Что такое обмен секций?
Одна из замечательных возможностей секционирования, в частности, секционирования по диапазону, - это возможность быстро и легко загружать новые данные, минимально влияя на работу текущих пользователей. В руководствах сказано, что принципиальное значение для достижения этого имеет команда вида:
alter table pt_tab1 exchange partition p_9999 with table new_data -- including indexes -- необязательная конструкция -- without validation -- необязательная конструкция ;
Эта команда "взламывает" словарь данных и меняет местами определения указанной секции и таблицы new_data, так что данные неожиданно оказываются в нужном месте в секционированной таблице. Более того, с добавлением двух необязательных дополнительных конструкций, будут заменены также определения индексов и Oracle не будет проверять, принадлежат ли реально данные указанной секции - поэтому обмен выполняется очень быстро.
Или так обычно пишут.
Обычно в статье, демонстрирующей это свойство обмена секций, будет создаваться таблица с несколькими секциями и парой сотен строк в каждой секции, вполне возможно, вообще без индексов, и почти наверняка без каких-либо связанных с ней таблиц.
Обычно, если вы заплатили за поддержку секционирования (partitioning option), таблицы у вас - очень большие, по ним есть несколько индексов и связанные внешними ключами таблицы. Так что же происходит в реальной жизни при выполнении обмена секций?
Обходные пути
В ваших специальных случаях вы вполне можете находить приемлемые решения или даже пути обхода этих проблем. Например, один (несомненно, жизнеспособный) способ обойти проблему отключения ограничений внешнего ключа опирается на тот факт, что можно удалять секцию в главной таблице, если в ней никогда не было никаких данных. Если "поиграться" с этой идеей, можно найти следующую стратегию удаления пары секций при наличии ограничений всего лишь в режиме novalidate:
создаем пустую таблицу parent_clone с индексами
удаляем секцию подчиненной таблицы
обмениваем секцию главной таблицы с parent_clone, указав конструкции without validation и including indexes
удаляем секцию в главной таблице, что теперь допустимо, поскольку она никогда не содержала данных
удаляем таблицу parent_clone, в которой и находятся все данные
Я не уверен, однако, что это абсолютно безопасно. Что, если отсуствие сообщения об ошибке Oracle ORA-02266 в этом особом случае- ошибка? Что вы будете делать, если корпорация Oracle включит исправление этой ошибки в следующий набор исправлений?
Остановить печать!
Незадолго до того, как я собрался посылапть эту статью в DBAZine
для публикации, я установил обновление до версии 9.2.0.4 и обнаружил замечание в списке исправленных ошибок, утверждающее, что ошибка, которая "может вызывать медленное выполнение обмена для таблиц с ограничениями уникальности", была исправлена. Решение состояло в удалении проверки ограничения, описанной в этой статье.
Джонатан Льюис () - независимый консультант с более чем 18-летним опытом использования Oracle. Он специализируется на физическом проектировании баз данных и стратегии использования сервера Oracle. Джонатан - автор книги "Practical Oracle 8i - Building Efficient Databases", опубликованной издательством Addison-Wesley, и один из наиболее известных лекторов среди специалистов по Oracle в Великобритании. Подробнее о его публикациях, презентациях и семинарах можно узнать на сайте
www.jlcomp.demon.co.uk, где также находится список ЧаВО The Co-operative Oracle Users' FAQ
по дискуссионным группам Usenet, связанным с СУБД Oracle.
Эта статья первоначально была опубликована на сайте DBAzine.com, сетевом портале, посвященном проблемам различных СУБД и их решениям. Перевод публикуется с разрешения автора.
Секции в реальном мире
Джонатан Льюис (Jonathan Lewis)
www.jlcomp.demon.co.uk
Перевод: , OpenXS Initiative
Вы обращали внимание, что в большинстве статей о возможностях Oracle для демонстрации преимуществ, которые хотят подчеркнуть, используются абсолютно тривиальные примеры? А обратили ли вы внимание, что только при попытке реального использования возможности начинают выявляться проблемы?
В этой статье представлены некоторые из проблем, возникающих при реальном использовании возможности обмена секции (exchange partition). В статье была использована версия Oracle 9.2.0.3- другие версии могут вести себя иначе.
У вас реляционная база данных?
Но всегда следует ждать в дальнейшем новостей и похуже. В данном случае, у вас может быть две секционированных таблицы с некоторой связью между ними (такое я наблюдал во многих системах). Как это влияет на работу с секциями?
create table child ( id_p number(12,6), seq_c number(10), v1 varchar2(10), padding varchar2(100), constraint c_fk_p foreign key (id_p) references parent, constraint c_pk primary key (id_p, seq_c) using index local ) partition by range(id_p) ( partition p1000 values less than (1000), partition p3000 values less than (3000), partition p5000 values less than (5000) );
Обратите внимание, кстати, как эта подчиненная таблица (с ограничением внешнего ключа) создана в соответствии с границами секций главной таблицы - эта архитектура помогает добиться специальной оптимизации соединения на уровне секций.
Когда вы начнете экспериментировать со связями главная-подчиненная, то обнаружите, что обмен секций жестко ограничен, если только не начать повсеместно переводить ограничения в состояние novalidate.
А потом все становится ещё хуже! Если вы когда-то решите удалить старые секции, это можно сделать простым оператором:
alter table child drop partition p1000; alter table parent drop partition p1000;
Если вы попытаетесь выполнить эти операторы на тестовом примере, который мы ранее использовали, то обнаружите, что они работают быстро и эффективно. К сожалению, наш тестовый пример весьма специфичен: удаляемые секции никогда не содержали никаких данных. Фактически же, при удалении пар секций в главной и подчиненной таблицах возникает три проблемы.
Первая проблема - если вы попытаетесь удалить пару секций главной/подчиненной таблицы, и в секции главной таблицы когда-либо были какие-то данные, то попытка удалить (или очистить, truncate) секцию главной таблицы приведет к выдаче сообщения об ошибке:
ORA-02266: unique/primary keys in table referenced by enabled foreign keys
Чтобы удалить секцию в главной таблице, придется отключить ограничение внешнего ключа - даже когда вы удаляете "очевидно" соответствующую секцию подчиненной таблицы. Это, конечно, вполне обоснованно, но интуитивно кажется "нечестным".
Вторая проблема - когда вы удаляете секцию, каждую секуию после нее надо перенумеровать (внутренне) в словаре данных. Представьте себе секционированную таблицу с 3000 секций и двумя локально секционированными индексами. При удалении первой секции сервер Oracle перенумеровывает 9000 строк в словаре данных - и делает это построчно. Один оператор drop
приводит к выполнению 9000 отдельных изменений. Это небыстро.
Наконец, как только вы выполнили первый оператор drop
(предположительно, для подчиненной таблицы), таблицы перестают быть одинаково секционированными - все соответствующие SQL-курсоры делаются недействительными (такое происходит при любой операции сопровождения с секциями) и оптимизируются заново, и оптимизатор не будет использовать посекционные соединения (partition-wise joins), пока не будет удалена соответствующая секция. Надо хорошо подумать, выбирая время для удаления секций.
Во что обходится обмен секций?
Давайте начнем с действительно простого случая- обмена таблицы из 1000000 строк с пустой секцией. Давайте начнем с SQL-операторов для создания секционированной таблицы и не секционированной таблицы - мы будем повторно использовать этот код, с некоторыми изменениями, в оставшейся части статьи. Нам также понадобится табличное пространство, в котором будет около 200 Мбайт свободного места.
create table parent ( id number(12,6), v1 varchar2(10), padding varchar2(100) ) partition by range(id) ( partition p1000 values less than (1000), partition p3000 values less than (3000), partition p5000 values less than (5000) );
create table parent_ex ( id number(12,6), v1 varchar2(10), padding varchar2(100)) nologging -- чтобы сэкономить немного времени ;
insert /*+ append ordered full(s1) use_nl(s2) */ into parent_ex select 3000 + trunc((rownum-1)/500,6), to_char(rownum), rpad('x',100) from sys.source$ s1, -- необходима соответствующая привилегия sys.source$ s2 where rownum <= 1000000;
А теперь давайте обменяем таблицу с секцией P5000, которой и принадлежат эти данные. Но давайте включим timing, чтобы увидеть, сколько времени на это потребуется.
alter table parent exchange partition p5000 with table parent_ex;
Elapsed: 00:00:17.06
Что произошло с "очень быстрым" переносом? Повторите тест с включенным sql_trace и вы обнаружите в трассировочном файле следующий SQL-оператор. Сервер Oracle проверяет, есть ли в таблице parent_ex строки, не принадлежащие указанной секции таблицы parent.
select 1 from "PARENT_EX" where TBL$OR$IDX$PART$NUM("PARENT",0,0,65535,"ID") != :1
Для этого необходимо выполнить полный просмотр таблицы и вызывать функцию для каждой строки в загружаемой таблице - представьте себе результат в реальной системе с большими объемами данных и загруженной подсистемой ввода-вывода.
Но не бойтесь, - именно для таких случаев предназначена конструкция without validation. Повторите эксперимент, но поместите в конце команды exchange эту конструкцию.
alter table parent exchange partition p5000 with table parent_ex without validation;
Elapsed: 00:00:00.00
Ур-ра - так работает намного быстрее! Но, не торопитесь с выводами; в реальных базах данных обычно есть индексы и ограничения первичного или уникального ключа. Поэтому давайте повторим упражнение, но добавим ограничение первичного ключа к основной и обмениваемой таблице перед обменом (Обратите внимание на синтаксис версии 9 для полного указания индекса при добавлении ограничения - я решил обеспечить выполнение ограничения уникального/первичного ключа с помощью уникального индекса). В этом случае, мы, вероятно, захотим включить в процесс обмена и индексы, чтобы данные оказались в основной таблице с пригодной к использованию секцией индекса.
alter table parent add constraint p_pk primary key(id) using index (create index p_pk on parent(id) nologging local);
alter table parent_ex add constraint px_pk primary key(id) using index (create index px_pk on parent_ex(id) nologging);
alter table parent exchange partition p5000 with table parent_ex including indexes without validation;
Elapsed: 00:00:28.05
А теперь что произошло? Повтор (не такой уж быстрый) эксперимента с включенным sql_trace выдает представленный ниже SQL-оператор. Сервер Oracle проверяет, что обмен не приведет к проблеме с уникальностью. Запрос просматривает всю таблицу parent (исключая секцию, которую мы обмениваем), чтобы узнать, нет ли дубликатов загружаемых нами строк. Это собенно глупо, поскольку ограничение уникальности поддерживается с помощью локального индекса, поэтому он обязательно включает ключ секционирования, а это означает, что строка может быть только в одной секции, и мы уже пообещали (с помощью конструкции without validation), что все строки принадлежат той секции, в которую мы их помещаем. Конечно, верно, что в других секциях могут быть строки, которые должны бы находиться в загружаемой секции, но и в этом случае я не думаю, что хочу тратить время на их поиск прямо сейчас.
Проверка значений на определенность также кажется немного странной, поскольку в данном случае у нас есть ограничение первичного ключа, которое неявно предполагает ограничение not null. Можно предположить, что это сделано, чтобы использовать тот же код не только для ограничений первичного ключа, но и для ограничений уникальности.
Обратите внимание, в частности, на операторы minus и intersect
- они требуют сортировки всего результирующего множества, и я ещё легко отделался со своими 28 секундами, поскольку (a) у меня не было данных в исходной таблице parent, и (b) данные в таблице parent_ex уже были отсортированы.
select "ID" from "TEST_USER"."PARENT_EX" where not( "ID" is null) intersect select "ID" from ( select "ID" from "TEST_USER"."PARENT" minus select "ID" from "TEST_USER"."PARENT" partition (P5000) ) B where not( "ID" is null)
Можно ли обойти эти огромные затраты? Да, и все, что нужно сделать - перевести ограничения по обеим таблицам в состяние novalidate перед выполнением обмена.
alter table parent_ex modify primary key novalidate; alter table parent modify primary key novalidate;
Общее назначение опции novalidate для ограничени - сообщить серверу Oracle, что он не должен проверять уже существующие данные, чтобы убедиться, что они соответствуют ограничению. Новые данные или изменения, которые вы будете делать в старых данных, будут, однако, проверяться, поскольку ограничение все равно действует.
Но тут есть очень тонкая скрытая ловушка. Существует специальный алгоритм оптимизатора, который оценивает стоимость ограничений первичного и уникального ключа ниже обычного, если только ограничение не допускает отложенную проверку или (как мы только что его установили) не находится в состоянии novalidate. Если мы изменим состояние ограничений с validate на novalidate, чтобы снизить затраты на обмен секций, мы можем обнаружить, что при этом случайный запрос начал выполняться иначе!
Так что, пожалуй, лучше оставить ограничения в состоянии validate, и не гнаться за "дешевизной", просто установив опцию without validation
при обмене. Один проход по добавляемым данным может быть куда более приемлемым, чем альтернативные варианты.
Практически неизбежно использование новых возможностей
Практически неизбежно использование новых возможностей потребует затрат процессорного времени, операций ввода-вывода и времени разработчиков. Убедитесь, что протестировали возможность в реальных условиях, прежде чем начинать использовать ее в системе.
Могут быть побочные эффекты, которых вы не заметите, если проверяете только, что работают новые синтаксические конструкции.
Когда вы знаете, во что обойдется новая возможность, вы сможете принять обоснованное решение о том, как использовать ее в своем приложении.
Использованные средства
Сервер базы данных Oracle8i, Выпуск 3 (8.1.7); Linux 6.2 Red Hat и
Quest Software's Benchmark Factory3.0.
Чтобы использовать эти технологии, вы должны обладать достаточными знаниями как в администрировании базы данных Oracle, и в управлении операционной системой Linux (или родственной ей UNIX). Но независимо от того, являетесь ли Вы официальным АБД и сисадмином UNIX, или просто АБД и "новичком" в Linux, основные советы и методы, приведенные здесь, сэкономят вам много времени. К числу рассматриваемых вопросов относятся установки файла параметров базы данных Oracle, версии ядра Linux, установки ядра и ключи трансляции, а также опции расширенной файловой системы и компилятора.
Сегодня меня, как и многих людей, приводит в восторг продвижение Linux, не только потому, что я в основном являюсь администратором базы данных на UNIX, но также и из-за той удивительной скорости, с какой такие основные производители, как Dell, HP/Compaq, IBM и Oracle, ухватились за эту открытую в исходных кодах операционную систему. В прошлом июле на выставке LinuxWorld Ларри Эллисон объявил, что к концу года все внутренние бизнес-системы в корпорации Oracle будут эксплуатироваться на Linux-кластерах (http://otn.oracle.com/techblast/archive/june2002.html) , что доказывает, что Linux – не просто преходящее увлечение.
Но что, если вы все еще эксплуатируете Oracle8i, и не совсем готовы к RAC (http://otn.oracle.com/products/oracle9i/pdf/rac_building_ha_rel2.pdf) (Real Application Clusters)? Должно удостовериться, что "выжали из репы все – до последней капли", когда мы развертываем Intel-серверы с Linux, особенно в тех случаях, когда базы данных Oracle эксплуатируются в промышленном режиме. Верите вы этому или нет, но весьма просто добиться повышения производительности базы данных на 1 000 процентов, если надлежащим образом настроить и сконфигурировать базу данных для Linux.
В этой статье я сделаю обзор некоторых подходов, обеспечивающих высокую окупаемость инвестиций (ROI - return-on-investment). Вы увидите, что по ставшему промышленным стандартом эталонному тесту от TPC (Transaction Processing Performance Council - Совет по средствам обработки транзакций) время загрузки тестовой базы данных улучшилось на 1 015 процентов, а число выполняемых за секунду транзакций увеличилось больше, чем на 45 процентов. Это в 10 раз быстрее по загрузке данных, и почти вдвое выше по скорости транзакций – на тех же самых аппаратных средствах. В части 2 этой серии мы углубимся в более “темные” и трудные методы. [От редакции OM/RE: перевод второй статьи этой серии будет опубликован в следующем номере нашего журнала. ]
Легкое достижение высокой производительности сервера базы данных (низко висящие яблоки)
Я начну с рассмотрения типичного создания базы данных. Люди часто начинают с задаваемой по умолчанию базы данных, созданной при помощи Oracle Installer, или с базы данных, которая была создана Database Configuration Assistant. Как бы то ни было, параметры по умолчанию, вообще говоря, довольно не оптимальны. Но АБД-новичок или консультант, выдающий себя за АБД, может выбрать такие значения, которые сделают ситуацию еще хуже. Дело в том, что базы данных, созданные с плохими параметрами инициализации и использующие табличные пространства для словаря данных подобно тому, как это показано в Таблице 1, встречаются не так уж редко.
Таблица 1: Типичные начальные параметры настройки базы данных
| Размер блока базы данных | 2 КБ |
| Буферный кэш SGA | 64 МБ |
| Разделяемый пул SGA | 64 МБ |
| Журнальный буфер в SGA | 4 МБ |
| Файл журнала регистации событий | 4 МБ |
Табличные пространства
Управление по словарюРезультаты TPC-C (первичные значения)
| Время загрузки (сек) | 49,41 |
| Транзакций/сек | 8,152 |
Очевидно, что самым первым должно стать увеличение размера SGA. Поэтому я увеличиваю буферный кэш и разделяемый пул, как показано в Таблице 2.
Таблица 2: Увеличение размера буферного кэша и разделяемого пула
| Размер блока базы данных | 2 КБ |
| Буферный кэш SGA | 128 МБ |
| Разделяемый пул SGA | 128 МБ |
| Журнальный буфер в SGA | 4 МБ |
| Файл журнала регистации событий | 4 МБ |
| Табличные пространства | Управление по словарю |
Результаты TPC-C
| Время загрузки (сек) | 48,57 |
| Транзакций/сек | 9,15 |
Это не совсем то, на что я не надеялся, так как улучшение времени загрузки произошло всего лишь на 1,73 процента, а увеличение скорости транзакций (transactions per seconds – TPS) на 10,88 процента. Возможно, я должен был увеличить и журнальный буфер в SGA, но я не хочу, чтобы журнал регистации событий был меньше, чем память, распределенная под SGA, так что я должен увеличить размер файла журнала регистации, как показано в Таблице 3.
Таблица 3: Увеличение размера журнального кэша SGA и файла журнала регистации
| Размер блока базы данных | 2 КБ |
| Буферный кэш SGA | 128 МБ |
| Разделяемый пул SGA | 128 МБ |
| Журнальный буфер в SGA | 16 МБ |
| Файл журнала регистации событий | 16 МБ |
| Табличные пространства | Управление по словарю |
Результаты TPC-C
| Время загрузки (сек) | 41,39 |
| Транзакций/сек | 10,09 |
Таблица 4: Увеличение размера блока до 4 КБ
| Размер блока базы данных | 4 КБ |
| Буферный кэш SGA | 128 МБ |
| Разделяемый пул SGA | 128 МБ |
| Журнальный буфер в SGA | 16 МБ |
| Файл журнала регистации событий | 16 МБ |
| Табличные пространства | Управление по словарю |
| Время загрузки (сек) | 17,35 |
| Транзакций/сек | 10,18 |
Таблица 5: Использование локальных табличных пространств
| Размер блока базы данных | 4 КБ |
| Буферный кэш SGA | 128 МБ |
| Разделяемый пул SGA | 128 МБ |
| Журнальный буфер в SGA | 16 МБ |
| Файл журнала регистации событий | 16 МБ |
| Табличные пространства | Локальное управляение |
| Время загрузки (сек) | 15,07 |
| Транзакций/сек | 10,43 |
Таблица 6: Увеличение размера блока до 8 КБ
| Размер блока базы данных | 8 КБ |
| Буферный кэш SGA | 128 МБ |
| Разделяемый пул SGA | 128 МБ |
| Журнальный буфер в SGA | 16 МБ |
| Файл журнала регистации событий | 16 МБ |
| Табличные пространства | Локальное управляение |
Результаты TPC-C
| Время загрузки (сек) | 11,42 |
| Транзакций/сек | 10,68 |
Так что у меня быстро подходят к концу низко висящие яблоки базы данных. Единственная другая мысль, которая приходит на ум: у меня ведь имеется несколько центральных процессоров, так, может быть, я могу создать подчиненные процессы ввода/вывода, чтобы использовать их, как в Таблице 7.
Таблица 7: Использование подчиненных процессов ввода/вывода
| Размер блока базы данных | 8 КБ |
| Буферный кэш SGA | 128 МБ |
| Разделяемый пул SGA | 128 МБ |
| Журнальный буфер в SGA | 16 МБ |
| Файл журнала регистации событий | 16 МБ |
| Табличные пространства | Локальное управляение |
| dbwr_io_slaves | 4 |
| Lgwr_io_slaves (вторичных) | 4 |
| Время загрузки (сек) | Улуч-шение | Транзак-ций/сек | Улуч-шение | |
| Результаты теста 1 | 49,41 | N/A | 8,15 | N/A |
| Результаты теста 2 | 48,57 | 1,73 | 9,15 | 10,88 |
| Результаты теста 3 | 41,39 | 17,35 | 10,09 | 9,33 |
| Результаты теста 4 | 17,35 | 138,56 | 10,18 | 0,89 |
| Результаты теста 5 | 15,07 | 15,13 | 10,43 | 2,36 |
| Результаты теста 6 | 11,42 | 31,96 | 10,68 | 2,42 |
| Результаты теста 7 | 10,48 | 8,97 | 10,72 | 0,32 |
| Общий результат | 19,48 | 371,47 | 10,72 | 23,93 |
Настройка сервера базы данных Oracle и Linux
Берт Скалзо ,
(Tuning Oracle Database Server and Linux,
by Bert Scalzo)
Источник: Oracle Magazine, articles online only, http://otn.oracle.com/oramag/webcolumns/2002/techarticles/scalzo_linux01.html
Низко висящие яблоки Linux
Теперь давайте посмотрим на повышение производительности операционной системы Linux, которая является достаточно интеллектуальной, чтобы распознать и адаптироваться к аппаратным проблемам, типа фирмы-изготовителя, скорости и числа центральных процессоров, количества системной памяти, а также типа, скорости и количества дисковых устройств. Тем не менее, остаются пригодными для использования многие неочевидные возможности повышения производительности. В данном случае я начну с типичной инсталляции Red Hat Linux 6.2. (Примечание: я начну работу с ядра 2.2.14-5smp, которое поставляется с Linux 6.2.)
Первым заданием после установки Linux должно быть создание монолитного ядра (то есть повторная компиляция ядра для статического включения библиотек, которые вы намереваетесь использовать и отключения динамически загружаемых модулей). Идея заключается в том, что маленькое ядро, куда включены только те опции, в которых вы нуждаетесь, превосходит “жирное” ядро, поддерживающее функции, которыми вы все равно не пользуетесь. Так что я собираюсь использовать команду cd для изменения каталога на /usr/src/Linux и издам команду очистки xconfig (загрузившись для этого в интерфейс командной строки вместо системы X-Windows).
Теперь я должен установить буквально сотни параметров. Я могу рекомендовать для использования любую из дюжины хороших книг или Web-сайтов по этой теме. Тот сайт, которым я пользовался чаще других, называется Securing and Optimizing Linux: Red Hat Edition (Обеспечение безопасности и оптимизация Linux: редакция Red Hat) Герхарда Моурани (Gerhard Mourani). (Вы можете также загрузить более старую версию книги Моурани в формате PDF (PDF version
http://www.tldp.org/LDP/solrhe/Securing-Optimizing-Linux-RH-Edition-v1.3.pdf ). Можно также посетить список OTN Members Booklist on Amazon (http://www.amazon.com/otn\), где можно найти другие рекомендованные книги по Linux).
К числу немногих установок параметров, которые задержались в моей памяти, относятся тип центрального процессора, поддержка симметричной многопроцессорной обработки (SMP), поддержка APIC (Advanced Peripheral Interrupt Controller – усовершенствованного программируемого контроллера прерываний), поддержка DMA (прямого доступа к памяти), активация значения по умолчанию IDE DMA и поддержка квот. Мой совет – нужно пройти их все, а если у вас возникли какие-то сомнения – читать справочный файл xconfig,.
Поскольку я знаю, что я собираюсь перекомпилировать ядро, я мог бы также исправить установки параметров взаимодействия процессов (IPC), как это записано в руководстве по установке базы данных Oracle. Для ядра 2.2, установки параметров общей памяти расположены в каталоге /usr/src/Linux/include/asm/shmparam.h. Я предлагаю установить значение параметра SHMMAX не менее 0x13000000. Параметры настройки семафора расположены в каталоге /usr/src/Linux/include/Linux/sem.h. Я рекомендую установить SEMMNI, SEMMSL и SEMOPN, равными, по крайней мере, 100, 512 и 100, соответственно.
Теперь я перекомпилирую ядро, используя команду make dep clean bzImage, скопирую карту ссылок и образ ядра в мой каталог начальной загрузки, отредактирую /etc/lilo.conf, выполню lilo и перезагружусь. Если я все сделал правильно, машина загрузится, используя мое новое (более экономное и более скромное) ядро.
Применение монолитного ядра с должным образом выставленными установками параметров IPC улучшает загрузку почти на 10 процентов, а TPS – почти на 7 процентов, как показано в Таблице 8.
Таблица 8: Результаты TPC для монолитного ядра с должным образом выставленными установками параметров IPC
| Время загрузки (сек) | 9,54 |
| Транзакций/сек | 11,51 |
Если простая перекомпиляция определенной версии ядра может привести к таким улучшениям, то, наверное, стоит задуматься, а не может ли обеспечить новые усовершенствования более свежая версия ядра из того же самого семейства. На Linux Interactive я нашел исходный код последней стабильной версии ядра того же самого семейства (в моем случае, 2.2.16-3smp). Но в результате я получил совершенно несерьезные усовершенствования – 1,5 процента для загрузки и фактически ничего для TPS, как показано в Таблице 9.
Таблица 9: Результаты TPC-C для более новой (младшей) версии ядра
| Время загрузки (сек) | 9,40 |
| Транзакций/сек | 11,52 |
Таблица 10: Результаты TPC-C для новейшей главной версии ядра
| Время загрузки (сек) | 8,32 |
| Транзакций/сек | 12,82 |
Если вы хотите сделать это только для файлов данных Oracle, задайте команду - chattr +A file_name. Если вы хотите сделать это для всего каталога, команда должна иметь вид - chattr-R +A directory_name. Но лучший метод состоит в том, чтобы отредактировать файл /etc/fstab, и для каждого его входа добавить к списку параметров файловой системы ключевое слово noatime (четвертый столбец). Ниже приводится пример файла /etc/fstab с этим изменением: LABEL=/ / ext2 defaults,noatime 1 1 LABEL=/boot /boot ext2 defaults,noatime 1 2 none /dev/pts devpts gid=5,mode=620 0 0 none /proc proc defaults 0 0 none /dev/shm tmpfs defaults 0 0 /dev/hda2 swap swap defaults 0 0 /dev/cdrom /mnt/cdrom iso9660 noauto,owner,ro 0 0 /dev/fd0 /mnt/floppy auto noauto,owner 0 0
Это гарантирует, что полный набор файловых систем выиграет от этой методики и, что более важно, эти установки будут сохранены в период между перезагрузками. Результаты весьма впечатляют – улучшения времени загрузки почти на 50 процентов и 8 процентов для TPS, как показано в Таблице 11.
Таблица 11: Результаты TPC-C для атрибута файла noatime
| Время загрузки (сек) | 5,58 |
| Транзакций/сек | 13,884 |
vm.bdflush = 100 1200 128 512 15 5000 500 1884 2
где, согласно /usr/src/Linux/Documentation/sysctl/vm.txt:
Первый параметр полностью управляет максимальным количеством грязных буферов в буферном кэше. “Грязный” здесь означает, что содержимое буфера еще должно быть записано на диск, в противоположность “чистому” буферу, о котором вы можете уже забыть. Установка этого параметра на высокое значение означает, что Linux может задержать запись на диск на долгое время, но это также означает, что он должен будет сделать за один раз большой объем ввода/вывода, когда системе станет не хватать памяти. Низкое значение разбрасывает дисковый ввод/вывод более равномерно. Второй параметр – 1200 ndirty, который дает максимальное количество грязных буферов, которые bdflush может записать на диск за один раз. Высокое значение означает отсроченный, пульсирующий ввод/вывод, тогда как маленькое значение может вести к нехватке памяти, когда bdflush не “просыпается” достаточно часто. Третий параметр – 128 nrefill, который определяет количество буферов, которые bdflush добавит в список свободных буферов при вызыве refill_freelist (). Необходимо заранее распределить свободные буфера, потому что буфера часто имеют другой размер, чем страницы памяти, и какая-то “бухгалтерия” должна быть проделана заранее. Чем больше их число, тем больше памяти будет потрачено впустую, и тем реже нужно будет выполнять refill_freelist (). Четвертый параметр – это 512 refill_freelist (). Когда оказывается, что он становится больше, чем nref_dirt грязных буферов, “пробуждается” (или, если угодно, запускается – прим. пер.) процесс bdflush.
Усовершенствования производительности – 26 процентов для времени загрузки и 7 процентов для TPS – показаны в Таблице 12.
Таблица 12: Результаты TPC-C при установке bdflush
| Время загрузки (сек) | 4,43 |
| Транзакций/сек | 14,99 |
Вот полная итоговая таблица полученных мной результатов
| Время загрузки (сек) | Улуч-шение | Тран-закций/сек | Улуч-шение | |
| Тест 1 | 49,41 | N/A | 8,15 | N/A |
10,48 371,47 10,72 23,93 Результаты теста 8 9,54 9,85 11,51 6,9 Результаты теста 9 9,40 1,49 11,52 0,10 Результаты теста 10 8,32 12,98 12,82 10,09 Результаты теста 11 5,58 49,10 13,88 7,70 Результаты теста 12 4,43 25,96 14,99 7,37 Общий результат 4,43 70,97 14,99 17,09 Окончательный результат 4,43 1.015,35 14,99 45,61 Это значит: Linux + База данных Oracle8i = скорость
Подведем итоги
Linux и сервер базы данных Oracle хорошо согласованы по мощности и конфигурируемости. Чтобы получить от ваших аппаратных средств оптимальную возможную производительность, вы должны настроить их до хорошо сбалансированного состояния, что не является слишком трудным делом, если использовать правильные инструментальные средства и методологию. И эти усовершенствования могут заставить ваши приложения выполняться на несколько порядков величины быстрее. Так что никогда не используйте Linux или базу данных Oracle “прямо из коробки” (не используйте при установке значения по умолчанию) – вы можете заставить ваши системы мурлыкать от удовольствия, затратив на это всего несколько минут усилия.
Берт Скалзо (Bert.Scalzo@Quest.com) – архитектор программных продуктов компании Quest Software (http://www.quest.com/ ) (Ирвин, шт. Калифорния), которая предлагает решения для управления приложениями, чтобы максимизировать доступность критичных бизнес-приложений и немедленную окупаемость инвестиций (ROI). Берт имеет степени бакалавра наук, магистра наук и доктора философии в области информатики. Он работал АБД Oracle, начиная с Oracle 4, а в настоящее время он работает с базой данных Oracle9i.
Установка эталонного теста
Ниже я приведу методы настройки управляемой среды, для которой я смог построить базовую конфигурацию, идентифицировать все поддающиеся изменению релевантные переменные, а также менять каждый раз по одной переменной и получать надежное измерение эффекта этого одиночного изменения.
В качестве тестовой среды я использовал четырехпроцессорный сервер Compaq с 512 МБ памяти и восемью ультра-широкими SCSI-дисками со скоростью 7 200 оборотов в минуту. Затем я провел точно те же самые испытания с однопроцессорной системой Athlon с тем же самым объемом памяти, но всего лишь с одним ультра 100 IDE-диском со скоростью 7 200 оборотов в минуту. Хотя полученные в результате опытов (сырые – raw) цифры и проценты не были идентичными, наблюдавшаяся мной модель усовершенствования была следующей: каждое испытание делало каждую систему лучше в том же самом общем направлении и на подобные величины.
Серверы Linux чрезвычайно гибки и просты в использовании в качестве Web-серверов, серверов приложений, баз данных, электронной почты, для работы с файлами и печати, а также как маршрутизаторы, экраны межсетевой защиты и комбинаций перечисленных выше функций. Для того, чтобы удовлетворить мое требование об изменении одной переменной за раз, я ограничусь только одним использованием. В следующей статье, я рассмотрю и другие использования.
Для простоты при моих испытаниях я использовал эталонный тест TPC-C. Он широко признан как надежный эталонный тест рабочей нагрузки при онлайновой обработке транзакций (online transaction processing – OLTP). Этот тест справляется и с онлайновыми, и с отсроченными транзакциями, он неоднороден по природе, и его можно применять для множества баз данных – в том числе для всех выпусков баз данных Oracle. Вдобавок, вы можете конфигурировать TPC-C так, чтобы подчеркнуть все аспекты аппаратных средств: центральный процессор, память, шина и диск. И, чтобы быть до конца искренним, я – администратор базы данных в Quest Software, а наша компания производит полезную утилиту Benchmark Factory, которая определяет, выполняет и измеряет результаты испытаний TPC столь же простым образом, как если бы это была посылка электронной почты. На Рисунке 1 показан интерфейс Benchmark Factory: вы создаете проект эталонного теста TPC-C, определяете параметры, например, размер базы данных и число параллельно работающих пользователей, копируете тесты, которые хотите измерить для выполнения очереди, выполняете испытания в очереди и наблюдаете результаты.
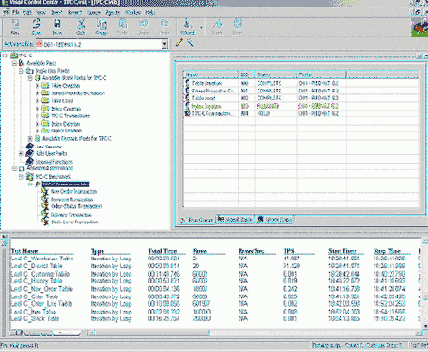
Рисунок 1: Интерфейс Benchmark Factory
Я говорил, что буду рассматривать некоторые подходы с высоким коэффициентом окупаемости инвестиций. Это означает, что я буду искать элементы, настолько простые и очевидные в терминах применимости и воздействия, что мне достаточно будет всего лишь увидеть различия во времени выполнения TPC-C, чтобы понять, что я нахожусь на верном пути. Так что я буду рассматривать только то, что я называю низко висящими яблоками (low-hanging fruit) операционной системы и базы данных. В последующих статьях мы углубимся в изменения, для которых будут требоваться такие инструментальные средства Linux, как, например, команды free, iostat, ipcs, mpstat, sar, top и vmstat.
Для многих АБД следующий раздел будет просто освежением некоторых очевидных (или, возможно, "не слишком очевидных") вопросов, связанных с конфигурацией и настройкой базы данных.
Быстрый доступ с двухуровневыми запросами
До недавнего времени производительность базы данных в основном определялась размером базы и эффективностью индексов. Но с Oracle Locator в Oracle Database
10g производительность становится функцией от количества фактически выбранных данных. Производительность оптимизируется через использование пространственного индекса и модели двухуровневого запроса. Эта модель значительно снижает непроизводительные издержки при загрузке данных и обработке запросов. Она обеспечивает превосходную масштабируемость по мере роста объема пространственных данных. Первый уровень, или первичный фильтр, позволяет провести быструю селекцию небольшого количества записей-кандидатов и перейти ко второму фильтру.
Первичный фильтр использует аппроксимации, хранимые в пространственном индексе, чтобы сократить сложность вычислений. Вторичный фильтр применяет точную вычислительную геометрию к результирующему набору первичного фильтра. Эти точные вычисления и приводят к заключительному ответу на запрос. Операции вторичного фильтра требуют более интенсивных вычислений, но они применяются к относительно небольшому результирующему набору первичного фильтра. Данные могут быть возвращены приложениям на основе этих аппроксимаций.
Запросы могут быть пространственно ограничены, как определено “областью интересов” ("area of interest"), выбранной пользователем. Исключение данных, не соответствующих этой области интересов, во время обработки запросов обеспечивает оптимальные уровни производительности.
Запросы к позиционным данным, использующие стандартный SQL, могут быть сделаны различными способами.
Например, экстракты в виде двухразмерного окна (two-dimensional window extracts) возможны для задания поиска по диапазону значений (range searches), по критерию близости (proximity searches) и поиска полигонов (polygon searches).
Геометрическая модель Земли как единого целого для поддержки геодезических координат
Oracle Locator предоставляет геометрическую модель Земли как единого целого, в которой учитываются искривления поверхности Земли при выполнении вычислений с геодезическими данными. Функция Oracle Locator по определению расстояния возвращает точные значения как для проектируемых, так и для геодезических данных (то есть, угловые координаты, определенные относительно некоторой модели формы Земли). Oracle поддерживает более 30 из наиболее часто используемых единиц измерений для расстояний и областей, которые полезны как для геодезических, так и для проектируемых данных, то есть, фут – квадратный фут (foot/square foot), метр – квадратный метр (meter/square meter), километр – квадратный километр (kilometer/square kilometer) и так далее.
Геометрия, слои
Oracle Locator поддерживает три основных геометрических объекта, которые представляют географические и позиционные данные:
Точки (Points): Точки могут представлять позиции таких физических объектов, как строения, пожарные машины, нефтяные платформы, товарные вагоны или передвигающиеся транспортные средства. Линии (Lines): Линии могут представлять позиции таких объектов, как дороги, железнодорожные линии, коммуникации коммунального хозяйства или линии разломов земной поверхности. Полигоны (многоугольники) и комплексные полигоны с анклавами (Polygons and complex polygons with holes): Полигоны могут представлять такие объекты, как города, районы, затопленные долины или нефтяные и газовые поля. Полигон с анклавом может представлять участок земли, окружающий болото.
Внутренне позиционные данные смоделированы по слоям (layers) с использованием геометрических столбцов (geometry column) в унифицированных таблицах с применением общей координатной системы. Например, представление города может включать отдельные слои для показа районов или кварталов домов, выделенных по социо-экономическим признакам, для показа расположения каждого жилого или функционального строения, совокупностей водных, газовых и канализационных сетей и электрических линий.
Поскольку все эти слои используют одну и ту же базу данных и представление о геометрии Земли (координаты (coordinate), геоид (geoid) и проекции (projection)), они могут быть соотнесены (между собой) через соответствующие (общие) местоположения.
Помимо перечисленных выше геометрических элементов Oracle Locator поддерживает следующие геометрические типы:
Отрезки дуги (Arc strings) Составные многоугольники (Compound polygons) Круги (Circles) Прямоугольники (Rectangles)
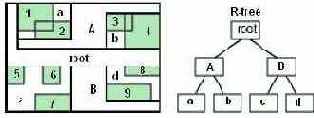
Индексирование пространственных данных: R-деревья
Oracle Locator применяет пространственные индексы (spatial indexes) – или индексы на базе R-деревьев (R-tree indexes) – к позиционным данным в базе данных Oracle. Индексы на базе R-деревьев просто создать и они почти не требуют настройки для достижения оптимальной производительности. Эти индексы могут быть созданы на двух, трех или четырех измерениях пространственных данных.
Типичные запросы специфицируют “окно интересов” (window of interest) и выбирают все данные, соответствующие или содержащиеся этом окне.
Индекс на базе R-дерева аппроксимирует каждый геометрический объект одним наименьшим прямоугольником, который включает в себя этот геометрический объект; этот прямоугольник называется MBR (minimum bounding rectangle – минимально ограничивающий прямоугольник).
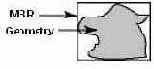
Для слоя геометрических объектов индекс на базе R-дерева состоит из иерархического индекса по MBR всех геометрических объектов в этом слое. Индексы на базе R-деревьев быстрые, так как работают непосредственно с геодезическими данными. Поэтому они являются предпочитаемым механизмом индексирования для работы с пространственными данными.
Геодезические данные – это данные, состоящие из угловых (angular) координат (ширина и высота (longitude and latitude)), которые определяются относительно некоторого представления фигуры Земли, или базиса (datum).
Пространственный индекс использует расширяемый механизм индексирования в Oracle Database 10g, который обеспечивает операции поддержки этого индекса при вставке (insert), изменении (update) и удалении (delete). Это значительно облегчает его использование.
Обеспечение индексирования на базе функций
Индекс на базе функций поддерживает пространственные запросы и анализ любых реляционных данных, связанных с позиционным атрибутом, без создания и предварительной загрузки столбца типа SDO_GEOMETRY.
Пользователи могут создавать пространственные индексы по позиционным данным, хранимых в реляционных столбцах (например, в столбцах высоты и широты). Пространственные операторы могут пользоваться как индексами на базе функций, так и традиционными пространственными индексами (spatial index). Пространственный ндекс сделает возможным вызов пространственных операторов на этих реляционных столбцах без необходимости создавать столбец SDO_GEOMETRY.
Это полезно для геобизнес-приложений, у которых есть схема для хранения позиционных данных, но которые не могут ее изменять, чтобы перенести эти позиционные данные в столбец типа SDO_GEOMETRY.
Операторы для работы с пространственными данными
Взаимоотношения различных геометрических особенностей может быть определено через применение операторов сравнения, таких как SDO_RELATE, SDO_CONTAINS, SDO_COVERS, SDO_ANYINTERACT (any interaction) и других. А это позволяет отвечать на такие запросы, как "перечислите все прилегающие к школам зоны, пересекаемые этой линией железной дороги" или "найдите все пункты продажи пиццы внутри данной области." В состав Oracle Database 10g Release 1 были включены новые операторы отношений в качестве удобных альтернатив использованию оператора SDO_RELATE со значением маски.
Oracle Locator также предоставляет функцию, которая вычисляет расстояние между двумя геометрическими объектами. Она полезна в запросах позиционных сервисов, таких как "определите ближайшие к аэропорту 10 отелей и расстояние к каждому из них в милях." Более продвинутые функции, такие как вычисляемая область (computing area) или возвращение новых геометрических объектов, таких как буферы (buffers), центроиды (centroids), объединения (unions), пересечения (intersections) или некоторые пространственные агрегаты, требуют использования механизма Oracle Spatial.
Открытые стандарты
Корпорация Oracle последовательно работает над тем, чтобы помочь сформировать, продвинуть, внедрить и поддерживать открытые стандарты в областях пространственных данных и сервисах на основе позиционных данных.
Корпорация Oracle – ведущий участник (Principal Member) открытого консорциума по геопространственным данным ODG (Open Geospatial Consortium) и активно участвует в соответствующем Техническом комитете (Technical Committee). Oracle Database 10g Release 1 (10.1.0.4) и Oracle Locator соответствуют спецификации OpenGIS Simple Features Specification for SQL, Revision 1.1, Types and Functions Alternative. Корпорация Oracle также привержена к поддержке нового языка GML (Geographic Markup Language) консорциума ODG, а также интерфейсов Open Location Service. Объектно-реляционная модель, используемая Oracle Locator для хранения геометрических объектов, также соответствует спецификациям, связанным с представлением в SQL92 точек, линий и полигонов.
Параллельные пространственные запросы (введены в 10g Release 1)
Пространственные запросы могут теперь выполняться параллельно на секционированных пространственных индексах, повышая производительность таких запросов, как “внутри заданного расстояния”, “ближайший сосед” и “относительно”. Производительность масштабируется с числом CPU, используемых для выполнения запроса. Это существенно для позиционных сервисов и приложений управления земельными участками нуждаются в быстром выполнении большого количества пространственных запросов.
Поддержка функциональности баз данных в Standard/Enterprise Edition
Oracle Locator поставляется в редакциях Oracle Standard Edition, Standard Edition One и Enterprise Edition. Часть его функциональности требует наличия ряда серверных функций, которые недоступны или ограничены в редакциях Standard Edition и Standard Edition One. Некоторые из этих функций и их доступность перечислены ниже:
Функциональность
Поддержка Standard/Enterprise Edition
| Построение параллельных пространственных индексов | Поддерживается только в Enterprise Edition | |
| Параллельные пространственные индексы | Поддерживается только в Enterprise Edition | |
| Секционированные пространственные индексы | Требует Partitioning Option в Oracle Enterprise Edition
Не поддерживается в Standard Edition | |
| Расширенная репликация с многими мастер-узлами (multimaster replication) для объектов SDO_GEOMETRY | Поддерживается только в Enterprise Edition
(За более подробной информацией обращайтесь к документации по Oracle Advanced Replication.) |
За более подробной информацией о доступности функций в редакциях Oracle, следует обратиться к материалу Oracle Database Licensing Information (документация по Oracle Database).
Поддержка секционирования для пространственных индексов
Архитектура баз данных Oracle включает секционирование, в рамках которого единая логическая таблица и ее индексы разбиваются на две или более физических таблиц, каждая, возможно, со своим собственным индексом. Пространственные индексы, связанные с секционированной таблицей, также могут быть секционированы; секционирование по диапазону (range partitioning) – это схема секционирования, поддерживаемая для пространственных индексов.
Секционирование обеспечивает значительные улучшения производительности, масштабируемости и управляемости, включая следующее:
Сокращенное время ответа для длительно исполняемых запросов; секционирование может сократить количество дисковых операций ввода-вывода. Сокращенное время ответа для конкурентных запросов; операции ввода-вывода могут исполняться одновременно по каждой секции. Более легкое сопровождение индексов из-за наличия операций создания и перестроения на уровне секций. Возможность перестраивать индексы на одних секциях, не влияя на запросы к другим секциям. Возможность изменять параметры хранения для каждого локального индекса независимо от других секций.
Секции также могут разделяться, объединяться и обмениваться.
Поддержка ведущих поставщиков GIS и сервисов на основе позиционных данных
Oracle Locator напрямую интегрируется с продуктами ведущих разработчиков GIS и сервисов на основе позиционных данных. Широкий спектр поддержки партнеров предоставляет разработчикам возможность выбора наилучшего инструмента, соответствующего их требованиям. С Oracle Database 10g и инструментами партнеров разработчики могут быстро развертывать масштабируемые, безопасные GIS масштаба предприятия и решения на основе позиционных данных.
Список партнеров доступен на www.oracle.com/technology/products/spatial .
Проекции и координатные системы – Поддержка на основе модели EPSG (новое в Oracle 10G RELEASE 2)
Oracle Locator поддерживает более 1000 широко используемых координатных систем, применяемых при составлении карт; он также поддерживает определенные пользователями системы координат. Он обеспечивает четкие преобразования проекций карт векторных объектов из одной системы координат в другую. Эти преобразования могут происходить с геометрическим объектом (geometry-level basis) или целой таблицей (entire layer (table)) за один раз.
В дополнении к модели систем координат, предоставляемой с предыдущими версиями, Oracle Locator в Oracle Database 10g Release 2 обеспечивает поддержку систем координат на основе модели данных и набора данных группы European Petroleum Survey Group (EPSG). Поддержка модели EPSG обеспечивает преимущества стандартизации, расширенной поддержки и гибкости для нефтяных и газовых компаний, поставщиков георастровых данных и пользователей GIS в целом.
Рабочие пространства баз данных
Oracle Workspace Manager, менеджер рабочих пространств баз данных Oracle, - это механизм Oracle, который предоставляет виртуальную среду (workspaces – рабочие пространства), позволяющую управлять в одной и той же базе данных текущими, предполагаемыми и историческими значениями данных.
Рабочие пространства могут совместно использоваться для:
изоляции ряда изменений производственных данных, пока они не одобрены и не загружены в базу производственных данных; ведения долгосрочной истории изменений к данным; и создании множества сценариев на основе данных, которые базируются на общем наборе данных для анализа типа “Что если”.
Расширенные возможности Oracle Locator в Oracle Database 10g
Oracle Database 10g обеспечивает мощную и надежную поддержку для критически важных приложений организации. Эти функции, необходимые для приложений масштаба предприятия, расширяют возможности Oracle по работе с позиционными данными благодаря гибкой Internet-архитектуре развертывания, возможностям работы с объектами и мощным утилитам управления данными, которые обеспечивают целостность данных (data integrity), восстановление данных (data recovery) и безопасность данных (data security). Этот уровень поддержки возможен только в однородной среде Oracle, развернутой на всем предприятии, и не может быть эффективно воспроизведен в гибридном решении, в котором сочетаются внешнее решение на базе позиционных данных с традиционным решением масштаба предприятия, при этом даже не имеет значения то, как тесно эти два компонента интегрированы.
Oracle Locator в полной мере использует увеличенные лимиты на размеры баз данных, высоко производительные утилиты сопровождения сверхбольших баз данных (VLDB), репликацию, менеджер рабочего пространства (управление версиями) (workspace manager (versioning)), более быстрое резервирование и восстановление и секционирование. Только пользователи свойственных для Oracle пространственных типов данных могут в полной мере воспользоваться такими функциями, как секционирование, репликация, построение и запросы параллельных индексов, многоуровневая безопасность, определяемая требованиями пространственных данных или приложений (spatially-driven multi-level security). Эти функции не доступны или функционально ограничены при использовании типов данных LONG RAW или BLOB. Весь диапазон утилит Oracle (в том числе SQL*Loader) также может быть использован, чтобы облегчить миграцию и помочь модернизировать приложения, которые используют функции позиционных сервисов. Некоторые из этих ключевых для приложений масштаба предприятия функций описаны ниже.
Репликация
Возможности расширенной репликации Oracle (Advanced Replication) могут быть использованы с позиционными данными.
Например, распределенные системы, в которые входят географически разнесенные, но логически реплицируемые web-сайты, могут использовать синхронную репликацию объектов пространственных данных по многим базам данных.
Замечание: Конфигурация Advanced Replication со многими мастер-узлами (multimaster replication) предлагается только с базами данных редакции Enterprise Edition. За более подробной информацией о функциях Advanced Replication следует обратиться к руководству Oracle Database Advanced Replication.
Создание параллельного пространственного индекса
Пространственные индексы и секции индексов могут создаваться параллельно. Создание индекса на базе R-дерева может быть разбито на меньшие задачи, которые могут выполняться параллельно с использованием неиспользуемых ресурсов оборудования (CPU).
Для некоторых наборов пространственных данных и типов/параметров индексов параллельное создание индекса может существенно повысить производительность построения индексов и привести к значительной экономии времени. Большие не_точечные (non-point) наборы данных (обычно используемые во многих стандартных GIS-приложениях) могут продемонстрировать значительные улучшения производительности.
Улучшение производительности
Приложения широкого диапазона, от сервисов, применяющих позиционные данные, до управления GIS-активами и земельными участками, часто должны изменять и запрашивать позиционные данные, что требует высокой производительности. Во исполнение этого требования каждая новая версия Oracle Locator обеспечивает резкий рост производительности.
Oracle Locator в первой версии Oracle Database 10g показал значительные улучшения производительности в сравнении с версией 9.2:
вставки с индексом R-дерево выполнялись в 5-10 быстрее время изменения с индексом R-дерево сократилось на 40% или больше, что особенно полезно для GIS масштаба предприятия и сервисов на базе позиционных данных пространственные запросы на определение расстояния и запросы на определение отношений выполняются на 20-40% быстрее пространственные запросы соединением (Spatial joins) выполняются в 2-6 раза быстрее
Во второй версии Oracle Database 10g производительность запросов с индексами на базе R-деревьев улучшилась. Другие возможности Oracle Locator могут использоваться для дальнейшего производительности.
Для параллельных запросов с секционированными пространственными индексами (partitioned spatial indexes) производительность масштабируется по числу CPU, используемых для выполнения этого запроса. Построение пространственных индексов на базе R-деревьев параллельным образом может очень резко сократить время создания индекса для очень больших не_точечных (non-point) пространственных наборов данных. Функции агрегирования пространственных данных ускоряют выборку больших наборов объектов из SDO_GEOMETRY. (Замечание. Oracle Locator включает функцию SDO_AGGR_MBR; все остальные пространственные функции агрегирования включены только в опцию Oracle Spatial.)
Каждая база данных Oracle включает
Каждая база данных Oracle включает развитые средства хранения, формирования запросов и анализа позиционных (location) данных. Эти средства, своойственные для базы данных Oracle, позволяют пользователям формировать запросы об относительном местоположении, например, в таких случаях, как расстояние до первого ответившего по сигналу тревоги, как продажи в разрезе территорий или распределение обслуживающего персонала по пунктам поддержки.
Интегрирование позиционных данных в бизнес-приложения позволяет организациям принимать лучшие решения, более эффективно обслуживать клиентов и сокращать расходы.
Oracle Locator – это механизм всех редакций СУБД Oracle (Standard Edition, Standard Edition One и Enterprise Edition), который реализует прищущие этой СУБД функции управления данными, формирования запросов и анализа применительно к позиционным данным; все эти функции доступны через стандартный SQL. Данная функциональность является основой для развертывания бизнес-приложений, использующих позиционные данные, разработанных партнерами географических информационных систем (Geographic Information Systems (GIS)) и сервисов, базирующихся на позиционных данных. Разработчики могут расширить существующие инструменты и приложения на базе СУБД Oracle, так как с Oracle Locator они легко могут использовать позиционные данные в свои приложения и сервисы. Это возможно, так как позиционные данные полностью интегрированы с сервером Oracle. Географическими и позиционными данными можно манипулировать, используя ту же самую семантику, которая применяется к данным типов CHAR, DATE или INTEGER, и эта семантика знакома всем пользователям SQL. Тем самым Oracle Locator отменяет все расходы на индивидуальные, собственные (proprietary) системы; он поддерживается всеми ведущими разработчиками GIS. Oracle Locator также предоставляет наивысшие в отрасли уровни безопасности, производительности, масштабируемости и управляемости, обеспечиваеиые Oracle Database 10g для критически важных активов в базе позиционных данных.
В данном материале представлены функции Oracle Locator, включая новые функции, появившиеся в первом и втором релизах Oracle Database 10g.
Примечание: Oracle Spatial 10g – это дополнительный механизм (option) Enterprise Edition, который расширяют Oracle Locator продвинутыми средствами работы с пространственными данными в GIS-приложениях и информационных системах масштаба предприятия, использующих пространственные данные. Эти средства включают управление георастровыми данными (GeoRaster data management), сетевые и топологические модели данных, механизмы (engines) геокодирования (geocoding) и маршрутизации (routing), функции анализа пространственных данных и другие. Более подробная информация находится в материалах Oracle Spatial 10g Technical White Paper и Oracle Spatial Option and Oracle Locator Data Sheet.
Наиболее полное и подробное описание функций Oracle Locator и Oracle Spatial можно найти в документации Oracle Spatial User's Guide (Appendix B) и Reference 10g Release 2 (10.2).
Oracle Locator обеспечивает основную функциональность
Oracle Locator обеспечивает основную функциональность для работы с позиционными данными в базе данных Oracle, не требуя при этом дорогих средств других разработчиков. Он поддерживает среды масштаба рабочей группы и предприятия, а также идеально подходит для многих приложений в виде позиционных сервисов, то есть сервисов на основе позиционных данных (location-based services). Этот инструмент позволяет организациям использовать стандартные GIS-средства партнеров для доступа к данным типа SDO_GEOMETRY. Он также позволяет любому бизнесу-приложению включать возможности позиционирования, чтобы раскрыть ценность информации, которой они уже обладают. Oracle Locator поддерживает хранение пространственного объектного типа (spatial object type storage), доступ через SQL, индексирование пространственных данных на базе R-дерева, операции с пространственными данными, хранение и управление геодезическими данными (geodetic data storage and management), модель координатной системы согласно EPSG (coordinate systems model) и так далее.
Oracle принадлежит 80-90% доля рынка управления базами геопространственных данных (IDC, Oracle 10g: Spatial Capabilities for Enterprise Solutions, Sonnen
and Morris, Feb. 2005). Клиенты и партнеры полагаются на то, что Oracle обеспечит производительность, масштабируемость, безопасность и легкость использования для их пространственных приложений. Oracle Locator в Oracle Database 10g развивается в сторону новых уровней производительности и включает богатый набор характеристик, который позволяет любому разработчику использовать Oracle для развертывания GIS, бизнес-приложений на основе позиционных данных, и беспроводных услуг на базе позиционных данных.
Oracle Locator: Location-Enabling Every Oracle Database
August 2005
Authors: Jean Ihm, Xavier Lopez
Contributing Authors: Jim Steiner, Jayant Sharma, Siva Ravada, Dan Abugov
Oracle Corporation
World Headquarters
500 Oracle Parkway
Redwood Shores, CA 94065
U.S.A.
Worldwide Inquiries:
Phone: +1.650.506.7000
Fax: +1.650.506.7200
oracle.com
Copyright © 2005, Oracle. All rights reserved.
This document is provided for information purposes only and the contents hereof are subject to change without notice.
This document is not warranted to be error-free, nor subject to any other warranties or conditions, whether expressed orally or implied in law, including implied warranties and conditions of merchantability or fitness for a particular purpose. We specifically disclaim any liability with respect to this document and no contractual obligations are formed either directly or indirectly by this document. This document may not be reproduced or transmitted in any form or by any means, electronic or mechanical, for any purpose, without our prior written permission.
Oracle, JD Edwards, and PeopleSoft are registered trademarks of Oracle Corporation and/or its affiliates. OGC, OpenGIS®, and CERTIFIED OGC COMPLIANT are trademarks or registered trademarks of Open Geospatial Consortium, Inc. in the United States and in other countries. Other names may be trademarks of their respective owners.
Использование инструмента формирования метаданных Map Definition Tool
Map Definition Tool является автономным приложением, написанным на Java. Оно позволяет создавать, модифицировать и удалять стили, темы и базовые карты. Например, можно разработать и задать новый стиль линии, увидеть предварительное отображение этого стиля, модифицировать его при необходимости, а затем вставить XML-описание нового стиля в базу данных. Инструмент использует введенную разработчиком информацию, относящуюся к стилю, чтобы сгенерировать соответствующее описание в XML-формате.
Когда возможно, желательно использовать Map Definition Tool вместо прямой модификации метаданных MapViewer. Утилита всегда проверяет и поддерживает ссылочную целостность между объектами.
Map Definition Tool содержит ряд закладок, сгруппированных в следующие категории
Connection: страница для подключения базе данных; Styles: все, что связано с настройкой и созданием стилей; Themes: страница для работы с темами; Maps: страница для работы с картами.
В первую очередь нужно воспользоваться вкладкой Connection, чтобы подключиться к базе данных Oracle. Кнопкой Connect to вызывается диалоговое окно для задания параметров нового подключения. В общем случае, в этом окне необходимо указать имя сервера или его IP-адрес, на котором запущен Oracle, задать имя экземпляра базы данных, порт и данные пользователя (имя и пароль).
Как только подключение будет выполнено, станут доступны и все остальные разделы утилиты.
Обычно, прежде всего, формируется библиотечка элементарных стилей, которые будут участвовать в отображении карты. Для рассматриваемого приложения создаются три типа стилей.
Через вкладку Color раздела Styles созданы стили COLOR_BUILDS для отображения темы зданий и COLOR_PARCELL для отображения темы земельных участков. На данной вкладке в поле Name указывается уникальное имя стиля. В группах Stroke Color и Fill Color задаются соответственно цвет окантовки объектов и цвет их заливки. Цвета можно задавать при включенной галочке Apply либо при помощи кнопки Sample Color, дающей доступ к наглядной палитре цветов. Можно также воспользоваться прямым указанием RGB-кода цвета в окошке ниже упомянутой кнопки. Регулятор Opacity позволяет регулировать степень прозрачности заливки или окантовки. В поле Description можно задать пояснительную информацию к данному стилю. Для занесения вновь сформированного стиля в библиотечку нужно нажать кнопку Insert внизу вкладки и название стиля появиться в списке доступных площадных стилей. В дальнейшем, если возникнет необходимость отредактировать данный стиль, нужно выбрать его в списке, изменить нужные свойства на вкладке и нажать кнопку Update. Чтобы очистить вкладку перед формированием нового стиля, нужно нажать кнопку New.
Через вкладку Line раздела Styles сформирован стиль LINE_STREET отображения темы улиц. В данной задаче оси улиц служат лишь в качестве опорных объектов для вывода названий улиц и желательно отображение самих линий сделать невидимым. Для этого можно оставит галочку Apply только в разделе Overall Style и указать в качестве цвета белый. Значение Opacity выставить на минимально возможную величину.
Для отображения надписей через вкладку Text раздела Styles созданы три текстовых стиля: TEXT_BUILDS для отображения номеров домов, TEXT_STREET для отображения названий улиц и TEXT_PARCELL для отображения номеров земельных участков. Все три стиля создаются одинаково. При необходимости можно указать, будет ли текст наклонным (флажок Italic) или жирным (флажок Bold), в поле Size размер шрифта, а в списке Family выбрать один из возможных стилей начертания шрифта. Кнопкой Sample Color напротив надписи Foreground Color можно задать цвет текста.
После того, как все стили были сформированы, через вкладку Themes были созданы три темы: тема THEME_BUILDS для отображения зданий, тема THEME_STREET для отображения улиц и тема THEME_PARCELL для отображения земельных участков. На вкладке в верхнем левом углу находится список уже сформированных тем, содержащихся в репозитории метаданных, справа находятся поля основных параметров темы, а внизу вкладки находится табличка, которая в общем случае позволяет настраивать одно или более правил отображения темы. В списке Base Table выбирается пространственная таблица, объекты из которой будет отображать тема (в нашем случае это в порядке перечисления тем таблицы BUILDS, STREET и PARCELL, находящиеся в схеме MAP). В списке Geometry Column указывается колонка из указанной выше таблицы, которая имеет пространственный тип SDO_GEOMETRY. Для всех трех таблиц это будет поле GEOLOC. В нижней настроечной таблице в верхней строке для каждой создаваемой тематики в колонке Feature Style указывается стиль отображения пространственных объектов на карте (соответственно в порядке создания тем были указаны ранее подготовленные стили COLOR_BUILDS, LINE_STREET и COLOR_PARCELL). В колонке Label Col выбирается столбец пространственной таблицы, из которой будут браться данные для надписей (соответственно в порядке создания тем были указаны поля: колонка NUM из таблицы BUILDS, содержащая номера домов, колонка NAME из таблицы STREET, содержащая названия улиц и колонка KU таблицы PARCELL, содержащая номера земельных участков). В следующей колонке Label Style указывается стиль текста надписей (соответственно в порядке создания тем были указаны стили TEXT_BUILDS, TEXT_STREET и TEXT_PARCELL). В поле Label Func для всех трех тем были указаны 1.
После завершения создания тем через вкладку Maps была сформирована базовая карта. В поле Name было указано имя базовой карты MAP_DEMO. В нижней таблице был сформирован список из ранее созданных тем, которые будут отображаться на карте. Темы были указаны в том порядке, в котором они должны отрисовываться (первой указана тема THEME_PARCELL, затем THEME_STREET в самом конце тема THEME_BUILDS). Колонки Min Scale и Max Scale были оставлены пустыми.
Имя сформированной карты используется при формировании запросов к MapViewer.
Концепция MapViewer применительно к разрабатываемому приложению
Для описания того, как и что будет выводить MapViewer в ответ на запрос клиента, используются метаданные в служебной схеме MDSYS, хранящие в виде XML-описаний информацию о правилах отображения пространственных объектов, перечне слоев, участвующих в формировании карты, и параметрах отображения самой карты. Основными типами метаданных являются стили, темы и базовые карты. Следует отметить, что при пересоздании схемы пользователя, метаданные не сохраняются, поскольку не находятся непосредственно в его схеме. При перезагрузке данных в схеме необходимо создавать метаданные заново или позаботиться о заполнении соответствующих таблиц в схеме MDSYS, например, с использованием соответствующих сохраненных SQL-команд.
Стили (styles) определяют свойства отображения для объектов, с которыми ассоциированы данные стили. Например, стиль текста определяет, как объекты будут подписываться на карте, а стиль линий определяет, как будут отображаться на карте линейные объекты, такие, как улицы. Каждый стиль имеет уникальное имя, и определяется одним или несколькими графическими элементами в синтаксисе XML
Основные типы стилей
Цвет (Color): служит для заливки площадных объектов и прорисовки их границ. Маркер (Marker): используются в качестве иконок для отображения точечных объектов, требующих отображения в виде условного знака. Линия (Line): данный стиль используется для оформления линейных объектов. Площадь (Area): используемый для представления площадных объектов с возможностью заливки их контура заданным графическим шаблоном (картинкой узора). Текст (Text): данный стиль используется для нанесения пояснений и надписей для объектов. Продвинутый (Advanced): комплексный стиль, используемый для тематического ранжирования.
Все стили, которые заданы пользователем, можно обнаружить в пользовательском представлении USER_SDO_STYLES.
Тема (theme) - это коллекция объектов (заданных как пространственными, так и непространственными атрибутами), с которыми ассоциированы стили отображения или набор правил, задающих стили отображения. Каждая тема (если эта тема - не изображение) связана с хранящимся пространственным слоем, представленным таблицей или представлением, имеющим в своем составе столбец типа MDSYS.SDO_GEOMETRY. Все предопределенные пользовательские темы можно увидеть в пользовательском представлении USER_SDO_THEMES.
Базовая карта (base map), на основе которой формируется вывод графических данных, обычно состоит из одной или нескольких тем. С картой связана определенная система координат, в которой отображаются все темы, образующие карту. Все темы в карте должны содержать пространственные объекты, которые заданы в данной системе координат. Порядок следования тем при добавлении определяет порядок их отрисовки на карте. Т.е. последняя добавленная тема отображается самой последней поверх всех остальных и так далее. Каждая тема в базовой карте может быть ассоциирована с масштабными границами, определяющими ее видимость.
Все имена базовых карт и все пользовательские настройки базы данных можно увидеть в пользовательском представлении USER_SDO_MAPS. Колонка DIFINITION в представлении USER_SDO_MAPS хранит XML-описание базовой карты.
Карта является компонентом, который MapViewer создает в ответ на картографический запрос на основе базовой карты и ряда других параметров. Карта может быть файлом изображения, объектом, который предоставляет доступ к файлу изображения карты или URL-ссылкой на файл изображения карты.
Под размером карты (Size) подразумевается высота карты в заданных единицах измерения карты. Масштаб карты вычисляется, как количество единиц измерения карты, представленных в одном дюйме на экране или устройстве вывода. Его можно использовать в качестве знаменателя в наиболее распространенном методе представления картографического масштаба 1/n.
Набор связанных объектов, участвующих в определении карты, можно назвать картографическим профилем приложения. Разработчик может управлять стилями, темами и базовыми картами также при помощи поставляемой дополнительно утилиты Map Definition Tool.
Организация PL/SQL-процедуры для обработки запросов Web-браузера
PL/SQL-процедура использует приведенный выше XML-запрос к MapViewer, чтобы получить ссылку на изображение карты, подставив в него входные параметры размера карты и координаты центральной точки. Данная ссылка используется, чтобы сформировать HTML-документ и в дальнейшем будет использована браузером, чтобы запросить у Web-сервера файл изображения карты.
Ниже приводится фрагмент текста простой процедуры, содержащий ключевые моменты реализации -------------------------------------------------------------------------------------------- PROCEDURE map_view( map_size IN VARCHAR2 DEFAULT NULL, map_x IN VARCHAR2 DEFAULT NULL, map_y IN VARCHAR2 DEFAULT NULL, ) IS
size_par NUMBER; -- размер карты x_par NUMBER; -- координата X центра карты y_par NUMBER; -- координата Y центра карты delta_ NUMBER; -- величина инкремента/декремента смещения центра карты при навигации
l_http_req utl_http.req; l_url varchar2(4000); l_value varchar2(4000); img_url varchar2(4000); -- URL изображения response sys.xmltype; map_req varchar2(4000);
BEGIN
size_par := to_number(map_size); x_par := to_number(map_x); y_par := to_number(map_y); delta_ := round(size_par/3,2);
-- организация запроса к MapViewer l_url := 'http://hostserver:8888/mapviewer/omserver'; utl_http.set_persistent_conn_support(TRUE); map_req := '<?xml version="1.0" standalone="yes"?> <map_request datasource="ds_demo" basemap="map_demo" width="640" height="480" bgcolor="#FFFFFF" antialiasing="false" format="GIF_URL"> <center size="'map_size'" > <geoFeature> <geometricProperty>
<Point> <coordinates>'map_x','map_y'</coordinates> </Point> </geometricProperty> </geoFeature>
</center> </map_request>';
-- отправка запроса к MapViewer l_http_req := utl_http.begin_request(l_url, 'POST', 'HTTP/1.0');
utl_http.set_header(l_http_req, 'Content-Type','application/x-www-form-urlencoded'); utl_http.set_header(l_http_req, 'Content-Length', length('xml_request='map_req)); utl_http.set_header(l_http_req, 'Host', 'zemhp'); utl_http.set_header(l_http_req, 'Port', '8888'); utl_http.write_text(l_http_req, 'xml_request=' map_req);
-- получение URL изображение карты l_http_resp := utl_http.get_response(l_http_req); utl_http.read_text(l_http_resp, l_value); response := sys.xmltype.createxml (l_value); utl_http.end_response(l_http_resp); img_url := response.extract('/map_response/map_image/map_content/@url').getstringval();
-- генерация HTML-страницы htp.htmlOpen; htp.headOpen; htp.title( 'Демонстрационное приложение' ); htp.headClose; htp.bodyOpen;
htp.tableOpen('border=0');
htp.prn('<tr>'); -- ячейка таблицы, содержащая изображением карты htp.prn('<td colspan=6><img border=1 src='''img_url''' width="640" height="480"></td>'); htp.prn('</tr>');
-- ячейки таблицы, содержащие вызовы данной PL/SQL-процедуры для организации навигации htp.prn('<tr>'); htp.prn('<td><img src="in.png" alt="Увеличить" onclick="location=''web.map_view?map_size='to_char(size_par-delta_)'&map_x='map_x'&map_y='map_y'""></td>'); htp.prn('<td><img src="out.png" alt="Уменьшить" onclick="location=''web.map_view?map_size='to_char(size_par+delta_)'&map_x='map_x'&map_y='map_y'""></td>'); htp.prn('<td><img src="left.png" alt="Влево" onclick="location=''web.map_view?map_size='map_size'&map_x='to_char(x_par+delta_)'&map_y='map_y'""></td>'); htp.prn('<td><img src="up.png" alt="Вверх" onclick="location=''web.map_view?map_size='map_size'&map_x='map_x'&map_y='to_char(y_par+delta_)'""></td>'); htp.prn('<td><img src="down.png" alt="Вниз" onclick="location=''web.map_view?map_size='map_size'&map_x='map_x'&map_y='to_char(y_par-delta_)'""></td>'); htp.prn('<td><img src="right.png" alt="Вправо" onclick="location=''web.map_view?map_size='map_size'&map_x='to_char(x_par-delta_)'&map_y='map_y'""></td>'); htp.prn('</tr>');
htp.tableClose;
htp.bodyClose; htp.htmlClose;
END; ----------------------------------------------------------------------------------------
Связка Web-браузер, Web-сервер и PL/SQL-процедура работает по рекурсивному принципу, так как каждый раз вновь генерируемая процедурой HTML-страничка содержит обратный вызов самой PL/SQL-процедуры, но уже с модифицированными относительно текущего состояния параметрами вызова. Это обеспечивает управление логикой запросов MapViewer и обеспечивает навигацию по плану посредством серии запросов данной HTML-страницы.
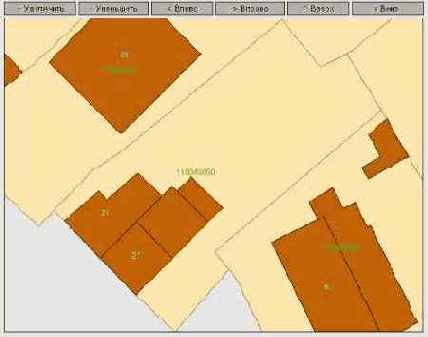
Основные принципы взаимодействия с MapViеwer
MapViewer представляет собой специализированный компонент среднего уровня в составе Oracle Application Server и состоит из двух основных компонентов:
подсистема рендеринга (на основе библиотеки Java-классов), которая формирует изображение картографической информации; прикладной интерфейс на основе XML, позволяющий управлять работой MapViewer (т.е. предоставляет программный интерфейс к функциям MapViewer).
Подсистема рендеринга подключается к базе данных Oracle посредством JDBC и выполняет доступ к пространственным данным (чтение и запись данных, хранящихся в Oracle Spatial или Oracle Locator). Также эта подсистема загружает из базы данных метаданные для настройки отображения карты (характеристики карты, стили и правила отображения данных, условные знаки и т.д.), чтобы в ходе работы применить их к извлекаемым из базы данных пространственным данным.
Использование языка XML предоставляет разработчикам приложений высокоуровневый интерфейс, при помощи которого можно отправлять картографические запросы к MapViewer и получать ответы в виде сгенерированного растрового изображения. MapViewer может взаимодействовать с такими клиентами, как Web-браузер или специально разработанное клиентское приложение, используя протокол HTTP.
Схема взаимодействия с MapViewer укладывается в два основных шага и не зависит от того, является ли это обычным клиентским запросом или некоторым административным действием (см. рисунок 1).
Для запроса клиентом картографической информации:
Выполняя запрос, клиент включает в него имя карты (то есть имя мета-описания хранящегося в базе данных), источник данных, центр местоположения, размеры карты, а возможно и другие данные, которые необходимы для отображения карты в нужном виде.
Сервер возвращает изображение карты (или URL-адрес по которому доступно это изображение) и габаритный прямоугольник (MBR - минимальный охватывающий прямоугольник) карты, а также статус, отражающий успешность выполнения запроса.
Для административных запросов, управляющих конфигурацией MapViewer:
Клиент запрашивает у MapViewer административное действие, посылая информацию о типе запроса и необходимые для полноты запроса значения его параметров.
Сервер возвращает статус запроса и запрошенную информацию.
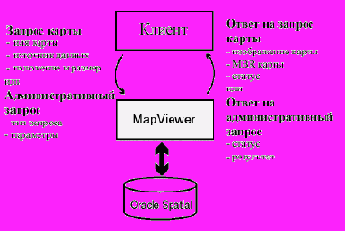
Рисунок 1. Схема базового взаимодействия для MapViewer

Рисунок 2. Обобщенная архитектура приложения.
Структура демонстрационного приложения

Рисунок 3. Основные элементы приложения
В рассматриваемом упрощенном приложении Web-браузер выступает в качестве клиента. Он обращается к поставляемому с сервером Oracle Web-серверу Apache с запросом на выполнение PL/SQL-процедур с заданными параметрами. Процедура динамически генерирует HTML-страницу, содержащую план-схему.
HTML-страница является носителем интерфейса пользователя и средством сохранения информации о состоянии пользовательского сеанса. Она содержит ссылку на растровое изображение плана-схемы, а также набор элементов управления для навигации по отображаемому на ней плану-схеме. Элементы управления выполнены в виде сгенерированных и вставленных в тело страницы запросов к PL/SQL-процедуре: увеличить, уменьшить масштаб; сдвинуть вправо, влево, вверх, вниз. Такой подход к организации навигации позволяет сохранить информацию о состоянии текущего сеанса пользователя в контексте взаимодействия браузера и Web-сервера без привлечения дополнительных механизмов (сookies, аутентификация и т.д.).
Web-сервер, функционирующий в составе сервера Oracle, обеспечивает работу Web-сервиса. Он осуществляет передачу и прием данных в рамках HTTP-протокола. В частности, он обеспечивает параметризированный вызов PL/SQL-процедуры, отправку браузеру динамически сгенерированной HTML-страницы и сгенерированного изображения плана-схемы.
MapViewer по XML-запросу PL/SQL-процедуры на основе заранее созданной карты и связанных с ней метаданных генерирует изображение плана-схемы фрагмента населенного пункта в указанном масштабе, с указанными размерами изображения и по указанным координатам. Он возвращает PL/SQL-процедуре ссылку на изображение сгенерированного изображения.
PL/SQL-процедура работает на стороне сервера и отвечает за генерацию HTML страницы. По запросу Web-браузера она генерирует HTML-страницу, в которую включает ссылку на изображение плана-схемы. Это изображение процедура предварительно запрашивает у MapViewer по заданным в качестве параметров процедуры координатам плана и масштабу, а также генерирует управляющие элементы навигации по плану-схеме. Эти управляющие элементы содержат обращения к той же самой PL/SQL-процедуре, но уже с модифицированными относительно текущего положения и масштаба плана-схемы параметрами.
Сервер Oracle Spatial содержит таблицы с пространственными данными и метаданными, необходимыми для работы приложения. Пространственные данные проиндексированы, могут формироваться и использоваться и другими приложениями.
Структуры данных Spatial, задействованные в проекте
Для того, чтобы вывести пространственные объекты при помощи MapViewer на растровое отображение карты, в базе данных Oracle необходимо создать таблицы, содержащие геометрические описания необходимых пространственных объектов, хранящиеся в столбцах типа SDO_GEOMETRY. Эти таблицы также могут содержать помимо колонок с пространственной информацией, необходимые столбцы, содержащие дополнительную семантическую информацию, по объектам. Например, подобная информация может служить для вывода текстовых надписей на объектах при формировании карты. Для более эффективной работы Spatial с этими таблицами необходимо создать пространственные индексы для столбцов с пространственной информацией.
Предположим нам необходимо обеспечить вывод информации о зданиях, улицах и земельных участках населенного пункта. Для обеспечения работы демонстрационного приложения в базе данных Oracle необходимо создать соответствующие таблицы пространственных данных:
Здания (BUILDS) - хранит полигональные объекты зданий и сооружение, а также информацию об адресных номерах зданий. Она содержит столбцы: PR_KEY NUMBER - первичный ключ; GEOLOC SDO_GEOMETRY - контуры зданий; NUM VARCHAR - номера зданий (номер и литера);
Улицы (STREET) - хранит линейные объекты, характеризующие пролегание улиц города, и информацию о названиях улиц. Включает столбцы: PR_KEY NUMBER - первичный ключ; GEOLOC SDO_GEOMETRY - оси улиц; NAME VARCHAR - названия улиц.
Участки (PARCELL) - хранит полигональные объекты, описывающие земельные участки, и информацию о кадастровых номерах участков.Содержит столбцы: PR_KEY NUMBER - первичный ключ; GEOLOC SDO_GEOMETRY - контура земельных участков; KU NUMBER - номера земельных участков.
Все три таблицы создадим в схеме, которую назовем MAP. Данные для примера в каждую из таблиц можно загрузить при помощи стандартного загрузчика Oracle или воспользоваться специализированной программой третьей фирмы. Например, Easy Loader, поставляемый с MapInfo, позволяет загрузить в Oracle Spatial данные из файлов формата MapInfo (TAB) и сразу же создать пространственные индексы на пространственные колонки (подробнее о программе смотрите здесь http://www.mapinfo.com). Также можно воспользоваться программой FME, позволяющей загружать данные из различных форматов (подробнее о программе смотрите http://www.safe.com/products/fme/).
Доступ к графической информации осуществляется опосредовано - через соответствующие процедуры PL/SQL, которые неявно формируют политику доступа к данным. Следует отметить, что в порядке разграничения доступа может возникнуть задача ограничения объема вывода информации, введения заданной погрешности в отображение данных, и другие. Эти проблемы могут быть решены, однако их рассмотрение выходит за рамки данной статьи. Для простейшего случая подключения к базе картографических данных MapViewer и Web-сервера необходимо создать соответствующего пользователя (или отдельно пользователей для MapViewer и Web-сервера для более полного разграничения доступа), в схеме которого будут храниться данные.
Управление MapViewer при помощи административных запросов
Основное использование MapViewer заключается в обработке различных запросов. Однако, MapViewer также принимает различные административные (то есть не картографические) запросы. К ним, например относится добавление источника данных при помощи прикладного интерфейса XML. Во все административные запросы вложен элемент <non_map_request> Административные запросы используются для следующих основных задач:
Управление источниками данных. Получение списка всех доступных карт (внесение в список). Получение списка всех доступных тем (внесение в список). Управление стилями. Управление КЭШем.
Наиболее типичным является использование административных запросов управления кэшем MapViewer. MapViewer использует два типа кэша:
кэш метаданных (кэшируются стили, темы и базовые карты) кэш пространственных данных.
Например, если был изменен какой либо из стилей, участвующих в формировании карты, то для того, чтобы эти изменения вступили в силу, необходимо либо перезапустить MapViewer, либо воспользоваться соответствующим административным запросом. Пример подобного запроса: <?xml version="1.0" standalone="yes"?> <non_map_request> <clear_cache data_source="ds_demo"/>
</non_map_request>
В результате выполнения данного запроса очищается текущий кэш метаданных и MapViewer загружает метаданные из сервера базы данных.
Установка и настройка MapViewer
Для того, чтобы начать работать с MapViewer, необходимо иметь следующие пакеты Java и продукты Oracle, соответствующих версий или выше:
Oracle Application Server 10g (9.0.4) или автономную версию Oracle Application Server Containers for J2EE (OC4J) версии 9.0.2 или выше. В примере мы используем версию 9.0.4. Существенных отличий при использовании более новой версии MapViewer 10.1.2 RC (Release Candidate) в рамках рассмотренного примера не обнаружено. Oracle Spatial или Oracle Locator (версии 8.1.6 или выше) Клиент Oracle (версии 8.1.7 или выше), если необходимо использовать возможности JDBC Oracle Call Interface (OCI). Java JDK (или JRE) версий 1.2, 1.3 или 1.4.
Все перечисленные компоненты доступны на сайте Oracle и Sun. Их использование в коммерческих целях требует соблюдения требований лицензирования.
MapViewer запускается, как OC4J Web-приложение и принимает запросы от клиентов. Его можно установить в составе полного Oracle Application Server или в виде отдельной автономной инсталляции компонента OC4J. С более подробными инструкциями по установке можно ознакомиться в соответствующей документации, прилагающейся к дистрибутиву продукта.
Если настройки MapViewer, установленные по умолчанию, необходимо изменить, можно отредактировать конфигурационный файл MapViewer mapViewerConfig.xml, который располагается по следующему пути: $ORACLE_HOME\lbs\mapviewer\conf. После того, как файл будет изменен, необходимо перезапустить MapViewer, чтобы изменения вступили в силу.
Конфигурационный файл задает следующую информацию в XML-формате:
Информация по подключению, задаваемая в элементе <logging>; Информация по изображению карты, расположенная в элементе <save_images_at>; Ограничения по выполнению административных запросов, задаваемые в элементе <ip_monitor>; Web-прокси информация для настройки внешних подключений через firewall, находящаяся в элементе <web_proxy>; Глобальные настройки карты, расположенные в элементе <global_map_config>; Установки внутреннего пространственного кэша, находящиеся в элементе <spatial_data_cache>; Настройки и регистрация нестандартного рендера, определенные в элементе <custom_image_renderer>; Источники данных карты, задаваемые в элементе <map_data_source>
Подробнее остановимся лишь на последнем элементе настройки, так как он имеет непосредственное отношение к приложению, которое рассматривается в этом материале. Конечно, источник данных для карты можно настроить динамически, выполнив соответствующий XML-запрос к MapViewer, но более простым решением будет задать нужный источник данных в конфигурационном файле, чтобы он был доступен всегда. Зададим нужный нам источник данных в элементе <map_data_source>
<map_data_source name="ds_demo" jdbc_host="hostserver" jdbc_sid="map9" jdbc_port="1521" jdbc_user="map" jdbc_password="!mappswrd" jdbc_mode="thin" number_of_mappers="5" />
Атрибут name задает уникальное имя источника данных, которое в дальнейшем будет использовано в запросах к MapViewer. Параметры jdbc_host, jdbc_sid, jdbc_port, и jdbc_user определяют информацию подключения к базе данных. Параметр jdbc_mode определяет, каким способом JDBC-драйвер будет обеспечивать подключение MapViewer к базе данных. По умолчанию это thin. Этот режим не требует наличия на сервере, где запущен MapViewer, установленного клиента Oracle. Также можно воспользоваться типом подключения oci8, который рекомендуется использовать, в случае если MapViewer запущен на одной машине с сервером базы данных. Параметр number_of_mappers определяет, сколько одновременно может быть создано рендеров карты для обслуживания одновременно подключившихся клиентов. Каждый рендер использует в среднем от 5 до 30 мегабайт оперативной памяти. Объем памяти зависит от объема полученных и обрабатываемых в процессе генерации карты данных. Каждый запрос, для которого нельзя сразу создать рендер, ставится в очередь. Максимально возможное количество рендеров - 64.
или просто MapViewer) является программным
Oracle Application Server MapViewer ( или просто MapViewer) является программным инструментом для отображения карт. Он использует пространственные данные, управляемые компонентами базы данных для работы с картографической информацией – Oracle Spatial или Oracle Locator. MapViewer предоставляет инструменты, которые скрывают сложность и комплексность организации запросов к пространственным данным и функциям отображения карт, но в то же время предоставляет широкий набор средств для более тонкой и всесторонней настройки параметров для более опытных пользователей. Эти инструменты могут быть помещены в платформно-независимую среду разработки и использованы для интеграции с приложениями, отображающими картографические данные.
В качестве примера, иллюстрирующего возможности использование MapViewer, рассмотрим реализацию простейшего Web-приложения. В качестве клиентской части данного приложения будет задействован обычный Web-браузер. HTML-страница для отображения на стороне клиента будет динамически генерироваться при помощи пакета PL/SQL UTL_HTTP и содержать необходимые функции для навигации по отображаемому в ее составе плану-схеме. Для обеспечения картографического изображения, которое находится на странице, будет задействован MapViewer. В качестве примера приложения решим задачу отображения картографического плана-схемы земельных участков города. Таким образом, вывод картографических элементов будет являться частью более крупной информационной Web-системы. Пример приложения, использующего MapViewer, содержит пространственные таблицы Oracle Spatial и метаданные, созданные для обеспечения работы с заданными таблицами, пример организации источника данных для MapViewer, XML-запросы к MapViewer и код PL/SQL процедуры, генерирующей HTML-страницу.
Вывод картографической информации средствами Oracle с использованием Web-приложения
Л. Рейнгольд, гл.специалист Управления земельными ресурсами,
А. Сорокин, гл.специалист Управления земельными ресурсами,
В.Фощанко, ведущий специалист МУП "Центр геодезии"
г.Владимир
Источник:
и любое технологическое решение MapViewer
Как и любое технологическое решение MapViewer имеет преимущества и недостатки.
Преимущества:
Так как MapViewer находится в одной "песочнице" с программными продуктами, обеспечивающими хранение пространственных данных, хранение вспомогательных метаданных, а также средств выполнения серверной логики (по аналогии с CGI-логикой Web-серверов), то в итоге информационные системы, созданные с использованием его и всех этих компонентов, во-первых, очень тесно и непротиворечиво взаимодействуют друг с другом, и во-вторых, находятся в едином пространстве информационных стандартов и правил обмена информацией. Подобные решения при создании Web-систем, в основе которых лежат мощные механизмы хранения и доступа к данным Oracle, позволяют безболезненно и, главное, гибко, с меньшими затратами открывать доступ пользователям к данным, хранящимся в базе данных, через Web-интерфейс. До появления MapViewer компонент представления картографической информации в линейке продуктов Oracle отсутствовал и приходилось прибегать к помощи программных продуктов третьих фирм. MapViewer заполнил данный пробел.
Недостатки:
По сравнению с программными продуктами других фирм, изначально нацеленных на отображение настраиваемых в широких пределах картографических данных в Web, MapViewer все же не является полноценным картографическим Web-сервером, о чем предупреждают и сами разработчики. Так данное программное средство целиком ориентировано на отображение данных Oracle Spatial, естественно отсутствует возможность подключения в картографическую композицию наряду с собственными данными Oracle данных из других источников (например, файловых), будь то фотографии, хранящиеся на сервере в виде файлов или данные, хранящиеся в применяемых в других ГИС форматах.
На наш взгляд, это средство может быть эффективно использовано в типичных системах отображения информации различного назначения как промышленного, так и коммерческого применения (муниципальном и региональном управлении, отображения в задачах позиционирования объектов с использованием мобильных терминалов и пр.).
Однако для решения специфических задач редактирования, сложной обработки картографической информации следует ориентироваться на специализированные ГИС-системы. Во всяком случае, до тех пор, пока фирма Oracle не разработает собственную полнофункциональную ГИС-систему или, по собственной коммерческой традиции, не приобретет фирму-производителя подобных решений.
Запросы, задействованные в задаче
Как было показано на схеме выше, основная последовательность действий клиента при работе с MapViewer является следующей: поиск запущенного экземпляра MapViewer, присоединение к нему, отправка картографического XML запроса и обработка результата, полученного от экземпляра MapViewer.
Запрос к сервлету MapViewer имеет следующий формат:
http://hostname[:port]/MapViewer-servlet-path?xml_request=xml-request
где hostname - это сетевой путь к серверу, на котором запущен MapViewer.
port - это порт, на котором сервис MapViewer слушает сеть.
MapViewer_servlet_path - это путь к сервлету MapViewer (например :/mapviewer/omserver)
xml_request - кодированный по правилам URL запрос в формате XML, который отсылается на сервер методами POST или GET. Форма представления запроса в виде XML требуется во всех видах запросов. Содержимое ответа на запрос может варьироваться от данных в виде XML-документа до бинарного объекта, содержащего файл изображения, запрошенного пользователем.
В отправляемом запросе необходимо указать источник данных и один или более необходимых параметров:
Темы и стили. Координаты центральной точки или прямоугольник, задающие отображаемую карту. Также дополнительно могут быть посланы надписи и стили. Предопределенную базовую карту, которая может быть многократно использована и частично переопределена в данном конкретном запросе. Настроенные темы, содержащие пользовательские точки данных (или другие геометрические объекты) генерируемые динамически и отображаемые непосредственно из доступной базы данных. Настроенные объекты (точки, линии, полигоны и пр.), заданные в строках XML запроса для отображения. Тематическое картографирование
В нашем конкретном случае, генерируя HTML-страницу, PL/SQL-процедура выполняет непосредственно один запрос к MapViewer вида: 'http://hostserver:8888/mapviewer/omserver? xml_request='<?xml version="1.0" standalone="yes"?> <map_request datasource="ds_demo" basemap="map_demo" width="640" height="480" bgcolor="#FFFFFF" antialiasing="false" format="GIF_URL"> <center size="[size]">
<geoFeature> <geometricProperty> <Point> <coordinates>[x],[y]</coordinates> </Point>
</geometricProperty> </geoFeature> </center> </map_request>
где hostserver:8888/mapviewer/omserver - сервер MapViewer datasource="ds_demo" - параметр запроса, определяющий источник данных, настроенный ранее для MapViewer basemap="map_demo" - параметр, определяющий имя базовой карты, и включающей в себя все необходимые метаданные, необходимые для формирования и отображения карты. width="640" height="480" - эти параметры задают размеры в пикселах результирующего изображения карты bgcolor="#FFFFFF" - параметр задает RGB-цвет фона изображения карты, поверх которого отрисовывается все остальное. antialiasing="false" - параметр сглаживания ступенчатости на изображении карты. format="GIF_URL" - параметр, указывающий MapViewer, что необходимо сформировать изображение карты и вернуть ссылку на него. <center>...</center> - раздел, определяющий участок карты, котрый нужно отобразить на результирующем изображении. size="[size]" - параметр определяющий размер карты. <geoFeature>...</geoFeature> - раздел указывающий MapViewer, что положение отображаемого участка карты будет задано при помощи пространственного объекта (в нашем случае при помощи точки). <geometricProperty>...</geometricProperty> - подраздел задает геометрические параметры пространственного объекта. <Point>...</Point> - этим подразделом конкретизируется, что в качестве пространтсвеннгшо объекта будет указана точка. <coordinates>[x],[y]</coordinates> - а здесь уже конкретно указываются координаты точки в единицах измерения и системе координат карты
Некоторые основные свойства
Materialized views, так же как и обычные именованные выводимые таблицы, являются с точки зрения словаря-справочника Oracle хранимыми объектами и создаются, изменяются и удаляются SQL-командами CREATE, ALTER и DROP, например:
CREATE MATERIALIZED VIEW имя [ENABLE QUERY REWRITE] AS SELECT ...
Если в предложении выше присутствует фраза ENABLE QUERY REWRITE, это выводимая хранимая таблица для возможности перенаправления к ней запроса, предъявленного к базовым. Иначе, если в предложении SELECT присутствует обращение к удаленной таблице (в другой БД), это выводимая хранимая таблица для локализации удаленных данных. Если в предложении CREATE MATERIALIZED VIEW нет ни того, ни другого, это обычная выводимая таблица с хранимым результатом, создаваемая для технических ухищрения программирования работы с данными в Oracle.
Кроме этого materialized views могут характеризоваться другими важными для этих объектов признаками:
Наличием в своем определении обобщения, например агрегатного выражения с GROUP BY. Наличием в своем определении операции соединения над базовыми таблицами.
В целом materialized views характеризуются следующими группами свойств:
Описание ожидаемого результата, задаваемое предложением SELECT Схема обновления результата Схема внутренней организации результата Свойства хранения и доступа
Все свойства этих групп формулируются собственными синтаксическими конструкциями в предложениях CREATE/ALTER MATERIALIZED VIEW
Некоторые типичные примеры
Ниже приводятся примеры построения materialized views нескольких важных категорий.
Общие положения
Разновидности выводимых таблиц ("виртуальных", "вторичных"; "представлений") в Oracle:
именованные выводимые таблицы - views: для моделирования данных и регулирования доступа к данным именованные выводимые таблицы с хранимым результатом - materialized views: для повышения эффективности доступа к данным или для программирования доступа неименованные выводимые таблицы без хранения результата - inline views: для формулирования запросов к данным.
В отличие от большинства других видов объектов, materialized views (за исключением одной их разновидности) не являются функционально самостоятельным видом объектов и чаще всего их функциональность может моделироваться вручную с помощью аппарата триггеров и системного пакета DBMS_JOB. В этом случае их использование просто повышает уровень абстракции при программировании БД в Oracle.
Подготовка примера
В примерах далее будет использована стандартная схема SCOTT. Для дальнейшей работы пользователю SCOTT нужно дать от имени SYS привилегию создавать materialized view:
GRANT CREATE SNAPSHOT TO scott;
Построение в рамках одной БД
Выводимые таблицы с хранимым результатом могут использоваться не только в распределенной среде или для повышения скорости доступа к большим таблицам, например:
CREATE MATERIALIZED VIEW jobsal AS SELECT job, SUM(sal) FROM emp GROUP BY job;
Мотивом для такого создания могут служить попытки найти в Oracle технические решения для конкретных манипуляций с данными в БД.
Построение в рамках одной схемы: подмена запроса
Эта разновидность materialized view может создаваться только на основе таблицы, находящейся в той же схеме. Кроме этого, для ее создания нужно иметь особую привилегию QUERY REWRITE.
Подготовка примера
Выдадим от имени SYS:
GRANT QUERY REWRITE TO scott;
Построение примера
Выдадим в SQL*Plus от имени SCOTT:
CREATE MATERIALIZED VIEW dept_salaries ENABLE QUERY REWRITE AS SELECT dname, COUNT(emp.deptno) emp_count, SUM(sal) tot_sal FROM emp, dept WHERE emp.deptno (+) = dept.deptno GROUP BY dname;
(В следующем примере и в двух далее одинаковым фоном выделены одинаковые участки кода).
Выводимая таблица DEPT_SALARIES показывает список отделов, число работающих в них и фонд зарплаты. Число отделов:
SELECT COUNT(*) FROM dept_salaries;
Проверка работы переформулировки
Проанализируем таблицы (желательно) и сравним планы:
ANALYZE TABLE emp COMPUTE STATISTICS; ANALYZE TABLE dept COMPUTE STATISTICS; ANALYZE TABLE dept_salaries COMPUTE STATISTICS;
SET AUTOTRACE TRACEONLY EXPLAIN
SELECT dname, COUNT(emp.deptno) emp_count, SUM(sal) tot_sal FROM emp, dept WHERE emp.deptno (+) = dept.deptno GROUP BY dname;
ALTER SESSION SET QUERY_REWRITE_ENABLED=TRUE;
SELECT dname, COUNT(emp.deptno) emp_count, SUM(sal) tot_sal FROM emp, dept WHERE emp.deptno (+) = dept.deptno GROUP BY dname;
Два последних оператора SELECT идентичны.
Пример показывает, что мы можем продолжать работать с исходными таблицами независимо от того, построена выводимая таблица DEPT_SALARIES, или нет. СУБД сама определила, что таковая имеется, и переадресовала запрос к ней. Сама таблица DEPT_SALARIES не несет в себе новых данных и ее наличие, подобно наличию индекса, позволяет в некоторых случаях сократить время доступа к исходной информации.
Следующие примеры свидетельствуют, что для подобной автоматической переадресации к данным в приложении не обязательно повторять в точности формулировку имеющейся выводимой таблицы. Достаточно, чтобы в выводимой таблице с хранимым результатом хватало данных для ответа:
SELECT dname, COUNT(emp.deptno) emp_count FROM emp, dept WHERE emp.deptno (+) = dept.deptno GROUP BY dname;
SELECT dname, COUNT(emp.deptno) emp_count, SUM(sal) tot_sal FROM emp, dept WHERE emp.deptno (+) = dept.deptno AND dept.deptno <> 10 GROUP BY dname;
Построение в рамках распределенной БД: тиражирование данных
Эта разновидность materialized views в ранних версиях Oracle существовала под названием snapshots. В ряде случаев Oracle продолжает поддерживать старое название snapshot на равных правах с более поздним materialized view.
Возможны два варианта использования materialized views для тиражирования данных: одностроннее тиражирование (хранимый результат доступен для выборки и закрыт для изменений приложением) и двустороннее тиражирование (хранимый результат может изменяться приложением). Для простоты здесь будет рассматриваться первый вариант, одностороннего тиражирования.
Подготовка примера
Для иллюстрации использования materialized view для тиражирования данных необходимо перевести БД на глобальную систему имен и создать связь с удаленной БД.
Назначим для БД REM_BASE домен CLASS. Пусть логическое имя соединения с этой БД - REMOTE_DB.
(1) Проставим в INIT.ORA DB_DOMAIN="class" и перезапустим СУБД для этой базы по этому файлу параметров
(2) Выдадим от имени SYS в REM_BASE:
ALTER DATABASE RENAME GLOBAL_NAME TO rem_base.class;
(3) Выдадим от имени SCOTT в локальной БД:
CREATE DATABASE LINK rem_base.class CONNECT TO scott IDENTIFIED BY tiger USING 'remote_db';
Убедиться, что созданная связь работает, можно выдав:
SELECT * FROM emp@rem_base.class;
Построение примера
Выдадим от имени SCOTT:
CREATE MATERIALIZED VIEW loc_emp AS SELECT * FROM emp@rem_base.class;
Пявившиеся в результате новые объекты схемы SCOTT можно посмотреть так:
SELECT object_name, object_type FROM user_objects;
Просмотр "локальных" данных об "удаленных" сотрудниках:
SELECT * FROM loc_emp;
Справочная информация
Сведения об имеющихся выводимых таблицах с хранимым результатом и их свойства хранятся в системных USER/ALL/DBA_-таблицах с подстрокой MVIEW в имени, например
USER_MVIEWS
USER_MVIEW_LOGS
USER_MVIEW_AGGREGATES
USER_MVIEW_DETAIL_RELATIONS
USER_MVIEW_JOINS
USER_MVIEW_KEYS
Часть свойств materialized views в этих таблицах унаследована от выводимых таблиц (обновляемость), часть от хранимых таблиц (внутренняя организация, организация храниения, а часть свойств является собственными (схемы обновления хранимого результата).
В то же время при работе с materialized views в схеме автоматически создаются специальные служебные объекты (таблицы, индексы). Сведения о них доступны из "обычных" справочных таблиц, в первую очередь из USER_OBJECTS.
в Мастерской
В.В. Пржиялковский , опубликовано в Мастерской Oracle,
Источники данных
Подобно обычным именованным выводимым таблицам, materialized views могут базироваться не только на хранимых таблицах, но и, в свою очередь, на выводимых: как views, так и materialized views.
Явное обновление полученных данных
Явное обновление результатов materialized view осуществляется через API, обращением к процедуре REFRESH из состава системного пакета DBMS_MVIEW (старое название - DBMS_SNAPSHOT):
EXECUTE DBMS_MVIEW.REFRESH('jobsal')
Первый параметр этой процедуры, LIST, может содержать имя выводимой таблицы или их список через запятую. Помимо него у процедуры есть несколько необязательных параметров. Среди них параметр METHOD используется для указания одного из возможных для данной таблицы метода обновления. Пример явного обновления с полным перевычислением результата:
EXECUTE DBMS_MVIEW.REFRESH(LIST => 'jobsal', METHOD => 'C')
Другие значения параметра METHOD: A (Always, то же, что и C, COMPLETE), F (FAST, быстрое обновление, путем внесения изменений), ? (форсированное обновление).
Явное обновление применимо к materialized view с любыми установленными режимом и методом обновления.
Неявное обновление данных
Происходит в режиме ON COMMIT или ON DEMAND. Режим ON DEMAND (явно можно не указывать) позволяет организовать автоматический пересчет результата по графику.
Метод для этих режимов обновления можно указывать любой: и FAST, и COMPLETE.
Если пересчет ведется методом FAST, то для таблицы нужно создать. журналы всех ее базовых таблиц (materialized view logs). Это будут вспомогательные таблицы, накапливающие сведения об изменениях, совершаемых в базовых. Они и позволят внести необходимые поправки в данные materialized view. После выполнения процедуры обновления журналы автоматически чистятся.
Для пересчета результата методом COMPLETE журнал не нужен.
Синхронизация с изменениями в исходных данных
Синхронизация образованных при создании materialized view данных с изменениями в базовых таблицах требуется, наверное, всегда. Принципы синхронизации общие для всех категорий materialized view. Синхронизация может выполняться явно, либо осуществляться автоматически.
Схема обновления хранимого результата характеризуется двумя свойствами:
Режим обновления. Указывает момент осуществления обновления, будет ли обновление делаться по фиксации транзакции (ON COMMIT) или с помощью API (ON DEMAND), процедурам из состава системных пакетов Oracle, вызываемым явно или неявно (автоматически). Метод обновления. Задает объем обновления. Два основных метода - полное перевычисление результата (COMPLETE) и экономное (FAST), достигаемое путем внесения в результат только изменений, вызванных изменениям в базовых таблицах.
Оба свойства могут указываются во фразе REFRESH предложения CREATE/ALTER MATERIALIZED VIEW:
CREATE MATERIALIZED VIEW имя [REFRESH ...];
При указании режима ON DEMAND дополнительно можно задать желаемое время внесения обновлений. Вот возможные сочетания задаваемых свойств схемы обновления:
REFRESH ON COMMIT FAST <требуются журналы REFRESH ON COMMIT COMPLETE REFRESH [ON DEMAND] FAST [START WITH ...] <требуются журналы REFRESH [ON DEMAND] COMPLETE [START WITH ...]
Обновления всех видов можно на время запретить, переведя materialized view в специальное состояние командой
ALTER MATERIALIZED VIEW имя NEVER REFRESH;
Создание на основе имеющихся данных
Фраза ON PREBUILT TABLE позволяет сформировать хранимый результат без начального вычисления, на основе хранимой таблицы с той же структурой, или незначительно отличающейся. Ниже приводится простой пример первого варианта:
CREATE TABLE e4 AS SELECT * FROM emp WHERE deptno = 20;
CREATE MATERIALIZED VIEW e4 ON PREBUILT TABLE AS SELECT * FROM emp;
SELECT * FROM e4;
Обратите внимание на то, что при таком построении materialized view сведения о былой самостоятельности таблицы E4 после создания выводимой E4 не теряются. Они восстановятся после удаления materialized view (что невозможно при обычном создании):
DROP MATERIALIZED VIEW e4;
SELECT * FROM e4;
Создание с отложенным построением результата
Фраза BUILD IMMEDIATE (умолчательная) в предложении CREATE MATERIALIZED VIEW сообщает, что сам хранимый результат будет вычислен автоматически немедленно после создания materialized view. Фраза BUILD DEFERRED сообщает, что вычисление хранимого результата произойдет позже, при выполнении первого обновления:
CREATE MATERIALIZED VIEW имя BUILD DEFERRED AS SELECT ...
в Мастерской
В.В. Пржиялковский, опубликовано в Мастерской Oracle,
Задание схемы обновления
Указание объема вычислений при обновлении
Синтаксически для указания метода обновления используются следующие ключевые слова во фразе REFRESH:
REFRESH COMPLETE: указывает СУБД, что при автоматическом обновлении хранимого результата он будет перевычисляться полностью путем повторения оператора SELECT, сформулированного для materialized view. Это гарантированно надежный вариант обновления. REFRESH FAST: указывает СУБД, что при неявном обновлении в хранимый результат будут вноситься изменения на основе информации, собранной в журналах базовых таблиц. Это более быстрый вариант. REFRESH FORCE: указывает СУБД выбрать режим FAST, если это возможно, иначе - COMPLETE. Это вариант по умолчанию.
Примеры:
DROP MATERIALIZED VIEW LOG ON emp;
CREATE MATERIALIZED VIEW LOG ON emp WITH (sal,comm), ROWID INCLUDING NEW VALUES;
ALTER MATERIALIZED VIEW jobsal REFRESH FAST;
DROP MATERIALIZED VIEW LOG ON emp;
ALTER MATERIALIZED VIEW jobsal REFRESH COMPLETE;
Пример показывает, что экономное обновление агрегирующего хранимого результата возможно только при выполнении некоторых условий на полноту журнальной таблицы.
Указание времени обновления
Синтаксические конструкции фразы REFRESH для указания времени осуществления обновлений:
ON COMMIT: режим, при котором обновление хранимого результата будет производиться по всякой фиксации транзакции (COMMIT). Время фиксации возрастет. ON DEMAND: режим, при котором обновление будет осуществляться процедурами из состава системного пакета DBMS_MVIEW.
o START WITH первый_раз NEXT потом: обновление будет выполнено единожды первый_раз, после чего автоматически повторяться по формуле, вычисляемой потом. Может быть только уточнением к режиму ON DEMAND.
Автоматическое выполнение обновлений по графику возможно только в случае, если в составе СУБД запущены необязательные фоновые процессы SNPn. Их запуск достигается путем указания параметра СУБД JOB_QUEUE_PROCESSES. До версии 9 умолчанием для него был 0.
Пример:
CREATE MATERIALIZED VIEW LOG ON emp WITH ROWID INCLUDING NEW VALUES;
ALTER MATERIALIZED VIEW jobsal REFRESH START WITH SYSDATE NEXT SYSDATE+1/1440;
COMMIT;
SELECT * FROM jobsal;
Примеры обновлений в режиме ON COMMIT:
DROP MATERIALIZED VIEW LOG ON emp;
CREATE MATERIALIZED VIEW emp2 REFRESH COMPLETE ON COMMIT AS SELECT * FROM emp;
CREATE MATERIALIZED VIEW jobtotals REFRESH ON COMMIT AS SELECT job, COUNT(*), COUNT(comm), SUM(comm), SUM(sal) FROM emp GROUP BY job;
Проверка:
UPDATE emp SET sal = 8000 WHERE ename = 'SMITH';
SELECT sal FROM emp2 WHERE ename = 'SMITH';
SELECT * FROM jobtotals;
COMMIT;
SELECT sal FROM emp2 WHERE ename = 'SMITH';
SELECT * FROM jobtotals;
Можно заметить, что последний пример позволяет обойти проблему Mutating Trigger при попытке автоматического обновления хранимых агрегатов (например, сумм) после обновления полей с исходными данными.
Журналы базовых таблиц
Пример создания журнала для исходной (базовой) таблицы:
CREATE MATERIALIZED VIEW LOG ON emp;
После этой команды в схеме появится служебная таблица для журнализации изменений в EMP и служебный триггер для актуализации таких изменений. (В последних версиях Oracle этот триггер сделан внутренним и в таблице USER_TRIGGERS не виден).
Объем данных, попадаемых в журнал, можно регулировать фразой WITH предложения CREATE MATERIALIZED VIEW LOG, вставляемой после фразы ON:
CREATE MATERIALIZED VIEW LOG ON имя WITH ...
Вот возможные указания для обычных таблиц:
PRIMARY KEY: можно не указывать, так как в последних версиях первичный ключ заносится в журнальную строку автоматически. ROWID: при внесении изменений в базовую таблицу в журнальной будет отмечаться ее физический адрес. (список_столбцов): при внесении изменений в базовую таблицу в журнальную будут заноситься значения полей. SEQUENCE: при добавлении в журнальную таблицу новой строки она будет специально нумероваться INCLUDING NEW VALUES: в журнал будут помещаться не только старые, но и новые значения. По умолчанию используется EXCLUDING NEW VALUES.
(Для более экзотических объектных таблиц можно еще указывать WITH OBJECT ID).
Примеры:
DROP MATERIALIZED VIEW LOG ON emp;
CREATE MATERIALIZED VIEW LOG ON emp WITH ROWID;
DROP MATERIALIZED VIEW LOG ON emp;
CREATE MATERIALIZED VIEW LOG ON emp WITH ROWID, SEQUENCE, (sal,comm);
DROP MATERIALIZED VIEW LOG ON emp;
CREATE MATERIALIZED VIEW LOG ON emp WITH (sal,comm) INCLUDING NEW VALUES;
Разный объем информации, включаемой в журнал, может быть востребован разными схемами обновления. Некоторые схемы обновления могут требовать включения в состав строк журнала определенных полей, а некоторые - нет.
