DOC_IDX$R.
Хранит список для обратного поиска: ROWID по DOCID. Вторичные, связанные с ней объекты:
сегменты типа LOBSEGMENT и LOBINDEX для хранения данных поля DATA типа BLOB.
Таблица DR$DOCS_VC2DOC_IDX$N.
Хранит список удаленных документов (DOCID) пополняющийся при оптимизации текстового индекса. Индексно-организованная таблица, хранится в структуре индекса.
Пример выдачи из таблицы DR$DOCS_VC2DOC_IDX$I:
CTX> SELECT token_text, token_count FROM dr$docs_vc2doc_idx$i;
TOKEN_TEXT TOKEN_COUNT ------------------------------------------------- ----------- LAMB 2 LITTLE 2 MARY 1 STAR 1 TWINKLE 1
Еще одно отличие текстового индекса от обычного в том, что он не правится автоматически при правке документа. Например:
CTX> UPDATE docs SET vc2doc = 'This Land is my land' WHERE doc_id = 3;
1 row updated.
CTX> COMMIT;
Commit complete.
CTX> SELECT token_text, token_count FROM dr$docs_vc2doc_idx$i;
TOKEN_TEXT TOKEN_COUNT ------------------------------------------------- ----------- LAMB 2 LITTLE 2 MARY 1 STAR 1 TWINKLE 1
В силу громоздкости текстового индекса сведения о необходимых исправлениях собираются в отдельной таблице, а сама правка выполняется по мере надобности вручную:
CTX> SELECT pnd_index_name, pnd_rowid FROM ctx_user_pending;
PND_INDEX_NAME PND_ROWID ---------------------------- ------------------ DOCS_VC2DOC_IDX AAAMm2AAEAAAABAAAC
CTX> EXECUTE CTX_DDL.SYNC_INDEX ( 'docs_vc2doc_idx' )
PL/SQL procedure successfully completed.
CTX> /
no rows selected
CTX> SELECT token_text, token_count FROM dr$docs_vc2doc_idx$i;
TOKEN_TEXT TOKEN_COUNT ------------------------------------------------- ----------- LAMB 2 LAND 1
LITTLE 2 MARY 1 STAR 1 TWINKLE 1
(Синхронизировать индекс можно и командой ALTER INDEX, но сейчас фирма Oracle этого не советует).
Стандартный прием - создать задание для плановой корректировки текстового индекса по расписанию.
Возможности иной формулировки
На практике использование обращения к CONTAINS в выражениях для формирования столбцов в предложении SELECT не всегда удобно и не способствует эффективности. Вынужденная в этом отношении мера - использование функции («оператора») SCORE, возвращающей тот же результат, что и CONTAINS, но которую можно повторять в запросе многократно без боязни замедлить вычисление. Однако поскольку операторов CONTAINS в запросе может встречаться несколько, придумана специальная техника числовых «меток», устанавливающих соответствие операторов SCORE и CONTAINS в рамках запроса SQL. Метки указываются как параметр операторов (еще одна вынужденная и не очень элегантная мера) и выбираются произвольно. Примеры этой техники:
CTX> SELECT SCORE ( 1 ), vc2doc 2 FROM docs 3 WHERE CONTAINS ( vc2doc, 'lamb', 1 ) > 0 4 ORDER BY SCORE ( 1 ) DESC 5 ;
SCORE(1) VC2DOC ---------- ------------------------------------------------ 7 This Lamb is my lamb 4 Mary had a little lamb
CTX> SELECT SCORE ( 1 ), SCORE ( 15 ), vc2doc 2 FROM docs 3 WHERE 4 CONTAINS ( vc2doc, 'lamb', 1 ) > 0 5 OR CONTAINS ( vc2doc, 'lamb AND mary', 15 ) > 0 6 ORDER BY 7 SCORE ( 15 ) DESC 8 ;
SCORE(1) SCORE(15) VC2DOC ---------- ---------- ---------------------------------- 4 4 Mary had a little lamb
7 0 This Lamb is my lamb
в первую очередь как система
СУБД Oracle известна в первую очередь как система управления «фактографическими» данными, но с первой половины 90-х годов в ней стали появляться возможности хранить и обрабатывать «сложно устроенные» данные. Одной из первых таких возможностей стала работа в версии 7.3 с частично структурированными данными: текстовыми документами.
До наших дней возможность работы с текстовыми документами в Oracle несколько раз поменяла название (SQL*TextRetrieval -> Text Server -> Oracle ConText -> Oracle Text) и существенно развилась. Начиная с версии 9, она встроена в обычную поставку СУБД Oracle, не требует, как ранее, отдельного лицензирования и автоматически включается в состав типовой БД. При отсутствии же в БД эту возможность можно установить самостоятельно либо при помощи DBCA, либо прогоном сценария dr0inst.sql (версия 9 и предшествующие) или же catctx.sql (с версии 10) в [ORACLE_HOME]/ctx/admin.
Текстовые возможности Oracle находят внутреннее употребление, например в Oracle Ultra Search, Content Management (ранее iFS) или в XML DB.
Текстовые возможности СУБД Oracle основаны на использовании специального вида индекса, являющегося одним из встроенных в систему вариантов «предметного» индекса (domain index), используемого для организации работы со сложно устроенными данными. Oracle Text имеет в готовом виде три вида текстового индекса:
CTXSYS.CONTEXT - для выполнения полнотекстового поиска по текстовым документам; CTXSYS.CTXCAT - для выполнения упрощенного и ускоренного поиска по «каталогам» (одно-двустрочным текстовым описаниям); CTXSYS.CTXRULE - для построения «классификаций» документов при том, что класс описывается набором характерных запросов.
Здесь рассматриваются общие возможности наиболее популярной разновидности индекса CTXSYS.CONTEXT. Этот вид текстового индекса позволяет хранить в БД текстовые документы и выполнять полнотекстовые запросы к документам как внутреннего хранения, так и внешнего (файловая система, интернет).
