Методы обучения в системе ODYSSEUS
Методы обучения, которые рассматривались в главе 20 (пространство версий и IDЗ), иногда называют методами, основанными на подобии (similarity-based). Реализация обучения на основе этих методов требует обработки больших объемов информации — позитивных и негативных примеров, — из которой извлекаются характерные свойства нового концепта.
Альтернативой таким методам являются методы, основанные на пояснениях (explanation-based), которые позволяют выполнить обобщение на осно.ве единственного обучающего экземпляра. Это становится возможным, поскольку в таких методах процессом обобщения "руководят" знания, специфические для конкретной предметной области. Обучение, основанное на пояснениях, является дедуктивным или аналитическим, а не эмпирическим или индуктивным [Bergadano and Gunetti, 1996]. Иными словами, при такой методике описание нового концепта формируется в результате анализа предъявленного экземпляра в свете имеющихся фоновых знаний.
Методика логического вывода на основе прецедентов, которой была посвящена глава 22, позволяет решить новую проблему, адаптируя ранее полученные решения аналогичных проблем. Эта же методика может быть использована и для обучения, поскольку если уж ранее сформированное решение адаптировано применительно к новой проблеме, его можно добавить в базу прецедентов для использования в будущем.
Ниже будут более подробно рассмотрены методика обучения на основе пояснений и возможность использования прецедентов для машинного обучения.
Термином обобщение на основе пояснений (EBG — explanation-based generalization) обозначается независимый от, предметной области метод использования знаний, специфических для предметной области, для контроля процесса обобщения по единственному обучающему экземпляру.
Использование метода EBG предполагает, что система располагает следующей информацией:
позитивным экземпляром обучающей выборки;
теорией предметной области;
определением концепта, который система должна "изучить".
Для формализации этих идей обычно используется язык логического программирования (см. главу 8). В частности, концепт, как правило, представляется в форме предиката, который характеризует то подмножество пространства объектов, которое нас интересует. Например, предикат сuр(Х) может представлять понятие "cuphood" (чашкообразность), которое определено в стиле языка PROLOG как сосуд малого объема (small), обладающий свойствами open (открытый), stable (устойчивый). Напомним, что выражение
а :-b.
читается как "а истинно, если b истинно". Тогда: cup(X) :- small(X), stable(X), open(X).
Знания о предметной области должны включать описания условий, выполнение которых необходимо для того, чтобы объект можно было считать "устойчивым" (stable), например указано, что объект должен иметь плоское дно, определение свойства "открытый" (open) — например, объект должен иметь вогнутую форму, причем центр кривизны должен быть расположен выше основания.
В качестве экземпляра обучающей выборки укажем объект с плоским дном вогнутой формы, диаметр которого не превышает нескольких дюймов. Экземпляр должен "сопровождаться" пояснением, что указанные свойства вполне достаточны для представления понятия "cuphood". Образец обычно описывается некоторым количеством фундаментальных литералов (ground literals), например:
color(red, obj). diameter(4, obj). flat(bottom, obj). concave(top, obj).
Эти литералы представляют определенный объект obj красного цвета (red) с плоским дном (flat bottom), вогнутый, причем центр кривизны располагается сверху (concave top). Знания о предметной области, представленные ниже, позволяют распознать этот экземпляр как представляющий концепт сир:
small(X) :- diameter(Y, X), Y < 5. stable(X) :- flat(bottom, X). open(X) :- concave(top, X).
Обратите внимание — то, что объект obj является чашкой, логически следует из этого фрагмента знаний. Наше пояснение, почему obj является чашкой, фактически есть доказательство. Этим завершается фаза пояснений в EBG.
Далее начинается фаза обобщения— вырабатывается набор достаточных условий, которые существовали при пояснении. Главное, что нужно при этом сделать, — определить самые слабые условия, которых достаточно, чтобы на основании имеющихся знаний прийти к заключению, что obj — это чашка. Полученное в результате обобщение концепта состоит в том, что чашкой является объект с плоским дном, вогнутый, с центром кривизны вверху и диаметром менее 5:
cup(X) :- flat (bottom, X), concaveftop, X), diameter(Y, X), Y < 5.
Обратите внимание на то, что это обобщение логически следует из исходного определения понятия "чашкообразности" и базовых знаний о том, что такое "малый объем", "устойчивость" и "открытость". В этом смысле новое обобщение уже было неявно представлено в ранее имевшихся знаниях. Анализ представленного образца позволил сделать это обобщение явным. Кроме того, использование сформированного заранее обобщенного определения "чашкообразности" позволило нам совершенно безболезненно проигнорировать несущественные характеристики, в данном случае — цвет.
Обучение на основе прецедентов (CBL — case-based learning) представляет собой подход к обучению, совершенно противоположный методу EBG. Как было показано в главе 22, извлечение информации при таком подходе базируется в основном на подобии аргументов, а не на их логическом анализе. Можно с полным правом утверждать, что процесс адаптации сформулированного ранее решения к новой проблеме не включает обобщения в смысле логического программирования. В качестве дополнительного средства, обеспечивающего использование знаний об отношениях между сущностями предметной области, можно использовать иерархию абстракций, в частности в форме семантической сети. Однако результатом будут не новые правила, включающие переменные, а скорее новые прецеденты, сформированные из старых подстановкой констант.
Рассуждения на основе прецедентов — это, по сути, рассуждения по аналогии, а не логический вывод. Если некто придет к заключению, что Джон, владелец Порше, — водитель, склонный к риску, поскольку имеется прецедент, что Джек, который ездит на Ферра-ри, тоже склонен к риску, то фактически по аналогии делается вывод— Джон похож на Джека, так как автомобиль Порше имеет много общего с Феррари. Напрашивается заключение, что, когда строится такая аналогия, каждый прецедент неявно генерирует определенное правило. В нашем примере такое обобщенное правило состоит в том, что люди, которые ездят на спортивных автомобилях, склонны к риску. Но такое правило не является полным. Все ли водители спортивных машин склонны к риску, или только водители-мужчины, или молодежь? Программа, использующая методику рассуждений на основе прецедентов, не может ответить на такой вопрос. Она способна только отыскать прецедент, наиболее близкий к рассматриваемому случаю.
Между методами CBL и EBG есть и кое-что общее. Оба метода можно противопоставить индуктивным методам, рассмотренным в главе 20, поскольку ни тот ни другой не предполагает анализа большого количества данных. Мы уже показали, что методу EBG достаточно иметь один обучающий экземпляр, а метод CBL для формирования аналогии может обойтись одним подходящим прецедентом.
Но обучение — это нечто большее, чем просто накопление сведений. Система, основанная на анализе прецедентов, должна обладать способностью выявить неподходящие прецеденты, которые не позволяют получить удовлетворительное решение насущной проблемы. В противном случае она будет накапливать прецеденты с ошибочными решениями.
Программа CHEF, описанная в главе 22, способна выявить ситуацию, в которой она формирует неудачный рецепт, и предпринимает попытку исправить его. Чтобы сделать это, программа должна объяснить, почему она полагает рецепт неудачным. Для этого программе требуется воспользоваться определенными знаниями из предметной области, которые в таком случае должны иметь форму правил причинной связи.
Например, модули извлечения и модификации могут предложить замариновать креветок, а потом уже их чистить. Но в этом случае креветки станут слишком влажными, и в рецепте не удастся реализовать заданное в заказе свойство "очищенные креветки". Программа обнаружит это, когда попытается смоделировать процесс приготовления блюда по созданному рецепту. Тогда другой модуль системы, ответственный за восстановление, обратится к знаниям о типах ошибок в рецептах, отыщет подходящую стратегию исправления ситуации и повторит этап составления рецепта. В новом рецепте сначала нужно очистить креветки, а уже потом их мариновать.
Даже после того, как будет получено решение для нового случая, программа не сможет его правильно индексировать до тех пор, пока не поймет, почему это решение считается успешным. Если пользователь заказывает легкое, нежирное блюдо и если программа, манипулируя прежними рецептами, сформировала новый, то этот результат можно использовать в будущем только после того, как с ним будут ассоциированы признаки "легкий" и "нежирный".
Системы ODYSSEUS и MINERVA
Программа ODYSSEUS обучается тому, как совершенствовать базы знаний экспертных систем, предназначенных для решения проблем эвристической классификации (см. главы 11 и 12). Она наблюдает за тем, как эксперт решает проблему, и формирует пояснение каждого действия эксперта (например, запрашивая эксперта, почему некоторому атрибуту присвоено то или иное значение). Формирование пояснений базируется на тех знаниях о проблемной области и стратегии решения проблем, которыми располагает программа. Если программе не удается сформировать пояснение, инициируется процесс коррекции базы знаний.
Оболочка экспертной системы MINERVA
MINERVA— это оболочка экспертной системы, разработанная на базе EMYCIN и NEOMYCIN (см. главы 10-12). Система MINERVA обеспечивает ODYSSEUS базой знаний и методом решения проблем и разработана специально для поддержки метода обучения EBL. Одно из главных отличий системы MINERVA от EMYCIN состоит в том, что в ней представлены не только знания о предметной области, но и стратегические знания, отражающие способ мышления практикующего врача. Такие знания можно рассматривать как дальнейшее развитие метаправил систем MYCIN, EMYCIN и NEOMYCIN.
Главным компонентом этой системы является база медицинских знаний о диагностировании менингита и других неврологических заболеваний. MINERVA реализована на языке PROLOG, и знания о предметной области представлены в этой системе в виде фраз Хорна (см. главу 8), но правила по содержанию аналогичны тем, что использовались в MYCIN. Например, следующее выражение представляет тот факт, что фотофобия может быть связана с головной болью:
conclude(migraine-headache, yes) :- finding(photophobia, yes).
Знания о состоянии проблемы записываются в виде выражений для фактов в процессе работы системы. Например, выражение
rule-applied(rulel63).
утверждает, что в процессе работы системы было активизировано правило 123 и что эта информация доступна программе в процессе дальнейшей работы. Другое простое выражение
differential(migraine-headache, tension-headache).
зафиксирует тот факт, что мигрень и повышенное давление — текущие гипотезы, выдвинутые программой.
Очевидно, что такая информация может быть представлена и зарегистрирована любым способом, например установкой флагов или переменных, но наиболее целесообразно использовать такое же представление, какое принято в базе знаний предметной области.
Несложное метаправило может быть представлено в следующем виде: goal(findout(Р)) :- not(concluded(P)), ask-user(P).
Это правило утверждает, что если текущая цель системы — найти значение параметра Р и если система не может прийти к заключению о значении этого параметра на основании имеющихся у нее знаний, то она должна запросить его у пользователя. Поскольку Р является переменной, то головная часть выражения goal (findout (Р)) сопоставляется с выражением цели системы, представленным в явном виде, например goal (f indout (temperature)). Подцели вроде not(concluded(P)) могут быть сопоставлены (успешно или нет) с системными данными, описывающими текущее состояние процесса вычислений, например concluded (temperature).
Такие стратегические знания используются для выработки суждения о текущем состоянии проблемы и принятия решения о том, располагает ли система в данном случае достаточными знаниями. Кроме того, наличие таких знаний упрощает программу обучения, которая может обращаться к структурам на метауровне экспертной системы.
Обучение в системе ODYSSEUS
Способ обучения, который используется в системе ODYSSEUS, существенно отличается от рассмотренных в главе 20. При разработке этой системы преследовалась цель наделить ее способностью расширять существующую неполную базу знаний, а не включать в базу знаний новые понятия на основании анализа обучающей выборки большого объема. Система обучается, "наблюдая" за тем, как эксперт решает задачу, примерно так, как прилежный ученик постигает таинства мастерства учителя, стоя у него за спиной.
Основной вид действий, которые выполняются экспертом в процессе решения проблемы диагностики, — определение значений разнообразных переменных, т.е. характеристик пациента, таких как температура и т.п. Программа, наблюдая за работой эксперта, расширяет свои знания, пытаясь понять, почему эксперту понадобился ответ на тот или иной вопрос.
Таким образом, концепция процесса обучения в системе ODYSSEUS очень близка к формулированию пояснений. Фактически в контексте работы этой системы смысл термина "пояснение" отличается как от общепринятого, так и от того, какой мы придавали ему в главе 16. В ODYSSEUS пояснение — это вид доказательства, которое несет информацию о том, почему эксперт задает определенный вопрос на конкретном этапе решения проблемы диагноза. Смысл определенного вопроса связан как с текущим состоянием проблемы, так и с той стратегией, которой пользуется эксперт. Поэтому, "уразумев", почему был задан вопрос, программа как бы постигает стратегию действий эксперта.
Если программа располагает исчерпывающими знаниями, она способна сформулировать вопрос (а точнее, высказывание, которое стоит за ним) как логическое следствие текущего состояния проблемы, стратегических знаний, заключенных в метаправилах, знаний о предметной области и одной из текущих целей.
Например, если задан вопрос askuser(temprature), то обратный просмотр приведет нас к ближайшей цели goal (f indout (temperature)).
Но эта цель, в свою очередь, сформирована целью более высокого уровня, например желанием применить определенное правило или произвести разделение гипотез. Наличие в текущей ситуации такой цели высокого уровня объясняет, почему была сформирована цель более низкого уровня, а следовательно, почему был задан определенный вопрос. Эта обратная цепочка рассуждений от подцелей к целям выполняется обычными средствами языка PROLOG или даже MYCIN, но обратите внимание — эти рассуждения выполняются на метауровне, т.е. на уровне, который определяет, почему программа работает именно так, а не иначе. Применяемая в системе ODYSSEUS стратегия обучения "из-за спины" включает три основные фазы.
Определение изъяна в базе знаний. Такой изъян обнаруживает себя, когда не удается сформировать объяснения действиям эксперта, используя описанный выше метод обратного просмотра. Неудача такого рода служит сигналом, что пора приступить к обучению.
Формирование предложений для внесения изменения в базу знаний. Если не удалось сформировать доказательство (пояснение в терминологии ODYSSEUS), значит, можно предположить, что в знаниях о предметной области или о состоянии проблемы имеется какой-то изъян. Если это изъян в знаниях о предметной области, можно временно добавить в базу подходящую фразу и посмотреть, будет ли после этого сформировано доказательство. Если же изъян существует в знаниях о состоянии проблемы, программа должна поискать другое доказательство.
Внесение изменения в базу знаний. Метод, который используется в системе ODYSSEUS для внесения изменений в базу знаний, называется "процедурой подтверждения принятого решения". Если не вдаваться в детали, то при этом требуется, чтобы разработчик системы сформировал процедуру, которая будет обрабатывать новые правила, определив, например, на сколько сократится количество конкурирующих гипотез в результате применения правила.
Детали реализации перечисленных фаз выходят за рамки обсуждения в данной книге, но основные принципы довольно очевидны. В применяемой методике экземпляр обучающей выборки представляет собой отдельную пару атрибут—значение, но в процессе сеанса обучения может возникнуть множество таких пар, так как программа пытается объяснить, почему она придает значение каждому из этих экземпляров. Если сформировать объяснение не удается, программа предпринимает попытку модифицировать базу знаний.
Для модификации правил или добавления новых правил в базу знаний программа ODYSSEUS использует также в примитивном виде и метод CBL. Программа располагает библиотекой прецедентов, каждый из которых содержит и соответствующий правильный диагноз. Эту библиотеку программа может использовать для тестирования. Если при тестировании окажется, что сформирован неверный диагноз, программа назначает использованным при этом правилам нечто вроде штрафов.
Предпосылки правил, которые привели к ошибочному заключению, "ослабляются", т.е. сужается зона их" применения. Если же применение правил подтвердило вынесенный ранее правильный диагноз, то соответствующие предпосылки "усиливаются". В этой процедуре есть много общего с тем методом, который используется в системе Meta-DENDRAL, описанной в главе 20. Конечно, этот метод модификации правил не гарантирует решения проблемы, но он может пригодиться для настройки новых правил.
23.3. Использование прецедентов для обработки исключений
В этом разделе мы рассмотрим способ совместного использования правил и прецедентов, отличный от того, какой применен в системе ODYSSEUS. Роль прецедентов при новом подходе состоит не в том, чтобы содействовать модификации правил, а в том, чтобы при обработке исключений служить дополнением тем знаниям, которые представлены в правилах. Таким образом, каждый из компонентов занимается тем, что у него лучше получается, — правила имеют дело с обобщениями предметной области, а прецеденты — с отдельными нетипичными случаями.
Как уже было не раз продемонстрировано в предыдущих главах (см., например, главы 10-15), построение набора правил для экспертной системы— задача далеко не тривиальная. Помимо сложностей, сопряженных с извлечением и представлением знаний, существует еще и проблема полноты охвата предметной области набором правил. В идеале база правил должна быть корректной, непротиворечивой (по крайней мере, в рамках принятой стратегии разрешения конфликтов) и полной. Но по мере того, как количество правил расширяется, а сами правила усложняются, достичь такого идеального состояния становится все труднее.
Особенно сложно учесть в правилах все возможные исключения. Такая попытка приводит к чрезвычайному усложнению правил. Утверждение, что не бывает правил без исключений, давно уже стало общим местом. Иногда эту проблему пытаются решить включением в набор множества "мелких" правил, которые должны активизироваться в таких исключительных ситуациях. Но это означает возлагать на правила несвойственную им функцию — обрабатывать не общий случай, а частный.
Голдинг и Розенблум предложили использовать в экспертных системах гибридную архитектуру, в которой при решении проблем методика использования порождающих правил сочетается с методикой использования прецедентов [Gaiding and Rosenbloom, 1996]. Идея состояла в том, что механизм обработки прецедентов должен использоваться для критического анализа результатов применения правил. Это выполняется путем поиска прецедентов, аналогичных рассматриваемому случаю, если последний можно считать исключением из правила. Такой подход требует, чтобы база прецедентов была индексирована по применяемым правилам. Авторы предложили и соответствующую меру близости, которая позволяет оценить степень подобия текущего случая и прецедента (рис. 23.1).

Рис. 23.1.
Архитектура гибридной системы, использующей правила и прецеденты
Цикл, ПОКА не будет получено решение
{
1 . Для выбора следующей операции использовать правила.
2. Поиск в библиотеке "неотразимых" прецедентов, которые предлагают противоположный вариант выбора операции.
3. Если прецедент найден, использовать предлагаемый в нем вариант операции. Иначе использовать тот вариант, который предлагается правилами.
}
Обратите внимание на то, что обращение к правилам и прецедентам выполняется в каждом цикле. (Если программа не сможет найти ни правила, которое можно было бы применить, ни прецедента, она останавливается.)
Для того чтобы предложенная идея стала работоспособной, прецеденты в библиотеке должны быть проиндексированы по правилам, которым они противоречат. Рассмотрим, например, правило страховки водителей транспортных средств:
"Мужчины не старше 25 лет платят страховой взнос по повышенному тарифу".
Такое правило должно быть связано в библиотеке с прецедентом, в котором упоминается 18-летний юноша, успешно прошедший тесты повышенной сложности и выплачивающий взнос по сниженному тарифу.
На основании каких соображений принимается решение, является ли прецедент "неотразимым" или нет? Предложенное Голдингом решение состоит в следующем. Когда мы проводим аналогию между прецедентом и текущим случаем, мы тем самым формируем некое неявное правило, скрытое от посторонних глаз. Предположим, что в нашем примере речь идет о водителе-мужчине 20 лет, который имеет квалификацию повышенной категории, и мы обнаружили аналогичный прецедент, но в нем речь шла о 1 8-летнем водителе. Эта аналогия сформирует неявное правило в виде
"Мужчины не старше 25 лет, имеющие повышенную квалификационную категорию, платят страховой взнос по сниженному тарифу".
Предположим, что при оценке степени близости, которая необходима для извлечения и последующего анализа прецедентов, возраст водителей разделяется на диапазоны, скажем "до 25 лет", "от 25 до 65 лет" и "свыше 65 лет". Эта мера близости оценит рассматриваемый нами случай и прецедент как очень похожие, поскольку совпадают возрастная категория и пол.
Можно протестировать это правило и на остальных прецедентах в библиотеке и оценить, какой процент выявленных прецедентов оно накрывает. Любой прецедент с мужчиной-водителем повышенной квалификационной категории, чей возраст не превышает 25 лет и который выплачивает взнос по повышенному тарифу, будет считаться исключением и, следовательно, снижать рейтинг прецедента. Если же случаи достаточно похожи, а правило достаточно точное, то аналогия считается "неотразимой" и компонент обработки прецедентов "выигрывает". В противном случае выигрыш будет за применяемым правилом, и в окончательном решении будет использован вариант, следующий из правила.
Таким образом, "неотразимость" зависит от трех факторов:
степени близости случаев, которая должна превышать определенный порог;
точности неявного правила, сформулированного в результате выявленной аналогии; в качестве меры точности берется пропорция прецедентов, которые подтверждают применение этого правила;
4 достоверности оценки точности, которая определяется размером выборки, на которой эта оценка сформирована.
Авторы продемонстрировали возможности предложенной архитектуры на примере задачи определения произношения имен. Реализованная ими система, получившая название ANAPRON, содержит около 650 лингвистических правил и 5000 прецедентов. Результаты испытания системы показали, что она обладает более высокой производительностью, чем системы-аналоги, использующие либо только правила, либо только прецеденты.
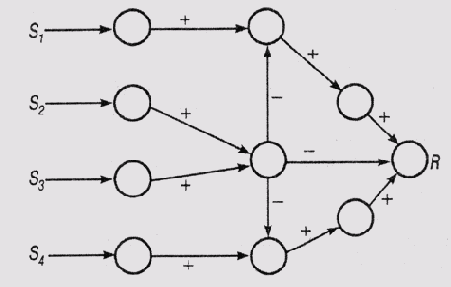
Гибридный символический подход и нейронные сетиВ этом разделе будет рассмотрена перспектива использования нейронных сетей в экспертных системах. Нейронные сети предполагают совершенно другую модель вычислительного процесса, принципиально отличную от той, которая традиционно используется в экспертных системах. В качестве примера будет рассмотрена система SCALIR (Symbolic and Connectionist Approach to Legal Information Retrieval) [Rose, 1994]. Эта система помогает пользователю отыскать правовые документы — описания прецедентов или статьи законов, — имеющие отношение к определенному делу. Поскольку юридическая практика охватывает все области жизни современного общества, использование традиционного подхода, основанного на обычных базах знаний, к поиску и извлечению правовой информации потребует представления в системе огромного объема знаний, в большинстве нетривиальных, представляющих такие сложные понятия, как права, разрешения, обязанности, соглашения и т.п. Проблема усугубляется использованием естественного языка при составлении запросов. Большинство поисковых систем, имеющих дело с запросами на естественном языке, которые используются для поиска в сети World Wide Web, основаны на статистическом подходе, а не на базах знаний. В системе предпринята попытка решить эту проблему посредством сочетания статистического подхода к извлечению информации и подхода, основанного на базах знаний, в которых учитываются смысловые связи между документами. Нейронные сетиВ отношении систем искусственного интеллекта вообще и экспертных систем, в частности, иногда можно услышать следующие критические замечания. Такие системы слишком "хрупкие" в том смысле, что, встретившись с ситуацией, не предусмотренной разработчиком, они либо формируют сообщения об ошибках, либо дают неправильные результаты. Другими словами, эти программы довольно просто можно "поставить в тупик". Они не способны непрерывно самообучаться, как это делает человек в процессе решения возникающих проблем. Еще в середине 1980-х годов многие исследователи рекомендовали использовать для преодоления этих (и других) недостатков нейронные сети. В самом упрощенном виде нейронную сеть можно рассматривать как способ моделирования в технических системах принципов организации и механизмов функционирования головного мозга человека. Согласно современным представлениям, кора головного мозга человека представляет собой множество взаимосвязанных простейших ячеек — нейронов, количество которых оценивается числом порядка 1010. Технические системы, в которых предпринимается попытка воспроизвести, пусть и в ограниченных масштабах, подобную структуру (аппаратно или программно), получили наименование нейронные сети. Нейрон головного мозга получает входные сигналы от множества других нейронов, причем сигналы имеют вид электрических импульсов. Входы нейрона делятся на две категории — возбуждающие и тормозящие. Сигнал, поступивший на возбуждающий вход, повышает возбудимость нейрона, которая при достижении определенного порога приводит к формированию импульса на выходе. Сигнал, поступающий на тормозящий вход, наоборот, снижает возбудимость нейрона. Каждый нейрон характеризуется внутренним состоянием и порогом возбудимости. Если сумма сигналов на возбуждающих и тормозящих входах нейрона превышает этот порог, нейрон формирует выходной сигнал, который поступает на входы связанных с ним других нейронов, т.е. происходит распространение возбуждения по нейронной сети. Типичный нейрон может иметь до 10J связей с другими нейронами. Было обнаружено, что время переключения отдельного нейрона головного мозга составляет порядка нескольких миллисекунд, т.е. процесс переключения идет достаточно медленно. Поэтому исследователи пришли к заключению, что высокую производительность обработки информации в мозге человека можно объяснить только параллельной работой множества относительно медленных нейронов и большим количеством взаимных связей между ними. Именно этим объясняется широкое распространение термина "массовый параллелизм" в литературе, касающейся нейронных сетей. Подход, базирующийся на нейронных сетях, часто рассматривается как несимволический, или субсимволический (subsymbolic), поскольку основная информационная единица, подлежащая обработке, является не символом (как это определено в главе 4), а чем-то более примитивным. Например, символ в LISP-программе, скажем МУ LAPTOP, можно было бы представить схемой активности некоторого числа связанных нейронов в нейронной сети. Но, поскольку нейронные сети часто моделируются программно, сам нейрон представляется некоторой программной структурой, которая, в свою очередь, может быть реализована с использованием символов. Например, роль нейрона может исполнять объект данных, располагающий подходящими свойствами и методами и связанный указателями с другими объектами в сети. Таким образом, на концептуальном уровне в субсимволической системе, реализованной компьютерной программой, которая содержит символы, нет ничего парадоксального. Независимо от способа реализации, нейронную сеть можно рассматривать как взвешенный ориентированный граф такого типа, который описан в главе 6. Узлы в этом графе соответствуют нейронам, а ребра — связям между нейронами. С каждой связью ассоциирован вес — рациональное число, — который отображает оценку возбуждающего или тормозящего сигнала, передаваемого по этой связи на вход нейрона-реципиента, когда нейрон-передатчик возбуждается. Поскольку нейронная сеть носит явно выраженный динамический характер, время является одним из основных факторов ее функционирования. При моделировании сети время изменяется дискретно, и состояние сети можно рассматривать как последовательность мгновенных снимков, причем каждое новое состояние зависит только от предыдущего цикла возбуждения нейронов. Для выполнения обработки информации с помощью такой сети необходимо соблюдение определенных соглашений. Для того чтобы сеть стала активной, она должна получить некоторый входной сигнал. Поэтому некоторые узлы сети играют роль "сенсоров" и их активность зависит от внешних источников информации. Затем возбуждение передается от этих входных узлов к внутренним и таким образом распространяется по сети. Это обычно выполняется посредством установки высокого уровня активности входных узлов, которая поддерживается в течение нескольких циклов возбуждения, а затем уровень активности сбрасывается. Часть узлов сети используется в качестве выходных, и их состояние активности считывается в конце процесса вычислений. Но часто интерес представляет и состояние всей сети после того, как вычисления закончатся, либо состояние узлов с высоким уровнем активности. В некоторых случаях интерес может представлять наблюдение за процессом установки сети в стабильное состояние, а в других — запись уровня активизации определенных узлов перед тем, как процесс распространения активности завершится. На рис. 23.2 показан фрагмент нейронной сети, состоящий из четырех сенсорных узлов S1—S4, возбуждение от которых передается другим узлам сети. Один узел, R, является выходным. Если веса связей в сети неизвестны, то узел R будет возбужден тогда, когда будут возбуждены узлы S1 и S4 Но если будут возбуждены также узлы S2 и S3, это приведет к подавлению возбуждения R даже при возбужденных узлах 5) и S4. Будет ли узел R действительно возбужден при таком состоянии сигналов на входах сенсорных узлов, зависит от весов связей в сети. Количество возможных конфигураций сети такого типа очень велико. Велико и количество способов вычисления состояния нейрона при заданной сумме состояний на его входах. Эти детали теории нейронных сетей выходят за рамки данной книги. Далее мы будем следовать идеям Роуза (Rose) и рассмотрим относительно простую модель нейронной сети, в которой любой узел может быть связан с любым другим узлом и в которой выходом узла является его состояние активности (т.е. не делается различия между активностью нейрона и сигналом на его выходе).
Рис. 23.2.
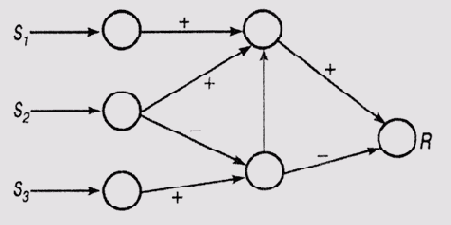
Фрагмент нейронной сети с возбуждающими и тормозящими связями wij — вес связи от узла j к узлу i, neti = Zj wij— состояние в текущий момент времени входов узла l, связанного с другими узлами сети. При любом определении нейронной сети необходимо принимать во внимание и фактор времени, поскольку состояние любого нейрона в некоторый момент времени зависит от его предыдущего состояния и от предыдущего состояния нейронов, связанных с его входами. Определение Сеть связности (connectionist network) может рассматриваться как взвешенный ориентированный граф, в котором для каждого узла i выполняются следующие требования: (1) состояние активности узла в любой момент времени t является действительным числом (будем обозначать его как ai(t)); (2) вес связи, которая связывает узел i с любым другим узлом у сети, является действительным числом wij, (3) активность узла в момент t+1 является функцией от его активности в момент времени t, ai(t); взвешенной суммы сигналов на входах в момент времени t, neti{f); произвольного внешнего входного сигнала xi(t). Простая функция вычисления состояния активности узла i, удовлетворяющая требованию (3) приведенного выше определения, имеет вид ai(t+1) = Cуммаj [wijaj(t)+xl(t)] Это, однако, не единственно возможный способ определения активности. Функции других видов включают добавление термов, соответствующих росту или спаду активности, или имеют вид нелинейных дифференциальных функций (см., например, [Hinton, 1989]). В данной книге они рассматриваться не будут. При конструировании сети веса связей могут быть назначены априори или изменяться со временем. В последнем случае изменение весов является одним из следствий активности сети. Веса можно рассматривать как отражение знаний, а процесс их настройки и уточнения — как процесс обучения системы. Поскольку веса существенно влияют на распространение активности по сети, от них во многом зависит и поведение сети, а следовательно, изменяя веса, можно изменять поведение сети в желаемом направлении. Как отмечено выше, знания в сети связности представлены неявно, поскольку нельзя выделить один определенный структурный элемент сети, который представлял бы отдельное правило или сущность предметной области. Знание отражено именно во взвешенных связях между мириадами отдельных элементов сети. Таким образом, в данном случае мы имеем дело с распределенными знаниями, которые нельзя представить в виде простого перечисления числовых или символических элементов. По этой причине часто можно встретить утверждение, что в нейронных сетях выполняется субсимволическая обработка информации. В сетях связности знания сохраняются не в декларативном виде, а потому они не могут быть доступны для интерпретации со стороны какого-либо внешнего процессора [Rumelhart and McClelland, 1986]. Доступ к знаниям и процесс логического вывода могут быть описаны только в терминах активности сети. Конечно, ничто не препятствует конструктору сети ассоциировать отдельные ее узлы с определенными сущностями предметной области, как это сделал Роуз в системе SCALIR. Однако такое отражение понятий на узлы сети не противоречит ранее сделанному утверждению, что отношения между сущностями неявно представлены в виде связей между узлами и обычно не могут интерпретироваться в форме правил. Следовательно, хотя мы и частично приоткрыли завесу таинственности, скрывающую, что же стоит за узлами сети, сущность взвешенных связей между ними остается по-прежнему "субсимволической". Даже в случае, если узлы представляют сущности предметной области, общая картина активности мириад узлов сети может скрывать понятия достаточно высокого уровня, объединяющие определенные аспекты сущностей, представленных узлами. Пусть, например, узлы представляют слова и пусть узлы "гонки", "машина", "водитель" возбуждены. Этим может быть представлено понятие "водитель гоночной машины" или, наоборот, факт вождения гоночной машины. В любом случае такое представление может расцениваться как субсимволическое, поскольку составляющие его узлы не могут быть оформлены в виде какой-нибудь синтаксической структуры, имеющей явно выраженный смысл. Точно так же нельзя выполнить и семантический анализ состояния мириад узлов с помощью какого-либо внешнего набора правил. SCALIR — гибридная система для извлечения правовой информацииУзлы в сетевой структуре системы SCALIR представляют прецеденты (дела, ранее рассмотренные судами), статьи правовых актов и важные (ключевые) слова, которые встречаются в подобных документах. Таким образом, структурно сеть разделена на три части (слоя), как показано на рис. 23.3. В этой сети слой прецедентов и слой законодательных актов разделены слоем узлов, представляющих ключевые слова (термины). Последние связаны с документами, в которых они встречаются. Таким образом, в базовой структуре сети связь между узлами терминов и документов образует схему индексации с взвешенными связями. В результате массив терминов отображается как на массив прецедентов, так и на массив правовых актов. Вместо того чтобы связывать каждый термин с каждым документом, в котором он встречается, в SCALIR вычисляется вес термина для каждого ключевого слова, связанного с документом, как функция от частоты упоминания этого термина в данном документе и частоты его упоминания во всем массиве документов. Интуитивно кажется, что термином, наиболее подходящим для индексации некоторого документа, будет такой, который часто появляется в этом документе, но редко во всех остальных. Полученное значение сравнивается с пороговым, в результате чего каждый документ индексируется примерно десятком ключевых слов. (Обращаю ваше внимание на тот факт, что на схеме сети системы SCALIR показаны двунаправленные связи. Фактически каждая из них представлена в системе парой однонаправленных связей, причем эти связи могут иметь разные веса. Таким образом, не только термин позволяет найти документ, но и по документу можно отыскать термин.)
Рис. 23.3.
Сеть связности в системе SCAUR ([Rose, 1994]) Такой тип связей (в документации они названы С-связями) не является единственным в SCALIR. Существуют и символические связи (S-связи), которые во многом напоминают связи в семантических сетях, поскольку маркированы и имеют постоянные веса. С помощью связей этого типа в сети представлены отношения между документами, например один документ цитирует другой, в одном судебном решении критикуется другое, один правовой акт ссылается на другой и т.д. Таким образом, S-связи представляют знания в явном виде. В целом сеть сиетемы SCALIR содержит порядка 13 000 узлов терминов, около 4 000 узлов прецедентов и около 100 узлов законодательных актов. Между узлами терминов и прецедентов организовано приблизительно 75 000 связей, а между узлами терминов и законодательных актов — около 2 000 связей. Кроме того, существует около 10 000 символических связей между узлами прецедентов. Роуз не счел нужным останавливаться на том, каких усилий потребовало создание подобной сети, но можно предположить, что такие ключевые задачи, как извлечение терминов и цитирование, были решены программно, а затем на основании этой информации автоматически сформированы узлы сети и связи между ними. Нужно принять во внимание и тот факт, что большинство горидических документов было уже ранее обработано публикаторами, которые составили достаточно полные индексы цитирования и ключевых слов. Описанная сеть была затем использована в качестве базовой информационной структуры для извлечения документов. В основу функционирования системы положен принцип распространяющейся активности (spreading activation). Этот принцип не нов — ранее он использовался Квиллианом для работы с семантическими сетями (см. об этом в главе 6). Использование этого формального аппарата позволяет выяснить, существует ли какое-либо отношение между узлами в сети. Для этого запускается процесс распространения маркеров от узлов, представляющих интерес, и анализируется, произошло ли где-либо в сети "пересечение" распространяющихся маркеров. Основная идея, положенная в основу работы SCALIR, состоит в том, что уровень активности данного узла должен быть пропорционален его "уместности" в рассматриваемом контексте. Если в результате обработки запроса возбуждается некоторое число узлов слоя терминов, это должно привести к возбуждению узлов тех документов, которые касаются данного запроса, причем уровень возбуждения зависит от того, насколько тот или иной документ отвечает сути запроса. Узлы, воспринимающие запросы, являются, по сути, сенсорными узлами нейронной сети, от которых возбуждение по С-связям передается другим узлам. В процессе распространения возбуждения в дело включаются и S-связи, которые передают возбуждения от одних узлов документов другим, связанным с ними. Таким образом, символические связи отражают знания о том, что если определенный документ имеет отношение к полученному запросу, то, скорее всего, и связанный с ним другой документ также имеет отношение к этому запросу. Веса символических связей фиксированы, поскольку сила такой ассоциативной зависимости может быть оценена заранее. Существуют два свойства функции активизации сети, которые представляются крайне желательными с точки зрения приложений, требующих ассоциативного поиска информации. Эти свойства влияют на выбор способа возбуждения сенсорных узлов, воспринимающих запросы пользователей, методики назначения весов связям и формы функции активизации. (1) Количество активности, которое вносится в систему, не должно зависеть от размерности запроса. (2) В каждом очередном цикле распространения активность не должна возрастать. Если первое из указанных требований не будет выполняться, то запрос, состоящий из одного слова, приведет к меньшей активности сети, чем многословный. При этом окажется, что в ответ на более ограниченный многословный запрос система извлечет больше документов, чем в ответ на более свободный однословный, а это противоречит нашим интуитивным ожиданиям. Если же сеть не обладает вторым из сформулированных свойств, то будет извлечено слишком много документов, имеющих крайне слабое касательство к сути запроса, т.е. система будет производить много "информационного мусора". Для того чтобы система обладала первым свойством, нужно на стадии предварительной обработки запроса распределить между входными узлами фиксированное количество активности. Вторым свойством система будет обладать в том случае, если сумма весов выходных связей не будет превышать единицы и, следовательно, значение функции активизации будет меньше или равно ее аргументу. С-связи используют линейную функцию активизации, которая содержит константу сдерживания (retention constant) р, как показано в приведенном ниже выражении. Значение этой константы определяет, какая часть активности узла сохраняется в последующем цикле возбуждения, а какая распространяется дальше по сети. ai(t + 1) = р аj(t) + (1 - p) Sumj [Wij aj(t)] Совершенно очевидно, что приведенная функция активизации будет удовлетворять сформулированным требованиям, поскольку ai(t +1)=< ai(t) до тех пока, пока Sumj[Wij= < 1] Функция такого же вида использована и в работе [Belew, 1986]. Роуз следует идеям, изложенным в этой работе, и в отношении организации управления активностью сети в SCALIR. Для выделения узлов, активность которых достаточна для участия в процессе извлечения информации, вводится параметр Os — порог значимости (significance threshold). Значение этого порога уменьшается по мере распространения активности по сети. Для выделения узлов, активность которых слишком слаба и которые поэтому можно игнорировать в процессе извлечения информации, вводится параметр Oq — порог успокоения (quiescence threshold). Использование этого порога позволяет избежать непроизводительных затрат времени на анализ малоактивных узлов. Эти параметры используются в алгоритме распространения активности по сети SCALIR, который в упрощенном виде представлен ниже. Этот алгоритм реализует метод поиска в ширину, начиная со входных узлов восприятия запроса (QUERY-NODES) и заканчивая всеми взвешеннымисвязями. Установить исходное значение OS. Включить в множество ACTIVE-NODES узлы из множества QUERY-NODES. Цикл { Если имеется запрос, установить уровни активности узлов в QUERY-NODES. Включить в множество RESPONSE-SET все узлы из ACTIVE-NODES, чья активность превышает OS. Удалить из множества ACTIVE-NODES все узлы, чья активность ниже Oq. Добавить в множество ACTIVE-NODES все узлы, связанные с узлами, уже включенными в ACTIVE-NODES. Обновить значение активности всех узлов множества ACTIVE-NODES, используя функцию активизации. Рассортировать узлы в множестве ACTIVE-NODES по уровню активности. Уменьшить значение Os. } пока не будет выполнено (OS =< Oq) или (ACTIVE-NODES = 0). В упрощенном варианте не рассматривается использование параметра, ограничивающего ширину пространства поиска. Кроме того, мы опустили в этой формулировке алгоритма и анализ максимального размера множества выходных узлов. Ограничение множества выходных узлов прекращает выполнение поиска после того, как выделено предельное количество извлекаемых документов. Значение большинства параметров, используемых в процессе управления активностью сети, устанавливается эмпирически. Настройка же весов связей между узлами сети Wij представляет собой, по сути, процесс обучения системы, который мы вкратце рассмотрим в следующем разделе. Организация обучения в системе SCALIRПоскольку веса С-связей могут регулироваться системой в процессе работы, она способна таким образом самообучаться в соответствии с информацией, вводимой пользователем. Ниже мы опишем, как это делается в системе SCALIR, опуская несущественные детали. Предположим, что один из входов узла i связан с выходом узла j, причем связь имеет вес Wij. Если узел i представляет документ, имеющий отношение к термину, представленному узлом j, то в процессе обучения нам может потребоваться усилить эту связь. Если же пользователь посчитает, что документ имеет мало общего с этим термином, то потребуется ослабить эту связь. Главный вопрос, который нужно при этом решить, — в какой степени нужно менять значение веса. Одно из простых правил вычисления значения изменения веса Wij может быть выражено формулой Wi = nfiaj, где n| — константа скорости обучения (learning rate), a fi — коэффициент обратной связи от пользователя, который, например, может принимать значение +1 или—1. Однако применение такого правила не настолько очевидно, как это может показаться с первого взгляда, по следующим причинам. Определить значения уровня активности а, не так просто, поскольку активизированный при возникновении запроса входной узел может снизить свою активность после того, как запрос будет снят. Соседи узлов, которые получают обратную связь, также должны, по-видимому, получать некоторую информацию обратной связи от пользователя, подтверждающую, что они представляют документы, имеющие отношение к запросу. Узел i может находиться в конце сети распространения активности, а следовательно, информация от пользователя (обратная связь) должна распространяться по сети в обратном направлении. Таким образом, получаемая от пользователя информация обратной связи должна распространяться по сети примерно так же, как активность. Максимальное значение обратной связи для каждого узла записывается и обновляется в процессе распространения, и эти значения в дальнейшем играют роль членов fi и аj в приведенном выше выражении. Далее полученные значения весов нормализуются таким образом, чтобы их сумма для каждого отдельного узла была равна 1.0. Конечно, в реальной системе SCALIR процесс самообучения несколько сложнее, поскольку в ней существуют связи разных типов. Читателям, интересующимся деталями этого процесса, следует познакомиться с работой [Rose, 1994], Но идея комбинированного использования символических и субсимволических методов заслуживает дальнейшего углубленного изучения. В системе SCALIR продемонстрирован довольно прагматический компромисс между чисто статистическим подходом к извлечению информации и традиционным подходом для экспертных систем, требующим большого объема знаний о предметной области. Будущее гибридных системИтак, вы могли убедиться на представленном в этой главе материале, что гибридные системы потенциально являются довольно мощным инструментом решения сложных проблем, которые не под силу отдельным "чистым" подходам. На примере сравнения систем ODYSSEUS и EMYCIN вы могли убедиться в том, что в первой использована гораздо более сложная методология построения и настройки базы знаний, которая не идет ни в какое сравнение с методикой синтаксического контроля, примененной в EMYCIN. Предстоит еще очень много сделать в теории экспертных систем, прежде чем такие системы смогут эмулировать способность к постоянному совершенствованию, которой обладает человек-эксперт. Аналогично, комбинирование парадигм использования правил и прецедентов позволяет повысить эффективность обработки исключений, не усложняя при этом набор правил. В системе SCALIR продемонстрирована возможность комбинированного использования в рамках одной системы символического и субсимволического подходов, которые обычно рассматриваются многими специалистами как взаимно исключающие. Следует надеяться, что в будущем мы станем свидетелями еще более значительного прогресса в этом направлении. Однако в теории искусственного интеллекта наблюдаются и тенденции движения в совершенно другом направлении, противоположном созданию гибридных систем. Имеет смысл здесь кратко упомянуть о них. Программное обеспечение систем искусственного интеллекта в значительной мере привязано к определенным платформам и реализовано на языках, которые используются только в области искусственного интеллекта. Методология разработки программного обеспечения систем искусственного интеллекта все еще отстает от современной практики создания программ, предполагающей использование объектно-ориентированного анализа и разработки, так же, как и технологии разработки распределенных многокомпонентных приложений. Для программ систем искусственного интеллекта характерны все недостатки, присущие исследовательским продуктам, — отсутствие полноценной документации, низкая надежность, возможность использования только в организации, где она была создана. Существует еще и психологический барьер, который трудно преодолеть современным исследователям, многие из которых стояли у истоков тех или иных подходов и не склонны переходить на сторону "конкурентов". Но этот барьер, скорее всего, будет преодолен новым поколением исследователей и разработчиков. Рекомендуемая литератураВ последнее время появилось множество программных продуктов, в которых комбинируются методики, основанные на применении правил и прецедентов. Примером может служить система CBR Express, разработанная фирмой Inference Corp., которая используется в качестве надстройки над системой ART-IM [Davles and May, 1995]. Разработки оболочек экспертных систем, в которых комбинируется применение правил логического вывода и обучения или нейронных сетей, находятся пока что в зачаточном состоянии. Попытки использовать нейронные сети в сочетании с традиционными экспертными системами описаны в работе [Кат et al, 1991]. В этой связи следует упомянуть и систему NeuroShell 2, разработанную фирмой Neuron Data, в которой порождающие правила используются для предварительной обработки информации, после чего она передается в нейронную сеть. Полученная на выходе нейронной сети информация также может быть обработана с помощью системы правил.
|