Дешифрование
Джилл, одна из разработчиков Джона, спросила: "Когда нужно расшифровывать зашифрованные данные и как мы будем это делать"?
Джон объясняет, что в пакете DBMS_CRYPTO есть функция дешифрования DECRYPT. Она принимает для дешифрования исходные зашифрованные данные; ключ, использованный во время шифрования; а также объединенный параметр: алгоритм, длина ключа и схемы сцепления и дополнения. Вместе с данными, которые нужно дешифровать, необходимо передавать те же самые ключ и модификаторы, использованные во время шифрования. Банк Acme использует стандартные (одинаковые) алгоритм, длину ключа и схемы сцепления и дополнения, поэтому Джон создал простую функцию для дешифрования зашифрованных данных, показанную на листинге 3. Эта функция принимает только два параметра - зашифрованные данные и ключ - и возвращает расшифрованные данные типа VARCHAR2 (преобразование данных типа RAW делается в строке 20 листинга 3).
Листинг 3. Простая функция дешифрования
1 create or replace function get_dec_val 2 ( 3 p_in in raw, 4 p_key in raw 5 ) 6 return varchar2 7 is 8 l_ret varchar2 (2000); 9 l_dec_val raw (2000); 10 l_mod number := dbms_crypto.ENCRYPT_AES128 11 + dbms_crypto.CHAIN_CBC 12 + dbms_crypto.PAD_PKCS5; 13 begin 14 l_dec_val := dbms_crypto.decrypt 15 ( 16 p_in, 17 l_mod, 18 p_key 19 ); 20 l_ret:= UTL_I18N.RAW_TO_CHAR 21 (l_dec_val, 'AL32UTF8'); 22 return l_ret; 23* end;
Дополнительные меры
Джон продолжает обсуждение, детализируя способы хранения ключа шифрования и реализации процесса доступа. Группа обсуждает безопасные контексты приложений, позволяющие использовать только одно представление для работы пользователей с различными уровнями авторизации.
После завершения обсуждения Джон немедленно посылает Джейн электронное письмо, извещая её, что план шифрования готов, и предлагает продемонстрировать его в удобное для неё время.

Пакеты, поставляемые с СУБД Oracle
Джон продолжает: в сервере Oracle Database 10g пользователи могут реализовывать свои методы шифрования, используя функции и процедуры, которые доступны во встроенном пакете DBMS_CRYPTO. В сервере Oracle Database 10g и более ранних версиях также доступен другой пакет, DBMS_OBFUSCATION_TOOLKIT, в котором предлагается подмножество функциональных возможностей пакета DBMS_CRYPTO. В банке Acme системы работают в среде Oracle Database 10g, а в более новом пакете DBMS_CRYPTO предлагаются дополнительные функциональные возможности, кроме того, корпорация Oracle рекомендует использовать именно его, поэтому Джон принял решение использовать этот пакет, и вся аудитория с ним согласилась.
Генерация ключей
. Поскольку безопасность зашифрованных данных зависит от трудности угадывания ключа, выбор надлежащего ключа - самый главный шаг в процессе шифрования. Ключ может быть любым значением данных типа RAW, но если оно выбрано не достаточно случайно, злоумышленник будет в состоянии угадать ключ. Джон предупреждает, ключ не может быть, например, именем вашего домашнего животного или вашей датой рождения; это должно быть действительно случайное число. Один младший администратор базы данных спрашивает: "Как вы сгенерируете такой случайный ключ"? Джон отвечает, что случайные числа могут генерироваться с помощью встроенного пакета DBMS_RANDOM, но криптографически стойкая генерация случайных чисел достигается использованием функции RANDOMBYTES в пакете DBMS_CRYPTO. Функция имеет один входной параметр (типа данных BINARY_INTEGER, на выходе выдается число типа данных RAW, длина которого определена входным параметром. Это число может использоваться как ключ. Джон демонстрирует это на примере простого PL/SQL-кода, показанного на листинге 1.
Листинг 1.
Шифрование данных
1 declare 2 enc_val raw (2000); 3 l_key raw (2000); 4 l_key_len number := 128; 5 l_mod number := dbms_crypto.ENCRYPT_AES128 6 + dbms_crypto.CHAIN_CBC 7 + dbms_crypto.PAD_PKCS5; 8 begin 9 l_key := dbms_crypto.randombytes (l_key_len); 10 enc_val := dbms_crypto.encrypt 11 ( 12 UTL_I18N.STRING_TO_RAW ('SECRET', 'AL32UTF8'), 13 l_mod, 14 l_key 15 ); 16 -- Здесь можно использовать зашифрованные данные enc_val 17 end;
Объясняя этот код, Джон обратил внимание, что для проекта шифрования в банке Acme в пакете DBMS_CRYPTO подходит несколько типов алгоритмов и соответствующих длин ключей (см. табл. 1).

Таблица 1. Константы для алгоритмов пакета DBMS_CRYPTO
Первый столбец в табл.1 - Constant Name (имя константы) - показывает константы, определенные в пакете для указания различных алгоритмов и длин ключей (Effective Key Length). Например, для указания 128-битового ключа, соответствующего стандарту Advanced Encryption Standard (AES, усовершенствованный стандарт шифрования), поясняет Джон, вы используете константу DBMS_CRYPTO.ENCRYPT_AES128 (см. строку 5 листинга 1). Чем длиннее ключ, тем меньше шансов у злоумышленника для его угадывания, но больше работы у сервера для шифрования и дешифрования. Для установления соотношения между безопасностью и нагрузкой на сервер Джон выбирает средний вариант - 128-битовый ключ и алгоритм AES.
Затем определяется тип сцепления, которое при блочном шифровании позволяет разбивать данные на участки для шифрования, как это показано в строке 6 листинга 1. Самый распространенный формат - Cipher Block Chaining (CBC, сцепление блоков шифротекста), указывается в пакете DBMS_CRYPTO константой CHAIN_CBC. Другие варианты сцепления: Electronic Code Book (CHAIN_ECB , электронная книга кодов), Cipher Feedback (CHAIN_CFB, шифрование с обратной связью от шифротекста) и Output Feedback (CHAIN_OFB, шифрование с обратной связью по выходу).
Наконец, поясняет Джон, при блочном шифровании данные обычно шифруются в блоках по восемь символов. Если длина входных данных не кратна восьми, добавляется недостающий символ или символы; этот процесс называется дополнением (padding). Простейший вариант - дополнение нулями. Джон указывает, что этот вариант включается константой PAD_ZERO, определенной в пакете DBMS_CRYPTO, но он не считается достаточно безопасным, поскольку потенциальный злоумышленник может угадать его. Более безопасное дополнение основано на стандарте Public-Key Cryptography Standard # 5 (PKCS#5, криптографический стандарт с общим ключом), задаваемый в пакете DBMS_CRYPTO константой PKCS5, как это показано в строке 7 листинга 1. Если вы уверены, комментирует Джон, что длина данных уже кратна размеру блоков, то дополнения не потребуется, и вы можете указать это с помощью константы PAD_NONE.
Все эти три параметра - алгоритм с длиной ключа, методы сцепления и дополнения - объединяются в один параметр, передаваемый во встроенную функцию шифрования ENCRYPT пакета DBMS_CRYPTO. Функции ENCRYPT требуется, чтобы незашифрованные данные имели тип RAW. Это преобразование делается в строке 12 листинга 1.
В целях стандартизации, продолжает Джон, банк Acme принял решение во всех приложениях использовать алгоритм AES с 128-битовыми ключами, сцепление CBC и дополнение PCKS #5. Используя эти значения, Джон создает простейшую функцию GET_ENC_VAL, показанную на листинге 2, которая принимает только два параметра - исходные незашифрованные данные и ключ - и возвращает зашифрованные данные.
Листинг 2. Простая функция шифрования
1 create or replace function get_enc_val 2 ( 3 p_in in varchar2, 4 p_key in raw 5 ) 6 return raw is 7 l_enc_val raw (2000); 8 l_mod number := dbms_crypto.ENCRYPT_AES128 9 + dbms_crypto.CHAIN_CBC 10 + dbms_crypto.PAD_PKCS5; 11 begin 12 l_enc_val := dbms_crypto.encrypt 13 ( 14 UTL_I18N.STRING_TO_RAW 15 (p_in, 'AL32UTF8'), 16 l_mod, 17 p_key 18 ); 19 return l_enc_val; 20* end;
Шифрование базы данных
После совещания ИТ-менеджеров Джон немедленно собирает своих непосредственных подчиненных для обсуждения стратегии шифрования и ее реализации в своей группе.
Он изложил свою точку зрения на стратегию шифрования, начав с краткого обзора процесса шифрования. Он представляет своей группе простой пример, в котором величина остатка на счете изменена дополнением секретного числа с одной цифрой. Если секретное число будет равно, например, 2, а величина остатка на с счете - 3467, то зашифрованная величина будет равна 3469. Реальная величина может быть расшифрована вычитанием числа 2 из зашифрованной величины, Джон пояснил, что этот процесс называется дешифрованием (decryption). Такую логику добавления определенного числа к реальным данным называют алгоритмом шифрования (encryption algorithm). Число 2, которое добавляется алгоритмом, называется ключом шифрования (encryption key). Исходные данные (original data) и ключ шифрования обрабатываются алгоритмом шифрования для создания зашифрованных данных (encrypted data), как показано рис.1.

Рис 1. Механизм шифрования
При дешифровании для получения исходных данных логика изменятся на обратную. Эта схема также называется симметричным шифрованием (symmetric encryption), поскольку один и тот же ключ используется для шифрования и дешифрования.
Алгоритмы шифрования чаще всего общедоступны; следовательно, безопасность обеспечивается выбором трудно угадываемого ключа. Если бы хакеры в этом примере должны были угадать 1-цифровой ключ, они должны были бы перебрать только 10 чисел - цифры от 0 до 9. Однако, если бы ключ состоял из двух цифр, то они должны были бы перебрать 100 чисел - от 0 до 99. Джон поясняет, чем длиннее ключ, тем более трудно угадать его.
Шифруем свои ресурсы данных
(Arup Nanda)
Оригинал: Encrypt Your Data Assets
Перевод:
Создание гибкой инфраструктуры для защиты конфиденциальных данных
Джон, главный администратор базы данных банка Acme Bank, вовлечен в очень важную инициативу, связанную с безопасностью и конфиденциальностью. Джейн, начальник службы информационной безопасности банка, описала стратегию безопасности банка, и Джон определил обязанности своей группы.
Джейн на совещании с ИТ-менеджерами банка Acme объяснила, что безопасность компании можно рассматривать как ряд уровней (слоев) защиты. Для иллюстрации этого Джейн использует "матрешку" - комплект кукол, вкладывающихся одна в другую. Последняя из четырех или пяти этих кукол содержит в себе что-то вроде приза. Чтобы получить приз нужно один за другим удалять "слои" кукол, и если по каким-то причинам слои не могут быть удалены, добраться до приза будет труднее. Джейн объясняет, что злоумышленник, чтобы добраться до корпоративных информационных ресурсов, должен также "победить" много уровней защиты.
Первая полоса обороны - межсетевой экран (МЭ), защищающий всю информационную инфраструктуру организации; он препятствует посторонним получать доступ к любому из информационных источников в компании. Однако никакая организация не является островом и МЭ совсем не воздухонепроницаемы - необходимы "отверстия" или порты, чтобы из внешнего мира мог поступать законный трафик.
Если злоумышленник проходит через внешний МЭ, то он будет обязан предоставить пароль, чтобы получить доступ к серверу, или, возможно, для аутентификации у него будут запрошены другие верительные данные, например, сертификат безопасности. Это - следующий уровень защиты. После аутентификации законному пользователю нужно разрешить доступ только к тем ресурсам, к которым он иметь доступ. Если пользователь подключается к серверу базы данных, но не имеет никаких полномочий, чтобы получить доступ к каким-либо таблицам, представлениям или любым другим источникам данных, информация по-прежнему будет защищена. Этот механизм - следующий уровень защиты.
Джейн подчеркивает, что злоумышленник может так или иначе победить все защитные меры и добраться до данных предприятия. С точки зрения планирования эта возможность должна быть допущена, проанализирована и устранена. Единственный вариант, оставшийся на этой стадии для защиты от злоумышленника, - последний уровень защиты, на котором данные изменяются так, чтобы они не казались злоумышленнику полезными. Это делается с помощью процесса, называемого шифрованием (encryption). Шифрование изменяет данные так, чтобы сделать их неразборчивыми для всех, кроме тех, кто знает, как расшифровать эту информацию.
Управление ключами
Занимаясь блочным шифрованием, группа Джона ищет и полное решение для шифрования информации на основе пакета DBMS_CRYPTO. Самой большой проблемой в шифровании, объясняет Джон, является не генерация ключей или использование функций, а управление ключами, используемыми в процессе шифрования. Одни и те же ключи используются для шифрования и дешифрования данных, поэтому их нужно надежно охранять, чтобы защитить данные. В то же самое время, однако, приложения и пользователи должны иметь доступ к ключам, чтобы дешифровать данные для нормального использования. Эта проблема решается, поясняет Джон, выбором места хранения ключей и обеспечением гарантий, что они будут доступны только законным пользователям. Он предоставляет два варианта управления ключами:
Использование одного и того же ключа для всех записей. Использование разных ключей для разных записей.
В варианте 1, продолжает Джон, для шифрования данных во всех строках используется один ключ. В этом случае для хранения ключа существует несколько вариантов:
В базе данных. Для хранения ключа может использоваться таблица ключей, принадлежащая специальному пользователю, который не является владельцем приложений. Джон написал простую функцию, которая всего лишь возвращает ключ в выходном параметре. Пользователи получают привилегии для выполнения этой процедуры, и никакие пользователи не получают каких-либо привилегий для доступа к таблице ключей. В этой функции имеется несколько проверок, обеспечивающих получение ключа только пользователями, которые имеют соответствующие привилегии. Эта функция - единственный источник для получения ключа, поэтому пользователей можно легко аутентифицировать и предоставлять им доступ к ключу. В файловой системе. Хранение ключа в базе данных защищает от большинства злоумышленников, но не от администраторов базы данных, которые могут иметь доступ к любой таблице. Кроме того, может быть очень сложно удостовериться в том, что пользователи, выполняющие запрос, действительно являются законными пользователями. Хранение ключа в файловой системе, к которой администратор базы данных не имеет доступа, например, на другом сервере, таком, как сервер приложений, может оказаться лучшей идеей. Тем не менее, это также означает, что если ключ пропадает из-за повреждения файловой системы, то зашифрованные данные пропадают навсегда. У пользователя. В третьем варианте, показывает Джон, можно разрешить пользователям хранить ключ, например, в карте памяти (мобильного устройства) или на клиентской машине. В этом случае никто кроме законных пользователей не сможет иметь доступ к уязвимым данным. Это особенно полезно в хранилищах данных, в которых зашифрованные данные регулярно посылаются пользователям, уже имеющим ключ. Если по пути данные будут похищены, конфиденциальная информацию будет по-прежнему защищена. Тем не менее, здесь самый высокий риск потери данных, поскольку пользователи чаще всего теряют ключи.
Джон предлагает использовать один ключ для всех записей с хранением его у пользователей для небольшого числа случаев, таких, как публикация итогового контента для различных пользователей, ранее получившим ключ.
Самый большой недостаток этого подхода - уязвимость ключа к воровству. Если ключ украден, все данные в базе данных поставлены под угрозу. Поэтому Джон предложил другой подход для защиты конфиденциальных данных в базах данных OLTP-систем. Такая база данных имеет таблицу ACCOUNT_MASTER, в которой хранится конфиденциальный элемент данных - имя владельца банковского счета (account holder). Столбец, содержащий это имя, ACC_NAME, должен быть зашифрован. Первичный ключ этой таблицы - ACCOUNT_NO. Таблица ACCOUNT_MASTER выглядит примерно так:
SQL> desc account_master
Name Null? Type ---------- -------- ------------ ACCOUNT_NO NOT NULL NUMBER ACC_NAME VARCHAR2(200) ACC_TYPE CHAR(1)
Джон предлагает использовать разные ключи для различных строк таблицы ACCOUNT_MASTER, что устраняет риск незащищенности данных на уровне всей базы данных, если ключ крадется. Он создает таблицу ACCOUNT_MASTER_ENC для хранения зашифрованных данных (имена владельцев счетов) и другую таблицу для хранения ключей, использованных для шифрования. Эти таблицы - ACCOUNT_MASTER_ENC и ACCOUNT_MASTER_KEYS - выглядят примерно так:
SQL> desc account_master_enc
Name Null? Type ------------ -------- -------- ACCOUNT_NO NOT NULL NUMBER ACC_NAME_ENC RAW(2000)
SQL> desc account_master_keys
Name Null? Type ---------- -------- --------- ACCOUNT_NO NOT NULL NUMBER KEY NOT NULL RAW(2000)
Затем Джон создает представление VW_ACCOUNT_MASTER, показанное на листинге 4, чтобы соединить эти три таблицы для получения расшифрованных данных. Он указывает на строку 8 листинга 4, в которой данные расшифровываются с помощью функции GET_DEC_VAL, рассмотренной выше. Эта функция возвращает данные типа VARCHAR2, поэтому они показываются как столбец VARCHAR2(2000); функция CAST в строке 7 преобразует их в данные типа VARCHAR2(20).
Это представление, не таблица, как раз есть то, что предоставляется для доступа другим пользователям. Джон создает публичный синоним ACCOUNT_MASTER, указывающий на представление VW_ACCCOUNT_MASTER, а не на таблицу с таким же именем как у синонима.
Листинг 4. Представление VW_ACCOUNT_MASTER
1 create or replace view 2 vw_account_master 3 as 4 select 5 m.account_no as account_no, 6 m.acc_type as acc_type, 7 cast ( 8 get_dec_val (e.acc_name_enc, k.key) 9 as varchar2(20)) as acc_name 10 from 11 account_master m, 12 account_master_enc e, 13 account_master_keys k 14 where 15 k.account_no = e.account_no 16* and m.account_no = e.account_no;
Публичный синоним ACCOUNT_MASTER указывает на это представление, поэтому пользователи могут извлекать из него данные. Но, спрашивает разработчик Джилл, как же пользователи смогут манипулировать данными в таблице ACCOUNT_MASTER? Используя триггер INSTEAD OF (см. листинг 5), поясняет Джон. Этот триггер модифицирует реальные таблицы, когда пользователи вставляют строки в представление или обновляют его.
Листинг 5. Триггер INSTEAD OF для представления
1 create or replace trigger io_vw_acc_master 2 instead of insert or update on 3 vw_account_master 4 for each row 5 declare 6 l_key raw(2000); 7 begin 8 if (inserting) then 9 l_key := dbms_crypto.randombytes (128); 10 insert into account_master 11 (account_no, acc_type, acc_name) 12 values 13 ( 14 :new.account_no, 15 :new.acc_type, 16 :new.acc_name 17 ); 18 insert into account_master_enc 19 (account_no, acc_name_enc) 20 values 21 ( 22 :new.account_no, 23 get_enc_val ( 24 :new.acc_name, 25 l_key ) 26 ); 27 insert into account_master_keys 28 (account_no, key) 29 values 30 ( 31 :new.account_no, 32 l_key 33 ); 34 else 35 select key 36 into l_key 37 from account_master_keys 38 where account_no = :new.account_no; 39 update account_master 40 set acc_name = :new.acc_name, 41 acc_type = :new.acc_type 42 where account_no = :new.account_no; 43 update account_master_enc 44 set acc_name_enc = 45 get_enc_val (:new.acc_name, l_key) 46 where account_no = :new.account_no; 47 end if; 48* end;
Пользователи не могут видеть данные непосредственно в таблицах, а только через представление, поэтому информация защищена. Чтобы показывать только зашифрованные данные, защищая исходное содержимое, можно создавать различные представления базовой таблицы.
Комплексное использование специальных и универсальных сообщений об ошибках
Гибкий механизм формирования информативных сообщений об ошибках для пользователя реализуется в несколько этапов (рис. 1):
Вывод специального сообщения об ошибке уровня приложения. Сначала программа выполняет поиск сообщения об ошибке среди специальных сообщений для данного приложения. Если такое сообщение найдено, оно выводится, и формирование сообщения на этом завершается. Вывод специального сообщения об ошибке уровня базы данных. Если на этапе 1 сообщение не было найдено, выполняется поиск специального сообщения об ошибке уровня базы данных. Если найдено, то оно выводится пользователю и формирование сообщения об ошибке на этом заканчивается. Вывод сообщения на основе анализа структуры базы данных (универсального сообщения). В случае, если на предыдущих этапах специальных сообщений не обнаружено, то оно формируется на основе анализа структуры базы данных. Оно выводится пользователю и на этом формирование сообщения завершается. Вывод сообщения от сервера базы данных. В случае, если на трех предыдущих этапах сообщение для пользователя не было сформировано, то отображается сообщение об ошибке от Oracle. Такая ситуация может возникнуть по нескольким причинам. Например, при возникновении пользовательской ошибки, которая была преднамеренно сгенерирована в хранимой процедуре или триггере c помощью функции RAISE_APPLICATION_ERROR, и изменение содержания сообщения о которой не требуется.
Возможны более сложные случаи, чем приведенный в этой статье. Например, если сообщение формируется в хранимой процедуре, которая в свою очередь может вызываться из триггера или другой хранимой процедуры. В этом случае может потребоваться так же информация, о том как вызывалась процедура, формирующая сообщение об ошибке. И поэтому исходное сообщение может быть дополнено или изменено, например, на основе информации о стеке вызова хранимых процедур и триггеров.
В ряде случаев такие сообщения могут быть даже более информативными, чем сформированные на предыдущих этапах. Например, вместо ограничения CK_PRICE для таблицы DEMO.GOODS (скрипт 1.1) можно в триггере перед вставкой и обновлением записи выполнять необходимую проверку и генерировать сообщение для пользователя в уже “готовом” виде:
CREATE OR REPLACE TRIGGER DEMO. TRIGGER_GOODS BEFORE INSERT OR UPDATE OF PRICE ON DEMO.GOODS FOR EACH ROW BEGIN IF :NEW.PRICE <= 0 THEN RAISE_APPLICATION_ERROR(-20001, 'Цена товара "' :NEW.TITLE ' " должна быть больше 0 руб (указана цена ' :NEW.PRICE ' руб)'); END IF; END TRIGGER_GOODS;
В случае цены товара меньшей или равной нулю сервер сгенерирует ошибку, например: ORA-20001: Цена товара "Лейка" должна быть больше 0 руб (указана цена 0 руб)
Клиентское приложение может сразу передать это сообщение пользователю без изменения.
Другой причиной может быть появление ошибки, для которой формирование сообщения не предусмотрено.

Рис. 1. Последовательность формирования сообщения об ошибке базы данных.
Хочется обратить внимание, что даже если в приложении используются только специальные сообщения об ошибках, то использование общей функции для формирования сообщений позволит улучшить структуру программы. При необходимости формат специальных сообщений может иметь поддержку ссылок на справочную систему, рисунки и т.д. Описываемый метод формирования сообщений об ошибках базы данных ориентирован в большей степени на реализацию в клиентском приложении. В то же время он может использоваться на стороне сервера в хранимых процедурах, триггерах таблиц, а так же в системных триггерах для события SERVERERROR базы данных или схемы.
Литература
В.Н. Лихачёв «Общий метод формирования сообщений об ошибках при работе с базами данных и его использование для БД Firebird» // RSDN Magazine. - 2008. -№ 4. () В.Н. Лихачёв «Локализация ошибок в приложениях Delphi c помощью библиотеки Jedi Code Library» // RSDN Magazine. - 2005. - № 3. - C. 23-27. ()
Нарушена уникальность значения поля или набора столбцов
Необходимость ввода уникального значения столбца может требоваться в основном в трех случаях:
столбец входит в главный ключ; столбец включен в уникальный ключ; столбец входит в уникальный индекс.
Во всех трех случаях Oracle Database генерирует одну и ту же ошибку: ORA-00001: нарушено ограничение уникальности (<Схема>.<Ограничение>)
В сообщении об ошибке указывается ограничение, которое вызвало ошибку. Для получения информации о столбцах, входящих в главный или уникальный ключи, можно использовать запрос 3.1, для получения информации об индексе - запрос 3.2. select dcs.constraint_type, cc.table_name, tc.comments astable_comment, cc.column_name, ccom.comments as column_comment
from all_cons_columns cc join all_tab_comments tc on (tc.owner = cc.owner and tc.table_name = cc.table_name) join all_col_comments ccom on (ccom.owner = cc.owner and ccom.table_name = cc.table_name and ccom.column_name = cc.column_name ) join all_constraints dcs on (dcs.constraint_name = cc.constraint_name)
where cc.owner = :owner and cc.constraint_name = :key_name
Запрос 3.1. Получение информации о столбцах таблицы, входящих в главный или уникальный ключи.
select ic.table_name, tc.comments astable_comment, ic.column_name, ccom.comments ascolumn_comment from all_ind_columns ic join all_tab_comments tc on (tc.owner = ic.table_owner and tc.table_name = ic.table_name) join all_col_comments ccom on (ccom.owner = ic.table_owner and ccom.table_name = ic.table_name and ccom.column_name = ic.column_name ) where table_owner = :owner and index_name = :index_name
Запрос 3.2. Получение информации о столбцах таблицы, входящих в индекс.
В качестве параметров запросам передаётся имя схемы (“owner“), имя ключа (“key_name“) или индекса (“index_name“). Запросы возвращают имена и комментарии для таблиц и столбцов, входящих в ограничение. Запрос 3.1 возвращает так же тип ограничения (“constraint_type”): “P” – главный ключ, “U” – уникальный ключ. Количество записей, возвращаемых запросами, соответствует количеству столбцов в ограничении уникальности.
На основе полученной информации об ограничении уникальности для пользователя могут быть сформированы варианты сообщений об ошибке, например, приведенные в разделе 1.
Не указано значение поля, обязательного для заполнения (ограничение NOT NULL)
Эта ошибка генерируется сервером в нескольких случаях:
нарушено ограничение “not null”, установленное для столбца; не указано значение столбца, входящего в уникальный индекс, главный или уникальный ключи.
Во всех этих случаях сервер генерирует ошибку: ORA-01400: невозможно <вставить/заменить> NULL в ("<Схема>"."<Таблица>"."<Столбец>")
Для получения описания таблицы и столбца из сообщения об ошибке, можно использовать запрос 2.1. select tc.comments astable_comment, cc.comments ascolumn_comment from all_tab_columns c, all_tab_comments tc, all_col_comments cc where c.owner = :owner and c.table_name = :table_name and c.column_name = :column_name and tc.owner = c.owner and tc.table_name = c.table_name and cc.owner = c.owner and cc.table_name = c.table_name and cc.column_name = c.column_name
Запрос 2.1. Получение описания таблицы и столбца
В качестве параметров запроса “owner”, ”table_name”, ”column_name” необходимо указать соответственно имя схемы, таблицы и столбца из сообщения об ошибке. Запрос возвращает комментарии для таблицы и столбца.
Используя результаты этого запроса, может быть сформировано сообщение об ошибке, например, следующего содержания:
Необходимо указать значение столбца “<Описание поля>” в таблице “<Описание таблицы>” при <добавлении новой/изменении> записи.
Ошибки, вызываемые ограничениями внешних ключей
При выполнении операций над табличными данными, связанными внешними ключами, можно выделить несколько причин, приводящих к возникновению ошибок:
В подчинённую таблицу добавляется запись, в которой для столбца, входящего во внешний ключ, нет соответствующего значения в главной таблице. Аналогичная ситуация происходит при изменении значения столбца подчиненной таблицы в случае, если нового значения столбца нет в главной таблице. Oracle Database в этом случае генерирует ошибку: ORA-02291: нарушено ограничение целостности (<Схема>.<Внешний ключ>) - исходный ключ не найден
В главной таблице выполняется попытка изменения значения столбца, на которое имеется ссылка в подчиненной таблице. Для этого случая Oracle Database генерирует ошибку: ORA-02292: нарушено ограничение целостности (<Схема>.<Внешний ключ>) - обнаружена порожденная запись
В главной таблице выполняется попытка удаления данных, на которые имеется ссылка в подчиненной таблице. Если в определении связи между таблицами указано ограничение “NO ACTION” для операции удаления данных, то Oracle не позволяет удалять данные из главной таблицы, если в подчинённой таблице есть записи связанные с удаляемой записью. Для этой ситуации Oracle Database генерирует ошибку, аналогичную предыдущему случаю.
Для получения информации о столбцах главной и подчиненной таблиц, входящих во внешний ключ, можно использовать приведенный ниже запрос 4.1. select a.constraint_name, a.table_name, tc1.comments astable_comment, a2.column_name, cc1.comments ascolumn_comment, b.owner asr_owner, b.table_name asr_table_name, tc2.comments asr_table_comment, b2.column_name asr_column_name, cc2.comments asr_column_comment from all_constraints a, all_constraints b, all_cons_columns a2, all_cons_columns b2, all_tab_comments tc1, all_col_comments cc1, all_tab_comments tc2, all_col_comments cc2 where a.owner = :owner and a.constraint_type = 'R' and a.constraint_name = :foreign_key and b.constraint_type in ('P','U') and b.constraint_name = a.r_constraint_name and b.owner = a.r_owner and a2.constraint_name = a.constraint_name and a2.table_name = a.table_name and a2.owner = a.owner and b2.constraint_name = b.constraint_name and b2.table_name = b.table_name and b2.owner = b.owner and b2.position = a2.position and tc1.owner = a.owner and tc1.table_name = a.table_name and cc1.owner = a2.owner and cc1.table_name = a2.table_name and cc1.column_name = a2.column_name and tc2.owner = b.owner and tc2.table_name = b.table_name and cc2.owner = b2.owner and cc2.table_name = b2.table_name and cc2.column_name = b2.column_name
Запрос 4.1. Получение информации о внешнем ключе.
Запрос имеет два параметра: “owner” и “foreign_key” – схема и внешний ключ, о котором необходимо получить информацию. Он возвращает информацию о столбцах, входящих во внешний ключ: "table_name", "table_comment" - имя и описание подчиненной таблицы; "column_name", "column_comment" - имя и описание столбца подчиненной таблицы. Столбцы запроса с префиксом “r_” возвращают информацию о главной таблице. Количество записей возвращаемых запросом соответствует количеству столбцов, входящих во внешний ключ.
На основе этой информации могут быть сформированы сообщения об ошибках внешних ключей для пользователя.
Особенности обработки ошибок сервера базы данных Oracle
К.п.н. Владимир Лихачёв, Калужский педагогический университет им К.Э.Циолковского.
Oracle Magazine - Русское издание
Сообщения об ошибках ограничений CHECK для таблиц
При возникновении ошибки, вызванной ограничением CHECK для таблицы, сервер генерирует ошибку: ORA-02290: нарушено ограничение целостности CHECK (<Схема>.<Имя ограничения>)
Как уже говорилось выше, для таких ошибок часто удобно использовать специальные сообщения. Например, для ограничения "CK_PRICE" таблицы “GOODS” может использоваться специальное сообщение, хранимое в таблице специальных сообщений: Цена товара в справочнике “Товары” должна быть больше нуля.
Специальные сообщения об ошибках, вызванных ограничениями БД
Необходимость использования специальных сообщений может возникнуть в случае, если универсальное сообщение об ошибке по каким-то причинам не может использоваться или не может быть сформировано. Примером последнего случая являются ограничения CHECK для таблиц. В условиях ограничений могут использоваться запросы и условия, анализ которых может оказаться довольно сложной задачей. Поэтому для этих ограничений часто удобнее использовать сообщения, которые определяются на этапе разработки.
Можно выделить две группы специальных сообщений об ошибках. Первый тип специальных сообщений предназначен для использования во всех приложениях, которые работают c общей базой данных. Их можно условно назвать “специальные сообщения об ошибках уровня базы данных”. Вторая группа сообщений специфична для конкретного приложения. Они могут быть необходимы, когда различные приложения должны выдавать пользователю различные сообщения об одной и той же ошибке. Их можно условно назвать “специальные сообщения об ошибках уровня приложения”. Информацию о первой группе сообщений удобно хранить в самой базе данных и использовать для этого отдельную таблицу. Сообщения, специфичные для программы могут храниться в её ресурсах, например, в виде отдельного файла или также в БД. Идентификация специальных сообщений может выполняться на основе кода ошибки, имени схемы и одного или нескольких ключевых слов из сообщения об ошибке.
Универсальные сообщения об ошибках, вызванных ограничениями БД
Как уже говорилось выше, основная идея создания универсальных сообщений заключается в том, чтобы на основе данных из сообщения об ошибке от Oracle и о структуре базы данных сформировать достаточно информативное и понятное для конечного пользователя сообщение. Предположим, в таблицу “GOODS” (скрипт 1.1) пользователь пытается добавить товар с названием (столбец “TITLE”), которое уже имеется в таблице.
CREATE TABLE DEMO.GOODS ( CODE INTEGER NOT NULL , TITLE VARCHAR2(50 byte) NOT NULL , PRICE NUMBER(16, 2) NOT NULL , CONSTRAINT CK_PRICE CHECK (PRICE > 0), CONSTRAINT PK_GOODS PRIMARY KEY(CODE)); COMMENT ON TABLE DEMO.GOODS is 'Товары'; COMMENT ON COLUMN DEMO.GOODS.CODE is 'Код товара'; COMMENT ON COLUMN DEMO.GOODS.TITLE is 'Название'; COMMENT ON COLUMN DEMO.GOODS.PRICE is 'Цена';
CREATE UNIQUE INDEX DEMO.IDX_GOODS_TITLE ON DEMO.GOODS (TITLE);
Скрипт 1.1. Создание таблицы “GOODS”.
Сервер в этом случае сгенерирует ошибку, так как столбец “TITLE”, в котором хранится название товара, включено в уникальный индекс “DEMO.IDX_GOODS_TITLE”: ORA-00001: нарушено ограничение уникальности (DEMO.IDX_GOODS_TITLE)
Вместо этого сообщения для пользователя может быть сформировано, например, одно из сообщений: Значение поля “Название” в таблице “Товары” должно быть уникальным! Товар с таким названием уже зарегистрирован! Проверьте название товара! В справочнике товаров не могут быть товары с одинаковыми названиями!
Хотя эти сообщения и различаются, но в них всех указывается информация об объекте, для которого нарушено ограничение уникальности – это поле “Название” таблицы “Товары”.
Одна из проблем формирования такого типа сообщений, заключается в том, что пользовательские названия полей и таблиц, отличаются от имен таблиц и столбцов в базе данных. Чтобы пользователю было понятно сообщение об ошибке, в нем должны использоваться именно пользовательские названия. Для сопоставления имен таблиц и полей и их пользовательских названий может использоваться отдельная таблица или комментарии для таблиц и столбцов. Последний вариант можно считать более предпочтительным, так как это позволяет одновременно документировать базу данных. Именно поэтому в скрипте 1.1 в качестве комментариев для таблицы и её столбцов приведены их пользовательские названия. Если сравнить выше приведённые сообщения и комментарии для таблицы и столбцов, то можно заметить, что формирование первого сообщения является наиболее простым вариантом. Для формирования двух других сообщений может потребоваться лексический синтез, но это уже отдельная задача. Хочется обратить внимание, что в дальнейшем в статье приводится только один из возможных вариантов сообщения для каждого случая ошибки. На практике выбор стиля сообщения и его содержания может зависеть от целого ряда факторов и будет определяться разработчиком системы.
Конечно, нельзя исключать ситуацию, когда для таблицы или столбца отсутствуют комментарии, которые должны быть указаны в сообщении. В этой ситуации в сообщении об ошибке возможно отображение непосредственно имени таблицы или столбца.
Далее рассматривается формирование универсальных сообщений для наиболее часто встречающихся ошибок, обусловленных ограничениями БД.
с базами данных, важным является

Для программ, работающих с базами данных, важным является не только корректность обработки их ошибок, но и формирование информативных сообщений об этих ошибках. Наличие таких сообщений позволяет быстрее выявлять причины и исправлять ошибки. Особенно это актуально при работе с программой конечного пользователя, так как ему в большинстве случаев не известна не только структура конкретной БД, но и теоретические основы реляционных баз данных.
Как ни странно, ситуация с формированием сообщений об ошибках в программах довольно часто сильно отличается от обработки самих ошибок. При обработке ошибок обычно удается выработать общую стратегию, что позволяет локализовать их обработку в одной или нескольких функциях. Аналогичный подход для сообщений об ошибках может быть реализован на основе того, что в сообщении об ошибке сервер Oracle указывает тип ошибки и объект базы данных, который явился причиной её возникновения. Такими объектами обычно являются ограничения, как, например, первичные, уникальные и внешние ключи, уникальные индексы, ограничения “not null” и др. Из системных таблиц и представлений базы данных может быть получена подробная информация об этих ограничениях и определены значения, изменение которых и привело к возникновению ошибки. Но проблема заключается в том, что реализация такого механизма формирования сообщений об ошибках в реальных приложениях встречает целый ряд сложностей: Зависимость сообщения об ошибке от назначения программы. Даже для программ, работающих с одной и той же базой данных, может потребоваться формирование различных сообщений об одной и той же ошибке. Например, в программе для редактирования данных пользователем сообщение должно быть: “Товар с таким названием уже зарегистрирован! Проверьте название товара!”. А в программе импорта данных требуется сообщение с совершенно другим содержанием: “Импортируемые данные дублируются – проверьте дату, за которую выполняется импорт данных!”. Сложность формирования сообщений для некоторых ошибок, вызванных ограничениями базы данных. Например, в ограничениях CHECK для таблиц могут использоваться довольно сложные запросы и условия. Поэтому формирование сообщений на основе их анализа может оказаться довольно сложной задачей. Использование в клиентских программах пользовательских названий таблиц и столбцов, отличных от их имен в БД. Например, таблица имеет имя “GOODS”, а в клиентском приложении данные этой таблицы могут отображаться в справочнике как “Товары” или “Продукция”.
Совокупность этих факторов обычно приводит к тому, что формирование сообщений даже об однотипных ошибках реализуется индивидуально для каждой транзакции. В результате код для формирования сообщений об ошибках оказывается распределенным по всему приложению, что усложняет его сопровождение. Из-за необходимости написания кода практически для каждой возможной ошибки, часть ошибок, о которых известно разработчику, оказываются без соответствующих сообщений для пользователя. В результате достаточно информативные сообщения для конечного пользователя формируются только для некоторой части ошибок, в остальных же случаях ему остается довольствоваться в лучшем случае сообщениями от самого сервера базы данных. Информативность таких сообщений для обычного пользователя в большинстве случаев недостаточна для выявления причины возникшей проблемы и её устранения.
Рассматриваемый в статье метод формирования информативных сообщений об ошибках для пользователя является довольно универсальным, может быть реализован как в клиентских приложениях, так и на стороне сервера Oracle. Он может использоваться в различных типах программ, как, например:
Программы, использующие специальный интерфейс для ввода и изменения данных БД. В большинстве случаев информативные сообщения об ошибках могут быть получены на основе анализа структуры базы данных. Это позволит информировать пользователя об их причине с минимальными затратами усилий со стороны разработчиков и программного обеспечения. Программы с возможностью построения пользователем произвольных SQL-запросов. Формирование сообщений на основе анализа структуры базы данных может быть особенно актуально для программ, которые ориентированы на широкий круг пользователей, в том числе и с низким уровнем знаний в этой области. Это позволит сделать более понятными для пользователя сообщения об ошибках в SQL-запросах. Предметные платформы. Использование методов, описанных в статье, позволит самой предметной платформе формировать информативные сообщения об ошибках базы данных на основе анализа её структуры. Это даст возможность сократить код на языке платформы, используемый для обработки ошибочных ситуаций. А ошибки, которые требуют специальных сообщений, но оказались без таковых, будут достаточно информативными для того, чтобы намного упростить выявление их причины.
Описанные выше проблемы формирования сообщений могут быть решены, если сообщения об ошибках условно разделить на две группы:
универсальные сообщения, которые формируются на основе анализа структуры базы данных; специальные сообщения, которые определяются индивидуально для каждой ошибки.
Описываемый в статье метод формирования сообщений об ошибках БД может быть применён для многих серверов реляционных баз данных. Пример его использования для баз данных сервера Firebird рассматривается в статье [1]. Если клиентское приложение разработано на Object Pascal (Delphi, Kylix, Free Pascal), то для выявления причин непредвиденных ошибок могут быть полезны возможности библиотеки JEDI [2].
Целью данной статьи является показать
Целью данной статьи является показать основные идеи метода, который может использоваться для формирования информативных сообщений об ошибках базы данных Oracle для конечного пользователя. Хотя за рамками статьи остались некоторые моменты реализации, хочется надеяться, что описанный в статье подход позволит уменьшить трудозатраты при разработке программного обеспечения, повысить его надежность и качество.
Архитектура HP Oracle Exadata Storage Server в составе HP Oracle Database Machine
В конце сентября 2008 г. Oracle анонсировала 2 программно-аппаратных решения: HP Oracle Exadata Storage Server, позиционируемый как интеллектуальное устройство хранения для реляционных баз данных, и HP Oracle Database Machine — оптимизированное прединсталлированное преконфигурированное DW на базе кластера Oracle Database с Real Application Clusters (RAC) и HP Oracle Exadata Storage Server. Хотя HP Oracle Exadata Storage Server и представляется как самостоятельное решение, оно не продается отдельно и поставляется только в составе HP Oracle Database Machine. Эти решения полностью реализованы на продуктах HP, изготавливаются и собираются на заводах HP по заказу Oracle. В настоящее время эти решения продвигаются и сопровождаются Oracle или ее сертифицированными партнерами.

Рис. 4. Архитектура HP Oracle Database Machine.
HP Oracle Exadata Storage Server работает только в составе HP Oracle Database Machine, начиная с версии Oracle Database 11g, Release 11.1.0.7. HP Oracle Exadata Storage Server призван заменить внешние дисковые массивы (SAN/NAS) и, самое главное, значительно повысить производительность обработки запросов в многотерабайтньгх В1-хранилищах.
Поставляется две версии HP Oracle Database Machine — полная и "половинчатая", соответственно, стандартная 42U стойка или ее половина.
Общая архитектура HP Oracle Database Machine представлена на рис. 4. В ней один или множество (для RAC) серверов БД соединяются через Infiniband-коммутаторы с HP Oracle Exadata Storage Server.
В полной комплектации HP Oracle Database Machine содержит:
8 DL360 Oracle Database серверов (2 quad-core Intel Xeon, 32GB RAM) с установленными Oracle Enterprise Linux и Oracle RAC; 14 Exadata Storage Cells с дисками SAS или SATA, соответственно, допуская масштабирование до 21 Тбайт и 46 Тбайт некомпрессионных пользовательских данных; 4 InfiniBand-коммутатора по 24 порта; оборудование для управления (1 Gigabit Ethernet-коммутатор, Keyboard, Video, Mouse (KVM) hardware).
Каждый HP Exadata Storage Server имеет потоковую производительность до 1 Гбайт/c и реализован на базе сервера HP DL180 G5 (2 Intel quad-core processors, 8 Гбайт RAM, Dual-port 4X DDR InfiniBand card, 12 SAS- или SATA-дисков). Он поставляется со следующим установленным ПО: Oracle Exadata Storage Server Software, Oracle Enterprise Linux, HP Management Software (рис. 5).
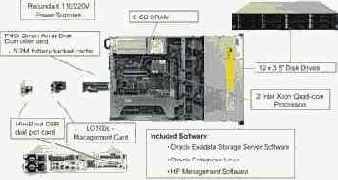
Рис. 5. Конструктивная реализация отдельной ячейки HP Exadata Storage Server.
Доступность данных на ячейках Exadata поддерживается за счет зеркалирования данных c помощью ПО Automatic Storage Management (ASM) и возможности горячей замены отдельных дисков. Зеркалирование данных отдельной ячейки на множестве других гарантирует, что отказ ячейки не будет вызывать потерю данных или снижать их доступность.
Каких-либо ограничений по масштабированию (по заявлениям Oracle) HP Oracle Exadata Storage Server не существует, поэтому приобретая дополнительные стойки Exadata, можно в онлайновом режиме объединять их в общее консолидированное хранилище.
В настоящее время поставки осуществляются только в виде двух вышеуказанных базовых конфигураций.
Где целесообразно использовать HP Oracle Exadata Storage Server?
HP Exadata Storage Server ориентирован, прежде всего, на работу с приложениями, которым приходится обрабатывать таблицы БД размером от сотен мегабайт до нескольких терабайт, и где часто необходимо выполнять полное сканирование таблиц. В качестве классических примеров можно назвать BI-системы, отчетные системы и им подобные. Транзакционные системы, имеющую высокую интенсивность по чтению/записи большого количества файлов размером до нескольких мегабайт и несколько больше преимуществ при работе с Exadata не получат или это будет не настолько эффективно как в первом случае.
Однако это не означает, что для разных классов приложений или групп пользователей требуется создание разных физических хранилищ данных. Exadata позволяет смешивать и приоритезировать различные нагрузки как между различными группами/классами пользователей/приложений внутри одной базы, так и между базами данных, гарантируя при этом заданный (в соответствии с SLA) уровень выделения ресурсов ввода/вывода (рис. 6). Например: БД "A" — 30% IO-ресурсов; БД "B" — 20% IO-ресурсов; БД "C" — 50% IO-ресурсов. для БД "А" — 60% IO-ресурсов для отчетов и 40% — для ETL-задач; для БД "В" — 30% IO-ресурсов для интерактивных задач и 70% — для пакетных задач.
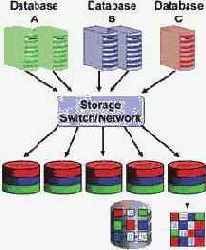
Рис. 6. HP Exadata Storage Server поддерживает гарантированное распределение IO-ресурсов как между БД, так и группами пользователей/приложений.
За счет чего достигается основное преимущество при использовании HP Exadata Storage Server?
Необходимо сразу отметить, что за счет устанавливаемого специализированного ПО каждая ячейка "понимает" структуру таблицы. Само повышение производительности при работе с таблицами большого размера происходит за счет двух факторов. Во-первых, при записи таблицы на HP Exadata Storage Server она равномерно "размазывается" на все ячейки — все серверы HP Exadata Storage Server. Поэтому при обработке запроса происходит его распараллеливание между всеми ячейками и, соответственно, чем и их больше, тем больше коэффициент параллелизма. Однако даже при наличии только одной ячейки эффект повышения производительности может быть многократным — это второй фактор. Это связано с тем, что за счет того, что сервер (ячейка) Exadata понимает структуру таблицы, при обработке запроса она не просто отсылает серверу БД часть таблицы (которая хранится на данной ячейки), а производит его обработку. Т.е. при использовании Oracle Exadata, обработка SQL перемещается с сервера базы данных к Oracle Exadata Storage Server. Oracle Exadata самостоятельно выполняет функцию отгрузки данных в дополнение к обеспечению традиционных блоковых сервисов к базе данных. Одна из уникальных вещей, которые Exadata-хранение делает по сравнению с традиционным хранением — возвращение только строк и столбцов, которые удовлетворяют запрос к базе данных, а не полную таблицу, как обычно делалось. Exadata выполняет SQL-запрос, максимально оптимизируя его для аппаратных средств, добиваясь максимального параллелизма работы дисков. В целом, это уменьшает загрузку центрального процессора на сервере базы данных, уменьшает требуемую полосу пропускания при перемещении данных между серверами базы данных и серверами хранения, обеспечивает балансировку нагрузки на ячейках Exadata.
Процесс фильтрации данных (в английской терминологии этот процесс еще называют Predicate Offload или Smart Scan), т.е. как именно Exadata возвращает меньше данных, чем обычный дисковый массив, является одним из ключевых преимуществ Exadata. Вот как описывает его более подробно в своем блоге Дмитрий Волков (менеджер по развитию бизнеса, Oracle).
Оптимизатор может использовать режим обращения Predicate Offload только, если запрос использует Direct Read Full table scan и таблица расположена на дисковой группе, которая состоит из дисков Exadata. Обычно, Direct Read производится, используя Parallel Query. В Parallel Query один процесс выполняет роль координатора, другие (PQ slaves) выполняют собственно чтение. PQ slave, определяет фильтр и набор записей, который ему нужно прочитать. Если это возможно, вместо кода чтения direct path вызывается код взаимодействия с Exadata (речь идет о kernel code path). Этот код, с помощью ASM, переводит имена сегментов в диски, смещения, необходимый объем для чтения. Дальше открывается специальный поток, в котором эти данные передаются на Exadata. Если у нас несколько cell, это также легко определить с помощью метаданных ASM. Таким образом, правильный набор команд посылается нужному cell.
Процесс CELLSRV на стороне Exadata, получает поток команд на чтение и необходимый фильтр. Далее с помощью библиотеки из состава ядра Oracle он выполняет необходимую фильтрацию и возвращает результат. Результат — это только необходимые нам записи и колонки.
Ячейкам Exadata (cell) нет необходимости общаться между собой в момент выполнения запроса. Каждая ячейка получает нужную ей команду.
Поскольку речь идет о Direct Path Read, нет проблемы c read consistency. Перед началом Direct Path Read всегда выполняется tablespace checkpoint object-checkpoint, т.е. сброс грязных блоков этого объекта.
DW на основе Exadata полностью прозрачно для приложений и не требует никакой модификации SQL-инструкций. При поставках HP Oracle Database Machine каких-либо модификаций приложения в целом также не требуется. Exadata одинаково хорошо работает как с единственным образцом (single-instance) Oracle БД, так и с Oracle БД, развернутой на Real Application Clusters. Функциональные возможности и управление такими инструментами БД, как: Data Guard, Recovery Manager (RMAN), Streams и др. те же самые, как с Exadata, так и без нее.
Развернутое покомпонентное представление архитектуры HP Oracle Database Machine дано на рис. 7.
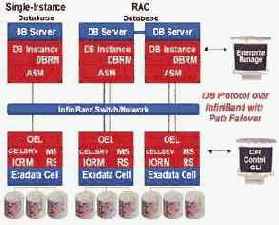
Рис. 7. Покомпонентное представление архитектуры HP Oracle Database Machine.
Сервер БД и Exadata Storage Server Software взаимодействуют, используя протокол iDB — Intelligent Database protocol. iDB реализован в ядре базы данных и прозрачно отображает операции базы данных к расширенным операциям Exadata. iDB используется, чтобы отправить SQL-операции к Exadata-ячейкам для выполнения и возвратить результат запроса к базе данных.
iDB построен на промышленном стандарте — Reliable Datagram Sockets (RDSv3) протоколе и работает на транспорте InfiniBand. ZDP (Zero-loss Zero-copy Datagram Protocol) и zero-copy имплементации RDS используются, чтобы устранить ненужное копирование блоков.
HP Oracle Exadata Storage Server — оптимизированная платформа для Oracle BI-хранилищ данных
Источник: Журнал «Storage News».
Публикуется с разрешения компании Oracle.
В конце сентября 2008 г. HP и Oracle анонсировали совместную разработку — HP Oracle Database Machine — специализированную платформу для хранилищ данных (data warehouse — DW) на базе Oracle 11.0.7, позволяющую от 10 до 70 раз и более повысить скорость обработки запросов в сравнении с реализациями DW на самых мощных традиционных компонентах серверов и систем хранения.
Тенденции в бизнесе
Почему возрастает интерес к BI-решениям — и не только у крупных компаний? Прежде всего, из-за постоянно возрастающих требований к современному бизнесу и изменения его "характера": в частности, все большая его онлайновость, географическая распределенность, персонификация, зависимость от многочисленных быстро меняющихся факторов требуют одновременно и все большей его интеллектуализации с точки зрения обеспечения понимания общих бизнес-процессов.

Рис. 1. Самые большие в мире хранилища данных утраиваются в размере каждые два года, начиная с 1999 г.
Растущая сложность бизнеса связана, во-первых, с резко возросшим потоком информации/данных, который необходимо обрабатывать/пропускать для принятия правильных и своевременных решений на всех уровнях ведения бизнеса и госуправления. Так, например, согласно WinterCorp TopTen программе, самые большие в мире хранилища данных утраиваются в размере каждые два года, начиная с 1999 г. (рис. 1). Эволюция поддержки сверхбольших хранилищ данных на базе Oracle представлена на рис. 2. Во-вторых, — со значительно возросшими требованиями к быстроте (или буквально "на лету") принимаемых решений, для чего прежде использовалась многочасовая или многодневная пакетная обработка.
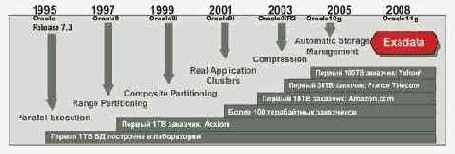
Рис. 2. Эволюция поддержки сверхбольших хранилищ данных.
Другие исследования показывают, что при реализации хранилищ данных на основе традиционных систем хранения экспоненциальный рост времени ответа в зависимости от типа системы хранения может наблюдаться уже при размере DW от нескольких терабайт (рис. 3).
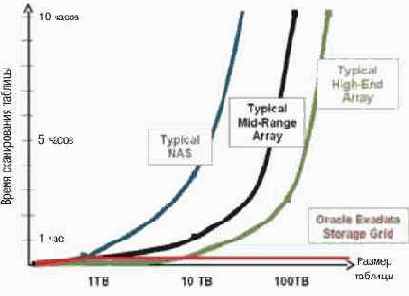
Рис. 3. Время доступа к таблице хранилища данных в зависимости от типа системы хранения, на которой оно реализовано, и размера таблицы.
Эта проблема связана с тем, что существующие реализации хранилищ данных часто имеют проблему "бутылочного горлышка", ограничивающего передачу данных с дисковой системы, на которой физически хранится БД, на серверы БД. Оценки показывают, что каналы между системами хранения и серверами БД от 10 до 100 раз медленнее того, что требуется при передаче данных огромных объемов.
При реализации HP Oracle Database Machine эта проблема решалась тремя способами:
передачей по каналам меньшего объема данных; добавлением числа каналов; расширением полосы пропускания каналов.
Тестирование производительности HP Oracle Database Machine
Тестирование HP Oracle Database Machine на улучшение скорости обработки запросов в сравнении с реализациями на традиционных компонентах корпоративного класса показало улучшение времени обработки от 10 до 100 раз. Это подтверждают как ряд западных компаний, проводивших тестирование, так и независимые агентства, например, Winter Corp.
Тестирование (рис. 8) HP Oracle Database Machine в телекоммуникационной компании — M-Tel, по словам руководителя администрирования БД (Plamen Zyumbyulev), показало, что "каждый запрос выполняется быстрее на Exadata по сравнению с существующими системами. Минимальное улучшение производительности было в 10 раз, а самое большое — в немыслимые 72 раза."

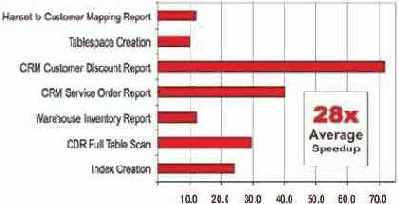
Рис. 8. Ускорение операций при обращении к DW в зависимости от типа DW (компания розничной торговли — вверху, телеком-компания — внизу) может достигать от 3—50 до 10—72 раз соответственно.
Другой пример — компания розничной торговли CME Group (USA, Chicago). Как заявил директор ее подразделения Enterprise Database Systems, "Oracle Exadata на сегодняшний день превосходит по результатам все, что мы тестировали ранее, от 10 до 15 раз." (см. рис. 8).
Вместо заключения
Интерес к рынку специализированных аппаратно-программных решений для DW в последние годы резко вырос. Это связано не только с возрастающими значимостью BI-систем и, соответственно, требованиями к ним по скорости обработки запросов, но и с их имплементацией и дальнейшим масштабированием.
В соответствии с проведенными несколько лет назад исследованиями, в среднем, более 50% проектов по созданию хранилищ данных терпят неудачу из-за того, что от 60% до 80% средств тратится на "чистку" и объединение данных от наследуемых систем, а управление данными и интеграция являются главными технологическими причинами, из-за которых CRM-проекты не оправдывают ожидания.
Некоторые компании, добиваясь успеха на ранних стадиях имплементации DW, не смогли его сохранить при дальнейшем масштабировании BI-проекта. Это явилось следствием значительных трудностей, возникших из-за: 1) возрастания сложности хранилища данных или недостаточной его производительности при высокой интенсивности запросов, или при высоких размерностях таблиц баз данных хранилищ; 2) невозможности поддерживать актуальную версию хранилища.
В этом контексте появление решения HP Oracle Database Machine, позволяющего прозрачно для пользователей Oracle DW мигрировать на новые технологии с возможностью дальнейшего беспроблемного масштабирования DW имеет большое значение.
Ряд storage-вендоров также проявили интерес к сектору DW специализированных хранилищ. В частности, в декабре прошлого года ЕМС заявила об открытии экспертного центра по аналитическим системам и хранилищам данных, основной задачей которого станет совместная разработка специализированных прикладных решений инженерами EMC и специалистами ведущих разработчиков систем и хранилищ данных, включая Greenplum, IBM, Microsoft, Netezza, Oracle, ParAccel, Sybase, Teradata и Vertica.
Microsoft приобрела Datallegro и, как ожидается, уже в течение года представит свое MPP DBMS (massively parallel processing database management system) развертывание SQL-сервера для больших DW.
Заметно вырос интерес к BI-решениям и в России. По данным IDC, этот сектор — один из самых быстрорастущих с ежегодным ростом 30%. Одна из главных причин столь высоких темпов роста — переход крупных компаний, внедривших интегрированные системы управления предприятием, в следующую фазу автоматизации бизнес-процессов. В условиях глобализации экономики бизнес-аналитика становится необходимым инструментом поддержания конкурентоспособности компаний. Немалую роль играет и растущий интерес к BI-технологиям со стороны среднего бизнеса.
BI становится востребованным по мере того, как все большее количество менеджеров убеждается в преимуществах наличия подручных инструментов, помогающих принятию решений. BI-системы поддерживают процессы управления эффективностью компании, предоставляя оперативный анализ соотношения плановых и текущих показателей и быстро выявляя "проблемные" зоны в бизнесе.
Интересные результаты опроса, проведенного среди участников прошлогоднего IDC CEMA BI Roadshow 2007, привел в своем выступлении Робер Фариш (Robert Farish Vice President, Regional Managing Director, CIS, IDC). На вопрос, "какие функции вы планируете добавить к вашим БА инструментам в течение следующих 12 месяцев", 54% опрашиваемых ответили: "в хранение данных" — самый высокий приоритет (за ним идут: "сбор данных" — 45%, "BPM" — 37%, "панели информации" — 33%, "ETL" — 32% и др.).

Oracle Database Machine является очень интересным решением для систем анализа данных. Это не прорыв технологий, но профессиональное, продуманное, архитектурно-сбалансированное программно-аппаратное решение, направленое на устранение проблемных мест, которое обеспечивает фантастическое увеличение производительности на специфичных запросах BI-систем, отчетных систем и хранилищ данных. Решение не только открывает новые горизонты объемов информации, которыми можно оперировать в аналитических задачах. Оно также позволяет повысить утилизацию вычислительной мощности непосредственно самих дисковых систем, используя эту мощность для предварительного агрегирования информации на уровне отдельной дисковой полки.
Как видно из графиков, разброс увеличения производительности запросов по сравнению с классической архитектурой аппаратных достаточно большой, что порождает некоторые сомнения пользователей по целесообразности применения данного решения. Трудности обоснования, связанные с невозможностью точно рассчитать среднюю стоимость транзакции существующей системы, преодолеваются достаточно легко двумя способами. Можно помочь просчитать плановую эффективность на специально подготовленном программном эмуляторе. С его помощью можно просчитать ожидаемое увеличение производительности системы, в зависимости от структуры данных, сложности и частоты выполняемых запросов. Более сложный и затратный с точки зрения времени и ресурсов путь — возможность протестировать собственную BI-систему на реальном оборудовании, которое для этих целей может быть предоставлено компанией Oracle. Уникальность технологии Exadata в том, что она абсолютно прозрачна для приложений. Нужно просто запустить приложение на Exadata, чтобы сразу увидеть его поведение. Отмечу, что компания "Ай-Теко" тоже обладает компетенциями по технологиям BI-систем и Grid & Consolidation, которые так гармонично увязаны в этом программно-аппаратном решении.
в том, что при определенном
Суть DW-проблемы в том, что при определенном размере DW в диапазоне от 10 до 100 Тбайт (порог зависит от производительности системы хранения, которая поддерживает DW — традиционная NAS, массив среднего класса, High-End массив) начинает резко возрастать время реакции (в разы и даже на порядки) на запросы. Анонсированное решение позволяет поддерживать время реакции на минимальном (приемлемом) уровне в очень широких пределах масштабирования DW (сотни терабайт и более).
Архитектура Exadata
Среда аппаратных средств для типичной решетки хранения на базе Exadata показана на рисунке 2. Каждая ячейка Exadata – это автономный сервер с памятью на дисках, на котором выполняется программное обеспечение Exadata, предлагаемое корпорацией Oracle. Базы данных развертываются для всех ячеек Exadata, и несколько баз данных могут совместно использовать ячейки Exadata. База данных и ячейки Exadata взаимодействуют через высокоскоростной интерфейс InfiniBand.
| Аппаратные средства Exadata обеспечиваются HP, а программное обеспечение – Oracle. |
Коллекцию ячеек Exadata, совместно используемых целым рядом баз данных, принято называть Exadata Realm (область Exadata). Набор из трех ячеек на рисунке 2 представляет собой пример такой области. Области гарантируют изоляцию и, следовательно, защиту для всего представленного набора баз данных. Предлагаются механизмы для управляемого и безопасного переноса отдельных дисков и целых ячеек между областями.
Архитектура решения для Exadata включает компоненты на сервере базы данных и в ячейке Exadata. Общая архитектура показана ниже.
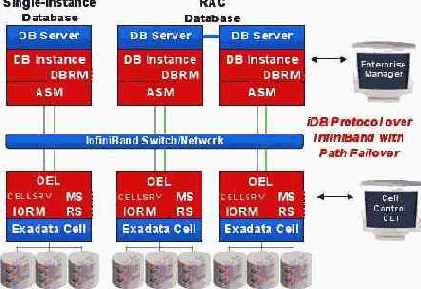
Рисунок 4: Архитектура программного обеспечения Exadata
Дополнительная защита данных при использовании Exadata
| Комплекс Exadata прозрачен для приложения и использует имеющиеся знания Oracle Database и инфраструктуры. |
Комплекс Exadata был спроектирован для включения тех же самых стандартов высокой доступности (High Availability – HA), которых заказчики ожидают от продуктов Oracle. При использовании Exadata все опции и инструментальные средства базы данных работают так же, как они работали с традиционными (non-Exadata) средами хранения. Пользователи и АБД используют знакомые им инструментальные средства и имеющиеся у них знания базы данных Oracle и процедур. При использовании архитектуры Exadata устраняются все элементы, выход которых из строя приводит к отказу всей системы. Чтобы гарантировать непрерывную доступность и защиту данных, в Exadata были включены знакомые опции, типа зеркалирования, изоляции ошибок и защиты от отказов дисков и ячеек. Другие характеристики, гарантирующие высокую доступность в пределах сервера хранения Exadata, описаны ниже.
Встроенная в Exadata Hardware Assisted Resilient Data (HARD)
Инициатива Oracle Hardware Assisted Resilient Data (HARD) – это комплексная программа, разработанная для предотвращения нарушений целостности данных прежде, чем они произойдут. Нарушения целостности данных происходят очень редко, но когда они случаются, они могут оказать катастрофическое влияние на базу данных и, следовательно, на весь бизнес. В комплексе Exadata значительно усилены функциональные возможности встроенной в него HARD, чтобы обеспечить еще более высокие уровни защиты и сквозной проверки правильности данных. Комплекс Exadata выполняет обширную проверку правильности хранящихся в нем данных, включая контрольные суммы, местоположения блоков, волшебные числа, головные и хвостовые проверки (head & tail checks), ошибки выравнивания и т.д. Реализация этих алгоритмов проверки правильности данных в комплексе Exadata будет препятствовать записи разрушенных данных на хранение в постоянную память. Кроме того, эти проверки и защиты предлагаются без ручных операций, которые обычно требуются при использовании HARD в обычных средах хранения.
Data Guard
Технология Oracle Data Guard – это программная опция Oracle Database, которая создает, поддерживает и ведет мониторинг одной или нескольких резервных баз данных, чтобы защитить вашу базу данных от отказов, бедствий, ошибок и разрушений. Технология Data Guard работает с Exadata без какой-либо модификации и может использоваться и для промышленных, и для резервных баз данных. При использовании Active Data Guard со средой хранения Exadata выполнение запросов и отчетов может быть перенесено с промышленной базы данных на чрезвычайно быструю резервную базу данных, с гарантией, что на критичную работу, выполняемую в промышленной базе данных, не будет оказано никакого воздействия, и при этом будет обеспечена защита от аварий.
Технология Flashback
В комплексе Exadata технология Oracle Flashback используется для обеспечения ряда опций для просмотра и восстановления данных назад во времени. Опция Flashback работает в Exadata точно так же, как она работает в средах хранения других производителей (non-Exadata). Опции Flashback предлагают возможность сделать запрос к хранящимся в архиве данным, выполнить анализ изменений и выполнить самостоятельный ремонт («самообслуживание»), чтобы избавиться от логических искажений, причем, база данных в это время остается в онлайновом режиме. В сущности, со встроенными опциями Oracle Flashback Exadata позволяет пользователю иметь нечто подобное функциональным возможностям снэпшотов и восстанавливать базу данных к состоянию, предшествующему моменту, когда произошла ошибка.
Диспетчер восстановления (RMAN) и защищенная резервная копия Oracle (OSB)
Чтобы обеспечить эффективное резервное копирование и восстановление баз данных Oracle, Exadata работает с диспетчером восстановления Oracle (RMAN) – инструментом на основе командной строки и Enterprise Manager. Все имеющиеся сценарии RMAN работают без изменений в среде Exadata. Диспетчер RMAN был спроектирован для тесной работы с сервером, обеспечивая в процессах резервного копирования и восстановления обнаружение искажений на уровне блоков. Диспетчер RMAN оптимизирует производительность и потребление дисковой памяти во время резервного копирования с помощью мультиплексирования файла и компрессирования набора резервных копий и интегрируется с Oracle Secure Backup (OSB – защищенной резервной копией Oracle), а также продуктами управления носителями производства третьих фирм для резервного копирования на магнитную ленту.
Другие виды обработки Exadata Smart Scan
Двумя другими операциями базы данных, которые направляются для выполнения в Exadata, являются создание инкрементальных резервных копий баз данных и создание табличных пространств. Скорость и эффективность создания инкрементальных резервных копий базы данных с помощью Exadata была значительно увеличена. При использовании среды хранения Exadata степень детализации отслеживания изменений в базе данных становится намного более тонкой. При применении Exadata изменения отслеживаются на уровне индивидуальных блоков Oracle, а не на уровне большой группы блоков. Это приводит к меньшему потреблению пропускной способности средств ввода-вывода, используемых для создания резервных копий, и более быстрому выполнению резервного копирования.
С помощью Exadata операция создания файла также выполняется намного более эффективно. Так, например, при выполнении команды Create Tablespace, вместо синхронной обработки каждого блока нового табличного пространства, форматируемым в памяти сервера и записываемым в среду хранения, в Exadata посылается команда iDB, инструктирующая комплекс о том, что необходимо создать табличное пространство и сформатировать блоки. Использование памяти хоста уменьшается, а ввод-вывод, связанный с созданием и форматирование блоков табличного пространства, переносится в среду Exadata. Экономия пропускной способности средств ввода-вывода для этих операций означает, что размер полосы пропускания, доступный для других критичных для бизнеса работ, увеличивается.
Фильтрация предикатов с помощью Smart Scan
Exadata при сканировании таблиц осуществляет фильтрацию по предикатам. На сервер базы данных возвращаются только требуемые строки, а не все строки таблицы. Например, когда выдается следующий SQL-оператор, из Exadata в экземпляр базы данных возвращаются только те строки, для которых дата найма служащих превышает указанную дату. SELECT FROM employee_table WHERE hire_date > '1-Jan-2003';
Такая возможность возвращать на сервер только релевантные строки значительно повышает производительность базы данных. Такое повышение производительности возможно и в тех случаях, когда выдаются и более сложными запросы. Таким образом, эти же преимущества имеют место и в случае сложных запросов, типа запросов с подзапросами.
Фильтрация столбцов с помощью Smart Scan
При сканировании таблиц Exadata обеспечивает фильтрацию столбцов, так называемое проецирование столбцов. На сервер базы данных возвращаются только требуемые для запроса столбцы, а не все столбцы таблицы. Например, при исполнении следующего SQL-оператора в ядро базы данных из Exadata возвращаются только столбцы employee_name и employee_number. SELECT employee_name, employee_number FROM employee_table;
Для таблиц со многими столбцами или со столбцами, содержащими большие объекты (LOB), экономия пропускной способности средств ввода-вывода может оказаться очень большой. В тех случаях, когда фильтрация предикатов и столбцов используется вместе, в значительной степени повышается производительность и сокращается потребление пропускной способности средств ввода-вывода. Кроме того, фильтрация столбцов применима также и к индексам, что позволяет еще более повысить производительность запросов.
Краткий технический обзор грид-сервера хранения данных HP Oracle Exadata
Официальный документ Oracle, Октябрь 2008 г.
Источник:
Оригинал:
Машина базы данных HP Oracle Database
В дополнение к ячейкам среды хранения Exadata Oracle предлагает полностью интегрированную платформу для приложений, работающих с хранилищами данных. Машина базы данных – это легко развертывающееся решение, готовое к использованию сразу же после установки хранилища данных предприятия. В состав машины базы данных входят следующие аппаратные средства:
|
Корпорация Oracle в тесном сотрудничестве с HP работала над тем, чтобы спроектировать конфигурацию аппаратных средств, оптимизирующую производительность базы данных Oracle. |
Четырнадцать серверов хранения Exadata (с дисками с интерфейсом SAS или SATA) Восемь серверов базы данных Oracle Database 11g Proliant HPDL360 G5 (четырехъядерные процессоры Intel® 2.66 ГГц с Dual Socket), оперативная память 32 Гбайт, четыре дисковода SAS емкостью 146 Гбайт каждый, двухпортовый канальный адаптер хоста InfiniBand (HCA), двойные порты Ethernet на 1 гигабит/сек и избыточные источники питания Вся необходимая инфраструктура InfiniBand (HCA, коммутаторы и кабели) для обеспечения взаимодействия сервера базы данных с сервером хранения Exadata Коммутатор Ethernet для коммуникации между машинами базы данных и клиентами или другими вычислительными системами Аппаратные средства для клавиатуры, видео-блока или устройства визуального отображения (дисплея) и мыши (KVM) И это все упаковано в отдельную стандартную 19-дюймовую стойку (размер 42U)
Каждая стойка машины базы данных, использующая ячейки хранения Exadata на основе SAS, обеспечивает до 46 Тбайт данных нескомпрессированной пользовательской емкости и полосу пропускания средств ввода-вывода до 10.5 Гбайт/сек. Кроме того, каждая стойка машины базы данных является строительным блоком хранилища данных. Путем использования включенной структуры коммутации InfiniBand стойки могут быть связаны друг с другом для построения отдельных баз данных, которые могут масштабироваться до петабайтов.
В итоге продукты Exadata решают вопросы, связанные с тремя критическими измерениями ввода-вывода базы данных, которые могут стать препятствиями для производительности хранилищ данных. Больше каналов: Exadata базируется на архитектуре с массовым параллелизмом, которая обеспечивает больше каналов для более быстрой доставки большего объема данных между серверами базы данных и серверами хранения. По мере того, как в конфигурацию данных базы добавляются серверы хранения Exadata, полоса пропускания масштабируется линейно. Сделайте каналы шире: канал InfiniBand в пять раз быстрее волоконно-оптического канала. Exadata построен с использованием более широких каналов InfiniBand, которые обеспечивают чрезвычайно широкую полосу пропускания между серверами базы данных и серверами хранения. Отправляйте по каналам меньше данных, выполняя обработку данных непосредственно в устройстве хранения: комплекс Exadata подготовлен к работе с базой данных и может отправлять только те данные, которые требуются для удовлетворения SQL-запросов, что приводит к тому, что между серверами базы данных и серверами памяти хранения пересылается меньше данных.
Миграция к среде хранения Exadata
Среда хранения Exadata может использоваться в дополнение к массивам хранения и продуктам, которые традиционно использовались для хранения баз данных Oracle. Отдельная база данных может частично храниться в среде хранения Exadata, а частично на традиционных запоминающих устройствах. Табличные пространства могут храниться в среде хранения Exadata, в средах других производителей или как комбинация этих двух возможностей, что является абсолютно прозрачным по отношению к операциям базы данных и приложениям. Но для того чтобы можно было воспользоваться всеми преимуществами функциональности Smart Scan среды хранения Exadata, все табличное пространство должно храниться в среде Exadata. Такое совместное хранение и сосуществование является основной характеристикой, делающей возможным онлайновый переход (миграцию) к среде хранения Exadata.
Для существующей базы данных может быть проведена онлайновая неразрушающая миграция к среде хранения Exadata, если эта база данных развернута в среде ASM и использует избыточность ASM. Это достигается следующим образом: Добавьте к существующей дисковой группе ASM грид-диск Exadata.
Затем ASM автоматически перенастроит данные внутри дисковой группы, перенося пропорциональное количество данных на недавно добавленный грид-диск Exadata. После этого диск от другого производителя (non-Exadata disk) должен быть выведен из состава дисковой ASM-группы. В результате ASM еще раз перенастроит данные, перенося данные с дисков от другого производителя на другие диски этой дисковой группы. Пункты 1-3 повторяются до тех пор, пока вся база данных не будет перенесена в среду хранения Exadata.
Кроме того, миграция может быть совершена с использованием диспетчера восстановления (RMAN), который позволяет выполнить создание резервных копий на традиционной среде хранения, а затем восстановить данные в среде Exadata. Для облегчения миграции может быть также использована технология Data Guard. Для этого сначала на базе среды хранения Exadata создается резервная база данных. Для резервной базы данных может использоваться среда хранения Exadata, а промышленная база данных может использовать традиционные средства хранения. Путем выполнения быстрого переключения, на что требуется всего лишь несколько секунд, можно преобразовать резервную базу данных в промышленную. Все эти подходы обеспечивают "страховочную сетку" (safety net), поскольку легко и изящно можно отменить миграцию, если вдруг возникнут непредвиденные обстоятельства.
Обработка Exadata Smart Scan
| Технология Smart Scan переносит сведения о базе данных как можно ближе к аппаратным средствам. |
При использовании традиционных неготовых к работе с iDB устройств хранения все сведения о базе данных постоянно хранятся на сервере вместе с программным обеспечением базы данных. Для иллюстрации того, как в этой архитектуре выполняется обработка запросов SQL, ниже показано как сканируется таблица.
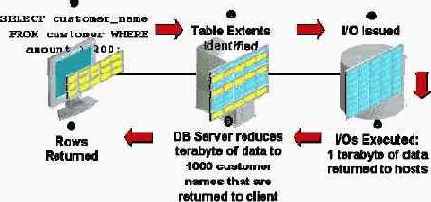
Рисунок 5: Традиционная модель ввода-вывода и обработки SQL-запросов для базы данных Клиент выдает оператор SELECT с предикатом фильтрации и возврата только представляющих интерес строк. Ядро базы данных представляет этот запрос в виде файлов и экстентов, содержащих просматриваемую таблицу. Ядро базы данных выдает команды ввода-вывода для чтения блоков. Все блоки таблицы, к которой был сделан запрос, считываются в память. Затем выполняется обработка SQL-запросов на «сырых» блоках для поиска строк, которые удовлетворяют предикату. Наконец, найденные строки передаются клиенту.
Как это часто имеет место с большими запросами, предикат отфильтровывает большинство прочитанных строк. Но тем не менее все блоки из таблицы должны быть прочитаны, переданы по сети хранения и скопированы в память. В память считывается намного больше строк, чем необходимо для выполнения требуемой SQL-операции. При этом генерируется большое число передач данных, на что расходуется полоса пропускания и что воздействует на пропускную способность (а значит, и на производительность) и время ответа приложения.
Интеграция функциональности базы данных на уровне среды хранения стека базы данных позволяет намного более эффективно выполнять запросы и другие операции базы данных. Реализация функциональных возможностей базы данных так близко к аппаратным средствам, насколько это возможно (в случае Exadata – на уровне дисков), может в значительной степени ускорить выполнений операций базы данных и увеличить пропускную способность системы.
При использовании среды хранения Exadata операции с базой данных обрабатываются намного более эффективно. Запросы, выполняющие сканирование таблицы, могут быть обработаны непосредственно внутри комплекса Exadata с использованием только необходимого подмножества данных, возвращаемых на сервер базы данных. Фильтрация строк, фильтрация столбцов и некоторая обработка соединений (наряду с другими функциями) выполняются в ячейках хранения Exadata. Когда это происходит, на сервер базы данных возвращаются только релевантные и необходимые данные.
Exadata Smart Scan возвращает только релевантные строки и столбцы запроса, позволяя лучше использовать полосу пропускания средств ввода-вывода и увеличивать производительность базы данных. |
На приведенном ниже рисунке 6 показано, как в среде хранения Exadata работает сканирование таблицы.
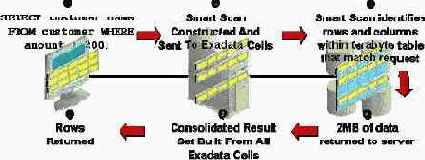
Рисунок 6: Разгрузка обработки при использовании Smart Scan Клиент выдает оператор SELECT с предикатом для фильтрации и возврата только строк, представляющих интерес. Ядро базы данных определяет, что среда хранения Exadata доступна, создает команду iDB, представляющую клиентскую команду SQL, и посылает ее в среду хранения Exadata. Компонент CELLSRV программного обеспечения Exadata просматривает блоки данных, чтобы определить те строки и столбцы, которые удовлетворяют полученному SQL-оператору. В память считываются только строки и требуемые столбцы, удовлетворяющие предикату. Ядро базы данных объединяет результирующие наборы из всех ячеек Exadata. И, наконец, строки возвращаются клиенту.
Сканирования Smart Scan прозрачны для приложения, – ни для какого приложения или SQL-оператора не требуется никаких изменений. Возвращенные данные являются полностью согласованными и транзакционными и строго соответствуют функциональности и поведению согласованного чтения (consistent read) для Oracle Database. Если в процессе такого «разумного сканирования» ячейка выходит из строя, незаконченные части Smart Scan прозрачно перенаправляются для завершения в другую ячейку. Сканирования Smart Scan должным образом обрабатывают сложные внутренние механизмы Oracle Database, включая: незафиксированные данные и заблокированные строки, сцепленные (chained) строки, компрессированные таблицы, обработку национального языка, операции с датами, поиски с помощью регулярных выражений, материализованные представления и секционированные таблицы. А SQL EXPLAIN PLAN показывает, когда используются «разумные сканирования» Exadata.
База данных Oracle и Exadata совместно выполняют различные SQL-операторы. Перенос обработки SQL-операторов с сервера базы данных приводит к сокращению числа циклов центрального процессора на сервере и значительно сокращает потребление полосы пропускания, которая вследствие такого сокращения становится доступной для лучшего обслуживания других запросов. SQL-операции выполняются быстрее, и одновременно может выполняться большее количество таких операций. Это происходит благодаря уменьшению конкуренции за полосу пропускания средств ввода-вывода. А сейчас мы посмотрим на различные SQL-операции, которые получают дополнительные преимущества, благодаря использованию Exadata.
Обработка соединений с помощью Smart Scan
Exadata выполняет соединения между большими таблицами и маленькими справочными таблицами – весьма часто встречающийся сценарий для хранилищ данных со схемами типа звезды. Такая обработка реализуется с использованием фильтров Блюма (Bloom Filters), которые являются очень эффективным вероятностным методом для определения, является ли строка членом желательного результирующего набора.
Плагин Enterprise Manager для Exadata
|
Exadata работает с Enterprise Manager, чтобы обеспечить графический пользовательский интерфейс для мониторинга и среду Exadata. |
Для облегчения ведения мониторинга среды Exadata комплекс был также интегрирован с Oracle Enterprise Manager (EM) Grid Control. Благодаря установке плагина для Exadata в существующие системы EM, стало возможным вести мониторинг статистики и деятельности на сервере хранения Exadata, а события и предупреждения теперь можно отослать администратору. Среди преимуществ интеграции системы EM с Exadata можно назвать: Мониторинг среды хранения Oracle Exadata Сбор информации о конфигурации среды хранения и ее производительности Возможность возбуждать на основании значений порогов режим извещений и предупреждений Предоставление обширного набора готовых показателей и отчетов, базирующихся на архивных данных
Все функциональные пользователи были уверены, что с Exadata будет работать Oracle Enterprise Manager. При использовании EM-интерфейса пользователи могут легко управлять средой Exadata наряду с другими средами базы данных Oracle, традиционно используемыми вместе с Enterprise Manager. АБД может использовать знакомый EM-интерфейс, чтобы просматривать отчеты, определять состояние системы Exadata и управлять конфигурациями среды хранения Exadata.
Программное обеспечение Exadata
Как и любое запоминающее устройство, сервер хранения Exadata представляет собой компьютер с центральными процессорами, оперативной памятью, шиной, дисками, сетевыми адаптерами (NIC) и другими компонентами, которые обычно можно найти в сервере. На сервере работает операционная система (OS), роль которой в случае Exadata исполняет Oracle Enterprise Linux (OEL) 5.1. Резидент Oracle Storage Server Software в ячейке Exadata функционирует под управлением OEL. OEL в ограниченном плане может администрировать и управлять ячейкой Exadata.
Основным компонентом программного обеспечения Exadata, которое выполняется в ячейке и обеспечивает большую часть сервисов хранения Exadata, является CELLSRV (Cell Services – сервисы ячейки). Это многопоточное программное обеспечение, которое используя протокол iDB взаимодействует с экземпляром базы данных на сервере базы данных и обслуживает базы данных блоками. Это обеспечивает расширенные возможности по разгрузке SQL-операторов, предоставляет блоки Oracle в тех случаях, когда разгрузить SQL-обработку невозможно, и реализует функциональные возможности управления ресурсами ввода-вывода DBRM, чтобы измерить пропускную способность средств I/O для различных баз данных и групп потребителей, издающих команды ввода-вывода.
Два других компонента программного обеспечения Oracle, выполняющиеся в ячейке, – это сервер управления (Management Server – MS) и сервер рестарта (Restart Server – RS). MS является первичным интерфейсом для администрирования, управления и задания запросов о состоянии ячейки Exadata. Он работает в сотрудничестве с интерфейсом командной строки ячейки Exadata (Command Line Interface – CLI) и плагином для EM Exadata, и обеспечивает управление и конфигурирование автономной ячейки Exadata.
К примеру, для ячейки имеются CLI-команды для конфигурирования среды хранения, для запроса статистики ввода-вывода и рестарта ячейки. Также поставляется распределенный CLI, чтобы для облегчения управления ячейками команды можно было бы посылать сразу в несколько ячеек. Сервер рестарта (RS) гарантирует непрекращающееся функционирование программного обеспечения Exadata и сервисов. Он используется для обновления программного обеспечения Exadata. Кроме того, он гарантирует, что сервисы хранения запущены и приведены в рабочее состояние, а когда это потребуется, они будут перезапущены.
Программное обеспечение сервера базы данных
База данных Oracle Database 11g была значительно усилена, для того чтобы воспользоваться всеми преимуществами среды хранения Exadata. Программное обеспечение Exadata оптимально разделяется между сервером базы данных и ячейкой Exadata. Сервер базы данных и программное обеспечение сервера хранения Exadata взаимодействуют, используя для этого iDB – протокол интеллектуальной базы данных. Протокол iDB реализован в ядре базы данных и прозрачно отображает операции базы данных на расширенные за счет Exadata операции. В дополнение к традиционной пересылке блоков данных, обеспечиваемой базой данных, протокол iDB реализует архитектуру передачу функций. Протокол iDB используется для передачи SQL-операций на выполнение вниз, в ячейки Exadata и для возвращения результирующих наборов запросов в экземпляр базы данных. Вместо того чтобы возвращать блоки базы данных, ячейки Exadata возвращают только строки и столбцы, удовлетворяющие SQL-запросам. Подобно существующим протоколам ввода-вывода, iDB может также непосредственно читать и писать последовательности байтов с диска и на диск, так что в тех случаях, когда разгрузить обработку не представляется возможным, Exadata работает, как традиционное запоминающее устройство для базы данных Oracle. Но когда подобная разгрузка выполнима, накопленные в экземпляре базы данных сведения дают возможность, например, передавать вниз просмотры таблиц, чтобы эти операции выполнялись на сервере хранения Exadata, а на сервер базы данных возвращались только запрошенные данные.
Протокол iDB построен на базе промышленного стандарта протокола Reliable Datagram Sockets (RDSv3) и выполняется поверх протокола InfiniBand. Для устранения ненужного копирования блоков используется реализация ZDP (Zero-loss Zero-copy Datagram Protocol) или RDS с отсутствием промежуточного копирования. На серверах базы данных и ячейках Exadata могут использоваться несколько сетевых интерфейсов. Это протокол с очень малым временем ожидания, который сводит к минимуму число создаваемых копий данных, которые требуются для обслуживания операций ввода-вывода.
| Комплекс Exadata предлагает избыточное и устойчивое к отказам решение с широкополосным доступом к базе данных. |
Механизм автоматического управления средой хранения (Automatic Storage Management – ASM) является фундаментом управления средой хранения Exadata. Механизм ASM виртуализирует ресурсы среды хранения и обеспечивает расширенное управление томами и функциональные возможности файловой системы Exadata. Равномерное расщепление файлов базы данных по всем доступным ячейкам Exadata и дискам (страйпинг) приводит к однородной нагрузке на ввод-вывод по всем аппаратным средствам хранения. Возможность ASM выполнять неагрессивное распределение и перераспределение ресурсов является ключевым условием для достижения желаемых коллективных возможностей разднляемой грид-памяти для сред Exadata. А функциональные возможности зеркалирования ASM и групп отказов (наборы дисков, разделяющих общие ресурсы, требующие защиты против сбоев – прим. пер.) обеспечивают большую часть защиты данных и способности системы противостоять ошибкам во всей среде Exadata. При использовании ASM данные зеркалируются по всем ячейкам, что гарантирует высокую доступность в случае отказа отдельной ячейки.
В Oracle Database 11g была усилена опция диспетчера ресурсов базы данных (DBRM) для использования с Exadata. В дополнение к управлению использованием CPU, сегментами отката, степенью параллелизма, активными сеансами и другими ресурсами, диспетчер DBRM позволяет пользователю определять и управлять пропускной способностью средств ввода-вывода как внутри базы данных, так и между базами данных. Он позволяет разделять среду хранения между базами данных, не испытывая опасений, что одна база данных монополизирует всю полосу пропускания средств ввода-вывода и окажет воздействие на производительность других баз данных, совместно использующих среду хранения. Группам потребителей выделяется определенный процент доступной пропускной способности средств ввода-вывода, и DBRM гарантирует, что заявленные плановые цифры будут обеспечены. Это реализуется благодаря тому, что база данных маркирует операции ввода-вывода метками, определяющими базу данных и группу потребителей, от имени которых эти операции ввода-вывода производятся. В результате базе данных предоставляется полная картина приоритетов операций ввода-вывода для всего стека ввода-вывода. Распределение ввода-вывода для группы потребителей внутри базы данных определяется и управляется на сервере базы данных. Распределение ввода-вывода между базами данных определяется программным обеспечением ячейки Exadata и управляется диспетчером ресурсов ввода-вывода (I/O Resource Manager – IORM). Программное обеспечение ячейки Exadata гарантирует, что ресурсы ввода-вывода для обмена между базами данных управляются и должным образом распределены как внутри, так и между базами данных. В целом, DBRM гарантирует, что каждая база данных получает выделенное ей количество ресурсов ввода-вывода, а определенные пользователями SLA выполняются.
Программное обеспечение среды хранения Exadata
Как говорилось ранее, ячейка Exadata – это сервер, на котором работает Oracle Enterprise Linux, а также предлагаемое Oracle программное обеспечение Exadata. При первом запуске ячейка загружается, как и любой другой компьютер, в режим обслуживания среды хранения Exadata. На первых двух дисководах имеются маленькие разделы LUN, называемые «системной областью», размером приблизительно 13 Гбайт, зарезервированные для операционной системы OEL, программного обеспечения Exadata и метаданных конфигурации. Системная область содержит данные Oracle Database 11g Automatic Diagnostic Repository (ADR) и другие метаданные о ячейке Exadata. Администратор не должен управлять LUN системной области, поскольку она создается автоматически. Ее контент автоматически зеркалируется на различных физических дисках для защиты от их отказов и проведения горячей замены дисков. Остальная часть этих двух дисководов доступна для данных пользователей.
Сегодняшние пределы для ввода-вывода базы данных
Фундаментом Exadata является интеллектуальное программное обеспечение базы данных для обработки сложных задач анализа, выполняемых приложениями, работающими с хранилищами данных. База данных Oracle обеспечивает интеллектуальное (brainy) программное обеспечение, типа битовой индексации, индексации соединений, кубов OLAP, материализованных представлений, кэшей результатов, секционирования и т.д. для того, чтобы сделать возможным очень сложный анализ данных и свести к минимуму потребность в дорогих аппаратных средствах. А обращение к базам данных, содержащим сотни терабайтов данных, наращивая интеллектуальное программное обеспечение мощными аппаратными средствами для выполнения "лобовых" просмотров и соединений, обеспечивает огромные возможности для увеличения объемов и ускорения обработки баз данных для бизнеса. Наличие мускулистых (brawny) аппаратных средств для обеспечения необходимой полосы пропускания для высокопроизводительных приложений, работающих с хранилищами данных, в дополнение к мозговитому (brainy) программному обеспечению, является ключом для достижения критической производительности, обеспечиваемой семейством продуктов Exadata.
| Интеллектуальный софтвер (Brainy software) и сильный хартвер (brawny hardware) обеспечат результат наиболее быстро |
Традиционные среды хранения предлагают базе данных Oracle узкий и ограниченный интерфейс к среде хранения данных. Сегодня в путях ввода-вывода имеется много так называемых узких мест, ограничивающих полосу пропускания данных, что, следовательно, ограничивает обшую производительность базы данных. Серверам базы данных требуется большое количество адаптеров главной шины (Host Bus Adapters – HBA) сети устройств хранения данных (Storage Area Network – SAN), чтобы обеспечить полосу пропускания, необходимую для доставки данных из среды хранения в базу данных с необходимой скоростью. Очень часто сервер оказывается не в состоянии поддержать количество HBA, требующихся для достижения адекватной производительности, или же это количество HBA становится слишком дорогим. Помимо этого, для обеспечения необходимой полосы пропускания и избыточности существенно увеличиваются стоимость и сложность SAN-коммутаторов. Кроме того, большие массивы хранения не могут предоставить адекватную полосу пропускания тем сотням дисков, которые в них входят. Это приводит к тому, что потенциальная производительность дисков искусственно ограничивается на уровне, который значительно ниже того, который они способны обеспечить. Производительность дисков становится узким местом для волоконно-оптических кольцевых линий связи (Fibre Channel Loops – FCL) с дисками и для производительности обработки массивов хранения.
|
При обработке SQL-запросов с помощью Smart Scan в среде хранения Exadata интеллект базы данных переносится как можно ближе (насколько это возможно) к аппаратным средствам для получения экстремальной производительности ввода-вывода. |
Традиционные внешние запоминающие устройства к тому же «не знают», что хранящаяся в них информация представляет собой базу данных, и поэтому не могут обеспечить какие бы то ни было операции обработки SQL-запросов или ввода-вывода, предназначенных специально для работы с базой данных. Хотя база данных запрашивает строки и столбцы, из устройств хранения на самом деле возвращаются блоки данных, а вовсе не результирующий набор запроса к базе данных. Традиционные устройства хранения не обладают никаким интеллектом базы данных, чтобы различить фактически запрошенные конкретные строки и столбцы. Так что, при обработке ввода-вывода от имени базы данных традиционные устройства хранения потребляют полосу пропускания, возвращая много данных, которые нерелевантны запросу, заданному базой данных. Продукты семейства Exadata решают вопросы, относящиеся к трем ключевым измерениям ввода-вывода базы данных, которые могут препятствовать производительности хранилища данных. Комплексы Exadata базируются на архитектуре с массовым параллелизмом, которая предлагает большее число каналов для обеспечения более быстрой пересылки большего объема данных между серверами баз данных и серверами хранения. Комплексы Exadata построены с использованием более широких каналов, которые предлагают чрезвычайно высокую полосу пропускания между серверами баз данных и серверами хранения. Комплексы Exadata готовы к работе с базами данных и могут поставлять только те данные, которые требуются для удовлетворения SQL-запросов, что приводит к существенному уменьшению объема пересылаемых данных между серверами баз данных и серверами хранения.
Семейство продуктов Exadata
Семейство продуктов Oracle Exadata состоит из двух членов. Фундаментом семейства продуктов Exadata является сервер хранения Oracle Exadata компании HP. Он используется для построения решений для хранилищ данных с использованием поставляемых заказчиками серверов базы данных и инфраструктуры. Вторым членом семейства продуктов Exadata является машина Oracle Database компании HP. Машина базы данных представляет собой полное и полностью интегрированное решение для работы с хранилищами данных, в состав которого включены все компоненты для быстрого и беспрепятственного развертывания хранилищ данных предприятия.
Сервер хранения данных HP Oracle Exadata
Сервер хранения данных HP Oracle Exadata – это механизм для хранения данных, в высшей степени оптимизированный для использования с базой данных Oracle. С помощью Exadata удается достичь потрясающей производительности подсистемы ввода-вывода и обработки SQL-запросов (SQL processing) для приложений, работающих с хранилищами данных, благодаря использованию архитектуры с массовым параллелизмом для активации динамической грид-памяти (dynamic storage grid) при развертываниях среды Oracle Database 11g. Комплекс Exadata представляет собой комбинацию программного обеспечения и оборудования, используемых для хранения данных в базе данных Oracle и обращения к ним. Он предлагает готовые к работе с базой данных услуги хранения, типа возможности разгрузить базу данных, перенося обработку с сервера базы данных в систему хранения, обеспечивая при таком переносе полную прозрачность обработки SQL-запросов и приложений базы данных. Устройства хранения Exadata предлагают существенное повышение производительности, а также неограниченную масштабируемость подсистемы ввода-вывода, они просты в использовании и управлении и обеспечивают предприятию доступность и надежность, требующиеся для решения стратегически важных задач.
|
Exadata обеспечивает для Oracle Database экстремальные значения производительности ввода-вывода и обработки SQL-запросов, используя во внедрениях Oracle Database 11g архитектуру с массовым параллелизмом для активации совместно используемой грид-памяти хранения (shared storage grid). |
Комплекс Exadata является совместным предложением Oracle и HP. HP обеспечивает технологию аппаратных средств, используемую в сервере хранения Exadata. Oracle обеспечивает программное обеспечение для придания среде хранения интеллекта базы данных и сильной интеграции среды хранения Exadata с базой данных Oracle и всеми ее возможностями. HP обеспечивает международное присутствие и безоговорочное лидерство в области производства серверов с процессорами x86, а также службу поддержки мирового класса, что делает это партнерство столь мощным. Партнерство Oracle и HP делает возможным производство сервера хранения Exadata и тех поистине революционных возможностей, которые он предлагает.
Сервер хранения HP Oracle Exadata
Сервер хранения Exadata является внешним устройством хранения данных базы данных, на котором выполняется программное обеспечение сервера хранения Exadata, поставляемое Oracle. Компоненты аппаратных средств сервера хранения Exadata (также называемые ячейками Exadata – Exadata cells) были тщательно выбраны, чтобы соответствовать потребностям высокопроизводительной обработки запросов. Программное обеспечение Exadata оптимизировано, чтобы можно было воспользоваться всеми возможными преимуществами компонентов аппаратных средств и Oracle Database. Каждая ячейка Exadata обеспечивает базе данных потрясающую производительность ввода-вывода и полосу пропускания.
|
Cервер хранения Exadata является фундаментом семейства продуктов Exadata. Ячейки подключаются к серверам базы данных и используются как постоянная память (среда постоянного хранения) для базы данных. |
Аппаратные средства ячейки базируются на серверах HP Proliant DLl 80 G5. Ячейка поставляется предварительно сконфигурированной и содержит два четырехъядерных процессора Intel с частотой 2.66 ГГц, двенадцать дисков, подключенных к интеллектуальному контроллеру массива хранения с 512 Кб энергонезависимого кэша, 8 Гбайт оперативной памяти, сдвоенный порт связи InfiniBand, плату управления для удаленного доступа, избыточные источники питания, полностью предварительно установленное программное обеспечение. Она может быть установлена в типовую 19-дюймовую стойку.

Рисунок 1: Ячейка хранения Exadata
Предлагаются две версии ячейки Exadata. Первая базируется на дисках с интерфейсом Serial Attached SCSI (SAS) емкостью 450 Гбайт. Эта версия ячейки обладает информационной емкостью до 1.5 Тбайт некомпрессированных пользовательских данных и полосой пропускания данных до 1 Гбайт/сек. Вторая версия ячейки Exadata базируется на дисках с интерфейсом SATA и обладает информационной емкостью до 3.3 Тбайт некомпрессированных пользовательских данных и полосой пропускания данных до 750 Мбайт/сек. Когда данные хранятся в компрессированном формате, количество пользовательских данных и размер полосы пропускания данных, обеспечиваемых каждой ячейкой, часто возрастает в 2-3 раза. Информационная емкость пользовательских данных вычисляется после зеркалирования всего дискового пространства, и после того, как выделено место для структур базы данных: журналы, пространство отката и временное пространство. Фактические данные пользователя изменяются от приложения к приложению.
Между серверами и средой хранения в Oracle Exadata используется самое современное межузловое соединение InfiniBand. Для повышения доступности ячейка Exadata имеет сдвоенный порт соединения InfiniBand. Каждая связь InfiniBand обладает 16-гигабитовой полосой пропускания, что во много раз выше, чем у традиционных сетей хранения или сетей серверов. Далее, протокол Oracle подключения к сети использует прямое размещение данных (прямой доступ к памяти – DMA или direct memory access), чтобы гарантировать очень низкие накладные расходы центрального процессора за счет непосредственного переноса данные «с провода» в буферы базы данных, не делая дополнительного копирования данных. Сеть InfiniBand имеет гибкость сети LAN и эффективность SAN. При использовании сети InfiniBand Oracle гарантирует, что сеть не станет узким местом для производительности. Та же самая сеть InfiniBand также обеспечивает высокопроизводительное межузловое соединение узлов в кластерах Oracle Database Real Application Cluster (RAC).
На приведенном ниже рисунке 2 показана небольшая среда базы данных на базе устройстве хранения данных Exadata. Две базы данных Oracle – один RAC и один одиночный экземпляр – совместно используют три ячейки Exadata. Все компоненты для этой конфигурации – серверы базы данных, ячейки Exadata, коммутатор InfiniBand, коммутаторы Ethernet и другие аппаратные средства поддержки – могут быть размещены в типовой 19-дюймовой стойке, занимая при этом меньше ее половины.
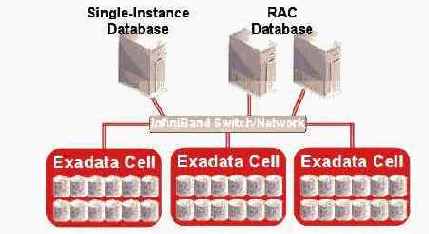
Рисунок 2: Облегченная конфигурация ячейки хранения Exadata
Архитектура комплекса Oracle Exadata проработана таким образом, чтобы в нем для достижения масштабирования до любого уровня производительности можно было использовать архитектуру scale-out. Для достижения более высокой производительности и емкости запоминающего устройства к конфигурации добавляются дополнительные ячейки Exadata. По мере добавления дополнительных ячеек емкость, пропускная способность и производительность увеличиваются линейно. В конфигурации Exadata никогда не делается (и не требуется) никаких каналов связи между ячейками (cell-to-cell communication).
По мере того, как добавляется емкость к серверу хранения Exadata, автоматически добавляется и производительность. Комплекс Exadata обеспечивает почти безграничную масштабируемость. |
Как показано на приведенном ниже рисунке 3, типовая 19-дюймовая стойка размера 42U может содержать до восемнадцати ячеек Exadata. Если выбраны диски с интерфейсом SAS, то доступны 97 Тбайт полной (неформатированной) емкости (216 Тбайт полной емкости для дисков SATA). Пиковая пропускная способность для конфигурации на базе SAS составляет 18 Гбайт/сек. Если требуется дополнительная емкость запоминающего устройства, добавьте больше стоек с ячейками Exadata, чтобы масштабироваться до любой необходимой полосы пропускания или производительности. Добавление дополнительных стоек – это простой процесс, поскольку связная архитектура InfiniBand может распространяться и между стойками при полном сохранении возможностей связи. Как только подключается новая стойка, новые диски Exadata обнаруживаются и делаются доступными Oracle Database.
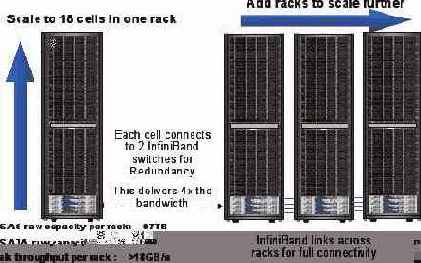
Рисунок 3: Масштабирование среды хранения Exadata для производительности и емкости
Зеркалирование дисков, обеспечиваемое механизмом автоматического управления средой хранения (Automatic Storage Management – ASM), и способные к «горячей» замене (то есть, замене без прекращения работы) диски Exadata являются гарантией того, что база данных может допускать отказы индивидуальных дисководов. Данные зеркалируются в различные ячейки, гарантируя, что отказ одной из ячеек не вызовет потери или не станет препятствием для доступности данных. Такая архитектура с массовым параллелизмом обеспечивает неограниченную масштабируемость и высокую доступность.
При использовании Oracle Exadata обработка SQL-запросов переносится с сервера базы данных на сервер хранения Oracle Exadata. В дополнение к обеспечению традиционного обслуживания блоками данных, Oracle Exadata делает возможной передачу функций от экземпляра базы данных в базовую среду хранения. Одним из уникальных механизмов, обеспечиваемых средой хранения Exadata по сравнению с традиционными средами, является возвращение не всей таблицы, к которой делался запрос, а только строк и столбцов, удовлетворяющих запросу к базе данных. Комплекс Exadata помещает обработку SQL-запросов настолько близко к аппаратным средствам, насколько это возможно, и обеспечивает работу в параллельном режиме всех дисков. Он уменьшает потребление CPU на сервере базы данных, занимает намного меньшую полосу пропускания при переносе данных между серверами базы данных и серверами хранения и возвращает результирующий набор запроса, а не целые таблицы. Устранение передачи данных и сокращение рабочей нагрузки на сервер базы данных может принести значительную пользу при запросах к хранилищам данных, которым традиционно не хватало полосы пропускания и времени CPU. Устранение передач данных может также привести к существенной выгоде для систем онлайновой обработки запросов (OLTP).
Среда хранения Exadata полностью прозрачна для приложений, использующих базу данных. Существующие SQL-операторы, будь то нерегламентированные (специальные, ad hoc) запросы или запросы из пакетированных или заказных приложений, не требуют никакой модификации в случае использования среды хранения Exadata. Все преимущества решения, связанные с разгрузкой обработки и расширением полосы пропускания, становятся доступными без какой бы то ни было модификации приложений. И все возможности базы данных Oracle полностью поддерживаются в среде хранения Exadata. Комплекс Exadata работает одинаково хорошо и в случае развертывания базы данных Oracle для одиночного экземпляра, и для кластеров Real Application Clusters. Такие функциональные возможности, как Data Guard, диспетчер восстановления (RMAN), Streams и другие инструментальные средства базы данных администрируются абсолютно одинаково как с Exadata, так и без них. Пользователи и администратор базы данных сегодня применяют те же самые инструментальные средства и знания, с которым они хорошо знакомы, потому что они работают точно так же, как они работали с традиционными (без Exadata) средами хранения. Среды хранения и с комплексами Exadata, и без них могут одновременно использоваться в среде хранения базы данных, чтобы облегчить переход к средам Exadata, или от них.
Применение памяти, напоминающей трубопровод (stovepiped), приводит к неэффективному использованию доступной ширины полосы пропускания памяти и других ресурсов. |
Природа традиционных продуктов для сред хранения поощряет неэффективное их развертывание для каждой базы данных в инфраструктуре ИТ. Архитектура Exadata гарантирует, что вся полоса пропускания и все ресурсы ввода-вывода подсистемы хранения Exadata могут быть сделаны доступными всякий раз, когда и к какой бы то ни было базе данных или классу работы требуется доступ. Пропускная способность подсистемы ввода-вывода измеряется для различных классов работ или баз данных, совместно использующих сервер хранения Exadata, основываясь на определяемых пользователем политиках и соглашениях об уровне обслуживания (service level agreements (SLAs)). Диспетчер ресурсов базы данных (Database Resource Manager – DBRM) был модифицирован для применения со средой хранения Exadata, чтобы управлять использованием определяемых пользователем ресурсов ввода-вывода как внутри баз данных(intra), так и между (inter) ними, чтобы гарантировать выполнение определенных заказчиком SLA. Функциональные возможности управления ресурсами ввода-вывода среды хранения Exadata делают возможным приспосабливание ресурсов ввода-вывода к деловым приоритетам организации и построение разделяемой грид-памяти хранения для баз данных Oracle.
Создание виртуальной среды хранения Exadata
В Exadata предлагается богатый набор изощренных и мощных возможностей создания виртуальной среды управления средой хранения, в которых используются сильные стороны Oracle Database, программного обеспечения Exadata и аппаратных средств Exadata.
Создание виртуальной среды хранения пользователя Exadata
Компонент Automatic Storage Management (ASM) используется для управления средой хранения в ячейке Exadata. Управление томами ASM, страйпинг и сервисы защиты данных делают его оптимальным выбором для управления томами. ASM обеспечивает защиту данных от отказов диска и ячейки, наилучшую возможную производительность и чрезвычайно гибкие опции конфигурирования и реконфигурирования.
Cell Disk (диск ячейки) является виртуальным представлением физического диска за вычетом системной области LUN (если она имеется). Cell Disk является одним из ключевых дисковых объектов, которыми администратор управляет внутри ячейки Exadata. Диск ячейки представляется отдельным LUN, который создан и управляется автоматически программным обеспечением Exadata, когда оно обнаруживает физический диск.
| Exadata и ASM обеспечивают интерактивное динамическое управление томами, автоматическое выравнивание (балансировку) нагрузки и надежную защиту данных. |
Диски ячейки могут быть далее виртуализированы в один или более грид-дисков (Grid Disk). Грид-диски сетки представляют собой дисковый объект, распределенный для ASM, как, например, диски ASM, чтобы от имени базы данных управлять пользовательскими данными. Самый простой случай - когда одному грид-диску соответствует весь диск ячейки. Но также возможно секционировать диск ячейки по нескольким разделам грид-диска. Помещение нескольких грид-дисков на диск ячейки позволяет администратору распределять память по пулам различной производительности или требованиям доступности. Разделы грид-диска могут использоваться для выделения "горячих", "теплых" и "холодных" областей диска ячейки или для разделения баз данных, совместно использующие диски Exadata. Например, диск ячейки может быть секционирован таким образом, что один грид-диск хранится на более высокопроизводительной части физического диска и конфигурирован с тройным зеркалированием, в то время как второй грид-диск хранится на менее производительной части диска и используется для архивирования или хранения резервных копий данных без какого-либо зеркалирования. А стратегия Information Lifecycle Management (ILM – управление жизненным циклом информации) может быть реализована с использованием функциональных возможностей грид-диска.

Рисунок 8: Создание виртуальной среды диска сетки
Следующий ниже пример иллюстрирует соотношение дисков ячейки с грид-дисками в более сложной грид-памяти хранения Exadata.
Как только диски ячейки и грид-диски будут сконфигурированы, для всей конфигурации Exadata определяются дисковые группы ASM. Определяются две дисковых группы ASM: одна для всех "горячих" грид-дисков, а вторая – для всех "холодных" дисков. Все "горячие" грид-диски помещаются в одну дисковую группу ASM, а все "холодные" грид-диски – в другую отдельную дисковую группу. Когда в базу данных загружаются данные, ASM равномерно распределяет данные и операции ввода-вывода по дисковым группам. Для этих дисковых групп может быть активизировано ASM-зеркалирование с целью защиты от отказов дисков для обеих, одной из двух, или для ни одной из дисковых групп. Зеркалирование может быть включено или выключено независимо для каждой из дисковых групп.

Рисунок 9: Пример дисковых групп ASM и зеркалирования
И, наконец, для защиты от отказа всей ячейки Exadata определяются ASM-группы отказа. Группы отказа гарантируют, что зеркалированные ASM-экстенты помещены в различные ячейки Exadata.
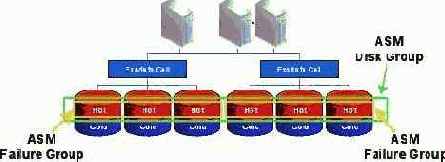
Рисунок 10: Пример ASM-зеркалирования и групп отказа
С Exadata и ASM: Конфигурирование дисков ячейки (создание LUN) автоматизируется программным обеспечением Exadata. Опционально на физическом диске могут сосуществовать несколько грид-дисков, чтобы приспособить производительность к потребностям приложения базы данных или сконструировать стратегию ILM с помощью Exadata. ASM автоматически расщепляет данные базы данных «полосками» по всем дискам и ячейкам Exadata, чтобы обеспечить сбалансированную загрузку ввода-вывода и оптимальную производительность. Динамическое добавление и удаление томов в ASM активирует ненарушающее работу ассигнование ячеек и дисков, а также их освобождение и перераспределение. ASM-зеркалирование и функциональные возможности горячей перестановки ячеек Exadata обеспечивают прозрачную защиту данных и доступ к ним, невзирая на отказы дисков. ASM предусматривает двойное или тройное зеркалирование, чтобы степень защиты данных соответствовала их критичности. В Exadata автоматически создаются ASM-группы отказа, чтобы обеспечить прозрачную защиту данных и доступ к ним, невзирая на отказы дисков.
Управление ресурсами ввода-вывода при работе с Exadata
|
Управление ресурсами ввода-вывода гарантирует, что самая критичная работа получает наивысший приоритет, и на нее не будут оказывать воздействия другие задачами, использующие ресурсы ввода-вывода. |
В традиционной среде хранения, созданной совместно используемой grid-памятью, трудно расположить по приоритетам работу различных заданий и пользователей, расходующих пропускную способность I/O подсистемы хранения. То же самое происходит, когда подсистема хранения совместно используется (разделяется) несколькими базами данных. В числе возможностей DBRM (диспетчер ресурсов базы данных) и управления I/O от Exadata есть способ, чтобы предотвратить ситуацию, когда один класс работ или одна база данных монополизируют дисковые ресурсы и полосу пропускания, и гарантировать, что при использовании среды хранения Exadata будут выполняться определяемые пользователем SLA.
DBRM осуществляет координацию и приоритезацию пропускной способности I/O, потребляемой при обмене между базами данных и между различными пользователями и классами работ. Благодаря сильной интеграции базы данных со средой хранения, Exadata знает о том, какие типы работы и сколько именно потребляется пропускной способности I/O. Поэтому пользователи могут использовать систему Exadata для определения различных типов рабочих нагрузок, назначения приоритетов этим рабочим нагрузкам, а также гарантирования, что самые критичные рабочие нагрузки будут самыми приоритетными.
В средах хранилищ данных или в средах со смешанными рабочими нагрузками можно гарантировать, что различным пользователям и задачам в базе данных будет выделено относительно правильное количество ресурсов I/O. Например, можно пожелать выделить 70% ресурсов ввода-вывода интерактивным пользователям системы и 30% ресурсов ввода-вывода – пакетным заданиям для генерации отчетов. Для этого достаточно ввести принудительное использование функциональных возможностей DBRM и управления I/O в Exadata.
Администратор Exadata может создать план распределения ресурсов, который определяет, как должны быть приоритезированы запросы ввода-вывода. Это достигается путем помещения различных типов работ в сервисные группировки, называющиеся группами потребителей (Consumer Groups). Группы потребителей определяются множеством атрибутов, включая имя пользователя, название программы клиента, функцию или отрезок времени, в течение которого выполнялся запрос. Как только эти группы потребителей определены, пользователь может установить иерархию, в соответствии с которой группа потребителей получает приоритет в распределении ресурсов ввода-вывода, и какая часть I/O ресурсов отдается каждой группе потребителей. Эта иерархия, определяющая установление приоритетов I/O ресурсов, может быть применена одновременно как к операциям внутрибазового обмена данными (то есть, к операциям, происходящим в пределах базы данных), так и к операциям межбазового обмена данными (то есть, к операциям, происходящим между различными базами данных).
Функциональные возможности управления ресурсами ввода- вывода Exadata позволяют устанавливать SLA и приоритеты для различных классов работ, чтобы они основывались на бизнес-потребностях, а не соответствовали стандартному приоритету: первым пришел, первым обслужен. |
В том случае, если среда хранения Exadata совместно используется между несколькими базами данных, можно расположить по приоритетам ресурсы ввода-вывода, выделенные каждой базе данных, чтобы не позволить одной базе данных монополизировать дисковые ресурсы и полосу пропускания и гарантировать, что выполняются определяемые пользователем SLA. Например, на схеме ниже вы представлены две базы данных, совместно использующие среду хранения Exadata.
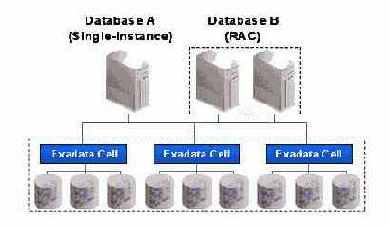
Рисунок 7: Управление ресурсами ввода-вывода для обмена между базами данных при использовании Exadata
Начнем с того, что бизнес-цели диктуют, что каждая из этих баз данных имеет относительную большую значимость и важность для организации. Принято решение, что база данных A должна получать 33% от всех доступных ресурсов ввода-вывода, а база данных B – 67% ресурсов I/O. Для того, чтобы гарантировать выделение в каждой базе данных правильного относительного количества ресурсов I/O различным пользователям и задачам, должны быть определены различные группы потребителей.
Для базы данных A определены две группы потребителей:
60% ресурсов ввода-вывода зарезервировано для интерактивной маркетинговой деятельности 40% ресурсов ввода-вывода зарезервировано для пакетной маркетинговой деятельности
Для базы данных B определены три группы потребителей:
60% ресурсов ввода-вывода зарезервировано для интерактивной деятельности по сбыту 30% ресурсов ввода-вывода зарезервировано для пакетной деятельности по сбыту 10% ресурсов ввода-вывода зарезервировано для действий по сбыту с основными клиентами
Эти выделения ресурсов группам потребителей являются относительными по отношению к полным ресурсам ввода-вывода, выделенных каждой базе данных.
В сущности, диспетчер ресурсов ввода-вывода Exadata разрешил одну из проблем, которую не смогла разрешить традиционная технология сред хранения: создание совместно используемой общедоступной грид-среды хранения с возможностью балансирования и расположения по приоритетам работ нескольких баз данных и пользователей, совместно использующих подсистему хранения. Управление ресурсами ввода-вывода Exadata гарантирует, что определяемое пользователем SLA будет выполнено для нескольких баз данных, совместно использующих среду хранения Exadata. А это гарантирует, что каждая база данных или пользователь получают для выполнения своих бизнес-целей должную долю дисковой полосы пропускания.
Увеличение производительности при применении Exadata
При работе с хранилищами данных среда хранения Exadata обеспечивает непревзойденное повышение производительности для типичных рабочих нагрузок. Полное сканирование таблиц получит произвольно большое ускорение, благодаря фильтрации Smart Scan и сбалансированным аппаратным средствам, используемым для хранилищ данных на базе Exadata. Серверы хранения Exadata обеспечивают такую архитектуру scale-out, чтобы по мере добавления ячеек росла и полоса пропускания конфигурации. Вместе с более быстрым межузловым соединением InfiniBand и сокращением объема передаваемых данных, вызванного переносом части обработки, это приводит к очень большому повышению производительности. Часто при использовании среды хранения Exadata в подобных операциях замечается десятикратное увеличение скорости по сравнению с продуктами для сред хранения, традиционно используемых с Oracle Database, – но во многих случаях было достигнуто 50-кратное или даже еще большее убыстрение.
и шире используют для принятия
Предприятия сегодня все шире и шире используют для принятия важных стратегических решений и анализа данных системы анализа бизнес-информации, чтобы довести до максимума эффективность эксплуатации. Хотя потребность в обработке все большего количества данных растет с каждым днем, корпорации сталкиваются с сокращением своих ИТ-бюджетов, что вынуждает их принимать более трудные решения для оправдания полной стоимости владения (TCO) используемого программного обеспечения и оборудования для ИТ. Благодаря включению Exadata в инфраструктуру ИТ компании смогут: Повысить производительность базы данных и быть в состоянии за то же самое время делать намного больше. Успешно справляться с ростом, так как по мере добавления данных и ячеек также добавляется и пропускная способность средств ввода-вывода. Обеспечить доступность и защиту стратегически важных данных.
Что нужно для работы
Для проверки примеров в этой статье ничего необычного не потребуется. В качестве инструмента будет служить самая обычная базовая поставка СУБД Oracle. Примеры будут использовать транспортный протокол HTTP как наиболее типичный (другими транспортными протоколами для служб web могут быть FTP, SMTP и некоторые более специфичные), и предполагается, что ПО Oracle установлено вместе с HTTP-сервером. В версии Oracle 10 последний поставляется на отдельном диске, а в версиях 8.1 и 9 - вместе с ПО СУБД.
Для удобства расположение каталогов ПО Oracle и HTTP сервера на винчестере будет считаться умолчательным для версий 8.1 и 9. Например, корневым каталогом для HTTP сервера Apache будет считаться c:\oracle\ora92\Apache\Apache\htdocs (в варианте для Windows), или, для краткости, просто htdocs.
Требуется, чтобы СУБД Oracle и HTTP сервер были запущены.
В примере с XSQL подразумевается, что БД носит название ORCL. В общем случае это, конечно, не обязательно.
Опубликование через Java-сервлет
В консольном окошке ОС выполним следующие установки (разновидность соответствует версии 9 и Windows):
set ORACLE_HOME=c:\oracle\ora92 PATH=%PATH%;%ORACLE_HOME%\jdk\bin set CLASSPATH=%ORACLE_HOME%\lib\servlet.jar;.
Составим текст сервлета (программы на Java) в файле ServletForXML.java:
import java.io.IOException; import java.io.PrintWriter; import javax.servlet.ServletException; import javax.servlet.http.HttpServlet; import javax.servlet.http.HttpServletRequest; import javax.servlet.http.HttpServletResponse;
public class ServletForXML extends HttpServlet {
public void service (HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
response.setContentType("text/xml");
PrintWriter out = response.getWriter();
out.println("<cover>"); out.println("<title>Oracle SQL*Loader</title>"); out.println("<author>Jonathan Gennick</author>"); out.println("<author>Sanjay Mishra</author>"); out.println("<pages>269</pages>"); out.println(""); } }
Странслируем сервлет и перенесем файл class в условное (по умолчанию) место для контейнера сервлетов (в данном случае - JServ от Apache):
javac ServletForXML.java move /y ServletForXML.class %ORACLE_HOME%\Apache\Jserv\servlets
В том, что документ опубликован, можно убедиться, обратившись из браузера по адресу http://localhost:7778/servlet/ServletForXML.
Упражнение. Проверьте возможность прочитать опубликованный документ процедурой readxml из предыдущего раздела.
Разумеется, текст сервлета можно усложнить и добавить в него обращение к БД через JDBC и остальное, что позволяет Java.
Опубликование XML-данных в web
Здесь тоже можно действовать по-разному. Ниже будут рассмотрены только два варианта: (1) базовый вариант опубликования через сервлет на Java и (2) более абстрактный, с помощью XSQL. Простейший вариант размещения в htdocs файла XML (что можно в Oracle делать программно, прибегнув к пакету UTL_FILE или через Java) рассматриваться не будет.
Oracle: ваш первый шаг к web-службам
, преподаватель технологий Oracle
Не покупай каштанов, но бери их на пробу.
К. Прутков
Прием сообщений XML в Oracle
Возможность обмена сообщениями в формате XML подразумевает для СУБД Oracle возможность приема таких сообщений с узлов web и возможность их публикации на узлах. Сначала рассмотрим первую возможность. Для этого составим файл mydoc.xml и поместим его в каталог htdocs:
<cover>
<title>Oracle SQL*Loader</title>
<author>Jonathan Gennick</author>
<author>Sanjay Mishra</author>
<pages>269</pages>
</cover>
Наберем в браузере адрес http://localhost:7778/mydoc.xml (здесь и далее - для версии 9; в версии 8.1 http://localhost/mydoc.xml). В окошке должен появиться текст "опубликованного в web" документа.
Для прочтения СУБД XML сообщений в Oracle есть разные способы. Рассмотрим способ совсем простой: с использованием встроенного пакета UTL_HTTP. В составе этого пакета есть процедуры, позволяющие читать заголовок HTTP ответа с web узла и текст сообщения. Вот пример их использования в SQL*Plus:
SET SERVEROUTPUT ON SIZE 40000
DECLARE req utl_http.req; resp utl_http.resp; name VARCHAR2(256); value VARCHAR2(1024);
BEGIN req := utl_http.begin_request
('http://localhost:7778/mydoc.xml'); resp := utl_http.get_response(req);
dbms_output.put_line('HTTP response status code:
' resp.status_code); dbms_output.put_line('HTTP response reason: '
resp.reason_phrase);
dbms_output.put_line('-----');
FOR i IN 1 .. utl_http.get_header_count(resp) LOOP utl_http.get_header(resp, i, name, value); dbms_output.put_line(name ': ' value); END LOOP;
dbms_output.put_line('-----');
LOOP utl_http.read_line(resp, value, TRUE); dbms_output.put_line(value); END LOOP;
EXCEPTION WHEN utl_http.end_of_body THEN
utl_http.end_response(resp); END; /
Результат будет примерно такой:
HTTP response status code: 200 HTTP response reason: OK -- Date: Fri, 28 May 2004 13:01:49 GMT Server: Oracle HTTP Server Powered by Apache/1.3.22
(Win32) mod_plsql/3.0.9.8.3b PHP/4.3.0 mod_ssl/2.8.5
OpenSSL/0.9.6b mod_fastcgi/2.2.12 mod_oprocmgr/1.0 mod_perl/1.25 Last-Modified: Thu, 13 May 2004 15:15:47 GMT ETag: "0-98-40a39123" Accept-Ranges: bytes Content-Length: 152 Connection: close Content-Type: text/xml -- <cover>
<title>Oracle SQL*Loader</title>
<author>Jonathan Gennick</author>
<author>Sanjay Mishra</author>
<pages>269</pages>
</cover>
Процедура PL/SQL успешно завершена.
SQL> ...
Построить процедуру получения XML документа на основе текста выше - дело техники. Разумно включить в процедуру проверку поля Content-Type ответа HTTP. Получится примерно следующее:
DECLARE xmldoc VARCHAR2(4000) := ''; ok BOOLEAN := FALSE;
PROCEDURE readxml(url IN VARCHAR2,
doc OUT VARCHAR2, success OUT BOOLEAN) IS req utl_http.req; resp utl_http.resp; name VARCHAR2(256); value VARCHAR2(1024);
BEGIN doc := ''; req := utl_http.begin_request(url); resp := utl_http.get_response(req);
success := resp.status_code = 200; IF success THEN FOR i IN 1 .. utl_http.get_header_count(resp) LOOP utl_http.get_header(resp, i, name, value); success := name = 'Content-Type' AND
value = 'text/xml'; EXIT WHEN success; END LOOP;
IF success THEN LOOP utl_http.read_line(resp, value, TRUE); doc := doc value; END LOOP; END IF; END IF;
EXCEPTION WHEN utl_http.end_of_body THEN
utl_http.end_response(resp); END;
BEGIN readxml('http://localhost:7778/mydoc.xml',
xmldoc, ok); IF ok THEN dbms_output.put_line(xmldoc); ELSE dbms_output.put_line('Not XML
or bad URL'); END IF; END; /
Более практично использовать для считываемого документа тип CLOB, а не VARCHAR2. Но это бы усложнило пример, а к сути не относится, и поэтому здесь не рассматривается. Так же ради простоты не рассматриваются технические вопросы форматирования текста документа.
Полученный таким образом текст XML документа можно помещать в БД или подвергать обработке.
То же самое можно в Oracle делать не только в PL/SQL, но и на Java.
Службы web
Web-службы - пока еще перегретое (точнее - "подогретое") понятие, и поэтому в его объеме и содержании существуют определенные путаница и произвол. Общее определение иногда формулируют : обмен в сети web сообщениями с узлами в формате XML.
На основе этого общего понятия скоро возникла специфичная разновидность под названием XML-RPC. XML-RPC - возможность запускать на узлах web удаленные процедуры, пользуясь XML для оформления запросов и ответов. Если есть узел web с сервером XML-RPC, то любая клиентская программа может пользуясь специальными правилами составления на XML запроса обратиться к серверу и получить в ответ результат вычислений.
Еще позже у архитекторов разработчиков технологий XML возникло желание построить более универсальную специфичную разновидность простого обмена сообщениями. Захотелось иметь такую службу в web, чтобы она обладала свойствами (а) самоописания и (б) самообнаружения. Реализовано это было под названием SOAP. Клиентская программа может осуществить на XML поиск нужной службы SOAP, запросить ее правила использования и воспользоваться ею.
Несмотря на то, что XML-RPC и SOAP являются воплощениями служб web - относительно изощренными, - простой обмен сообщениями XML (лежащий в основе этих технологий) тоже остается таковым и даже имеет свою самоценность. Самолет - современное средство перемещения, однако в деревню за молоком вы, наверное, поедете на велосипеде.
Ниже будут показаны некоторые способы, позволяющие выполнять такой обмен между БД под управлением Oracle и web, не прибегая к знаниям разного рода хитроумных сокращенний, дополнительных понятий и специальных технологий.
Выдача данных из БД с помощью XSQL
В версии Oracle 9.2 появилась еще одна возможность опубликования в web документов в формате XML на основе данных их БД. Хотя технически она основывается на использовании сервлета так, как это было описано только что, она не требует от потребителя знания Java, но зато может потребовать более досконального знания технологий XML. Эта возможность носит название XSQL.
В каталогах ПО Oracle в результате типовой установки образуется каталог c:\oracle\ora92\xdk\demo\java\xsql. Создадим там свой рабочий каталог myxsql. Заведем файл с именем emps.xsql:
<?xml version="1.0"?>
<page connection="demo" xmlns:xsql="urn:oracle-xsql">
<xsql:include-request-params/>
<xsql:query tab="EMP" null-indicator="yes" >
SELECT * FROM {@tab}
</xsql:query>
</page>
Обратимся из браузера по адресу http://localhost:7778/xsql/myxsql/emps.xsql?tab=emp. Данные из Oracle опубликованы в web.
Упражнение. Замените в адресе tab=emp на tab=dept, потом на tab=bonus; наблюдайте результат. Уберите из адреса параметр запроса (знак вопроса и все, что справа от него). Наблюдайте результат.
Может возникнуть вопрос: как Oracle распознает, что запрашивать следует таблицы в схеме SCOTT, если мы нигде этого не указали ? На самом деле указали. Обратите внимание на фрагмент connection="demo" в тексте выше. Ссылка на БД и схему спрятана под именем demo. Обратитесь к файлу XSQLConfig.xml в каталоге с:\oracle\ora92\xdk\admin и найдите определение этой ссылки. Это будет БД ORCL и схема SCOTT. При желании эту ссылку можете переопределить, или добавить собственную.
Сервлет, который фактически обрабатывает запросы формата XSQL, интересен тем, что умеет обрабатывать поля типов XMLTYPE и объектов, а также типа коллекции, в том числе вложенные, и иерархии вложенных курсоров (на последние обстоятельства мое внимание обратил ). Например, подправим таблицу EMP следующим образом:
CREATE TYPE typ_va IS VARRAY(10) OF VARCHAR(20); /
CREATE TYPE typ_obj IS OBJECT (city VARCHAR2(20), street VARCHAR2(20)); /
ALTER TABLE emp ADD (xmlc XMLTYPE, vac typ_va, addr typ_obj);
UPDATE emp SET xmlc = XMLTYPE(<a>bbb</a>) , vac = typ_va('Alice', 'Bob') , addr = typ_obj('Ленинград', 'Невский') WHERE ename='SMITH';
COMMIT;
Результат можно наблюдать по старому адресу http://localhost:7778/xsql/myxsql/emps.xsql. Обратите внимание на отсутствие проблем с русскими буквами.
XSQL полезен тем, что позволяет осуществлять публикацию не только в формате XML, но это уже выходит за рамки настоящей статьи.
