Формирование пояснений на основе знаний
На начальном этапе исследований в области экспертных систем, которые выполнялись в Станфордском университете в 60-70-х годах/поясняющая информация предоставлялась в виде трассировки процесса выполнения программы и использовалась в основном для отладки разрабатываемых систем. Этого было достаточно для разработчиков экспериментальных систем, подобных MYCIN, но не соответствовало тому уровню сервиса пользователя, который необходим для коммерческого программного продукта. Впоследствии вопросу формирования информации, которая давала бы возможность пользователю четко представить себе ход рассуждений программы, стало уделяться значительно больше внимания.
Исследователи пришли к заключению, что автоматическое формирование пояснений требует доступа к модели предметной области точно так же, как и извлечение знаний (см. об этом в главе 10). Другими словами, представление о знаниях в конкретной области необходимо для предоставления пользователю информации о поведении системы в процессе формирования результата точно так же, как и для приобретения новых знаний.
Такое знание позволит перекинуть мост между деталями реализации процесса вывода (например, в какой последовательности активизировались правила) и стратегией поведения системы (например, какие соображения побудили систему выбрать ту или иную гипотезу из множества конкурирующих).
В последние десятилетия специалисты серьезно потрудились над развитием этой идеи, и обзор некоторых из полученных результатов читатель найдет в разделе 16.2. Совершенно очевидно, что проблемы извлечения знаний и формирования пояснений тесно связаны. По сути, они представляют две стороны одной медали. Существенным толчком для совершенствования средств, используемых для предоставления пользователю пояснений, как, впрочем, и для извлечения знаний, стало развитие методов графического интерфейса в современных операционных системах, которые обеспечивают возможность вывода не только статической, но и динамической видеоинформации со звуковым сопровождением.
Подсистема формирования пояснений в MYCIN
Модуль формирования пояснений в экспертной системе MYCIN (о ней шла речь в главе 3) автоматически вызывается по завершении каждого сеанса консультаций. Для того чтобы предоставить пользователю информацию о том, почему система рекомендует именно такие значения медицинских параметров, модуль извлекает список правил, активизированных в процессе сеанса, и распечатывает его вместе с заключениями, которые были сделаны этими правилами. Модуль также позволяет пользователю задавать вопросы системе по поводу выполненной консультации, причем вопросы могут носить и обобщенный характер.
Способность системы отвечать на вопросы пользователя, касающиеся выполненной работы, основывается на следующих функциях:
вывод на экран правил, активизированных на любой стадии консультации;
запись и сохранение в процессе работы активизированных правил и связанных с ними событий, например задаваемых вопросов и сформированных заключений;
использование индексации правил, которая дает возможность извлечь определенное правило в ответ на вопрос, содержащийся в пользовательском запросе.
Как отмечалось в главе 3, процесс выполнения консультаций в экспертной системе, использующей обратную цепочку логического вывода, включает поиск в дереве целей (рис. 16.1). Следовательно, справки о ходе выполнения консультации можно разделить на два типа:
почему система сочла необходимым задать пользователю определенный вопрос;
как система пришла к определенному заключению.
Чтобы ответить на вопрос почему, нужно просмотреть дерево целей "вверх" и определить, какую цель более высокого уровня пытается достичь система. Чтобы ответить на вопрос как, нужно просмотреть дерево "вниз" и выяснить, достижение каких подцелей привело к данной цели (в текущее состояние). Таким образом, процессе формирования пояснений можно рассматривать как некоторый вид прослеживания дерева целей, т.е. свести к задаче поиска в дереве.
Тот факт, что MYCIN отслеживает прохождение структур цель-подцель в процессе выполнения вычислений, позволяет этой системе отвечать на вопросы вроде приведенного ниже.
"Почему вас интересует, является ли окраска микроорганизма грамотрицательной?"
Рис. 16.1.
Формирование ответов на основе дерева целей в системе MYCIN
В MYCIN сохраняется список всех решений, принятых в течение сеанса работы, а затем этот список используется для пояснения и уточнения принятых решений в ответ на вопрос пользователя почему, например, такой:
"Почему вы предполагаете, что Организм-1 это протеин?"
В ответ MYCIN процитирует правило, относящееся к этому заключению, и выведет значение степени уверенности в достоверности этого правила. Системе MYCIN можно также задавать вопросы общего характера. Такие вопросы касаются правил безотносительно к текущему состоянию базы данных, т.е. безотносительно к конкретному пациенту. Например:
"Что прописывать при заражении инфекцией pseudonomas?"
В ответ система выведет тот набор препаратов, который рекомендуется в правилах, касающихся инфекции pseudonomas.
Однако пользователь не может получить доступ к информации, хранящейся в виде статических знаний или в таблицах знаний, поскольку эти источники данных не имеют формата порождающих правил. Кроме того, механизм формирования рекомендаций о курсе лечения и выборе предпочтительных медикаментов представлен в программе в виде LISP-функций, которые пользователь не может просмотреть (а если и сможет, то вряд ли что-нибудь в них поймет). Пользователь также не может задать системе вопросы о том, в каком порядке просматриваются правила в процессе формирования решения и в каком порядке анализируются условия, специфицированные в этих правилах.
Подытоживая сказанное о средствах формирования пояснений в системе MYCIN, отметим, что хотя вопросы как и почему и дают пользователю определенную информацию о порядке логического вывода, но признать ее достаточной можно с большими оговорками. Пользователю трудно проследить за логикой процесса по длинной распечатке активизированных правил. Правда, такая распечатка содержит довольно ценную информацию для инженеров по знаниям и разработчиков системы, особенно на стадии ее настройки.
В тех экспертных системах, в которых используется прямая цепочка рассуждений, список активизированных правил несет еще меньше полезной для пользователя информации, поскольку на промежуточной стадии вычислений трудно по нему судить, куда же ведет цепочка рассуждений.
Формирование пояснений в системах, производных от MYCIN
Вряд ли для кого-нибудь является секретом, что по мере увеличения размеров базы знаний в экспертной системе проблемы понимания ее поведения, оперативного наблюдения и корректировки поведения нарастают как, снежный ком (см., например, [Davis, 1980, b]). Например, бывает трудно обеспечить полную совместимость новых правил с включенными ранее в базу знаний или разобрать в потоке управления в тех ситуациях, когда большое число конкурирующих друг с другом правил пытается "обратить на себя внимание" интерпретатора. Исследователям пришлось немало потрудиться над проблемой обнаружения противоречивости и преодоления избыточности множества правил (см. в [Suwa et al, 1980, b]).
Система EMYCIN (Empty MYCIN — пустая MYCIN) представляет собой оболочку, созданную на базе системы MYCIN [van Melle, 1981]. Идея состояла в том, чтобы удалить из системы MYCIN базу знаний и создать таким образом систему, сохраняющую все функциональные возможности MYCIN, которую в дальнейшем можно наполнять знаниями из той или иной предметной области (подробнее об этом см. в главе 10). В процессе разработки в EMYCIN были внесены некоторые усовершенствования по сравнению с прототипом. Для облегчения работы инженеров по знаниям в ходе отладки новой базы знаний в систему включены команды EXPLAIN (объяснение), TEST (проверка) и REVIEW (просмотр). Как и в MYCIN, команда EXPLAIN выводит на печать список тех правил, которые были активизированы в процессе сеанса работы. При этом выводится еще и дополнительная информация:
(1) значение коэффициента уверенности, полученное в результате выполнения правила;
(2) значения условий, специфицированных в активизированном правиле;
(3) последний вопрос, который задавала система пользователю перед тем, как сформировать заключение.
Использование в MYCIN и EMYCIN метаправил, которые позволяют в явной форме управлять выбором активизируемых правил, создает предпосылки для анализа пользователем стратегии поведения экспертной системы в процессе формирования рекомендаций. Теперь можно было задуматься и над тем, как отразить применение метаправил в формируемых пояснениях, — предоставить пользователю информацию о том, почему в данной ситуации из множества возможных правил система выбрала именно это, а остальные отвергла.
В конце 1970-х годов в Станфорде на основе ранее созданных систем была разработана усовершенствованная программа NEOMYCIN, в которой была предпринята попытка использовать более абстрактный подход к решению медицинских проблем, чем в прототипе, все в той же MYCIN [Clancey and Letsinger, 1984], [Clancey, 1987, с]. В центре внимания разработчиков оказались те знания, которыми пользуются врачи-практики при рутинной процедуре диагностики, и связанный с ними ход рассуждений. Таким образом, было уделено значительное внимание моделированию того метода решения проблемы, который присущ человеку (так называемое когнитивное моделирование). Тот метод логического вывода, который был использован в системе-прототипе MYCIN, вряд ли придет в голову кому-либо из практикующих врачей — совпадают у них только результаты.
Этот новый подход отразился и на средствах формирования пояснений. В NEOMYCIN упор был сделан на пояснении стратегии поведения системы — предоставлении пользователю информации об общем плане решения проблемы и методах, использованных для достижения поставленной цели, а не просто перечислении правил, активизированных в процессе работы [Hasting et al., 1984]. В процессе накопления и интерпретации данных в центре внимания постоянно находилось текущее множество гипотез (дифференциал — термин, производный от дифференциального диагностирования). Для того чтобы разобраться в поведении программы, т.е. в вопросах, которые ставит программа, и в потоке управления, пользователю нужен доступ к стратегии диагностирования, которую использует программа.
Основные принципы организации системы NEOMYCIN следующие.
Стратегические знания отделены от собственно медицинских и представлены в виде метаправил.
Информация о заболеваниях имеет таксономическую организацию, как в системе INTERNIST, и таким образом обеспечено в некотором роде явное представление пространства гипотез.
Знания перечисленных выше типов отделены от правил, которые связывают гипотезы с данными.
Таким образом, основным является все-таки подход на базе эвристической классификации (см. об этом в главах 11 и 12), но смешанная схема представления структур данных и управления использованием правил упрощает реализацию процесса. Кроме того, правила, относящиеся к предметной области, в свою очередь, разделены на четыре класса.
Причинные правила связывают симптомы и гипотезы через сеть симптомов и категорий заболеваний.
Запускающие правила связывают данные с гипотезами и таким образом обеспечивают построение прямой цепочки рассуждений. Когда активизируется правило этого типа, соответствующая гипотеза помещается в дифференциал.
Правила данные/гипотезы также связывают данные с гипотезами, но распространяются они только на те гипотезы, которые уже включены в дифференциал.
Правила отображения представляют такие операции, как ограничение данных, например "если пациент мужчина, то отбросить возможность беременности".
Процитированное ниже метаправило представляет общую стратегию поведения системы, которая заключается в том, что выискиваются данные, отличающие две текущие гипотезы, например данные, которые подтверждают правдоподобность одной гипотезы, но никак не связаны с другой.
METARULE397
ЕСЛИ: В дифференциале имеются два элемента, которые отличаются какими-либо характеристиками заболевания, ТО: Задать вопрос, который позволит выяснить отличие этих заболеваний.
Таким образом, использованный в MYCIN глобальный режим управления, организующий обратную цепочку логического вывода, заменен в NEOMYCIN выполнением метаправил, которые полностью определяют поток управления в программе. Это значительно более радикальный способ использования метаправил, чем тот, который имел место в MYCIN.
Упорядоченный набор метаправил выполнения определенных задач можно рассматривать как своего рода метауровневую архитектуру, в которой задачи и подзадачи соответствуют целям и подцелям на метауровне. Метаправила представляют собой методы достижения абстрактных целей, например "сформировать вопросы", а уже правила предметного уровня задают конкретные вопросы. Вместо того чтобы формировать суждения об отдельных фрагментах информации, метаправила представляют общую стратегию манипулирования информацией.
В дополнение к правилам, которые запрашивают конкретные данные у пользователя, в NEOMYCIN существуют и правила, управляющие процессом опроса пользователя. Эти правила цитируются при формировании пояснения, почему пользователю был задан конкретный вопрос.
Другой вариант модернизации системы MYCIN был осуществлен в 1970-х годах и вылился в создание системы CENTAUR [Aikins, 1983]. В этой программе (см. главу 13) используется смешанное представление знаний, заимствованных из ранее созданной экспертной системы PUFF, предназначенной для диагностики легочных заболеваний. В архитектуре системы CENTAUR фреймы (см. главу 6) и порождающие правила (см. главу 6) объединены таким образом, что это значительно упрощает формирование пояснений.
h1>
Формирование пояснений на основе фреймов
Вы уже имели
возможность убедиться в том, что сформировать достаточно информативные пояснения,
пользуясь только результатами трассировки активизированных правил, довольно
сложно. Информация, содержащаяся в правилах, не несет достаточных сведений о
контексте, в котором эти правила были активизированы. Фактически мы узнаем только
о выполнении тех условий, которые явно специфицированы в активизированном правиле.
Отсутствуют сведения о том, для какой задачи более высокого уровня потребовалось
активизировать то или иное правило. Например, желательно знать, потребовалось
ли это для подтверждения какой-либо гипотезы, или для принятия решения о выборе
между конкурирующими гипотезами, или для запроса данных у пользователя и т.п.В результате исследователи и разработчики экспертных систем в 1980-х годах задумались над тем, как объединить порождающие правила с фреймами, которые могли бы предоставить необходимую информацию о контексте. Во фреймах могут быть представлены важные отношения между данными и гипотезами, которые не нашли отражения в порождающих правилах. Кроме того, фреймы могут служить удобными контейнерами для поясняющих текстов. Когда в начале 1990-х годов в распоряжении программистов появились мультимедийные средства, фреймы стали использоваться для хранения не только поясняющих текстов, но и ссылок на сопутствующие изображения, например схемы, или даже на целые руководства в электронном виде.
h1>
Организация вывода пояснений в системе CENTAUR
Первый вариант
реализации системы PUFF, который был выполнен на основе оболочки EMYCIN (см.,
например, [Aikins et al., 1984]), оказался вполне работоспособным в том
смысле, что хорошо справлялся с решением проблем в своей области, но схема представления
знаний в нем не совсем удовлетворила разработчиков по следующим причинам.С ее помощью трудно представлять типовые образцы данных или типичные классы пациентов.
Добавление или модификация правил при расширении базы знаний или уточнении ранее введенных знаний требовали слишком больших затрат.
Изменение порядка, в котором информация запрашивается у пользователя, также было связано с определенными сложностями, поскольку запросы формируются интерпретатором автоматически, как только активизируются правила.
Особую проблему представляет формирование ясных пояснений, поскольку практически для выполнения этой задачи доступна информация, лишь незначительно более обширная, чем просто результаты трассировки последовательности активизации правил.
Эйкинс (Aikins) также обратила внимание на то, что отчетливо выраженная модульность и единообразие порождающих правил имеет и обратную сторону. Большинство наборов правил обладает неявно выраженной группировкой, которая существует либо в виде определенного порядка индексации, скрытой в интерпретаторе (например, в наборе ORGRULES и PATRULES системы MYCIN, которые относятся к микроорганизмам и пациентам соответственно), либо в виде условий и операций, которые манипулируют лексемами целей в рабочей памяти. Такая организация зачастую имеет иерархический характер, предполагающий таксономический характер организации гипотез (в задачах классификации) и декомпозицию целей на подцели (в задачах конструирования). Многие из упомянутых выше проблем можно свести к минимуму, выделив отдельные виды знаний и манипулируя ими по-разному. Как вы помните из главы 13, в системе CENTAUR разработчики объединили методы программирования, основанные на правилах и концепции фреймов, таким образом, чтобы компенсировать слабости каждого из подходов и усилить их достоинства.
Что касается формирования пояснений, то в системе CENTAUR сделан акцент на контексте, в котором формировалось суждение, и на зависимости между применяемой экспертом методикой и этапом процесса решения проблемы. Для того чтобы понять, почему задан определенный вопрос, нужно принимать во внимание не только то правило, которое при этом активизировано, но и ту гипотезу, которая анализируется на данном этапе. Таким образом, Эйкинс вполне разделяет опасения, высказанные Кленси, хотя ее подход и менее амбициозен, поскольку в нем дело не дошло до когнитивного моделирования.
Работа консультирующей программы CENTAUR состоит в основном из выполнения интерпретатором текущего списка актуальных задач, кроме того, в ней значительно меньше места отводится построению цепочки правил. Основное назначение списка актуальных задач— способствовать формированию пояснений, почему система поступает именно так в ходе данного сеанса консультаций. Поэтому каждый элемент в списке задач содержит информацию как об источнике задачи, так и о причине, которая побудила систему включить данную задачу в список актуальных.
Источником задачи может быть активный прототип (т.е. тот, который наиболее близок к специфическим данным рассматриваемого случая) или другая задача. Новые задачи добавляются в список актуальных либо слотами управления прототипов, либо в процессе выполнения тех задач, которые ранее были включены в список актуальных. Информация о причине добавления генерируется на основе наименования прототипа и имени управляющего слота, ответственного за включение задачи.
В ходе выполнения программы прототип находится в одном из трех возможных состояний:
неактивный, т.е. не рассматриваемый в качестве гипотезы;
потенциальный кандидат, т.е. такой, который имеет смысл рассмотреть исходя из имеющихся значений данных;
активный, т.е. выбранный из множества потенциальных кандидатов и помещенный в список гипотез.
Прототипы заболеваний представляют гипотезы! Список гипотез — это, по сути, список пар "прототип-коэффициент уверенности", упорядоченных в убывающем порядке значений коэффициентов уверенности. Имеются еще два списка, которые служат для отслеживания подтвержденных и отвергнутых прототипов.
Основные события в сеансе выполнения консультации с помощью системы CENTAUR следующие:
ввод исходных данных;
отбор прототипов с использованием антецедентных правил;
оценка прототипов и выбор единственного, который назначается "текущим";
анализ известных фактов и заполнение на их основе полей данных текущего прототипа;
проверка соответствия фактов и ожидаемых значений;
выявление данных, не учтенных начальным вариантом диагноза;
уточнение диагноза на основе выявленных данных;
суммирование и вывод результатов.
В самом начале сеанса в качестве текущего выбирается прототип CONSULTATION (консультация), а в список активных включаются две задачи текущего прототипа: FILL-IN (заполнение) и CONFIRM (подтверждение), которые извлекаются из управляющих слотов TO-FILL-IN и IF-CONFIRMED прототипа. Структура слотов прототипа CONSULTATION представлена ниже.
CONSULTATION
....................
TO-FILL-IN:
Запросить значение TRACING-LEVEL для задачи CONSULTATKDN Запросить значение AGENTA-PRINTING для задачи CONSULTATION Запросить значение STRATEGY для задачи CONSULTATION
IF-CONFIRMED:
Установить порог подтверждения равным 0
Установить относительное заполнение слотов, необходимое для подтверждения прототипа, равным 0.75
Установить процедуру по умолчанию для заполнения слотов: заполнение в убывающем порядке по степени важности Определить предмет консультации Выбрать лучший из текущих прототипов Заполнить прототип
Применить задачи из слота IF-CONFIRMED прототипа Отметить все факты, принимаемые во внимание прототипом Применить правила уточнения, связанные с подтвержденными прототипами; применить правила подведения итога, связанные с подтвержденными прототипами; выполнить операции, связанные с подтвержденными прототипами
Слот TO-FILL-IN прототипа фактически содержит три подзадачи, каждая из которых устанавливает определенную переменную сеанса консультаций: переменная TRACING-LEVEL задает уровень детализации трассировки, переменная AGENTA-PRINTING указывает, будут ли выводиться на печать наименования задач по мере включения их в список активных или по мере выполнения, а переменная STRATEGY может принимать значения CONFIRMATION (выбор наилучшего варианта и подтверждение его), или ELIMINATION (выбор наихудшего варианта и исключение его), или FIXED-ORDER (использование предопределенного порядка обработки гипотез).
Первые три задачи слота IF-CONFIRMED устанавливают значения переменных, управляющих процессом консультации. В частности, одна из переменных определяет, какая часть полей прототипа должна быть заполнена прежде, чем его можно будет считать подтвержденным. Наличие таких переменных позволяет инженеру по знаниям экспериментировать с разными режимами управления процессом и, возможно, настраивать работу системы в разных предметных областях. Остальные задачи слота IF-CONFIRMED управляют отдельными этапами проведения консультации.
После того как будет определен предмет консультации (в настоящем контексте это область легочных заболеваний), следующим текущим прототипом становится PULMONARY-DISEASE. Первой задачей, специфицированной в этом прототипе, является запрос данных у пользователя. Протокол такого диалога представлен ниже (в переводе на русский язык). Нумерованная строка в протоколе — запрос системы, а текст после двух звездочек, выделенный полужирным шрифтом, — ответ пользователя. В квадратных скобках приведены комментарии — сообщения, которыми система дает знать пользователю, что она отыскала соответствующий прототип в базе знаний и в дальнейшем будет рассматривать его в качестве кандидата для более подробного анализа.
------ПАЦИЕНТ-7 -------------
1) Идентификационный номер пациента: 7446
2) По поводу какого заболевания: АСТМА
[Прототип ASTHMA, МП 900]
3) ООЛ/ООЛ предсказываемый:
261
4) ОЕЛ (плетизмографическая) наблюдаемая/предсказываемая: 139
5) ФЖЕ/ФЖЕ предсказываемая:
81
[Прототип NORMAL, МП 500]
6) Отношение ОФВ1/ФЖЕ: 40
[Прототип ОАО, МП 900]
7) ПСОУ/ПСОУ предсказываемая: 117
[Прототип NORMAL, МП 7dO]
8) Изменение в ОФВ1 (после приема бронхолитиков): 31
9) УПМС/УПМС предсказываемая:
12
[Прототип ОАО, МП 900]
10) Наклон П5025: 9
[Прототип ОАО, МП 900]
Рассмотрим подробнее один из вопросов в этом протоколе.
6) Отношение ОФВ1/ФЖЕ: 40 [Прототип ОАО, КУ900]
Аббревиатуры в этих строках обозначают найденные прототипы заболеваний, МП означает "мера правдоподобия", ООЛ, ОЕЛ, ФВЖ и т.д. — результаты лабораторных анализов и измерения легочных функций:
ООЛ — остаточный объем легких, литры;
ОЕЛ — общая емкость легких, литры;
ФУКЕ — форсированная жизненная емкость легких, литры;
ОФВ1 — объем форсированного выдоха за 1 с, литры;
ПСОУ — проникающая способность для окиси углерода.
Введенное пользователем значение 40 отношения объема форсированного выдоха за 1 с (ОФВ1) к форсированной жизненной емкости легких (ФЖЕ) побуждает систему активизировать прототип ОАО (Obstructive Airways Dicease — обтурация воздухоносных путей) с мерой правдоподобности этой гипотезы 900.
Значение меры правдоподобия той или иной гипотезы выбирается в диапазоне от -1000 до 1000 исключительно из соображений упрощения вычислений. Этот параметр отражает степень уверенности системы в обоснованности выдвинутой (активизированной) гипотезы на основе имеющихся данных о конкретной истории болезни. Фактически при определении меры правдоподобия система сравнивает введенные пользователем данные с теми, которые хранятся в слотах прототипа-кандидата. Полученные значения служат основанием для выбора самой правдоподобной из имеющихся гипотез (прототипов). Назначение параметра "мера правдоподобия" в системе CENTAUR такое же, как и коэффициента уверенности в системах MYCIN и EMYCIN, причем для операций с мерами правдоподобия используются те же алгоритмы, что и для операций с коэффициентами уверенности. Обратите внимание — в процессе диалога с пользователем система не объясняет, почему выбрано именно такое, а не иное значение меры правдоподобия. Для пользователя алгоритм вычисления меры правдоподобия является "черным ящиком".
В экспертных системах, полностью основанных на правилах, в протоколе трассировки обычно выводятся только те исходные данные, которые активизируют правило, получившее наивысшую оценку при разрешении конфликта. Пользователю в такой ситуации остается только гадать, как система отреагировала на данные, которые были введены, но не упоминаются в протоколе. Как видно в приведенном выше протоколе диалога с пользователем, программа CENTAUR сразу же дает знать пользователю, какие предварительные соображения вызвали у нее введенные значения отдельных параметров.
После завершения диалога система предъявляет пользователю свои "соображения" по поводу введенных данных.
Гипотеза: ASTHMA, МП: 900. Причина: предыдущий диагноз — АСТМА
Гипотеза: NORMAL, МП: 500. Причина: ФЖЕ равно 81
Гипотеза: ОАО, МП: 900. Причина: отношение ОФВ1/ФЖЕ равно 40
Гипотеза: NORMAL, МП: 700. Причина: ПСОУ равно 117
Гипотеза: ОАО, МП: 900. Причина: УПМС равно 12
Гипотеза: ОАО, МП: 900. Причина: наклон П5025 равен 9
Наиболее правдоподобные гипотезы: NORMAL, ОАО [Новые анализируемые прототипы: NORMAL, ОАО]
Из этой распечатки следует, что далее система сосредоточится на двух наиболее правдоподобных гипотезах: NORMAL и OAD. Эти две гипотезы являются непосредственными "наследниками" прототипа PULMONARY-DISEASE. Рассмотрение гипотезы ASTHMA на время откладывается по той причине, что она является подтипом гипотезы OAD. Эта гипотеза будет рассмотрена в процессе уточнения гипотезы OAD, в полном соответствии со стратегией нисходящего уточнения. Иерархическая структура пространства гипотез позволяет дать пользователю полную и ясную информацию о том, как эта стратегия претворяется в жизнь в экспертной системе. В системах, полностью основанных на правилах, пользователь должен представлять себе ту стратегию разрешения конфликтов между конкурирующими правилами, которая используется в системе, и только тогда он сможет понять, почему в определенной ситуации было отдано предпочтение именно той гипотезе, которая зафиксирована в распечатке результата трассировки, а не какой-либо иной.
Обратите внимание — не все данные, введенные пользователем в ходе начального диалога, приводят к выбору гипотез-кандидатов, а в список гипотез-кандидатов попадает несколько прототипов. При заполнении данными отобранных в этом списке двух гипотез — NORMAL и OAD — такой параметр, как ОЕЛ (общая емкость легких), который в ходе диалога не повлиял на начальный список, будет учтен и, вполне возможно, повлияет на значение меры правдоподобия анализируемой гипотезы. Значение этого параметра (139) заставляет систему подвергнуть сомнению правдоподобность гипотезы NORMAL, как будет показано ниже в примере распечатки значений тех параметров, которые привели систему "в замешательство". Данные, которые "не вписываются" в диапазон, представленный в слотах определенных прототипов, заставляют систему снижать меру правдоподобия соответствующей гипотезы.
!.Неожиданное значение: ООЛ равно 261 в NORMAL, МП: 700 !Неожиданное значение: ОЕЛ равно 139 в NORMAL, МП: 400 !Неожиданное значение: ОФВ1/ФЖЕ равно 40 в NORMAL, МП: -176 !Неожиданное значение: УПМС равно 12 в NORMAL, МП: -499 !Неожиданное значение: П5025 равно 9 в NORMAL, МП: -699
Из представленной распечатки видно, что, хотя по итогам предварительного экспресс-анализа введенных данных гипотеза NORMAL представлялась весьма правдоподобной, более подробное исследование всей совокупности данных, в частности пяти параметров, включенных в распечатку, заставило систему весьма засомневаться в ее обоснованности. Всю эту информацию пользователь может почерпнуть из распечаток, которые система CENTAUR выводит в процессе работы. Затем формируется список гипотез, который упорядочивается в порядке убывания, причем на первом месте оказывается прототип ОАО:
Список гипотез: (ОАО 999) (NORMAL -699)
Проверяется гипотеза ОАО (ОБТУРАЦИЯ ВОЗДУХОНОСНЫХ ПУТЕЙ)
Далее система подтвердит гипотезу о том, что пациент страдает обтурацией воздухоносных путей, причем степень заболевания — серьезная, а подтип заболевания — астматический. После этого система переходит к этапу уточнения диагноза. На этом этапе пользователю задаются дополнительные вопросы, ответы на которые несут необходимую для этого информацию. Этот этап выполняется под управлением специальных правил уточнения, которые хранятся в слотах соответствующего прототипа. Протокол фрагмента уточняющего диалога с пользователем приведен ниже.
[Выполнение уточняющих правил ...]
20) Число "пачко-лет" курения: 17
21) Как давно пациент бросил курить: 0
22) Степень затруднения дыхания: НЕТ
После завершения уточняющего диалога в дело вступают правила, формирующие заключение для данного сеанса консультаций. Эти правила специфичны для каждого из возможных прототипов, и в конце сеанса выполняется тот набор правил, который связан с прототипом выбранной гипотезы. Набор правил этого типа, связанных с прототипом OAD, приведен ниже.
[Выполняются действия, заданные в слоте ACTION прототипа ОАО ...]
Заключение: показания, свидетельствующие в пользу диагноза "Обтурация воздухоносных путей", следующие:
Увеличенные объемы легких указывают на гипернаполнение.
Увеличенное значение отношения ООЛ/ОЕЛ согласуется с наличием тяжелой обтура-ции воздухоносных путей. Форсированная жизненная емкость в норме, но отношение ОФВ1/ФЖЕ понижено, что указывает на обтурацию воздухоносных путей в тяжелой форме.
Низкий средневыдыхаемый поток согласуется с наличием тяжелой обтурации воздухоносных путей. На обтурацию воздухоносных путей указывает кривизна зависимости потока воздуха от объема.
После приема бронхолитиков улучшается проходимость воздухоносных путей, что подтверждается изменением значения ОФВ1.
После приема бронхолитиков улучшается проходимость воздухоносных путей, что подтверждается изменением значения УПМС.
Обратимость обтурации воздухоносных путей подтверждается улучшением проходимости после приема бронхолитиков.
Эти правила суммируют информацию, собранную в процессе диалогового "обследования" пациента, и не требуют никакой ответной реакции со стороны пользователя.
Пример окончательного заключения, которое выполняется правилами, хранящимися в слоте ACTION прототипа PULMONARY-DISEASE, представлен ниже.
[Выполняются действия, заданные в слоте ACTION прототипа PULMONARY-DISEASE ...]
-------Заключение--------
— Обтурация воздухоносных путей------
Диагноз "Обтурация воздухоносных путей" сделан на основании следующих фактов:
Отношение ОФВ1/ФЖЕ для ПАЦИЕНТА-7: 40
Отношение УПМС/УПМС-предсказываемая для ПАЦИЕНТА-7: 12
Значение наклона П5025 для ПАЦИЁНТА-7: 9
Кроме того, диагноз "Обтурация воздухоносных путей" согласуется со следующими
данными:
Отношение ОЕЛ/ОЕЛ-предсказываемая для ПАЦИЕНТА-7: 139
Отношение ООЛ/ООЛ-предсказываемая для ПАЦИЕНТА-7: 261
Значение П25 для ПАЦИЕНТА-7: 45
Степень затруднения дыхания для ПАЦИЕНТА-7: НЕТ
Интенсивность кашля для ПАЦИЕНТА-7: НЕТ
При установлении диагноза "Обтурация воздухоносных путей" должны приниматься во внимание следующие показания:
Ранее поставленный диагноз для ПАЦИЕНТА-7 Отношение ОФВ1/ФЖЕ для ПАЦИЕНТА-7 Значение П25 для ПАЦИЕНТА-7 Степень затруднения дыхания для ПАЦИЕНТА-7 Интенсивность кашля для ПАЦИЕНТА-7
Все указанные факты были приняты во внимание при подтверждении прототипа.
Заключение: возможно, курение усугубляет серьезность обтурации воздухоносных путей у пациента. Прекращение курения поможет избавиться от некоторых симптомов. Хорошая реакция на бронхолитики согласуется с астматическим характером заболевания. Высокая проникающая способность согласуется с астмой.
Диагноз: обтурация воздухоносных путей астматического типа в серьезной форме. Консультация завершена.
Поскольку поведение программы по отношению к пользователю на каждом этапе зависит от смысла этого этапа, пользователю довольно легко разобраться в логике рассуждений "консультанта". На каждой стадии процесса понятно, чего пытается добиться система и какой прототип активизирован. Поэтому разобраться в работе системы и инженеру, занимающемуся отладкой, и пользователю, обратившемуся за консультацией, значительно легче, чем в случае, когда приходится иметь дело с программой, не оснащенной дополнительными структурными элементами, присущими системе иерархических фреймов.
Подводя итог обсуждению возможностей программы CENTAUR, Эйкинс обратила внимание на то, что пользователю, для того чтобы правильно интерпретировать заключение, представленное программой, необходимо иметь четкое представление о смысле вопросов, которые задает программа, причинах, побудивших программу задавать именно такие вопросы, и механизме уточнения промежуточных заключений.
Эйкинс отметила наличие четырех принципиальных недостатков в том виде пояснений, которые формируются в программе EMYCIN.
Пользователь вынужден следовать за цепочкой обратных рассуждений в процессе применения правил, а эта стратегия не свойственна тому способу логического вывода, который привычен для человека.
Знания в правилах, используемых системой, могут быть неполными или недостаточно специфичными для того уровня детализации, который позволит пользователю проследить за очередностью применения правил.
Знания, касающиеся контекста и режима управления, не выделяются на фоне прочих знаний о конкретной предметной области, т.е. отсутствует четкая граница между мета- и объектным уровнем знаний.
Применение каждого очередного правила объясняет только последний заданный перед этим вопрос, поэтому теряется общий контекст рассуждений.
Система CENTAUR задает пользователю вопросы в том случае, когда ей не удается выделить необходимую информацию из правил или когда она нуждается в значениях параметров, помеченных в правилах маркером "ask-first" (сначала спроси). Вопросы, которые пользователь может задавать системе CENTAUR, по своему характеру напоминают вопросы "КАК" и "ПОЧЕМУ", которые возможны и при работе с системой EMYCIN, но они интерпретируются в зависимости от текущей стадии процесса консультации. Так, вопрос "ПОЧЕМУ", заданный в контексте конкретного прототипа в ходе выполнения этапа формирования диагноза, будет интерпретироваться как "Почему рассматривается именно данный прототип?" Такой же вопрос на этапе просмотра исходных данных будет интерпретироваться по-другому: "Почему данный прототип подтверждается?" Система CENTAUR всегда предоставляет пользователю информацию о текущем прототипе, а потому пользователь всегда может ориентироваться, в каком контексте программа задает тот или иной вопрос.
Система CENTAUR включает в протокол формирования заключения не только список подтвержденных прототипов, но и множество дополнительной информации:
данные, которые побудили ее рассматривать каждый прототип;
данные, согласующиеся с каждым прототипом;
данные, противоречащие каждому прототипу;
данные, не принятые во внимание ни одним из прототипов.
Все данные, которые не были приняты во внимание ни одним из подтвержденных прототипов, перечисляются в итоговом протоколе. Туда же включаются и сведения о тех отвергнутых прототипах, которые учитывают эти данные. Это позволяет пользователю не упустить из виду как возможные ошибки системы (пробелы в знаниях), так и возможные ошибки в выполнении лабораторных анализов. Пользователь имеет возможность ознакомиться в итоговом протоколе не только с теми прототипами, которые программа сочла правдоподобными, но и с теми, которые она отвергла, посчитав, что они не подтверждаются имеющимися в ее распоряжении данными.
Из того краткого обзора, с которым читатель мог ознакомиться в этой главе, думаю, можно сделать вывод, к которому пришел и Кленси, — задачу формирования пояснений невозможно выделить в отдельный, достаточно автономный модуль экспертной системы. Предмет пояснений настолько связан со всеми остальными аспектами работы экспертной системы, что выделить его в отдельный компонент вряд ли кому-нибудь удастся. Мораль всей этой истории такова — о тех средствах, которые будут использованы для формирования пояснений, нужно начинать думать сразу же после начала проектирования экспертной системы, поскольку встроить их каким-либо образом в уже работающую или хотя бы наполовину спроектированную систему невозможно.
Использование мультимедийного интерфейса для формирования пояснений
Те примеры, которые мы рассматривали выше, базируются на самых непритязательных диалоговых средствах, предоставляющих пользователю информацию в текстовом виде и в таком же виде принимающих от него информацию. В этом разделе мы вкратце затронем тему использования современных средств поддержки графического интерфейса и более широко — мультимедийного интерфейса между компьютерной системой и пользователем для формирования пояснений в экспертных системах. Естественно, многие детали останутся за рамками этой книги, и тем читателям, которые хотят подробнее познакомиться с этой темой, следует обратиться к специальной литературе, перечисленной в конце главы. Основное внимание в этом разделе будет уделено рассмотрению общих проблем проектирования с использованием мультимедийных средств и координации различных видов таких средств при формировании пояснений в экспертных системах.
Один из способов дополнить и расширить возможности формирования пояснений в системах, базирующихся на представлении знаний в виде фреймов, — добавить в них возможность формирования изображений. В системе JETA [Abu-Hakima et al., 1993] привычный текстовый интерфейс, подобный тому, который использовался при формировании пояснений в системе CENTAUR, был дополнен изображениями диаграмм в виде схем и графов. В основу архитектуры системы JETA положена трехуровневая структура фреймов (рис. 16.2). Два уровня фреймов — диагностики и параметров — аналогичны фреймам системы CENTAUR. Третий уровень — уровень фреймов глоссария (glossary frames) — поддерживает функционирование двух первых и содержит маркеры гипертекста. Фреймы этой группы предназначены специально для формирования пояснений и поддержки системы оперативной справки, касающейся функционирования фреймов других уровней. Назначение экспертной системы JETA — определение причин отклонений в работе реактивных двигателей.
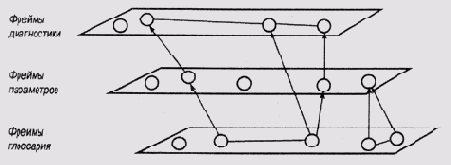
Рис. 16.2.
Трехуровневая структура фреймов экспертной системы JETA
системы фреймов, представляющей предметную область и действия в ней; базы диагностических правил;
базы знаний о геометрии, необходимой для формирования изображений геометрических фигур.
Предметная область, на которую была ориентирована разработка системы COMET, — техническое обслуживание и ремонт систем радиосвязи военного назначения. Программа может формировать набор инструкций по выполнению тех или иных операций обслуживания аппаратуры и осуществлять диагностику и поиск неисправностей, снабжая при этом персонал обширными пояснениями, касающимися последовательности ремонтных работ. Идея, положенная в основу этой системы, — обеспечить координацию предоставления пользователям графической и текстовой информации, которая должна иллюстрировать ключевые моменты выполнения ремонтных работ и операций по текущему обслуживанию аппаратуры.
Например, для проверки удаленного модуля ввода/вывода приемопередающей станции нужно выполнить следующие операции, оговоренные в инструкции.
(1) Нажать кнопку ВАТТ/CALL на передней панели.
(2) Настроить приемопередатчик, используя для этого переносной пульт.
(3) Проверить, появилась ли на табло надпись CALL.
В системе такая инструкция для пользователя озвучивается и снабжается иллюстрацией в виде анимации. Для этого координированно выполняются две последовательности операций — одна формирует звук (V), а другая — динамическое изображение (А):
V: Нажмите и удерживайте кнопку ВАТТ/CALL.
А: На экране увеличивается изображение клавиатуры и табло и крупным планом выделяется кнопка BAIT/CALL
V: Удерживая кнопку, настройте приемопередатчик.
А: На экране крупным планом выводится переносной пульт.
V: Одновременно следите за надписью на табло.
А: На экране подсвечивается изображение табло.
В следующем разделе мы несколько детальнее остановимся на планировании отдельных этапов представления пояснений пользователю, рассматривая их как часть общего процесса формирования пояснений. Теперь же просто отметим, что использование мультимедийных средств требует тщательной предварительной подготовки. Нужно продумать, что, когда и как показывать, как координировать работу различных звуковых и изобразительных средств, какие сервисные средства предоставить в распоряжение пользователя, и т.д.
Формирование пояснений
b>и автоматическое программирование
В этом разделе будет рассмотрен достаточно радикальный подход к формированию пояснений в экспертных системах, который предполагает представление соответствующих знаний в явной форме и хранение их отдельно от знаний, необходимых для решения проблем в предметной области. Причиной возникновения сложностей с формированием пояснений в значительной мере является использование в процессе логического вывода различного рода эвристик и методов, "спрятанных" в самой структуре системы и таким образом недоступных тем компонентам программы, которые формируют пояснения.
В этом разделе мы остановимся на двух экспертных системах, XPLAN и PEA, при разработке которых создатели попытались решить указанные проблемы, воспользовавшись специальной программой-оболочкой. Работы выполнялись в рамках исследовательского проекта EES — Explainable Expert Systems (экспертные системы, способные давать пояснения).
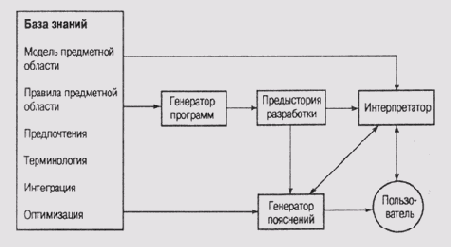
Автоматическое программирование в системе XPLANХотя трассировка активизации правил и дает информацию о поведении системы, сама по себе она не может объяснить мотивов этого поведения [Swartout, 1983]. Это объясняется тем, что мотивация поведения является частью знаний, используемых при построении и внедрении программы, и она нигде не представлена явно в виде программного кода. Другими словами, те "знания как", которые заложены в конструкции системы, т.е. принципы логического вывода суждений, как правило, смешаны со "знанием что", т.е. моделью той предметной области, на работу в которой ориентирована конкретная экспертная система. В основу проектирования системы XPLAN, созданной Свотаутом (Swartout), была положена простая, но вместе с тем продуктивная идея увязать процесс разработки экспертной системы с процессом формирования пояснений. Один из методов проектирования экспертных консультирующих систем состоит в том, чтобы выработать спецификацию модели предметной области, включив в нее и принципы функционирования объектов этой области, а затем воспользоваться услугами "автоматического программиста" и сформировать по этой спецификации собственно программу экспертной системы. Предписывающие и описывающие компоненты спецификации объединяются таким образом в единую систему и используются затем для формирования пояснений в процессе функционирования этой системы. Модель предметной области содержит сведения, касающиеся специфики области приложения экспертной системы, в частности сведения о причинно-следственных связях и систематике объектов в этой области. Эта концепция достаточно близка тому, что Кленси (Clancy) назвал "структурным знанием" (см. об этом в главе 12). Подобные знания лежат в основе системы правил, регламентирующих действия в определенных ситуациях. Но модель предметной области включает и такие методы и эвристики, которые обычно жестко "встраиваются" в интерпретатор экспертной системы или передаются интерпретатору в качестве метаправил. Этот вид знаний в терминологии Кленси получил наименование стратегических. Свотаут отметил, что такое разделение видов знаний положительно сказывается на производительности экспертной системы при выполнении большинства функций, исключая функцию формирования пояснений. Свотаут собрал информацию о тех вопросах, которые задают студенты-медики при работе с консультирующей системой Digitalis Therapy Advisor. В собранном массиве он выделил три базовые группы. Вопросы, касающиеся методов, которые используются программой. Например, как программа вычисляет значение того или иного параметра. Вопросы, касающиеся причин принятия программой того или иного решения. Например, почему программа рекомендует именно такой, а не иной курс лечения. Вопросы, предлагающие системе уточнить смысл вопроса, заданного пользователю. Такие вопросы возникают в тех ситуациях, когда у студентов возникали сомнения, правильно ли понят пользователем заданный системой вопрос или каких именно сведений ожидает система от пользователя. На вопросы первого типа большинство экспертных систем может ответить без особых затруднений. Все, что требуется при этом от программы, — перевести на обычный "человеческий" язык тот программный код, который она выполняет. Ответы на вопросы второго типа требуют несколько большего — программа должна обладать способностью представить пользователю те знания, на которых базируется программный код. Еще с большими сложностями сталкивается экспертная система при ответах на вопросы третьего типа. Она должна обладать способностью представлять себе, как пользователь понимает терминологию, используемую в исходном вопросе (т.е. в вопросе, который система задала пользователю и который послужил причиной ответного вопроса), и разрешать любые конфликты между действительным смыслом вопроса и тем, как он воcпринят пользователем. При разработке системы XPLAN основное внимание было уделено способности системы отвечать на вопросы второго типа. Подход на основе автоматического программирования, который использован в системе XPLAN, можно рассматривать как метод объединения фаз спецификации и реализации в процессе создания экспертной системы. Идея состоит в том, что описание модели предметной области должно быть полностью декларативным. В этом случае программа может использовать одни и те же структурные элементы знаний для выполнения разных функциональных задач. Принципы организации объектов в предметной области можно использовать для рекурсивного уточнения структуры целей, связанной с решаемой задачей. Рекурсивное уточнение выполняется до тех пор, пока в модели существуют методы, связанные с каждым из шагов самого нижнего уровня, которые должна выполнить программа. Представленный в модели вид управления должен быть более строгим, чем использование метаправил, аналогичных тем, что имеются в системе MYCIN. На управление возлагаются более широкие функции, чем просто установление порядка применения отдельных правил, специфических для предметной области. Интеграция сформированных таким образом фрагментов программы является довольно сложным процессом, которым мы сейчас заниматься не будем, поскольку главное, что нас интересует, как из декларативного описания модели предметной области можно извлечь информацию для формирования пояснений. Проект Explainable Expert SystemsСвотаут обратил внимание на проблему "компьютерных артефактов" в тех средствах формирования пояснений, которые использовались в ранее разработанных экспертных системах. Под такими артефактами он подразумевал те аспекты выполнения вычислений, которые связаны не с лежащей в основе системы моделью предметной области, а с программной реализацией алгоритмов самого нижнего уровня. Эти аспекты поведения программы совершенно не интересуют специалистов, пользующихся услугами экспертной системы. Система XPLAN создавалась в рамках проекта Explainable Expert Systems (EES) [Heches et al, 1985], [Moore, 1995]. Идея этого проекта вполне созвучна существующей в настоящее время тенденции группировать и представлять в явном виде знания различного вида. Кроме того, в рамках этого проекта предпринята попытка использовать формальные методы, которые позволили бы зафиксировать в базе знаний системы основные решения, принимаемые в процессе ее разработки. Отсутствие таких формальных методов приводит к тому, что информация об основных решениях, положенных в основу проектирования, теряется на стадии реализации системы. На рис. 16.3 представлена структурная схема оболочки, созданной в рамках проекта EES. Обратите внимание на прямоугольник в левой части схемы, который представляет базу знаний системы. В эту базу знаний входят не только модель и правила предметной области, но и много дополнительной информации, например описание терминологии предметной области, информация, связанная с правилами предметной области, о доводах в пользу и против выбора определенной стратегии достижения цели, информация о том, каким целям отдается предпочтение в процессе решения проблемы, и т.д. Знания, выделенные в группу "Интеграция", используются для разрешения конфликтов между правилами предметной области в процессе работы "автоматического программиста", а знания, выделенные в группу "Оптимизация", имеют отношение к производительности экспертной системы, генерируемой этим автоматическим программистом. Эти служебные группы знаний представляют те виды метазнаний, которые не связаны непосредственно с выбором правил объектного уровня в процессе логического вывода на этапе функционирования экспертной системы, а имеют отношение скорее к этапу ее проектирования.
Рис. 16.3.
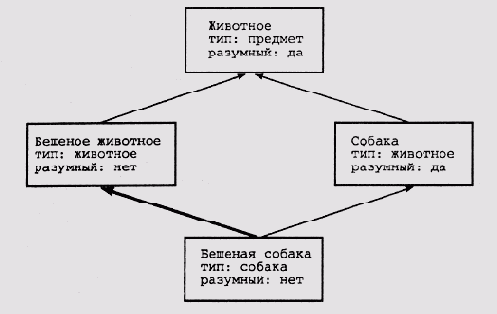
Структура оболочки EES ([Neches et al., 1985]) Пусть, например, в сети имеются узлы концептов ЖИВОТНОЕ, СОБАКА и БЕШЕНОЕ-ЖИВОТНОЕ, а в классификатор поступает новый концепт БЕШЕНАЯ-СОБАКА. В ответ классификатор формирует новый узел для этого концепта и отводит ему место в иерархии. Новый узел будет связан "узами наследования" с узлами СОБАКА и БЕШЕНОЕ-ЖИВОТНОЕ. Это выполняется после анализа свойств и характеристик нового концепта (рис. 16.4). Трудно переоценить способность системы наращивать таким образом базу знаний, которая, как правило, никогда не создается за "один присест". Исчез (Neches) описал применение оболочки EES для построения экспертной системы Program Enhancement Advisor (PEA). Эта программа предназначена для оказания помощи программистам в повышении "читабельности" текстов программ. В той предметной области, в которой должна работать новая экспертная система, концептами семантической сети являются преобразования элементов программного кода, например замена оператора COND языка LISP на конструкцию IF-THEN-ELSE. Концепт является частным случаем другого концепта, KEYWORD CONSTRUCT, который, в свою очередь, является частным случаем концепта Easy-TO-READ CONSTRUCT. Используя организованную таким образом базу знаний, экспертная система может предложить программисту-пользователю заменить оператор (COND ((АТОМ X) X) (Т (CAR X))) другим оператором, смысл которого более понятен при анализе текста программы: (IF (АТОМ X) THEN X ELSE (CAR X)).
Рис. 16.4.
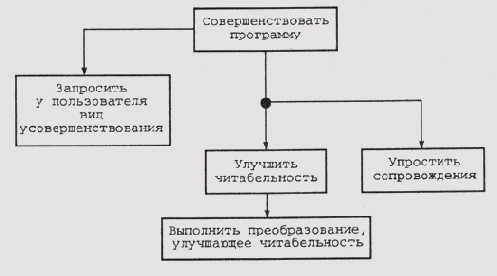
Включение нового концепта в семантическую сеть знаний Генератор программ работает по принципу нисходящего (сверху вниз) уточнения, выполняя декомпозицию целей на подцели. Так, главная цель программы PEA — усовершенствовать программу — разделяется на подцели, например улучшить читабельность. Разработчики системы назвали такой процесс декомпозиции целей "динамическим уточнением, направляемым пользователем", поскольку характер действий, выполняемых создаваемой системой, определяется инженером по знаниям, формирующим базу знаний. Если выбрана определенная цель, скажем улучшить читабельность, то она автоматически становится субъектом процесса дальнейшей декомпозиции цель/подцель. Например, следующими подцелями будет просмотр текста программы и выявление в нем синтаксических конструкций, которые можно безболезненно заменить другими, более понятными, получение подтверждения от пользователя, одобряющего предлагаемую замену, выполнение замены и т.д. Фрагмент предыстории разработки системы PEA, в котором отображена описанная декомпозиция, представлен на рис. 16.5.
Рис. 16.5.
Фрагмент предыстории разработки системы PEA, в котором отображена декомпозиция
цели на подцели ([Moore, 1995]) Позволяет относительно просто выразить сложные стратегии высокого уровня, которые в обычных экспертных системах представлены неявно и "упрятаны" в алгоритм интерпретатора. Разделение всех знаний на отдельные группы упрощает разбиение системы на набор относительно независимых модулей, а значит, облегчает последующую модификацию системы в процессе ее эксплуатации. Автоматическая классификация новых знаний с помощью языков представления семантических сетей, подобных NIKL, упрощает разработку и сопровождение системы, поскольку освобождает инженеров по знаниям от забот о структурировании новых знаний. Планирование текстов пояснений и модели пользователей в PEAПомимо совершенствования базы знаний и явного представления структуры целей, для формирования пояснений необходимо также иметь определенный план выполнения этой процедуры. Мур отказался от идеи использования сценариев или шаблонов поясняющих текстов по следующим причинам [Moore, 1995]. Сценарии могут помочь в представлении шаблонов сообщений, но не учитывают возможности представления более субъективных вещей вроде информации о тех соображениях, которые побудили систему выполнить определенную манипуляцию с переменными или задать вопрос пользователю. Сценарии образуют слишком "жесткую" конструкцию, в которую сложно втиснуть подходящие по смыслу ответы на запросы пользователя. Вместо сценариев Мур использовал операторы планирования, в которых специфицируются определенные цели диалогового процесса, например передать пользователю информацию о мотивации некоторого действия системы. Каждое правило в операторе планирования имеет список условий, при выполнении которых применение оператора даст желаемый эффект. Ниже представлен перевод на "человеческий язык" оператора планирования, побуждающего пользователя (собеседника программы) выполнить определенное действие, например заменить какую-либо программную конструкцию языка LISP, если речь идет об области применения системы PEA. Для перехода в состояние, в котором собеседник будет склонен выполнить операцию ЕСЛИ Операция представляет собой шаг к достижению некоторой цели (целей), приемлемой для собеседника, и Цели являются наиболее приемлемыми среди всех возможных путей уточнения ТО Мотивировать это действие в терминах целей. Процитированный оператор является достаточно общим и может быть применен к любой предметной области, а не только к той, в которой используется конкретная экспертная система. Однако действие, к выполнению которого этот оператор побуждает пользователя, конечно же, связано с конкретной предметной областью. Точно так же и цели имеют смысл, связанный с конкретной предметной областью. Если речь идет о системе PEA, то такой целью может быть либо улучшение читабельности программы, либо упрощение ее сопровождения, либо какая-то другая цель, которую может преследовать пользователь, работая с системой. Как и при работе с программой STRIPS и другими экспертными системами планирования, связывание таких правил в цепочку приводит к последовательному разложению целей на подцели (рис. 16.6).
Рис. 16.6.
Уточнение целей при планировании диалога с пользователем (COMPETENT USER (DO USER REPLACE)) (KNOW-ABOUT USER (CONCEPT PROGRAM)) (KNOW-ABOUT USER (CONCEPT LISP-FUNCTION)) (KNOW-ABOUT USER (CONCEPT S-EXPR)) (KNOW-ABOUT USER (CONCEPT READABILITY)) (KNOW-ABOUT USER (CONCEPT MAINTAINABILITY)) Эти выражения на языке LISP отражают тот факт, что пользователь знает, как с по-Мощью редактора заменить одно выражение другим, имеет представление о программе и функциях языка LISP и т.д. Но система PEA может также учитывать и уровень подготовки не усредненного, а конкретного пользователя, анализируя его поведение и представленный для модификации программный код. Например, программа в процессе просмотра кода выясняет, каким функциям LISP программист отдает предпочтение, и соответственно корректирует модель пользователя. Она также фиксирует, когда пользователь соглашается с предлагаемыми программой мерами модификации анализируемого текста. В результате система способна определить, достигнута ли поставленная цель диалога с пользователем. Подведем итоги всему сказанному о возможностях системы PEA. Планировщик этой программы располагает сформулированной целью общения с пользователем, с которой он время от времени сверяет свои действия. Как правило, это происходит, когда возникает необходимость убедить в чем-то пользователя. Обладая способностью анализировать уровень подготовки пользователя, система может адекватно формировать пояснения на том уровне детализации, который необходим именно данному пользователю. Перспективы дальнейших исследований методов формирования поясненийВ главе 13 мы обсуждали, как используется технология иерархического построения и проверки гипотез для факторизации большого пространства решений и построения обширных баз знаний в системе INTERNIST. Иерархический подход к методике решения проблем имеет и другие достоинства, в частности прозрачность поведения программы с точки зрения пользователя и гибкость управления этим поведением. Указанные возможности продемонстрированы в этой главе на примере программы CENTAUR, в которой используются иерархия фреймов для отслеживания контекста применения порождающих правил и список актуальных задач для управления порядком анализа гипотез. Проект EES служит хорошим примером одного из направлений в современной методологии инженерии знаний, которое предполагает разделение процесса на этапы спецификации знаний и компиляции системы. Но пока что совершенно неясно, как такая методология может справиться с задачей комбинирования разных стратегий решения проблем в рамках единой системы (как это выполняется, например, в системе CENTAUR). Основная сложность в использовании этой методологии — большой объем предыстории разработки и необходимость использования чрезвычайно мощного генератора программ (см. об этом в [Neches et al, 1985]). Альтернативой такому подходу является усложнение интерпретатора включением в него мощных управляющих примитивов. В результате предыстория разработки сокращается и снижаются требования к функциональным возможностям генератора программ, но информация о принятии решений, касающихся поведения программы, оказывается спрятанной в программном коде интерпретатора. Интересно звучит предложение дополнительно нагрузить генератор программ — заставить его формировать и интерпретатор, и информацию, необходимую для формирования пояснений относительно управляющих функций. Это должно привести к еще большему разделению управляющих знаний и знаний о предметной абласти, но, предположительно, одновременно поставит перед разработчиками множество проблем, связанных с интеграцией компонентов системы. Из приведенного краткого и довольно поверхностного описания проекта EES вы уже могли сделать вывод, что проблема автоматизации формирования пояснений является чрезвычайно сложной. Но этого описания достаточно, чтобы представить, на чем сосредоточено основное внимание исследователей в этой области. Можно выделить такие основные направления: (1) дифференциация знаний; (2) явное представление стратегических и структурных знаний, которые в прежних системах оказывались скрытыми в программном коде; (3) моделирование индивидуального уровня подготовки пользователя, работающего с экспертной системой. В этой главе основное внимание было уделено двум первым направлениям, а что касается третьего, то мы постарались хотя бы очертить круг проблем, над которыми работают исследователи. Рекомендуемая литератураЧитателей, интересующихся историей разработки модели пользователя, мы отсылаем к сборникам [Sleeman and Brown, 1982] и [Poeson and Richardson, 1988]. Довольно обширная подборка статей, касающихся проблематики интерфейса с пользователем; представлена в сборнике [Maybury, 1993]. В работах [Moore and Paris, 1993] и [Moore et al, 1996] суммируется опыт планирования диалога, приобретенный авторами в процессе разработки оболочки EES и экспертной системы PEA. Читателям, интересующимся дескриптивными языками описания семантических сетей, мы советуем обратить внимание на язык LOOM, представленный в работе [MacGregor, 1991].
|