Физический и канальный уровень модели OSI для Ethernet и Fast Ethernet
Рисунок 9.1. Физический и канальный уровень модели OSI для Ethernet и Fast Ethernet

Можно выделить следующие подуровни:
Reconciliation - подуровень согласования. Служит для перевода команд МАС-уровня в соответствующие электрические сигналы физического уровня. MII - Medium Independent Interface, независимый от среды интерфейс. Обеспечивает стандартный интерфейс между МАС-уровнем и физическим уровнем. PCS - Physical Coding Sublayer, подуровень физического кодирования. Выполняет кодирование и декодирование последовательностей данных из одного представления в другое. PMA - Physical Medium Attachment, подуровень подсоединения к физической среде. Преобразует данные в битовый поток последовательных электрических сигналов, и обратно. Кроме того, обеспечивает синхронизацию приема/передачи. PMD - Physical Medium Dependent, подуровень связи с физической средой. Отвечает за передачу сигналов в физической среде (усиление сигнала, модуляция, формирование сигнала). AN - Auto-negotiation, согласование скорости. Используется для автоматического выбора устройствами протокола взаимодействия. MDI - Medium Dependent Interface, зависимый от среды интерфейс. Определяет различные виды коннекторов для разных физических сред и PMD-устройств.
Необходимо подчеркнуть различия между классическим Ethernet 802.3i (10 Мбит) и Fast Ethernet 802.3u, объединяющий FX, TX, и T4. В первом роль связующего звена между MAC-уровнем и PHY играл интерфейс AUI. Так как кодирование было всегда одинаковым (Манчестер-2), то схема была простой. Поэтому AUI располагался между подуровнем физического кодирования сигнала и подуровнем физического присоединения к среде. Усложнение Fast Ethernet повлекло и изменение схемы. Добавилось несколько блоков, и интерфейс MII занял место над подуровнем кодирования сигнала, который, в свою очередь, логически вошел в PHY.
Надо так же отметить, что подуровень согласования скоростей (AN) используется не во всех способов передачи. Например, его нет в 10baseT, 10/100baseF.
Подробное рассмотрение подуровней лучше вести "снизу", от физической среды. Так же, в предыдущих главах были подробно рассмотрены вопросы подсоединения к физической среде (MDI), и формирования сигналов (PMD).
Физический уровень.
Физический уровень.
Особенности физического уровня модели OSI удобно рассматривать с использованием следующего рисунка:
Физическое кодирование (PCS)
Физическое кодирование (PCS)
Как уже было показано выше, коды MLT-3 и NRZI не являются самосинхронизирующимся. Передача длинной последовательности единиц или нулей подряд приведет к потере несущей, и ошибкам приема.
Для исключения таких цепочек применяют кодирование данных 4B/5B, в котором используется пяти-битовая основа для передачи четырех-битовых сигналов. Кроме синхронизации, этот метод улучшает помехоустойчивость благодаря контролю принимаемых данных на пяти-битном интервале. Очевидная цена кодирования данных - снижение на 25% скорости передачи полезной информации.
Преобразованный пяти-битовый сигнал имеет 16 значений для передачи информации, и 16 избыточных значений, из которых для служебных сигналов отведены девять символов, а семь комбинаций, имеющие более трех нулей - не используются. Исключенные сигналы (01 - 00001, 02 - 00010, 03 - 00011, 08 - 01000, 16 - 10000) интерпретируются символом V (VIOLATION - сбой).
Наличие служебных символов позволяет применять схему непрерывного обмена сигналами между передатчиком и приемником. Это позволяет сетям 100base-T осуществлять более эффективные методы доступа к физической среде по сравнению с 10Base-T.
Необходимо обратить внимание, что именно методам кодирования обязан рост скоростей передачи как в Ethernet, так и других технологий передачи данных (например xDSL), с использованием прежней кабельной инфраструктуры. Выше показано, как переход на другой способ кодирования способен снизить требуемую полосу пропускания почти на 40%.
Еще более заметно это на протоколе 1000base-T - в нем современные методы кодирования успешно используются для серьезного повышения скорости передачи. Если посмотреть на проблему с другой стороны, то можно показать возможность передачи с небольшой скоростью 10 мегабит на расстояние до 3 километров. Подробнее этот вопрос будет рассмотрен в следующих главах.
В заключение, отметим еще один важный момент. В PHY TX есть специальный механизм шифрования-дешифрования (scrambler/descrambler). Определен он в спецификации ANSI TP-PMD, и используется для равномерного распределения сигнала по частотному спектру. Что, в свою очередь, уменьшает электромагнитное излучение кабеля.
Сетевые протоколы.
Глава 9. Сетевые протоколы.
Контора пишет...
В Главах 7 и 8 были показаны физические линий передачи данных, по которым можно передавать электрические или оптические импульсы с заданной частотой и формой сигнала. Теперь нужно рассмотреть тот путь, который проходят данные от шины компьютера до передатчика сетевого адаптера.
Вопрос весьма объемный, и нужно его упорядочить, разбить на небольшие, относительно независимые части. Для этого даже существует несколько вполне логичных моделей. Однако решить, какая из них более удобная, порой не могут даже специалисты. Поэтому подход в изложении материала будет вполне традиционен - краткий обзор разных методик, и пристальное внимание техническим особенностям.
Глава 9 | «« Назад | Оглавление | Вперед »»
Кадры Ethernet с тегами VLAN 802.1q
Кадры Ethernet с тегами VLAN 802.1q
Первое время массовому внедрению Ethernet не мешали "врожденные" недостатки стандарта (в особенности полное отсутствие средств обеспечения безопасности). Но сети быстро росли, и ограничения начали всерьез сдерживать технологию в целом.
Для решения проблемы было предложено несколько "фирменных" методов маркировки фреймов (например ISL, VLT), однако на сегодня имеет смысл говорить только о стандарте 802.1q. Его смысл достаточно прост - в заголовок добавляется 4 байта, в которых содержится информация о номере виртуальной сети (vlan), и информация о приоритете.
Таким образом, заголовок приобретает следующий вид:
| Preamble Преамбула |
SFD | DA Адрес назначения | SA Адрес Источника | Ether Type |
Метка | Type/Length Тип/Длина |
Data Данные |
FCS Контр. сумма |
| 7 байт | 1 байт | 6 байт | 6 байт | 2 байта | 2 байта | 2 байта | 46-1500 байт | 4 байта |
Поле EtherType, TPID (Tagged Protocol Identifier) содержит код 0x8100. Оно соответствует полю тип протокола стандартного поля кадра Ethernet и указывает на необходимость обработки кадра согласно требованиям IEEE 802.1q.
Поле "Метка" надо рассмотреть подробнее:
| Приоритет | CFI | VLAN ID |
| 3 байта | 1 байт | 12 байт |
Поле приоритета кадра - 3 бита, 1-битовое поле CFI (Canonical Format Identifier) и 12-битовое поле VID (идентификатор виртуальной сети) называются TCI (Tagged Control Information).
Такое решение позволило решить проблемы приоритезации и разделить одну сеть на множество отдельных виртуальных сетей. Т.е. основные проблемы оказались решены.
Однако, тут не обошлось и без проблем. Прежде всего, фрейм ethernet увеличил длину до 1522 октетов, и с 802.1q может корректно работать далеко не всякое старое оборудование (регулируется спецификацией 802.3ас). Да и вообще, нововведение серьезно усложнило коммутаторы - для распознавания тегов о них требуется большая мощность, и для соблюдения приоритетов - несколько очередей в исходящих буферах. А для установки тегов приоритета более того. Способность анализировать более высокие протоколы (например 4-го уровня по модели OSI), и исходя из порта назначения и настроек устанавливать тэги.
Во-вторых, внедрение дополнительных тегов не решило всех проблем Ethernet - количество VLAN ограничено 4096. С приоритетами до сих пор оборудование разных брендов обращается довольно произвольным образом...
Тем не менее, стандарт 802.1q позволил сильно усложнить структуру сетей, и добавил принципиальные возможности. Сейчас без него просто невозможно представить сколь-нибудь большую сеть.
Глава 9 | «« Назад | Оглавление | Вперед »»
Канальный уровень.
Канальный уровень.
Задача канального уровня - обеспечить взаимодействие устройств внутри локальной сети путем передачи специальных блоков данных, которые называются кадрами (frame). В процессе формирования они снабжаются служебной информацией (заголовком), необходимой для корректной доставки получателю, и, в соответствии с правилами доступа к среде передачи, отправляются на физический уровень.
При приеме данных с уровня PHY необходимо выделить кадры, предназначенные данному устройству, проверить их на отсутствие ошибок, и передать сервису или протоколу, которому они предназначались.
Нужно обратить внимание, что именно канальный уровень отправляет, принимает, и повторяет кадры в случае коллизии. Но определяет состояние разделяемой среды физический уровень. Поэтому процесс доступа (с необходимым уточнением) подробно описан в предыдущей главе.
Информационное взаимодействие на канальном уровне сетей стандарта Ethernet так же, как и на физическом, принято разделять на дополнительные подуровни, которые не были предусмотрены стандартом OSI-7.
LLC (Logical Link Control). Уровень управления логическим каналом; MAC (Media Access Control). Уровень доступа к среде.
Подуровень MAC
В идеология множественного доступа к среде Ethernet передачу данных приходится реализовать по широковещательному принципу "каждый для всех" (broadcasting). Это не может не наложить отпечаток на процесс формирования и распознавания кадров. Рассмотрим строение кадра Ethernet DIX, как наиболее часто используемого для передачи IP трафика.
Для идентификации устройств используются 6-ти байтовые MAC-адреса, которые отправитель обязательно должен указать в передаваемом кадре. Старшие три байта представляют собой идентификатор производителя оборудования (Vendor codes), младше - индивидуальный идентификатор устройства.
За уникальность последних несет ответственность производитель оборудования. С идентификаторами производителя дело обстоит сложнее. Существует специальная организация в составе IEEE, которая ведет список вендоров, выделяя каждому из них свой диапазон адресов. Кстати, занести туда свою запись стоит совсем не дорого, всего US $1250. Можно отметить, что создатели технологии Ethernet, Ксерокс и DEC, занимают первую и последнюю строчку списка соответственно.
Такой механизм существует для того, что бы физический адрес любого устройства был уникальным, и не возникло ситуации его случайного совпадения в одной локальной сети.
Нужно особо отметить, что на большинстве современных адаптеров можно программным путем установить любой адрес. Это представляет определенную угрозу работоспособности сети, и может быть причиной тяжелых "мистических" неисправностей.
MAC-адрес может быть записан в различной форме. Наиболее часто используется шестнадцатеричная, в которой пары байтов отделяются друг от друга символами "-" или ":". Например, сетевая карта Realtek, установленная в моем домашнем компьютере, имеет адрес 00:C0:DF:F7:A4:25.
МАС-адрес позволяет выполнять единичную (Unicast), групповую (Multicast) и широковещательную адресацию кадров (Broadcast).
Единичная адресация означает, что узел-источник направляет свое сообщение только одному получателю, адрес которого явно указывается.
В режиме групповой адресации кадр будет обработан теми станциями, которые имеют такой же Vendor Code, как и у отправителя. Признаком такой посылки является "1" в младшем бите старшего байта МАС-адреса (X1:XX:XX:XX:XX:XX). Такой формат достаточно удобен для "фирменного" взаимодействия устройств, но на практике используется достаточно редко.
Другое дело широковещательная посылка, в которой адрес получателя кодируется специальным значением FF-FF-FF-FF-FF-FF. Переданный пакет будет принят и обработан всеми станциями, которые находятся в локальной сети.
Таблица 9.2. Формат кадра Ethernet
|
Preamble Преамбула |
SFD | DA Адрес назначения | SA Адрес Источника |
Type/Length Тип/Длина |
Data Данные |
FCS Контрольная сумма |
| 7 байт | 1 байт | 6 байт | 6 байт | 2 байта | 46-1500 байт | 4 байта |
Преамбула (Preamble). Состоит из 8 байтов. Первые семь содержат одну и ту же циклическую последовательность битов (10101010), которая хорошо подходит для синхронизации приемопередатчиков. Последний (Start-of-frame-delimiter, SFD), 1 байт (10101011), служит меткой начала информационной части кадра. Это поле не учитывается при определении длины кадра и не рассчитывается в контрольной сумме. МАС-адрес получателя (Destination Address, DA). МАС-адрес отправителя (Source Address, SA). Первый бит всегда равен нулю. Поле длины либо тип данных (Length/Type, L/T). Два байта, которые содержат явное указание длины (в байтах) поля данных в кадре или указывают на тип данных. Ниже, в описании LLC будет показано, что возможно простое автоматическое распознавание разных типов кадров. Данные (Data). Полезная нагрузка кадра, данные верхних уровней OSI. Может иметь длину от 0 до 1500 байт. Для корректного распознавания коллизий необходим кадр не менее чем из 64 байт. Если поле данных менее 46 байт, то кадр дополняется полем заполнения (Padding). Контрольная сумма (Frame Check Sequence, FCS). 4 байта, которые содержит контрольную сумму всех информационных полей кадра. Вычисление выполняется по алгоритму CRC-32 отправителем и добавляется в кадр. После приема кадра в буфер, приемник выполняет аналогичный расчет. В случае расхождения результата вычислений, предполагается ошибка при передаче, и кадр уничтожается.
Кодирование битовой последовательности
Кодирование битовой последовательности
Что бы избежать в дальнейшем терминологической путаницы, нужно разделить кодирование битовой последовательности в электрический сигнал, и кодирование данных, которое преобразует одну последовательность битов в другую. Процессы эти принципиально различны по сути, но логически тесно связаны. Дело в том, что для разных способов передачи применяются разные формы представления данных.
Рассмотрим операции, которые требуются для передачи и последующего приема битовой последовательности:
синхронизация тактовой частоты передатчика и приемника; преобразование последовательности битов в электрический сигнал; уменьшение частоты спектра электрического сигнала с помощью фильтров; передача урезанного спектра по каналу связи; усиление сигнала и восстановление его формы приемником; преобразование аналогового сигнала в цифровой.
Битовый поток передается со скоростью, определяемой числом бит (дискретных изменений сигнала) в единицу времени. Тактовая частота, измеряемая в герцах, означает число синусоидальных изменений сигнала в единицу времени.
Такое очевидное соответствие часто вызывает ошибочное сопоставление скорости передачи данных и тактовой частоты. Но на практике все сложнее. Данные могут передаваться не только битами, но и их группами, иметь не два, а 3, 5, и более уровней напряжения. Или даже передаваться по нескольким парам параллельно.
Классический Ethernet, пожалуй, последняя из распространенных технологий передачи данных в которой кодирование данных не применяется. При помощи алгоритма Манчестер-2 в линию передаются битовые последовательности (прямо с МАС-уровня).
Кодирование Манчестер-2, NRZI, MLT-3.
Рисунок 9.6. Кодирование Манчестер-2, NRZI, MLT-3.
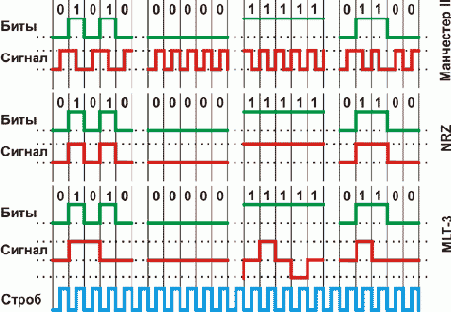
Из рисунка легко видеть, что в этом случае сигнал имеет две несущие частоты. При передаче только нулей, или только единиц - 10 МГц, и 5 МГц при чередовании нулей и единиц.
Большое достоинство этого кода - отсутствие постоянной составляющей при передаче длинной серии нулей или единиц. Изменение сигнала в центре каждого бита позволяет не принимать специальных мер для синхронизации приема-передачи.
Следующий простейший двухуровневый код - NRZ (Non Return to Zero), или "без возврата к нулю". Нулевому значению соответствует нижний уровень сигнала, единице - верхний. Переходы электрического сигнала происходят на границе битов.
Достоинство кода в его простоте. Из рисунка видно, что кодировка по сути отсутствует. Еще один плюс - даже при самой неудачной последовательности данных (чередование нулей и единиц) скорость передачи данных вдвое превышает частоту. Для других комбинаций частота будет меньше, и при одинаковых битах частота изменения сигнала равна нулю.
К недостаткам NRZ (или инвертированного NRZI) можно отнести то, что он не имеет синхронизации. Поэтому, применяют искусственные меры - например не допускают появления длинных последовательности одинаковых байтов, или используют специальный стартовый служебный бит.
Используется кодировка NRZI в основном для работы с оптоволоконной средой (PHY FX), и протоколами 100Base-FX.
Код трехуровневой передачи MLT-3 (Multi Level Transmission - 3) несколько похож на NRZ, только с тремя уровнями сигнала. Единице соответствует переход с одного уровня сигнала на другой, и изменение уровня сигнала происходит последовательно, с учетом предыдущего перехода. Максимальной частоте сигнала соответствует передача последовательности единиц, при передаче нулей сигнал не меняется. Основной недостаток кода MLT-3 такой же, как и NRZ - отсутствие синхронизации.
Применение MLT-3 - сети 100base-T на основе витой пары (PHY TX). Наличие двух методов кодирования для протоколов одной скорости вызвано отличием физических сред. Для оптоволокна технически невозможно использовать кодирование, отличное от двухуровневого, но оно имеет достаточно широкую полосу пропускания. С другой стороны, витая пара очень критична к полосе пропускания, и трехуровневое (или пятиуровневое для 1000base-T) кодирование позволяет значительно снизить частоту несущей.
На рисунке 9.7. электрические сигналы изображены в виде прямоугольников. Но в реальности формировать такую их форму очень сложно, и применяются гармонические (синусоидальные) колебания. Если говорить точнее, то используется сумма основной составляющей (несущей частоты), и высших гармоник, задающих форму импульсов. Совокупность нескольких таких колебаний называется спектр.
Коммутируемый Ethernet.
Коммутируемый Ethernet.
Принципиально меняет ситуацию использование коммутируемого Ethernet. В нем используются специальные устройства - коммутаторы (свитчи), которые, на основании адресов узлов сети могут устанавливать независимые друг от друга соединения между пользователями.
В этом случае каждое устройство может принимать и передавать данные независимо друг от друга. Соответственно, механизм доступа к среде сильно упрощается. Понятие коллизий отсутствует, нет ограничения на расстояние передачи, нет деградации производительности. Именно это позволяет использовать Ethernet в операторских решениях, на равных конкурируя с намного более сложными и дорогостоящими технологиями детерминированного доступа к среде.
При работе в полнодуплексном режиме компьютер может в любой момент отправлять кадры в коммутатор, так как если бы он был один (не принимая во внимание другие компьютеры). В реальности часто встречается ситуация, когда несколько компьютеров отправляют кадры одному, и их поток превышает возможности передачи. Порт коммутатора неизбежно столкнется с перегрузками.
Если это будет происходить недолго, поможет буфер входного порта. Но для работы при долговременной перегрузке необходимо предусмотреть механизм управления потоком кадров. Для этого коммутатор может использовать кадры "паузы" технологии Advanced Flow Control, описанной в стандарте IEEE 802.3х.
К сожалению, эта удобная технология не приемлема при работе в полудуплексном режиме, с сетевыми адаптерами не поддерживающими 802.3х. В этом случае для управления потоком кадров коммутатор может использовать два метода, основанных на нарушении некоторых правил доступа к среде передачи данных.
Для Fast Ethernet используется метод обратного давления (backpressure). При этом коммутатор для "подавления" активности какого-либо устройства искусственно генерирует коллизии на этот порт, посылая ему jam-последовательности.
Второй метод (на сегодня неактуальный), применяемый для Ethernet (10 Мб), основан на агрессивном поведении коммутатора. В этом случае порт использует межкадровый интервал в 9,1 мкс, вместо 9,6 мкс, положенных по стандарту. Как следствие, порт коммутатора монопольно захватывает шину, направляя сетевому адаптеру только свои кадры и разгружая свой внутренний буфер. Похожий способ используется для захвата шины после коллизии, когда он выдерживает интервал отсрочки, равный 50 мкс вместо положенных 51,2 мкс.
Логика передачи пакетов на сетевом уровне
Логика передачи пакетов на сетевом уровне
Как было описано выше, взаимодействие на канальном уровне ограничивается локальной сетью, и механизм передачи кадров между разными сетями отсутствует (без их фактического объединения). Поэтому реально кадры Ethernet передают не данные, а дейтаграммы сетевого уровня, которые занимают место данных.
Устройства, способные выделять IP дейтаграммы из кадров, определять их маршрут назначения, и упаковывать дейтаграммы опять в кадры канального уровня (обычно, уже другой сети), называются маршрутизаторами (router). Таким образом, упрощенно можно представить Интернет как совокупность сетей разного типа, объединенных посредством маршрутизаторов.
Для определения маршрута следования дейтаграммы, используются специальные таблицы маршрутизации, которые могут быть задана администратором (статически), или определена маршрутизатором при помощи специальных (и достаточно сложных) протоколов взаимодействия (динамически).
При этом для каждой сети, или группы сетей задаются правила (адреса маршрутизатора), в соответствии с которыми должны быть переданы дейтаграммы для достижения узла назначения. Причем в качестве правил могут быть указаны только адреса, до которых может быть проведена непосредственная доставка (next hop routing). Таким образом, на каждом маршрутизаторе задаются только адреса сетей, с которыми он имеет прямую связь, а не полную информацию о маршруте.
Более того, нет необходимости одного "сквозного" протокола для всего пути дейтаграммы. Для ее передачи между компьютерами, которые подключены к разным локальным сетям (подсетям), нужно провести следующие действия.
Отправитель посылает кадр, включающий IP дейтаграмму с адресом получателя, устройству, определенному как шлюз локальной сети (маршрутизатор). Для получения кадра шлюз должен быть подключен к той же локальной сети, что и отправитель; Маршрутизатор получает кадр, извлекает из него IP-дейтаграмму. По адресу назначения, в соответствии с таблицей маршрутизации, формирует кадр канального уровня, и направляет его в соответствующую подсеть следующему шлюзу согласно таблице маршрутизации. Операция повторяется до тех пор, пока IP-дейтаграмма не достигнет маршрутизатора, подключенного к той же подсети, что и получатель. В этом случае кадр будет оправлен непосредственно получателю.
Исходя из такого способа доставки сообщений, удобно, что бы каждый из узлов имел уникальный сетевой адрес, состоящий из двух частей - адреса сети (Net ID) и адреса узла (Host ID). Для установки соответствия между адресами канального и сетевого уровня используется специальный протокол разрешения адресов (Address Resolution Protocol, ARP). При составлении и модификацией таблиц маршрутизации используются RIP (Routing Internet Protocol) и OSPF (Open Shortest Path First), а также протокол межсетевых управляющих сообщений ICMP (Internet Control Message Protocol).
Модели коммуникации.
Модели коммуникации.
Из давнего 1984 года дошла до настоящего времени семиуровневая эталонная модель коммуникации OSI (Open System Interconnection, Взаимодействия Открытых Систем). Предложена она была Международной организацией по стандартизации (ISO) для упрощения взаимодействия соединений между большим числом сетей разного типа. Основная идея - каждый уровень предполагает, что напрямую взаимодействует с подобным уровнем другого устройства, хотя на самом деле может соединяться только с соседними уровнями своего узла.
Такой подход должен был привести к открытой и независимой от поставщиков базовой сетевой технологии (согласованного набора протоколов и реализующих их программно-аппаратных средств, достаточных для построения вычислительной сети).
С методологической же точки зрения, модель OSI служит основой для описания сетевой стратегии, разделяя для этого задачу на семь относительно автономных уровней, и определяя их функции и правила взаимодействия.
Физический уровень (Physical). Определяет такие характеристики, как уровень напряжения, синхронизацию изменений напряжения, скорость передачи физической информации и другие характеристики физических сред передачи данных, и параметров электрических сигналов. Как основная величина используется бит (bit). Канальный уровень (Data link). Обеспечивает безошибочную передачу данных через физический канал. Он оперирует блоками данных, которые называются кадрами (frame). В протоколах канального уровня заложена определенная процедура доступа к среде, и способы адресации кадров. Сетевой уровень (Network). Обеспечивает работу в сети с произвольной топологией, при этом он не берет на себя никаких обязательств по надежности передачи данных. В качестве объекта передачи используется дейтаграмма. Транспортный уровень (Transport). Описывает протокол передачи данных с требуемым уровнем надежности (transport protocol). Например, он должен обладать необходимыми средствами для нумерации, установления соединения, упорядочивания пакетов. Сеансовый уровень (Session). Содержит средства управления диалогом двух или нескольких узлов (session protocol). Предоставляет средства синхронизации в рамках процедуры обмена сообщениями. Уровень представления (Presentation). Используется для работы с внешним представлением данных, выполнения преобразования между различными их видами (presentation protocol). Как пример, можно привести операции, компрессии или шифрования. Прикладной уровень (Application). Определяет сетевые сервисы, используемые конечными пользователями и приложениями (Application protocol). Как пример, можно привести передачу файлов, подключение удаленных дисков, управление удаленным сервером.
С точки зрения практического применения, для организации межсетевого взаимодействия необходимы только процессы, соответствующие первым трем уровням эталонной модели OSI (физического, канального и сетевого). Именно они связаны с сетевым оборудованием - адаптерами, хабами, мостами, коммутаторами, маршрутизаторами. Функции более высокого уровня реализуются операционными системами и приложениями конечных узлов. Особо можно выделить транспортный уровень, который играет роль посредника между этими двумя группами протоколов.
Однако, для описания локальных сетей оказалась более удобной четырехуровневая модель TCP/IP. Transmission Control Protocol/Internet Protocol (TCP/IP) - это стандарт стека протоколов, разработанный более 20 лет назад по инициативе Министерства обороны США для связи нескольких сетей между собой. Существуют они в виде спецификаций RFC (Request for Comment) - последовательной серии документов, описывающих функционирование сети Internet.
Уровень IV. Соответствует физическому и канальному уровням модели OSI, и определяет метод инкапсуляции пакетов IP в кадры сетевой технологии. Не регламентируется, но поддерживает Ethernet и большинство известных стандартов (PPP, Frame Relay, X.25, и др.). Уровень III, межсетевого взаимодействия, по значению соостветствующий сетевому уровню модели OSI. В качестве основного используется дейтаграмный (без гарантии доставки) протокол IP, изначально предназначенный для передачи информации в глобальной сети. Так же применяются протоколы сбора маршрутной информации RIP (Routing Internet Protocol), и OSPF (Open Shortest Path First), а также протокол межсетевых управляющих сообщений ICMP (Internet Control Message Protocol). Уровень II. Носит название основного, и соответствует транспортному и сеансовому уровню модели OSI. Определяет функционирование протокола управления передачей TCP, и протокола дейтаграмм пользователя UDP (User Datagram Protocol). TCP образует виртуальное соединение (сессию) между прикладными процессами, и обеспечивает надежную передачу сообщений. Протокол UDP обеспечивает передачу пакетов дейтаграммным способом, и выполняет только функции связующего звена между III и I уровнями. Уровень I, или прикладной. К этим протоколам и сервисам относятся такие широко используемые, как FTP (копирования файлов), эмуляции терминала telnet, почтовый SMTP, гипертекстовые сервисы доступа WWW и многие другие.
Связь между моделью OSI и стеком TCP/IP можно показать следующим образом.
Таб. 9.1. Связь между моделью OSI и стеком TCP/IP
|
Модель OSI |
Протоколы информационного обмена |
Стек TCP/IP |
| 7 | HTTP, SNMP, FTP, Telnet, SSH, и много других | I |
| 6 | ||
| 5 | TCP, UDP, DNS, NetBios | II |
| 4 | ||
| 3 | IP, ARP(RARP), ICMP, RIP, DHCP | III |
| 2 |
Ethernet, ATM, Frame Relay, SDH (Для стека TCP/IP не регламентируется) |
IV |
| 1 |
Глава 9 | «« Назад | Оглавление | Вперед »»
Мультипротокольная коммутация меток (протокол MPLS)
Мультипротокольная коммутация меток (протокол MPLS)
Одно из узких мест IP связано с низкой скоростью маршрутизации данных. Действительно, пограничные рутеры должны прочитывать все заголовки IP-кадров что бы перепрвить их на нужный интерфейс. Конечно, есть много фирменных технологий, ускоряющих процесс... Однако методов, позволяющих ускорить маршрутизацию всей сети сразу не так и много. Наиболее популярным последнее время стал MPLS (разработка Cisco).
Принципиальной основой MPLS являются IP-туннели. Для его работы нужна поддержка протокола маршрутизации MP-BGP. Протокол MPLS может работать практически для любого маршрутизируемого транспортного протокола (не только IP).
При появлении пакета в виртуальной сети ему присваивается метка, которая не позволяет ему покинуть пределы данной виртуальной сети. Протокол MPLS предоставляет возможность обеспечения значения QoS, гарантирующего более высокую безопасность.
Для обеспечения структурирования потоков в пакете создается стек меток, каждая из которых имеет свою зону действия. Формат стека меток представлен на Рисунок 3 (смотри RFC-3032). В норме стек меток размещается между заголовками сетевого и канального уровней (соответственно L2 и L3). Каждая запись в стеке занимает 4 октета.
| MAC-заголовок | Стек меток MPLS | IP-заголовок |
Место заголовка МАС может занимать заголовок РРР. В случае работы с сетями АТМ метка может занимать поля VPI и VCI.
В свою очередь, стек MPLS выглядит следующим образом:
CoS
| Метка | S | TTL | Стек | |
| 20 бит | 3 бита | 1 бит | 8 бит | - |
Полю СoS соответствует приоритет поля ToS. Поле CoS имеет три бита, что достаточно для поля приоритета IP-заголовка. S - флаг-указатель дна стека меток; TTL - время жизни пакета MPLS.
MPLS представляет собой интеграцию технологий уровней L2 и L3. Управление коммутацией по меткам основывается на базе данных LIB (Label Information Base). Пограничный маршрутизатор MPLS LER (Label Edge Router) удаляет метки из пакетов, когда пакет покидает облако MPLS, у вводит их во входящие пакеты.
Управление трафиком MPLS автоматически устанавливает и поддерживает туннель через опорную сеть. Путь туннеля вычисляется, основываясь на сформулированных требованиях и имеющихся ресурсах (constraint-based routing). IGP автоматически маршрутизирует трафик через эти туннели. Обычно, пакет, проходящий через опорную сеть MPLS движется по одному туннелю от его входной точки к выходной.
Глава 9 | «« Назад | Оглавление | Вперед »»
Независимый от среды интерфейс (MII) и подуровень согласования (Reconciliation)
Независимый от среды интерфейс (MII) и подуровень согласования (Reconciliation)
Во времена использования 10base5 для доступа к конкретной среде передачи данных применялось отдельное устройство (трансивер), которое было логически связанно с сетевым адаптером или повторителем специальным кабелем снижения (до 50 метров длиной, амплитуда сигнала 12 вольт, 15 контактов в разъеме). При этом на логическом уровне использовался независимый от конечной среды передачи интерфейс AUI (Attachment Unit Interface, интерфейс подключения устройства). Кодирование данных не производилось вообще, а кодирования битовой последовательности в электрический сигнал происходило в сетевом адаптере.
Введение стандарта Fast Ethernet (802.3u) потребовало новой, более скоростной и удобной связи MAC и PHY уровней. Для этого используется независимый от среды интерфейс (MII), имеющий, в случае внешнего исполнения, большой по размеру разъем с 40 контактами, длину кабеля не более 1 метра, и амплитуду сигналов в 5 вольт.
Но обычно на практике шина MII интегрирована в одной микросхеме с другими логическими элементами сетевого адаптера (повторителя), и имеет структуру, далекую от канонического вида.
Канал передачи данных от подуровня MAC к PHY образован 4-битной шиной данных, которая синхронизируется тактовым сигналом, генерируемым PHY, а также сигналом "Передача", исходящим от MAC-подуровня. Подобно устроен прием данных - это другая 4-битной шина, синхронизирующаяся тактовым сигналом и сигналом "Прием", которые генерируются PHY.
Обмен командами управления идет по отдельной двухпроводной шине. Подуровни могут передавать друг другу сообщения об возникших ошибках ("ошибка приема", "ошибка передачи"). Кроме этого, данные о конфигурации, состоянии порта и линии хранятся соответственно в регистрах управления (Control Register) и статуса (Status Register).
Регистр управления. Используется для установки скорости и параметров работы порта. Регистр статуса. Содержит информацию о действительном состоянии работы порта.
Кроме связи между подуровнями, в повторителе (хабе, репиторе) интерфейс MII может применяться для соединения нескольких устройств PHY.
Роль подуровня согласования (Reconciliation), несмотря на его выделение в отдельный функциональный блок, весьма прозаична. При переходе от шины AUI к MII интерфейс МАС-подуровня был сохранен. Соответственно, возникла потребность его согласования с новой шиной MII, что и было сделано с помощью этого подуровня.
Глава 9 | «« Назад | Оглавление | Вперед »»
Определение коллизий
Рисунок 9.4. Определение коллизий

Строго говоря, кадры формируются, и повторяются при коллизии на МАС-уровне. Но состояние среды определяется на физическом уровне, и именно он определяет ход процесса доступа к среде. Однако, разделять описание по разным пунктам не целесообразно.
Для передачи в Ethernet выбран минимальный размер кадра на MAC-уровне 512 бит, или 64 байта. При скорости 10 Мбит/c для передачи требуется 51,2 мкс. Самая неблагоприятная ситуация возникнет, когда узел сети "Б" начнет передачу перед самым приходом пакета от узла "А", начавшего передачу ранее. В этом случае сигнал "Б" должен достигнуть узла "А", раньше, чем он закончит передачу.
Нужно специально отметить, что в описании процесса распознавания коллизий часто используется термин "столкновения" пакетов, с последующим его распознаванием передатчиком. Это совершенно не верно отражает происходящие физические процессы, но, вероятно, повышает наглядность объяснения.
Скорость распространения электромагнитного или оптического сигнала в среде передачи составляет около 2/3 от скорости света в вакууме (3х108 м/c), или 200 м/мкс. Несложно подсчитать, что за 51,2 мкс сигнал успеет пройти почти 12 километров. Соответственно, расстояние между узлами может составлять до 6 километров, если не происходит задержек по другим причинам. В реальности это неизбежно происходит в тракте сетевого адаптера и на повторителях (хабах).
Сложно сказать, что учитывали разработчики при выработке стандартов на 10Base5, но в нем максимальное расстояние между узлами составляет 2500 м. Далее, в 10baseT, оно еще уменьшилось до 500 за счет сохранения прежнего количества повторителей - но без какого-либо технического обоснования. В Fast Ethernet (100 Мбит) кадр передается в канал всего за 5 мкс, поэтому ограничения на расстояния намного более жесткие.
Подуровень LLC
Подуровень LLC
Данный подуровень обеспечивает единый, независимый от используемого метода доступа, интерфейс с верхним (сетевым) уровнем. По сути, можно сказать, что на нем определяется логическая структура заголовка кадра Ethernet.
Как ни странно, единый стандарт не определен до сих пор. Так как особых технических трудностей при определении типов кадров устройствами не оказалось, на практике могут параллельно использоваться четыре модификаций:
802.3/LLC (или кадр Novell 802.2) Raw 802.3 (или кадр Novell 802.3) Ethernet DIX (или кадр Ethernet II) Ethernet SNAP
Причина вполне обычна. Технология Ethernet начала свое развитие задолго до принятия стандартов IEEE 802. Первоначально подуровень LLC не выделялся из общего протокола и, соответственно, в специальном заголовке не было нужды. После принятия стандартов IEEE, и появления двух отличных друг от друга форматов кадров канального уровня, понадобился механизм согласования. Попытка введения нового, "объединяющего" варианта заголовка, привела к возникновению очередного формата кадра.
Что бы не слишком запутаться в частных (и не слишком важных) отличиях, рассмотрим только наиболее широко распространенный в локальных сетях кадр Ethernet DIX (Ethernet II), структура которого уже была рассмотрена в описании подуровня МАС.
Как наиболее важный момент, необходимо отметить смысл поля Length/Type (длина/типа данных). 2-байтовое поле Length (Длина) кадра Raw 802.3, в кадре Ethernet DIX используется в качестве поля типа протокола (Type), и явно указывает на тип протокола верхнего уровня, вложившего свой пакет в поле данных кадра. Если подходить строго, то видно, что к Ethernet DIX название Length (Длина) не имеет отношения. Но терминология устоялась, и проще пойти на неоднозначную формулировку, чем ее ломать.
Автоматическое распознавание типов кадров Ethernet выполняется достаточно просто, и поддерживается подавляющим большинством сетевых устройств. Так, для отличия Ethernet DIX от Raw 802.3 в поле Type указываются значения, превышающие значение максимальной длины поля данных (1500 байт). Например, для IP используется код 0800, для IPX - 8037, Х.25 - 0805, и т.п.
Так же, в случае наличия полей LLC, несложно отличить кадр Ethernet SNAP от 802.3/LLC. Но эти форматы не используются в 10/100baseT, и подробно останавливаться на них в рамках данного изложения не имеет смысла.
Принцип установления связи в сети Ethernet.
Рисунок 9.2. Принцип установления связи в сети Ethernet.

Принцип работы на первый взгляд достаточно прост. Нужно сначала убедиться, что канал свободен, и установить связь. В случае, если среда занята - подождать, когда она освободится. Если в течение заданного промежутка среда не освобождается - сформировать сигнал ошибки.
В сетях Ethernet признаком свободной среды является "отсутствие несущей" (10 МГц). Наоборот, в стандарте Fast Ethernet признаком свободного состояния шины является передача по ней специального Idle-символа (11111) соответствующего избыточного кода, который поддерживает синхронизм и проверяет целостность сети.
Что бы одно устройство не смогло монопольно использовать канал, используют простой механизм. После передачи каждого кадра делаются специальные перерывы в передаче, которые называются межкадровыми интервалами (Inter Packet Gap, IPG). Его длительность для Ethernet (10 Мбит) составляет 9,6 мкс, а для Fast Ethernet в 10 раз меньше, 0,96 мкс.
Значительно более сложной проблемой являются коллизии, или ситуации одновременной параллельной передачи двумя (или более) устройствами. Происходит это из-за того, что сигнал проходит между узлами не мгновенно. И за время его распространения другие сетевые устройства вполне могут начать передачу. При этом происходит "столкновение", в котором искажаются оба пакета. Такая ситуация вполне штатная, и даже неизбежная в некоммутируемом Ethernet.
Присоединение к физической среде (PMA).
Присоединение к физической среде (PMA).
Этот подуровень наиболее важный для понимания взаимодействия устройств на физическом уровне. Пожалуй, не будет преувеличением сказать, что именно в нем заключается ключ технологии Ethernet, все его главные отличия от других способов передачи данных. Соответственно, без понимания этих процессов невозможно использовать все возможности Ethernet, особенно при работе за пределами стандартов, присущей многим домашним (территориальным) сетям. И так как данная книга посвящена именно им, то на эту главу придется очень часто ссылаться.
Доступ к среде передачи
Пожалуй, можно сказать, что основное назначение устройства физического уровня - доступ к среде. Как уже говорилось в второй главе, в Ethernet используется CSMA/CD (carrier-sense multiple access/collision detection) - множественный доступ с контролем несущей / обнаружением коллизий. Физическая среда делится между всеми устройствами, и одновременно передавать сообщение может только одно из них.
Пропускная способность Ethernet
Рисунок 9.5. Пропускная способность Ethernet
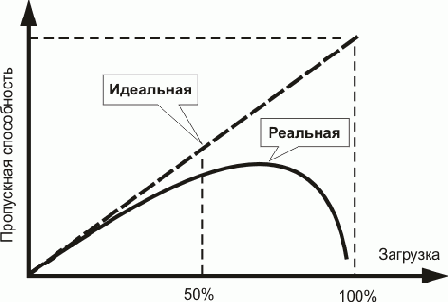
Легко видеть, что в случае большой загруженности сети вероятность возникновения коллизий резко возрастает, и пропускная способность сети уменьшается из-за многочисленных попыток передачи одних и тех же кадров. Для описания этого явления даже вводят специальный термин - деградация производительности.
Ну, а практической рекомендацией будет простой. Не использовать некоммутируемый Ethernet при загрузке более 30-40%.
Глава 9 | «« Назад | Оглавление | Вперед »»
Протокол адресации (IP)
Протокол адресации (IP)
Основными функциями протокола IP можно назвать разделение данных (передаваемых протоколами более высокого уровня) на дейтаграммы для их доставки получателю в другой сети, и сборку блоков данных из дейтаграмм при их получении от других узлов сети. Для этого к данным присоединяется специальный заголовок унифицированного формата, который для используемой в настоящее время четвертой версии IP может иметь длину до 20 байт (пять 32-х битовых слов).
Таб. 9.3. Формат дейтаграммы IP
| Версия | Длина | Тип сервиса | Общий размер |
| Идентификация | Флаги | Смещение фрагмента | |
| Время жизни | Протокол | Контрольная сумма заголовка | |
| Адрес отправителя | |||
| Адрес получателя | |||
| Опции и заполнение | |||
| Данные |
Заголовок дейтаграммы IP имеет следующие поля:
Номер версии (Vers) протокола IP. Длина заголовка (Hlen), измеренная в 32-битовых словах. Как правило, заголовок составляет 20 байт (пять 32-битовых слов). Но в теории, он может быть увеличен за счет использования поля Резерва (IP OPTIONS). Тип сервиса (Servise type) задает приоритетность дейтаграммы, и критерий выбора способа доставки. Маршрутизаторы могут использовать это поле (вернее, его первые три бита) для установления очередности обработки сообщений. Для обычного пакета данных значение поля устанавливается равным "0", а для управляющей информации (максимальный приоритет) - "7". Следующие три бита определяют способ доставки. Так, значение "D" (delay) предписывает использовать путь с минимальной задержкой доставки, "T" - для достижения максимальной пропускной способности, "R" - с использованием пути, имеющего максимальную надежность доставки. Общая длина (Total length) с учетом заголовка и поля данных. Надо заметить, что максимальный размер дейтаграммы IP определяется для каждого типа сетей по максимальной единице транспортировки (Maximum Transfer Unit, MTU). Для сети Ethernet она имеет значение, равное 1500 байт, а сеть Х.25 используют MTU в 128 байт. Идентификатор (Identification) используется для определения дейтаграмм, до фрагментации являющихся частями одного блока данных. Флаги (Flags) позволяют управлять фрагментацией данных. Так, установленный бит DF (Do not Fragment) запрещает маршрутизатору разделять данную дейтаграмму, а бит MF (More Fragments) - признак того, что дейтаграмма содержит промежуточный фрагмент. Смещение фрагмента (Fragment offset) используется сборке/разборке частей пакетов при передачах их между сетями с различными величинами максимальной длины дейтаграммы. Для этого указывается в байтах смешение начала фрагмента, вошедшего в дейтаграмму, от начала общего блока данных, подвергнутого фрагментации. Время жизни (Time to live) определяет предельный срок, в течение которого дейтаграмма может перемещаться по сети. При значении этого поля, равном "0", дейтаграмма уничтожается. Время измеряется в секундах, и вычитается на транзитных узлах при передаче (единица вычитается даже в том случае, если передача заняла меньшее время). При современных скоростях передачи, можно считать, что время жизни задается числом транзитных узлов. Идентификатор протокола верхнего уровня (Protocol) указывает на протокол верхнего уровня, которому принадлежит дейтаграмма. Контрольная сумма (Header Checksum), которая рассчитывается по всему заголовку на каждой точке обработки дейтаграммы. Адрес источника (Source IP address) и Адрес назначения (Destination IP address) служат для доставки дейтаграммы, и получения ответа. Резерв (IP options) является необязательным и, как правило, используется на стадии при отладке сети.
Остановимся подробнее на IP-адресах, по которым происходит доставка дейтаграмм. На практике существует достаточно сложный механизм, позволяющий эффективно организовывать этот процесс.
IP-адрес состоит из 4 байт (одно 32-битное слово), которое принято записывать в десятичном виде. Например, 192.168.0.2 - адрес одного из сетевых адаптеров моего компьютера в маленькой изолированной "квартирной" сети. Если записать этот же адрес в двоичном виде, получится 11000000-10101000-00000000-00000010. Биты, входящие в адрес, часто называют октетами.
Как уже говорилось выше, IP-адрес состоит из двух частей: номера сети и номера узла. Если устройство является частью сети Интерент, то адрес сети назначается согласно рекомендациям одного из подразделений Сетевого Информационного Центра (Network Information Center, NIC). Для независимой (закрытой) сети администратор может назначить адреса самостоятельно.
На практике сложилось, что Интернет-провайдеры сначала получают диапазоны адресов (подсети) в NIC для себя, а далее предоставляют их своим клиентам на тех, или иных условиях.
Особо надо отметить, что не только каждый узел сети может иметь несколько адресов. Одному сетевому адаптеру (интерфейсу) могут быть назначены различные адреса, или, наоборот, нескольким интерфейсам - один адрес. Система управления достаточно гибкая, описать все ее возможности сложно.
В начале развития сети Интеренет для удобства управления адресным пространством введено деление сетей на классы "Классовая модель", но впоследствии была повсеместно принята "Безклассовая модель" (CIDR).
Рассмотрим классовую модель. В ней граница между сетевой частью IP-адреса, и части, предназначенной для идентификации хостов, всегда проходит по границе октета. Т.е. возможно четыре и только четыре типа сети.
Таб. 9.4. Деление IP сетей на классы
| Класс | Диапазон значений первого октета | Значения адреса в десятичной записи | Возможное кол-во сетей |
Возможное кол-во узлов |
| A | от 00000001-… до 01111110-… |
от 1.ххх.xxx.xxx до 126.ххх.ххх.ххх |
126 | 16777214 |
| B | от 1000000-00000000-… до 1011111-11111111-… |
от 128.0.ххх.ххх до 191.255.ххх.ххх |
16382 | 65534 |
| C | от 1100000-00000000-00000000… до 1101111-11111111-11111111… |
от 192.0.0.ххх до 223.255.255.ххх |
2097150 | 254 |
| D | от 1110000-… до 1110111-… |
от 224.ххх.ххх.ххх до 239.ххх.ххх.ххх |
- | 268435456 |
| E | от 1111000-… до 1111111-… |
от 240.ххх.ххх.ххх до 255.ххх.ххх.ххх |
- | 134217728 |
Понятно, что адреса класса A предназначены для использования в очень больших сетях общего пользования (например, национальных). Класс B может найти применение в сетях крупных провайдеров или компаний (при американском толковании масштабов). Небольшим провайдерам, или сетям, приходится иметь дело в основном с сетями класса C, которые позволяют адресовать 254 узла. Адреса класса D используются при обращениях к группам машин, а адреса класса E зарезервированы для использования в эксперементальных целях.
В любой сети первый (вернее, нулевой) адрес является номером всей сети и не может быть присвоен никому конкретно. Адрес, являющийся последним в сети, предназначен для широковещательных (broadcasting) сообщений, которые доставляются всем узлам данной сети. Соответственно, эти два адреса недоступны для узлов. Именно поэтому, в сети класса С можно адресовать не 256, а только 254 узла.
Кроме этого, зарезервировано несколько групп адресов специального назначения. Так, сеть класса A с номером 127 (loopback), предназначена для общения компьютера с собой. При посылке данных на этот адрес, они не передаются по сети, а возвращаются протоколам верхнего уровня. Поэтому, узлам запрещено присваивать адреса этой сети, и считается, что она не входит в адресное пространство Интернет.
Аналогично, адрес вида 0.0.0.0 считается локальным адресом данного узла, и из диапазона доступных сетей исключен соответствующий блок.
Есть еще одно важное соглашение (RFC 1918) о сетях, которые считаются "частными", т.е. не маршрутизируемыми в сети Интернет. Это блоки адресов от 10.0.0.0 - 10.255.255.255 (сеть класса А), 172.16.0.0-172.31.255.255 (16 сетей класса В), 192.168.0.0-192.168.255.255 (255 сетей класса С). Такие адреса часто используются для маскарадинга, транзитных, или изолированных сетей. В этом случае даже ошибки в маршрутизации не вызовут сбоев в работе других узлов Интернет.
Как ни велико адресное пространство, при таком простом способе адресации оно не может быть использовано эффективно. Тяжело представить физическую сеть, в которой количество узлов будет достаточным для IP-сети класса А. С другой стороны, невозможно использовать только небольшие сети. Каждая сеть, так или иначе, создает особое правило на транзитных маршрутизаторах. И большое количество сетей вызовет их неоправданную загрузку (или вообще, неработоспособность).
В классовой модели старшие биты IP-адреса определяли принадлежность узла к конкретному классу, и соответственно по нему маршрутизаторы определяли размер сети. Для претворения в жизнь технически привлекательного принципа произвольного разделения адресного пространства пришлось ввести 32-битовую маску (netmask) или маску подсети (subnet mask).
Сетевая маска действует по следующему простому принципу:
в позициях, соответствующих номеру сети, биты установлены в 1;
в позициях, соответствующих номеру хоста, биты сброшены в 0.
Таким образом, был разработана "безклассовая модель" адресации (CIDR, Classless Internet Direct Routing, прямая бесклассовая маршрутизация). В ней отсутствуют технические причины разделения сеть-хост в IP-адресе точно по границе октета. И вдобавок, схема может быть иерархической. При этом крупные магистральные маршрутизаторы обрабатывают проходящий трафик в соответствии с правилами для полных сетей, даже не подозревая о том, что они где-то разделены на подсети. Таким образом, нагрузка "перекладывается" на периферийные маршрутизаторы.
Рассмотрим этот вопрос на наиболее распространенном случае разделения сети класса С, например 192.168.25.0 с маской 255.255.255.0 (11111111. 11111111. 11111111.00000000), или, в компактной форме записи, 192.168.25.0/24 (24-количество значащих разрядов маски).
Таб. 9.5. Возможные варианты разделения сети класса С на подсети.
| Запись маски | Последний октет маски | Количество подсетей | Количество адресов в подсети | Количество значащих разрядов |
| 255.255.255.252 | 11111100 | 64 | 4 | 30 |
| 255.255.255.248 | 11111000 | 32 | 8 | 29 |
| 255.255.255.240 | 11110000 | 16 | 16 | 28 |
| 255.255.255.224 | 11100000 | 8 | 32 | 27 |
| 255.255.255.192 | 11000000 | 4 | 64 | 26 |
| 255.255.255.128 | 10000000 | 2 | 128 | 25 |
В остальном, нужно отметить, что возможны самые разные варианты разделения сетей. Так, например, сеть класса "С" можно представить как сумму из 2*4+1*8+1*16+3*32+2*64. Но при этом будет "потеряно" 16 адресов.
Роль подсетей нельзя недооценивать. Например, с точки зрения маршрутизатора адрес 192.168.25.149/255.255.255.128 (192.168.25.149/25) будет выглядеть как номер сети 192.168.25.128 и номер узла 21, что несколько отличается от привычной записи, и может породить серьезные проблемы.
Протокол преобразования адресов ARP (RARP)
Протокол преобразования адресов ARP (RARP)
Как уже было сказано выше, маршрутизаторы упаковывают дейтаграммы IP в кадры локальных сетей (обычно Ethernet). Для установления соответствия MAC по IP адресу они используют специальный протокол разрешения адреса (Address Resolution Protocol, ARP). Соответственно, для решения обратной задачи (установления IP по известному MAC-адресу) используется реверсивный протокол разрешения адреса (Reverse Address Resolution Protocol, RARP). Классический случай применения RARP - старт рабочей станции, у которой IP-адрес не установлен в явном виде.
Алгоритм работы протокола следующий:
Маршрутизатор, которому необходимо доставить дейтаграмму IP-адреса узлу в локальной сети, формирует ARP-запрос, и вкладывает его в кадр широковещательной рассылки. Все узлы локальной сети получают кадр с ARP-запросом, и сравнивают указанный там IP-адрес с собственным. При совпадении адресов, узел формирует ARP-ответ (совпадающий по формату с ARP-запросом), в котором указывает свой IP-адрес и МАС-адрес, и отправляет его маршрутизатору. После получения кадра маршрутизатор отправляет по MAC-адресу IP-дейтаграмму адресату.
Работа протокола занимает вполне определенное, и часто не малое время, за которое дейтаграмма может быть потеряна (превысит время хранения в кэше сетевого адаптера). Поэтому, маршрутизаторы и рабочие станции с сети хранят таблицу соответствия (ARP-таблицу), по которой отправка производится без посылки ARP-запроса.
Кроме IP и МАС-адреса, в таблице хранится возраст записи, что позволяет ее обновлять по определенным условиям. Далее, нужно особо отметить, что во многих операционных системах таблица может быть сформирована вручную администратором сети. Такая возможность часто используется для установления жесткого соответствия MAC и IP адреса узла для ограничения несанкционированного доступа к различным ресурсам.
Таб. 9.6. Формат пакета протокола ARP/RARP в Ethernet
| Тип оборудования (для Ethernet - 1) | Тип протокола (для IP-0800) | |
| Длина МАС-адреса | Длина IP-адреса | Операция. 1-ARP (запрос), 2-ARP (ответ), 3-RARP (запрос), 4-RARP (ответ) |
| Аппаратный адрес (для Ethernet МАС) отправителя (байты 9-14) | ||
| IP-адрес отправителя (байты 15-18) | ||
| Аппаратный адрес (для Ethernet МАС) получателя (байты 19-24) | ||
| IP-адрес получателя (байты 25-28) |
В общем случае, форматы локальных адресов различны для разных видов протоколов. Поэтому красивую таблицу с определенными заранее полями составить сложно. Так как длина МАС-адреса в Ethernet составляет 6 байт, а IP - 4 байта, получается, что запрос занимает 28 байт.
Распознавание коллизий
Распознавание коллизий
Для распознавания коллизий каждое устройство прослушивает сеть во время, и после передачи кадра. Если получаемый сигнал отличается от передаваемого, то станция определяет эту ситуацию как коллизию. В сетях Fast Ethernet, станция, обнаружившая коллизию, не только прекращает передачу, но и посылает в сеть специальный 32-битный сигнал, называемый jam-последовательностью. Его назначение - сообщить всем узлам сети о наличии коллизии.
В любом случае, после обнаружения коллизии, передача должна быть повторена по достаточно сложному алгоритму отката, показанном на следующем рисунке:
Реализация повторения передачи (отката) при коллизии в сетях Ethernet.
Рисунок 9.3. Реализация повторения передачи (отката) при коллизии в сетях Ethernet.

Ключевым моментом является выбор задержки (T) передачи перед повтором, которая равна случайно выбранному из заданного диапазона количеству интервалов (N) времени (t). Иначе говоря, Т = N*t, где t = 51,2 мкс. Всего предпринимается 16 попыток передать кадр. В случае невозможности это сделать формируется сообщение об ошибке.
Очевидно, что для переповтора кадра при коллизии, устройство должно ее обнаруживать. Если передающие узлы будут находиться на большом расстоянии друг от друга, то может случиться, что передача одного из них закончится раньше, чем будет распознана коллизия.
Так как для кадров Ethernet на канальном уровне подтверждение доставки не предусмотрено, то пакет будет просто потерян. Повторить передачу может только протокол более высокого (не ниже транспортного) уровня. Но это уже займет значительно больше времени (в сотни раз).
Можно видеть, что необходимость корректного обнаружения коллизий накладывает ограничение на минимальный размер пакета и расстояние между узлами сети.
Реальный вид сигнала при использовании протокола 100baseT (MLT-3).
Рисунок 9.7. Реальный вид сигнала при использовании протокола 100baseT (MLT-3).

В теории, цифровой метод передачи позволяет восстановить исходный сигнал только несущей спектра. Но в реальности удовлетворительной помехоустойчивости удается достигнуть только с использованием первой гармоники. Это удваивает ширину спектра, необходимого для передачи сигналов.
Так, из рисунка 9.7. можно видеть, что для передачи 100 Мбит информации с использованием метода кодирования MLT-3, необходима несущая, частотой 25 Мгц. С учетом первой гармоники, требования повышаются до 50 МГц. А с учетом избыточного кодирования 4B/5B, необходимо уже 62,5 МГц.
Аналогично, для передачи 10 Мбит с кодировкой Манчестер-2, требуется полоса пропускания в 20 Мгц. Эта величина окончательная, так как в этом случае избыточное кодирование не применяется.
Сетевой уровень.
Сетевой уровень.
Этот уровень первоначально использовался для образования единой транспортной системы, объединяющей несколько сетей, не зависимо от способа передачи данных. В качестве блока данных сетевого уровня используется дейтаграмма, который предназначен для доставки некоторого фрагмента передаваемого сообщения. Такой подход позволяет отделить процесс передачи данных от прикладных программ, позволяя обрабатывать сетевой трафик одинаковым способом для любых приложений.
По сети произвольной топологии дейтаграмма перемещается на основании адреса пункта назначения и адреса источника, и делает это независимо от всех остальных дейтаграмм. В качестве примера протоколов сетевого уровня можно привести X.25, IPX, и, конечно, популярнейший на сегодня Internet протокол - IP.
Кроме этого, для осуществления своих функций, сетевой уровень имеет возможности структуризации сети и согласования различных методов работы канального уровня.
Наиболее важный вопрос передачи данных, адресация, может быть решен двумя способами. Во-первых, с использованием совпадающих, во-вторых - различных сетевых и канальных адресов. Первый способ (например, протокол IPX) упрощает администрирование локальной сети. Второй обеспечивает гибкость, независимость от аппаратной части, и логическое единство адресного пространства. Эти преимущества позволили способу адресации, использующему различные сетевые и канальные адрес, получить распространение в сети Интернет (под названием Internet Protocol, IP), практически вытеснив все остальные способы передачи данных.
Все остальные протоколы (кроме ARP/RARP, который часто относят к протоколу канального уровня) используют IP для передачи данных между узлами сети.
Согласование скорости (Auto-negotiation)
Согласование скорости (Auto-negotiation)
К концу 90-х годов сложилась ситуация, при которой в одной и той же сети, по одним и тем же кабелям могло работать сразу пять протоколов - 10base-T, 10base-T full-duplex, 100base-T, 100base-T4, 100base-T full-duplex. Немного позже к ним присоединился 1000base-T. Оставить "ручное" управление таким хозяйством было бы слишком жестоко по отношению к сетевым администраторам.
Первоначально протокол автоматического согласования скорости работы под названием Nway предложила компания National Semiconductor. Немного позже, он был принят в качестве стандарта IEEE 802.3u (Auto-negotiation).
Логично предположить, что возможны два варианта - либо оба договаривающихся устройства поддерживают Auto-negotiation, либо только одно. В первом случае адаптеры (или коммутаторы) должны выбрать наиболее предпочтительный протокол из поддерживаемых (порядок см. выше). При втором варианте более умное устройство должно поддержать единственный вариант, на который способен партнер (как правило, 10Base-T).
Процесс авто-переговоров начинается при включении питания устройства, или команде управляющего устройства (если оно имеется). Для согласования используется группа импульсов, которые называются Fast Link Pulses (FLP). Оборудование, не поддерживающие Auto-negotiation, воспринимают их как служебные сигналы проверки целостности линии 10Base-T (link test pulses).
Устройство, начавшее процесс auto-negotiation, посылает своему партнеру пачку импульсов FLP, в котором содержится 8-битное слово, кодирующее предлагаемый режим взаимодействия. При этом протокол предлагается самый приоритетный из поддерживаемых.
Если подключенное к линии оборудование поддерживает Auto-negotuiation, и может работать в предложенном режиме, то оно посылает подтверждающее слово, и переговоры заканчиваются. При невозможности работы в предложенном режиме, устройство-партнер отвечает своим предложением, которое и принимается для работы.
Часто возникают проблемы, если настройки negotiation на портах устройств отличаются друг от друга. Нужно либо оба связанных порта устанавливать в режим auto, либо оба зажимать на конкретные значения.
Несколько иначе обстоит дело с оборудованием, поддерживающим только 10Base-T. Такие устройства каждые 16 миллисекунд посылают импульсы для проверки целостности линии, и не отвечают на запрос FLP. Если сетевой адаптер или коммутатор получает в ответ на свой запрос только импульсы проверки целостности линии, он прекращает согласование и устанавливает такой же режим работы.
Глава 9 | «« Назад | Оглавление | Вперед »»
Структура протокольных модулей сети, построенной на основе IP
Рисунок 9.8. Структура протокольных модулей сети, построенной на основе IP

В общем виде схема достаточно сложная (более того, спорная), ее подробное рассмотрение лежит далеко за рамками рассматриваемого в данной книге материала.
Тем не менее, в следующих главах постараемся рассмотреть основные принципы передачи данных на сетевом уровне.
Транспортный протокол TCP
Транспортный протокол TCP
Этот протокол, пожалуй, более распространен, чем все остальные, вместе взятые. Он используется для гарантированной доставки сообщений (называемых пакетами) в сетях Интернет.
Таб. 7.8. Формат пакета TCP
| Номер порта отправителя | Номер порта получателя | |||||||
| Порядковый номер | ||||||||
| Номер подтверждения | ||||||||
| Смещение | Резерв | U | A | P | R | S | F | Окно |
| Контрольная сумма | Указатель важности | |||||||
| Опции и заполнение | ||||||||
| Данные |
Заголовок пакета TCP состоит из нескольких (обычно 6) 32-х битных слов, и в этом похож на формат дейтаграммы IP. Поясним значение некоторых полей:
Порядковый номер первого октета в сегменте необходим для определения места пакета для сборки блока переданных данных после сегментации (если она была проведена перед передачей). Номер подтверждения содержит значение следующего порядкового номера, который отправитель сегмента рассчитывает получить. Смещение данных - 4-х битовое поле, указывающее число 32-х битовых слов в заголовке пакета, или начало поля данных. Резерв - зарезервированное поле размером в 6 бит. Поле флагов управления. U (URG) - значимое поле указателя важности, A (ACK) - значимое поле подтверждения, P (PSH) - функция push, R (RST) - сброс соединения, F (FIN) - нет данных от отправителя. Окно, это 16-битовое поле, которое содержит число октетов данных, которые отправитель данного сегмента будет отправлять без немедленного подтверждения доставки. Отсчет ведется, начиная с октета, указанного в поле номер подтверждения. Уровень важности - значение смещения до октета, с которого начинаются важные (urgent) данные. Разумеется, поле принимается во внимание только для пакетов с установленным флагом "U".
Различия в величине заголовка пакета TCP и дейтаграммы UDP сразу обращают на себя внимание. Объяснение кроется в сложности обеспечения гарантированной и эффективной доставки (да еще и с заданным уровнем качества). Для этого можно использовать метод квитирования с повторной передачей.
Несмотря на сложное название, его суть достаточно проста. При получении пакета узел назначения посылает отправителю специальный сигнал ACK (квитанцию). Узел, передавший пакет, в свою очередь, до получения подтверждения прекращает передачу. А в случае отсутствия "квитанции" в течение определенного времени, начинает передачу пакета заново. Несмотря на простоту, такой алгоритм имеет большой недостаток - пропускная способность сети передачи данных используется очень неэффективно. Как минимум, половину времени процессы ожидают получения подтверждения.
В связи с этим применяется более эффективный алгоритм квитирования с использованием "скользящего окна", при котором передающий узел отправляет сразу несколько пакетов, не дожидаясь получения подтверждения о приеме. Для определения максимального количества передающихся таким образом пакетов TCP применяют параметр "окно" в заголовке. Соответственно, узел, принимающий пакеты так же может обработать несколько "квитанций" за один раз.
При отсутствии ошибок и задержек передачи, получается что "окно" передаваемых пакетов непрерывно скользит вдоль входящего потока данных, эффективно загружая сеть.
От размера окна очень много зависит, но его выбор - не слишком тривиальная задача. На практике алгоритм пошел немного "от противного", не от максимальной скорости передачи. Каждое сообщение подтверждения доставки пакета содержит значение размера окна, которое может быть предоставлено принимающим узлом (window advertisement). Обычно, оно определяется размером свободного в данный момент буфера принимающего адаптера.
При этом достигается еще одна цель - становятся не нужными дополнительные механизмы, которые контролируют процесс переполнения. В каком-то плане, это можно рассматривать как довольно красивый (хотя и не полный) ответ сложным методам, применяемым для тех же целей (но на канальном уровне) в технологии АТМ.
Но для обеспечения передачи с заданным качеством одного механизма квитирования совершенно недостаточно. И существует еще достаточно широкий спектр способов повышения эффективности транспортных протоколов. Например, этому служит виртуальное логическое соединение, или TCP-сессия. Инициировать ее установление может один из узлов, а далее обе стороны контролируют качество, и при возникновении сложностей в информационном обмене, могут разорвать сессию с отправкой соответствующих сообщений протоколам более высокого уровня.
Кроме этого, может быть использован режим потокового обмена, механизм ускорения доставки трафика, чувствительного ко времени (push), и некоторые другие.
Чем более высокий уровень OSI используется, тем больше возможностей предоставляют протоколы для управления. Описать их все - большая, но отдельная задача. Поэтому, рассматривать сеансовый и более высокие уровни (или уровень приложений стека TCP/IP) в рамках данной главы не целесообразно. Разумеется, необходимые для работы простых сетей протоколы (такие как NetBios, DNS, FTP, Telnet, http) будут описаны в следующих главах.
С другой стороны, для функционирования простой сети становится более важно умение работать (или настраивать) вполне определенные программные комплексы, а не понимание механизма работы протоколов. Так, например, большинство специалистов предпочитает не вдаваться в протокольные подробности функционирования операционной системы, довольствуясь обычными руководствами по эксплуатации. И, разумеется, такой подход им совершенно не мешает получать хорошие результаты в работе.
Исходя из вышесказанного, на транспортном уровне описание модели OSI можно закончить, и рассматривать работу протоколов более высокого уровня на примере конкретных приложений.
Глава 9 | «« Назад | Оглавление | Вперед »»
Транспортный протокол UDP
Транспортный протокол UDP
Дейтаграммы UDP имеют переменную длину и состоят из заголовка сообщения, и собственно данных.
Таб. 7.7. Формат дейтаграммы UDP
| Номер порта отправителя | Номер порта получателя |
| Длина сообщения | Контрольная сумма |
| Данные |
Номер порта источника указывается только в том случае, если предполагается ответ. Минимальная длина дейтаграммы составляет 8 байт (размер заголовка).
Протокол UDP не обеспечивает гарантированной доставки сообщений. Поэтому, он может быть использован только для приложений, которые не нуждаются в этом качестве. Как пример можно привести передачу звука, или видео. Второй вариант использования UDP - приложения, которые обеспечивают доставку своими средствами. Например, всем известный Telnet и старые версии ICQ.
Транспортный уровень.
Транспортный уровень.
Как следует из названия, протоколы транспортного уровня предназначены для непосредственного взаимодействия двух пользовательских процессов. При этом для передачи информации они используют описанные выше дейтаграммы IP, помещая свои сообщения в их поле данных.
В общем виде существует два типа протоколов транспортного уровня - сегментирующие (TCP, разбивают исходное сообщение на блоки), и не сегментирующие, или дейтаграммные (UDP, отправляют сообщение "как есть", одним куском). Разумеется, второй способ намного проще, но он не гарантирует доставки.
Не будет большой ошибкой сказать, что в реальной сети Интернет используются всего два транспортных протокола:
Протокол передачи пользовательских дейтаграмм (UDP User Datagram Protocol). Протокол управления передачи (TCP Transmission Control Protocol).
На практике для эффективной организации обмена информацией между процессами оказалось недостаточно сетевого адреса узла (на котором выполняется пользовательские программы). Понятно, что на одном компьютере может одновременно работать десятки приложений, и для каждого желательно иметь возможность устанавливать соединения независимо от других. Для решения задачи используется специальный виртуальный интерфейс (порт), номер которого передается в заголовке пакета TCP (или дейтаграммы UDP).
Дополнительные возможности коммутаторов.
Как уже говорилось выше, современные коммутаторы имеют настолько много возможностей, что обычная коммутация (казавшаяся технологическим чудом десять лет назад) уходит на второй план. Действительно, быстро, и относительно качественно, коммутировать кадры умеют модели стоимостью от $50 до $5000. Различие идет именно по дополнительным возможностям.
Понятно, что наибольшее количество дополнительных возможностей имеют управляемые коммутаторы. Далее в описании будут специально выделены опции, которые обычно нельзя корректно реализовать на настраиваемых коммутаторах.
Активные устройства.
Глава 10. Активные устройства.
Из всех способов межличностного общения
он предпочитал полнодуплексные
В предыдущих главах были рассмотрены вопросы построения оптимальной кабельной инфраструктуры. Но сама по себе она не может и не должна являться конечной целью работы. Сеть создается для передачи данных между рабочими станциями, серверами, и другими активными устройствами.
Активные устройства осуществляют формирование, преобразование, коммутацию, а так же прием сигнала с использованием внешнего (не передающегося в составе сигнала) источника энергии. Соответственно, они является неотъемлемым компонентами любой сети передачи данных.
Вопрос правильного выбора оборудования далеко не второстепенен. Даже в недорогих офисных сетях от этого зависит качество и скорость работы сети. Что уж говорить про условия домашних сетей, с их жесткой внешней средой и критическими нагрузками. В этом случае важны даже мелочи, приходится ориентироваться не только на тип и параметры устройства, но на опыт реальной эксплуатации разных моделей.
Активные устройства можно, с некоторой долей условности, разделить на рабочие станции, повторители (концентраторы), коммутаторы, мосты и маршрутизаторы.
Простое соединение рабочих станций было рассмотрено в главе 5, поэтому основное внимание будет уделено другим группам устройств. Кроме этого, в этой главе будут кратко рассмотрены вопросы оптимального выбора по производителю, модельному ряду, и другим факторам, влияющим на стоимость и работоспособность сети.
Использование пассивного оборудования не предусматривается стандартами Ethernet, тем не менее, в некоторых случаях применение возможно, и будет рассмотрено в одной из следующих глав, совместно с описанием альтернативных способов построения сетей.
Глава 10 | «« Назад | Оглавление | Вперед »»
Классификация коммутаторов.
Для определения порта (или портов) назначения, процессору коммутатора необходимо для анализа иметь доступ к заголовку кадра Ethernet. Соответственно, эти данные нужно принять в буфер. Отсюда вытекает различие коммутаторов по способу продвижения кадра:
на лету (cut-through); с буферизаций (Store-and-Forward).
При коммутации "на лету", коммутатор может не помещать приходящие кадры в буфер целиком. Запись их целиком происходит только в случае, когда нужно согласовать скорости передачи, занята шина, или порт назначения. Таким образом, при большом объеме трафика большая часть данных будет все равно в той или иной степени буферизироваться.
Иначе говоря, коммутатор лишь анализирует адрес назначения в заголовке пакета, и в соответствии с САМ-таблицей (время задержки от 10-40 мкс) направляет кадр в соответствующий порт. Штатной является ситуация, когда кадр еще целиком не поступил на входной порт, а его заголовок уже передается через выходной.
При методе полной буферизации (Store-and-Forward) кадр записывается целиком, а лишь затем процессор порта принимает решение о передаче (или фильтрации). Такой путь имеет некоторые недостатки (большое время задержки), и существенные достоинства, например, уничтожение испорченного кадра, поддержка разнородных сетей. Большая часть современных коммутаторов поддерживает именно такой режим работы.
Наиболее сложные и дорогие модели имеют возможность автоматической смены механизма работы коммутатора (адаптацию). В зависимости от объема трафика, количества испорченных кадров, и некоторых других параметров может быть использован один из описанных режимов.
Кроме способа продвижения кадров, коммутаторы можно разделить на группы по внутренней логической архитектуре.
коммутационная матрица; многовходвая разделяемая память; общая шина.
Коммутационная матрицаНаиболее
Коммутационная матрица. Наиболее быстрый способ, который был реализован в первом промышленном коммутаторе. После анализа заголовка входящего кадра процессором порта, в соответствии с таблицей коммутации, в начало кадра добавляется номер порта назначения. Затем кадр (вернее сказать, номер порта назначения) попадал в двухмерную матрицу логических переключателей, каждый из которых управлялся определенным битом номера порта назначения.
Коммутационная матрица пытается установить путь до порта назначения. Если это возможно, последовательно проходя через переключатели, кадр оказывается в нужном исходящем порту.
Если нужный исходящий порт занят (например, соединен с другим входящим портом), кадр остается в буфере входного порта, а процессор ожидает возможности образования коммутационной матрицей нужного пути.
Важной особенностью является то, что коммутируются физические каналы. Таким образом, если несколько кадров должны пройти на один и тот же порт, или через один "общий" переключатель матрицы, сделать это они могут только последовательно. Кроме этого, к недостаткам можно отнести быстро нарастающую с увеличением числа портов сложность. По сути, можно сказать, что решение плохо масштабируемо, и сейчас применяется очень редко (хотя еще есть варианты использования многоступенчатых коммутаторов).
Многовходовая разделяемая память. В этом случае входные и выходные блоки соединяются через общую память, подключением которой к блокам которой управляет специальный менеджер очередей выходных портов. Он же организует в памяти несколько (обычно по числу портов) очередей данных.
Входные блоки передают менеджеру запросы на запись данных (части кадров) в очередь нужного исходящего порта.
Системы такого типа достаточно сложны, требуют дорогой быстродействующей памяти, но не обладают при этом серьезными преимуществами перед более простой шинной архитектурой. Поэтому, широкого практического применения системы с разделяемой памятью не нашли.
Архитектура с общей шиной. Название говорит само за себя - для связи процессоров портов используется одна шина. Для сохранения высокой производительности ее скорость должна быть по крайней мере в C/2 (где C - сумма скоростей всех портов) раз больше, чем скорость поступления данных в порт коммутатора.
Коммутаторы 3-го уровня.
Коммутаторы 3-го уровня.
Технический прогресс двух последних лет не разочаровал поклонников коммутируемого Fast Ethernet. После того, как производители Китая освоили массовый выпуск свитч-чипов стоимость коммутаторов упала почти до уровня упаковки. Действительно, сносный неуправляемый 8-ми портовый коммутатор можно купить дешевле $40. С хорошей упаковкой, документацией, и годовой гарантией.
Поползли вниз и цены на профессиональные управляемые модели. Все, что положено делать "классическому" коммутатору уже имеют модели дешевле $400 за 24 порта. Поэтому можно сказать, что производители коммутаторов в последние несколько лет начали своеобразную "гонку уровней" - ведь не только производителям процессоров нужны четкие и простые ориентиры (типа гигагерцев) для привлечения покупателей. (попытка сыграть на мощности матрицы коммутации провалилась с массовым выходом неблокируемых моделей).
Прогресс пошел по вполне очевидным путем - ведущие производители не захотели соревноваться ценой с устройствами "made in china", и перевели острие технологической моды на усложнение коммутаторов в области расширения их функций за счет возможностей следующих уровней по модели OSI.
И сейчас можно видеть в продаже сравнительно недорогие модели 3-го и 4-го уровней. В них видят что-то вроде универсального средства решения всех проблем сетей - от существенного увеличения производительности до обеспечения конфиденциальности трафика.
В принципе, такую постановку вопроса нельзя считать совсем неверной - хороший коммутатор L3 действительно способен кардинально изменить возможности управления сетью. Но применение теории к реальности (да еще Российской) никогда не было простым. Поэтому вопросов с уровнями выходит много…
Немного теории для тех, кто ее подзабыл. Если сузить поле применения стандартов до конкретной реальности современных бюджетных сетей (не использующих что-либо типа SDH или ATM), то уровень 2 (по семиуровневой модели OSI) соответствует кадрам Ethernet. Соответственно их передвижение происходит согласно MAC-адресам, известных CAM-таблицам коммутаторов. Свитчи, которые "не знают" ничего выше по стеку протоколов называются коммутаторами 2-го уровня.
При этом они могут производить весьма сложные операции. Например, ставить и убирать метки VLAN, распознавать приоритеты (QoS), устанавливать кадры в очереди, определять атаки, считать Ethernet-трафик, шейпить его, фильтровать по номерам портов, и т.п. Классическим типом "продвинутого" L2 можно считать несколько устаревшие на сегодня 3com SuperStack 3300 или Catalyst 2924. Следующие модели этих брендов (например 3com SuperStack 4400 или Catalyst 2950) уже имеют те или иные возможности следующих уровней.
Соединять разные сети Ethernet (т.е. реальные и виртуальные сети 2-го уровня) должны маршрутизаторы, которые обрабатывают данные на 3-м уровне (IP пакетов). При этом заголовки IP идут по сети Ethernet в поле данных, и обычным коммутаторам 2-го уровня недоступны.
Такая технология сложилась из-за того, что традиционно сети Ethernet соединялись друг с другом при помощи иной (не Ethernet) канальной средой передачи данных (WAN). Например Frame Relay, X.25, ATM, G.703, и т.п. Для преобразования данных была нужна гибкость, универсальность, сложный софт, и... хватало небольшой скорости.
Когда сети Ethernet "выросли", внедрились в "магистральные" ниши, то необходимость в таком подходе отпала, и даже более того, стала мешать (как и любая избыточность возможностей). Можно сказать, что очень к месту появились коммутаторы 3-го уровня, способные в добавление к обычным функциям маршрутизировать трафик между портами на IP-уровне. Быстро, но с весьма ограниченными возможностями (как правило нельзя подсчитать трафик, построить сложные фильтры, добавить скрипты, NAT, и т.п.). Хотя конечно есть и монстры типа Catalyst 6509...
Вроде бы почти финал длинной истории L3… Но она еще не совсем закончена. Так, сначала различали маршрутизирующую коммутацию, коммутация потоков и коммутирующую маршрутизацию. Эти термины сейчас можно считать в некотором роде анахронизмом, но корни той же MPLS растут из них, и в дальнейшем смогут сильно изменить дизайн сетей. Но это уже лежит далеко за рамками рассматриваемой темы.
Конечно, о серьезных операторских или корпоративных сетях речь не идет. Можно сказать, что там коммутаторы 3-го и последующих уровней уже прошлый день, и речь идет скорее о внедрении технологий типа MPLS. Но посмотрим, как можно применить коммутаторы 3-го уровня в небольшой или средней бюджетной сети?
Возьмем условную схему сети.
Коммутаторы (Свитчи).
Коммутаторы (Свитчи).
Разделяемая среда передачи данных Ethernet была и остается причиной обвинений этой технологии в недостаточной стабильности и надежности. Отчасти это действительно так - алгоритм CSMA/CD не обманешь никакими программными решениями. И для преодоления этих недостатков фирма Kalpana (впоследствии купленная Cisco) в 1990 предложила технологию коммутации сегментов Ethernet. Таким образом, разделяемая среда (домен коллизий) не ограничивалась (с помощью мостов или маршрутизаторов), а полностью исчезала.
Сказать, что это было принципиальное логическое изобретение, нельзя. Работа основывалось на простом, но в то время труднодостижимом технологическом фундаменте - параллельной обработке поступающих кадров на разных портах (мосты обрабатывают кадры последовательно, кадр за кадром). Это особенность позволила коммутаторам Kalpana передавать кадры независимо между каждой парой портов, и реализовать на практике привлекательную идею отказа от разделяемой среды.
Технологии Ethernet очень повезло, что коммутаторы появились раньше, чем начала применяться технология АТМ. У пользователей вовремя оказалась в наличии достойная альтернатива, позволяющая получить существенный рост качества сети с небольшими затратами. Для этого требовалось лишь заменить концентраторы на коммутаторы, или просто добавить последние в растущую сеть для разделения сегментов. Огромное количество уже установленного оборудования конечных узлов, кабельных систем, повторителей и концентраторов сохранялось, что давало колоссальную экономию по сравнению с переходом на какую-либо новую технологию (например, АТМ).
Коммутаторы (подобно мостам) прозрачны для протоколов сетевого уровня, маршрутизаторы их "не видят". Это позволило не менять основную схему работы сетей между собой.
Более того, в стремительном распространении коммутаторов не последнюю роль сыграла простота их настройки и установки. По умолчанию (без использования дополнительных возможностей) это самообучающееся устройство, его не обязательно конфигурировать. Достаточно правильно подключить кабельную систему к свитчу, а дальше он сможет работать без вмешательства администратора сети, и при этом сравнительно эффективно выполнять поставленную задачу.
В общем, сегодня можно с полной уверенностью сказать, что коммутаторы - это самый мощный, универсальный, удобный для ЛВС класс оборудования. В простейшем случае (как было показано выше) это многопортовый мост Ethernet. Но развитие технологии внесло так много изменений в их свойства, что подчас основной принцип работы тяжело увидеть за нагромождением полезнейших технических возможностей.
Маршрутизаторы.
Маршрутизаторы.
Можно сказать, что маршрутизаторы (роутеры, routегs) - это следующая ступень сетевой иерархии. Упрощенного говоря, их задача - выбор маршрута передачи данных (иначе говоря, объединение разнородных сетей). Соответственно, если мосты для передачи кадров используют адреса физического уровня (МАС), то маршрутизаторы (роутеры) обычно используют IP адреса глобальной сети Интернет.
Для этого им, как минимум, нужно развернуть кадр Ethernet, извлечь из его поля данных дейтаграмму IP, и по ее заголовку направить пакет (возможно, опять упаковав дейтаграмму в кадр Ethernet). Однако, большинство маршрутизаторов работает по еще более сложному алгоритму, используя для передачи данных протоколы следующих уровней модели OSI (TCP, UDP, Nоvеll IРХ, АррlеТаlk II, и другие).
Мосты.
Мосты.
В предыдущем параграфе было показано, что для соединения двух соседних сегментов Ethernet можно применять повторители или концентраторы. Но что делать, если две (или более) сети уже слишком велики для объединения в один коллизионный домен, или, вдобавок, территориально удаленны друг от друга?
Для решения этой задачи применяют мосты (Bridge). Как и повторители, они принимают данные на входящий порт, и передают на исходящий с восстановленными уровнем и формой сигнала. Но на этом сходство заканчивается, и начинаются различия.
Назначение и классификация концентраторов
Основное назначение концентраторов (хабов) - это объединение территориально сосредоточенных рабочих мест в рабочую группу. Но вполне возможно использование хабов в качестве ретрансляторов между удаленными сетями или связи нескольких рабочих групп.
Особенности работы концентраторов
Первое, что необходимо отметить - концентраторы работают на физическом уровне модели OSI. Поэтому для них совершенно безразлично, какие протоколы более высоких уровней используются в сети. Идеология проста и поэтому достаточно надежна. Все порты хаба равноправны, никакой логической обработке сигнал не подвергается, не буферизируется, коллизии не обрабатываются (только фиксируются их наличие на индикации некоторых моделей устройств).
Есть несколько простейших операций, которые делаются большинством концентраторов в автоматическом режиме.
Автосегментация (network integrity), иначе говоря, автоматическое включение или отключение порта. Порт, к которому подсоединена неисправная линия, или не подключено какое-либо активное устройство, считается свободным и находится в неактивном режиме. При обнаружении устройства работоспособность порта восстанавливается. Для этого используются служебные сигналы проверки целостности линии (link test pulses) представляющий собой периодический импульс длительностью 100 нс, посылаемый через каждые 16 мс; Показывают состояние портов (или устройства в целом) на светодиодных индикаторах. Единого подхода к индикации нет, но распространены следующие: состояние портов (Port Status), наличие коллизий (Collisions), активность канала передачи (Activity) и наличие питания (Power); Обнаруживают ошибку полярности (перепутаны проводники внутри пары) при использовании витопарного кабеля, и автоматически ее переключают.
Как повторители, так и концентраторы можно использовать в качестве отдельного устройства, или соединять друг с другом, увеличивая размер сети и усложняя топологию. Возможным вариантом будет шина, звезда, иерархическая звезда (дерево). Кольцевая топология недопустима.
Так как логической обработки сигнала не происходит, данные передаются с использованием всей полосы пропускания. Если не учитывать задержку на хабе (по стандарту IEEE 802.3 менее 3 микросекунд, а в реальности существенно меньше), то концентратор (или повторитель) ничем не отличается по смыслу от сегмента коаксиального кабеля.
В этом есть некоторые плюсы - полная прозрачность перед протоколами более высоких уровней и прямая доступность всех узлов. Но недостатки разделяемой среды то же видны в полной мере. Все устройства, подключенные к сети, построенной на хабах, видят весь сетевой трафик. Данные, адресованные другому узлу, принимаются, анализируются по крайней мере на уровне заголовка кадра, и только после этого отбрасываются.
По скорости можно различить хабы 10baseT и 100baseT. Часто встречаются смешанные конструкции, которые работают на полную скорость только в том случае, если соединены только с оборудованием 100baseT. Последнее легко объяснимо - при разных скоростях на разных портах неизбежно придется каким-то образом обрабатывать данные, и накапливать их в специальном буфере. А это означает резкое усложнение конструкции (вернее так было несколько лет назад).
Надо обратить внимание на следующий момент. В литературе часто встречается разделение повторителей на классы (I и II). И стандарт 802.3u действительно это предусматривает. Различие между ними следующее. Повторители I класса полностью декодируют входящий сигнал, преобразуют его в логическую форму, и передают на активные порты (задержка в районе 0,7 мс). При этом возможно использование нескольких технологий одновременно - например, 100BaseT4, 100BaseTX или 100BaseFX. Повторители II класса восстанавливают форму сигнала без его явного преобразования в логический вид. Соответственно, в этом случае задержка передачи заметно меньше (менее 0,46 мс по стандарту), но можно использовать только один протокол.
Однако в реальной практике встретить концентратор I класса почти невозможно (разве что в музее). Они стали мертворожденным раритетом совместно с 100BaseT4, и ему подобными технологиями.
Повторители и концентраторы.
Повторители и концентраторы.
Одной из первых задач, которая стоит перед любой технологией транспортировки данных, является возможность их передачи на максимально большое расстояние.
Физическая среда накладывает на этот процесс свое ограничение - рано или поздно мощность сигнала падает, и прием становится невозможным. При этом не имеет значения абсолютное значение амплитуды - для распознавания важно соотношение сигнал/шум.
Привычное для аналоговых систем усиление не годится для высокочастотных цифровых сигналов. Разумеется, при его использовании какой-то небольшой эффект может быть достигнут, но с увеличением расстояния искажения быстро нарушат целостность данных.
Проблема не нова, и в таких ситуациях применяют не усиление, а повторение сигнала. При этом устройство на входе должно принимать сигнал, далее распознавать его первоначальный вид, и генерировать на выходе его точное подобие. Такая схема в теории может передавать данные на сколь угодно большие расстояния (если не учитывать особенности разделения физической среды в Ethernet).
Первоначально в Ethernet использовался коаксиальный кабель с топологией "шина", и нужно было соединять между собой всего несколько протяженных сегментов. Для этого обычно использовались повторители (repeater), имевшие два порта. Несколько позже появились многопортовые устройства, называемые концентраторами (concentrator). Их физический смысл был точно такой же, но восстановленный сигнал транслировался на все активные порты, кроме того, с которого пришел сигнал.
Применение маршрутизатора в корпоративно сети
Рисунок 10.4. Применение маршрутизатора в корпоративно сети

Подобно повторителям, маршрутизаторы восстанавливают уровень и форму предаваемого сигнала. Так же, как и мосты, они не передают адресату коллизии или поврежденные кадры, и из-за буферизации имеют задержку при передаче. Но в отличие от повторителей, мостов и коммутаторов, маршрутизаторы изменяют все передаваемые кадры Ethernet (вернее сказать, они их разбирают, и формируют заново по определенным правилам).
Но даже на этом функциональные возможности роутеров не заканчиваются. В зависимости от типа, программного обеспечения, они могут поддерживать очень сложные и не типовые функции. Например, подсчет трафика, авторизацию пользователей, ведение статистики, и т.п.
Так же очень сильно они могут отличаться по мощности. Наиболее простой и недорогой вариант - персональный компьютер с несколькими (или даже одной) сетевыми адаптерами. Программное обеспечение может быть любым, но наиболее распространены клоны unix - linux или FreeBSD, которым обычно достаточно даже устаревших "486" процессорных блоков.
Кроме "самосборных" маршрутизаторов на рынке представлена масса специализированных устройств - от простейших (от $100), до мощных систем (начиная с нескольких, и заканчивая многими сотнями тысяч долларов), способных определять маршруты для значительных потоков данных.
Несмотря на большие функциональные возможности, и сравнительно не большую скорость, маршрутизаторы практически не применяются в локальных сетях. В них просто нет надобности, а большие потенциальные возможности обычно оборачиваются малой надежностью и сложностью в эксплуатации. Поэтому применять маршрутизацию желательно как можно реже, только в случаях, когда от нее невозможно отказаться.
Классический пример их использования в простых провайдинговых схемах - граница между локальной сетью и Интернет. Вот незаменимые преимущества маршрутизаторов в этой технологической нише:
обеспечивает более высокий уровень локализации трафика, чем мост, так как позволяет фильтровать широковещательные кадры, не имеющие корректных адресов назначения (нет угрозы бродкастовых штормов); развитые возможности защиты от несанкционированного доступа из-за возможности использования фильтрации трафика на более высоких уровнях модели OSI (сетевом и транспортном); сеть, части которой соединены через маршрутизаторы, не имеют ограничений на число узлов; обеспечивают возможность настройки параметров качества (Quality of Service, QoS), настройку системы приоритетов, ширины полосы пропускания для каждого типа трафика; поддерживают основные протоколы динамической маршрутизации, такие как RIP, OSPF, BGP-4, IPX RIP/SAP, могут связывать несколько IP сетей одновременно;
Последняя возможность очень важна для построения действительно больших телекоммуникационных сетей со сложной, и часто многосвязной топологией. При этом задача максимально эффективной и быстрой доставки отправленного пакета решается совсем не просто. Распространены два основных алгоритма выбора наиболее выгодного пути и способа: RIP и OSPF.
При использовании протокола RIР, основным критерием выбора является минимальное число сетевых устройств между устройством-отправителем и получателем. Технически это просто реализуется, не требует существенных вычислительных ресурсов, и достаточно часто применяется в простых сетях.
Однако, понятно, что лучше 10 ретрансляторов на оптоволокне, чем одно модемное соединение. Поэтому при использовании RIP на практике появляется много дополнительных ограничений, серьезно затрудняющих управление.
OSPF лишен этих недостатков, поскольку который кроме числа "хопов" учитывает производительности сети, задержки при передаче пакета и т.п. критерии. Оборотной стороной, как обычно, является относительно высокая сложность управления, и требовательность к аппаратным ресурсам.
Производительность маршрутизаторов принято измерять в PPS (Packets Per Second), т.е. количество маршрутизируемых пакетов в секунду. Рассчитать возможную скорость передачи данных легко по следующей формуле:
Скорость = N/(К)*8*S ,
Где:
К - Коэффициент поправки на реальные условия (примерно около 5);
S - размер пакета (для Интернет - ~500, для ЛВС - ~1500, для VOIP - ~100).
Например, для 3620 Cisco получаем 40000/5*500*8=32 Mbit/s
Однако нужно учитывать, что access листы, роутмапы, firewallы, динамический роутинг, и другие дополнительные функции способны снизить реальную скорость маршрутизации в несколько раз.
В заключение параграфа надо сказать, что к рассмотрению роутеров мы еще вернемся в следующих главах, при рассмотрении практической маршрутизации в домашних (территориальных) сетях.
Глава 10 | «« Назад | Оглавление | Вперед »»
Пропускная способность измеряется
Пропускная способность измеряется количеством данных, переданных через порты в единицу времени. Естественно, что чем больше длина кадра (больше данных прикреплено к одному заголовку), тем больше должна быть пропускная способность. Так, при типичной для таких устройств "паспортной" скорости продвижения в 14880 кадров в секунду, пропускная способность составит 5.48 Мб/с на пакетах по 64 байта, и ограничение скорости передачи данных будет наложено коммутатором.
В то же время, при передаче кадров максимальной длины (1500 байт), скорость продвижения составит 812 кадров в секунду, а пропускная способность - 9,74 Мб/c. Фактически, ограничение на передачу данных будет определяться скоростью протокола Ethernet.
Задержка передачи кадра означает время, прошедшее с момента начала записи кадра в буфер входного порта коммутатора, до появления на его выходном порту. Можно сказать, что это время продвижения единичного кадра (буферизация, просмотр таблицы, принятие решения о фильтрации или продвижении, и получение доступа к среде выходного порта).
Величина задержки очень сильно зависит от способа продвижения кадров. Если применяется метод коммутации "на лету", то задержки невелики и составляют от 10 мкс до 40 мкс, в то время как при полной буферизации - от 50 мкс до 200 мкс (в зависимости от длины кадров).
В случае большой загруженности коммутатора (или даже одного из его портов), получается, что даже при коммутации "на лету" большая часть входящих кадров вынужденно буферизируется. Поэтому, наиболее сложные и дорогие модели имеют возможность автоматической смены механизма работы коммутатора (адаптацию) в зависимости от нагрузки и характера трафика.
Размер адресной таблицы (САМ-таблицы). Определяет максимальное количество MAC-адресов, которые содержатся в таблице соответствия портов и МАС-адресов. В технической документации обычно приводится на один порт, как число адресов, но иногда бывает, что указывается размер памяти под таблицу в килобайтах (одна запись занимает не менее 8 кб, и "подменить" число весьма выгодно недобросовестному производителю).
Для каждого порта САМ- таблица соответствия может быть разной, и при ее переполнении наиболее старая запись стирается, а новая - заносится в таблицу. Поэтому при превышении количества адресов сеть может продолжить работу, но при этом сильно замедлиться работа самого коммутатора, а подключенные к нему сегменты будут загружены избыточным трафиком.
Раньше встречались модели (например, 3com SuperStack II 1000 Desktop), в которых размер таблицы позволял хранить один или несколько адресов, из-за чего приходилось относиться очень внимательно к дизайну сети. Однако, сейчас даже самые дешевые настольные коммутаторы имеют таблицу из 2-3К адресов (а магистральные еще больше), и этот параметр перестал быть узким местом технологии.
Объем буфера. Он необходим коммутатору для временного хранения кадров данных в тех случаях, когда нет возможности сразу их передать на порт назначения. Понятно, что трафик неравномерен, всегда есть пульсации, которые нужно сглаживать. И чем больше объем буфера, тем большую нагрузку он может "принять на себя".
Простые модели коммутаторов имеют буферную память в несколько сотен килобайт на порт, в более дорогих моделях это значение достигает нескольких мегабайт.
Производительность коммутаторов. Прежде всего, надо отметить, что коммутатор - сложное многопортовое устройство, и просто так, по каждому параметру в отдельности, нельзя оценить его пригодность к решению поставленной задачи. Существует большое количество вариантов трафика, с разной интенсивностью, размерами кадров, распределением по портам, и т.п. Общей методики оценки (эталонного трафика) до сих пор нет, и используются разнообразные "корпоративные тесты". Они достаточно сложны, и в данной книге придется ограничиться только общими рекомендациями.
Идеальный коммутатор должен передавать кадры между портами с той же самой скоростью, с которой их генерируют подключенный узлы, без потерь, и не вносить дополнительных задержек. Для этого внутренние элементы коммутатора (процессоры портов, межмодульная шина, центральный процессор и т.п.) должны справляться с обработкой поступающего трафика.
В то же время, на практике есть много вполне объективных ограничений на возможности свитчей. Классический случай, когда несколько узлов сети интенсивно взаимодействуют с одним сервером, неизбежно вызовет уменьшение реальной производительности из-за фиксированной скорости протокола.
На сегодня производители вполне освоили производство коммутаторов (10/100baseT), даже очень дешевые модели имеют достаточную пропускную способность, и достаточно быстрые процессоры. Проблемы начинаются, когда нужно применять более сложные методы ограничений скорости подключенных узлов (обратного давления), фильтрации, и других протоколов, рассмотренных ниже.
В заключение, нужно сказать, что лучшим критерием по-прежнему остается практика, когда коммутатор показывает свои возможности в реальной сети.
Схема применения хабов
Рисунок 10.2. Схема применения хабов

Из-за отсутствия в концентраторах каких либо механизмов обеспечения безопасности, гарантированной скорости, их применение рационально только в части сети, где существуют общие требования по этим важным параметрам. Например, неправильным будет соединение при помощи хабов нескольких фирм, или бухгалтерии с отделом нелинейного видеомонтажа.
В каком-то плане хабы можно отнести к устаревшему оборудованию. Действительно, практически по всем техническим показателям они серьезно уступают коммутаторам, и очень близки по цене (дешевле всего на 30-40%). Поэтому, их применение в локальной сети предприятия не имеет смысла - при незначительном увеличении затрат можно получить в десятки (!) раз большую скорость.
Но в домашних или территориальных сетях дело обстоит несколько сложнее. Хабы более надежны в тяжелых условиях эксплуатации, и способны передавать данные на большие расстояния (или по кабелю худшего качества). Поэтому в данной нише им предстоит еще весьма долгая жизнь, окончательно их вытеснит только широкое распространение оптики.
По сложности, можно разделить коцентраторы на следующие классы:
Начальный уровень. 5-ти или 8-ми портовые концентраторы. Часто имеют порт для подсоединения коаксиального кабеля (BNC), реже - порт AUI. При небольшой стоимости ($30-50) являются простым и дешевым решением для сети небольшого размера. Средний уровень. Это 12-ми, 16-ти и 24-х портовые устройства. Имеют 19-ти дюймовое исполнение, BNC или AUI порты. Такое решение позиционируют для построения средних и малых сетей. Однако, в связи с стремительным снижением цен на коммутаторы, вытеснение хабов из этой технической ниши можно считать завершившимся делом. Управляемые концентраторы. Их отличает наличие консольного порта RS-232 для управления или сбора статистики с использованием протоколов SNMР/IР или IРХ. В настоящее время практически не применяются. Хабы 10/100. Обычный хаб может связывать рабочие станции только на одной скорости. Так, стоит в сети, построенной на 100-мегабитных хабах появиться всего одной 10-ти мегабитной сетевой карте, вся сеть начнет работать с этой пониженной скоростью. Это крайне неудобно. Поэтому появились хабы, содержащие коммутатор между 10 и 100 мегабитными шинами. Получилось достаточно удобная и не дорогая конструкция. Но широкого распространения она просто не успела получить, так как была полностью вытеснена дешевыми неуправляемыми свитчами.
Глава 10 | «« Назад | Оглавление | Вперед »»
Схема типичного варианта применения моста
Рисунок 10.3. Схема типичного варианта применения моста

Мост принимает входящий кадр в свой буфер, определяет его целостность и адрес (МАС) назначения. При этом каждая половина моста, анализируя поле адреса отправителя, ведет таблицу Ethernet-адресов узлов, находящихся на своей стороне. На другую сторону моста передаются только кадры широковещательной рассылки (Broadcast), и кадры, не имеющие получателя на своей стороне. Таким образом, коллизии не транслируются (как это происходит в повторителях).
Буферизация данных перед их отправкой (store-and-forward) приводит к возникновению большей по сравнению с концентраторами задержки, что несколько снижает скорость работы сети. С другой стороны, количество устройств, которые разделяю между собой физическую среду, снижается. В результате обычно реальная скорость передачи данных возрастает.
Первые мосты были, подобно повторителям, двухпортовыми. Но распространение получила технология 10baseT, построенная на многопортовых хабах, и следовательно, популярность получили многопортовые мосты. Последние приобрели специальное название - коммутатор (switch), которое полностью вытеснило старый термин.
Тем не менее, совсем из сетевого лексикона мосты не исчезли. Так часто стали называть устройства, предназначенные для связи ЛВС по отличной от Ethernet физической среде. Например, по радиоканалу, xDSL, модемной связи, или другими способами. При этом с одной стороны моста кадры Ethernet будут инкапсулированы в какой-либо иной протокол канального уровня, а с другой - восстановлены обратно.
В свете такого использования, надо отметить следующий момент. Мосты не могут выполнять фрагментацию и повторную сборку пакетов более высокого (сетевого) уровня. Это свойство вызывает важное, но не заметное на первый взгляд следствие. Многие модели мостов имеют ограничение по размеру передаваемого кадра, слишком большой может быть отброшен как поврежденный.
Иногда приходится искусственно снижать посредством параметра MTU (Maximum Transmission Unit) размер дейтаграммы IP перед его инкапсуляцией в кадр Ethernet, что бы не превысить допустимый итоговый размер.
Глава 10 | «« Назад | Оглавление | Вперед »»
Схематическое изображение активных устройств
Рисунок 10.1. Схематическое изображение активных устройств

С появлением протокола 10baseT (витой пары) для избежания терминологической путаницы многопортовые повторители для витой пары стали называться хабами (hub), а коаксиальные - репитерами (по крайней мере в русскоязычной литературе). Эти названия хорошо прижились, и используется в настоящее время очень широко.
Соединение коммутаторов в стек
Соединение коммутаторов в стек. Эта дополнительная опция одна из наиболее простых, и широко используемых в больших сетях. Ее смысл - соединить несколько устройств скоростной общей шиной для повышения производительности узла связи. При этом иногда могут быть использованы опции единого управления, мониторинга и диагностики.
Надо заметить, что не все вендоры используют технологию соединения коммутаторов при помощи специальных портов (стекирование). В этой области все большее распространение получают линии Gigabit Ethernet, или при помощи группировки нескольких (до 8) портов в один канал связи.
Протокол покрывающего дерева (Spanning Tree Protocol, STP). Для простых ЛВС соблюдать в процессе эксплуатации правильную топологию Ethernet (иерархическая звезда) не сложно. Но при большой инфраструктуре это становится серьезной проблемой - неправильная кроссировка (замыкание сегмента в кольцо) может привести к остановке функционирования всей сети или ее части. Причем найти место аварии может быть совсем не просто.
С другой стороны, подобные избыточные связи часто удобны (многие транспортные сети передачи данных построены именно по кольцевой архитектуре), и могут сильно повысить надежность - при наличии корректного механизма обработки петель.
Для решения этой задачи используется Spanning Tree Protocol (STP), при котором коммутаторы автоматически создают активную древовидную конфигурацию связей, находя ее с помощью обмена служебными пакетами (Bridge Protocol Data Unit, BPDU), которые помещаются в поле данных кадра Ethernet. В результате, порты, на которых замыкаются петли, блокируются, но могут быть автоматически включены в случае разрыва основного канала.
Таким образом, технология STA обеспечивает поддержку резервных связей в сети сложной топологии, и возможность ее автоматическую изменения без участия администратора. Такая возможность более чем полезна в больших (или распределенных) сетях, но в силу своей сложности редко используется в настраиваемых коммутаторах.
Способы управления входящим потоком. Как уже отмечалось выше, при неравномерной загрузке коммутатора он просто физически не сможет пропустить через себя поток данных на полной скорости. Но просто отбрасывать лишние кадры по понятным причинам (например разрыв TCP сессий) крайне не желательно. Поэтому приходится использовать механизм ограничения интенсивности передаваемого узлом трафика.
Возможно два способа - агрессивный захват среды передачи (например, коммутатор может не соблюдать стандартные временные интервалы). Но этот способ годится только для "общей" среды передачи, редко используемой в коммутируемом Ethernet. Этим же недостатком обладает метод обратного давления (backpressure), при котором узлу передаются фиктивные кадры.
Поэтому на практике востребована технология Advanced Flow Control (описанна в стандарте IEEE 802.3х), смысл которой в передаче коммутатором узлу специальных кадров "пауза".
Фильтрация трафика. Часто бывает очень полезно задавать на портах коммутатора дополнительных условий фильтрации кадров входящих или исходящих кадров. Таким образом можно ограничивать доступ определенных групп пользователей к определенным сервисам сети, используя МАС-адрес, или тэг виртуальной сети.
Как правило, условия фильтрации записываются в виде булевских выражений, формируемых с помощью логических операций AND и OR.
Сложная фильтрация требует от коммутатора дополнительной вычислительной мощности, и при ее нехватке может существенно снизить производительность устройства.
Возможность фильтрации очень важна для сетей, в которых конечными пользователями выступают "коммерческие" абоненты, поведение которых невозможно регулировать административными мерами. Так как они могут предпринимать несанкционированные деструктивные действия (например, подделывать IP или MAC адрес своего компютера), желательно предоставить для этого минимум возможностей.
Коммутация третьего уровня (Layer 3). Из-за быстрого роста скоростей, и широкого применения коммутаторов, на сегодня образовался видимый разрыв между возможностями коммутации и классической маршрутизацией при помощи универсальных компьютеров. Наиболее логично в этой ситуации дать управляемому коммутатору возможность анализировать кадры на третьем уровне (по 7-ми уровневой модели OSI). Такая упрощенная маршрутизация дает возможность значительно поднять скорость, более гибко управлять трафиком большой ЛВС.
Однако в транспортных сетях передачи данных применение коммутаторов пока очень ограничено, хотя тенденция к стиранию их отличий от маршрутизаторов по возможностям прослеживается достаточно явно.
Управление и возможности мониторинга. Обширные дополнительные возможности подразумевают развитые и удобные средства управления. Ранее простые устройства могли управляться несколькими кнопками через небольшой цифровой индикатор, или через консольный порт. Но это уже в прошлом - последнее время выпускаются коммутаторы с управлением через обычный порт 10/100baseT при помощи Telnet'а, Веб-браузера, или по протоколу SNMP. Если первые два способа по большому счету являются лишь удобным продолжением обычных стартовых настроек, то SNMP позволяет использовать коммутатор как поистине универсальный инструмент.
Для Etherenet интересны только его расширения - RMON и SMON. Ниже описан RMON-I, кроме него существует RMON-II (затрагивающий более высокие уровни OSI). Более того, в свитчах "среднего уровня" как правило, реализованы только группы RMON 1-4 и 9.
Принцип работы следующий: RMON-агенты на свитчах шлют информацию на центральный сервер, где специальное программное обеспечение (например, HP OpenView) обрабатывает информацию, представляя ее в удобном для администрирования виде.
Причем процессом можно управлять - удаленным изменением настроек привести работу сети в норму. Кроме мониторинга и управления, при помощи SNMP можно строить систему биллинга. Пока это выглядит несколько экзотично, но примеры реального использования данного механизма уже есть.
Стандарт RMON-I MIB описывает 9 групп объектов:
Statistics - текущие накопленные статистические данные о характеристиках кадров, количестве коллизий, ошибочных кадров (с детализацией по типам ошибок) и т.п. History - статистические данные, сохраненные через определенные промежутки времени для последующего анализа тенденций их изменений. Alarms - пороговые значения статистических показателей, при превышении которых агент RMON генерирует определенное событие. Реализация этой группы требует реализации группы Events - события. Host - данные о хостах сети, обнаруженных в результате анализа MAC-адресов кадров, циркулирующих в сети. Host TopN - таблица N хостов сети, имеющих наивысшие значения заданных статистических параметров. Traffic Matrix - статистика о интенсивности трафика между каждой парой хостов сети, упорядоченная в виде матрицы. Filter - условия фильтрации пакетов; пакеты, удовлетворяющие заданному условию, могут быть либо захвачены, либо могут генерировать события. Packet Capture - группа пакетов, захваченных по заданным условиям фильтрации. Event - условия регистрации событий и оповещения о событиях.
Более подробное рассмотрение возможностей SNMP потребует не меньшего объема, чем данная книга, поэтому будет целесообразно остановиться на этом, весьма общем описании этого сложного, но мощного инструмента .
Виртуальные сети (Virtual Local-Area Network, VLAN). Пожалуй, это наиболее важная (особенно для домашних сетей), и широко используемая возможность современных коммутаторов. Надо отметить, что существует несколько принципиально отличных способов построения виртуальных сетей с помощью коммутаторов. В связи с большим значением для Ethernet-провайдинга, ее развернутое описание технологии будет сделано в одной из следующих глав.
Краткий же смысл - средствами коммутаторов (2 уровня модели OSI) сделать несколько виртуальных (независимых друг от друга сетей) на одной физической ЛВС Ethernet, предоставив возможность центральному маршрутизатору управлять портами (или группами портов) на отдаленных коммутаторах. Что собственно и делает VLAN очень удобным средством для оказания услуг передачи данных (провайдинга).
Глава 10 | «« Назад | Оглавление | Вперед »»
Техническая реализация коммутаторов.
Техническая основа работы коммутатора достаточно проста, и может быть выражена одним длинным предложением. Кадр, которые попадает на его вход (source port), направляется не на все активные порты (как это делает концентратор), а только на тот, к которому подключено устройство с МАС-адресом, совпадающим с адресом назначения кадра (destination port).
Соответственно, первый вопрос, который приходится решать - соответствие портов коммутатора подключенным устройствам (вернее, их MAC-адресам). Для работы используется специальная таблица соответствия (content-addressable memory, САМ), которую коммутатор формирует в процессе "самообучения" по следующему принципу: стоит порту получить ответ от устройства с физическим адресом Х, как в CAM таблице появляется соответствующая строчка соответствия.
Кадры с адресом назначения (source address, SA), имеющимся в таблице, направляются на соответствующий порт. При этом кадр, предназначенный всем узлам, или имеющий неизвестный коммутатору адрес назначения (destination address, DA), направляется на все активные порты. В процессе работы физические адреса подключенного оборудования могут меняться. При этом в таблице появляется новая запись. Если в ней отсутствует свободное место, стирается самая старая запись (принцип вытеснения).
Так как скорость выборки нужного адреса напрямую зависит от размера САМ таблицы, неиспользованные в течении продолжительного промежутка времени записи автоматически удаляются.
Однако такой упрощенный алгоритм жестко (без изменений) действует только в неуправляемых коммутаторах (Dumb). Это недорогие, простые устройства, которые успешно вытесняют хабы из ниши простейших сетей. Как правило они имеют небольшое количество портов, "офисное" исполнение, и не высокие технические характеристики. Возможность управления администратором отсутствует.
Следующей ступенью развития стали настраиваемые коммутаторы (Smart). В них, используя порт RS-232, обычный Ethernet, или даже простейшую микро-клавиатуру, администратор может менять многие важные конфигурационные параметры, которые считываются затем только один раз (при загрузке). Например, таким образом можно блокировать механизм "самообучения" (составлять статическую таблицу соответствия портов МАС-адресам), устанавливать фильтрацию, виртуальные сети, задавать скорость и многое другое.
Но самые большие возможности имеют управляемые коммутаторы (Intelligent). Они имеют интерфейс к полноценному процессору (точнее, компьютеру, поскольку он имеет и свою память), который позволяет контролировать работу и изменять параметры устройства без перезагрузки. Так же появляется возможность в реальном времени наблюдать за проходящими пакетами, считать проходящий трафик, и т.п.
Однако, несмотря на огромное различие в уровне возможностей (и стоимости), общий принцип остается неизменным. Все узлы оказываются соединенными "отдельными" каналами с полной полосой пропускания (если нет одновременного обращения нескольких устройств к одному), и могут работать не подозревая о существовании друг друга. Единственную опасность для коммутируемой сети представляют "бродкастовые" штормы, т. е. случаи лавинообразно нарастающей перегрузки сети широковещательными (бродкастовыми) кадрами. Однако, во-первых, это возможно только в большох сетях (несколько сотен узлов), во-вторых, большинство управляемых коммутаторов позволяет легко решать и эту проблему за счет разделения одной большой сети на несколько виртуальных.
Соответственно, базовые свойства (и ограничения) Ethernet (как разделяемой среды передачи данных) не применимы к сети, построенной с использованием коммутаторов. Коллизии отсутствуют, нет физического обоснования понятия максимальной длины линии, и максимального количества подключенных устройств.
Например, реально могут использоваться оптоволоконные линии, передающие кадры Ethernet на сотни километров, а локальные сети могут объединять сотни рабочих станций или серверов.
Технические параметры коммутаторов.
Технические параметры коммутаторов.
К основным техническим параметрам, которыми можно оценить коммутатор, построенный с использованием любой архитектуры, является скорость фильтрации (filtering) и скорость продвижения (forwarding).
Скорость фильтрации определяет количество кадров в секунду, с которыми коммутатор успевает проделать следующие операции:
прием кадра в свой буфер; нахождения порта для адреса назначения кадра в адресной таблице; уничтожение кадра (порт назначения совпадает с портом-источником).
Скорость продвижения, по аналогии с предыдущим пунктом, определяет количество кадров в секунду, которые могут быть обработаны по следующему алгоритму:
прием кадра в свой буфер, нахождения порта для адреса назначения кадра; передача кадра в сеть через найденный (по адресной таблице соответствия) порт назначения.
По умолчанию считается, что эти показатели измеряются на протоколе Ethernet для кадров минимального размера (длиной 64 байта). Так как основное время занимает анализ заголовка, то чем короче передаваемые кадры, тем более серьезную нагрузку они создают на процессор и шину коммутатора.
Следующими по значимости техническими параметрами коммутатора будут:
пропускная способность (throughput); задержка передачи кадра. размер внутренней адресной таблицы. размер буфера (буферов) кадров; производительность коммутатора;
Условная схема сети.
Рисунок 10.6. Условная схема сети.
Собственно, большинство небольших сетей так или иначе сводятся к такой простой иллюстрации. А из нескольких подобных сегментов можно построить уже вполне крупную инфраструктуру.
Перечислим варианты установки оборудования.
Полностью неуправляемые коммутаторы. Вариант, разумеется, вполне реальный, но для рассмотрения не интересный. Да и перспективность его в общем сомнительна - слишком много неудобств. Достоинство только одно - сверхнизкая стоимость. S7, S5, S10 - управляемые свитчи 2-го уровня, остальные неуправляемые. Такое построение не даст заметного выигрыша. Если два управляемых коммутатора 2-го уровня разделены неуправляемым (с подключенными пользователями) то не все, но большинство функций (VLAN, QoS) будет потеряно. Поэтому имеет смысл поставить мощные устройства только в точках S7 и S5 - тогда их можно будет использовать эффективно. S7, S5, S10 - управляемые 3-го уровня, остальные неуправляемые. Вполне эффективное использование для разделения сегментов в точках S5, S10, но в S7, рядом с маршрутизатором, функции 3-го уровня могут быть излишни. Ну а в остальных точках контроль над сетью будет неполным. Все коммутаторы управляемые 2-го уровня. Этот вариант дает возможность полностью контролировать и при необходимости маршрутизировать каждый порт сети. Для мультисервисного использования возможно соблюдение QoS, мультикастинг, и прочие функции. Как недостаток - необходим отдельный мощный маршрутизатор, через который пойдет весь междусегментный трафик. S7, S5, S10 - управляемые 3-го уровня, остальные - управляемые 2-го уровня. Этот вариант на сегодня фактически стандарт для серьезных корпоративных и операторских структур, но для небольших сетей рекомендовать его несколько рано. Все коммутаторы управляемые 3-го уровня. Подход возможно и неплох, но на сегодня избыточен даже для корпоративных решений. Про остальные и говорить нечего.
Из краткого перечисления вариантов видно, что при выборе стратегического направления развития можно использовать варианты 3 и 4. Кстати сказать, производители оборудования пришли (судя по продаваемым линейкам) к похожим выводам, но к этому придется вернуть после небольшого отступления.
Сначала надо ответить на вопрос - "зачем нужно разделять трафик на уровне IP?".
Когда сети строились на хабах, ответ был тривиален - нужно разделять коллизионные домены, поэтому маршрутизаторы (коммутаторы L3 обычно были непозволительной роскошью) ставились между каждыми 4 хабами (или 30-40 пользователями). Если этого не делать, то наступала быстрая деградация производительности сети.
Однако, в коммутируемой сети такого ограничения нет. И ее размер ограничивается только бродкастовым трафиком, который постепенно заполняет полосу пропускания. Считается, что "бродкастовый шторм" может наступить около 300-500 одновременно работающих пользователей. И это не предел, если в центре сети использовать оборудование с фильтрацией на 4-м уровне (т.е. по протоколам).
Много ли найдется в России сетей, в которых возможно собрать столько пользователей в помещении, не разделенными каналами WAN? Только единичные случаи, наиболее типичным размером можно считать решения в 100-200 портов. Таким образом, можно сказать что технологическая причина применения L3 в "гладкой" сети Ethernet по сути отсутствует. А традиционно узкие места типа коммутатор-сервер дешевле "расшить" недорогим гигабитом.
Для чего может быть нужно разделение на отдельные сегменты в случае 4? Подсчет локального трафика, ограничение скорости отдельных сегментов, фильтрация, построение закрытых VLAN. В остальном сеть и так полностью управляемая, в ней отдельно можно маршрутизировать каждый отдельный порт. Да и с мультисервисными сервисами проблем не возникнет.
Минусов два. Приличная стоимость управляемого железа (оно понадобится на все порты) и проведение межсегментного трафика через центральный узел, что плохо сказывается на пропускной способности основной магистрали. Собственно последнее и ограничивает размеры плоской сети Ethernet на управляемых коммутаторах 2-го уровня.
Для варианта 3 вероятные причины сегментирования иные. Подсчет трафика на недорогих коммутаторах 3-го уровня делать затруднительно (а при отсутствии финансовых проблем см. вариант 5). Закрытые VLAN то же сделать не удастся - разве что ставить управляемые свитчи во всех точках подключения "отдельных" пользователей. Так что единственный смысл решения - повысить производительность и управляемость сети в некоторых "узких" точках, локализовать неисправности, ограничить доступ пользователей друг до друга хотя бы на уровне нескольких узлов.
Наиболее полно достоинства можно видеть на примере корпоративной сети, распределенной по нескольким отдаленным территориям, которые связаны бриджами xDSL. Коммутаторы L3 позволят строить сети без установки маршрутизаторов на каждый сегмент таким образом, что низкоскоростные xDSL линии будут загружены минимально (только данными, адресованными непосредственно на другую территорию).
Можно сказать, что достоинство данного решения - не нужен выделенный маршрутизатор, нет лишнего трафика через центральные магистрали. Недостаток - из-за многократной маршрутизации на IP-уровне сильно повышается сложность сети - лишние подсети, лишние проблемы. Если сегментов будет более десятка, по неволе придется поднимать OSPF, RIP-2 или что-то подобное из арсенала операторов связи.
Сравним некоторые коммутаторы L3, например D-Link DES-3326S ($800) и Catalyst 3550-24 ($4500). Конечно не на уровне технических параметров, а по парадигме их использования. На мой взгляд, они наиболее полно характеризуют ориентацию производителя оборудования на решение по вариантам 3 и 4 соответственно.
Первый, вероятно, предназначен к использованию по варианту 3, и именно в расчете на небольшие офисные сети, не имеющие разветвленной структуры и требований по ограничению доступа между пользователями. Хорошо вписываются в подобную схему коммутаторы от с портовыми, нетегированными виланами, для которых L3 на ближайшей по топологии развилке - хорошее решение проблемы как скорости, так и безопасности.
Однако большую сеть построить таким образом будет достаточно сложно.
Ну а Cisco 3550 конечно "заточена" под варианта 5, и проходит в связке с Catalyst 2950 через пособия по дизайну сетей. Как раз один 3550 или 3550-12G, и к нему звездой - десяток-другой 2950 (2950T). Это позволяет достичь максимальной скорости передачи данных. Кстати, нет в линейке этого производителя свитчей с портовыми виланами, а вот поддержка тегированных 802.1q на маршрутизирующих портах становится принципиально необходимой...
Подведем краткие итоги.
Решений много, выбирать или комбинировать нужно в каждом конкретном случае по разному. Но на мой взгляд, даже широкое применение устройств L3 с неуправляемыми или частично управляемыми коммутаторами (без поддержки полных возможностей L2) не позволяет получить значительных преимуществ в управлении сетью (нельзя произвольно контролировать каждый отдельный порт). Но с их помощью можно добиться повышения скорости передачи данных на структуре со сложной топологией или большим "горизонтальным" трафиком.
В остальных случаях их применение будет не слишком эффективным из-за наличия недорогой альтернативы гигабитных магистралей. Т.е. пока пользователи включены на 100 мегабит, они не смогут (конечно до определенного количества) перегрузить магистраль до центрального маршрутизатора.
Возможно именно по этой причине сейчас более широкое распространение получили устройства с "возможностями" 3-го, 4-го, или даже более высоких уровней. При этом из полного спектра свойств IP-заголовка берется всего несколько наиболее полезных (например фильтрация по IP адресу). Это не слишком дорого, но уже в некотором роде позволяет принять участие в "гонке уровней".
Дальнейшее развитие ситуации спрогнозировать сложно. Если пользователи массово перейдут на гигабит, а 10-ти гигабитные магистральные линии останутся слишком дорогим удовольствием, то L3 станет более чем востребован (нельзя будет построить даже минимальную "пирамиду скорости" магистраль-пользователь).
Однако, на мой взгляд более реален другой путь. Десятигигабитные сетевые адаптеры уже существуют, и при появлении недорогой возможности перевода основных каналов на 10 гигабит сегодняшняя ситуация повторится - только уже на более высоких скоростях, и с большими "дополнительными" возможностями.
В заключение, остается добавить что есть большое количество локальных вариантов использования коммутаторов 3-го уровня, при которых L3 будет удобен, или даже незаменим. Поэтому о их наличии стоит помнить при проектировании сети. Но так же надо учитывать, что "третий уровень" совсем не волшебное средство решения всех проблем, а лишь инструмент. Который имеет смысл применять к месту и в нужных количествах. Как лекарство.
Глава 10 | «« Назад | Оглавление | Вперед »»
