Влияние сложности пространства гипотез на организацию работы системы
Такие системы, как MYCIN, имеют дело с отдельной, очень специфической частью проблемной области (в данном случае — медицины). В частности, система MYCIN диагностирует только заболевания крови. Поскольку пространство состояний в системах, подобных MYCIN, достаточно ограничено, в них можно использовать метод исчерпывающего поиска в глубину.
А что делать, если мы собираемся построить экспертную систему, имеющую дело со всеми возможными заболеваниями, а не только с отдельным специфическим классом? Количество различных заболеваний, известных врачам на сегодняшний день (диагностических категорий), лежит, по разным оценкам, в диапазоне от двух до десяти тысяч. Нужно также учитывать, что существуют пациенты, у которых обнаруживается до десятка заболеваний одновременно. Как отметил Попл (Pople), в худшем случае программе, использующей обратную цепочку рассуждений, придется при диагностировании таких пациентов проанализировать около 1040 диагностических категорий!
Именно в тех системах, в которых пространство решений потенциально может быть очень большим, и проявляются преимущества метода иерархического построения и проверки гипотез. Пространство поиска в таком случае может рассматриваться как дерево, представляющее таксономию типов решений. Узлы более верхних уровней дерева соответствуют более широким (а потому менее четко очерченным) категориям решений, чем узлы более нижних уровней. Терминальные узлы дерева соответствуют совершенно конкретным решениям. При такой организации пространства решений процесс уточнения гипотез значительно упрощается, поскольку структура пространства решений может быть использована для формирования эвристик управления последовательностью анализа.
На рис. 13.1 показана часть иерархической систематики заболеваний, которая используется в системе CENTAUR. Корневым узлом этого фрагмента являются ЗАБОЛЕВАНИЯ_ ОРГАНОВ_ДЫХАНИЯ, а все последующие узлы — различные виды таких заболеваний. Следующий уровень узлов представляет наиболее общие категории заболеваний органов дыхания, а терминальные узлы (листья) — конкретные заболевания, которые можно диагностировать и в дальнейшем лечить.
Естественно, если таким образом представить медицинские знания обо всех возможных болезнях, то дерево очень сильно "разрастется". В системе INTERNIST организация дерева привязана к основным органам — легким, печени, сердцу и т.п. Хотя иерархическая организация и помогает выполнять поиск, она не устраняет проблему отыскания наилучшего объяснения имеющегося набора данных (симптомов). Для этого необходимо объединять гипотезы об отдельных болезнях и добиваться, чтобы в такой комбинированной гипотезе были учтены все признаки и симптомы, обнаруженные у пациента.
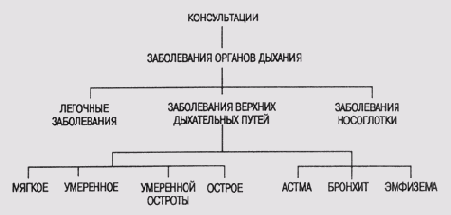
Рис. 13.1.
Иерархическое представление заболеваний органов дыхания
ассоциативные связи между свидетельствами и "терминальными" гипотезами слабые, а ассоциативные связи между исходными данными и "нетерминальными" гипотезами достаточно сильные, и существуют методы уточнения построенных гипотез и их разделения;
в полном наборе правил имеется большая избыточность, т.е. значительная часть условий одновременно включена во множество правил и таким образом связывается с множеством различных заключений;
система спроектирована с расчетом на явное представление пространства гипотез, которым можно манипулировать, причем на любом этапе работы может существовать множество конкурирующих гипотез, которые нельзя анализировать независимо;
не все условия можно одинаково легко сформулировать либо из-за сложности сопутствующих вычислений, либо вследствие факторов стоимости и риска; таким образом, оказывается, что процесс накопления свидетельств сам по себе представлен в пространстве состояний и к нему нужно применять некоторые методы логического вывода;
возможны множественные и частичные решения, например пациент может страдать несколькими заболеваниями, либо для проведения лечения вполне достаточно знания класса заболеваний или основных альтернативных заболеваний.
Один из этапов подхода, использованного в CENTAUR, состоит в том, что просматривается, насколько полно представление гипотетического заболевания совпадает с имеющимися данными (симптомами, показаниями и т.п.). Узлы в дереве представления гипотез активизируются имеющимися данными, конкретизируются, оцениваются и упорядочиваются по степени "накрытия" имеющихся фактов. Узлы, "получившие" наиболее высокие оценки, включаются в список заявок и в дальнейшем анализируются более подробно. В первом приближении этот анализ сводится к выяснению, насколько имеющиеся симптомы соответствуют каждому из дочерних узлов. Последовательно применяя такую процедуру анализа, программа в конце концов формирует список терминальных узлов с достаточно высокими оценками степени соответствия имеющимся данным.
13.1.
Обход дерева
НАТ-алгоритм
(1) Считать исходные данные.
(2) Для каждой исследуемой гипотезы сформировать оценку, которая показывает, какая часть исходных данных учитывается этой гипотезой.
(3) Определить ту гипотезу (узел) л, которая имеет наивысшую оценку.
(4) Если п— терминальный узел, то завершить выполнение алгоритма. В противном случае выделить в пространстве гипотез два подпространства К и L Подпространство К должно содержать дочерние узлы п, а подпространство L — узлы-конкуренты п на том же уровне дерева.
(5) Собрать дополнительные данные, которые можно использовать для анализа гипотез в подпространстве К, и провести оценку гипотез на основе этих дополнительных данных. Пусть k— наивысшая оценка гипотез из К, а l— наивысшая оценка гипотез из L
(6) Если k выше, чем /, то положить п = k. В противном случае положить n = /.
(7) Перейти к п. 4.
Структурированные объекты в CENTAUR
Для того чтобы понять алгоритм работы программы CENTAUR, нужно хотя бы в общих чертах представлять себе ту предметную область, на которую ориентирована эта программа. CENTAUR выполняет практически те же задачи, что и разработанная ранее система PUFF (см. [Кит et al, 'I978J, [Aikins et al., 1984]}. Система PUFF предназначалась для диагностики нарушения работы дыхательных органов. В качестве исходных данных, как правило, использовались результаты анализа объема выдыхаемого воздуха и скорость движения воздуха при выдохе (этот анализ выполняется с помощью спирографа).
Структура фреймов в CENTAUR
Основная идея, положенная в основу системы CENTAUR, состоит в том, что фреймо-подобные структуры обеспечивают явное представление предметной области, которое может быть использовано для формирования суждений с помощью порождающих правил. Такое описание предметной области позволяет разделить стратегические знания о том, как управлять процессом формирования суждений, и ситуационные знания о том, какой вывод можно сделать из имеющегося набора фактов. Теоретически это позволит отделить ситуационные знания, специфичные для конкретной предметной области, а значит, создать систему, которую можно будет приспособить для работы в разных областях.
При таком подходе порождающие правила могут быть просто включены в структуру фрейма в качестве значения одного из слотов. Связывание правил со слотами фрейма создает возможность организации единого механизма функционирования правил на основе естественного группирования. Другие слоты в данном фрейме образуют в явном виде контекст применения правила.
В CENTAUR используются три типа фреймоподобных структур: прототипы, компоненты и факты. Из 24 прототипов двадцать один представляет определенные заболевания органов дыхания, один — знания, общие для всех заболеваний этого вида, а еще два — знания, в определенной мере независимые от предметной области. Это знания о том, как запустить консультирующую программу и просмотреть имеющиеся свидетельства. Таким образом, знания организуются вокруг самих диагностических категорий. Альтернативный вариант, используемый в большинстве других систем, — заложить эти знания в неявной форме в набор неструктурированных правил.
Прототипы в программе CENTAUR содержат знания и объектного, и метауровня. Из них организована сеть, фрагмент которой представлен на рис. 13.1. Верхний уровень иерархии занимает прототип CONSULTATION (консультация), который управляет всеми стадиями процесса проведения консультаций (ввод исходных данных, активизация гипотез и т.п.). Затем следует слой прототипов, представляющих определенные патологические состояния, такие как RESTRCTIVE LUNG DESEASE (легочные заболевания), OBSRTUCTIVE AIRWAYS DESEASE (заболевания верхних дыхательных путей) и т.п. И на самом нижнем уровне категории заболеваний разделяются, во-первых, на конкретные заболевания, а во-вторых, по степени остроты. Так, категория заболеваний верхних дыхательных путей (OBSRTUCTIVE AIRWAYS DESEASE) может быть разделена на подкатегории MILD (мягкие), MODERATE (умеренные), MODERATELY SEVERE (умеренной остроты) и SEVERE (острые). А конкретные виды заболеваний, представленные на этом уровне, — ASTHMA (астма), BRONCHITIS (бронхит) и EMPHYSEMA (эмфизема).
Каждый прототип имеет слоты для некоторого набора компонентов, которые содержат указатели на субфреймы знаний на объектном уровне. В каждом прототипе заболеваний органов дыхания существуют слоты, представляющие результаты анализов легких, причем каждый из этих слотов также является фреймом с собственными правами и собственной внутренней структурой. Например, фрейм OBSRTUCTIVE AIRWAYS DESEASE (заболевания верхних дыхательных путей) включает 13 компонентов, каждый из которых имеет собственное наименование, характеризуется диапазоном допустимых значений и степенью (мерой) важности. В дополнение к этому фрейм компонента часто содержит специальный слот, называемый "inference rules" (правила вывода), в котором хранятся порождающие правила формирования логического вывода на основе значения этого компонента. Если компонент не содержит такого рода правил или правило по каким-либо причинам не может обработать значение компонента, программа обращается с вопросом к пользователю. Такую меру предосторожности в отношении набора правил можно рассматривать как процедурную связь определенного вида. Процедурная связь обычного вида потребовала бы включение в программу довольно значительного по объему фрагмента LISP-кода.
Факты, с которыми работает программа, представляются фреймами, каждый из которых имеет шесть слотов. В них содержится информация о наименовании параметра, его значении, степени достоверности, источнике, классификации и обоснованности.
Помимо знаний, специфичных для предметной области, в прототипах имеется и управляющий слот. В нем представлены знания метауровня о том, как использовать этот структурный элемент знаний. Этот слот содержит LISP-выражения, предназначенные для
конкретизации прототипа— установки множества компонентов, значения которых должны быть определены;
реагирования на подтверждение или отклонение прототипа; реакция программы заключается в том, что задается множество прототипов, которые следует активизировать на следующем шаге;
вывода сообщения, в котором приводится окончательное заключение.
Каждый управляющий слот можно рассматривать как консеквентную часть правила, условная часть которого сопоставима с ситуацией, описанной компонентами прототипа.
Правила, включенные в прототипы
Нелишне напомнить, что именно компоненты прототипа представляют большую часть знаний объектного уровня, специфичных для определенной предметной области, поскольку в структуре этого типа содержится информация о лабораторных исследованиях, результаты которых должны быть использованы при диагностировании того или иного конкретного заболевания. Эти компоненты являются значениями слотов прототипов, представляющих заболевания, и в то же время имеют собственную внутреннюю структуру и являются прототипами со своими собственными правами. Таким образом, оказывается, что в составе прототипа имеются не только порождающие правила, но и другие прототипы. Можно с полным правом утверждать, что система прототипов имеет по крайней мере двухмерную организацию в дополнение к иерархической организации, представленной в явном виде в терминах типов и подтипов заболеваний. Структуры данных, которые могут быть включены сами в себя, принято называть рекурсивными.
В CENTAUR используется пять типов правил.
Правила логического вывода. Связаны с компонентами, представляющими клинические параметры, и задают возможные способы определения их значений.
Правила активизации. Это антецедентные правила, связанные с клиническими параметрами, которые служат для выдвижения прототипов в качестве гипотез с некоторой степенью правдоподобности.
Правша обработки остаточных фактов. После того как система придет к какому-нибудь заключению в форме набора подтвержденных прототипов, эти правила стараются оценить, как это заключение согласуется с фактами, неучтенными при формировании заключения (остаточными фактами).
Уточняющие правила. Эти правила предполагают проведение дополнительных лабораторных анализов. После выполнения этих правил будет сформировано окончательное множество прототипов с указанием, какой из них учитывает тот или иной из имеющихся фактов, причем каждый факт должен быть учтен по крайней мере одним прототипом.
Правша вывода. Эти правила переводят информацию, представленную в прототипах, на "человеческий" язык и представляют ее пользователю.
Другие слоты содержат обычную информацию, необходимую для учета, — имя автора, сведения об источнике информации и о текущей ситуации, которые затем используются при формировании объяснения, почему данный прототип был активизирован.
Как видно, в системе CENTAUR в основу классификации правил положены функции, выполняемые с их помощью. В системе PUFF, реализованной на базе оболочки EMYCIN, все правила считаются правилами логического вывода, хотя многие из них и не имеют непосредственного отношения к логическому выводу. Например, большая группа правил предназначена для сбора информации, используемой в качестве свидетельств, или для установки значений по умолчанию. Кроме того, контекст применения правил в CENTAUR представлен в явном виде, поскольку правила являются значениями слотов. Например, в системе PUFF правила для оценки значений клинических параметров индексированы по наименованию параметра, которое появляется в консеквентной части правила, т.е. использован тот же принцип, что и в системе MYCIN. В системе CENTAUR правила оценки определенных параметров хранятся в виде значения одного из слотов в прототипе компонента, представляющего этот параметр, и применяются только в контексте этого прототипа, т.е. в том случае, если прототип активизирован.
Ниже, в главе 18, будет показано, что дальнейшее углубление такого "распределенного" подхода к организации порождающих правил приводит к созданию нового класса систем, получивших название систем с доской объявлений (blackboard systems). Но уже на опыте эксплуатации системы CENTAUR исследователи убедились в преимуществах явного связывания правил с контекстом их применения. Это не только упрощает процесс программирования экспертной системы, но и помогает при формировании объяснений, почему в конкретной ситуации были использованы определенные правила (более подробно об этом — в главе 16).
Формирование суждений на базе модели в системе INTERNIST
В программе INTERNIST предпринята попытка смоделировать поведение врача на различных этапах диагностического процесса. Как правило, общая картина, которая вырисовывается на основании имеющихся симптомов, порождает одну или несколько гипотез о том, какие патологии имеются у пациента. Эти гипотезы, в свою очередь, подталкивают врача к поиску других симптомов. Дальнейшее наблюдение пациента может привести к тому, что какие-то из ранее выдвинутых гипотез получат дальнейшее подтверждение, а другие, наоборот, окажутся противоречащими новым данным. Не исключен и вариант появления после более тщательного исследования пациента новых гипотез. Гипотезы, которые появились на начальном этапе, можно считать порожденными первичными данными в том смысле, что определенное проявление патологии порождает множество догадок. Последующее накопление новых данных, призванных подтвердить или опровергнуть первоначальные догадки, можно рассматривать как ведомое моделью в том смысле, что оно базируется на определенных стереотипах или концептуальных идеях о том, как проявляется то или иное заболевание.
В большинстве задач, связанных с логическим выводом (к ним относятся и задачи диагностирования), редко когда рассуждение ведется только в одном направлении, т.е. в направлении одной цели (версии о причинах случившегося). В основном это происходит из-за неполноты исходной информации, которой бывает недостаточно для четкой формулировки проблемы. Например, врач может не располагать на начальном этапе обследования достаточно полной информацией для того, чтобы очертить круг возможных заболеваний пациента, или та информация, которой он располагает, может вести его в разных направлениях (не исключено, что пациент страдает не одним, а несколькими заболеваниями).
При разработке программы INTERNIST ставилась задача провести разграничение между множеством взаимно исключающих гипотез о заболеваниях, которые могут возникнуть, в процессе диагностирования. Если пациент страдает несколькими заболеваниями, то программа должна отобрать такое множество гипотез, которое "накрывало" бы как можно большую часть (а лучше все) обнаруженных симптомов. Для этого сначала исследуется наиболее правдоподобная гипотеза, определяется, какую часть из имеющихся симптомов она учитывает, затем анализируется следующая по степени правдоподобия гипотеза, и так до тех пор, пока набором гипотез не будут учтены все имеющиеся симптомы.
Представление знаний в дереве заболеваний
Попл (Pople) рассматривает четыре этапа процесса логического вывода при диагностировании.
(1) Клинические наблюдения должны дать основания для формирования списка возможных заболеваний (кандидатов для дальнейшего уточнения), которые могут быть причиной наблюдаемых явлений или симптомов.
(2) Эти гипотетические кандидаты затем порождают предположения относительно того, какими другими проявлениями они могли бы "дать знать" о себе.
(3) Далее потребуется изыскать какой-либо метод, позволяющий сделать выбор в пользу определенных гипотез на основании имеющихся свидетельств.
(4) Нужно иметь возможность разделить множество имеющихся гипотез на ряд взаимно исключающих подмножеств. Правдоподобие одного подмножества автоматически означает при этом неправдоподобие другого.
Ключевым моментом в рассматриваемой Поплом схеме является двунаправленная связь между заболеваниями, с одной стороны, и признаками или симптомами, с другой. Программа INTERNIST рассматривает такую связь как пару отдельных отношений: EVOKE и MANIFEST.
Отношение EVOKE (истребование) указывает на способ, которым некоторый признак дает основание предполагать наличие определенного заболевания.
Отношение MANIFEST (провозглашение) указывает на то, как (в виде каких показаний или симптомов) может проявляться определенное заболевание.
Знания в области медицины представлены в программе INTERNIST в виде дерева заболеваний — иерархической классификации типов заболеваний. Корневой узел в этом дереве соответствует всем известным заболеваниям, нетерминальные узлы — областям заболеваний, а терминальные — сущностям заболеваний, т.е. конкретным заболеваниям, которые можно диагностировать и для которых можно назначать курс лечения. Это дерево представляет собой статическую структуру данных, отдельную от основного программного кода системы INTERNIST, что делает его сходным с таблицами знаний в системе MYCIN. Но в отличие от таблиц знаний в MYCIN, знания в системе INTERNIST играют куда более активную роль в управлении процессом логического вывода.
База знаний программы INTERNIST формируется следующим образом.
(1) Определяется базовая структура иерархии— к корневому узлу подсоединяются узлы основных областей внутренних болезней (органов дыхания, болезней печени, сердца и т.п.).
(2) Выделяются подкатегории, в которых объединяются области заболеваний с похожими схемами протекания (патогенезом) и проявлениями (признаками и симптомами).
(3) Эти подкатегории разделяются до тех пор, пока не будет достигнут уровень сущностей, т.е. конкретных заболеваний.
(4) Собираются данные, касающиеся связей между сущностями заболеваний и их проявлениями. В число этих данных входят: список всех проявлений конкретного заболевания; оценка вероятности того, что данное заболевание является причиной проявления именно такого признака или симптома; оценка того, насколько часто у пациентов, страдающих определенным заболеванием, наблюдается каждое из отмеченных проявлений.
(5) К представлению каждого заболевания D присоединяется список связанных с ним проявлений (M1, ..., Мn), список показателей причинности L(D, Mi) и список показателей частотности L(Mi, D). Показатели обоих типов определены в диапазоне 0-5.
(6) С каждым заболеванием D, помимо признаков и симптомов, могут быть связаны и другие заболевания, которые также могут рассматриваться как проявления заболевания D. Такие ''вторичные" заболевания связываются в структуре представления знаний с узлом заболевания отношениями EVOKE и MANIFEST.
(7) После сбора и представления всей информации, касающейся "обслуживаемых" системой заболеваний D (т.е. терминальных узлов дерева), запускается программа, которая преобразует описанное дерево в обобщенное представление иерархической структуры. В этом представлении нетерминальные узлы содержат только те свойства, которые являются общими для всех его дочерних узлов.
(8) Вводятся данные об отдельных проявлениях. Наиболее существенными свойствами проявлений являются TYPE (например, признак, симптом, лабораторный тест и т.п.) и INDEX (число в диапазоне 1-5, которое является показателем важности данного проявления).
В ходе выполнения первых трех этапов формируется "суперструктура" базы знаний, т.е. в общих чертах определяется ее схема — диапазон категорий и уровень анализа каждой категории. На последующих трех этапах сформированная структура базы знаний наполняется содержимым. Введенные значения показателей причинности и частотности позволяют программе манипулировать в дальнейшем с "вескостью" свидетельств в пользу или против определенной гипотезы.
На шаге 7 программа определяет проявления для нетерминальных узлов, представляющих области заболеваний, анализируя степень их общности для дочерних узлов более низких уровней иерархии. Например, разлитие желчи является проявлением целой группы заболеваний печени, которая объединяется областью гепатитные заболевания.
Целесообразность такого обобщения проявлений объясняется следующим образом. Как уже не раз подчеркивалось ранее, пространство диагностируемых категорий для пациентов, страдающих несколькими заболеваниями, оказывается чрезвычайно большим. Вследствие этого на практике не удается применить в этом пространстве обычные методы поиска, такие как поиск в глубину. Нужно каким-то способом "свернуть" пространство поиска или сфокусировать усилия программы на определенной области пространства и таким образом добиться приемлемой скорости поиска.
Проблема скорости поиска не стояла бы с такой остротой даже при наличии у пациента нескольких заболеваний, если бы существовали более прямые ассоциативные связи между заболеваниями и их проявлениями, т.е. если бы определенное проявление сразу позволило врачу прийти к заключению о наличии определенного заболевания. Такие отношения в медицинской литературе называются патогенетическими, и они действительно существуют, но, к несчастью, значительно реже, чем нам хотелось бы. Хуже всего то, что патогенетические отношения характерны для тех проявлений, которые могут быть выявлены только в процессе сложных лабораторных исследований или хирургическим путем.
Установить же достаточно жесткие связи между определенными проявлениями и целой группой заболеваний (областью заболеваний в терминологии программы INTERNIST) удается гораздо чаще. Такое проявление, как разлитие желчи, жестко связано с областью заболеваний печени, а кровохаркание — с областью легочных заболеваний. Программа INTERNIST использует связи на верхних уровнях дерева для "сужения" пространства поиска. При этом начальная точка поиска как бы переносится на более низкие уровни иерархии в пространстве заболеваний и уже оттуда начинается выполнение процедуры поиска в глубину.
В используемой Поплом терминологии сужение (constrictor) для конкретного случая диагноза — это нахождение во множестве известных проявлений "намека", в какой области пространства заболеваний находятся правдоподобные гипотезы. Однако не следует забывать, что такое сужение является эвристическим, а потому не гарантирует на все сто процентов, что искомое заболевание находится именно в определенной таким способом области. Хотя на верхних уровнях иерархии и могут существовать проявления, прямо связанные с определенной областью, другие проявления остаются только более предпочтительными для одной области и менее предпочтительными, но отнюдь не невозможными, для другой. При этом ситуация еще более ухудшается по мере перехода на более низкие уровни иерархии.
Из всего сказанного следует, что то упорядочение проявлений, которое выполняется на этапе 7, позволяет консультационной программе начинать диагностическую процедуру на том уровне иерархии, на котором начинают проявляться патогенетические отношения, и отсеивать таким образом целые классы заболеваний.
На этапе 8 обрабатываются свойства самих проявлений, что в процессе работы программы скажется на эффективности выполнения функций на стратегическом уровне. Например, свойство TYPE позволяет судить о том, насколько велики будут затраты на получение того или иного показателя или насколько процесс его получения будет опасен для здоровья пациента, а эту информацию следует учитывать при назначении уточняющих анализов. Свойство IMPORT позволяет принять решение, нельзя ли проигнорировать данное проявление в контексте определенного заболевания. Обратите внимание на то, что на этапах 5 и 8 используется довольно неформализованное представление неопределенности в суждениях. Но в дальнейшем мы увидим, что основной причиной появления проблем в процессе работы с системой INTERNIST является неудовлетворительная формулировка структуры пространства поиска, а не недостаточная точность исходных данных.
Ниже, в разделе 13.4, мы рассмотрим, как отражается использование в программе INTERNIST иерархической структуры дерева гипотез на методике извлечения знаний при опросе экспертов.
Методика выделения правдоподобных гипотез в INTERNIST
В процессе выполнения консультаций программа INTERNIST работает следующим образом. Сначала пользователь вводит список существующих проявлений заболеваний пациента. Каждое проявление активизирует один или несколько узлов в дереве заболеваний.
Из выделенных на этом этапе узлов программа формирует модели заболевания, каждая из которых включает четыре списка:
(1) наблюдаемые проявления, не связанные с данным заболеванием;
(2) наблюдаемые проявления, согласующиеся с данным заболеванием;
(3) проявления, отсутствующие во введенных данных, но всегда сопутствующие данному заболеванию;
(4) проявления, которые отсутствуют во введенных данных, но не согласуются с данным заболеванием (опровергают выдвинутую гипотезу).
В модели заболевания проявления, подтверждающие гипотезу, получают положительные оценки, а те, которые им противоречат, — отрицательные. Оба типа оценок "взвешиваются" значениями свойств IMPORT соответствующих проявлений, и модель получает премиальные очки, если имеет причинную связь с другим подтвержденным заболеванием. Затем модели заболеваний разделяются на две группы. В одну группу попадают модель с самой высокой оценкой и все остальные, которые представляют взаимно исключающие с ней гипотезы. Их можно считать "соседними" узлами на дереве заболеваний. Другая группа включает заболевания, совместимые с наиболее правдоподобной гипотезой, т.е. узлы, принадлежащие другим областям заболеваний (рис. 13.2).
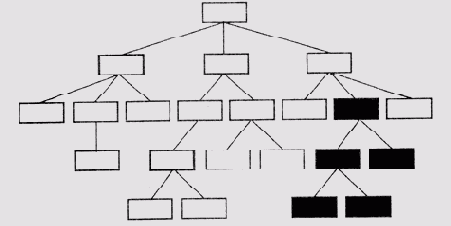
Рис. 13.2.
Разделение узлов в дереве гипотез. Узлы активизированных гипотез вычерчены утолщенными
прямоугольниками, а узел наиболее правдоподобной гипотезы и его дочерние узлы
залиты серым цветом
Рациональное зерно в таком разделении в том, что модели, включенные в привилегированную группу на любом этапе уточнения, можно считать взаимно исключающими альтернативами. Такое заключение основано на том, что для любых гипотез (моделей) Di и Dj в этой группе диагноз, включающий Di иDj, добавит очень немного или не добавит ничего к "полноте накрытия" каждой из гипотез Di и Dj по отдельности. На следующем этапе уточнения модели обрабатываются по той же методике, если проблема выбора среди моделей, связанных с Do, будет решена. Разделение начинается с нового узла Do, который получит наивысшую оценку среди уточняемых моделей.
Уже после ввода первой порции исходных данных будет активизирована только часть всех узлов дерева. Теперь задача программы состоит в том, чтобы преобразовать дерево из исходного состояния в состояние решения. В состоянии решения дерево должно включать только те терминальные узлы, которые в совокупности "накрывают" все имеющиеся симптомы.
Разделив модели заболеваний, программа может использовать ряд альтернативных стратегий, которые выбираются в зависимости от количества обрабатываемых гипотез.
Если обрабатывается более четырех гипотез, используется стратегия опровержения (режим RULEOUT). Смысл ее заключается в том, чтобы как можно сильнее свернуть дерево пространства гипотез, задавая пользователю вопросы о симптомах, которые являются наиболее сильными индикаторами гипотез-кандидатов.
Если количество анализируемых гипотез не превышает четырех, но больше одной, используется стратегия дифференциации (режим DISCRIMINATE). При этом пользователю задают вопросы, которые помогут выбрать между гипотезами-кандидатами.
Если анализируется всего одна гипотеза, используется стратегия верификации (режим PURSUING). Пользователю задают вопросы, способные подтвердить справедливость анализируемой гипотезы.
Весь процесс носит итеративный характер. Данные, которые пользователь вводит в ответ на вопросы программы в любом из перечисленных режимов, обрабатываются по той же методике, что и введенные сразу после начала сеанса работы с программой. При этом, в частности, активизируются новые узлы дерева, обновляется активизация ранее проанализированных узлов, формируются и сортируются модели заболеваний и выбираются узлы (возможно, новые) для формирования уточняющих вопросов.
Проблемы, обнаруженные в процессе эксплуатации системы INTERNIST
В общих чертах программа INTERNIST работает следующим образом. На начальном этапе данные о пациенте вводятся в любом порядке, при этом объем данных значения не имеет. Далее программа приступает к первому шагу решения задачи дифференциального диагностирования — формируется первичный набор гипотез, который может включать как области заболеваний (т.е. нетерминальные узлы дерева заболеваний), так и конкретные заболевания (терминальные узлы). Если какая-либо из отобранных гипотез объясняет наличие важных проявлений из числа тех, которые наблюдаются у пациента, то этой гипотезе "начисляются" поощрительные очки. Если из гипотезы следует, что у пациента должно быть определенное проявление заболевания, а в действительности оно не наблюдается, то гипотеза "наказывается" штрафными очками. В списке гипотез, отсортированном по сумме набранных оценок, два элемента считаются конкурирующими в том случае, если их объединение не объясняет никаких новых проявлений, которые не могли бы быть объяснены любой из этих гипотез по отдельности. Определив набор альтернатив, программа таким образом формулирует задачу дифференциации. Далее программа "сосредоточит внимание" на множестве гипотез, в которое входят наиболее правдоподобная гипотеза и ее конкуренты.
Однако следует подчеркнуть, что INTERNIST в действительности не использует тот простой алгоритм иерархического построения и проверки гипотез, который в общих чертах был описан в разделе 13.1. Это объясняется тем, что симптомы, которые активизируют определенный нетерминальный узел в дереве заболеваний, могут быть также существенны и для других узлов. Таким образом, программа не может предполагать, что заболевание, которым страдает пациент, должно быть найдено только среди дочерних узлов активизированного нетерминального узла. Так, хотя симптомом холеры (cholestasis) и является разлитие желчи (jaundice), существуют и другие заболевания, никакого отношения к холере не имеющие, которые могут иметь такой же симптом, например группа алкогольных гепатитов (alcoholic hepatitis). Таким образом, хотя основная идея построения дерева заболеваний состоит в том, что соседние узлы в иерархии должны соответствовать заболеваниям или группам заболеваний с общими симптомами, программе приходится часто рассматривать гипотезы из достаточно разнородных областей заболеваний.
В этом и состоит основная проблема при решении задачи диагностирования с помощью INTERNIST. В одной из своих работ Попл указал на то, что на практике использованные в программе эвристические методы управления процессом логического вывода иногда оставляют без внимания важные данные о состоянии пациента, а отдают предпочтение менее существенным с точки зрения специалистов-практиков [Pople, 1982]. Поскольку сходимость процесса поиска не совсем соответствует той идеальной картине, которая была описана выше, это приводит к серьезному затягиванию интерактивного процесса диагностирования в сложных случаях, так как на начальной стадии программа отдала предпочтение неконструктивной гипотезе. Так, результаты клинических анализов исследования различных органов пациента, если рассматривать их по отдельности, заставляют программу "распылять" внимание в нескольких направлениях. Опытный клиницист постарается интегрировать имеющиеся данные на ранних стадиях диагностирования и сосредоточиться на какой-либо одной ключевой гипотезе. Таким образом, оказывается, что схема управления процессом логического вывода, реализованная в программе INTERNIST, на практике оказывается слишком упрощенной по сравнению с моделью рассуждений, используемой опытным врачом.
Как показал опыт эксплуатации систем PUFF и CENTAUR, при работе в ограниченной предметной области, т.е. в случае, когда диагностируется довольно жестко очерченный круг заболеваний, описанная стратегия оказывается вполне приемлемой. Проблемы возникают при расширении предметной области. Нельзя сказать, что при этом метод оказывается вообще неработоспособным, поскольку программа INTERNIST все-таки справляется с довольно сложными случаями, но врачи отмечают, что при этом она иногда демонстрирует довольно странный путь поиска решения.
Попл пришел к выводу, что базовая стратегия иерархического построения и проверки гипотез нуждается в дополнении новыми структурами знаний, которые представляли бы сведения о подходящем структурировании множества альтернатив, известных опытным клиницистам. Он отметил, что в нынешней базе знаний программы INTERNIST знания о возможных конкурирующих заболеваниях представлены недостаточно полно, нужно провести дальнейшие исследования целесообразности использования различных стратегий управления логическим выводом после того, как задача дифференциального диагностирования сформулирована, в частности разработать наиболее удачные критерии отсеивания гипотез.
Если воспользоваться терминологией Кленси (см. главу 12), то в решении проблем, связанных с медицинской диагностикой, имеются структурный и стратегический аспекты, которые не представлены явно ни в организации пространства гипотез, ни в организации процедур конструирования и решения задач дифференциального диагностирования.
Рабочая среда инженерии знаний TDE
TDE [Kahn et at, 1987] представляет собой среду разработки для комплекса инструментальных средств создания экспертных систем TEST [Pepper and Kahn, 1987]. Последний ориентирован прежде всего на решение проблем классификации, к которым, в частности, относится и задача диагноза. Название системы TEST— аббревиатура от Troubleshooting Expert System Tool (комплекс инструментальных средств для построения экспертных систем поиска неисправностей), а название системы TDE — аббревиатура от TEST Development Environment (среда разработки TEST). При создании этих программ был использован подход, существенно отличающийся как от подхода при разработке программ MYCIN/EMYCIN (см. главу 10), так и от подхода, использованного при разработке программ MUD/MORE (см. главу 12).
Основным элементом представления знаний является структурированный объект, а не порождающее правило. (Для разработки TDE был использован язык описания фреймов Knowledge Craft.)
Объекты представляют понятия, тесно связанные со способом мышления специалистов по поиску и устранению неисправностей. Такие абстрактные понятия, как гипотезы и симптомы, заменены конкретными— вид отказа (failure mode) и тестовая процедура (test procedure), смысл которых будет объяснен ниже.
Свои знания пользователи вводят в систему, манипулируя пиктограммами (в этом смысле процедура ввода знаний напоминает использованную в системе OPAL (см. главу 10)).
Представление знаний имеет ярко выраженный процедуральный аспект. Например, в представлении знаний тестовые процедуры связаны с видами отказов в дополнение к вычислению степени уверенности в правдоподобности гипотезы, которая рассматривается как функция от наблюдаемых симптомов.
Вид отказа, пожалуй, самое важное понятие в TEST и TDE: оно означает любое отклонение в поведении объекта при тестировании — от полной неработоспособности до отклонений в функционировании какого-нибудь малозначительного компонента. Так, если речь идет об обслуживании автомобиля, то "двигатель не заводится" — это типичный вид отказа, но "разряжена аккумуляторная батарея" — это тоже один из видов отказа. В традиционных экспертных системах нужно было различать, чем является разряд аккумуляторной батареи, — гипотезой об источнике неисправности, которая следует из первичных данных, или симптомом, представленным в составе первичных данных. Для системы TEST это разделение не имеет такого существенного значения, как для системы MUD или MYCIN. При организации знаний в TEST использованы и другие концепции:
процедуры тестирования и ремонта неисправностей (отказов);
представление в явном виде причинно-следственных связей между отказами.
Виды отказов в системе организованы в древовидную структуру, в которой корневой узел, как правило, представляет неисправность всего устройства (составного объекта), а терминальные узлы (листья дерева)— неисправности конкретных компонентов устройства (простейших объектов). Нетерминальные узлы представляют отклонения или неисправности при выполнении отдельных функций, например "нет освещения". Между корнем дерева и терминальными узлами может находиться довольно много уровней нетерминальных узлов.
Как и в системах CENTAUR и INTERNIST, это дерево неисправностей в TEST является скелетом базы знаний. Следующий уровень структуризации составляют процедуры выполнения тестирования и устранения неисправностей и различные виды правил, представляющих процедуральные знания, связанные с видами отказов. К ним относятся знания о том, какие измерения нужно выполнить для подтверждения неисправности, как устранить ее, как отыскать компонент, неисправность которого может быть причиной данного отказа, и т.п. И, наконец, существует еще и третий уровень структуризации декларативных знаний, который представлен множеством атрибутов, связанных с узлами отказов. Эти атрибуты описывают разнообразные свойства компонентов, имеющих отношение к определенной неисправности, а также связи между компонентами.
Хотя в структуре базы знаний системы TEST и не используются такие традиционные понятия, как гипотезы и симптомы, все же можно говорить о том, что работа системы построена на базе метода эвристической классификации. Узлы отказов, расположенные ближе к корню дерева, представляют абстрактные категории данных, а те, что ближе к листьям, — абстрактные категории решений (рис. 13.3). Задача программы— построить цепочку причинно-следственных связей от узлов отказов верхних уровней, например "двигатель не заводится", до терминальных узлов вроде "разряжена аккумуляторная батарея". Отображение абстрактных категорий данных на абстрактные категории решений состоит из двух типов отношений между узлами отказов в дереве — из-за (due-to) и всегда_приводит_к (always-leads-to). Эвристики представляются на программном уровне в виде подключенных к узлам дерева правил, которые направляют процесс поиска узлов более нижних уровней.
TDE является сравнительно новой системой, которую можно считать существенным шагом вперед по сравнению с системой MORE. К сожалению, когда эта книга готовилась к печати, у нас не было возможности опробовать эту систему на практике, но кое-какие тенденции в ее конструкции просматриваются довольно четко. Например, совершенно очевидно, что графический интерфейс предоставляет пользователю гораздо большую свободу при построении базы знаний, чем символьный интерфейс системы MORE. Для новичков в системе предусмотрена опция переключения на режим вопросов и ответов. В этом режиме система задает пользователю вопросы и последовательно "ведет" его через три стадии описания знаний, которые были описаны чуть выше. Опытный пользователь может отказаться от такого режима и вводить информацию, необходимую для представления знаний, в той последовательности, которую считает наиболее целесообразной.
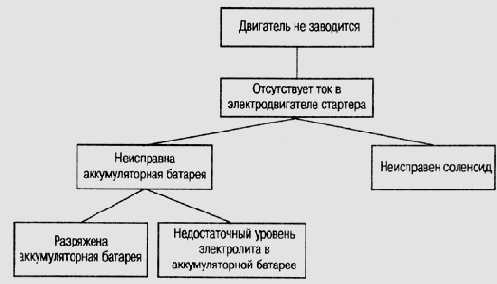
Рис. 13.3.
Иерархическая организация узлов отказов в системе TEST
Рекомендуемая литература
Подробное описание программы INTERNIST и исследований, выполненных в процессе работы над этой программой, читатель найдет в работе [Pople, 1982]. Но не все идеи, описанные в этой статье, были реализованы в готовой системе и не все декларированные принципы были соблюдены при ее разработке. Архитектура системы GENTAUR была успешно использована для построения экспертных систем, не имеющих отношения к медицине. В частности, эта архитектура использована в системе REX, консультирующей статистиков при выполнении регрессионного анализа [Gale, 1986]. В работе этого же автора [Gale, 1987] описана программа извлечения знаний Student, созданная для работы в той же предметной области, что и Rex. В этой системе использованы некоторые принципы, опробованные в системе OPAL, в частности во главу угла поставлены знания, а не определенная стратегия решения проблем, принятая в данной проблемной области.
В работе [Мшеп et al, 1995] описан опыт переделки программы INTERNIST с помощью набора инструментальных средств PROTEGE (о последнем см. в [Musen, 1989] и [Rothenfluket al., 1994]). Комплекс PROTEGE во многом сходен с CommonKADS. В нем объединена1 онтологическая оболочка, подобная реализованной в системе OPAL, с обобщенным методом решения проблем [Puerto et al., 1994].
в системе CENTAUR? Какие функции1. Что понимается под прототипом в системе CENTAUR? Какие функции возлагаются на прототипы? 2. В чем преимущества смешанного способа представления знаний в системе CENTAUR? 3. Что представляет собой модель заболевания в системе INTERNIST? Объясните смысл концепции доминантности применительно к модели заболеваний в системе INTERNIST. 4. Какие проблемы обнаружились при работе над системой INTERNIST и как они соотносятся с проведенным Кленси анализом различных видов знаний? 5. Выполнение этого упражнения потребует некоторых познаний в медицине — знаний о физическом смысле некоторых параметров, измеряемых при лабораторных анализах органов дыхания. (Лично я узнал о них от д-ра Джереми Уатта (Jeremy Wyatt) и д-ра Патриции Твидейл (Patricia Tweedale). Любые фактические ошибки в приведенном ниже описании прошу отнести на мой счет, но думаю, они не повлияют на смысл самого упражнения.) При диагностике легочных заболеваний используются следующие параметры, измеряемые при лабораторном обследовании пациентов. Index0.htm FEV1 (Forced Expiratory Volume). Объем форсированного выдоха за 1 секунду, измеренный в литрах. Измеряется количество воздуха, выдыхаемого пациентом в течение 1 секунды. Этот параметр является показателем эластичности легочных тканей (а следовательно, и их здоровья). Index0.htm IFV1. Показатель изменения FEV1 после курса лечения с применением бронхолитиков. Index0.htm FVC (Forced Vital Capacity). Жизненная емкость легких - объем вдыхаемого воздуха при максимальном наполнении легких. Index0.htm IFVC. Показатель изменения FVC после курса лечения с применением бронхолитиков. Index0.htm TLC (Total Lung Capacity). Общая емкость легких. Index0.htm RV (Residual Volume). Остаточный объем легких - объем воздуха, который остается в легких после максимального выдоха. Index0.htm RATI01 = FEV1/FVC. Index0.htm RATI02 = FEV1/FVC после курса лечения с применением бронхолитиков. Ниже в постановке задачи переменная PRED означает ожидаемое значение любого из перечисленных выше параметров. (Ожидаемое значение медицинского параметра зависит главным образом от пола пациента.) Выражения вида 80% < RATI01 < 100% (PRED-2SD) означают, что параметр RATI01 имеет значение между 80 и 100 процентами от ожидаемого значения, уменьшенного на удвоенное стандартное отклонение в соответствующей популяции. Аббревиатура RTB означает Response To Bronchodilation (реакция на прием бронхолитиков). I) Разработайте структуру фреймов для каждого из следующих заболеваний дыхательных органов и связанных с ними медицинских параметров. Организуйте иерархию фреймов и включите ее в иерархию других аналогичных заболеваний, представленную на рис. 13.1. AIRWAIS OBSTRUCTION существует, если: RATI01 < PRED-2SD отсутствует RTB, если: RATI02 < PRED-2SD хороший показатель RTB, если: RATI02 > PRED-2SD SLIGHT AIRWAIS OBSTRUCTION существует, если: 801 < RATI01 < 100% (PRED-2SD) отсутствует RTB, если: IFV1 < FEV1/10 IFVC < FVC/10 хороший показатель RTB, если: FEV1 > (PRED-2SD)/4 FEV1/3 < IFEV1 MODERATE AIRWAIS OBSTRUCTION существует, если: 55% < RATI01 < 80% (PRED-2SD) SEVERE AIRWAIS OBSTRUCTION существует, если: RATI01 <= 55% (PRED-2SD) RESTRICTIVE DEFECT существует, если: RV < PRED+2SD TLC <= 80% (PRED-2SD) RATI01 > 80% (PRED-2SD) EARLY RESTRICTIVE DEFECT существует, если: TLC < (PRED-2SD) RATI01 > (PRED-2SD) MILD RESTRICTIVE DEFECT существует, если: RATI01 > (.PRED-2SD) 80% < TLC < 100% (PRED-2SD) MODERATE RESTRICTIVE DEFECT существует, если: RATI01 > (PRED-2SD) 60% < TLC < 80 (PRED-2SD) SEVERE RESTRICTIVE DEFECT существует, если: RATI01 > (PRED-2SD) TLC < 60 (PRED-2SD) Вам понадобятся процедуры для накопления диагностических знаний, связанных с этими заболеваниями. В каждом фрейме нужно предусмотреть слоты для хранения ожидаемых среднестатистических значений и стандартных отклонений. Так, слот PRED-RATI01 будет хранить ожидаемое значение параметра RATI01, а слот SD-RATI01 — стандартное отклонение этого параметра. Конечно, для этого упражнения можно подставить любые значения в эти слоты, поскольку главное, что от вас требуется, — правильно организовать связи между слотами. Например, фрейм-объект SEVERE-RESTRICTIVE-DEFECT может включать метод (процедуру LISP) PRESENT, который определен следующим образом: SEVERE-RESTRICTIVE-DEFECT.PRESENT (and( > RATI01 (- PRED-RATI01 ( SD-RATI01 2))) (< TLC (/ ( 6 (- PRED-TLC (*SD-TLC 2))) 10))) Эта процедура возвращает значение Т, если соблюдаются специфицированные в ней условия. II) Представьте диагностические знания, связанные с этими фреймами, в виде порождающих правил, а не в виде процедур. Как и в предыдущем случае, правила должны ссылаться на значения слотов. 6. Разработайте и реализуйте простую программу извлечения знаний, которая позволила бы пользователю передать сведения о неисправностях в некотором устройстве и перечислить их возможные причины. Например, если вас привлекает предметная область обслуживания автомобиля, то программа должна принимать сведения о таких видах отказов (в терминологии TDE), как "двигатель не заводится", уточнять причину отказа, например "подается ли ток на электродвигатель стартера?", и связывать возможные причины с каждым таким уточнением. Естественно ожидать, что отказ "двигатель не заводится" будет связан с такими причинами, как "неисправна аккумуляторная батарея" и "неисправен соленоид стартера", а узлы отказов вроде "неисправна аккумуляторная батарея" должны требовать дальнейшего уточнения — "разряжена аккумуляторная батарея" и "недостаточный уровень электролита в аккумуляторной батарее". Программа должна сохранять всю полученную информацию в древовидной структуре, которая была описана в разделе 13.4. 7. Протестируйте разработанную в упр. 6 программу либо самостоятельно, либо пригласите коллегу, которого считаете специалистом в соответствующей предметной области. Если не удастся найти никого, кто помог бы вам в этом деле, воспользуйтесь доступной технической литературой. Например, для ввода знаний о возможных неисправностях автомобиля вполне достаточно руководства, которое выдают к каждому автомобилю при покупке. |
