Имена объектов, ключевые и зарезервированные слова
История этой задачки началась с форума Oracle на , куда я однажды случайно забрел. Один из участников форума пытался перенести в Oracle схему БД, подготовленную в другой системе. В таблице было поле, названное NUMBER. Очевидно, в нем хранилось какое-то число; с этим-то полем в Oracle и случилась незадача. Ее раскрывает следующий (уже мой) пример:
SQL> CREATE TABLE t(number NUMBER); CREATE TABLE t(number NUMBER) * ERROR at line 1: ORA-00904: : invalid identifier
Автор вопроса правильно сообразил, что NUMBER - это зарезервированное в Oracle слово (мы помним, что перед обработкой предложения SQL Oracle повышает регистр букв в именах объектов), и ошибка возникает при синтаксическом разборе. В документации про ошибку ORA-00904 сказано: "… [column name] may not be a reserved word". Раз уж говорим о заморочках, обратите внимание на текст сообщения: между двумя двоеточиями по замыслу разработчиков должно стоять то самое неправильное имя, а в нашем случае оно оказалось настолько неправильным, что не попало в результат синтаксического анализатора ! Не самый большой грех в Oracle, но ведь по теме статьи.
Неужели перенося базу в Oracle придется править схему, а значит и приложение ? Если не выход, то лазейку из положения автор вопроса в форум нашел правильно. Заключив имя объекта в Oracle в двойные кавычки мы приобретем право использовать абсолютно любые доступные в кодировке символы, хоть звездочки, хоть точки, хоть пробелы:
SQL> CREATE TABLE t(" ./()*" NUMBER, "NUMBER" NUMBER);
Table created.
SQL> DESCRIBE t Name Null? Type ------------------- -------- ---------------------- ./()* NUMBER NUMBER NUMBER
SQL> ALTER TABLE t DROP COLUMN " ./()*";
Table altered.
SQL> DESCRIBE t Name Null? Type ------------------- -------- ---------------------- NUMBER NUMBER
Если смириться с неудобством двойных кавычек, это вполне рабочий вариант:
SQL> INSERT INTO t VALUES (123);
1 row created.
SQL> UPDATE t SET "NUMBER" = "NUMBER";
1 row updated.
Беда в том, что точно та же команда UPDATE, равно как и любая другая, обращающаяся к столбцу "NUMBER", не работает в PL/SQL:
SQL> BEGIN UPDATE t SET "NUMBER" = "NUMBER"; END; 2 / BEGIN UPDATE t SET "NUMBER" = "NUMBER"; END; * ERROR at line 1: ORA-06550: line 1, column 53: PL/SQL: ORA-06552: PL/SQL: Compilation unit
analysis terminated ORA-06553: PLS-320: the declaration of the type
of this expression is incomplete or malformed ORA-06550: line 1, column 25: PL/SQL: SQL Statement ignored
Это и вызвало недоумение автора вопроса в форум. В Oracle уверяют, что начиная с версии 9 (которая помогала готовить эту статью) обработка запросов в SQL и в PL/SQL ведется одним и тем же модулем СУБД. И тем не менее факт налицо: SQL терпит обращение к полю "NUMBER", а PL/SQL - нет.
Заинтересовавшись, после серии экспериментов я нащупал очередную уступку Oracle, позволившую достичь компромисса, но сообщить найденное решение автору вопроса уже не смог, так как sql.ru оказался для меня слишком сложно устроен: он не только требует регистрации (а придуманные себе кличку и пароль я назавтра же забыл), но и содержит чересчур много "нитей", среди которых "свою" я безнадежно потерял.
Вот что выяснилось: PL/SQL начинает все обрабатывать правильно, как только в названии столбца появляется хотя бы одна малая буква, например, не "NUMBER", а "NuMBER". Лучше, конечно, "number". Возникает вопрос: в чем причина такого странного поведения ?
Переписка с разработчиками PL/SQL несколько прояснила ситуацию. Можно посочувствовать: им приходится расплачиваться по счетам самой логики жизни. В любом языке есть множество зарезервированных слов, которые нельзя использовать для имен объектов. В Oracle первую очередь это ключевые слова: BEGIN, SELECT и другие. Заметьте кстати, что множества зарезервированных слов Oracle в SQL и PL/SQL не совпадают:
SQL> CREATE TABLE t1 (begin NUMBER);
Table created.
SQL> UPDATE t1 SET begin = 1;
0 rows updated.
SQL> BEGIN UPDATE t1 SET begin = 2; END; 2 /
PL/SQL procedure successfully completed.
SQL> DECLARE begin NUMBER; BEGIN NULL; END; 2 / DECLARE begin NUMBER; BEGIN NULL; END; * ERROR at line 1: ORA-06550: line 1, column 38: PLS-00103: Encountered the symbol "end-of-file"
when expecting one of the following: ... ... ... ...
(Но, конечно же:
SQL> DECLARE "begin" NUMBER; BEGIN NULL; END; 2 /
PL/SQL procedure successfully completed.
)
Однако жизнь бывает сложнее, чем иногда хотелось бы. Вопреки утверждению документации по Oracle (сказали разработчики PL/SQL) не все ключевые слова являются зарезервированными. Вызвано это тем, что язык живет, и в нем могут появляться новые ключевые слова, которые кто-то, когда они еще не были ключевыми, мог использовать для названий объектов. Запрет вдруг их такового употребления способен был бы вызвать возмущение пользователей, принужденных переделывать имеющиеся БД и приложения. Отсюда и отклонения от идеального равенства "ключевые слова" = "зарезервированные слова". Нагладный пример: до версии 9 в Oracle не было типа TIMESTAMP, и многие использовали это слово для именования поля в таблице. В версии 9 эту вольность (по законам новой версии) употребления пришлось оставить, хотя и удалось это не совсем последовательно:
SQL> ALTER TABLE t1 ADD (timestamp TIMESTAMP);
Table altered.
SQL> UPDATE t1 SET timestamp = SYSTIMESTAMP;
SQL> DECLARE t TIMESTAMP; BEGIN t := SYSTIMESTAMP; END; 2 /
PL/SQL procedure successfully completed.
SQL> DECLARE timestamp NUMBER; BEGIN timestamp := 1; END; 2 /
PL/SQL procedure successfully completed.
но, правда
SQL> DECLARE timestamp TIMESTAMP; BEGIN timestamp := NULL; END; 2 / DECLARE timestamp TIMESTAMP; BEGIN timestamp := NULL; END; * ERROR at line 1: ... ... ... ...
Есть в Oracle и другое правило, уже наблюдавшееся выше по тексту: и в SQL, и в PL/SQL заключение имени объекта в двойные кавычки сравнение со списком зарезервированных слов отменяет:
SQL> DECLARE "timestamp" TIMESTAMP; BEGIN "timestamp" := NULL; END; 2 /
PL/SQL procedure successfully completed.
Это и объясняет срабатывание примера, с которого начался этот раздел, при замене "NUMBER" вместо NUMBER.
Все это можно понять. А остался ли за Oracle какой-нибудь грех ? Не без того. Разработчики PL/SQL признались: несмотря на то, что с версии 9 обработка SQL в PL/SQL и в качестве самостоятельных команд происходит одинаково, список зарезервированных слов в PL/SQL свой (по-прежнему) собственный, и, как оказалось, не всегда совпадает со аналогичным списком в SQL там, где он бы должен совпадать. Это и привело к непредусмотренному архитекторами Oracle результату при попытке обратиться к полю "NUMBER" в PL/SQL. Иными словами, это ошибка разработчиков, которая сохранилась в нынешней версии 10.1, и которую пообещали исправить в будущем.
Как сделать функцию невидимой
Следующий пример показывает архитектурное упущение создателей Oracle. Оно обязано одному из недальновидных решений, принятых в первых версиях Oracle, очевидно в угоду скорости утверждения на рынке. Позже, подобно некоторым другим подобным в этом отношении "ранним" решениям Oracle, исправить положение дел уже не представилось возможным.
К счастью, проблема неожидаемой маскировки объекта в БД, о которой пойдет речь, довольно специфична. Однако ж она вполне реальна.
Рассмотрим пример функции в схеме SCOTT:
SQL> CREATE FUNCTION ename RETURN VARCHAR2 AS 2 BEGIN RETURN 'I am a function'; END; 3 /
Function created.
Это не запрещено, несмотря на наличия поля ENAME в одной из таблиц схемы, так как пространства имен функций и столбцов не пересекаются (и правильно !). Но что произойдет, если к ней обратиться при выборке данных из таблицы EMP ? Если выполнить следующий запрос, что мы увидим: столбец или функцию ?
SELECT ename FROM emp;
Правильный ответ дает документация, где в одном из бесчисленных закоулков перечислена последовательность обработки имен объектов в предложениях SQL. Однако в данном случае гораздо проще изматывающего поиска в документации поставить эксперимент и убедиться, что по принципу "своя рубашка ближе к телу" СУБД выдаст значения столбца таблицы.
Закономерно возникает вопрос: а как при обращении к EMP выдать значение функции ENAME ? Несложные эксперименты приводят к необходимости указать полное имя функции, снабдив его именем схемы:
SELECT scott.ename, ename FROM emp;
Или же (что в некоторых смыслах более правильно)
SELECT scott.ename, emp.ename FROM emp;
Крайне неудачная система обозначений (в SCOTT.ENAME SCOTT - это имя схемы, а в такой же по виду записи EMP.ENAME EMP - это имя таблицы), но свое дело она делает. К сожалению, этим дело не кончается. Пространства имен схем и пакетов тоже разные, что тоже правильно. Рассмотрим теперь следующее:
CREATE OR REPLACE PACKAGE scott IS FUNCTION ename
RETURN varchar2; END scott; /
CREATE OR REPLACE PACKAGE BODY scott IS FUNCTION ename RETURN varchar2 IS BEGIN RETURN 'I am a package function'; END ename; END scott; /
SELECT scott.ename FROM emp;
Убедитесь, что получим 'I am a package function'. Но теперь, обращаясь к EMP мы никогда не увидим результат самостоятельной (не пакетированной) функции ENAME ! Если в вашем приложении были запросы типа SELECT scott.ename FROM emp, то после создания пакета они начнут выдавать попросту другой ответ.
Способ формирования составных имен не идеален и в других языках. Например, даже в таком архитектурно продуманном языке, как Java, понять по тексту смысл каждой компоненты в имени java.lang.System.out.println без дополнительной информации невозможно. Но другой системы, кроме Oracle, где допускалось бы исчезновение видимости имени одного объекта вследствие вполне законного заведения других, мне неизвестно.
Рекурсивные вызовы
PL/SQL в Oracle относится к языкам, в которых рекурсивные вызовы подпрограмм разрешены. В теле одной подпрограммы можно обратиться к самой себе, или же, например, к другой, а та, в свою очередь к первой. Рекурсия иногда удобна. Пример из учебников - вычисление факториала. Более жизненный пример - размечивание весами древовидной структуры, позволяющее организовать быстрый доступ к хранимому в БД справочнику без привлечения нестандартных и несовместимых конструкций (в Oracle это конструкция CONNECT BY).
Особенность в том, что машина PL/SQL в СУБД Oracle никак не регламентирует глубину повторных обращений, что оставляет лазейку "бесконечного" зацикливания. Ответственность за его возникновение СУБД перекладывает на программистов. Хуже того, организовать такое зацикливание может любой пользователь, обладающий всего только-то привилегией CREATE SESSION:
SQL> CONNECT / AS SYSDBA Connected. SQL> CREATE USER adam IDENTIFIED BY eva;
User created.
SQL> GRANT CREATE SESSION TO adam;
Grant succeeded.
SQL> CONNECT adam/eva Connected.
Прежде чем двигаться дальше, удостоверьтесь, что вы готовы перезагрузить свою БД.
SQL> DECLARE PROCEDURE a IS BEGIN a; END; BEGIN a; END; /
Дальнейшее лучше наблюдать какой-нибудь программой ОС, показывающей использование процессорного времени и оперативной памяти.
Во-первых, сеанс пользователя ADAM начинает жадно расходовать процессорное время. Другие сеансы связи с СУБД это сразу почувствуют.
Во-вторых, сеанс пользователя ADAM начинает неумолимо захватывать оперативную память во все больших и больших количествах. Пусть не сразу, но другие сеансы связи с СУБД почувствуют и это.
Если ваша база загружена какой-то реальной работой, проделанная простая операция - эффективный способ дезорганизовать эту работу. У меня ни разу не хватило терпения дождаться, когда Oracle исчерпает всю оперативную память, и проверить его способность самому переварить проблему. Но если не препринять заблаговременных мер по нейтрализации подобных диверсий, даже естественная попытка убить вредоносный сеанс не будет простой. Сначала из-за страшно медленной реакции СУБД на ваши действия от имени SYS, а потом из-за страшно медленного освобождения памяти после команды ALTER SYSTEM KILL SESSION.
Вопрос, стоило ли разработчикам Oracle оставлять возможность неограниченной рекурсии, способен разжечь спор. Но сделано то, что сделано: Oracle награждает нас здесь одновременно со свободой действий и риском потери нормальной работы СУБД.
к тому, что СУБД Oracle
Большинство специалистов склоняется к тому, что СУБД Oracle представляет собой наиболее полноценную и эффективную SQL-машину среди прочих. К сожалению это не означает автоматически, что Oracle безгрешна. С одной стороны, работа с Oracle нередко доставляет истинное удовольствие (особенно любителям найти красивое решение), но с другой - разочарование и раздражение.
Эта заметка продолжает серию статей о возможностях Oracle, но выбор самих возможностей необычен. Речь пойдет о неудобных или даже неприятных возможностях - хотя бы и потенциально неприятных. Признаться, некоторые колебания в целесообразности подобной публикации у меня были, но ведь многие читатели доверяют СУБД Oracle самое святое - бизнес, и поэтому знать, откуда ждать беду они просто обязаны. В более безобидном варианте знание некоторых "заморочек от Oracle" способно улучшить ваше понимание этой системы.
По сути это заключение является
По сути это заключение является лирическим отступлением, на мой взгляд способным несколько сгладить то негативное мнение о СУБД Oracle, которое способна породить эта статья. Дело в том, что среди писем от разработчиков, которые я получил расследуя последнюю описанную проблему, неожиданно оказалось письмо от Кена Джекобса. Напомню, это вице-президент компании Oracle, второй по размеру в области разработки ПО. Конечно, не он дал исчерпывающий ответ, это сделал другой специалист (к слову сказать, тоже не низшей должности), но он обратил внимание на проблему. Сам факт такой реакции мне показался крайне симпатичным и симптоматичным. Представьте себе компанию с оборотами в десятки миллиардов долларов, на втором уровне иерархии управления которой имеются технические специалисты, а не специалисты по рекламе, связям с общественностью и организации денежных потоков ! Это так непохоже на некоторые соразмерные Oracle однопрофильные компании и (увы) на все отечественные (за отсутствием таковых, соответственно другого профиля).
Конкретно меня такое положение дел побуждает смотреть на грехи разработчиков Oracle, по крайней мере отчасти, сквозь пальцы. Кстати, если у вас есть что добавить в приведенную коллекцию, буду рад получить от вас письмо.
Заморочки от Oracle, или знать бы, где упасть
Преподаватель технологий Oracle
... "Да вот веревкой хочу море морщить
Да вас, проклятое племя, корчить".
А. С. Пушкин,
Сказка о попе и его работнике Балде
Два критерия профессионализма программирования Oracle: (1) употребление ссылки на курсор в программе
Преподаватель технологий Oracle
Церковь была отворена, за оградой стояло несколько саней;
по паперти ходили люди.
«Сюда! сюда!» — закричало несколько голосов ...
А. С. Пушкин, «Метель»
Ограничения использования ссылки на курсор
Мысли, возникающие по поводу возможного использования ссылок на курсор в программе, несколько осаждаются существующими ограничениями, часть которых, если вдуматься, имеют свою логику. Как упоминалось, ссылки на курсор не представлены типом SQL (до некоторой степени это естественно), и не могут храниться в качестве переменных пакета PL/SQL. Более полно: ссылки на курсор не могут объявляться как переменные пакета PL/SQL и их нельзя передавать через переменные пакета
ссылкам на курсор нельзя присваивать значение NULL (в версии 10 уже можно) и их нельзя сравнивать друг с другом (но их можно присваивать друг другу)ссылки на курсор нельзя хранить в столбцах таблиц и в элементах коллекцииссылки на курсор нельзя передавать от сервера к серверу с помощью RPCссылки на курсор нельзя использовать с пакетом DBMS_SQL
ссылки на курсор не допускают над собой выражений.
Описание ссылки на курсор и использование в PL/SQL
На каком бы языке вы не общались с БД посредством ссылки на курсор, без программирования на PL/SQL не обойтись. Формальная сторона работы со ссылкой на курсор в PL/SQL обставлена просто.
Во-первых, чтобы завести в PL/SQL переменную-ссылку на курсор, нужно сначала описать ее тип. Это делается в разделе описания с помощью предложения TYPE:
TYPE имя_типа_ссылки_на_курсор IS REF CURSOR [RETURN тип_записи];
Если конструкция RETURN присутствует, ссылка на курсор называется строгой; если нет – нестрогой. Нестрогая может ссылаться на любой курсор (запрос), а строгая – только на тот, что возвращает результат указанного типа.
Пример описания обоих типов ссылки на курсор:
DECLARE TYPE any_curtype IS REF CURSOR; generic_curvar any_curtype;
TYPE departments_curtype IS REF CURSOR RETURN dept%ROWTYPE; departments_cur departments_curtype;
BEGIN NULL; END; /
Открытие курсора с помощью переменной-ссылки на курсор: OPEN ссылка_на_курсор FOR предложение_SELECT;
Команды FETCH и CLOSE используются как обычно, толькот вместо имени курсора указываем имя ссылки на курсор.
Во-вторых, для удобства программирования поддерживается «системный» тип SYS_REFCURSOR нестрогой ссылки на курсор. Так, в блоке выше, в разделе описания можно было бы не приводить предложение TYPE, а сразу сказать: generic_curvar SYS_REFCURSOR;
Тип SYS_REFCURSOR сокращает текст программы, а иногда позволяет и обойтись без создания служебного пакета (пример чего в этой статье не рассматривается).
Пример программирования в Java
В клиентской программе на Java обращаться к БД через ссылку на курсор можно с помощью собственных расширений, сделанных фирмой Oracle в реализации ею драйвера JDBC. В программе ниже предполагается имя СУБД MYDB. Обратите внимание, что текст с запросом SQL передается нашему пакету объектом класса CallableStatement, а извлечение в программу ссылки на курсор делается после приведения этого объекта к сугубо Oracle’овскому классу OracleCallableStatement.
Получение в программу ссылки на курсор соответствует формированию объекта класса ResultSet, обработка которого делается стандартно.
Выдача второго запроса в программе ниже демонстрирует возможность использования одного и того же пакета для получения результата разной структуры. Очевидно, по своей гибкости эта техника находится посередине между тем, что имеется в PL/SQL и в SQL*Plus.
Подготовим файл GenericRefCursor.java: import java.sql.DriverManager; import java.sql.Connection; import java.sql.CallableStatement; import java.sql.ResultSet; import oracle.jdbc.driver.OracleCallableStatement; import oracle.jdbc.driver.OracleTypes;public class GenericRefCursor
{public static void main ( String[] args ) {
try { DriverManager.registerDriver ( new oracle.jdbc.driver.OracleDriver ( ) );
Connection cn; cn = DriverManager.getConnection ( "jdbc:oracle:oci:@mydb", "scott", "tiger" );
CallableStatement cst; OracleCallableStatement ocst; ResultSet rs;
cst = cn.prepareCall ( "BEGIN generic_ref_cursor.get_ref_cursor ( ?, ? ); END;" ); cst.setString ( 1, "SELECT sal FROM emp" ); cst.registerOutParameter ( 2, OracleTypes.CURSOR );
cst.execute ( );
ocst = ( OracleCallableStatement ) cst;
rs = ocst.getCursor ( 2 );
while ( rs.next ( ) ) { System.out.println ( rs.getInt ( 1 ) ); }
/* Новый запрос ... */ cst.setString ( 1, "SELECT dname, loc FROM dept" ); cst.execute ( ); rs = ocst.getCursor ( 2 ); while ( rs.next ( ) ) { System.out.println ( rs.getString ( 1 ) + rs.getString ( 2 ) ); }
/* ... и так далее, запрос за запросом */ cst.close ( ); } catch ( Exception e ){System.out.println ( e ); } }
}
В ОС оттранслируем класс GenericRefCursor и выполним программу: >javac GenericRefCursor.java >java GenericRefCursor
Пример программирования в PL/SQL
В этом примере с помощью нашего пакета открываем курсор и передаем ссылку на курсор в программу. Извлечение результатов предложений SELECT выполняется отдельными процедурами, причем для результатов с разной структурой мы вынуждены предусмотреть разные процедуры извлечения. Это – плата за минимализм и общность пакета.
Выдадим в SQL*Plus: SET SERVEROUTPUT ON
DECLARE lrc SYS_REFCURSOR;
PROCEDURE fetchandclose ( rc IN sys_refcursor) IS somename VARCHAR2 ( 20 ); BEGIN DBMS_OUTPUT.PUT_LINE ( '------------------------------' ); LOOP FETCH rc INTO somename; EXIT WHEN rc%NOTFOUND; DBMS_OUTPUT.PUT_LINE ( somename ); END LOOP; CLOSE rc; END; PROCEDURE fetch2andclose ( rc IN sys_refcursor) IS somename VARCHAR2 ( 20 ); somenumber NUMBER; BEGIN DBMS_OUTPUT.PUT_LINE ( '------------------------------' ); LOOP FETCH rc INTO somename, somenumber; EXIT WHEN rc%NOTFOUND; DBMS_OUTPUT.PUT_LINE ( RPAD ( somename, 10, ' ' ) somenumber ); END LOOP; CLOSE rc; END;
BEGIN -- Примеры:generic_ref_cursor.get_ref_cursor ( 'SELECT ename FROM emp', lrc ); fetchandclose ( lrc );
generic_ref_cursor.get_ref_cursor ( 'SELECT dname FROM dept', lrc ); fetchandclose ( lrc );
generic_ref_cursor.get_ref_cursor ( 'SELECT job, sal FROM emp', lrc ); fetch2andclose ( lrc ); END; /
(Чтобы не усложнять пример, результат на экране почти не оформляется).
Обратим внимание: программам, обрабатывающим по общей схеме однотипные курсоры, мы передаем не тексты запроса, а ссылки на уже открытый и динамически (а не статически, как в случае его определения в отдельном пакете) сформированный курсор.
Пример программирования в SQL*Plus
SQL*Plus позволяет заводить собственные переменные, в том числе и типа нестрогой ссылки на курсор. Открывается курсор, как и в примере выше, нашим пакетом, а вот извлечение возможно обычной командой PRINT. Эта команда умеет распознавать структуру фактического курсора, что очень удобно для работы.
Выдадим в SQL*Plus: VARIABLE refcur REFCURSOR
BEGIN generic_ref_cursor.get_ref_cursor ( 'SELECT ename, sal FROM emp', :refcur ); END; /
PRINT refcur
BEGIN generic_ref_cursor.get_ref_cursor ( 'SELECT * FROM emp', :refcur ); END; /
PRINT refcur
В отличие от предыдущего примера команда PRINT закрывает курсор, так что вторичная выдача PRINT refcur
приведет к ошибке.
Создание пакета в PL/SQL
Приводимые ниже примеры в каждой из трех сред программирования будут использовать для доступа к БД через ссылку на курсор один и тот же пакет. В реальной жизни именно на подобный пакет и ляжет описание требуемой программной логики. Тут же он воимя наглядности устроен максимально просто, (почти) безо всякой программно-прикладной логики, но это обстоятельство и обеспечивает ему универсальность.
Выдадим в SQL*Plus: CONNECT scott/tiger
CREATE OR REPLACE PACKAGE generic_ref_cursor AS PROCEDURE get_ref_cursor(sqlselect IN VARCHAR2, rc OUT sys_refcursor); END; /
CREATE OR REPLACE PACKAGE BODY generic_ref_cursor AS PROCEDURE get_ref_cursor(sqlselect IN VARCHAR2, rc OUT sys_refcursor) AS BEGIN OPEN rc FOR sqlselect; END; END; /
В реальной практике такому выхолощенному пакету вполне может найтись свое место, однако часто будут использоваться и другие, общие с приведенным выше только тем, что
(а) в теле будет обязательно присутствовать предложение OPEN
(б) среди параметров должен присутствовать выходной типа ссылки на курсор (возможно строгой).
Остальное регламентируется исключительно логикой приложения и организации программы.
Ссылки на курсор
В пору моего обучения в техническом ВУЗе люди, как и сечас, были склонны называть себя как угодно, и в народе бытовал критерий настоящего математика. Право им назваться отдавалось тому, кто знал, что такое поле Галуа. Таки не ставши математиком, не берусь судить о корректности этого критерия (сдается, он ребяческий), однако занимаясь Oracle, могу предложить другой критерий профессионализма: для программиста этой СУБД.
В диалекте SQL, придуманном фирмой Oracle, есть много разных конструкций, не всякому известных; например, для аналитические функции, или же средства для работы с рукотворными объектами. Но это вещи специфические, не каждому программисту потребные, а вот ссылки на курсор – явление безусловно общего характера.
Ссылка на курсор дает возможность не заводить структуры курсора (CURSOR … IS …) в клиентской программе, а ограничиться в ней выделением памяти только для адреса курсора, в то время как сам курсор будет располагаться целиком в СУБД. Программист способен прожить и без ссылок на курсор, однако те могут дать программам заметные конструктивные выгоды:
Они позволяют перенести программную логику на сервер. Клиентские приложения оказываются не так жестко привязаны к конкретным запросам; одни и те же запросы могут вызываться с одинаковым эффектом из программ на PL/SQL, C или Java.
Они позволяют перенести вычислительную нагрузку на сервер.
Поскольку принципиально для программирования ссылки на курсоры не нужны, большинство разработчиков обходится обычным способом общения с СУБД. Выгоды же извлекают программисты, которых и можно в данном контексте признать профессионалами.
Ссылки на курсор реализованы в Oracle программно и в SQL. В программе они реализуются в виде специальной переменной, и именно этот вариант показан в этой статье. Клиентскими средами будут выступать PL/SQL, SQL*Plus и Java.
Два критерия профессионализма
Преподаватель технологий Oracle
... Родила царица в ночь
Не то сына, не то дочь;
Не мышонка, не лягушку,
А неведому зверюшку.
А. С. Пушкин, «Сказка о царе Салтане»
Применение в XSQL
В некоторых случаях использование курсорного выражения в SELECT дает выгоду и вне программы.
Средства XSQL, поставляемые в рамках штатной поставки ПО СУБД Oracle («XML Development Kit», XDK), позволяют хранить на сервере web сервлет, порождающий по запросу SELECT к базе данных документ XML. Этот сервлет способен обрабатывать ссылки на курсор, порождаемые курсорным выражением.
Подготовим файл departments.xsql: <?xml version="1.0"? <xsql:query connection="demo" xmlns:xsql="urn:oracle-xsql" SELECT dname ,CURSOR ( SELECT ename FROM emp WHERE emp.deptno = dept.deptno )
AS employees
FROM dept </xsql:query
Создадим каталог company в месте файловой системы, предусмотренным в Oracle для расположения файлов формата XSQL. Например, при установленном расширении XDK ПО Oracle версии 9.2 этим местом может быть $ORACLE_HOME/xdk/demo/java. Обратимся браузером по адресу
http://localhost:7778/xsql/company/departments.xsql (сервер HTTP при этом должен быть запущен). Получим примерно такой результат:

В этом изображении для краткости узлы ROW с атрибутами num = "2" и num = "3" свернуты средствами браузера.
Полученный документ XML может играть для сервера приложений в web как самостоятельную роль (выдавая результат обращений по определенному адресу в web в формате XML), так и роль исходного материала для дальнейшего преобразования XSL (выдавая результат в конечном итоге в формате HTML, в том числе с графическим оформлением). Эти преобразования здесь не рассматриваются, как не относящиеся к возможностям собственно Oracle.
Замечательно, что обрабатывающий запросы XSQL сервлет, разработанный фирмой Oracle, способен обрабатывать не только одиночные, но и вложенные выражения типа CURSOR. Подготовим еще один файл multicursor.xsql и положим его в тот же каталог company: <?xml version="1.0"? <xsql:query connection="demo" xmlns:xsql="urn:oracle-xsql" SELECT TO_CHAR ( SYSTIMESTAMP,'SS:FF3' ) AS seconds , CURSOR ( SELECT TO_CHAR ( SYSTIMESTAMP,'SS:FF3' ) secondsone , CURSOR ( SELECT TO_CHAR( SYSTIMESTAMP,'SS:FF3' ) AS secondstwo
FROM DUAL ) AS leveltwo
FROM DUAL ) AS levelone
FROM dept </xsql:query
Таблица DEPT здесь взята только ради примера из малого числа строк.
Обратимся браузером по адресу
http://localhost:7778/xsql/company/multicursor.xsql и увидим примерно такой результат:

Как и в первом случае, некоторые узлы документа свернуты средствами браузера ради экономии в статье места, занимаемого картинкой.
Обращение к SYSTIMESTAMP позволяет наблюдать процесс вычисления ответа сервлетом Oracle.
Нетрудно сообразить, что в случае «запроса» на XSQL, равно как и в случае запроса с курсорным выражением в SQL*Plus, мы имеем дело с иллюзией отсутствия программной обработки, которая на деле присутствует в тексте сервлета и в SQL*Plus, во встроенном виде. Но ведь также мы имеем дело с иллюзией таблицы, работая с view, что никоим образом не снижает практической ценности этого понятия.
Программная обработка
Рассмотрим следующий пример блока PL/SQL, где используется (а) обычный курсор для SELECT и (б) курсорное выражение внутри: SET SERVEROUTPUT ON
DECLARE CURSOR main_cur IS SELECT dname , CURSOR ( SELECT ename FROM emp WHERE emp.deptno = dept.deptno )
FROM dept ; deptname dept.dname%TYPE; empname emp.ename%TYPE; inner_cur SYS_REFCURSOR;
BEGIN OPEN main_cur; LOOP FETCH main_cur INTO deptname, inner_cur;
EXIT WHEN main_cur%NOTFOUND; dbms_output.put_line ( '-----------------' deptname ); LOOP FETCH inner_cur INTO empname; EXIT WHEN inner_cur%NOTFOUND; dbms_output.put_line( empname ); END LOOP; CLOSE inner_cur; END LOOP; CLOSE main_cur; END; /
В результате такой организации запроса мы не просто выдали список отделов и их сотрудников, но смогли обработать каждый раз возникающий перечень сотрудников программно. Если бы не было выражения CURSOR, такого рода программную обработку можно было бы организовать только заведя в программе два курсора, а не один (а при использовании в одном предложении SELECT сразу нескольких
курсорных выражений, возможно вложенных, – более чем два).
Более того, этот один программный курсор с выражениями CURSOR просто и точно указывает на логику обработки предложения SELECT (то есть играет документирующую роль), в то время как определение в программе нескольких курсоров без курсорных выражений ничего
не говорит о логике их совместной обработки, так что понять последнюю мы сможем только по процедурным конструкциям, а давно известно, что понять, что делает программа, по процедурным конструкциям гораздо труднее, чем по описаням ее структур.
Более того, при использовании курсорного выражения мы избавлены от необходимости его открывать, сразу приступая к операциям FETCH, что быстрее в исполнении и экономнее в тексте.
Резюме: использование ссылки на курсор в предложении SELECT упрощает код программной
обработки, улучшает читаемость кода и повышает эффективность его исполнения.
Ссылки на курсор в предложении SELECT
Ссылки на курсор могут использоваться не только в программе, но и в предложении SQL. Это обеспечивается указанием во фразе SELECT предложения SELECT выражения CURSOR для формирования столбца результата. Если мы попытаемся сделать это в SQL*Plus, результат покажется довольно неожиданым: SQL SELECT 2 dname 3 , CURSOR ( SELECT ename FROM emp WHERE emp.deptno = dept.deptno )
4 FROM dept; DNAME CURSOR(SELECTENAMEFR -------------- -------------------- ACCOUNTING CURSOR STATEMENT : 2 CURSOR STATEMENT : 2 ENAME
---------- CLARK
KING
MILLER
RESEARCH CURSOR STATEMENT : 2 CURSOR STATEMENT : 2 ENAME ---------- SMITH
JONES
SCOTT
ADAMS
FORD
SALES CURSOR STATEMENT : 2 ... ... ... ...
На деле произошло вот что: предложение SELECT ... FROM dept вернуло во втором столбце результата каждой своей строки ссылку на курсор, сформированный динамически предложением внутри CURSOR ( ... ). Программа SQL*Plus проинтерпретировала эту ссылку, перебрав строки, словно как это делали мы в примерах предыдущей статьи, и выдала строки на экран. В результате мы увидели на экране перечень четырех строк-отделов, и для каждого отдела – перечень сотрудников.
Форма выдачи занятная, но, кажется, практически бесполезная. Так зачем же нужно выражение CURSOR в предложении SELECT ? Чтобы ответить на этот вопрос, снова обратимся к программированию.
Использование переменных связывания
Как было показано в предыдущем разделе, при просмотре библиотечного кеша только полностью идентичные операторы SQL будут считаться идентичными. Следовательно, два оператора: select * from emp where empno=1234 и select * from emp where empno=5678
считаются различными и для их выполнения потребуются два полных разбора и две отдельных записи в библиотечном кеше. Вот почему настоятельно рекомендуется для связывания значений в прикладной программе использовать в операторах SQL переменные связывания, фактические значения которых подставляются только во время выполнения программы. Оператор, показанный выше, теперь будет таким:
select * from emp where empno=:x
Его можно выполнять много раз с различными значениями переменной связывания :x. В хорошо написанном приложении будет выполняться один разбор этого оператора, затем его можно выполнять столько раз, сколько требуется, с различными значениями переменной связывания в прикладной программе. Такой подход не только повышает производительность одной программы, он также обеспечивает масштабируемость многочисленных параллельно работающих программ, разделяющих одну и ту же копию данного оператора SQL. Корпорация Oracle рекомендует при программировании приложений всегда использовать этот подход. (Тем не менее есть исключения, об этом см. данные ниже рекомендации в разделе о специфических проблемах приложений для хранилищ данных.)
Лучшие практические методы
Тесты (описаны в приложении к этой статье) показывают, что надлежащая установка значения параметра cursor_sharing позволяет повысить производительность приложений, которые были написаны без использования переменных связывания. В частности, время ответа в приложениях с часто повторяющимися операторами SQL, которые отличаются друг от друга только литералами, может быть чрезвычайно большим. Кроме указанного повышения производительности, использование этого параметра также позволяет уменьшить объем потребляемой памяти, так как разделяется большее количество операторов SQL. Однако поскольку по-прежнему выполняется частичный разбор, использование приложений без переменных связывания может привести к проблемам масштабируемости, хотя и на более высоких уровнях пропускной способности.
Кроме того, тесты показывают, что надлежащая установка значения параметра session_cached_cursors может привести к некоторому улучшению масштабируемости некоторых типов приложений, в частности тех, где используются переменные связывания, но для каждого оператора SQL будут выполняться открытие и закрытие курсора или частичный разбор. Надлежащее значение этого параметра обычно находится между количеством часто выполняемых в приложении операторов SQL и значением параметра инициализации экземпляра open_cursors.
Для хорошо спроектированных приложений (многократное выполнение разобранных операторов SQL) установка параметра cursor_space_for_time = true может привести к некоторому улучшению масштабируемости за счет потребления дополнительной памяти.
Параметры инициализации cursor_sharing и session_cached_cursors позволяют разработчикам приложений немного "смягчить" несоблюдение руководящих принципов надлежащей разработки приложений. Однако чтобы полностью обеспечить масштабируемость и производительность системы баз данных Oracle, приложения следует проектировать в соответствии с руководящими принципами корпорации Oracle.
В процессе программирования приложений следует соблюдать следующие общие рекомендации:
операторы SQL, многократно выполняемые в одном и том же модуле приложения, следует связывать с конкретными курсорами, которые открываются один раз: их операторы SQL с переменными связывания разбираются один раз и выполняются многократно. Такой способ обеспечивает возможно лучшие время ответа и масштабируемость. Этого можно добиться, используя явные курсоры в программах Oracle Precompiler и надлежащим образом используя описатели операторов (statement handles) в программах Oracle Call Interface. Программы Oracle Precompiler, использующие неявные курсоры, следует запускать с параметрами HOLD_CURSOR=YES, RELEASE_CURSOR=NO для конкретных операторов SQL или с общим параметром MAXOPENCURSORS, значение которого должно быть достаточно высоким для сохранения открытыми всех часто используемых курсоров; значение этого параметра, устанавливаемое по умолчанию и равное 10, обычно слишком мало. Этот подход также используется в программах, написанных на PL/SQL, и при использовании курсоров в циклах и декларации курсоров в статическом SQL;
операторы SQL, многократно выполняемые в разных модулях приложения, для которых нельзя применить описанный выше метод, следует выполнять с использованием переменных связывания. Если это невозможно, или если в уже написанном приложении необходимо воспользоваться преимуществами использования переменных связывания, можно установить в параметре cursor_sharing значения force или similar. Однако см. ниже замечания по приложениям систем поддержки принятия решений (decision support type applications);
в общем, следует избегать частого частичного разбора операторов SQL или открытия и закрытия курсоров. Если в приложениях это все-таки используется, то некоторого улучшения масштабируемости можно добиться, установив надлежащее значение параметра session_cached_cursors, но установка этого параметра не должна подменять корректного программирования приложений;
не следует совершенно отказываться от использования в приложениях переменных связывания, полностью полагаясь на использование параметра cursor_sharing. Главное достоинство этого параметра заключается в повышении производительности существующих приложений, в которых переменные связывания не используются, что помогает избегать дорогостоящего полного разбора. Заметим, проблемы масштабируемости при обработке SQL возникают также из-за выполнения частичного разбора; использование этого параметра не помогает избавиться от частичного разбора. Заметим также, что никаких преимуществ от использования этого параметра не получают приложения, в которых фактически отсутствует многократное выполнение операторов SQL, отличающихся только литералами, а также приложения, не испытывающие реальных проблем с выполнением разбора;
как исключение операторы SQL, в частности, сложные операторы SQL, которые редко выполняются чаще одного раза, должны разбираться с использованием литералов и без использования переменных связывания, что позволит оптимизатору воспользоваться всеми преимуществами доступных статистик. Более подробно об этом см. в разделе "Особые ситуации".
Примечательно, что кроме повышения производительности, использование параметра cursor_sharing позволяет обеспечить реальное разделение операторов SQL, которые в противном случае были бы различными из-за различий в литералах (это также влияет на потребление памяти).
И еще следует упомянуть, что для некоторых приложений или некоторых частей приложений, использующих литералы, не желателен запуск с установленными значениями параметра cursor_sharing, если они отличаются от значения по умолчанию. В частности, это справедливо, если в вашем приложении используются литералы, которые не изменяются между вызовами. Примером такого оператора SQL может быть оператор со списком литералов в предикате (IN-list), типа: select * from elements where status in (1,4)
Здесь при каждом вызове оператора будут использоваться фактически одни и те же значения литералов: 1 и 4.
Обработка операторов SQL в СУБД Oracle
При обработке операторов SQL в СУБД Oracle обычно выполняется четыре или пять шагов в зависимости от типа оператора SQL:
Шаг полного разбора (hard parse), во время которого СУБД Oracle разбирает оператор SQL, проверяет его синтаксическую корректность и существование таблиц и столбцов, на которые есть ссылки в операторе.
Шаг частичного разбора (soft parse), во время которого оператор SQL связывается с конкретным сеансом и проверяются права доступа.
Шаг оптимизации (optimization), во время которого СУБД Oracle определяет лучший способ выполнения оператора SQL, используя информацию о размере различных объектов (таблиц, индексов и т.д.), к которым будет осуществляться доступ.
Шаг выполнения (execution), в котором для фактического доступа к данным используются результаты шагов разбора и оптимизации.
Для запросов (то есть операторов select) после шага выполнения следует шаг выборки (fetch), во время которого приложение действительно получает строки запроса.
Понимание обработки операторов SQL в СУБД Oracle позволяет разработчикам приложений писать масштабируемые приложения. В частности избегая полных и частичных разборов, можно существенно уменьшить накладные расходы ЦП и повысить разделение оперативной памяти.
Для выполнения первых трех шагов могут потребоваться значительное время и другие ресурсы, что обычно рассматривается как накладные расходы, так как никакой фактической обработки пользовательских данных не выполняется. Следовательно, приложения нужно писать так, чтобы минимизировать время выполнения этих шагов. Наиболее эффективный способ – по мере возможности избегать выполнения этих шагов.
Главным компонентом СУБД Oracle, задействованным в обработке операторов SQL, является библиотечный кеш (library cache), в которым кешируются текущие выполняемые операторы SQL. Во время шага разбора (с точки зрения программирования приложений существует только одна операция разбора; операции полного и частичного разбора различаются только в СУБД Oracle в зависимости от обстоятельств, описанных ниже). СУБД Oracle сначала проверяет, находится ли оператор SQL в библиотечном кеше. Если это так, то требуется только небольшая дополнительная обработка оператора, такая, как проверка прав доступа и связи с окружением сеанса, и частичный разбор. Если оператор не найден в библиотечном кеше, требуется полный разбор с проверкой синтаксиса, корректности имен таблиц и столбцов и т.д. Предшествующий тип разбора, частичный разбор, выполняется значительно быстрее полного разбора. Следовательно, в приложениях нужно избегать, в частности, полных разборов.
Во время первого выполнения оператора SQL происходит его оптимизация, то есть СУБД Oracle находит лучший путь доступа к данным (в некоторых случаях оптимизация реально выполняется во время первого шага. Это, однако, не относится к теме данной статьи). В конце концов, оператор SQL выполняется, а затем для запросов происходит выборка результирующих строк. После того как оператор разобран и выполнен, его можно эффективно выполнять, не предпринимая шагов разбора и оптимизации.
Для проверки, находится ли уже оператор SQL в библиотечном кеше, СУБД Oracle использует просмотр с хешированием, после этого выполняется просто строковое сравнение. Следовательно, только полностью идентичные операторы SQL будут рассматриваться как идентичные.
Особые ситуации
Использование переменных связывания в операторах SQL либо непосредственно запрограммированных в приложении, либо косвенно с помощью установки значения параметра cursor_sharing, в общем, позволяет повысить производительность. Однако есть случаи, когда их использование либо не оказывает никакого реального влияния на производительность, либо вы подвергаетесь реальному риску снижения ее. В этом разделе рассматриваются эти проблемы и обсуждаются пути их решения в Oracle9i.
Параметр cursor_sharing в СУБД Oracle9i
В СУБД Oracle9i параметр cursor_sharing может иметь значение similar (аналогичные операторы), которое позволяет средствам разделения курсоров учитывать особенности запросов в системах поддержки принятия решений. Рассмотрим два оператора SQL, показанных ниже. Предположим, что таблица emp имеет индекс первичного ключа (столбец empno) и индекс столбца deptno: select * from emp where empno=1234 и select * from emp where deptno<400
В первом случае будет выполняться поиск по индексу первичного ключа, и это будет лучшим планом выполнения; решение, принятое оптимизатором не будет изменено, если литерал 1234 будет заменен другим литералом, таким, как 5678. Следовательно, курсоры могут благополучно разделяться, не оказывая никакого влияния на производительность; такие литералы называются надежными литералами (safe literals). Во втором случае с условием неравенства желательно, чтобы оптимизатор сгенерировал другой план выполнения, если, например, литерал 400 будет заменен другим литералом, таким, как 10. Следовательно, несмотря на то что два оператора SQL разбираются одинаково, они не будут иметь разделяемого плана выполнения; такие литералы называются ненадежными литералами (unsafe literals). В СУБД Oracle9i это распознавание осуществляется механизмом разделения курсоров, если значение параметра cursor_sharing – similar.
Значение similar в параметре cursor_sharing также выгодно использовать для изменения поведения механизма разделения курсоров, когда в операторах SQL используются литералы, которые фактически не изменяются между вызовами, как в показанном выше примере оператора со списком литералов в предикате (IN-list).
Кажется заманчивым в СУБД Oracle9i устанавливать параметр cursor_sharing=similar как для OLTP-систем, так и для систем поддержки принятия решений, однако существуют случаи, когда это не выгодно. В тех случаях, когда в операторах SQL есть литералы, фактические значения которых инициируют оптимизацию, а сами значения изменяются почти в каждом операторе, производительность выполнения операторов будет равна производительности выполнения операторов без разделения курсоров (то есть как при установке значения параметра по умолчанию: cursor_sharing=exact), во время которого выполняется полный разбор каждого оператора. Поэтому в таких случаях не следует использовать разделение курсоров. В тех случаях, когда фактические значения литералов изменяются лишь несколько раз, установка параметра cursor_sharing=similar может улучшить масштабируемость и сократить время ответа. Однако представляется, что это редкие случаи, установка параметра cursor_sharing=similar в общем не дает какого-либо положительного эффекта по сравнению с надлежащим программированием приложений. Результаты тестирования, приведенные в приложении, ясно показывают, что установка параметра cursor_sharing=similar реально приводит к небольшому снижению производительности, если фактическое значение литерала (инициирующее оптимизацию) изменяется между вызовами.
Переменные связывания и совместное использование курсоров: новые тенденции в СУБД Oracle9i
Бьерн Энгсиг, ,
(Bind variables and cursor sharing – new directions in Oracle9i, By Bjorn Engsig, Miracle A/S)
Источник: OracleWorld, Copenhagen, Denmark, 24-27 June 2002, (http://www.oracle.com/pls/oow/oow_user.show_public?p_event=12&p_type=session&p_session_id=15524 )
Поддержка приложений, использующих литералы
Значения 1234 и 5678 в двух примерах, показанных выше, являются константами (литералами), их использование в операторах SQL является причиной возникновения накладных расходов из-за допол-
нительных разборов и означает, что операторы SQL в библиотечном кеше не разделяются. Тем не менее при разработке многих приложений этому не уделяется должное внимание, поэтому в СУБД Oracle предусмотрено средство уменьшения влияния такого программирования на систему. Оно позволяет разделять в библиотечном кеше информацию о курсорах для тех операторов SQL, которые фактически не являются идентичными, но их различие заключается только в литералах. Реализация данного средства заключается в выполнении простого просмотра оператора SQL, во время которого все обнаруженные литералы заменяются переменными связывания. Этот просмотр выполняется перед фактическим шагом разбора, следовательно, когда СУБД будет разбирать два оператора, показанные выше, они будут заменены оператором, который будет иметь примерно следующий вид:
select * from emp where empno=:SYS_B_0
В этом операторе литерал был заменен переменной связывания, поэтому оператор станет разделяемым и полный разбор будет выполняться только один раз, соответственно уменьшая накладные расходы. Следовательно, даже для приложений, в которых не используются переменные связывания, средство автоматической замены литералов переменными связывания может принести пользу. Данный механизм управляется установкой в файле init.ora значений параметра cursor_sharing (разделение курсоров). Параметр может иметь следующие значения:
exact (точное соответствие)
Отключает данный механизм, то есть для операторов с разными литералами отключается разделение курсоров. Это значение устанавливается по умолчанию.
force (безусловное)
Включает механизм безусловного разделения операторов SQL, но только тех, которые имеют отличающиеся литералы.
similar (аналогичные операторы)
Разделение курсоров осуществляется тогда, когда известно, что оно не окажет никакого влияния на оптимизацию. Это значение не доступно в Oracle8i.
Этот параметр может быть установлен либо глобально в файле init.ora, либо динамически для всех сеансов с помощью оператора alter system или для конкретного сеанса с помощью оператора alter session. Его значение по умолчанию (exact) может быть изменено в будущих версиях СУБД Oracle.
При первом чтении данной статьи
При первом чтении данной статьи создается впечатление, что автор излагает очевидные истины, известные всем разработчикам приложений СУБД Oracle. При более внимательном чтении приходишь к выводу, что в статье представлен практический и исследовательский (Бьерн – бывший сотрудник корпорации Oracle) опыт работы автора с реальными приложениями как на стадии их разработки, так и на стадии оптимизации производительности СУБД, чаще всего работающих с приложениями, которые были разработаны без учета рекомендаций корпорации Oracle. Поэтому эта статья может быть полезной как разработчикам приложений, так и администраторам баз данных.
Особое внимание автор уделяет приложениям, многократно выполняющим одни и те же (или сходные, то есть отличающиеся только значениям литералов) операторы SQL.
Публикация перевода разбита на две части. В первой части обсуждается обработка операторов SQL в СУБД Oracle и подводятся итоги этого обсуждения, а также рассматриваются лучшие практические методы и даются общие рекомендации, которые направлены на обеспечение надлежащей производительности и масштабируемости. Вторая часть посвящена особым ситуациям, которые могут возникать в приложениях OLTP-систем и систем поддержки принятия решений, рассматриваются новые возможности СУБД Oracle9i; в приложении к статье приведены результаты тестирования разных способов выполнения операторов SQL с использованием различных моделей программирования и параметров инициализации СУБД Oracle.
результаты тестирования
В данной статье обсуждается эффективность разных способов выполнения операторов SQL: с использованием различных моделей программирования и параметров инициализации CУБД Oracle. Тесты были специально спроектированы, чтобы показать эту эффективность. Прогоны тестов выполнялись в испытательной системе с 24 ЦП. Ядро каждого теста – цикл, выполняющий оператор SQL одну тысяч раз, и каждый тест выполнялся как одиночная программа, а также как 3, 6, 12 и 24 параллельно выполняемых копии. Во всех случаях измерялись среднее значение суммы использованного времени всеми копиями, а также время, затраченное на ожидание защелок (время ЦП извлекалось из статистики CУБД Oracle 'CPU used by this session' – "время ЦП, использованное в данном сеансе", а время ожидания защелок из данных события 'latch free' – "время ожидания защелки, занятой другим процессом"). Абсолютные значения результатов не имеют никакого значения, но результаты можно сравнивать для демонстрации преимущества использования конкретных моделей программирования приложений или параметров инициализации CУБД Oracle.
В первом тесте используются переменные связывания, как советует корпорация Oracle для обеспечения лучшей производительности OLTP-приложений. Он демонстрирует эффективность моделей программирования, в которых каждый оператор SQL разбирается и выполняется или один раз разбирается и многократно выполняется, а также эффективность использования параметров session_cached_cursors и cursor_space_for_time startup.
Второй и третий тесты демонстрируют использование параметра cursor_sharing. Второй тест – типичный пример OLTP-приложения с надежными литералами: никакие литералы не инициируют оптимизацию и используется установка параметра cursor_sharing=force. Третий тест – вариант с ненадежными литералами, в котором используется установка параметра cursor_sharing=similar.
В первых двух тестах можно непосредственно сравнивать все полученные показатели, так как реально выполняются одни и те же операторы SQL. В разных частях третьего теста используются различные операторы SQL, поэтому результаты, полученные в разных частях теста, нельзя сравнивать друг с другом и с результатами первого и второго тестов.
Работа с курсорами
Курсор – это указатель на область контекста, с помощью которого приложение выполняет операторы SQL. Приложение может открывать столько курсоров, сколько требуется – в рамках ограничений по памяти и в зависимости от значения параметра open_cursors (максимальное количество открытых в экземпляре курсоров) в файле init.ora, впоследствии курсоры связываются с операторами SQL. Для наиболее эффективного выполнения операторов SQL приложения должны иметь необходимое количество курсоров, чтобы используемые часто операторы всегда были готовы к выполнению. Для этого приложения открывают требуемое количество курсоров и выполняют разбор соответствующих операторов SQL, использующих переменные связывания. Затем, когда будут доступны фактические данные, нужно будет выполнить только шаг выполнения (и шаг выборки для запросов).
Несмотря на то что корпорация Oracle рекомендует использовать данный подход, в большинстве приложений он не применяется или, другими словами, при разработке приложений редко соблюдается эта рекомендация корпорации Oracle. Поэтому приложения либо будут постоянно открывать и закрывать курсоры, либо будут повторно использовать один курсор с различными операторами SQL (в этом случае будет выполняться, по крайней мере, частичный разбор, а во многих случаях полный разбор). Для изменения такого поведения приложений можно использовать параметр инициализации session_cached_cursors (максимальное количество курсоров, кешируемых в сеансе). В этом параметре может быть установлено целочисленное значение. В этом случае некоторая часть области контекста на стороне сервера, связанная с операторами SQL, будет сохраняться, даже если на стороне клиента будут закрываться курсоры или повторно использоваться с новыми операторами SQL.
Для хорошо написанных приложений, которые открывают курсоры и выполняют разбор операторов SQL только один раз, а затем многократно повторяют шаги выполнения одного или более курсоров, требуется некоторая работа по выделению памяти, используемой только во время фазы выполнения оператора SQL (runtime memory). Для того чтобы эта память выделялась только один раз, при первом выполнении, нужно установить в параметре cursor_space_for_time (часть области контекста курсора, используемая во время фазы выполнения) значение true (по умолчанию устанавливается значение false) - это позволит повысить производительность за счет использования дополнительной памяти. Этот параметр следует использовать только тогда, когда ваше приложение имеет строго ограниченный набор операторов SQL, который полностью размещается в разделяемом пуле (shared pool), так как издержки использования памяти могут быть очень велики.
Использование хорошей методики программирования всегда
Использование хорошей методики программирования всегда имеет важное значение для достижения надлежащей производительности и масштабируемости приложений, в частности приложений, которые работают с общим, централизованным репозиторием, размещенном в базе данных Oracle и параллельно обслуживающим сотни и тысячи пользователей. В таких случаях важно понимать, как функционирует СУБД Oracle.
Работа СУБД, которую ей необходимо выполнить для приложений, выражается с помощью языка SQL, и СУБД Oracle спроектирована таким образом, чтобы многочисленные идентичные операторы SQL, которые параллельно выполняют много пользователей, могли разделять информацию. Для управления этим режимом, а также режимом совместного использования операторов SQL, которые не являются полностью идентичными, предусмотрен набор параметров инициализации.
Главная цель данной статьи – объяснить, как СУБД Oracle обрабатывает операторы SQL, и таким образом помочь разработчикам приложений проектировать и программировать хорошо работающие и масштабируемые приложения. Кроме того, объяснить администраторам баз данных, как можно конфигурировать СУБД Oracle, чтобы некоторые неоптимально написанные приложения могли работать с приемлемой производительностью.
Результаты
В контексте данной статьи приложения, которые используют сходные (similar) операторы SQL (то есть операторы SQL, отличающиеся только фактическими значениями литералов), можно разделить на три категории:
1.
Приложения, в которых не используются переменные связывания. Такой стиль программирования наблюдается часто, когда разработчики приложений не осведомлены о важности уменьшения количества разборов, или когда приложения переносятся из других СУБД.
2a.
Приложения, выполняющие все шаги для каждого отдельного оператора SQL: открытие курсора, разбор с переменными связывания, выполнение (и выборка для запросов) и закрытие курсора. Это – поведение Oracle Forms при входе и выходе из блоков, а также в собственном динамическом SQL (native dynamic SQL) языка PL/SQL. Преимущества использования переменных связывания при таком подходе не очевидны программистам, работающим с интерфейсом вызовов Oracle (Oracle Call Interface, OCI) или прекомпиляторами Oracle (Oracle Precompilers), поэтому в этой среде переменные связывания встречаются редко.
2b.
Приложения, в которых для каждого оператора SQL один раз открывается курсор, а затем многократно выполняются следующие шаги: разбор с переменными связывания, выполнение (и выборка для запросов). Этот тип приложений часто наблюдается, когда разработчики приложений используют Oracle Precompilers с опциями HOLD_CURSOR=NO (не удерживать курсор) и RELEASE_CURSOR=NO (не освобождать курсор), которые устанавливаются по умолчанию, или когда используется пакет PL/SQL DBMS_SQL.
3.
Приложения, в которых для каждого отдельного (отличного от других) оператора SQL один раз открывается курсор, выполняется разбор с переменными связывания, а затем следует многократное выполнение (и выборка для запросов). Это наиболее эффективный способ разработки приложений, многократно исполняющих одни и те же операторы SQL. Обычно наблюдается в хорошо спроектированных приложениях, разработчики которых использовали Oracle Call Interface или Oracle Precompilers. Особенно это относится к Oracle Precompilers, когда для конкретных операторов SQL используются опции HOLD_CURSOR=YES (удерживать курсор) и RELEASE_CURSOR=NO (не освобождать курсор), или используется установка общего параметра MAXOPENCURSORS (максимальное количество открытых курсоров), которая определяет поведение неявных курсоров для данной категории приложений. Этот подход также используется в программах, написанных на PL/SQL, и при использовании курсоров в циклах и явных курсоров в статическом SQL.
Категории 2a и 2b практически идентичны, так как фактическое открытие и закрытие курсоров оказывает очень малое влияние на производительность, реальные накладные расходы – на разбор.
Производительность приложений, в общих чертах можно определять по времени ответа, то есть реальному времени, затраченному на каждое выполнение оператора SQL, а также по пропускной способности или масштабируемости, то есть способности параллельно выполнять многочисленные копии приложения. Оба этих показателя производительности были измерены для различных категорий приложений с различными сценариями установки значений параметров инициализации cursor_sharing и session_cached_cursors, рассмотренных ранее. Результаты измерений по каждой из трех категорий приложений, перечисленных выше, в комбинации с параметрами инициализации сведены в показанную ниже таблицу. В приложении к этой статье приведены некоторые фактические результаты тестов, которые были специально разработаны для демонстрации поведения различных категорий приложений.
Общее поведение
cursor_
sharing = force или similar
session_
cached_
cursors = достаточно высокое значение
cursor_
space_for
_time = true
1. Совершенно не используются переменные связывания.
В общем, плохое время реакции и масштаби-
руемость. Тем не менее эта категория рекомендуется для DSS-
приложений, у которых нет или очень мало повторений операторов SQL.
Значительное сокращение времени ответа и увеличение масштаби-
руемости; хотя результаты не столь хороши, как в приложениях 2-й и 3-й категорий.
Незна-
чительное улучшение исходных данных.
Никакого влияния.
2. Разбор с переменными связывания, выполнение (и выборка) для каждого выполнения оператора SQL.
Относительно короткое время ответа из-за разделения курсоров в библиотечном кеше; ограниченная масштаби-
руемость из-за повторяющихся открытий и закрытий курсоров и частичных разборов.
Никаких допол-
нительных улучшений.
Сокращается время ответа и увеличивается масштаби-
руемость, так как сервер сохраняет кешированные курсоры. Никакого влияния.
3. Однократное открытие курсора и разбор с переменными связывания, многократное выполнение (и выборка).
Самые лучшие из возможных время ответа и масштаби-
руемость.
Никаких допол-
нительных улучшений.
Никаких допол-
нительных улучшений
Допол-
нительное увеличение масштаби-
руемости.
Считывание значений переменных связывания в СУБД Oracle9i
В СУБД Oracle9i оптимизатор считывает фактические значения переменных связывания, если они доступны. В результате оптимизатор при использовании переменных связывания может использовать собранные статистики на уровне таблиц, индексов или столбцов. Это выгодно как для приложений, которые были написаны с использованием переменных связывания, так и для приложений, в которых литералы заменяются переменными связывания (при соответствующей установке значения параметра cursor_sharing).
Проведенное нами тестирование показало, что считывание значений переменных связывания работает как предполагалось: оптимизатор принимает свои решения на основе фактических значений переменных связывания. Но как только оптимизатор сгенерирует план выполнения, дальнейшего считывания значений переменных связывания не будет ни в том же самом сеансе, ни в другом, для которого выполняется разбор такого же оператора SQL. В обоих случаях оператор SQL и связанный с ним план выполнения будут найдены в библиотечном кеше.
Системы поддержки принятия решений (decision support systems)
Системы поддержки принятия решений, такие, как приложения хранилищ данных, характеризуются небольшим количеством пользователей, выполняющими сложные операторы SQL, которые имеют мало повторений или не имеют их вообще. Для каждого сложного оператора SQL также имеет важное значение то, чтобы оптимизатору для выбора правильного плана выполнения была доступна вся необходимая информация. В СУБД Oracle8i это возможно только в том случае, когда переменные связывания не используются. В Oracle8i использование переменных связывания скрывает от оптимизатора фактические значения, поэтому он для генерации лучшего плана выполнения будет использовать эвристику, вместо того чтобы потенциально использовать информацию о реальном распределении данных. Для этого типа приложений основной объем ресурсов используется не на шагах разбора или оптимизации, поэтому сокращение времени выполнения этих шагов мало влияет на общую производительностью. Важнее то, чтобы шаг выполнения не затягивался на минуты и часы, а шаг оптимизации выполнялся с возможно лучшими доступными данными, позволяющими сгенерировать наиболее эффективный план выполнения. В частности, это справедливо, если вы соберете статистики по столбцам, которые предоставляют оптимизатору детализированную информацию о доступных данных.
Таким образом, для данного типа приложений, работающих под управлением СУБД Oracle8i, не должны использоваться переменные связывания, а значение параметра cursor_sharing должно быть установлено как exact, чтобы курсоры и, следовательно, планы выполнения не разделялись.
СУБД Oracle9i
В СУБД Oracle9i появились новые средства (значение similar для параметра cursor_sharing и считывание значений переменных связывания), которые могут помочь немного повысить производительность плохо написанных приложений. Тем не менее необходимо подчеркнуть, что возможно лучшая производительность обеспечивается использованием надлежащих методов проектирования приложений, которые фактически не изменились в СУБД Oracle9i. Эти методы можно представить очень просто:
приложения (обычно OLTP- приложения), многократно выполняющие одни и те же операции, должны инициировать разбор операторов SQL только один раз, использовать переменные связывания и реально повторять только шаг выполнения; приложения (обычно приложения систем поддержки принятия решений), выполняющие операции, которые редко повторяются, должны инициировать разбор операторов SQL, использующие литералы, чтобы у оптимизатора была возможность прибегать ко всей доступной информации.
Тестирование параметра cursor_sharing и операторов с надежными литералами
В тестовой программе поиск по простому индексу первичного ключа выполняется так же эффективно, как и в первом тесте, но вместо переменных связывания используются литералы. Во всех тестах открытие и закрытие курсоров выполняется за пределами циклов.
|
1 |
3 |
6 |
12 |
24 |
|
|
В тесте используются надежные литералы, установка параметра cursor_sharing=exact (то есть разделение курсоров не используется). |
349 |
407 |
499 |
995
2135
В тесте используются надежные литералы, установка параметра cursor_sharing=force.
85
95
97
102
164
В тестовой программе выполняется запрос индексированного столбца таблицы с несимметричным распределением данных. Статистики столбца собраны вместе, поэтому в некоторых запросах будет использоваться полный просмотр таблицы, а в некоторых - поиск по индексу. Тесты демонстрируют эффективность использования ненадежных литералов, которые более или менее часто изменяются между вызовами, а также эффективность установки параметра cursor_sharing=similar. Во всех тестах открытие и закрытие курсоров выполняется за пределами циклов, в цикле повторяются разбор и выполнение операторов SQL. Кроме того, во всех тестах фактически используется корректный план выполнения (полный просмотр таблицы или поиск по индексу), поэтому различия в результатах не связаны с некорректным планом выполнения.
Заметим: результаты тестирования можно сравнивать только в пределах каждой подгруппы тестов (подгруппы разделены пустой строкой), так как выполняемые в разных подгруппах тесты отличаются друг от друга и имеют разную частоту изменения ненадежных литералов. Результаты нельзя также сравнивать с результатами первых двух тестов.
|
1 |
3 |
6 |
12 |
24 |
|
|
В тесте используются ненадежные литералы, которые редко изменяются, параметр cursor_sharing не используется. |
557 |
607 |
670 |
1058 |
2355 |
|
В тесте используются ненадежные литералы, которые редко изменяются, установка параметра cursor_sharing=similar. |
318 |
350 |
352 |
396 |
554 |
|
В тесте используются ненадежные литералы, которые изменяются через каждые 10 вызовов, параметр cursor_sharing не используется. |
321 |
389 |
489 |
938 |
1993 |
|
В тесте используются ненадежные литералы, которые изменяются через каждые 10 вызовов, установка параметра cursor_sharing=similar. |
120 |
139 |
133 |
158 |
222 |
|
В тесте используются ненадежные литералы, которые изменяются через каждые 3 вызова, параметр cursor_sharing не используется. |
330 |
365 |
485 |
900 |
1949 |
|
В тесте используются ненадежные литералы, которые изменяются через каждые 3 вызова, установка параметра cursor_sharing=similar. |
172 |
194 |
210 |
264 |
524 |
|
В тесте используются ненадежные литералы, которые непрерывно изменяются, параметр cursor_sharing не используется. |
316 |
358 |
468 |
846 |
1838 |
|
В тесте используются ненадежные литералы, которые непрерывно изменяются, установка параметра cursor_sharing=similar. |
369 |
417 |
505 |
824 |
1724 |
Тестирование параметров session_cached_cursors, cursor_space_for_time и моделей программирования
В тестовых программах для поиска по простому индексу первичного ключа используются переменные связывания. Тестируются различные комбинации моделей программирования и параметры инициализации. Во всех тестах открытие и закрытие курсоров выполняется за пределами циклов.
|
1 |
3 |
6 |
12
24
В программе повторяются разбор и выполнение оператора SQL, параметр session_cached_cursors не используется.
74
78
78
95
146
В программе повторяются разбор и выполнение оператора SQL, установка параметра session_cached_cursors=1.
68
67
66
73
83
В программе выполняется только один разбор, повторяется выполнение оператора SQL, параметр cursor_space_for_time не используется.
33
32
37
43
47
В программе выполняется только один разбор, повторяется выполнение оператора SQL, установка параметра cursor_space_for_time=true.
28
28
31
35
33
СУБД Oracle написана для поддержки
СУБД Oracle написана для поддержки приложений с масштабированием от десятков до тысяч пользователей. Обеспечить такое масштабирование можно на стадии разработки приложений, следуя определенным рекомендациям. Некоторые параметры инициализации СУБД Oracle могут быть использованы для изменения поведения ядра СУБД – как для обеспечения некоторого повышения производительности некорректно написанных приложений, так и для дополнительного повышения производительности корректно написанных приложений.
В этой статье рассмотрены:
проектирование приложений, в которых в полной мере используются функциональные возможности СУБД Oracle; настройка СУБД для поддержки приложений, программирование которых не было или было очень мало сфокусировано на обеспечении масштабируемости.
Три параметра, рассмотренные в этой статье, следует использовать в соответствии со следующими рекомендациями:
| cursor_sharing | Этот параметр позволяет повысить масштабируемость и производительность приложений, которые были написаны с использованием в операторах SQL литералов, а не переменных связывания. Использование значения force этого параметра может привести к большому увеличению пропускной способности и к некоторому увеличению масштабируемости. В СУБД Oracle8i в системах поддержки принятия решений и приложениях хранилищ данных его следует использовать осторожно или не использовать вообще. В СУБД Oracle9i появилось новое значение этого параметра similar, которое во многих случаях позволяет разделять курсоры в системах поддержки принятия решений и приложениях хранилищ данных. |
Решение об установке значения этого параметра обычно принимает администратор базы данных, когда многократно повторяются полные разборы операторов SQL, отличающиеся только литералами.
session_cached_cursors Установка значения этого параметра, которое находится между фактическим количеством используемых курсоров и значением параметра open_cursors, может привести к некоторому повышению масштабируемости и пропускной способности за счет некоторого увеличения нагрузки на ЦП (установка значений, превышающих 50-100, делает этот параметр бесполезным). Кроме того, немного увеличивается потребление памяти, но этим обычно можно пренебречь. Решение об установке значения этого параметра принимает, как правило, администратор базы данных, когда многократно повторяются частичные разборы операторов SQL.
cursor_space_for_time Если установить в этом параметре значение true, то можно дополнительно повысить масштабирование хорошо написанных приложений за счет увеличения потребления памяти.
Деревья решений
Хотя многие задачи data mining резервируются за аналитиками данных, бизнес-пользователи, похоже, чувствуют себя комфортно с деревьями решений. Эти деревья логичны, хорошо воспринимаются визуально, и результат может быть объяснен в типичных бизнес-терминах.
Использование дерева решений - это способ классификации существующих данных, определения факторов или правил, которые имеют отношение к целевому результату (target result), и их применения для прогнозирования результата, что означает:
Бизнес-пользователи могут определять факторы, которые в наибольшей степени влияют на решения о покупках; Департаменты маркетинга могут "целиться" в "правильные" группы потенциальных клиентов, исключая тех, кто с малой вероятностью будет покупать; Аналитики данных и финансовые аналитики могут прогнозировать продажи благодаря анализу атрибутов потенциальных клиентов, о которых есть данные; Бизнес-аналитики могут корректировать цели и стратегии при изменениях тенденций; Компании могут реорганизовывать поддержку (support, enhancements, and desupport) для обеспечения максимального удовлетворения клиентов
И не нужно быть доктором философии (PhD) в математике, чтобы использовать и понимать деревья решений. Чтобы проиллюстрировать это, я проанализирую одну бизнес-задачу:
Производитель предлагает два продукта, A и B. В целом отзывы потребителей были положительны, но владелец предприятия-производителя хочет узнать, что-то можно изменить в поддержке, что может повысить уровень удовлетворения потребителей. У предприятия есть весьма ограниченная информация о своих потребителях, включая только данные о продукте, который они используют, его версии и времени получения его последней модификации.
С использованием этой информации, полученной от выборки по клиентской базе (sample customer population), и Oracle Data Miner это предприятие может создать модель дерева решения, показанную на рис. 1.

Рис. 1: Дерево решений
Каждый прямоугольник в дереве на рис. 1 называется узлом (node) и каждая линия называется веткой (branch) или ребром. Верхний прямоугольник в дереве (или его корень (root)) включает все значения (all cases) этой выборки.
Дерево решений разделяет данные по атрибутам в попытке определить лучших предсказателей (predictors) целевого значения (target value). Эти предсказатели формируют правило (rule) или набор правил, которые будучи применены к узлу, сформируют результат. Вы можете думать о них, как о предложениях IF-THEN для принятия решений.
Oracle Data Miner анализирует все атрибуты в наборе данных. Если, к примеру, в данном наборе данных три атрибута, то Oracle Data Miner анализирует эти три атрибута. Если же атрибутов 80, то Oracle Data Miner анализирует все эти 80 атрибутов. Он определяет атрибут для первого расщепления (split) дерева решения, которое наилучшим образом делит целевые данные (target data) на различные секции.
С эти набором данных, разделенным надвое, Oracle Data Miner может определить атрибуты для расщеплений на следующем уровне. Обратите внимание, что на рис. 1 Oracle Data Miner расщепил ветви 2-го уровня по разным атрибутам.
К последнему ряду узлов ссылаются как к терминальному узлу или листу (terminal node, or leaf). Вполне возможно продолжить анализ далее, чем изображено на рис. 1, но в данном случае два уровня были выбраны как максимум.
Деревья решений в Oracle Data Miner: классификация и анализ данных
Вы когда-нибудь размышляли о том, кто из ваших потенциальных покупателей c высокой степенью вероятности станут вашими реальными покупателями, или кто обеспечит наиболее доходные сделки? На кого вы должны нацеливаться в своей маркетинговой компании и что будет важным для них, когда они начнут звонить? Какие продукты, версии продуктов, предоставят вашим клиентам то, что им нужно, а какие нет и, тем самым, негативно отразятся на вашей компании? Oracle Data Miner поможет перебросить мост между вопросами бизнеса, такими как эти, и техническими и статистическими задачами, которые имеют отношение к "раскопкам" (mining) данных для ответов.
Oracle Data Miner может проанализировать существующий набор данных из вашего хранилища данных и классифицировать те данные, которые определяют или прямо соотносятся с желаемым результатом или целью. Конкретнее, при классификации данных (data classification) обнаруживаются patterns (паттерны, шаблоны) и отношения с целью группирования подобных записей для последующего более легкого и эффективного анализа. В этой статье рассматривается один конкретный тип классификации, называемый decision trees (деревья решений).
Как начать работать с Oracle Data Miner
Oracle Data Miner позволяет легко генерировать деревья решений. Чтобы показать это, я сгенерирую дерево решения на рис. 1. Для этого нужно скачать и установить Oracle Data Miner и выполнить следующие шаги по подготовке вашего источника данных для данного примера:
1. Скачать sample data file.
2. Раскрыть (Unzip) содержание (contents), открыть подсказку и перейти (cd) к директории, содержащей скрипт create_user.sql.
3. Подключиться (Log in) к SQL*Plus под именем SYSDBA, и выполнить скрипт create_user.sql.
Этот скрипт создает пользователя SURVEYS с паролем SURVEYS, и предоставляет ему все необходимые полномочия (permissions). Он соединяется с SURVEYS, создает таблицу CUSTOMER_SATISFACTION и вносит в нее 4920 записей. Структура этой таблицы показана в Listing 1.
Code Listing 1: Описание таблицы CUSTOMER_SATISFACTION SQL> desc CUSTOMER_SATISFACTION
CUSTOMER_SATISFACTION_ID NOT NULL NUMBER(10) PRODUCT VARCHAR2(100) VERSION NUMBER(2) LAST_UPGRADE_YEAR VARCHAR2(4) FEEDBACK VARCHAR2(10)
Данные хранятся в этой таблице следующим образом:
CUSTOMER_SATISFACTION_ID - это первичный ключ и, следовательно, уникальный идентификатор. PRODUCT - может быть A или B. VERSION - это 1, 2 или 3. LAST_UPGRADE_YEAR - это год последней модификации в диапазоне 1999-2006. FEEDBACK - это либо POSITIVE (положительно), либо NEGATIVE (отрицательно).
Чтобы запустить Oracle Data Miner, найдите bin-директорию, в которую вы распаковали этот скачанный продукт, и дважды нажмите по odminerw.exe. Предоставьте информацию о соединениях в схеме SURVEYS (SURVEYS/SURVEYS), когда появится соответствующая подсказка, и нажмите OK, чтобы сохранить детали соединений. Нажмите OK еще раз, чтобы соединиться и показать интерфейс Oracle Data Miner (см. рис. 2).

Рис. 2: Интерфейс Oracle Data Miner с выбранной таблицей CUSTOMER_SATISFACTION
Отметим, таблица CUSTOMER_SATISFACTION с данными выборки показана справа. Вы можете позднее посмотреть эту таблицу, нажав SURVEYS -> Data Sources -> Tables-> CUSTOMER_SATISFACTION.
Выполните следующие шаги для создания деревьев решений: В меню Activity выберите пункт Build. Первый экран мастера (wizard) содержит общую информацию. Нажмите Next. На шаге 1 из 5: Тип модели (Model Type), оставьте Function Type (тип функции) как Classification (классификация) и Algorithm (алгоритм) как Decision Tree. Нажмите Next. В продукте Oracle Data Miner классификация - это тип функции, или категория алгоритмов, относящихся к классификации, а дерево решений - это алгоритм, который принадлежит данному типу функций.
На шаге 2 из 5: Данные (Data), удостоверьтесь, что выбранная схема - это SURVEYS и таблица/представление (table/view) - это CUSTOMER_SATISFACTION. Если они еще не выбраны, выберите их из списка. Уникальный идентификатор является в этом случае единственным значением. Удостоверьтесь, что выбран первичный ключ МCUSTOMER_SATISFACTION_ID. В секции Select Columns выберите все столбцы. Нажмите Next. На шаге 3 из 5: Использование данных (Data Usage), выберите все колонки, кроме CUSTOMER_SATISFACTION_ID, как ввод и выберите FEEDBACK как назначение. Нажмите Next. Столбец FEEDBACK в таблице содержит ответ как POSITIVE или NEGATIVE. Oracle Data Miner проанализирует этот двоичный ответ применительно ко всем атрибутам, чтобы определить те из них, которые влияют на отзывы клиентов в наибольшей степени.
На шаге 4 из 5: Для выбора Preferred Target Value, выберите Negative. Нажмите Next. (Это значение может быть изменено в любой момент.) Выбор Negative настраивает Oracle Data Miner на поиск решений, результатом которых является отрицательный ответ, и дерево решений будет структурировано в соответствии с этим. На шаге 5 из 5: Имя действия (Activity Name), измените имя на CUSTOMER_SAT_1 (увеличьте последнее число, если вы повторно выполняете это действие). Нажмите Next. В шаге Finish оставьте выбранную опцию Run upon finish и нажмите Finish для начала этого процесса.
На этом этапе Oracle Data Miner определяет лучшие расщепления атрибутов, строит модель и тестирует правила, которые сгенерированы с этим набором данных. Рисунок 3 показывает шаги-действия (activity steps).
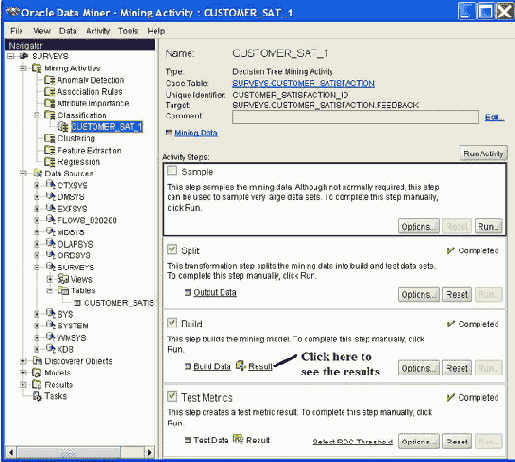
Рис. 3: Шаги- действия классификации CUSTOMER_SAT_1 classification activity steps
Щелкните Result link в Build activity, чтобы увидеть дерево решений, показанное на рис. 4. Отметим, что вы можете контролировать число показываемых уровней узлов. Чтобы увидеть расщепления и ветви, показанные на рис. 1, покажите только два уровня.

Рис. 4: Result Viewer показывает правила расщепления
Результаты на рис. 4 те же самые, что и на рис. 1. Отметим, что первое расщепление или ветвление имеет место на атрибуте Last Upgrade Year (год последней модификации). Если Last Upgrade Year больше или равен 2003, то ответ положителен с 90% уверенности. Отметим, что число значений в данном случае равно 1604 из 2951 в корне. Это примерно 54% от общего числа. Если Last Upgrade Year меньше или равен 2002, ответ предсказывается отрицательным с 91% уверенности. В этом случае в узле 1347 значений, что составляет 46% от общего числа.
Из 4-х узлов 2-го уровня один показывает, что клиенты, использующие версии 2 или 3 продукта A или B, к которым они перешли между 2003 и 2006, с 92% уверенности высказывают положительное мнение о продукте. Другой же узел показывает, что клиенты, использующие продукт A, к которому они перешли между 1999 и 2001, будут, как предсказывается, отрицательно относиться к этому продукту. Безусловно, эта информация будет полезной при планировании поддержки.
Но, очевидно, возможны варианты, когда значение атрибута неопределенно (null) для некоторых записей. Что тогда? Oracle Data Miner определяет не только отношения атрибутов к цели, но и их взаимные отношения. Обратите внимание на секцию Split Rules внизу рис. 4. она показывает замещающее (surrogate) значение для узла ID 1. Если для некоторой записи нет значения Last Upgrade Year, то Oracle Data Miner все-таки включит эту запись в этот узел, если версия 3. Oracle Data Miner определяет это автоматически, не требуя явного задания чего-либо.
Правовая оговорка о статистике
Одна из первых книг по бизнесу и статистике, которые я прочитал, называлась "Как врать, используя статистику" (How to Lie With Statistics), Даррелла Хаффа (Darrell Huff). Нет, это не учебник по тому, что заявлено в названии. Наоборот, в этой книжечке рассматривались распространенные ошибки, приводящие к неверным выводам, при применении статистического анализа - и не из-за ошибочных вычислений, а вследствие неправильных определений проблем, неаккуратных или неполных данных. Поиск смысла там, где его нет, и пропуск смысла там, где есть хоть какой-то, поиск неверного смысла в неверных статистических данных, все это обсуждается (в книге). Следующий полностью вымышленный пример показывает такой тип анализа:
Люди с ростом более 2.25 метра намного менее вероятно пострадают в автоаварии, чем менее высокие . . . и заголовки новостей по всей стране кричат, "Исследование подтверждает, что действительно высокие люди намного сильнее и более стойки, чем невысокие."
А не могло ли дело обстоять так, высокие люди скорей чаще всего пользуются большими автомашинами? Либо вместо процентов при формировании статистики использовались "сырые" (raw) числа? Как много людей в группе очень высоких, особенно в сравнении с группой невысоких?
Oracle Data Miner легко выполняет анализ данных в части математики и программирования, но определение проблемы, отбор данных и корректное применение результатов целиком остается на пользователе. Но если проблема определена правильно, вы можете положиться на результаты.
Применение построения дерева решений
Чтобы увидеть, как построение этого дерева решений будет применено к индивидуальных записям, откройте результаты построения еще раз, переходя к Mining Activities -> Classification, выбирая CUSTOMER_SAT_1, нажимая Result link в Build activity, и нажимая Show Leaves Only в верху окна Result Viewer. С каждым листом ассоциируется правило расщепления, которое появляется внизу данного окна, если щелкнуть по соответствующему узлу.
Например, последний лист (Node ID = 20 на Рис. 4) предсказывает отрицательный ответ со 100% уверенностью. Нажмите этот узел и следующее правило расщепления появится внизу: PRODUCT is in A AND LAST_UPGRADE_YEAR is in { 1999 2001 2002 }
Для любой записи, соответствующей этому правилу, будет предсказан отрицательный ответ со 100% уверенностью.
Данные о клиентах, не попавших в выборку, хранятся в таблице CUSTOMER_SATISFACTION_NEW. Все колонки содержат значения, кроме FEEDBACK. Чтобы обнаружить, какие ответы, положительные или отрицательные, будут получены, применим правила построения CUSTOMER_SAT_1, следующим образом: Откройте главное окно Oracle Data Miner и выберите Activity -> Apply из главного меню. Первая страница для приветствий. Нажмите Next. На шаге 1 из 5: Создать действие (Build Activity), выберите CUSTOMER_SAT_1. Нажмите Next. В шаге 2 из 5: Примените данные (Apply Data), нажмите Select link вправо от таблицы и перейдите к SURVEYS -> CUSTOMER_SATISFACTION_NEW. Нажмите Next.
В шаге 3 из 5: Дополнительные атрибуты (Supplemental Attributes), выберите только колонку CUSTOMER_SATISFACTION_ID. Нажмите Next. На шаге 4 из 5: Примените Опцию (Apply Option), Оставьте значения по умолчанию (default settings). Нажмите Next. На шаге 5 из 5: Дайте имя действию (Activity Name), назовите его CUSTOMER_SAT_APPLY_1. Нажмите Next. Нажмите Finish.
Когда это действие завершится, нажмите Result link в окне действий (activity window), чтобы увидеть предсказанное значение; вероятность, связанную с этим предсказанием; и стоимость (cost), которая похожа на ранжирование вероятностей, за исключением того, что меньшая стоимость означает лучшее предсказание.
Oracle Data Miner позволяет также увидеть, какие правила были использованы для каждой записи. Нажмите одну из записей, а затем Rule button справа от результатов. Просмотрщик правил Rule Viewer появится, как показано на рис. 5.

Рисунок 5: Просмотрщик правил Rule Viewer
Решения "растут" на деревьях
Рон Хардман
Оригинал: , Oracle Magazine March/April 2007
Перевод: Oracle Magazine - Русское издание (Июль-Август 2007)
[От редакции OM/RE: Корпорация Oracle последовательно развивает свои продукты класса Data Mining (принятый русский перевод этого термина - "глубинный анализ данных" - см. http://www.rdtex.ru/docs/glossary), наращивая их функциональность и делая их более "дружественными" и легкими в использовании. Чтобы эффективно эти продукты, необходимо понимание методов Data Mining. Помимо материалов корпорации Oracle на эту тему, уже есть немало материалов и на русском языке, в частности в Интернете, которые легко найти через поисковые системы.
Одним из наиболее понятных методов Data Mining являются деревья решений. Поддержка этого метода недавно была реализована в продукте Oracle Data Miner и она рассматривается в данной статье.]
так как предоставляют логический результат,
Деревья решений полезны для бизнес-пользователей, так как предоставляют логический результат, который можно обсуждать в бизнес-терминах. Они просто создаются с применением Oracle Data Miner, и очень эффективны и точны при обеспечении хорошим набором данных. Они могут предложить прогнозы с соответствующими вероятностями и единое место для просмотра прогнозов, вероятностей и правил, "стоящими" за этими прогнозами.
Рон Хардман (Ron Hardman) работает со школами Academy District 20 в Colorado Springs, Colorado, и является основателем компании 5-Mile Software. Он соавтор книг Oracle Database 10g PL/SQL Programming и Expert PL/SQL, вышедших в Oracle Press, и консультант Oracle ACE.
Архитектура Oracle Data Mining
Согласно новой архитектуре Oracle Data Mining функции data mining переносятся в базу данных. В комплекте Oracle Data Mining Suite Release 3.7 данные выбираются из базы данных, где происходит все манипулирование с данными, раскапывание и зачет (mining, and scoring). Пользователи взаимодействуют с этим ПО через графический интерфейс Windows.
Новые продукты data mining от корпорации Oracle (см. ниже) будут использовать более тесную интеграцию с базой данных для минимального перемещения данных и максимального доступа пользователей. Используя более тесную интеграцию с базой данных, новая архитектура data mining облегчит агрегирование данных из различных источников. Данные, как традиционного офлайнового бизнеса, так и е-бизнеса могут быть более легко консолидированы, управляемы, "раскопаны" для большего понимания и получения полного представления об этом новом клиенте.
Пользователи смогут использовать функциональность data mining через браузер тонкого клиента и API на основе Java.
Архитектура Oracle Personalization
Продукт Oracle Personalization разработан на основе концепции базы данных в оперативной памяти для обработки с нужной скоростью больших объемов данных, связанных сWeb. Реализации алгоритмов Naive Bayes и Associations algorithms для параллельных компьютерных архитектур обеспечивает проникновение в суть процессов Интернет-пользователям как в режиме реального времени, так и неопративном режиме. Средства data mining в Oracle Personalization реализованы на стороне сервера и используют возможности параллельных многопроцессорных (SMP) систем, так что можно использовать общую мощность множества компьютеров и выполнять анализ в "n" раз быстрее и "раскапывать" в "n" раз больше данных Web-сайтов. Механизмы рекомендаций обслуживают Web-сайты предприятия в режиме реального времени.

Что такое Data Mining?
Давайте рассмотрим, что такое Data Mining, и чем он дополняет и отличается от средств выдачи запросов и формирования отчетов, OLAP и других аналитических средств.
"Попросту говоря, data mining обычно используется для обнаружения
(скрытых) закономерностей в ваших данных для того, чтобы помочь
вам принимать более лучшие деловые решения."
Роберт Смолл, Two Crows Corporation
Data mining помогает найти скрытые ранее закономерности и отношения в ваших данных для того, чтобы можно было принять более обоснованные решения. А теперь рассмотрим некоторые обшеизвестные определения.
Средства формирования запросов и отчетов помогают выбрать информацию из базы или хранилища данных. Они вполне хороши при ответе на вопросы типа: "Кто покупал заемные ценные бумаги за последние 3 года?"
Средства OLAP идут дальше этого, обеспечивая получение итогов, сравнений и предсказаний путем экстраполяции. OLAP хорош при проведении детализации (drill-down) для получения более подробных данных, таких как: "Каково распределение по доходу покупателей заемных ценных бумаг (mutual funds)?"
Средства формирования запросов и отчетов, а также OLAP, хороши тогда, когда пользователю нужна детализация и понимание того, что произошло в прошлом. Data Mining идет дальше, анализируя прошлое для того, чтобы предсказать будущее.
Data mining "углубляется" в данные, чтобы открыть полезные закономерности и нюансы, которые "погребены" в данных из-за огромного размера этих данных и сложности проблем. Data mining хорош при обнаружении тонких нюансов (detailed insights) и совершении индивидуальных предсказаний типа: "Кто, возможно, купит заемные ценные бумаги в следующие 6 месяцев и почему?" Средства формирования SQL-запросов и отчетов полезны при детализации данных . Если вы знаете, что ищете в своей огромной корпоративной базе данных, располагаете хорошим инструментом, хорошим аналитиком и у вас полно времени, вы постепенно найдете ответ. Средства OLAP и статистического анализа превосходны для извлечения информации с целью анализа и получения отчетов, но они могут отказать, когда объем данных становится чрезмерным для этих средств. Кроме того, когда вы имеете дело с более чем, к примеру, 25 входными переменными, техника традиционного статистического регрессионного анализа отказывает.
Data Mining от Oracle: настоящее и будущее
Чарльз Бергер, подразделение корпорации Oracle по развитию Data Mining
Источник: "Oracle’s Data Mining Solutions", Oracle OpenWorld White Paper, Конференция OOW2000, San Francisco, доклад 134,
http://openworld.oracle.com,
перевод на русский язык "Oracle Magazine/Русское Издание" №1, 2001г.
Концепция Data mining
Data mining предлагает иной, "вверх дном" (bottom-up) подход. Data mining "просеивает" данные ("sifts" through the data), одну запись и одну переменную за один раз, раскрывая ранее скрытую информацию, которую, вы, наверное, раньше никогда не раскрывали, просто вследствие огромного количества данных. Разработаны масштабируемые инструменты data mining для решения этих сложных и больших, насыщенных данными и требующих большой вычислительной мощи проблем.
Давайте рассмотрим пример, чтобы понять как работает data mining.
Data mining просеивает данные, запись за записью и переменная за переменной. Разработан ряд методов, алгоритмов для data mining (или обучения машины - machine-learning) для поиска закономерностей (patterns) в данных, такие как нейронные сети (neural networks), деревья решений (decision trees) и алгоритмы кластеризации (clustering algorithms).

В этом случае мы используем алгоритм "дерево решений" для ответа на вопрос: "Кто, возможно, купит автомашину Buick?" При каждом расщеплении дерева клиенты делятся на две группы. В данном примере первое расщепление происходит на основе возраста и второе - на основе пола. Отметим, что по мере того как data mining "вкапывается" все глубже и глубже в данные, он создает все больше "отфильтрованных" (refined) сегментов однородных групп клиентов с похожим поведением.
Каждый конечный узел предоставляет "правило" ("rule"), которое описывает группу клиентов. Чем глубже вы спускаетесь по дереву, добавляя характеристики "правилу", тем выше уровень "уверенности" ("confidence") в точности предсказания. Например, правило нижнего левого узла дерева таково "Родители владеют автомобилем Buick, Мужчина, возраст более 45 лет" ("Parents owned Buick, Male, and Age is over 45") с уровнем уверенности 92%, что клиент с этим профилем купит Buick. Обладая такой информацией, компании могут взаимодействовать с клиентами индивидуализировано.
Обзор
Корпорация Oracle предлагает своим пользователям набор продуктов класса и сервисов класса Data Mining (Добыча Данных или ИАД (Интеллектуальный Анализ Данных)). Этот набор помогает компаниям понять и предвидеть поведение клиентов (покупателей, заказчиков) и создавать полные интегрированные решения по управлению отношениями с клиентами (CRM).
В настоящее время вы можете использовать комплект Oracle Data Mining Suite (ранее известный как "Oracle Darwin") для построения моделей предсказания (predictive models), обнаруживающих скрытые в ваших данных закономерности и новую ценную информацию, которая может быть использована:в системах раннего обнаружения экстремальных ситуаций;для более полного понимания поведения и запросов клиентов и рыночной ситуации;для определения эффективности различных видов продаж;как помощь в борьбе со злоумышленниками.
Информация, извлеченная из данных таким образом, обеспечивает бизнес-анализ, результатом которого является улучшение отношений с клиентами и, тем самым, увеличение доходов и экономия в основном бизнесе.
В этой статье обсуждаются:преимущества Data Mining;определение Data Mining;обзор возможностей комплекта Oracle Data Mining Suite;функциональность Data Mining в приложении Oracle CRM 11I;новый продукт для персонализации и Data Mining в среде Web;будущее Data Mining от Oracle.
ORACLE DATA MINER
Oracle Data Miner расширяет концепцию Oracle Personalization применительно к типовым применениям data mining и предлагает аналогичный пользовательский интерфейс, а также адаптированные "методологии", разработанные для решения предварительно определенных проблем бизнеса - например, модели формирования ответов и лояльности ( loyalty and response modeling). Oracle Data Miner предлагает для тонкого клиента с браузером пользовательский интерфейс к большинству стандартных функций Oracle Data Mining Suite Release 3.7.
Oracle Data Miner заменит функциональность Oracle Data Mining Suite, упрощая, автоматизируя и расширяя применение функциональности data mining. Oracle Data Miner будет более тесно интегрирован с СУБД Oracle9i для быстрого преобразования данных, более быстрого построения моделей, автоматизированного "подсчета очков" ("scoring") и
запоминания результатов в базе данных. Мастеры шаг за шагом проведут пользователя через этапы data mining, но позволят пользователям-экспертам настроить значения по умолчанию. С продуктом Oracle Data Miner сотрудники, ведущие маркетинг на основе базы данных могут принять значения по умолчанию, чтобы подготовить данные для анализа и получить специфичную для приложения помощь и советы. Результаты data mining, например, "отчет о неопределенных рисках" ("churn jeopardy report"), могут быть автоматически созданы и показаны с использованием средств корпорации Oracle для формирования запросов и отчетов.
Oracle Data Miner делает обоснованные предположения о том, как обрабатывать данные и предоставляет рекомендации пользователю для принятия или отклонения.
Oracle Data Miner автоматизирует задачи применения моделей data mining к "неклассифициремым"("unclassified") данным и размещения результатов в базе данных для доступа других пользователей и приложений. Стандартные отчеты, такие как отчеты "Наболее рискованные операторы" ("High Risk Churners") и "Наиболее вероятные респонденты" ("Likely Responders") создаются автоматически.

В настоящее время [обзор составлен в 2000 г. - прим. ред.] Oracle Data Miner запланирован к выпуску вскоре после выхода коммерческой версии Oracle9i.
В Антона Шмакова к этой статье кратко рассматриваются история Data Mining в Oracle и состояние дел на конец 2007 г.
Oracle Data Mining Suite (DARWIN RELEASE 3.7)
Комплект Oracle Data Mining Suite Release 3.7 - это программный продукт data mining, выполняющийся на UNIX-сервере, который предоставляет легкость использования и богатую функциональность для решения сложных проблем. Oracle Data Mining Suite находит скрытые закономерности в данных, строит модели предвидения (predictive models) и помещает свои "предвидения" ("predictions") и "интуиции" ("insights") в базу данных для использования другими приложениями и пользователями Oracle. Иначе говоря, Oracle Data Mining Suite - это "производитель" ("producer") ценной новой информации для других "потребителей" ("consumers") данной организации.
Oracle Data Mining Suite предоставляет легкий в использовании, интуитивно понятный пользовательский интерфейс. Oracle Data Mining Suite предлагает мастер-утилиты (wizards) для упрощения и автоматизации шагов data mining. Например, мастер Key Fields в Oracle Data Mining Suite автоматически находит переменные, которые наиболее нужны (максимально влияют) при решении некоторого конкретного вопроса. Мастер Model Seeker автоматически строит многие модели data mining, показывает интерактивные графы (interactive graphs) и таблицы результатов, а также рекомендует наилучшие модели.
Oracle Data Mining Suite предлагает всю эту функциональность в дружественной пользователю среде, которую бизнес-аналитики могут использовать, причем они могут использовать мощные, возможно, многопроцессорные (SMP) системы и, благодаря этому, смогут "раскапывать" огромные массивы данных и извлекать больше ценной информации.
Oracle Data Mining Suite может получать данные из различных сетевых источников данных. Oracle Data Mining Suite извлекает информацию из баз данных Oracle, используя технологию прямого доступа к данным Oracle (OCI). Корпорация Oracle также предоставляет шлюзы (gateways) к данным, хранимым в других базах данных. Как только вы обеспечите Oracle Data Mining Suite данными, вам часто будет нужно подготовить эти данные для анализа, и Oracle Data Mining Suite предоставляет обширный набор функций преобразования, таких как отбор образцов (sampling), случайный выбор (randomization), генерация новых вычисляемых полей, обработка (handling) отсутствующих значений, слияние (merging), замена значений, расщепление набора данных в последовательность (train) поднаборов, тестирование и наборы данных для сверки (evaluation datasets) и так далее.
На фазе построения моделей Oracle Data Mining Suite предоставляет множество алгоритмов -C&RT, деревья классификации и регрессии (classification and regression trees), также известных как деревья решений, нейронные сети (neural networks), алгоритм нахождения ближайших k соседей (k-nearest-neighbors technique of memory-based reasoning) и кластеризация (clustering). Все эти алгоритмы полнофункциональны (full-featured), протестированы, документированы и хорошо поняты.
Кроме того, они очень мощны, так как все они были реализованы таким образом, чтобы использовать аппаратуру параллельных вычислений для скорости и обработки больших объемов данных - гигабайтов и терабайтов.


Перечислим некоторые основные функции Oracle Data Mining Suite Release 3.7:Мастеры прямого импорта и экспорта для доступа к данным из баз данных Oracle и запоминания результатов и предвидений Oracle Data Mining Suite в этих базах данных.Мастер Model Seeker, который автоматически строит многие различные модели data mining, представляет результаты в интерактивных графах и таблицах, а также рекомендует лучшие модели.Задание вычисляемых полей, которое позволяет пользователям создавать новые выводимые поля, используя более 100 формул - статистических, математических, сравнения и булевской логики.Функция показа интерактивного дерева (interactive Tree), которая позволяет пользователям просматривать и запрашивать деревья решений и правила, генерируемые Oracle Data Mining Suite.Мастер Key Fields, который автоматически просеивает данные, используя серию погружений по C&RT в данные для определения полей, которые наиболее нужны при решении некоторой конкретной проблемы. Результат мастера Key Fields может быть полезным поднабором полей данных для ввода в OLAP.
ORACLE PERSONALIZATION(tm)
Oracle Personalization - это новое средство, которое будет доступно с базой данных Oracle9i. Это средство обеспечит персонализацию в масштабе реального времени для каналов продаж е-бизнеса, таких как Web-магазины, среды сдачи приложений в аренду и центры обработки звонков. Oracle Personalization предоставляет интегрированный механизм выдачи рекомендаций (в масштабе реального времени), который будет полностью встроен в СУБД Oracle9i.
Oracle Personalization разработан для решения проблем обработки огромных объемов данных Web и обеспечить персональные (1:1) отношения, которые необходимы е-бизнесу, чтобы выдерживать современный уровень конкуренции. Поскольку Oracle Personalization будет использовать масштабируемость Oracle9I, этот продукт сможет анализировать большие объемы данных о клиентах, в то же время сохраняя индивидуальные отношения с клиентами.
Oracle Personalization использует технологию data mining, чтобы просеить горы данных электронного бизнеса, сгенерированных пользователями при посещении web-сайтов (click), транзакциями, а также демографические данные и данные рейтингов, собранные с Web-сайтов. Oracle Personalization предоставляет механизм рекомендаций в масштабе реального времени и отвечает на такие вопросы, как:Какие N предметов персона A наиболее вероятно купит (или они, предметы, ему нравятся?Люди, которые купят или им нравится, предмет X, возможно, купят или им понравится какие-то другие предметы?Насколько вероятно, что персона A купит или ей понравится предмет X?Какие N предметов персона A наиболее вероятно купит или ему они понравятся при условии, что он покупает или ему нравится какой-то другой предмет?Какие дополнительные N предметы наиболее похожи на предмет X?
Oracle Personalization помогает компаниям установить истинно однозначные (1:1) отношения через Internet, предоставляя для работы с е-клиентами индивидуализированные рекомендации, оценки вероятности того, что этому клиенту подойдут эти рекомендации и улучшенную навигацию по сайту на основе интересов и профилей клиентов.
Oracle Personalization позволяет пользователям создавать "фермы механизмов рекомендаций" ("recommendation engine farms"), которые предоставляют индивидуализированные рекомендации Web-сайтам на основе анализа поведения Web- клиентов. Модели предсказания Oracle Personalization могут модифицироваться периодически, т.е. ежедневно, еженедельно, ежемесячно и использоваться механизмами рекомендаций.
Преимущества Data Mining
Данные собираются из различных источников: служб обслуживания клиентов, ввода заказов, продаж, а также из web-сайтов и т.д. Данных много, но как использовать их должным образом? Как получить полное представление о клиентах? Как узнать, что покупатель, который только что купил товар в вашем магазине, это тот же самый человек, который оставил жалобу на вашем web-сайте или просматривал ваш сайт в поисках других товаров и услуг? Как можно получить полное (360 градусов) представление о клиенте, если все данные о нем находятся во многих и столь различных источниках данных?
Ответ - в ваших данных! Вы должны консолидировать все эти данные в один источник с унифицированным представлением о пользователе, в рамках которого агрегируются все данные. Большая возможность заключается в исследовании, "раскопке" этих данных с целью лучшего понимания своих клиентов и предвидения их потребностей. Исследуя эти данные, вы можете найти подробные профили своих лучших клиентов, а затем найти других клиентов, которые соответствуют этим профилям. Вы сможете предвидеть их запросы и предложить им товары и услуги, которые их удовлетворят, удержать этих людей в качестве своих клиентов и увеличить доходы, благодаря продаже им дополнительных товаров и услуг.
Проблема заключается в том, как использовать, обработать должным образом эти данные? Как определить наиболее релевантные, имеющие наибольшее значение для данного вопроса, данные? Какие факторы определяют удовлетворенность клиентов? Часто настоящая ценность данных скрыта в деталях, относящихся только к отдельным клиентам. Но со всей информацией такого рода есть риск утонуть в данных, если вы не сможете с ними справиться.
В условиях современной конкурентной экономики критическое значение для предприятий приобретает управление их наиболее ценными активами - клиентами и информацией о них. Именно здесь Data Mining может помочь. Data Mining поможет проанализировать огромные массивы и найти скрытую, но ценную информацию, которая может помочь вам лучше понять своих клиентов и предвидеть их поведение. А конкретнее, именно комплект Oracle Data Mining Suite поможет вам это сделать.
Вооружившись этой ценной информацией, можно выстроить более близкие отношения с клиентами, понять их, что позволит:лучше удерживать клиентов и избежать "пены", ненужных действий;составлять профили клиентов и понимать их поведение;поддерживать и повышать уровень прибыли;сократить затраты клиентов при покупках;выходить на клиентов с нужными им предложениями.
Комплект Oracle Data Mining Suite поможет выйти за пределы, доступные традиционным генераторам отчетов, которые сообщают только что произошло. А этот комплект проанализирует прошлое и использует его, как основу для предсказания будущего. Анализируя профили ваших лучших клиентов, Oracle Data Mining Suite поможет идентифицировать других людей, кто пока не являются вашими наиболее ценными клиентами, но соответствуют профилям тех, кто ими уже стал. Знание "стратегической ценности" клиентов - тех, кто могут стать ценными в будущем и тех, кто вряд ли станет такими, - является ключевым условием для активного управления бизнеса.
Средства data mining, интегрированные в приложение Oracle CRM 11i
В приложение Oracle CRM 11i добавлены средства data mining для проведения сфокусированных целевых маркетинговых кампаний, направленных на списки клиентов, которые с большой вероятностью ответят на предложения. Oracle Data Mining Suite может быть применен, используя разумно заданные значения по умолчанию, для ответа на некоторый ограниченный набор предварительно специфицированных бизнес-вопросов, включая:Какие клиенты, возможно, ответят предложение, сделанное по электронной почте или по прямой адресной рассылке?Какие клиенты, возможно, останутся лояльными?Какие клиенты будут "доходными"?
Пользователи CRM могут разрабатывать целевые кампании, выбирая кнопку "Audience" и отвечая на несколько простых вопросов. Для этих пользователей вся подготовка данных, анализ (data mining) и "зачет" ("scoring") данных производятся автоматически.

Отныне приложение CRM 11i Marketing Online позволяет бизнес-аналитикам и профессиональным сотрудникам маркетинга воспользоваться мощью data mining без необходимости изучения сложных методов аналитики и выполнения интенсивной подготовки данных.

Менеджеры, изучающие рынок, могут просто выбрать верхнюю десятку потребителей, которых и определить, как наиболее вероятных респондентов, отвечающих некоторому типу поведения.
